Queremos apresentar nossa nova ferramenta para tokenização de texto - YouTokenToMe. Ele funciona de 7 a 10 vezes mais rápido que outras versões populares em idiomas semelhantes em estrutura aos europeus e 40 a 50 vezes - em idiomas asiáticos. Falamos sobre o YouTokenToMe e o compartilhamos em código aberto no GitHub. Link no final do artigo!

Hoje, uma proporção significativa das tarefas dos algoritmos de redes neurais é de processamento de texto. Porém, como as redes neurais funcionam com números, o texto precisa ser convertido antes de ser transferido para o modelo.
Listamos as soluções populares que geralmente são usadas para isso:
- quebra de espaço
- algoritmos baseados em regras: spaCy, NLTK;
- stemming, lematização.
Cada um deles tem suas próprias desvantagens:
- Você não pode controlar o tamanho do dicionário de token. O tamanho da camada de incorporação no modelo depende diretamente disso;
- informações sobre o parentesco de palavras que diferem em sufixos ou prefixos não são usadas, por exemplo: educado - indelicado;
- depende do idioma.
Recentemente, a abordagem de
codificação de pares de bytes tem sido popular. Inicialmente, esse algoritmo era destinado à compactação de texto, mas há vários anos foi usado para tokenizar texto na tradução automática. Agora é usado para uma ampla gama de tarefas, incluindo aquelas usadas nos modelos BERT e GPT-2.
As implementações mais eficazes do BPE foram o
SentençaPiece , desenvolvido pelos engenheiros do Google, e o
fastBPE , criado pelo Facebook AI Research. Mas conseguimos provar que a tokenização pode ser significativamente acelerada. Otimizamos o algoritmo BPE e publicamos o código-fonte e também postamos o pacote finalizado no repositório pip.
Abaixo, você pode comparar os resultados da medição da velocidade do nosso algoritmo e de outras versões. Como exemplo, pegamos os primeiros 100 MB
do corpus de dados da Wikipedia em russo, inglês, japonês e chinês.
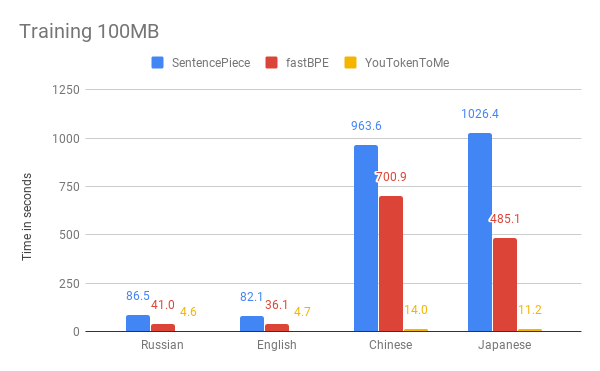

Os gráficos mostram que o tempo de operação depende significativamente do idioma. Isso ocorre porque os idiomas asiáticos têm mais alfabetos e as palavras não são separadas por espaços. O YouTokenToMe funciona de 7 a 10 vezes mais rápido em idiomas semelhantes em estrutura que os europeus e de 40 a 50 vezes em asiáticos. A tokenização foi acelerada pelo menos duas vezes e em alguns testes mais de dez vezes.
Alcançamos esses resultados graças a duas ideias principais:
- o novo algoritmo tem um tempo de execução linear, dependendo do tamanho do caso para treinamento. SentençaPiece e fastBPE têm comportamento assintótico menos eficaz;
- o novo algoritmo pode efetivamente usar vários fluxos no processo de aprendizado e no processo de tokenização - isso permite que você obtenha aceleração várias vezes mais.
Você pode usar o YouTokenToMe através da interface para trabalhar na linha de comando e diretamente no Python.
Você pode encontrar mais informações no repositório:
github.com/vkcom/YouTokenToMe