Oi Habr.
Recentemente, neste ano de 2019, a NVIDIA
anunciou um computador de placa única compatível com o fator de forma do Raspberry Pi, focado na IA e em cálculos intensivos em recursos.

Depois que apareceu à venda, ficou interessante ver como funciona e o que pode ser feito. Não é tão interessante usar benchmarks padrão, por isso, criaremos nossos próprios; para todos os testes, o código-fonte é fornecido no texto. Para aqueles que estão interessados no que aconteceu, continuaram sob o corte.
Hardware
Para iniciantes, as especificações do site da NVIDIA:

Do interessante, aqui estão alguns pontos.
A primeira é uma GPU com 128 núcleos, respectivamente, na placa, que você pode executar tarefas orientadas à GPU, como CUDA (suportado e instalado imediatamente) ou Tensorflow. O processador principal é de 4 núcleos e, como mostrado abaixo, é bastante bom. Memória de 4 GB compartilhada entre CPU e GPU.
O segundo é a compatibilidade com o Raspberry Pi. A placa possui um conector de 40 pinos com várias interfaces (I2C, SPI, etc.), há também um conector de câmera, que também é compatível com o Raspberry Pi. Pode-se supor que um grande número de acessórios existentes (telas, placas de controle do motor etc.) funcione (talvez seja necessário usar um cabo de extensão, porque o tamanho do Jetson Nano ainda é diferente).
Em terceiro lugar, a placa possui 2 saídas de vídeo, Gigabit-Ethernet e USB 3.0, ou seja, O Jetson Nano como um todo é ainda um pouco mais funcional que o protótipo. A energia de 5V pode ser obtida via Micro USB e por meio de um conector separado, recomendado para
minerar bitcoins de tarefas que consomem
muitos recursos. Como no Raspberry Pi, o software é carregado no cartão SD, cuja imagem deve ser gravada primeiro. Em geral, ideologicamente, o conselho é bastante semelhante ao Raspberry Pi, que aparentemente foi concebido na NVIDIA. Mas não há WiFi na placa, há um sinal de menos definitivo, aqueles que desejam terão que usar um módulo USB-WiFi.
Se você observar atentamente, poderá ver que estruturalmente o dispositivo consiste em dois módulos - o próprio módulo Jetson Nano e a placa inferior com conectores, a conexão é através de um conector.

I.e. a placa pode ser desconectada e usada separadamente, pode ser conveniente para soluções incorporadas.
Falando em preço. O preço original do Jetson Nano nos EUA é de US $ 99, o preço na Europa com uma marcação nas lojas locais é de cerca de 130 Euros (se você obtiver descontos, provavelmente poderá encontrar mais barato). Quanto custa o Nano na Rússia é desconhecido.
De software
Como mencionado acima, o download e a instalação não são muito diferentes do Raspberry Pi. Carregamos a
imagem no cartão SD via Etcher ou Win32DiskImager, entramos no Linux, colocamos as bibliotecas necessárias. Um excelente guia passo a passo está
aqui , eu o usei. Vamos passar para os testes imediatamente - tente executar diferentes programas no Nano e ver como eles funcionam. Para comparação, usei três computadores - meu laptop de trabalho (Core I7-6500U 2.5GHz), Raspberry Pi 3B + e Jetson Nano.
Teste de CPUPara começar, uma captura de tela do comando lscpu.
Raspberry Pi 3B +:
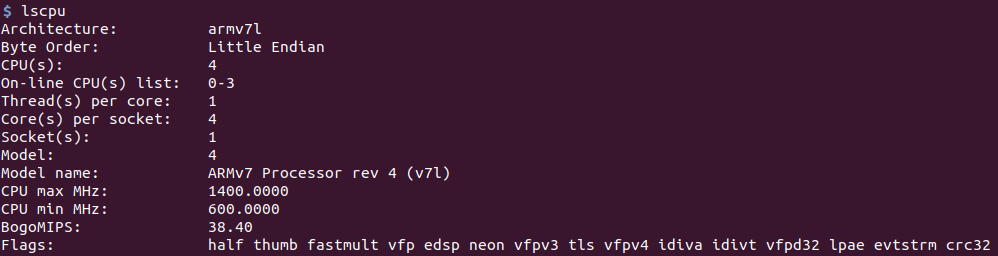
Jetson nano:
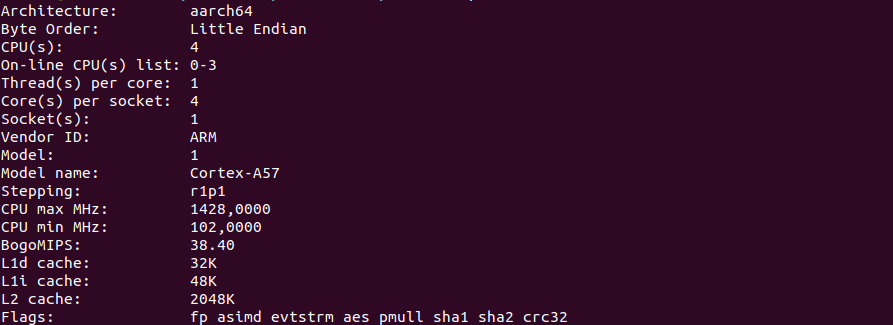
Para cálculos, vamos começar com algo simples, mas exigindo tempo do processador. Por exemplo, calculando o número Pi. Peguei um programa simples em Python com
stackoverflow .
Não sei se é ideal ou não, mas isso não importa para nós - estamos interessados no
tempo relativo .
Código fonte sob o spoiler Como esperado, o programa não funciona rápido. Resultado para Jetson Nano: 0.8c.
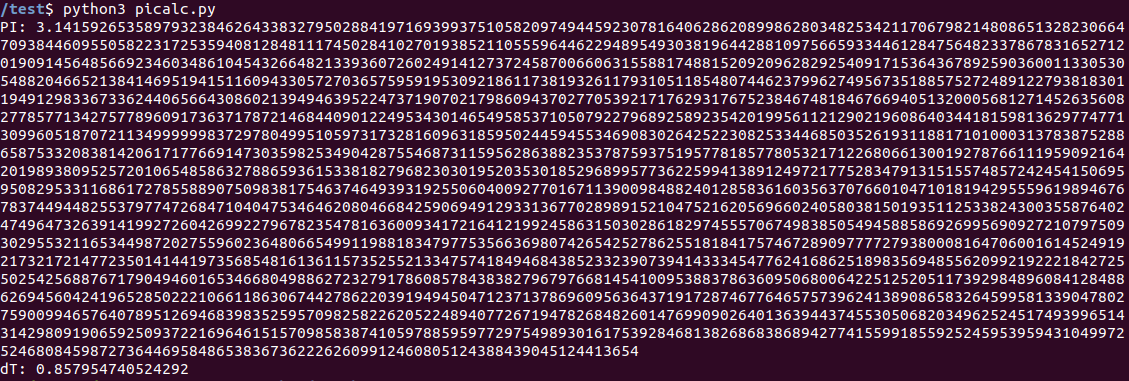
Raspberry Pi 3B + mostrou um tempo visivelmente mais longo: 3.06c. O laptop "exemplar" completou a tarefa em 0,27s. Em geral, mesmo sem o uso de uma GPU, o processador principal no Nano é muito bom por seu fator de forma. Quem quiser pode conferir o Raspberry Pi 4, não o tenho disponível.
Certamente há quem queira escrever nos comentários que o Python não é a melhor escolha para esses cálculos, repito mais uma vez que era importante
comparar o tempo, não há necessidade de minimizá-lo. É claro que existem programas que calculam o número do Pi muito mais rapidamente.
PycudaVamos passar para cálculos mais interessantes usando a GPU, para a qual, é claro (a placa é da NVIDIA), usaremos o CUDA. A biblioteca PyCUDA exigiu algum xamanismo durante a instalação, mas não encontrou cuda.h, o uso do comando "sudo env" PATH = $ PATH "pip install pycuda" ajudou, talvez haja outra maneira (mais opções foram discutidas
no fórum devtalk.nvidia.com ).
Para o teste, fiz o programa simples
SimpleSpeedTest for PyCUDA, que simplesmente conta os senos em um loop, não faz nada útil, mas é bem possível avaliá-lo e seu código é simples e claro.
Código fonte sob o spoiler Como você pode ver, o cálculo é feito usando a GPU através do CUDA e usando a CPU através de numpy.
Resultados:
Jetson nano - GPU 0.67c, CPU 13.3c.
CPU Raspberry Pi 3B + - 41.85c, GPU - sem dados, CUDA no RPi não funciona.
Notebook - GPU 0.05s, CPU 3.08c.
Tudo é bastante esperado. Os cálculos na GPU são muito mais rápidos que os cálculos na CPU (ainda com 128 núcleos), o Raspberry Pi fica bastante significativo. Bem, é claro, não importa
o quanto você alimente o lobo, o elefante ainda possui uma placa de vídeo para laptop muito mais rápida que a placa do Jetson Nano - é provável que haja muito mais núcleos de processamento nele.
Conclusão
Como você pode ver, a placa NVIDIA acabou sendo bastante interessante e muito produtiva. É um pouco maior e mais caro que o Raspberry Pi, mas se alguém precisar de mais poder de computação com um tamanho compacto, vale a pena. Obviamente, isso nem sempre é necessário - por exemplo, para enviar a temperatura ao narodmon, o Raspberry Pi Zero é suficiente e com várias margens. Portanto, a Jetson Nano não pretende
substituir o Raspberry e os clones, mas para tarefas com muitos recursos, é muito interessante (pode ser não apenas drones ou robôs móveis, mas também, por exemplo, uma
câmera para uma campainha com reconhecimento de rosto).
Em uma parte, tudo concebido não se encaixava. Na segunda parte, haverá testes da parte AI - testes de Keras / Tensorflow e tarefas de classificação e reconhecimento de imagens.