Em 27 de maio, no salão principal da conferência DevOpsConf 2019, realizada como parte do festival
RIT ++ 2019 , como parte da seção Entrega contínua, foi feito um relatório "werf é a nossa ferramenta para CI / CD em Kubernetes". Ele fala sobre os
problemas e desafios que todos enfrentam ao implantar no Kubernetes , bem como sobre as nuances que podem não ser imediatamente perceptíveis. Analisando possíveis soluções, mostramos como isso é implementado na ferramenta de código aberto
werf .
Desde o programa, nosso utilitário (anteriormente conhecido como dapp) superou o limite histórico de
1000 estrelas no GitHub - esperamos que a crescente comunidade de seus usuários simplifique a vida de muitos engenheiros de DevOps.

Então, apresentamos o
vídeo com o relatório (~ 47 minutos, muito mais informativo que o artigo) e o principal extrato dele em forma de texto. Vamos lá!
Entrega de código no Kubernetes
A conversa não será mais sobre werf, mas sobre CI / CD no Kubernetes, o que implica que nosso software é empacotado em contêineres do Docker
(falei sobre isso no relatório de 2016 ) , e os K8s serão usados para iniciá-lo na produção
(sobre isso - em 2017 ) .
Como é a entrega do Kubernetes?
- Existe um repositório Git com código e instruções para construí-lo. O aplicativo é compilado em uma imagem do Docker e publicado no Registro do Docker.
- No mesmo repositório, há instruções sobre como implantar e executar o aplicativo. No estágio de implantação, essas instruções são enviadas ao Kubernetes, que recebe a imagem desejada do registro e a inicia.
- Além disso, geralmente existem testes. Alguns deles podem ser realizados ao publicar uma imagem. Você também pode (pelas mesmas instruções) implantar uma cópia do aplicativo (em um espaço para nome K8s separado ou em um cluster separado) e executar testes nele.
- Por fim, precisamos de um sistema de IC que receba eventos do Git (ou cliques no botão) e chame todos os estágios indicados: construir, publicar, implantar, testar.

Existem algumas notas importantes aqui:
- Como temos uma infraestrutura imutável, a imagem do aplicativo usada em todas as etapas (preparo, produção, etc.) deve ser uma . Eu falei mais sobre isso e com exemplos aqui .
- Como seguimos a infraestrutura como um código (IaC) , o código do aplicativo e as instruções para compilar e executá-lo devem estar em um repositório . Para mais informações, consulte o mesmo relatório .
- Normalmente, vemos a cadeia de entrega (entrega) assim: o aplicativo é montado, testado, liberado (estágio de liberação) e é tudo - a entrega ocorreu. Mas, na realidade, o usuário recebe o que você lançou, não quando você o entregou à produção, mas quando ele pôde ir até lá e essa produção funcionou. Portanto, acredito que a cadeia de entrega termina apenas no estágio operacional (execução) e, mais precisamente, mesmo no momento em que o código foi removido da produção (substituindo-o por um novo).
Voltemos ao esquema de entrega do Kubernetes descrito acima: ele foi inventado não apenas por nós, mas literalmente por todos que lidaram com esse problema. Em essência, esse padrão agora é chamado GitOps
(mais sobre o termo e as idéias por trás dele podem ser encontradas aqui ) . Vejamos as etapas do esquema.
Fase de Construção
Parece que em 2019 você pode falar sobre a montagem de imagens do Docker, quando todo mundo sabe escrever Dockerfiles e executar a
docker build ? ... Aqui estão as nuances que eu gostaria de prestar atenção:
- O peso da imagem é importante, portanto, use vários estágios para deixar apenas o aplicativo realmente necessário para a imagem.
- O número de camadas deve ser minimizado combinando as cadeias de comandos
RUN dentro do significado. - No entanto, isso aumenta os problemas de depuração , pois quando o assembly falha, você precisa encontrar o comando necessário da cadeia que causou o problema.
- A velocidade de criação é importante porque queremos implementar rapidamente as alterações e observar o resultado. Por exemplo, não quero remontar as dependências nas bibliotecas de idiomas com cada compilação de aplicativo.
- Muitas vezes, muitas imagens são necessárias em um repositório Git, que pode ser resolvido por um conjunto de Dockerfiles (ou estágios nomeados em um arquivo) e um script Bash com sua montagem sequencial.
Foi apenas a ponta do iceberg que todo mundo está enfrentando. Mas existem outros problemas, e em particular:
- Freqüentemente, no estágio de montagem, precisamos montar algo (por exemplo, armazenar em cache o resultado de um comando como o apt em um diretório de terceiros).
- Queremos Ansible em vez de escrever no shell.
- Queremos construir sem o Docker (por que precisamos de uma máquina virtual adicional na qual você precisa configurar tudo para isso quando já existe um cluster Kubernetes no qual você pode executar contêineres?).
- Montagem paralela , que pode ser entendida de diferentes maneiras: comandos diferentes do Dockerfile (se forem usados vários estágios), vários commits de um repositório, vários Dockerfiles.
- Montagem distribuída : queremos coletar algo em vagens “efêmeras”, porque seu cache desaparece, o que significa que ele precisa ser armazenado em algum lugar separadamente.
- Por fim, chamei o pináculo dos desejos de auto- magia : seria ideal ir ao repositório, digitar alguma equipe e obter uma imagem pronta, montada com uma compreensão de como e o que fazer corretamente. No entanto, pessoalmente, não tenho certeza de que todas as nuances possam ser previstas dessa maneira.
E aqui estão os projetos:
- moby / buildkit - um construtor da empresa Docker Inc (já integrada nas versões atuais do Docker), que está tentando resolver todos esses problemas;
- kaniko - um colecionador do Google, que permite construir sem o Docker;
- Buildpacks.io - uma tentativa do CNCF de executar automagia e, em particular, uma solução interessante com rebase para camadas;
- e um monte de outros utilitários como buildah , genuinetools / img ...
... e veja quantas estrelas eles têm no GitHub. Ou seja, por um lado, a
docker build é e pode fazer alguma coisa, mas, na realidade, o
problema não foi completamente resolvido - isso é evidenciado pelo desenvolvimento paralelo de construtores alternativos, cada um dos quais resolve alguns dos problemas.
Construir em werf
Então chegamos ao
werf (anteriormente conhecido como dapp) - o utilitário de código aberto do Flant, o que estamos fazendo há muitos anos. Tudo começou há cerca de 5 anos com scripts Bash que otimizam a montagem de Dockerfiles e, nos últimos 3 anos, o desenvolvimento completo está em andamento no âmbito de um projeto com seu próprio repositório Git
(primeiro no Ruby e depois reescrito no Go, e ao mesmo tempo renomeado) . Quais problemas de compilação são resolvidos no werf?

Os problemas sombreados em azul já foram implementados, a montagem paralela foi realizada no mesmo host e planejamos concluir as perguntas amarelas até o final do verão.
Estágio de publicação no registro (publicação)
Digitamos o
docker push ... - o que pode ser difícil no upload de uma imagem para o registro? E então surge a pergunta: "Qual tag colocar a imagem?" Surge pela razão de termos o
Gitflow (ou outra estratégia do Git) e o Kubernetes, e o setor está comprometido em garantir que o que está acontecendo no Kubernetes siga o que está sendo feito no Git. Git é a nossa única fonte de verdade.
O que é tão complicado?
Garanta a reprodutibilidade : de uma confirmação no Git, inerentemente
imutável , a uma imagem do Docker que deve ser mantida igual.
Também é importante
determinarmos a origem , porque queremos entender a partir de qual commit o aplicativo iniciado no Kubernetes foi construído (então podemos fazer diferenças e coisas semelhantes).
Estratégias de marcação
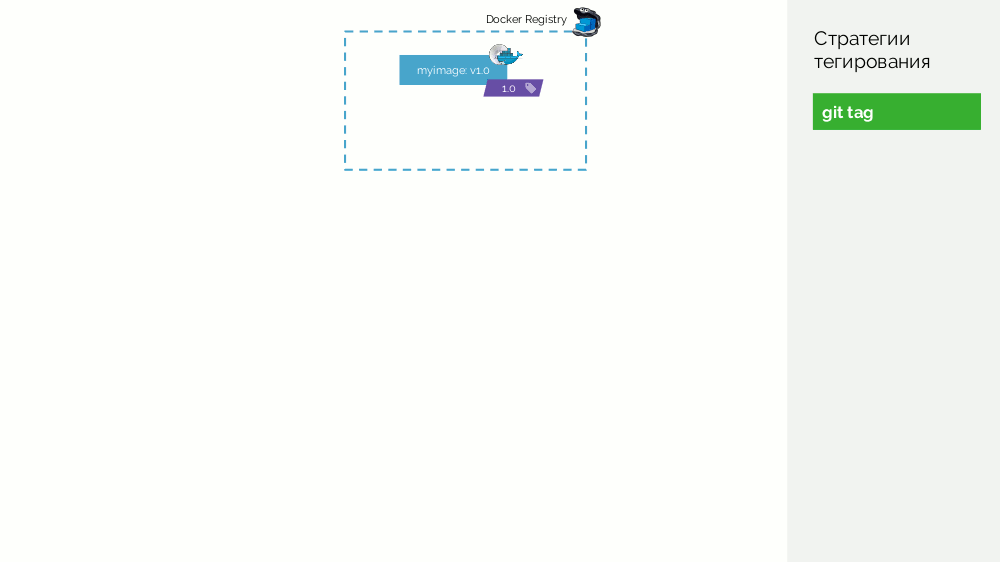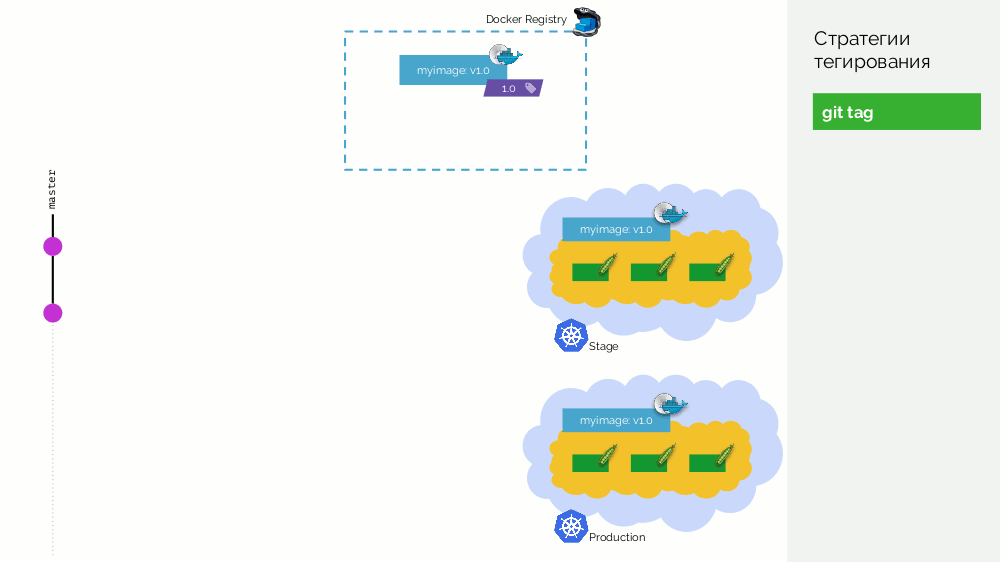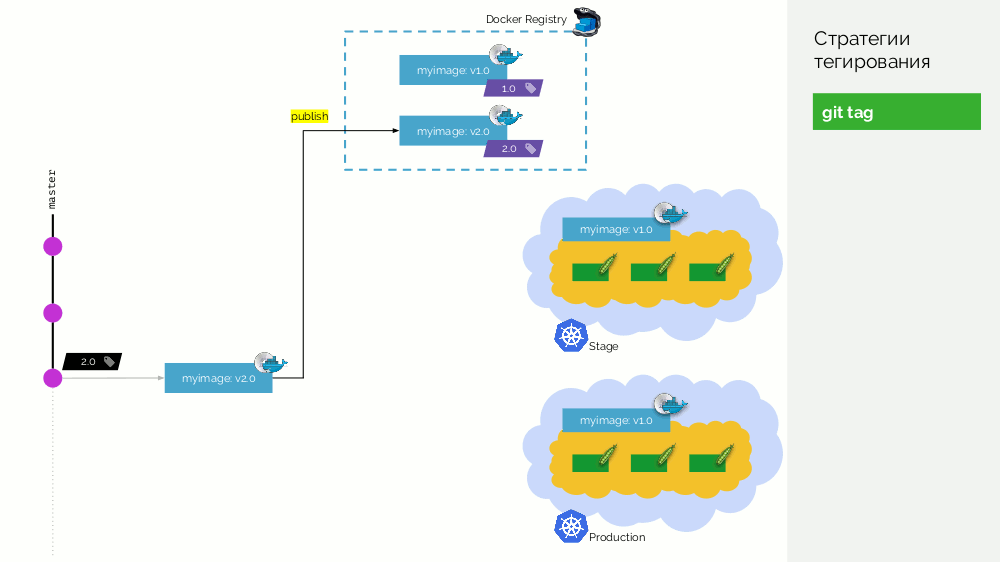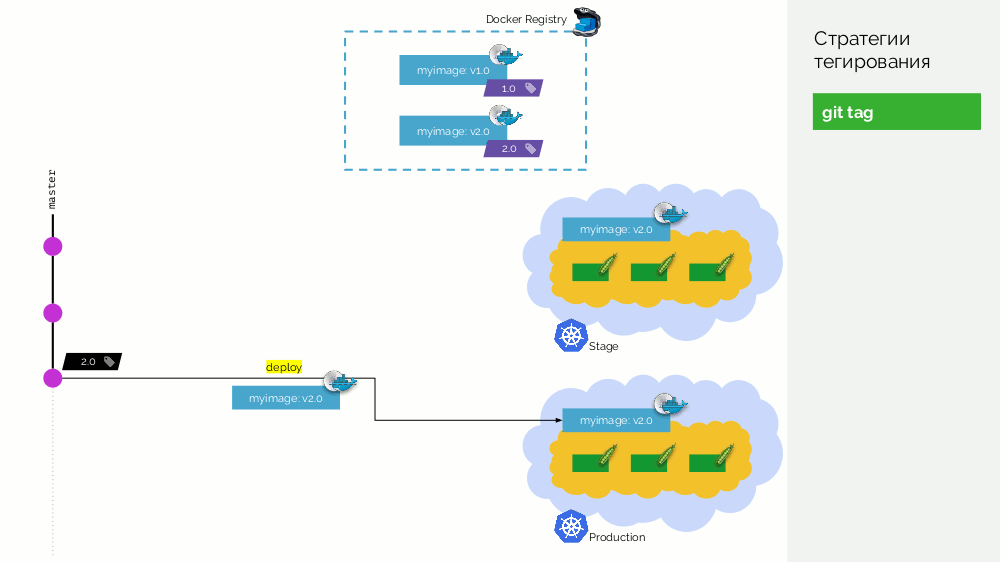
O primeiro é uma
tag git simples. Temos um registro com uma imagem marcada como
1.0 . Kubernetes tem palco e produção, onde esta imagem é bombeada. No Git, fazemos commits e, em algum momento, colocamos a tag
2.0 . Nós o coletamos de acordo com as instruções do repositório e o colocamos no registro com a tag
2.0 . Nós lançamos no palco e, se estiver tudo bem, então na produção.
O problema com essa abordagem é que primeiro definimos a tag e só então a testamos e a implementamos. Porque Primeiro, isso é simplesmente ilógico: fornecemos uma versão do software que ainda não testamos (não podemos fazer o contrário, porque, para verificar, você precisa colocar uma tag). Em segundo lugar, esse caminho não é compatível com o Gitflow.
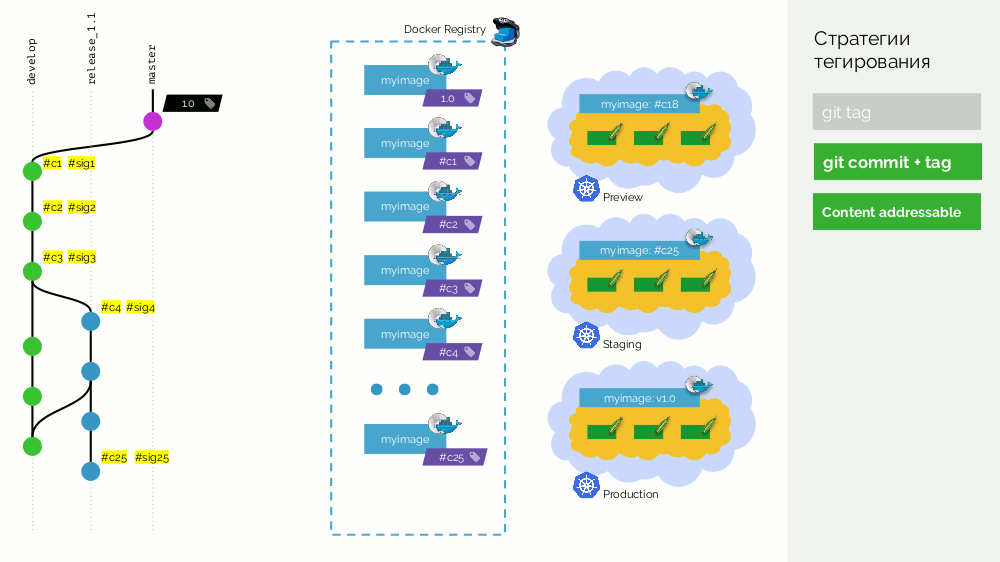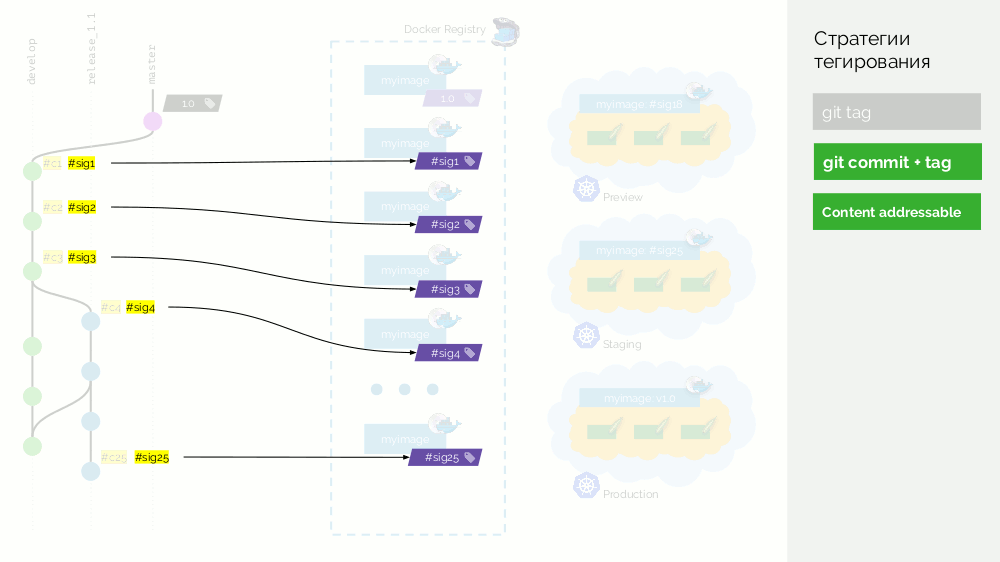
A segunda opção é
git commit + tag . Há uma tag
1.0 no ramo mestre; para ele no registro - uma imagem implantada na produção. Além disso, o cluster Kubernetes possui loops de pré-visualização e preparação. Além disso, seguimos o Gitflow: no ramo principal do desenvolvimento,
develop novos recursos, como resultado do qual existe um commit com o identificador
#c1 . Nós coletamos e publicamos no registro usando este identificador (
#c1 ). Lançamos a visualização com o mesmo identificador. Fazemos o mesmo com os commits
#c2 e
#c3 .
Quando percebemos que existem recursos suficientes, começamos a estabilizar tudo. No Git, crie a ramificação
release_1.1 (com base no
#c3 do
develop ). A coleta deste release não é necessária, porque Isso foi feito na etapa anterior. Portanto, podemos apenas implementá-lo na preparação. Corrigimos bugs no
#c4 e
#c4 mesma forma na preparação. Ao mesmo tempo, o desenvolvimento está em andamento no
develop , onde as alterações da
release_1.1 são realizadas periodicamente. Em algum momento, recebemos um commit e
#c25 para o commit temporário, com o qual estamos felizes (
#c25 ).
Em seguida, fazemos uma mesclagem (com avanço rápido) da ramificação de lançamento (
release_1.1 ) no master. Colocamos uma tag com a nova versão (
1.1 ) nesse commit. Mas essa imagem já está montada no registro, portanto, para não coletá-la novamente, basta adicionar uma segunda tag à imagem existente (agora ela possui as tags
#c25 e
1.1 no registro). Depois disso, lançamos para produção.
Existe uma desvantagem de que uma imagem (
#c25 ) é
#c25 no preparo e outra (
1.1 ) é
#c25 na produção, mas sabemos que "fisicamente" é a mesma imagem do registro.
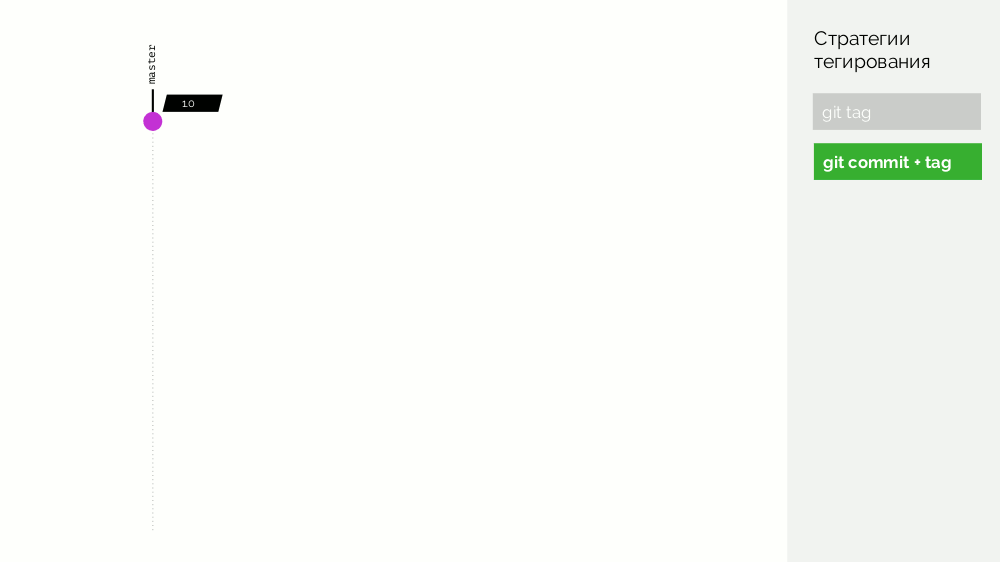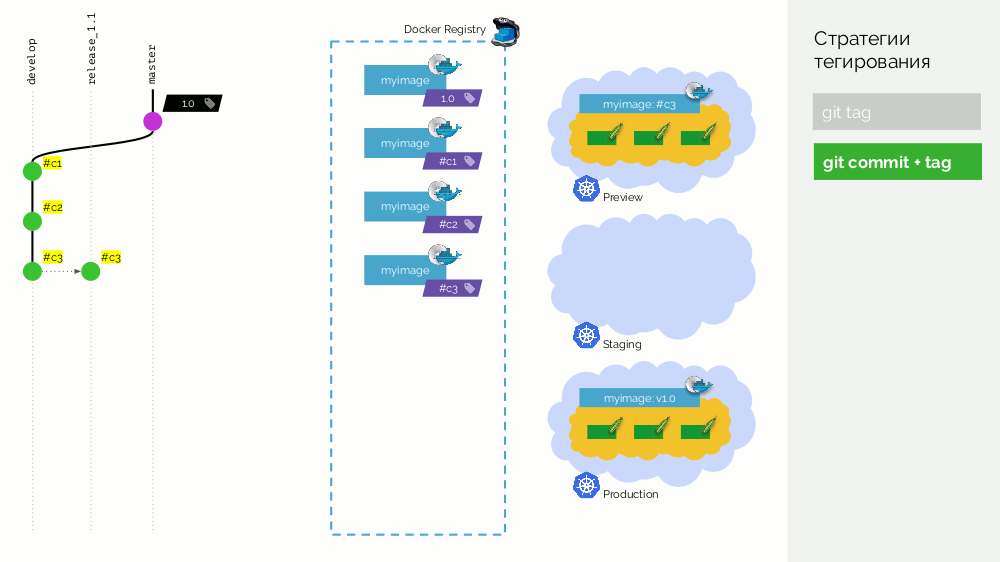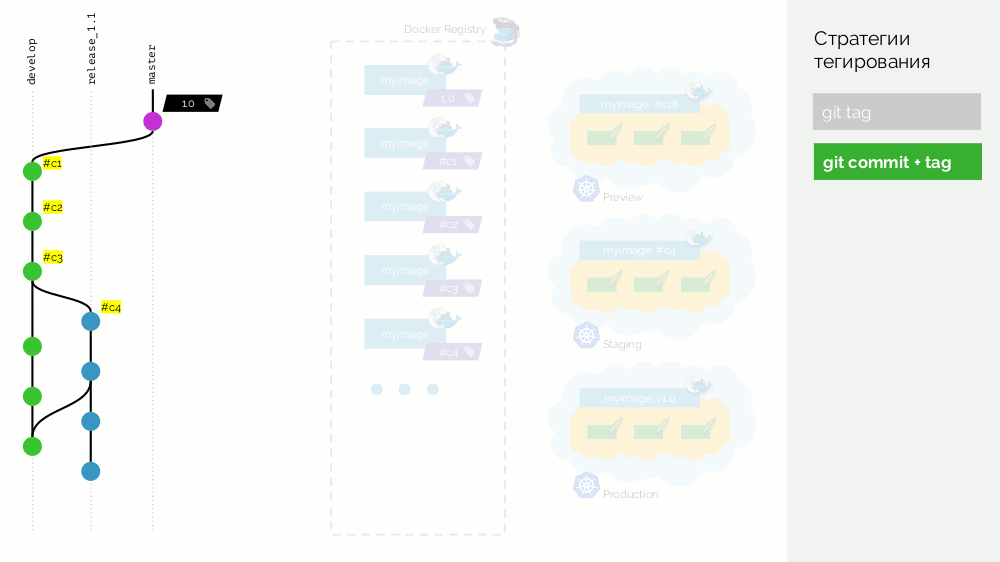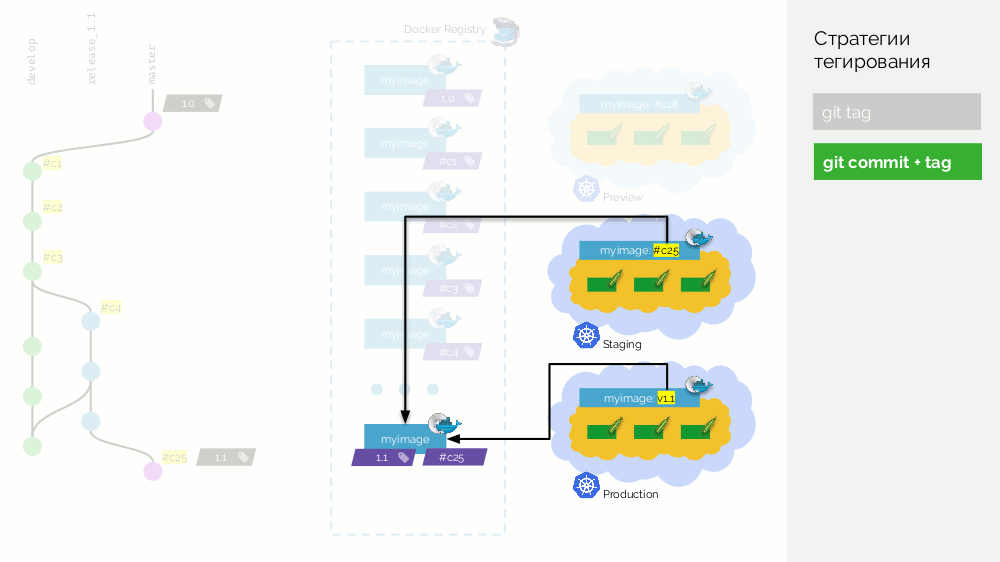
O real menos é que não há suporte para mesclar commit'ov, você precisa avançar rapidamente.
Você pode ir além e executar o truque ... Considere um exemplo de um Dockerfile simples:
FROM ruby:2.3 as assets RUN mkdir -p /app WORKDIR /app COPY . ./ RUN gem install bundler && bundle install RUN bundle exec rake assets:precompile CMD bundle exec puma -C config/puma.rb FROM nginx:alpine COPY --from=assets /app/public /usr/share/nginx/www/public
Nós construímos um arquivo a partir dele de acordo com este princípio, que usamos:
- SHA256 de identificadores de imagens usadas (
ruby:2.3 e nginx:alpine ), que são somas de verificação de seu conteúdo; - todas as equipes (
RUN , CMD , etc.); - SHA256 dos arquivos que foram adicionados.
... e pegue a soma de verificação (novamente SHA256) desse arquivo. Essa é a
assinatura de tudo que define o conteúdo de uma imagem do Docker.

Vamos voltar ao esquema e, em
vez de confirmações, usaremos essas assinaturas , ou seja, marque imagens com assinaturas.
Agora, quando você precisar, por exemplo, mesclar alterações da versão para master, podemos fazer uma consolidação de mesclagem real: ela terá um identificador diferente, mas a mesma assinatura. Com o mesmo identificador, apresentaremos a imagem na produção também.
A desvantagem é que agora não será possível determinar que tipo de confirmação foi bombeada para a produção - as somas de verificação funcionam apenas em uma direção. Esse problema é resolvido por uma camada adicional com metadados - vou contar mais adiante.
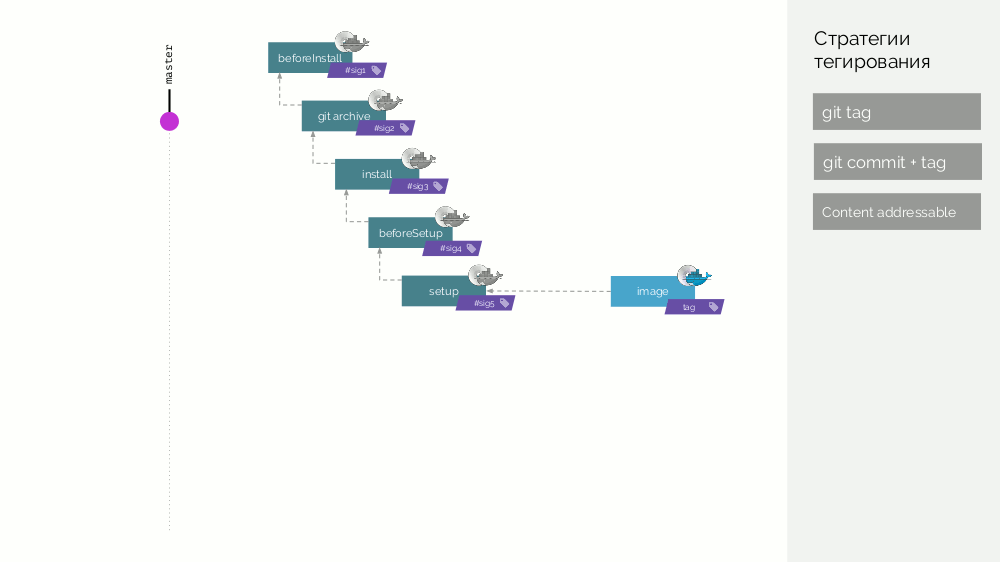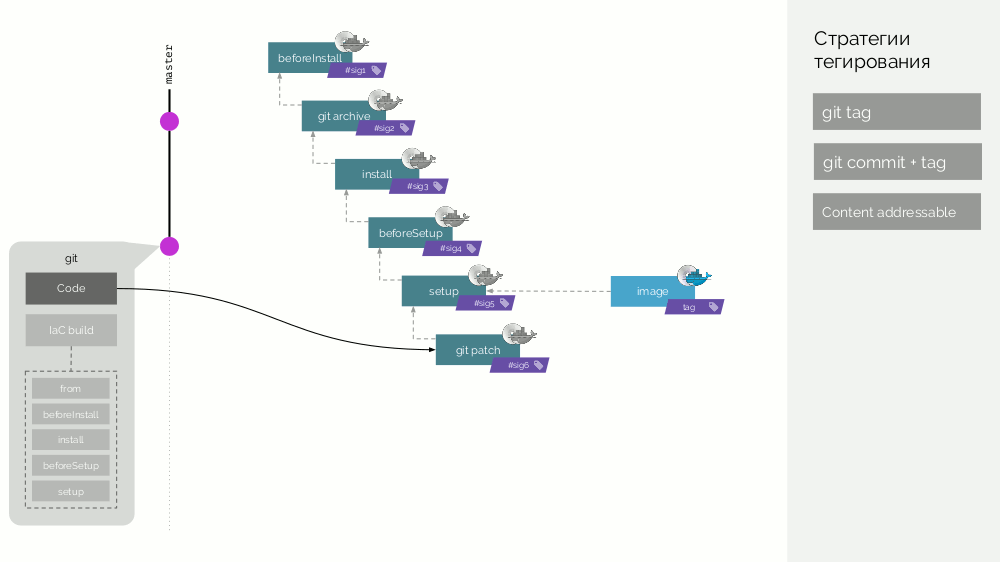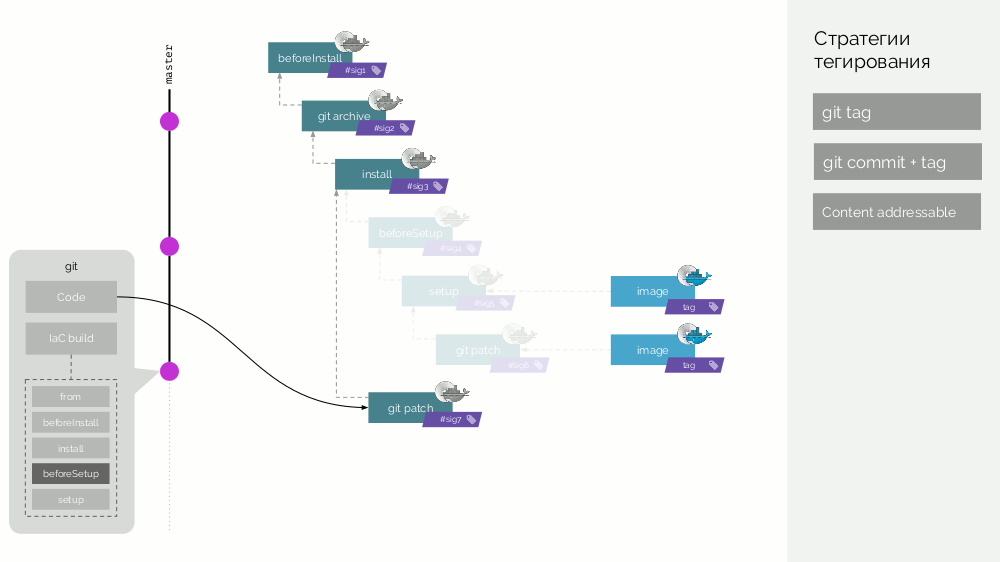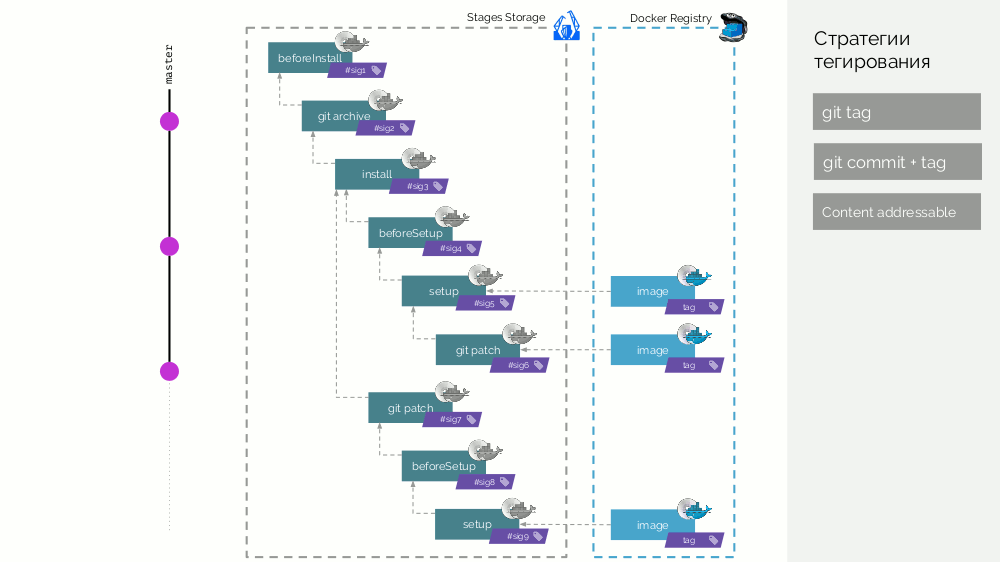
Marcando em werf
No werf, fomos ainda mais longe e estamos nos preparando para fazer uma montagem distribuída com um cache que não é armazenado na mesma máquina ... Portanto, temos dois tipos de imagens do Docker, que chamamos de
estágio e
imagem .
O repositório werf Git armazena instruções de construção específicas que descrevem os diferentes estágios da construção (
beforeInstall ,
install ,
beforeSetup ,
setup ). Coletamos a imagem do primeiro estágio com uma assinatura definida como a soma de verificação das primeiras etapas. Em seguida, adicionamos o código fonte; para a nova imagem de palco, consideramos sua soma de verificação ... Essas operações são repetidas para todos os estágios, como resultado, obtemos um conjunto de imagens de palco. Em seguida, fazemos a imagem-imagem final contendo também metadados sobre sua origem. E identificamos essa imagem de maneiras diferentes (detalhes mais adiante).

Deixe depois que um novo commit apareça, no qual apenas o código do aplicativo seja alterado. O que vai acontecer? Um patch será criado para alterações de código, uma nova imagem de estágio será preparada. Sua assinatura será definida como a soma de verificação da imagem do estágio antigo e do novo patch. A partir desta imagem, uma nova imagem-imagem final será formada. Comportamento semelhante ocorrerá com alterações em outros estágios.
Assim, as imagens de palco são um cache que pode ser distribuído distribuído e as imagens de imagem já criadas a partir dele são carregadas no Docker Registry.
Limpeza do registro
Não se trata de excluir camadas que permanecem suspensas após as tags excluídas - esse é um recurso padrão do próprio Docker Registry. É uma situação em que muitas tags do Docker estão se acumulando e entendemos que não precisamos mais de algumas delas, e elas ocupam espaço (e / ou pagamos por isso).
Quais são as estratégias de limpeza?
- Você simplesmente não pode limpar nada. Às vezes, é muito mais fácil pagar um pouco pelo espaço extra do que desvendar uma enorme bola de tags. Mas isso só funciona até um certo ponto.
- Reset completo . Se você excluir todas as imagens e reconstruir apenas as relevantes no sistema de IC, poderá ocorrer um problema. Se o contêiner reiniciar na produção, uma nova imagem será carregada para ele - uma que ainda não foi testada por ninguém. Isso mata a ideia de infraestrutura imutável.
- Azul esverdeado . Um registro começou a transbordar - carregando imagens em outro. O mesmo problema do método anterior: em que momento você pode limpar o registro que começou a transbordar?
- Pelo tempo . Excluir todas as imagens com mais de 1 mês? Mas com certeza existe um serviço que não foi atualizado por um mês ...
- Determine manualmente o que já pode ser excluído.
Existem duas opções realmente viáveis: não limpe ou uma combinação de azul esverdeado + manualmente. No último caso, estamos falando do seguinte: quando entender que é hora de limpar o registro, crie um novo e adicione todas as novas imagens por, por exemplo, um mês. Um mês depois, veja quais pods no Kubernetes ainda estão usando o registro antigo e transfira-os para o novo registro também.
Para onde fomos a
werf ? Nós coletamos:
- Git head: todas as tags, todas as ramificações, - assumindo que tudo o que é testado no Git, precisamos nas imagens (e, se não, precisamos excluir no próprio Git);
- todos os pods que agora são baixados no Kubernetes;
- ReplicaSets antigos (algo que foi lançado recentemente), bem como planejamos digitalizar versões do Helm e selecionar as imagens mais recentes lá.
... e criamos uma lista de permissões deste conjunto - uma lista de imagens que não excluiremos. Limpamos tudo o resto, após o que encontramos as imagens de palco órfãs e as excluímos também.
Estágio de implantação (implantação)
Declaratividade robusta
O primeiro ponto que eu gostaria de chamar a atenção na implantação é implementar a configuração de recursos atualizada, declarada declarativamente. O documento YAML original que descreve os recursos do Kubernetes é sempre muito diferente do resultado que realmente funciona no cluster. Como o Kubernetes adiciona à configuração:
- identificadores
- informações de serviço;
- muitos valores padrão;
- seção com status atual;
- alterações feitas como parte do webhook de admissão;
- o resultado do trabalho de vários controladores (e agendador).
Portanto, quando uma nova configuração de um recurso (
novo ) aparece, não podemos simplesmente pegar e substituir com ele a atual configuração "ativa" (
ativa ). Para fazer isso, precisamos comparar a
nova configuração com a última aplicada (
última aplicação ) e lançar o patch resultante no
live .
Essa abordagem é chamada
mesclagem bidirecional . É usado, por exemplo, no Helm.
Há também uma
mesclagem de três vias , que difere em que:
- comparando o último aplicado e o novo , examinamos o que foi removido;
- comparando novo e ao vivo , vemos o que foi adicionado ou alterado;
- aplique o patch resumido para viver .
Implementamos mais de 1000 aplicativos com o Helm, portanto, vivemos com uma mesclagem bidirecional. No entanto, ele tem vários problemas que resolvemos com nossos patches que ajudam o Helm a funcionar normalmente.
Status real de lançamento
Após o próximo evento, nosso sistema de IC gerou uma nova configuração para o Kubernetes, passando-a para
aplicar ao cluster usando Helm ou
kubectl apply . Em seguida, ocorre a mesclagem N-way já descrita, para a qual a API do Kubernetes aprova o sistema de IC e o último responde ao usuário.

No entanto, há um enorme problema: afinal, um
aplicativo bem -
sucedido não significa uma implementação bem-sucedida . Se o Kubernetes entende quais alterações aplicar, aplica-as - ainda não sabemos qual será o resultado. Por exemplo, a atualização e a reinicialização de pods no front-end podem ser bem-sucedidas, mas não no back-end, e obteremos versões diferentes das imagens do aplicativo em execução.
Para fazer tudo certo, surge um link adicional nesse esquema - um rastreador especial que receberá informações de status da API do Kubernetes e as transmitirá para uma análise mais aprofundada do estado real das coisas. Criamos uma biblioteca de código aberto no Go -
kubedog (veja seu anúncio aqui ) - que resolve esse problema e é incorporado ao werf.
O comportamento desse rastreador no nível werf é configurado usando anotações colocadas em Deployments ou StatefulSets. A anotação principal,
fail-mode , compreende os seguintes significados:
IgnoreAndContinueDeployProcess - ignore os problemas de IgnoreAndContinueDeployProcess deste componente e continue a implantação;FailWholeDeployProcessImmediately - um erro neste componente interrompe o processo de implantação;HopeUntilEndOfDeployProcess - esperamos que este componente funcione até o final da implantação.
Por exemplo, uma combinação de recursos e valores de anotação no
fail-mode :

Ao implantar pela primeira vez, o banco de dados (MongoDB) ainda não está pronto - as implantações falham. Mas você pode esperar até o momento em que iniciar e a implantação ainda passará.
Existem mais duas anotações para o kubedog no werf:
failures-allowed-per-replica - o número de quedas permitidas por réplica;show-logs-until - ajusta o momento até o qual o werf mostra (no stdout) logs de todos os pods que estão sendo lançados. Por padrão, é PodIsReady (para ignorar as mensagens que mal precisamos quando o tráfego começa a chegar no pod), no entanto, os valores ControllerIsReady e EndOfDeploy também EndOfDeploy .
O que mais queremos da implantação?
Além dos dois pontos já descritos, gostaríamos de:
- ver logs - e apenas necessário, mas não tudo;
- acompanhar o progresso , porque se um trabalho "silenciosamente" travar por vários minutos, é importante entender o que está acontecendo lá;
- ter uma reversão automática caso algo dê errado (e, portanto, é fundamental saber o status real da implantação). A distribuição deve ser atômica: ou vai até o fim ou tudo volta ao seu estado anterior.
Sumário
Como empresa, para nós, implementar todas as nuances descritas em diferentes estágios de entrega (compilação, publicação, implantação), o sistema de CI e o utilitário
werf são
suficientes .
Em vez de uma conclusão:

Com a ajuda do werf, fizemos um bom progresso na solução de um grande número de problemas dos engenheiros do DevOps e ficaremos felizes se a comunidade em geral, pelo menos, tentar esse utilitário na prática. Conseguir um bom resultado juntos será mais fácil.
Vídeos e slides
Vídeo da apresentação (~ 47 minutos):
Apresentação do relatório:
PS
Outros relatórios do Kubernetes em nosso blog: