
A solução do problema de reconhecimento de imagem (OCR) está repleta de várias dificuldades. Essa imagem não pode ser reconhecida devido ao esquema de cores não padrão ou à distorção. Que o cliente deseja reconhecer todas as imagens sem nenhuma restrição, e isso está longe de ser sempre possível. Os problemas são diferentes e nem sempre é possível resolvê-los imediatamente. Neste post, daremos algumas dicas úteis com base na experiência de resolver situações reais com os clientes.
Mas primeiro, um pouco de história. Muito tempo se passou desde a publicação do artigo sobre
como reescrevemos o serviço de filtragem . Nele, falamos um pouco sobre filtragem e processamento de mensagens, sobre como nosso serviço de filtragem como um todo é organizado. Desta vez, tentaremos responder à pergunta "Como processamos imagens, como os serviços interagem e o que acontece com o sistema sob carga?" Se operarmos em um artigo sobre um serviço de filtragem, agora consideraremos apenas uma ramificação da interação do serviço - essa é a interação de um serviço de filtragem e do OCR.
O que é um OCR?
Antes de falar sobre a interação dos serviços e os problemas do uso do OCR, vamos tentar entender o que é o OCR. Veja a definição
complicada da Wikipedia.
Reconhecimento
óptico de caracteres (OCR) - a tradução mecânica ou eletrônica de imagens de texto manuscritas, datilografadas ou digitadas em dados de texto usados para representar caracteres em um computador (por exemplo, em um editor de texto).
Simplificando, eles tiraram uma foto, a enviaram para reconhecimento, então a
mágica estava fora de Hogwarts e recebeu o texto.

Você também pode obter a definição de OCR no site da ABBYY, que parece mais simples.
O reconhecimento óptico de caracteres (OCR) é uma tecnologia que permite converter vários tipos de documentos, como documentos digitalizados, arquivos PDF ou fotos de uma câmera digital, em formatos editáveis pesquisáveis.
E por que precisamos (reconhecimento de imagem)?
Podemos usar o reconhecimento de imagens mesmo em nosso PC doméstico para converter imagens digitais em dados de texto editáveis, mas a tarefa que temos diante de nós é muito mais ampla (afinal, um sistema DLP): precisamos controlar o fluxo de informações na organização.
Os sistemas DLP há muito tempo aparecem no mercado e agora fazem parte do arsenal familiar dos sistemas corporativos de segurança da informação (ferramentas de proteção da informação). O DLP enfrenta a tarefa de controlar o movimento de informações gráficas (documentos digitalizados, capturas de tela, fotos). E não apenas controlar o movimento de arquivos gráficos, mas, antes de tudo, a análise de seu conteúdo. O sistema deve ser capaz de entender exatamente quais informações foram encontradas, compará-las com amostras de informações protegidas e oferecer oportunidades para o usuário pesquisar mais essas informações. O uso de outras ferramentas de análise, como comparação com impressões digitais, cálculo de hash, análise por formato de arquivo, tamanho e estrutura, também são fontes valiosas de informação, mas não permitem responder à pergunta: “que texto é transmitido nesta imagem?” Enquanto isso, o texto ainda é o suporte mais comum de informações estruturadas, inclusive em arquivos gráficos.
Tradicionalmente, a tecnologia OCR é usada para reconhecer informações gráficas (o que já determinamos). De fato, o OCR é geralmente a única classe de tecnologias que fornece a capacidade de extrair informações de texto das imagens. Portanto, não se trata tanto da abordagem tradicional, mas da falta de escolha.
Quantas imagens são processadas por sistema DLP?
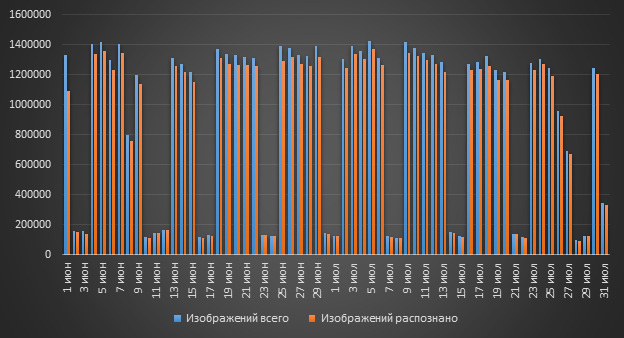
Você não pode fazer sem OCR? Existem tantas imagens no DLP que você precisa aplicar o OCR? A resposta a esta pergunta é "Sim!". Mais de um milhão de imagens podem entrar no sistema por dia e todas essas imagens podem conter texto.
O OCR como parte do sistema Rostelecom-Solar DLP é usado por empresas de petróleo e gás e agências governamentais. Todos os clientes usam o OCR para detectar dados confidenciais em documentos digitalizados. O que pode estar contido em uma “agenda”? Sim, qualquer coisa. Podem ser digitalizações de vários documentos internos, por exemplo, contendo PD. Ou informações da categoria de segredos comerciais, aglomerado (para uso oficial), demonstrações financeiras, etc.
Como o OCR reconhece imagens?
O processo é o seguinte: O DLP intercepta uma mensagem que contém uma imagem (digitalização de documento, fotografia, etc.), determina que a imagem está realmente na mensagem, extrai-a e envia-a ao OCR para reconhecimento. Na saída, o DLP recebe informações sobre o conteúdo da imagem (e a mensagem como um todo) na forma de TEXT / PLAIN extraído.
Se falamos sobre a interação de serviços diretamente em nosso sistema Solar Dozor, o serviço de filtragem envia imagens (se houver) da mensagem para o serviço de extração de texto de imagem (OCR). Este último, após a conclusão do reconhecimento, envia o texto recebido para o filtro de correio. Acontece algo como manipular imagens e texto.

Vamos considerar o mecanismo de reconhecimento mais a fundo pelo exemplo das tecnologias de OCR ABBYY, que usamos em nosso próprio DLP.
Talvez o principal problema do OCR ao reconhecer texto seja a ortografia de um caractere. Se pegarmos qualquer letra do alfabeto (por exemplo, russo ou inglês), encontraremos várias opções de ortografia para cada uma delas. Os mecanismos de OCR resolvem esse problema de várias maneiras:
- Encontrando um personagem por padrão. Por exemplo, usando uma variedade de fontes de ortografia.
- Identificação de sinais para escrever um personagem.
Se você der um exemplo grosseiro de trabalho, o OCR dividirá o texto em caracteres que ele identificou anteriormente na imagem e os impõe a modelos prontos. Em seguida, é verificado se o símbolo se parece com uma ortografia de modelo ou não. Quando um caractere é identificado, ele é convertido no código de caractere na codificação usada. Como resultado desse processo, símbolos são adicionados em palavras, frases no texto final.
Existem muitos artigos diferentes sobre o trabalho do OCR. Você pode ler mais sobre o trabalho do OCR, por exemplo, aqui
https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/Como preparar o OCR como um todo para reconhecimento?
Já descobrimos que mais de um milhão de imagens podem entrar no DLP. Mas todas as imagens deste milhão são úteis para nós?
A resposta para a pergunta é mais do que óbvia - é claro que não. Mas por que nem todas as imagens serão úteis para nós? A resposta a esta pergunta também é bastante transparente: muitas fotos de assinaturas em mensagens "andam" pelo correio. Provavelmente 90% das mensagens (se não houver mais) conterão o logotipo da empresa.
Essas figuras são pequenas demais para serem reconhecidas; talvez não exista nenhum texto. Aqui, podemos aconselhar (e até mesmo recomendar fortemente) a definir restrições no tamanho das imagens reconhecidas. Nesse caso, as restrições devem ser definidas tanto no limite inferior quanto no superior. A probabilidade de enviar arquivos pesados para processamento é menor do que para fotos de uma assinatura, mas ainda é bastante alta.Vale a pena notar que as imagens digitais geralmente apresentam defeitos diferentes. É improvável que o DLP sempre obtenha digitalizações de documentos em boa resolução. Pelo contrário, as varreduras nem sempre terão a melhor qualidade e muitos defeitos.
Por exemplo, em uma foto digital, a perspectiva pode ficar distorcida, realçada ou invertida e as linhas de digitalização podem ser curvas. Essa distorção pode complicar o reconhecimento. Portanto, os mecanismos de OCR podem pré-processar as imagens para prepará-las para o reconhecimento. Por exemplo, uma imagem pode ser torcida, convertida em preto-e-branco, inverter cores e corrigir inclinações de linha.
Tudo isso pode ser definido nas configurações de OCR e, como resultado, essas ferramentas podem ajudar a melhorar o reconhecimento de texto nas imagens.Como resultado, chegamos aos princípios básicos da preparação do OCR para reconhecimento:
- Determine o tamanho das imagens que reconheceremos, em pixels e em Mb.
- Ativar pré-processamento de imagem.
Para aumentar a eficiência do OCR, você também pode armazenar em cache os dados reconhecidos para não enviar as mesmas imagens várias vezes para reconhecimento.
No que mais você deve prestar atenção ao preparar o OCR, descreveremos abaixo exemplos de uso dessa tecnologia nas práticas de combate.
Quais desafios são possíveis ao usar o OCR no DLP sob carga pesada?
1. Limites muito amplos no tamanho das imagens reconhecidasVamos começar com o que já mencionamos - com limites.
Com base em nossa prática, os clientes geralmente estabelecem limites muito amplos para o tamanho dos arquivos de imagem reconhecidos. Sim, para que o OCR funcione bem, você precisa limitar o tamanho da imagem. Mas os clientes se esforçam para controlar tudo, acreditando que mesmo em uma imagem de 100x100 pixels e 5 KB de tamanho, dados valiosos podem vazar. Em geral, é claro, 100x100 pixels e 5 Kb também são limitações, mas esses limites são muito baixos.
O outro extremo é o desejo de reconhecer arquivos pesados de várias centenas de MB. É claro que essas imagens não serão rastreadas pelo correio corporativo devido a restrições no tamanho das mensagens enviadas. Mas aqui em outros canais de interceptação (por exemplo, na esfera da rede corporativa), arquivos pesados procuram persistentemente reconhecer. Se o cliente deseja adicionar a isso uma grande quantidade de imagens de alta resolução, para isso você precisa ter as capacidades de servidor apropriadas. Como resultado, com limites mínimos e máximos tão amplos para o tamanho dos arquivos reconhecidos, uma alta carga de processador é criada nos servidores, o que diminui a velocidade da operação de todos os subsistemas.
O que pode ser recomendado aqui? Primeiro, analise qual “cronograma” usado pela empresa contém dados confidenciais e, em seguida, estime as restrições mínimas e máximas razoáveis no tamanho das imagens monitoradas. Normalmente, recomendamos que os clientes fixem o limite inferior da resolução da imagem de 200 pixels, idealmente de 400 pixels (ao longo dos eixos X e Y), e tamanhos de arquivo de pelo menos 20 Kb, maiores. Também não faz sentido enviar imagens pesadas para o OCR - elas simplesmente sobrecarregam seus servidores e não o fato de serem reconhecidas.2. Filas de filas e tempos limite de processamento de solicitaçõesA carga excessiva nos servidores, decorrente dos motivos acima, leva ao longo da cadeia a aumentar o tempo de reconhecimento de imagem e processamento de consultas em geral. Como resultado, a fila de mensagens para filtragem começa a aumentar no sistema DLP. Além disso, arquivos gráficos que não podem ser reconhecidos em princípio (arquivos pesados, baixa qualidade etc.) podem chegar ao módulo de OCR, resultando em tempos limite de processamento de imagem. Se houver muitos arquivos não reconhecidos e o sistema tiver altos tempos limite de reconhecimento, o serviço de filtragem aguardará até que esse tempo limite ocorra e só então processará a próxima solicitação. Todo o processo de processamento pode ser seriamente inibido.
O que podemos aconselhar? Se houver uma fila para processar imagens gráficas, você precisará observar as configurações de OCR no sistema DLP e tentar encontrar a causa da frenagem. Isso pode ocorrer, por exemplo, devido a problemas de comunicação entre processos no próprio servidor. Em geral, esses problemas merecem uma discussão separada. Alguns detalhes sobre questões gerais podem ser encontrados no artigo “Introdução à comunicação entre processos no Linux” .Além disso, um ponto importante ao configurar o OCR é definir intervalos adequados para o reconhecimento de imagens. Em geral, 90 segundos são suficientes para que a imagem seja reconhecida com precisão. Se nenhum texto foi extraído da imagem em 90 segundos, pode-se presumir que o OCR não reconhece a imagem em princípio. Nesse ponto, os problemas de configuração do OCR também podem ocorrer quando eles definem altos tempos limite de reconhecimento e, assim, tentam reconhecer os não reconhecidos.O que mais poderia causar um tempo limite? Aqui voltamos à questão da configuração do sistema. O serviço de filtragem, como o serviço de OCR, opera com threads que processam mensagens e imagens. O sistema pode não estar configurado corretamente em termos do número de manipuladores de serviços de filtragem e o número de manipuladores de OCR. Por exemplo, um serviço de filtragem terá muitos manipuladores de threads, enquanto o OCR terá apenas um. Em tal situação, em alguns momentos o OCR pode simplesmente não ter tempo para processar todas as solicitações de reconhecimento e, assim, os tempos limite do processamento de imagens aparecerão.
Esse comportamento do sistema sugere pensamentos sobre problemas e erros de design na arquitetura, mas na verdade não é. A arquitetura do nosso DLP oferece a flexibilidade de configurar o sistema e personalizá-lo de acordo com as necessidades dos clientes. Por exemplo, podemos simplesmente configurar um OCR para trabalhar com dois serviços de filtragem sem sacrificar o desempenho.
3. Imagens não reconhecidasSe uma imagem que o OCR não consegue reconhecer entra no sistema DLP para análise, existem várias soluções para o problema.
Por que razões as imagens podem não ser reconhecidas? Por exemplo, pelo seguinte:
1. Esquema de cores não padrão da imagem.
2. Imagem de baixa resolução.
3. Orientação incorreta da imagem e do texto nela contido no espaço.
4. Inclinações da linha e distorção das proporções do texto na imagem, etc.
Aqui está um exemplo: um dos clientes durante o processo de monitoramento descobriu que o OCR não reconhece documentos PDF executados em um esquema de cores não padrão. Ou seja, a imagem foi extraída do documento PDF no modo normal, mas quando se tratava de processar o módulo OCR, ele não entendeu o esquema de cores da imagem e produziu o “quadrado Malevich” na saída. Em nossa interface, a imagem era algo como isto:
 Os mecanismos de OCR têm várias funções para correção automática de imagem, o que aumenta muito as chances de reconhecimento bem-sucedido do texto contido nele. No entanto, na prática, essas ferramentas mágicas nem sempre funcionam. Nesse caso específico, personalizamos o módulo OCR para o cliente, para que ele reconheça esse esquema de cores não padrão.
Os mecanismos de OCR têm várias funções para correção automática de imagem, o que aumenta muito as chances de reconhecimento bem-sucedido do texto contido nele. No entanto, na prática, essas ferramentas mágicas nem sempre funcionam. Nesse caso específico, personalizamos o módulo OCR para o cliente, para que ele reconheça esse esquema de cores não padrão.5. Inconsistência de um dos parâmetros do documento para os tamanhos especificados reconhecidos
imagens.
Por exemplo, na configuração do sistema, os limites de tamanho das imagens reconhecidas são definidos para 200x1000 pixels e um arquivo de 500x1500 pixels é recebido no OCR (limite superior excedido).
Nesse caso, você precisa corrigir as configurações de OCR para reconhecer essas imagens.Esse talvez seja um dos cenários mais populares de reconfiguração do sistema, depois de sabermos que o OCR não funciona.
Por que o OCR não está nos agentes?
O OCR nos sistemas DLP é implementado em duas versões - em agentes e em servidores. Somos a favor da segunda abordagem, já que o reconhecimento de imagem diretamente na estação de trabalho cria uma carga alta no processador e, consequentemente, diminui o trabalho de outras aplicações. O próprio OCR é uma tecnologia muito voraz, mesmo para servidores, e sua aplicação requer planejamento adequado das capacidades do processador e monitoramento de desempenho.
No entanto, muitas empresas domésticas, especialmente no setor público, ainda possuem uma frota de PCs bastante antiga. O que acontece neste caso? Os usuários começam a reclamar com o departamento de TI sobre a "frenagem" do PC, e os especialistas em TI finalmente descobrem que a causa da frenagem é o módulo de OCR do sistema DLP. Isso os incomoda e usuários que não conseguem resolver rapidamente as tarefas de trabalho. No final, tudo isso resulta em dor de cabeça para um segurança que tem muitas outras tarefas.
O uso do OCR nos agentes é justificado apenas quando o sistema DLP funciona "isoladamente". Nesse caso, o reconhecimento de imagem deve ocorrer exatamente no momento em que o usuário executa ações com esse arquivo gráfico em sua estação de trabalho. Ou seja, o sistema DLP deve decidir instantaneamente o destino do documento que contém esta imagem - permitir que ele seja enviado / copiado ou proibido. Mas, na prática, apenas alguns clientes usam o sistema DLP no modo de bloqueio ativo, e isso se aplica não apenas ao nosso próprio DLP. Aqui o princípio funciona: "tudo o que pode ser retirado para verificações no servidor deve ser executado no servidor".
Total
As tecnologias OCR oferecem recursos de reconhecimento gráfico e, além disso, sempre fornecemos recomendações gerais para a configuração do sistema. No entanto, em um projeto específico, pode ser necessário reconfigurar o módulo OCR para atender às necessidades específicas do cliente, tanto nos estágios de pilotagem e implementação da solução quanto no estágio de sua operação industrial. Isso não é apenas normal - é a única maneira correta de fornecer resultados tangíveis, fazer o OCR funcionar na empresa o mais eficiente possível e minimizar o vazamento de informações confidenciais através de imagens gráficas.
Nikita Igonkin, engenheira líder de serviços, Rostelecom Solar