Já nos familiarizamos com o dispositivo de
cache de buffer , um dos principais objetos da memória compartilhada, e percebemos que, para recuperar-se de uma falha quando o conteúdo da RAM é perdido, é necessário manter um
registro de pré-registro .
O problema não resolvido que paramos na última vez é que não se sabe em que ponto você pode começar a reproduzir os logs durante a recuperação. Começar do início, como o rei de
Alice aconselhou, não funcionará: é impossível armazenar todas as entradas do diário desde o início do servidor - isso é potencialmente uma quantidade enorme e o mesmo tempo de recuperação. Precisamos de um ponto de avanço progressivo a partir do qual possamos iniciar a recuperação (e, portanto, podemos excluir com segurança todos os lançamentos contábeis anteriores). Este é o
ponto de controle que será discutido hoje.
Ponto de controle
Que propriedade um ponto de controle deve ter? Devemos ter certeza de que todos os lançamentos contábeis manuais, a partir do ponto de verificação, serão aplicados às páginas gravadas no disco. Se não fosse assim, durante a restauração, poderíamos ler no disco uma versão muito antiga da página e aplicar uma entrada de diário a ela, danificando permanentemente os dados.
Como obter um ponto de interrupção? A opção mais fácil é suspender periodicamente o sistema e liberar todas as páginas sujas do buffer e outros caches no disco. (Observe que as páginas são gravadas apenas, mas não são ejetadas do cache.) Esses pontos satisfazem a condição, mas, é claro, ninguém deseja trabalhar com um sistema que congela constantemente por tempo indeterminado, mas muito significativo.
Portanto, na prática, tudo é um pouco mais complicado: um ponto de controle de um ponto se transforma em um segmento. Primeiro,
começamos o ponto de interrupção. Depois disso, sem interromper o trabalho e, se possível, sem criar picos de carga, despejamos lentamente buffers sujos no disco.

Quando todos os buffers que estavam sujos
no início do ponto
de verificação foram gravados, o ponto de verificação é considerado
completo . Agora (mas não antes), podemos usar o ponto
inicial como o ponto a partir do qual você pode iniciar a recuperação. E os lançamentos contábeis até esse ponto não precisamos mais.

O ponto de verificação é tratado por um processo especial de apontador de verificação em segundo plano.
A duração dos buffers sujos é determinada pelo valor do parâmetro
checkpoint_completion_target . Mostra quanto tempo entre dois pontos de controle adjacentes a gravação ocorrerá. O valor padrão é 0,5 (como nas figuras acima), ou seja, a gravação leva metade do tempo entre os pontos de controle. Normalmente, o valor é aumentado para 1,0 para maior uniformidade.
Vamos considerar com mais detalhes o que acontece quando um ponto de controle é executado.
O processo do ponto de verificação libera primeiro os buffers de status da transação (XACT) no disco. Como existem alguns deles (128 no total), eles são gravados imediatamente.
Então o trabalho principal começa - escrevendo páginas sujas do cache do buffer. Como já dissemos, é impossível redefinir todas as páginas de uma vez, pois o tamanho do cache do buffer pode ser significativo. Portanto, primeiro, todas as páginas sujas atualmente são marcadas no cache do buffer nos cabeçalhos com um sinalizador especial.
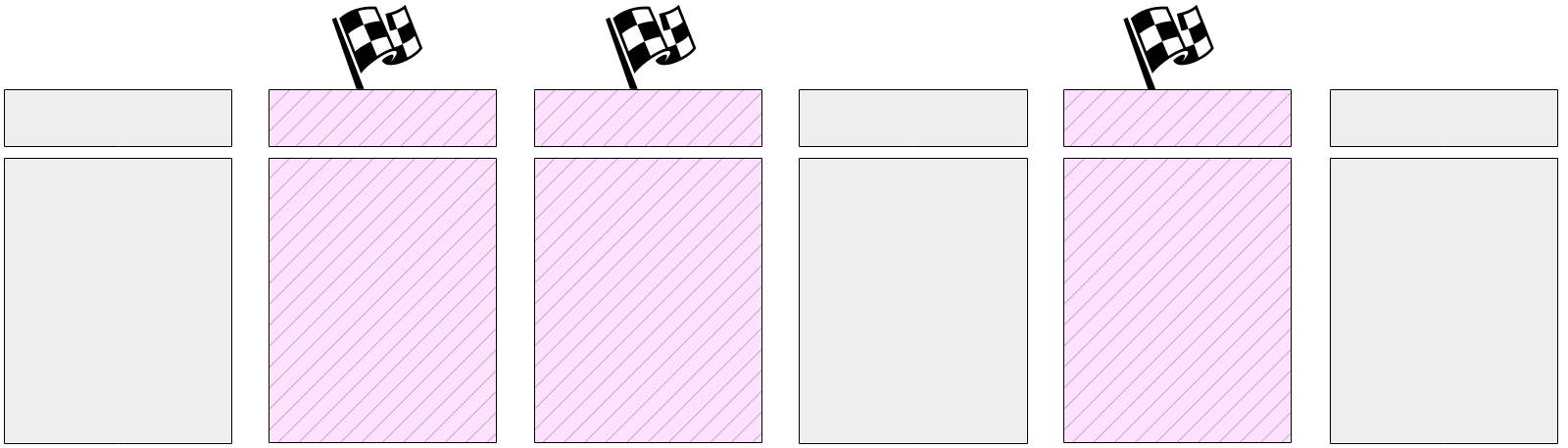
E então o processo do ponto de verificação passa gradualmente por todos os buffers e libera os marcados no disco. Lembre-se de que as páginas não são ejetadas do cache, mas são gravadas apenas no disco, portanto, você não precisa prestar atenção ao número de chamadas ao buffer ou à sua correção.
Os buffers rotulados também podem ser gravados pelos processos do servidor - dependendo de quem chega primeiro ao buffer. Em qualquer caso, o sinalizador definido anteriormente é removido durante a gravação, portanto (para fins do ponto de verificação) o buffer será gravado apenas uma vez.
Naturalmente, durante a execução do ponto de verificação, as páginas continuam a mudar no cache do buffer. Mas os novos buffers sujos não são sinalizados e o processo do ponto de verificação não deve gravá-los.
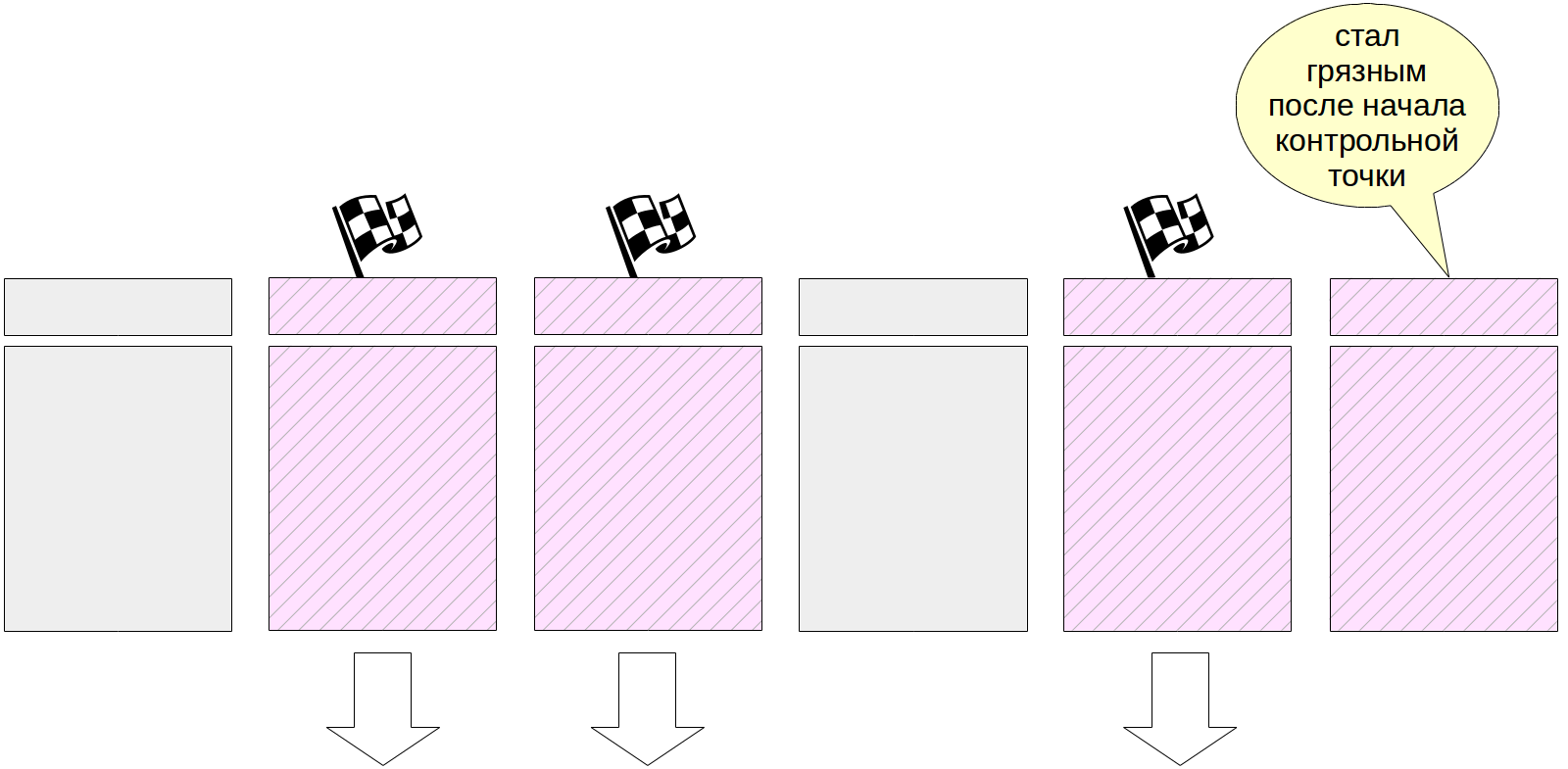
No final de seu trabalho, o processo cria um lançamento no diário para o final do ponto de verificação. Este registro contém o LSN do início do trabalho do ponto de controle. Como o ponto de controle não grava nada no log no início de seu trabalho, esse LSN pode conter qualquer registro de log.
Além disso, o arquivo $ PGDATA / global / pg_control atualiza a indicação do último ponto de verificação
passado . Antes da conclusão do ponto de verificação, pg_control aponta para o ponto de verificação anterior.

Para examinar o trabalho do ponto de verificação, crie uma tabela - suas páginas irão para o cache do buffer e ficarão sujas:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); => CREATE EXTENSION pg_buffercache; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 78 (1 row)
Lembre-se da posição atual no log:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A048 (1 row)
Agora, executaremos o ponto de verificação manualmente e garantiremos que não haja páginas sujas no cache (como dissemos, novas páginas sujas podem aparecer, mas, no nosso caso, não houve alterações no processo de execução do ponto de verificação):
=> CHECKPOINT; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
Vamos ver como o ponto de verificação foi refletido no log:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A0E4 (1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
Aqui vemos duas entradas. O último é um registro de aprovação do ponto de controle (CHECKPOINT_ONLINE). O LSN do início do ponto de verificação é indicado após a palavra refazer e essa posição corresponde ao lançamento no diário, que foi o último no início do ponto de verificação.
Nós encontraremos as mesmas informações no arquivo de controle:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C Latest checkpoint's REDO location: 0/3514A048
Recuperação
Agora, estamos prontos para esclarecer o algoritmo de recuperação descrito no artigo anterior.
Se o servidor travar, na próxima vez em que iniciar, o processo de inicialização detectará isso observando o arquivo pg_control e vendo um status diferente de "desligar". Nesse caso, a recuperação automática é realizada.
Primeiro, o processo de recuperação lerá do mesmo pg_control a posição do início do ponto de controle. (Para garantir a integridade, observamos que, se o arquivo backup_label estiver presente, o registro do ponto de controle será lido - isso é necessário para a restauração dos backups, mas esse é um tópico para um ciclo separado.)
Em seguida, ele lerá a revista, começando pela posição encontrada, aplicando sequencialmente os lançamentos do diário nas páginas (se necessário, como discutimos na
última vez ).
Em conclusão, todas as tabelas não registradas no diário são substituídas usando imagens nos arquivos init.
Nesse ponto, o processo de inicialização é finalizado e o processo do apontador de verificação executa imediatamente um ponto de verificação para corrigir o estado restaurado no disco.
Você pode simular uma falha parando à força o servidor no modo imediato.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(A chave
--skip-systemctl-redirect é necessária aqui porque o PostgreSQL está instalado no Ubuntu a partir do pacote. É controlada pelo comando pg_ctlcluster, que realmente chama systemctl, e já chama pg_ctl. Com todos esses wrappers, o nome do modo é perdido ao longo do caminho, e a
--skip-systemctl-redirect permite que você fique sem o systemctl e salve informações importantes.)
Verifique o status do cluster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
Na inicialização, o PostgreSQL entende que ocorreu uma falha e que é necessária uma recuperação.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK 2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress 2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048 2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0 2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C 2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections 2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
A necessidade de recuperação é observada no log de mensagens: o
sistema do banco de dados não foi desligado corretamente; recuperação automática em andamento . Em seguida, os lançamentos contábeis manuais começam a ser reproduzidos a partir da posição marcada em “refazer início às” e continuam até que os próximos lançamentos contábeis manuais possam ser recuperados. Isso conclui a recuperação na posição “refazer feito em” e o DBMS começa a trabalhar com os clientes (o
sistema de banco de dados está pronto para aceitar conexões ).
E o que acontece durante um desligamento normal do servidor? Para liberar páginas sujas para o disco, o PostgreSQL desconecta todos os clientes e executa o ponto de verificação final.
Lembre-se da posição atual no log:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A14C (1 row)
Agora pare suavemente o servidor:
student$ sudo pg_ctlcluster 11 main stop
Verifique o status do cluster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
E no log, encontramos o único registro sobre o ponto de controle final (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(Em uma terrível mensagem fatal, pg_waldump só quer dizer que leu até o final da revista.)
Execute a instância novamente.
student$ sudo pg_ctlcluster 11 main start
Gravação em segundo plano
Como descobrimos, o ponto de verificação é um dos processos que grava páginas sujas do cache do buffer no disco. Mas não é o único.
Se o back-end precisar retirar a página do buffer e a página estiver suja, será necessário gravá-la no disco por conta própria. Essa é uma situação ruim, levando a expectativas - é muito melhor quando a gravação ocorre de forma assíncrona em segundo plano.
Portanto, além do
processo do ponto de verificação
, também existe
um processo de gravação em segundo plano (gravador em segundo plano, bgwriter ou apenas gravador). Esse processo usa o mesmo algoritmo de pesquisa de buffer que o mecanismo de preempção. Existem basicamente duas diferenças.
- Ele não usa um ponteiro para a "próxima vítima", mas sim o seu. Ele pode estar à frente do ponteiro para a "vítima", mas nunca fica atrás dele.
- Ao atravessar buffers, o contador de visitas não diminui.
Buffers são escritos simultaneamente:
- conter dados alterados (sujos),
- não fixo (contagem de pinos = 0),
- tem zero acertos (contagem de uso = 0).
Assim, o processo de gravação em segundo plano, por assim dizer, corre à frente da multidão e encontra aqueles buffers que provavelmente serão lotados em breve. Idealmente, devido a isso, os processos de serviço devem descobrir que os buffers selecionados podem ser usados sem parar para escrever.
Personalização
O processo do ponto de verificação é geralmente configurado pelos seguintes motivos.
Primeiro, você precisa decidir quantos arquivos de log podemos economizar (e qual o tempo de recuperação que mais nos convém). Quanto maior, melhor, mas, por razões óbvias, esse valor será limitado.
Em seguida, podemos calcular quanto tempo esse volume será gerado sob carga normal. Já consideramos como fazer isso (precisamos lembrar as posições no diário e subtrair uma da outra).
Esse tempo será o intervalo habitual entre os pontos de controle. Nós o escrevemos no parâmetro
checkpoint_timeout . O valor padrão de 5 minutos é obviamente muito pequeno, geralmente o tempo é aumentado, digamos, para meia hora. Repito: quanto menos vezes você puder pagar marcos, melhor - isso reduz as despesas gerais.
No entanto, é possível (e até provável) que às vezes a carga seja maior que o normal e que sejam gerados muitos lançamentos no tempo especificado no parâmetro. Nesse caso, eu gostaria de executar o ponto de controle com mais frequência. Para fazer isso, no parâmetro
max_wal_size , especificamos a quantidade que é válida dentro do mesmo ponto de controle. Se o volume real for obtido mais, o servidor inicia um ponto de verificação não programado.
Assim, a maioria dos pontos de controle ocorre em uma programação: uma vez por unidades de tempo
checkpoint_timeout . Porém, com o aumento da carga, o ponto de controle é chamado com mais frequência quando o volume
max_wal_size é
atingido .
É importante entender que o parâmetro
max_wal_size não determina a quantidade máxima que os arquivos de log no disco podem ocupar.
- Para se recuperar de uma falha, é necessário armazenar os arquivos a partir do momento em que o último ponto de verificação foi passado, além dos arquivos acumulados durante a operação do ponto de verificação atual. Portanto, o volume total pode ser estimado aproximadamente como
(1 + ponto de verificação_completo_target ) × max_wal_size . - Antes da versão 11, o PostgreSQL também armazenava arquivos para o ponto de verificação de dois anos; portanto, até a versão 10 na fórmula acima, você deve definir 2 em vez de 1.
- O parâmetro max_wal_size é apenas um desejo, mas não um limite rígido. Pode resultar mais.
- O servidor não tem o direito de apagar arquivos de log que ainda não foram transferidos pelos slots de replicação e que ainda não foram arquivados durante o arquivamento contínuo. Se essa funcionalidade for usada, é necessário monitoramento constante, pois é fácil sobrecarregar a memória do servidor.
Para concluir a imagem, você pode definir não apenas o volume máximo, mas também o mínimo: parâmetro
min_wal_size . O significado dessa configuração é que o servidor não exclui arquivos enquanto eles cabem no volume em
min_wal_size , mas simplesmente os renomeia e os utiliza novamente. Isso economiza um pouco, criando e excluindo constantemente arquivos.
O processo de gravação em segundo plano faz sentido para configurar após a configuração do ponto de verificação. Juntos, esses processos devem ter tempo para gravar buffers sujos antes de serem necessários pelos processos de manutenção.
O processo de gravação em segundo plano é executado em ciclos de no máximo páginas
bgwriter_lru_maxpages , adormecendo entre os ciclos em
bgwriter_delay .
O número de páginas que serão gravadas em um ciclo de trabalho é determinado pelo número médio de buffers que foram solicitados pelos processos de manutenção da última execução (usando uma média móvel para suavizar a desigualdade entre as execuções, mas não depende de um longo histórico). O número calculado de buffers é multiplicado pelo coeficiente
bgwriter_lru_multiplier (mas, em qualquer caso, não excederá
bgwriter_lru_maxpages ).
Valores padrão:
bgwriter_delay = 200ms (provavelmente muito,
vaza muita água em 1/5 segundo),
bgwriter_lru_maxpages = 100,
bgwriter_lru_multiplier = 2.0 (estamos tentando responder à demanda com antecedência).
Se o processo não detectar buffers sujos (isto é, nada acontece no sistema), ele "hiberna" a partir do qual se deduz que o processo do servidor acessa o buffer. Depois disso, o processo é ativado e funciona novamente da maneira usual.
Monitoramento
As configurações do ponto de controle e da gravação em segundo plano podem e devem ser ajustadas, recebendo feedback do monitoramento.
O parâmetro
checkpoint_warning exibe um aviso se os pontos de verificação causados pelo excesso de tamanho do arquivo de log forem executados com muita freqüência. Seu valor padrão é 30 segundos e deve ser alinhado com o valor de
checkpoint_timeout .
O parâmetro
log_checkpoints (desativado por padrão) permite receber informações sobre os pontos de verificação executados no log de mensagens do servidor. Ligue-o.
=> ALTER SYSTEM SET log_checkpoints = on; => SELECT pg_reload_conf();
Agora mude algo nos dados e execute o ponto de verificação.
=> UPDATE chkpt SET n = n + 1; => CHECKPOINT;
No log de mensagens, veremos algo como isto:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait 2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
Aqui você pode ver quantos buffers foram gravados, como a composição dos arquivos de log mudou após o ponto de controle, quanto tempo o ponto de controle levou e a distância (em bytes) entre os pontos de controle vizinhos.
Mas, provavelmente, as informações mais úteis são as estatísticas do trabalho dos processos de ponto de verificação e registro em segundo plano na visualização pg_stat_bgwriter. A visualização é de um para dois, porque uma vez que as duas tarefas foram executadas por um processo; então suas funções foram divididas e a visão permaneceu.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------ checkpoints_timed | 0 checkpoints_req | 1 checkpoint_write_time | 1 checkpoint_sync_time | 13 buffers_checkpoint | 79 buffers_clean | 0 maxwritten_clean | 0 buffers_backend | 42 buffers_backend_fsync | 0 buffers_alloc | 363 stats_reset | 2019-07-17 15:27:49.826414+03
Aqui, entre outras coisas, vemos o número de pontos de controle concluídos:
- checkpoints_timed - de acordo com a programação (ao atingir checkpoint_timeout),
- checkpoints_req - sob demanda (inclusive ao atingir max_wal_size).
O grande valor de checkpoint_req (comparado com checkpoints_timed) indica que os pontos de controle ocorrem com mais frequência do que o esperado.
Informações importantes sobre o número de páginas gravadas:
- buffers_checkpoint - processo de ponto de verificação,
- buffers_backend - servindo processos,
- buffers_clean - processo de gravação em segundo plano.
Em um sistema bem ajustado, o valor de buffers_backend deve ser substancialmente menor que a soma de buffers_checkpoint e buffers_clean.
Além disso, maxwritten_clean é útil para configurar a gravação em segundo plano - esse número mostra quantas vezes o processo de gravação em segundo plano parou de funcionar devido a exceder
bgwriter_lru_maxpages .
Você pode redefinir as estatísticas acumuladas usando a seguinte chamada:
=> SELECT pg_stat_reset_shared('bgwriter');
Para ser continuado .