Nota perev. : O autor deste material é Cindy Sridharan, engenheira da imgix que está envolvida no desenvolvimento de APIs e, em particular, no teste de microsserviços. Neste artigo, ela compartilha sua visão detalhada dos problemas reais no campo do rastreamento distribuído, onde, em sua opinião, há uma falta de ferramentas realmente eficazes para resolver problemas prementes. [A ilustração é emprestada de outro material sobre rastreamento distribuído.]
[A ilustração é emprestada de outro material sobre rastreamento distribuído.]Acredita-se que o
rastreamento distribuído seja difícil de implementar e o retorno sobre ele
seja duvidoso . O "problema" do rastreamento é explicado por vários motivos, geralmente referindo-se à complexidade de configurar cada componente do sistema para transmitir os cabeçalhos correspondentes, juntamente com cada solicitação. Embora esse problema ocorra, ele não pode ser chamado de intransponível. A propósito, não explica por que os desenvolvedores realmente não gostam de rastrear (mesmo que já estejam funcionando).
A principal dificuldade do rastreamento distribuído não é coletar dados, não padronizar os formatos de distribuição e apresentação dos resultados e não determinar quando, onde e como fazer a amostra. Não estou tentando apresentar esses "problemas de digestibilidade" como
triviais - na verdade, existem desafios técnicos e (se realmente estamos olhando para os
padrões e protocolos de código aberto) bastante políticos que devem ser superados para que esses problemas possam ser considerados resolvido.
No entanto, se você imaginar que todos esses problemas foram resolvidos, é provável que nada mude significativamente em termos de
experiência do usuário final . O rastreamento ainda pode não ser prático nos cenários de depuração mais comuns - mesmo após a implantação.
Um traço tão diferente
O rastreamento distribuído inclui vários componentes diferentes:
- equipar aplicativos e middleware com controles;
- Transmissão de contexto distribuído
- coleção de traços;
- armazenamento de vestígios;
- sua extração e visualização.
Muita conversa sobre rastreamento distribuído se resume a considerá-lo como um tipo de operação unária, cujo único objetivo é ajudar no diagnóstico completo do sistema. Isso se deve em grande parte à maneira como o conceito de rastreamento distribuído foi formado. Em
um post feito quando as fontes Zipkin foram abertas, foi mencionado que
ele [Zipkin] torna o Twitter mais rápido . As primeiras ofertas comerciais para rastreamento também foram promovidas como
ferramentas de APM .
Nota perev. : Para que o texto adicional seja melhor compreendido, definimos dois termos básicos de acordo com a documentação do projeto OpenTracing :- Extensão - o elemento básico do rastreamento distribuído. É uma descrição de um determinado fluxo de trabalho (por exemplo, uma consulta ao banco de dados) com um nome, horário de início e término, tags, logs e contexto.
- As extensões geralmente contêm links para outras extensões, o que permite combinar várias extensões no Rastreio - uma visualização da vida útil de uma solicitação à medida que ela se move por um sistema distribuído.
O Trace'y contém dados incrivelmente valiosos que podem ajudar em tarefas como: teste na produção, realização de testes de recuperação de desastres, teste com a introdução de erros etc. De fato, algumas empresas já usam o rastreamento para esses fins. Para começar,
a transferência de contexto universal tem outros usos, além de simplesmente transferir extensões para o sistema de armazenamento:
- Por exemplo, o Uber usa resultados de rastreamento para distinguir entre o tráfego de teste e o tráfego de produção.
- O Facebook usa dados de rastreamento para analisar o caminho crítico e alternar o tráfego durante testes regulares de recuperação de desastres.
- A rede social também usa blocos de anotações Jupyter, que permitem que os desenvolvedores executem consultas arbitrárias nos resultados do rastreamento.
- Os adeptos da injeção de falha controlada por linhagem ( LDFI) usam rastreamentos distribuídos para teste de erro.
Nenhuma das opções acima se refere inteiramente ao cenário de
depuração , durante o qual o engenheiro tenta resolver o problema observando o rastreamento.
Quando se trata do cenário de depuração, o diagrama de
rastreamento de rastreamento continua sendo a interface principal (embora alguns também o chamem de
"gráfico de Gantt" ou
"diagrama em cascata" ). Por
visualização em rastreamento, quero
dizer todos os intervalos e metadados associados que juntos formam o rastreamento. Cada sistema de rastreamento de código aberto, bem como cada solução comercial de rastreamento, oferece uma interface de usuário baseada em
traceview para visualizar, detalhar e filtrar dados de rastreamento.
O problema com todos os sistemas de rastreamento com os quais estou familiarizado no momento é que a
visualização final
(visualização em rastreamento) reflete quase completamente os recursos do processo de geração de rastreamento. Mesmo quando visualizações alternativas são oferecidas: mapas de intensidade (mapa de calor), topologias de serviço, histogramas de latência - no final, eles ainda se
resumem à
visualização em
rastreamento .
No passado, eu
reclamei que a maioria das “inovações” na rastreabilidade em relação à interface do usuário / UX parece
estar limitada a
incluir metadados adicionais no rastreamento, incorporar informações com
alta cardinalidade neles ou fornecer a capacidade de detalhar detalhes em extensões específicas ou executar consultas
entre e intra-rastreamento . Nesse caso, a
traceview continua sendo o principal meio de visualização. Enquanto esse estado de coisas persistir, o rastreamento distribuído (na melhor das hipóteses) ocupará o 4º lugar como ferramenta de depuração, seguido por métricas, logs e rastreios de pilha, e na pior das hipóteses, será um desperdício de dinheiro e tempo.
Problema com o rastreamento
O objetivo da
traceview é fornecer uma imagem completa do movimento de uma solicitação individual em todos os componentes de um sistema distribuído ao qual ela se relaciona. Alguns sistemas de rastreamento mais avançados permitem que você faça drill down em intervalos individuais e visualize a divisão do tempo
em um único processo (quando os intervalos têm limites funcionais).
A premissa básica da arquitetura de microsserviços é a ideia de que a estrutura organizacional cresce com as necessidades da empresa. Os defensores dos microsserviços argumentam que a distribuição de várias tarefas de negócios em serviços separados permite que equipes de desenvolvimento autônomas pequenas controlem todo o ciclo de vida desses serviços, permitindo que eles criem, testem e implantem esses serviços independentemente. No entanto, a desvantagem dessa distribuição é a perda de informações sobre como cada serviço interage com outros. Em tais circunstâncias, o rastreamento distribuído afirma ser uma ferramenta indispensável para
depurar interações complexas entre serviços.
Se você tem um
sistema distribuído verdadeiramente
incrivelmente complexo , ninguém consegue ter em mente sua imagem
completa . De fato, o desenvolvimento de uma ferramenta baseada na suposição de que geralmente é possível é um pouco antipadrão (abordagem ineficiente e improdutiva). Idealmente, a depuração requer uma ferramenta para ajudar a
restringir sua pesquisa, para que os engenheiros possam se concentrar em um subconjunto das dimensões (serviços / usuários / hosts, etc.) relevantes para o cenário em questão. Ao determinar a causa da falha, os engenheiros não precisam entender o que aconteceu em
todos os serviços de uma só vez , pois esse requisito contradiz a própria idéia de uma arquitetura de microsserviço.
No entanto, a traceview é
exatamente isso. Sim, alguns sistemas de rastreamento oferecem visualizações de rastreamento compactadas quando o número de extensões no rastreamento é tão grande que não podem ser exibidas em uma única visualização. No entanto, devido à grande quantidade de informações contidas mesmo em uma visualização tão truncada, os engenheiros ainda são
forçados a analisá-la, restringindo manualmente a seleção a um conjunto de fontes de serviço de problemas. Infelizmente, neste campo, as máquinas são muito mais rápidas que os humanos, menos propensas a erros e seus resultados são mais repetíveis.
Outra razão pela qual acho que o método traceview está errado é porque não é adequado para depuração hipotética. Na sua essência, a depuração é um processo
iterativo que começa com uma hipótese, seguido pela verificação de várias observações e fatos recebidos do sistema usando diferentes vetores, conclusões / generalizações e uma avaliação mais aprofundada da verdade da hipótese.
A capacidade
de testar hipóteses de maneira
rápida e barata e melhorar o modelo mental de acordo é a
pedra angular da depuração. Qualquer ferramenta de depuração deve ser
interativa e restringir o espaço de pesquisa ou, no caso de um rastreamento falso, permitir que o usuário volte e se concentre em outra área do sistema. Uma ferramenta ideal fará isso de forma
proativa , chamando imediatamente a atenção do usuário para áreas potencialmente problemáticas.
Infelizmente, o
traceview não pode ser chamado de ferramenta de interface interativa. O melhor que você pode esperar ao usá-lo é detectar uma certa fonte de maiores atrasos e visualizar todos os tipos de tags e logs associados a ele. Isso não ajuda o engenheiro a identificar
padrões no tráfego, como as especificidades da distribuição de atrasos, ou a detectar correlações entre diferentes medidas.
A análise de rastreamento genérico pode solucionar alguns desses problemas. De fato,
existem exemplos de análises bem-sucedidas usando o aprendizado de máquina para identificar extensões anormais e identificar um subconjunto de tags que podem estar associadas a um comportamento anormal. No entanto, ainda não encontrei visualizações convincentes de descobertas feitas usando aprendizado de máquina ou análise de dados aplicadas a extensões que seriam significativamente diferentes da visualização em traceview ou DAG (gráfico acíclico direcional).
Os vãos são de nível muito baixo
O problema fundamental com a traceview é que as
extensões são primitivas de nível muito baixo para análise de latência e análise de causa raiz. É como analisar comandos individuais do processador na tentativa de eliminar uma exceção, sabendo que existem ferramentas de nível superior, como o backtrace, que são muito mais convenientes de se trabalhar.
Além disso, tomarei a liberdade de afirmar o seguinte: idealmente, não precisamos de uma
imagem completa do que aconteceu durante o ciclo de vida da solicitação, que representam as ferramentas modernas de rastreamento. Em vez disso, é necessária alguma forma de abstração de nível superior, contendo informações sobre o que
deu errado (semelhante ao backtrace), além de algum contexto. Em vez de observar todo o traço, prefiro ver
parte dele onde algo interessante ou incomum acontece. Atualmente, a pesquisa é realizada manualmente: o engenheiro recebe um rastreio e analisa de forma independente as extensões em busca de algo interessante. A abordagem quando as pessoas olham para extensões em rastreamentos separados na esperança de detectar atividades suspeitas não tem escala (especialmente quando elas precisam compreender todos os metadados codificados em extensões diferentes, como ID de extensão, nome do método RPC, duração da extensão 'a, logs, tags etc.).
Alternativas de Traceview
Os resultados do rastreamento são mais úteis quando podem ser visualizados de forma a obter uma idéia não trivial do que está acontecendo nas partes interconectadas do sistema. Até que este seja o caso, o processo de depuração permanece bastante
inerte e depende da capacidade do usuário perceber as correlações corretas, verificar as partes corretas do sistema ou montar partes do mosaico - ao contrário da
ferramenta que ajuda o usuário a formular essas hipóteses.
Não sou designer visual nem especialista em UX, mas na próxima seção quero compartilhar algumas idéias sobre como essas visualizações podem parecer.
Foco em serviços específicos
Em um ambiente em que o setor está se consolidando em torno das idéias de
SLO (objetivos de nível de serviço) e SLI (indicadores de nível de serviço) , parece razoável que as equipes individuais primeiro monitorem a relevância de seus serviços para esses objetivos. Daqui resulta que
a visualização
orientada a serviços é mais adequada para essas equipes.
Rastreios, especialmente sem amostragem, são um repositório de informações sobre cada componente de um sistema distribuído. Essas informações podem ser fornecidas a um manipulador complicado que fornecerá descobertas orientadas a serviços para os usuários, que podem ser detectadas com antecedência - mesmo antes de o usuário examinar os rastreamentos:
- Atrasar os diagramas de distribuição apenas para solicitações fortemente diferenciadas (solicitações externas) ;
- Atraso nos diagramas de distribuição para os casos em que as metas de serviço da SLO não são atingidas;
- As tags mais "comuns", "interessantes" e "estranhas" nas consultas, que são mais frequentemente repetidas ;
- Detalhamento dos atrasos nos casos em que as dependências de serviço não atingem as metas SLO definidas;
- Repartição dos atrasos em vários serviços a jusante.
As métricas internas simplesmente não podem responder a algumas dessas perguntas, forçando os usuários a estudarem cuidadosamente os períodos. Como resultado, temos um mecanismo extremamente hostil para o usuário.
Nesse sentido, surge a pergunta: e as interações complexas entre os vários serviços controlados por diferentes equipes? A
traceview não é considerada a ferramenta mais apropriada para cobrir essa situação?
Desenvolvedores de dispositivos móveis, proprietários de serviços sem estado, proprietários de serviços gerenciados com estado (como bancos de dados) e proprietários de plataformas podem estar interessados em outra
visão de um sistema distribuído;
o traceview é uma solução universal demais para essas necessidades fundamentalmente diferentes. Mesmo em uma arquitetura de microsserviço muito complexa, os proprietários de serviços não precisam de conhecimento aprofundado de mais de dois ou três serviços upstream e downstream. Em essência, na maioria dos cenários, os usuários precisam apenas responder perguntas sobre um
conjunto limitado de serviços .
É como olhar para um pequeno subconjunto de serviços através de uma lente de aumento para fins de estudo meticuloso. Isso permitirá que o usuário faça perguntas mais prementes sobre a complexa interação entre esses serviços e suas dependências imediatas. Isso é semelhante ao backtrace no mundo dos serviços, onde o engenheiro sabe o
que está errado e também tem alguma idéia do que está acontecendo nos serviços ao redor para entender o
porquê .
A abordagem que estou promovendo é exatamente o oposto da abordagem de cima para baixo, com base na visualização de rastreamento, quando a análise começa com todo o rastreamento e depois desce gradualmente para extensões individuais. Pelo contrário, a abordagem de baixo para cima começa com uma análise de uma pequena área próxima à causa potencial do incidente e, em seguida, o espaço de pesquisa é ampliado, se necessário (com o possível envolvimento de outras equipes para analisar uma ampla gama de serviços). A segunda abordagem é mais adequada para testar rapidamente as hipóteses iniciais. Após a obtenção de resultados específicos, será possível avançar para uma análise mais focada e detalhada.
Construção de topologia
As visualizações associadas a um serviço específico podem ser incrivelmente úteis se o usuário souber
qual serviço ou grupo de serviços é responsável por aumentar os atrasos ou é uma fonte de erros. No entanto, em um sistema complexo, identificar um invasor pode não ser uma tarefa trivial durante uma falha, especialmente se nenhuma mensagem de erro tiver sido recebida dos serviços.
Construir uma topologia de serviço pode ser muito útil para descobrir qual serviço mostra um aumento na taxa de erros ou um aumento na latência, levando a uma deterioração perceptível no desempenho do serviço. Falando sobre a construção de uma topologia, não estou falando de
um mapa de serviço que exibe todos os serviços disponíveis no sistema e conhecido por seus
mapas de arquitetura na forma de uma estrela da morte . Essa representação não é melhor do que uma visualização em rastreamento baseada em um gráfico acíclico direcionado. Em vez disso, gostaria de ver uma
topologia de serviço gerada dinamicamente com base em certos atributos, como taxa de erro, tempo de resposta ou qualquer parâmetro especificado pelo usuário que ajude a esclarecer a situação com serviços suspeitos específicos.
Vejamos um exemplo. Imagine um site de notícias hipotético. O serviço de
primeira página se comunica com a Redis, com um serviço de recomendação, com um serviço de publicidade e serviço de vídeo. O serviço de vídeo captura vídeos do S3 e os metadados do DynamoDB. O serviço de recomendação recebe metadados do DynamoDB, baixa dados do Redis e MySQL, grava mensagens no Kafka. O serviço de publicidade recebe dados do MySQL e grava mensagens no Kafka.
A seguir, é apresentada uma representação esquemática dessa topologia (muitos programas de roteamento comercial constroem a topologia). Pode ser útil se você precisar entender as dependências dos serviços. No entanto, durante a
depuração , quando um determinado serviço (por exemplo, um serviço de vídeo) demonstra maior tempo de resposta, essa topologia não é muito útil.
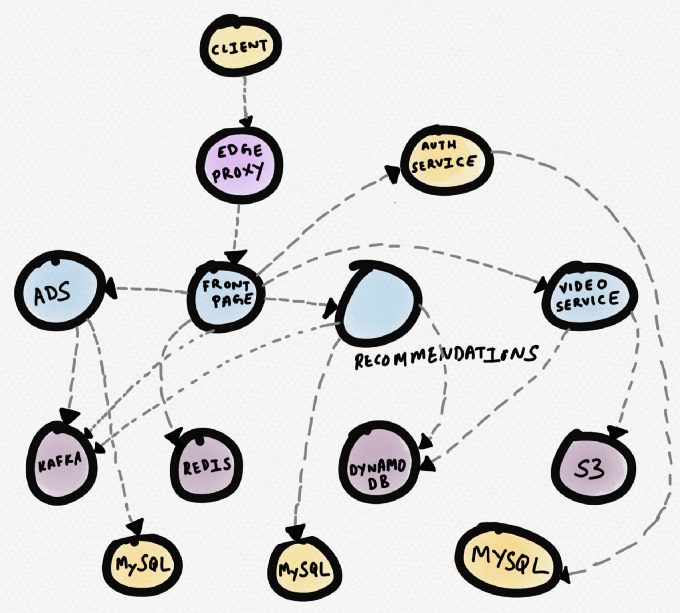 Esquema de serviços hipotéticos para sites de notícias
Esquema de serviços hipotéticos para sites de notíciasO diagrama abaixo seria melhor. Nele, um serviço problemático
(vídeo) é representado bem no centro. O usuário imediatamente o nota. A partir dessa visualização, fica claro que o serviço de vídeo funciona de maneira anormal devido ao aumento do tempo de resposta do S3, o que afeta a velocidade de download de parte da página principal.
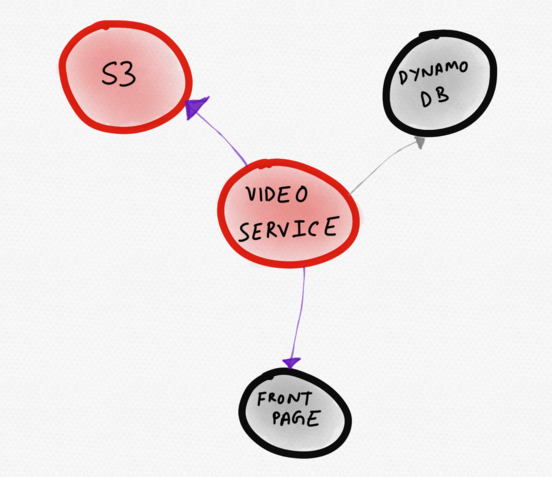 Topologia dinâmica que exibe apenas serviços "interessantes"
Topologia dinâmica que exibe apenas serviços "interessantes"Os esquemas topológicos gerados dinamicamente podem ser mais eficientes que os mapas de serviços estáticos, especialmente em infraestruturas flexíveis e auto-escaláveis. A capacidade de comparar e contrastar topologias de serviço permite que o usuário faça perguntas mais relevantes. Perguntas mais precisas sobre o sistema provavelmente levarão a uma melhor compreensão de como o sistema funciona.
Exibição comparativa
Outra visualização útil seria uma exibição comparativa. Atualmente, os rastreamentos não são adequados para comparações lado a lado; portanto, os
períodos são geralmente comparados. E a idéia principal deste artigo é precisamente que os períodos são de nível muito baixo para extrair as informações mais valiosas dos resultados do rastreamento.
A comparação de dois trace'ov não exige visualizações fundamentalmente novas. De fato, algo como um histograma representando a mesma informação que a traceview é suficiente. Surpreendentemente, mesmo esse método simples pode trazer muito mais frutos do que um simples estudo de dois traços separadamente. Ainda mais poderosa seria a capacidade de
visualizar a comparação de traços
no agregado . Seria extremamente útil ver como uma configuração de banco de dados implantada recentemente com a inclusão de GC (coleta de lixo) afeta o tempo de resposta de um serviço downstream em algumas horas. Se o que estou descrevendo aqui parece uma análise A / B do impacto das alterações de infraestrutura
em uma variedade de serviços usando resultados de rastreamento, você não está muito longe da verdade.
Conclusão
Não questiono a utilidade do rastreamento em si. Sinceramente, acredito que não há outra maneira de coletar dados tão ricos, informais e contextuais quanto os contidos no rastreamento. , . , traceview-, , , trace'. , , .
, , . ,
, . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PS do tradutor
Leia também em nosso blog: