Nota perev. : Temos o prazer de compartilhar a tradução do maravilhoso material do evangelista sênior de tecnologia da AWS - Adrian Hornsby. Em palavras simples, ele explica a importância de experimentos projetados para mitigar as conseqüências de falhas nos sistemas de TI. Você provavelmente já ouviu falar sobre o Chaos Monkey (ou até usou soluções semelhantes)? Hoje, abordagens para a criação de tais ferramentas e sua implementação em um contexto mais amplo são realizadas como parte de uma atividade chamada engenharia do caos. Leia mais sobre isso neste artigo.
"Mas por trás de toda essa beleza está o caos e a loucura." - curtimento de paredes
Bombeiros . Esses especialistas altamente qualificados arriscam suas vidas todos os dias, combatendo o fogo. Você sabia que antes de se tornar bombeiro, você precisa passar pelo menos 600 horas em treinamento? E este é apenas o começo. Segundo relatos, os bombeiros treinam até 80% do seu tempo de trabalho.
Porque
Quando um bombeiro luta contra o fogo real, ele precisa de
intuição adequada. Para desenvolvê-lo, você precisa treinar hora após hora, dia após dia. Como se costuma dizer, a prática faz maravilhas.
“Parece que eles penetram na própria essência do fogo; tais análogos do Dr. Phil para a chama ". - Combate a incêndios florestais com computadores e intuição
Nota perev. : Phillip Calvin "Phil" McGraw é um psicólogo, escritor e apresentador do popular programa de televisão "Doctor Phil", no qual o apresentador oferece aos participantes soluções para seus problemas.Era uma vez em Seattle
No início dos anos 2000,
Jesse Robbins , que ocupava uma posição oficial na Amazon com o nome oficial de
Master of Disaster , criou e liderou o programa GameDay. Foi baseado em sua experiência como bombeiro. O GameDay foi projetado para testar, educar e preparar vários sistemas, software e pessoas da Amazon para possíveis situações de crise.
Assim como os bombeiros desenvolvem intuição para combater incêndios, Jesse estava prestes a ajudar sua equipe a desenvolver intuição para combater eventos catastróficos em larga escala.
"GameDay: Criando resiliência através da destruição" - Jesse RobbinsO GameDay foi projetado para aumentar a resiliência do site de varejo da Amazon, introduzindo deliberadamente erros em sistemas de missão crítica.
A GameDay começou com uma série de anúncios para toda a empresa de que um alarme de treinamento foi planejado - às vezes em larga escala, por exemplo, desativando um data center inteiro. Os detalhes sobre o desligamento planejado foram mínimos e a equipe recebeu vários meses para se preparar. O principal objetivo do exercício era verificar se os funcionários podem lidar com a crise local e eliminar rapidamente suas conseqüências.
Durante esses exercícios, ferramentas e processos especiais, como monitoramento, alertas e chamadas urgentes, foram usados para analisar e identificar erros nos procedimentos de resposta a incidentes. Como se viu, o GameDay revela perfeitamente os problemas arquitetônicos clássicos. Às vezes, também era possível detectar os chamados "defeitos ocultos" - problemas manifestados devido às especificidades do incidente. Por exemplo, os sistemas de gerenciamento de incidentes críticos para o processo de recuperação falharam devido a efeitos colaterais inesperados causados por um problema causado pelo homem.
À medida que a empresa crescia, o raio teórico de derrota do GameDay se expandia. No final, esses exercícios pararam: o dano potencial à empresa se tornaria muito grande se algo desse errado. Desde então, o programa degenerou em uma série de experimentos de negócios díspares e sem impacto para o treinamento de pessoal em situações de crise. Não vou entrar em detalhes dos experimentos neste artigo, mas farei isso no futuro. Desta vez, quero discutir a importante ideia subjacente ao GameDay:
engenharia de resiliência , também conhecida como
engenharia do caos .
Ascensão do macaco
Você provavelmente já ouviu falar da Netflix, o provedor de conteúdo de vídeo on-line. A Netflix começou a mudar de seu próprio data center para a AWS Cloud em agosto de 2008. Essa etapa foi causada por sérios danos ao banco de dados, devido ao atraso na entrega do DVD por três dias (sim, o Netflix começou enviando filmes por correio normal). A migração para a nuvem foi associada à necessidade de suportar cargas de streaming muito mais altas, bem como ao desejo de abandonar a arquitetura monolítica e migrar para microsserviços fáceis de dimensionar, dependendo do número de usuários e do tamanho da equipe de engenharia. A parte do usuário do serviço de streaming foi transferida para a AWS primeiro, entre 2010 e 2011, seguida pela TI corporativa e todas as outras estruturas. O data center da Netflix foi fechado em 2016. A empresa mede a acessibilidade como uma razão entre o número de tentativas bem-sucedidas de lançar um filme e o número total, e não como uma simples comparação de tempo de atividade e tempo de inatividade, e tenta atingir uma figura de 0,9999 em cada região trimestralmente (geralmente é bem-sucedido). A arquitetura global da Netflix abrange três regiões da AWS. Assim, em caso de problemas em uma das regiões, a empresa pode redirecionar usuários para outras.
Repito uma das minhas citações favoritas:
“O fracasso é inevitável; eventualmente, qualquer sistema falhará com o tempo. ” - Werner Vogels
De fato, falhas em sistemas distribuídos, especialmente em larga escala, são inevitáveis, mesmo na nuvem. No entanto, a nuvem da AWS e suas primitivas de redundância - em particular, o
princípio de várias zonas de acesso nas quais ela é construída - permitem que qualquer pessoa crie serviços altamente confiáveis.
Usando os princípios de redundância e
degradação graciosa , a Netflix
conseguiu sobreviver a falhas sem afetar os usuários finais.
Desde o início, a Netflix aderiu aos princípios arquitetônicos mais rigorosos. Um dos primeiros aplicativos implantados na AWS foi o
Chaos Monkey - para oferecer suporte a microsserviços sem estado de escala automática. Em outras palavras, qualquer instância pode ser parada e substituída automaticamente sem nenhuma perda de estado. O Caos Monkey garante que ninguém viole esse princípio.
Nota perev. : A propósito, para Kubernetes, existe um análogo chamado kube-monkey , cujo desenvolvimento parece ter parado em março deste ano.A Netflix possui mais uma regra, que prevê a distribuição de cada serviço em três zonas de disponibilidade. Ele deve continuar funcionando se apenas dois deles estiverem disponíveis. Para garantir que essa regra seja cumprida, o
Chaos Gorilla desativa as zonas de disponibilidade. Mais globalmente, o
Chaos Kong pode desativar toda a região da AWS para confirmar que todos os usuários do Netflix podem ser atendidos em qualquer uma das três regiões. E eles fazem esses testes em larga escala a cada poucas semanas na produção para garantir que nada escapa à atenção.
Por fim, a Netflix também desenvolveu as
ferramentas Chaos Testing mais focadas para ajudar a detectar problemas com microsserviços e arquitetura de armazenamento. Você pode aprender mais sobre essas técnicas no livro Chaos Engineering, que recomendo a qualquer pessoa interessada neste tópico.
"Conduzindo experimentos regularmente que imitam interrupções regionais, conseguimos identificar várias falhas sistêmicas e eliminá-las em um estágio inicial". - Blog da Netflix
Hoje, os princípios da engenharia do caos são
formalizados ; eles recebem a seguinte definição:
“A engenharia do caos é uma abordagem que envolve a realização de experimentos em um sistema de produção para garantir sua capacidade de suportar várias interferências que ocorrem durante a operação.” - principiosofchaos.org
No entanto, em um
discurso na AWS re: Invent 2018 sobre engenharia do caos,
Adrian Cockcroft , ex-criador da arquitetura em nuvem da Netflix, que ajudou a empresa a mudar totalmente para a infraestrutura em nuvem, introduziu uma definição alternativa de engenharia do caos. Na minha opinião, é mais preciso e bem estabelecido:
"A engenharia do caos é um experimento projetado para mitigar as consequências de falhas."
De fato, sabemos que as falhas acontecem o tempo todo. Com a resposta certa, eles não devem afetar os usuários finais. O principal objetivo da engenharia do caos é detectar problemas que não foram resolvidos adequadamente.
Pré-requisitos para criar o caos
Antes de iniciar a engenharia do caos, certifique-se de fazer todo o trabalho necessário para garantir a sustentabilidade em todos os níveis da organização. Criar sistemas tolerantes a falhas não é apenas um software. Começa no nível da
infraestrutura , estende-se à
rede e aos dados , afeta a estrutura dos
aplicativos e, finalmente, abrange
pessoas e cultura . No passado, escrevi muito sobre modelos de estabilidade e falhas (
aqui ,
aqui ,
aqui e
aqui ) e não vou me concentrar nisso agora, mas não posso ficar sem um pequeno lembrete.
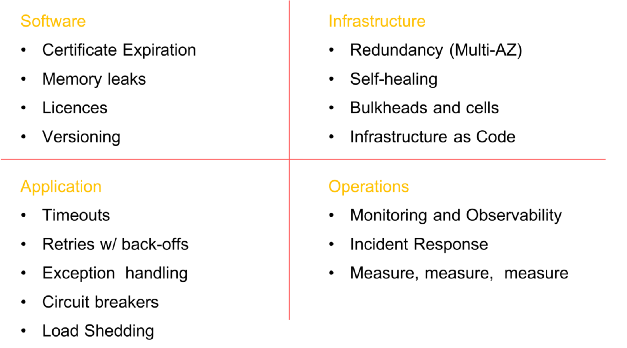 Alguns elementos obrigatórios antes de introduzir o caos no sistema (a lista não é completa)
Alguns elementos obrigatórios antes de introduzir o caos no sistema (a lista não é completa)Etapas da Engenharia do Caos
É importante entender que a essência da engenharia do caos
NÃO é soltar os macacos e destruí-los em sequência, sem nenhum objetivo. O objetivo desta disciplina é destruir alguns elementos do sistema em um ambiente controlado por meio de experimentos bem planejados para verificar se o seu aplicativo pode suportar condições turbulentas.
Para fazer isso, você deve seguir o processo claramente definido e formalizado mostrado na figura abaixo. Com ele, você pode passar da compreensão do estado estacionário do seu sistema para a formulação de uma hipótese, testando-a e, finalmente, analisando a experiência adquirida durante o experimento e aumentando a estabilidade do próprio sistema.
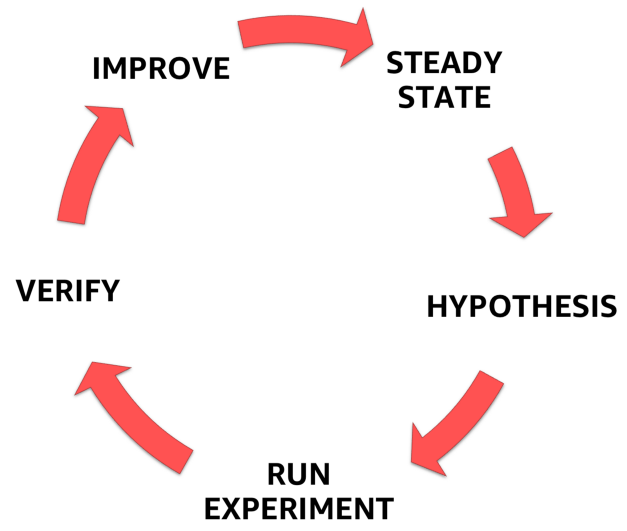 Etapas da Engenharia do Caos
Etapas da Engenharia do Caos1. Condição estável
Um dos elementos mais importantes da engenharia do caos é entender o comportamento de um sistema em condições normais.
Porque É simples: após a introdução de falha artificial, você deve garantir que o sistema retorne a um estado estável bem estudado e que o experimento não interfira mais com seu comportamento normal.
O ponto principal aqui é que você precisa se concentrar não nos atributos internos do sistema (processador, memória, etc.), mas monitorar os sinais de saída mensuráveis que conectam o desempenho à experiência do usuário. Para que esses sinais de saída estejam em um estado estável, o comportamento observado do sistema deve ter um padrão previsível, mas sofrer alterações significativas quando ocorrer um mau funcionamento no sistema.
Tendo em mente a
definição de engenharia do caos proposta acima por Adrian Cockcroft, esse estado estável muda quando uma falha fora de controle causa um problema inesperado e sinaliza que o experimento do caos deve ser interrompido.
Como exemplo de condições estáveis, citemos a experiência na Amazônia. A empresa usa o número de pedidos como uma das métricas de uma condição estável e por boas razões. Em 2007, Greg Linden, que trabalhou anteriormente na Amazon, falou sobre como, como parte de um experimento usando o método de
teste A / B, ele tentou diminuir o tempo de carregamento de páginas no site em incrementos de 100 ms e descobriu que até pequenos atrasos resultam em a uma queda séria na receita. Com um aumento no tempo de carregamento de 100 ms, o número de pedidos (e, portanto, de vendas) diminuiu 1%. É por isso que o número de pedidos é um excelente candidato para métricas estáveis.
A Netflix usa uma métrica do lado do servidor associada ao início da reprodução - o número de cliques no botão reproduzir. Eles notaram uma regularidade no comportamento do indicador SPS (partidas por segundo) e suas flutuações significativas em caso de falhas no sistema. A métrica é chamada "Pulso da Netflix" (
Pulso da Netflix ).
O número de pedidos no caso da Amazon e Netflix Pulse são excelentes barômetros de estabilidade, pois combinam a experiência do usuário e as métricas operacionais em um único indicador mensurável e altamente previsível.
Meça, meça e meça novamente
Não é necessário dizer que, se você não conseguir registrar adequadamente o desempenho do sistema, não poderá monitorar as alterações em um estado estável (ou mesmo detectá-las). Preste atenção especial à remoção de todos os parâmetros / indicadores da rede, hardware e finalização com o aplicativo e as pessoas. Desenhe gráficos dessas medidas, mesmo que elas não mudem com o tempo. Você ficará surpreso ao descobrir correlações que não conhecia.
"Torne o mais fácil possível para os engenheiros o acesso aos dados que eles podem contar ou traduzir em forma gráfica." - Ian Malpass
2. Hipótese
Tendo lidado com um estado estável, podemos prosseguir na formulação de uma hipótese.

- E se o mecanismo de recomendação parar?
- E se o balanceador de carga cair?
- E se o cache cair?
- E se o atraso aumentar em 300 ms?
- E se a base principal falhar?
Obviamente, apenas uma hipótese deve ser escolhida e não é necessário complicá-la desnecessariamente. Comece pequeno. Eu gosto de começar com a hipótese da equipe. Você já ouviu falar do
fator ônibus ? O fator de barramento é uma medida de risco associada ao fato de que o conhecimento não é distribuído igualmente entre os membros da equipe. Permite calcular o número mínimo de participantes, após uma súbita perda do qual o projeto será interrompido devido à falta de conhecimento ou experiência.
Muitas empresas têm especialistas técnicos cujo desaparecimento repentino ("atropelado por um ônibus") terá um efeito devastador no projeto e na equipe. Identifique essas pessoas e conduza experimentos de caos com a participação deles: por exemplo, pegue computadores deles e envie-os para casa por um dia e observe os resultados (geralmente caóticos).
Torne o problema comum a todos!
Envolva
toda a equipe no desenvolvimento de uma hipótese. Permita que todos participem do brainstorming: proprietário do produto, gerente técnico, desenvolvedores de back-end e front-end, designers, arquitetos etc. Todos que estão de uma forma ou de outra conectados ao produto.
Antes de tudo, peça a todos que escrevam sua própria resposta à pergunta "E se ...?" em um pedaço de papel. Você verá que, na maioria dos casos, todos terão sua própria resposta e entenderá que alguma parte da equipe ainda não pensou em um problema assim.
Pare neste momento e discuta por que os membros da equipe têm uma visão diferente do comportamento do produto no caso de "E se ...?". Volte às suas especificações e certifique-se de que todos entendam corretamente o possível desenvolvimento de eventos.
Tomemos, por exemplo, o site de varejo da Amazon mencionado. E se o serviço Comprar por categoria parar de carregar na página principal?

Devo retornar um erro 404? Vale a pena carregar a página, deixando um espaço vazio como na imagem abaixo?

Vale a pena sacrificar parte da funcionalidade e, por exemplo, deixar a página expandir e ocultar o erro?
E isso é apenas no lado da interface do usuário. O que deve acontecer no back-end? Os alertas devem ser enviados? Um serviço com falha deve continuar recebendo solicitações sempre que o usuário carrega a página inicial ou o back-end deve cortá-lo completamente?
E o último. Por favor, não formule uma hipótese, que é sabida antecipadamente que ela partirá lenha! Faça experiências com partes do sistema que, na sua opinião, são estáveis - em última análise, esse é o objetivo do experimento.3. Projete e execute um experimento
- Escolha uma hipótese;
- Defina o escopo do experimento;
- Definir os indicadores relacionados a serem medidos;
- Notifique a organização.
Hoje, muitas pessoas, assim como o site de
princípios do caos, estão promovendo a idéia de engenharia do caos na produção. Embora esse seja o objetivo final, a maioria das organizações tem medo dessa abordagem, portanto você não deve começar com ela.
Para mim, a engenharia do caos não é apenas a destruição de vários elementos dos sistemas de produção. Esta é uma jornada. Uma jornada ao mundo do conhecimento, indissociável de atividades como a destruição de sistemas em um ambiente controlado - qualquer ambiente, seja um ambiente de desenvolvimento local, beta, estadiamento ou prod. Destruição através de experimentos bem projetados para criar confiança na capacidade do seu aplicativo de tolerar condições turbulentas. “
Construir confiança ” é um ponto-chave nesse caso, pois é um precursor das mudanças culturais necessárias para a implementação bem-sucedida da engenharia do caos e a prática de melhorar a confiabilidade da sua empresa.
Honestamente, a maioria das equipes aprenderá muito quebrando coisas mesmo em um ambiente de não produção. Apenas tente fazer com que o
docker stop database em seu ambiente local e veja se você consegue lidar com esse problema sem consequências. Alta probabilidade de que não.
Parada de banco de dados - exemploComece pequeno e gradualmente construa confiança dentro de sua equipe e organização. Você será informado de que "o tráfego real de produção é a única maneira de capturar com segurança o comportamento do sistema". Ouça, sorria e continue fazendo lentamente o que está fazendo. A pior coisa que você pode fazer é aplicar a engenharia do caos à produção e falhar miseravelmente. Depois disso, ninguém confiará em você, e você será forçado a esquecer os “macacos do caos” para sempre.
Ganhe credibilidade primeiro. Mostre às organizações e colegas que você sabe o que está fazendo. Torne-se um bombeiro e aprenda sobre a chama o máximo possível antes de começar a treinar com fogo ativo. Ganhe credibilidade. Lembra da
história da tartaruga e da lebre ? A corrida é sempre ganha por uma lenta e paciente.
Um dos pontos mais importantes durante o experimento é entender o
raio potencial
de dano causado pelo mau funcionamento inserido e minimizá-lo. Faça a si mesmo as seguintes perguntas:
- Quantos clientes serão afetados pelo experimento?
- Que funcionalidade sofrerá?
- Quais lugares serão afetados?
Pense em um "botão de parada de emergência" ou em uma maneira de encerrar imediatamente um experimento e retornar a um estado estável o mais rápido possível. Eu gosto de realizar experiências usando o chamado. Lançamentos "Canárias". Essa técnica reduz o risco de falha ao iniciar novas versões de um aplicativo em produção, implementando gradualmente as alterações em um pequeno subconjunto de usuários e depois espalhando-as lentamente por toda a infraestrutura e todos os usuários. Adoro lançamentos de canários simplesmente porque eles satisfazem o princípio de uma
infraestrutura fixa , e o experimento em si é bem fácil de parar.
 Um exemplo de distribuição de canários baseada em DNS para experimentos de caos
Um exemplo de distribuição de canários baseada em DNS para experimentos de caosTenha cuidado com experimentos que alteram o estado do aplicativo (cache ou banco de dados) ou aqueles que não podem ser revertidos (facilmente ou em princípio).
É curioso que Adrian Cockcroft me disse que um dos motivos pelos quais a Netflix começou a usar os bancos de dados NoSQL foi a falta de esquemas de alterações ou reversões neles, portanto, é muito mais fácil atualizar gradualmente ou corrigir registros individuais com dados (ou seja, eles são mais amigável à engenharia do caos).
4. Observe e aprenda
Para aprender algo novo e monitorar o progresso do experimento, você deve poder acompanhar o desempenho do sistema. Como mencionado anteriormente, preste muita atenção a todos os tipos de métricas e parâmetros! Quantifique os resultados e sempre - sempre! - Anote o tempo até os primeiros sinais de um problema aparecerem. Na minha história, aconteceu várias vezes que os sistemas de aviso se recusaram e o primeiro a relatar o problema aos clientes no Twitter ... acredite, você não vai querer estar nessa situação, então use experimentos de caos para verificar seus sistemas de monitoramento e aviso.
- Hora de descobrir?
- Hora de alertar e iniciar uma ação ativa?
- Hora de aviso público?
- Tempo para perda parcial de funcionalidade?
- A duração do período de autocura?
- Tempo para recuperação total ou parcial?
- Hora de terminar a crise e voltar a um estado estável?
Lembre-se de que não há uma causa isolada isolada de falha. Os acidentes graves são sempre o resultado de várias pequenas falhas que se acumulam e levam a uma crise em larga escala.
Faça uma análise post-mortem detalhada para cada experimento!Na AWS, prestamos muita atenção na análise de falhas detectadas e no entendimento das causas que as levaram a evitar problemas semelhantes no futuro. Todas as conclusões e resultados do experimento estão resumidos em um documento chamado Correção de Erros (COE). O COE nos permite aprender com nossos erros, sejam falhas de tecnologia, processo ou mesmo organização. Usamos esse mecanismo para eliminar as causas principais de falhas e desenvolvimento contínuo.
A chave para o sucesso nesse processo é a abertura e a transparência em relação ao que deu errado. Um dos princípios mais importantes ao escrever um bom COE é ser imparcial e evitar mencionar pessoas específicas. Isso geralmente é difícil em um ambiente que não incentiva esse comportamento e não permite falhas. A Amazon usa uma coleção de
Princípios de
Liderança para promover esse comportamento - por exemplo,
autocrítica, uma abordagem analítica, comprometimento com os mais altos padrões e responsabilidade são componentes essenciais do processo de COE e excelência operacional em geral.
O relatório do COE possui cinco seções principais:
- O que aconteceu (ordem cronológica)?
- Qual foi o impacto nos clientes?
- Por que o erro aconteceu? ( Cinco "por quê?" )
- O que aprendemos?
- Como evitar isso no futuro?
É mais difícil responder a essas perguntas do que parece à primeira vista, pois você precisa se certificar de que todo momento incompreensível / desconhecido seja cuidadosamente estudado.
Para transformar o mecanismo do COE em um processo completo, realizamos constantemente verificações na forma de reuniões semanais com uma análise obrigatória das métricas operacionais. Além disso, os principais especialistas técnicos conduzem análises de métricas semanais com toda a equipe da AWS.
5. Corrija e melhore!
A principal lição aqui é
, em primeiro lugar, eliminar os problemas identificados durante as experiências do caos, atribuindo-lhes uma prioridade mais alta do que o desenvolvimento de novas funções . Envolva a alta gerência nesse processo e apresente a ele que a solução dos problemas atuais é muito mais importante do que o desenvolvimento de novas funcionalidades.
Certa vez, com a ajuda de um experimento de caos, ajudei um cliente a identificar problemas críticos de estabilidade, mas devido à pressão do departamento de vendas, a prioridade da correção foi reduzida e todos os esforços foram direcionados para a introdução de uma coisa nova que é "extremamente importante" para os clientes. Duas semanas depois, um período de inatividade de 16 horas obrigou a empresa a enfrentar os mesmos problemas que identificamos durante o experimento do caos. Somente as perdas foram muito maiores.
Os benefícios da engenharia do caos
Existem muitas vantagens. Vou destacar dois, na minha opinião, os mais importantes:
Em primeiro lugar, a engenharia do caos ajuda a resolver problemas desconhecidos no sistema e corrigi-los antes que levem à falha de produção, digamos, às 3 da manhã de domingo. Ou seja,
aumenta a resistência a colisões e, de fato, a qualidade do sono .
Em segundo lugar, experimentos de caos realizados com eficiência sempre causam mudanças mais extensas (principalmente culturais) do que o previsto. Talvez o mais importante deles seja a evolução natural para uma
cultura " não culpada" , quando a pergunta "Por que você fez isso?" se transforma em "Como podemos evitar isso no futuro?". Como resultado, a equipe se torna mais feliz, mais eficiente, mais interessada e bem-sucedida.
E isso é maravilhoso!Sobre isso, a primeira parte chega ao fim. Espero que tenham gostado. Escreva críticas, compartilhe opiniões ou bata palmas no
Medium . Na próxima parte, examinarei ferramentas e técnicas para introduzir falhas no sistema. Até tchau!
Para aqueles que desejam se familiarizar com a segunda parte, ofereço minha apresentação sobre o tópico da engenharia do caos na NDC em Oslo. Nele, falo sobre muitas das minhas ferramentas favoritas:
PS do tradutor
A segunda parte do artigo em inglês já apareceu e a traduziremos também se percebermos interesse suficiente dos leitores do Habré por esse material - comentários relevantes sobre o artigo são bem-vindos! ATUALIZADO (3 de setembro): Também é
publicada uma tradução da segunda parte.
ATUALIZADO (19 de dezembro): a
tradução da terceira parte ficou disponível.
Leia também em nosso blog: