Criar e manter componentes comuns é um processo no qual muitas equipes devem estar envolvidas. O chefe do serviço de componentes compartilhados de Yandex Vladimir Grinenko
tadatuta explicou como seu desenvolvimento superou a equipe dedicada de Lego, como criamos um repositório mono baseado no GitHub usando Lerna e configuramos lançamentos de canários com a implementação de serviços diretamente no CI, o que era necessário e o que ainda a ser.
"Fico feliz em receber todos vocês." Meu nome é Vladimir, faço coisas comuns em interfaces Yandex. Eu quero falar sobre eles. Provavelmente, se você não usar nossos serviços muito profundamente, poderá ter uma pergunta: o que estamos todos escrevendo? O que há para escrever?


Há uma lista de respostas nos resultados da pesquisa, às vezes há uma coluna à direita. Cada um de vocês provavelmente vai lidar em um dia. Se você se lembrar de que existem navegadores diferentes e assim por diante, adicionamos outro dia para corrigir bugs e todos os usuários lidam com isso.
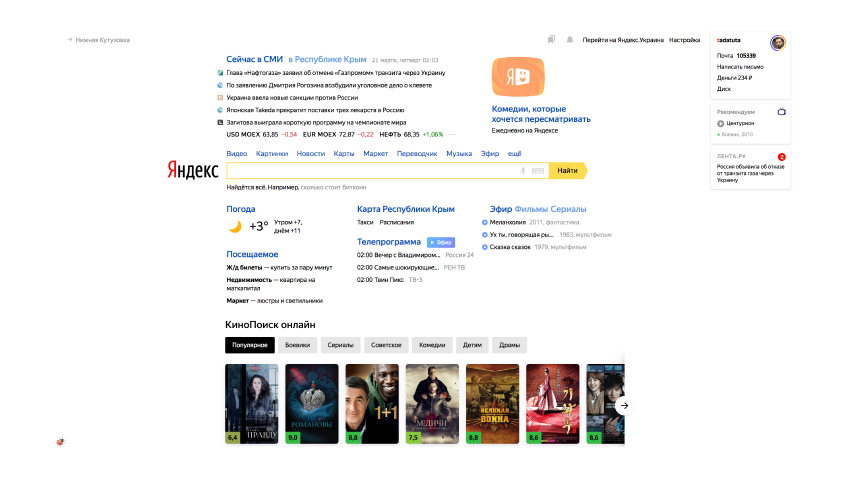
Alguém se lembrará de que ainda existe essa interface. Levando em conta todas as pequenas coisas que você pode dar a ele por mais uma semana e seguir em frente. E Dima acabou de nos dizer que existem tantos de nós que precisamos de nossa própria escola. E todas essas pessoas inventam páginas o tempo todo. Todos os dias eles vêm trabalhar e escrever, imagina? Claramente, há algo mais.

De fato, os serviços em Yandex, de fato, são mais. E ainda há um pouco mais do que neste slide. Por trás de cada link, há várias interfaces diferentes com grande variabilidade. Eles são para dispositivos diferentes, em diferentes idiomas. Às vezes, trabalham mesmo em carros e outras coisas estranhas.

Hoje, o Yandex não é apenas a web, não apenas mercadorias diferentes com armazéns, entrega e tudo mais. Passeio de carros amarelos. E não apenas o que você pode comer, e não apenas pedaços de ferro. E não apenas todos os tipos de inteligências automáticas. Mas tudo o que foi dito acima é unido pelo fato de que para cada item são necessárias interfaces. Muitas vezes - muito rico. Yandex é centenas de diferentes serviços enormes. Estamos constantemente criando algo novo todos os dias. Temos milhares de funcionários, incluindo centenas de desenvolvedores front-end e desenvolvedores de interface. Essas pessoas trabalham em escritórios diferentes, vivem em fusos horários diferentes, novos funcionários constantemente vêm trabalhar.
Ao mesmo tempo, nós, na medida em que temos força suficiente, tentamos torná-lo monótono e uniforme para os usuários.

Esta é a busca de documentos na Internet. Mas se mudarmos para a emissão de imagens, o cabeçalho corresponderá, apesar de ser um repositório separado, envolvido em uma equipe completamente separada, possivelmente até em outras tecnologias. Parece que é complicado? Bem, eles fizeram um chapéu duas vezes, como uma coisa simples. Cada botão na tampa também possui seu próprio mundo interno rico e separado. Alguns pop-ups aparecem aqui, algo também pode ser enviado para lá. Tudo isso é traduzido para diferentes idiomas, funciona em diferentes plataformas. E aqui vamos das fotos, por exemplo, para o vídeo, e este é novamente um novo serviço, outra equipe. Outro repositório novamente. Mas ainda o mesmo chapéu, embora haja diferenças. E tudo isso deve ser deixado uniforme.
Qual é o valor, alternando assim nos slides, para garantir que nada ocorra em nenhum lugar do pixel? Tentamos impedir que isso aconteça.

Para mostrar um pouco mais a escala, tirei uma captura de tela do repositório, que armazena apenas o código de front-end para novos navegadores - apenas a saída de documentos, sem fotos e vídeos. Existem dezenas de milhares de confirmações e quase 400 colaboradores. Isso é apenas no layout, apenas um projeto. Aqui está uma lista de links azuis que você está acostumado a ver.
Sergey Berezhnoy, meu líder, ama muito essa história, já que reunimos muito na empresa. Quero que nossa interação funcione em conjunto como se estivesse em JavaScript: um mais um é mais que dois.
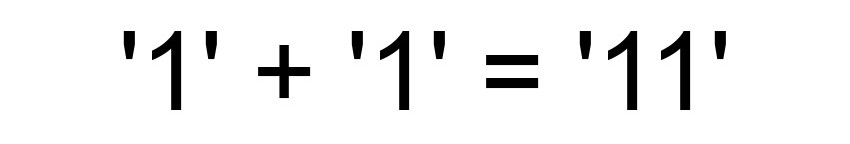
E estamos tentando obter tudo o que podemos com a interação. A primeira coisa que vem à mente nessas condições é a reutilização. Aqui, por exemplo, um snippet de vídeo em um serviço nos resultados da pesquisa para um vídeo. Este é algum tipo de imagem com uma assinatura e outros elementos diferentes.
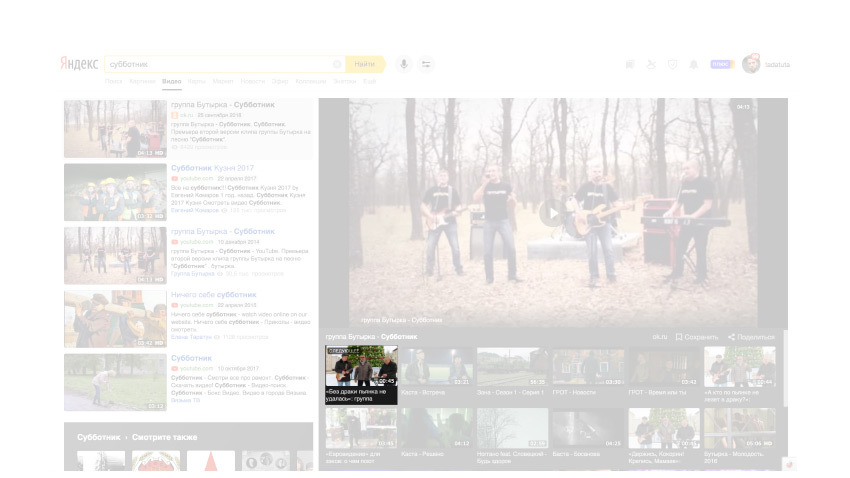
Se você procurar mais, aqui está a emissão usual de documentos. Mas aqui também há exatamente o mesmo trecho.

Ou, digamos, existe um serviço Yandex.Air separado, que consiste em um pouco menos do que completamente em trechos semelhantes.

Ou, digamos, o snippet de vídeo no notificador, que está em diferentes páginas do portal.
Ou aqui está um trecho de vídeo quando você o adiciona aos seus Favoritos e depois assiste às suas Coleções.

Soa como? Obviamente, parece. E daí? Se realmente permitirmos que os serviços integrem facilmente nossos componentes finalizados a outros serviços de portal, obviamente, esse serviço, devido ao fato de os usuários poderem interagir com seus dados em sites diferentes, obterá mais usuários. Isso é ótimo. Os usuários também se beneficiarão com isso. Eles verão as mesmas coisas igualmente. Eles vão se comportar como de costume. Ou seja, não é preciso adivinhar repetidamente o que o designer tinha em mente aqui e como interagir com ele.
E, finalmente, a empresa obterá economias óbvias com isso. Além disso, parece - por que existe um layout de miniatura de vídeo e algum tipo de assinatura / De fato, para obtê-lo exatamente assim, você precisa realizar muitas experiências diferentes, testar hipóteses diferentes, escolher tamanhos, cores, recuos. Adicione alguns elementos, talvez, e remova, porque eles não voaram. E o que aconteceu, o que realmente funciona, é o resultado de um processo muito longo. E se toda vez em qualquer novo lugar para fazê-lo novamente, isso é uma enorme quantidade de esforço.
Agora imagine. Digamos que conseguimos algo que funcione bem. Em todos os lugares, em todos os lugares em que o implementaram, eles realizaram um novo experimento e perceberam o que poderia ser melhorado. E, novamente, temos que repetir toda essa cadeia de implementação. Caro

Ok, parece óbvio reutilizar bem. Mas agora temos que resolver uma série de novos problemas. Você precisa entender onde armazenar esse novo código. Por um lado, parece ser lógico. Aqui temos um trecho de vídeo, feito pela equipe de vídeo, eles têm um repositório com seu projeto. Provavelmente deve ser colocado lá. Mas como então distribuí-lo para outros repositórios de todos os outros caras? E se outros caras quiserem trazer algo próprio para esse trecho? Mais uma vez não está claro.
É necessário versioná-lo de alguma forma. Você não pode mudar nada e, assim, pronto, tudo de repente acontece. Algo precisa ser testado. Além disso, nós, por exemplo, testamos isso no serviço do próprio vídeo. Mas e se, quando integrado a outro serviço, algo quebrar? Mais uma vez não está claro.
No final, é necessário, de alguma forma, garantir uma entrega rápida o suficiente para diferentes serviços, porque será estranho se tivermos em algum lugar a versão anterior, em algum lugar novo. O usuário parece clicar na mesma coisa e existe um comportamento diferente. E precisamos fornecer, de alguma forma, a oportunidade para desenvolvedores de equipes diferentes fazerem alterações nesse código comum. De alguma forma, precisamos ensiná-los a usar tudo. Temos um longo caminho para tornar conveniente a reutilização de interfaces.

Começamos no tempo imemorial, de volta ao SVN, e era conveniente e prático: um pai com HTML, como no Bootstrap. Você copia para si mesmo. Ao lado do papai com estilos, algum tipo de JS lá, que então sabia como simplesmente mostrar / ocultar algo. E isso é tudo.

De alguma forma, a lista de componentes era assim. O b-domeg, responsável pela autorização, é destacado aqui. Talvez você ainda se lembre, no Yandex, de fato, havia um formulário para login e senha, com um teto. Nós chamamos a "casa", embora ela tenha sugerido o envelope de correio, porque eles costumavam entrar no correio.
Em seguida, criamos toda uma metodologia para suportar interfaces comuns.

A própria biblioteca da empresa adquiriu seu próprio site com uma pesquisa e qualquer taxonomia.

O repositório agora se parece com isso. Veja bem, também quase 10 mil confirmações e mais de 100 colaboradores.

Mas esta é a pasta da própria casa na nova reencarnação. Agora ela se parece com isso. Já existem mais pastas próprias dentro da metade da tela.

E assim o site parece hoje.

Como resultado, a biblioteca compartilhada é usada em mais de 360 repositórios no Yandex. E existem implementações diferentes, um ciclo de lançamento depurado etc. Parece que aqui temos uma biblioteca comum, agora vamos usá-la em qualquer lugar e tudo é ótimo. O problema de introduzir coisas comuns em qualquer lugar foi resolvido. Na verdade não.

Tentando resolver o problema de reutilização no estágio em que você já possui código pronto, é tarde demais. Isso significa que, a partir do momento em que o designer desenhou o layout dos serviços, os distribuiu para os serviços e, em particular, para a equipe que lida com componentes comuns, já passou algum tempo. O mais provável é que, a essa altura, ele acabe para que em cada serviço separado, ou pelo menos em vários deles, esse mesmo elemento de interface também tenha sido criado. Eles inventaram de alguma maneira à sua maneira.
E mesmo que uma solução geral apareça mais tarde na biblioteca compartilhada, ela continuará sendo executada, assim você terá que reimplementar tudo o que conseguiu concluir em cada serviço. E isso é novamente um problema. É muito difícil justificar. Aqui está a equipe. Ela tem seus próprios objetivos, tudo já está funcionando bem. E dizemos essas coisas - olha, finalmente temos uma coisinha comum, aceite. Mas a equipe é assim - já temos trabalho suficiente. Por que precisamos disso? Além disso, de repente algo não vai nos servir lá? Nós não queremos.
O segundo grande problema é, de fato, a disseminação de informações sobre o que são esses novos componentes legais. Só porque existem tantos desenvolvedores, eles estão ocupados com suas tarefas diárias. E eles têm a oportunidade de sentar e estudar o que está acontecendo lá na área de comum, não importa o que isso signifique, de fato.
E o maior problema é que é fundamentalmente impossível resolver os problemas comuns a todos os serviços com uma única equipe dedicada. Ou seja, quando temos uma equipe que lida com vídeo, e ela cria seu próprio trecho com vídeo, fica claro que concordaremos com eles e faremos esse trecho em alguma biblioteca centralizada. Mas existem diretamente milhares desses exemplos em diferentes serviços. E aqui certamente nenhuma mão é suficiente. Portanto, a única solução é que todos devem lidar com componentes gerais o tempo todo.

E você precisa começar, estranhamente, não com os desenvolvedores de interface, mas com os designers. Eles entendem isso também. Temos várias tentativas simultâneas dentro para que esse processo converja. Designers criam sistemas de design. Eu realmente espero que, mais cedo ou mais tarde, seja possível reduzi-los a um único sistema comum que leve em consideração todas as necessidades.

Agora existem vários deles. Surpreendentemente, as tarefas são exatamente as mesmas: acelerar o processo de desenvolvimento, resolver o problema de consistência, não reinventar a roda e não duplicar o trabalho realizado.

E uma maneira de resolver o problema de comunicação de informações é permitir que os desenvolvedores conheçam outras equipes, incluindo uma que lida com componentes de interface comuns. Nós resolvemos isso deste lado pelo fato de termos um bootcamp, que, quando um desenvolvedor aparece no Yandex, primeiro permite que ele vá para equipes diferentes por oito semanas, veja como funciona e, em seguida, escolha onde ele funcionará. . Mas durante esse período, seus horizontes se expandirão significativamente. Ele será guiado para onde está.
Nós conversamos sobre coisas comuns. Vamos agora ver como tudo parece mais próximo do processo de desenvolvimento. Digamos que temos uma biblioteca comum chamada Lego. E queremos implementar algum novo recurso ou fazer algum tipo de revisão. Corrigimos o código e lançamos a versão.
Precisamos publicar esta versão no npm e, em seguida, ir para o repositório de algum projeto em que a biblioteca é usada e implementar esta versão. Provavelmente, isso corrigirá algum número no package.json, reinicie o assembly. Talvez até gere novamente o bloqueio de pacotes, crie uma solicitação pull, veja como os testes passam. E o que vamos ver?
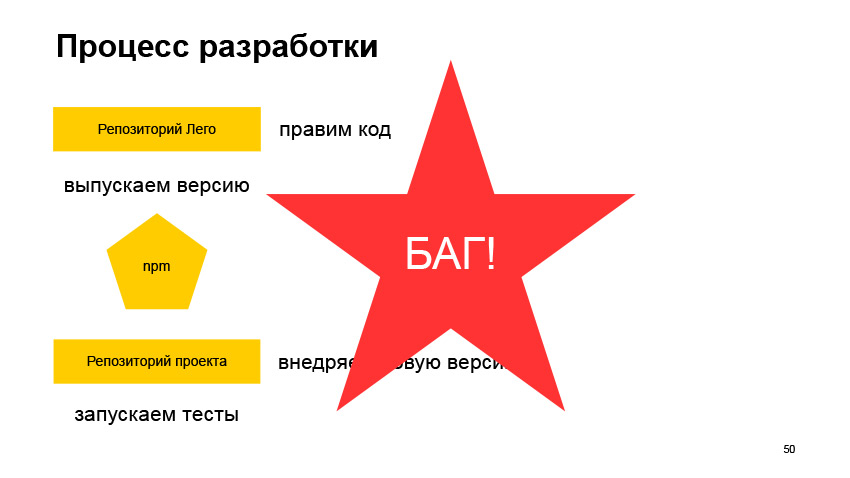
Muito provavelmente, veremos que ocorreu um erro. Porque é muito difícil prever todas as maneiras de usar o componente em diferentes serviços. E se isso aconteceu, então qual é a nossa saída? Então percebemos que não se encaixava. Continuamos refazendo. Retornamos ao repositório com uma biblioteca compartilhada, corrigimos o bug, lançamos a nova versão, enviamos para o npm, implantamos, executamos os testes e o que é? Provavelmente, um bug acontecerá novamente.
E isso ainda é bom quando o implementamos em um serviço e, ali mesmo, tudo quebrou imediatamente. Foi muito mais triste quando fizemos tudo isso, implementamos em dez serviços diferentes. Nada quebrou lá. Já fomos preparar um smoothie, ou o que for necessário. No momento, a versão está sendo apresentada no 11º projeto ou no 25º. E há um erro. Retornamos ao longo de toda a cadeia, fazemos um patch e implementamos em todos os 20 serviços anteriores. Além disso, esse patch pode explodir em um dos anteriores. Bem e assim por diante. Divirta-se.
A única saída, ao que parece, é que você só precisa escrever muito código rapidamente. Então, mais cedo ou mais tarde, se executarmos muito, muito rápido, provavelmente, conseguiremos tempo para lançar na produção uma versão na qual ainda não há nenhum erro. Mas então um novo recurso aparecerá e nada nos salvará.
Ok. De fato, o esquema pode ser algo como o seguinte. A automação nos ajudará. É sobre isso, em geral, toda a história, de fato. Tivemos a ideia de que um repositório com uma biblioteca comum pode ser construído de acordo com o esquema de mono-repositório. Você provavelmente já se deparou, agora existem muitos desses projetos, especialmente os de infraestrutura. Todos os tipos de Babel, e coisas assim, vivem como mono-repositórios quando existem muitos pacotes npm diferentes. Eles podem estar de alguma forma ligados um ao outro. E eles são gerenciados, por exemplo, através do Lerna, para que seja conveniente publicar tudo isso, dadas as dependências.
Exatamente de acordo com esse esquema, é possível organizar um projeto em que tudo em comum seja armazenado para toda a empresa. Pode haver uma biblioteca envolvida em uma equipe separada. E, inclusive, pode haver pacotes que cada serviço individual desenvolve, mas que ele deseja compartilhar com os outros.

Então o circuito fica assim. O começo não é diferente. De uma forma ou de outra, precisamos fazer alterações no código comum. E então, com a ajuda da automação, de uma só vez, queremos executar testes não apenas próximos a esse código, mas imediatamente em todos os projetos nos quais esse código comum está incorporado. E veja o resultado agregado.
Então, mesmo que um bug ocorra lá, ainda não conseguimos lançar nenhuma versão, não a publicamos em nenhuma NPM, não a implementamos especificamente com nossas mãos, não fizemos todos esses esforços extras. Vimos um bug, imediatamente o corrigimos localmente, executamos testes gerais novamente e tudo está em produção.
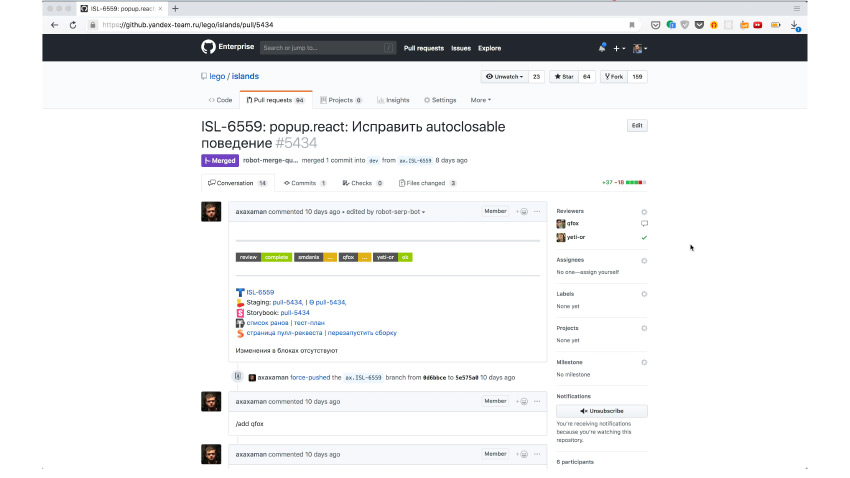
Como é na prática? Aqui está uma solicitação de recebimento com uma correção. Aqui você pode ver que a automação solicitou os revisores necessários para verificar se tudo está bem no código. De fato, os revisores chegaram e concordaram que estava tudo bem. E, neste momento, o desenvolvedor simplesmente escreve um comando especial / canário, diretamente na solicitação de recebimento.
Um robô chega e diz - tudo bem, criei uma tarefa para o próximo milagre. O milagre é que uma versão canária com essas mudanças foi lançada e foi implementada automaticamente em todos os repositórios em que esse componente é usado. Os autotestes foram lançados lá, como neste repositório. Aqui você pode ver que várias verificações foram lançadas.
Por trás de cada teste pode haver mais cem testes diferentes. Mas é importante que, além dos testes locais que pudéssemos gravar separadamente no componente, também lançássemos testes para cada projeto em que ele foi implementado. Os testes de integração já foram lançados lá: verificamos que esse componente funciona normalmente no ambiente em que é concebido no serviço. Isso já nos garante realmente que não esquecemos nada, não quebramos nada para ninguém. Se tudo estiver bem aqui, podemos realmente lançar uma versão com segurança. E se algo estiver ruim aqui, vamos consertar aqui.
Parece que isso deve nos ajudar. Se sua empresa tiver algo semelhante, você verá que há partes que você poderia potencialmente reutilizar, mas, por enquanto, é necessário reorganizá-las porque não há automação. Recomendamos que você chegue a uma solução semelhante.

O que conseguimos? O monorepositório geral no qual as linhas são reconstruídas. Ou seja, todo mundo escreve o código da mesma maneira, ele tem todos os tipos de testes. Qualquer equipe pode vir, colocar seu componente e testá-lo com testes de unidade JS, cobrir com capturas de tela etc. Tudo já estará pronto para uso. A revisão de código inteligente que eu mencionei. Graças às ferramentas internas ricas, é realmente inteligente aqui.
O desenvolvedor está de férias agora? Convocá-lo para uma solicitação pull é inútil; o sistema levará isso em consideração. O desenvolvedor está doente? O sistema também levará isso em consideração. Se ambas as condições não forem cumpridas e o desenvolvedor parecer livre, ele receberá uma notificação em um de seus mensageiros de sua escolha. E ele é assim: não, agora estou ocupado com algo urgente ou em uma reunião. Ele pode chegar lá e apenas escrever o comando / busy. O sistema entenderá automaticamente que você precisa atribuir o próximo da lista.
O próximo passo é publicar a mesma versão canária. Ou seja, com qualquer alteração de código, precisamos lançar um pacote de serviços que possamos verificar em diferentes serviços. Em seguida, precisamos executar testes ao implantar em todos esses serviços. E quando tudo aconteceu, lance os lançamentos.
Se uma alteração afetar alguma estática que deve ser carregada a partir da CDN, você precisará publicá-la automaticamente separadamente. . , , , , . , , , changelog - .
, , , , . , , .
, . . , , : , ? A resposta é simples. , . . , .