Olá pessoal! Uma conferência sobre o desenvolvimento de aplicativos altamente carregados HighLoad ++ Siberia 2019 foi realizada em Novosibirsk em junho. Anteriormente, nos artigos sobre Habré, mencionamos que na Plesk realizamos uma retrospectiva de conferências e relatórios de que participamos para não perder o conhecimento adquirido e posteriormente aplicá-los. Nós lhe diremos quais relatórios anotamos para nós mesmos e também compartilharemos com você uma receita retrospectiva. Os organizadores estão postando gradualmente o vídeo aqui:
canal do youtube . Parte do que estamos descrevendo já pode ser vista.
Visão geral dos relatórios
Victor Eremchenko (Miró)Este é um relatório de revisão sobre a migração bem-sucedida do Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. O autor fornece esquemas, armadilhas típicas de soluções óbvias, fala sobre soluções alternativas e por que elas não se encaixavam. Do interessante:
- Os engenheiros da Miro montaram sua solução para não pagar pelo Amazon RDS, e até agora essa solução é adequada para eles.
- Likbez em gerenciadores de conexões para PostgreSQL.
- Descreve o processo de atualização de nós do cluster sem parar o aplicativo.
- Mostra um truque para atualizar rapidamente o PostgreSQL.
É útil ver aqueles que usam ou vão usar o PostgreSQL e que possuem uma quantidade crescente de dados.
Vasily Bogonatov (Yandex)Como palestrante introdutório, ele fez uma breve comparação de alguns recursos do Kafka e RabbitMQ. Resumidamente: Kafka - uma fila simples, um destinatário complexo; RabbitMQ é uma fila complexa, um receptor simples. O autor também falou sobre os tipos de garantias para entregar uma mensagem da fila. Nota importante: nenhuma fila pode garantir a entrega de uma mensagem exatamente 1 vez sem suporte do remetente e do destinatário.
O relatório é dedicado ao YandexMQ. YandexMQ (YMQ) é uma API compatível com a fila do Amazon SQS. A base do YandexMQ é o Yandex Database (YDB). Vasily mostrou a vantagem do YandexMQ, como obter consistência e confiabilidade estritas, e deu uma visão geral da arquitetura do YMQ. O YMQ implementa o padrão Consumidores concorrentes - uma mensagem para um consumidor. Chip YMQ: quando o consumidor pede uma mensagem, ela fica oculta na fila para que ninguém mais a processe. Se houver problemas durante o processamento, depois de VisibilityTimeout, a mensagem se tornará visível na fila novamente. O orador alega que o Apache Kafka tem um problema de perda de dados quando o processo é subitamente interrompido; o Yandex MessageQueue é resistente a isso.

O relatório é recomendado para todos que desejam entender os recursos fundamentais das filas.
Ivan Muratov (Primeira Empresa de Monitoramento)Relate como armazenar e processar dados na série temporal do PostgreSQL.
O TimescaleDB permite armazenar grandes volumes devido ao particionamento astuto, e o PipelineDB fornece trabalho com fluxos diretamente no PostgreSQL (bem como a integração com filas).
TimescaleDB:
- Possui uma velocidade de gravação muito estável, com um aumento no volume do banco de dados sob cargas pesadas e um aumento no número de partições, medidas em milhares.
- Permite usar recursos padrão do PostgreSQL, como SQL, replicação, backup, restauração, etc.
- Um bom conjunto de integrações é anunciado, por exemplo, com Prometheus, Telegraf, Grafana, Zabbix, Kubernetes.
- Existe uma versão de código aberto gratuita.
A ideia principal: o TimescaleDB é necessário principalmente para armazenar dados.
PipelineDB:
- Permite processar continuamente os dados recebidos usando SQL e adicionar o resultado a uma tabela.
- Tem uma interface SQL.
- Há um desempenho de procedimentos armazenados nas condições.
- São possíveis integrações com o Apache Kafka e o Amazon Kinesis.
- Existe uma versão de código aberto gratuita.
- O desenvolvimento do PipelineDB está congelado na versão 1.0 e agora apenas as correções são lançadas.
A idéia principal: o PipelineDB é necessário principalmente para o processamento de dados.
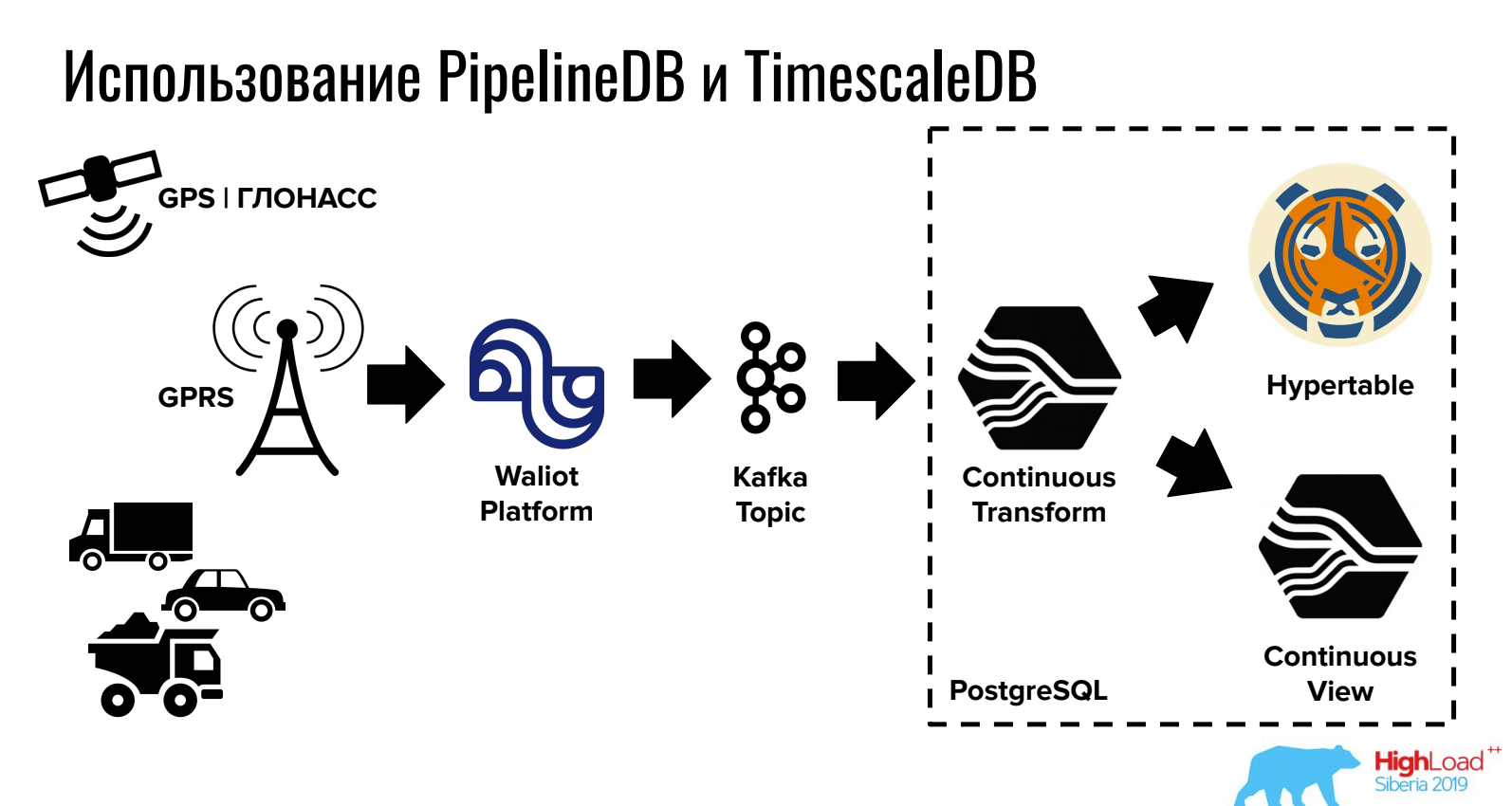
Para tarefas nas quais um DBMS relacional, NoSQL e séries temporais são necessários ao mesmo tempo, essa opção pode ser bastante conveniente.
Pavel Luzanov (profissional do Postgres)Um bom relatório de visão geral do PostgreSQL, herança de tabelas e desempenho de dicas e truques do PostgreSQL 10, 11, 12+. Particionando por herança, fragmentação. É útil ver todos que usam o PostgreSQL e desejam torná-lo um pouco mais rápido.
Sergey Polovko (Yandex)O produto em nuvem Yandex Monitoring, que ainda está no estágio "Preview", é gratuito. Um pouco sobre arquitetura. Uma técnica interessante é mostrada - a separação dos metadados dos dados, o que permite dimensionamento e otimização independentes. O Grafana é usado como uma GUI, enquanto seus alertas não estão no Grafana.
 Andrey Salnikov (Garça de Dados)
Andrey Salnikov (Garça de Dados)Experiência na administração comercial de sistemas de muitos servidores PostgreSQL. Ele informa quais parâmetros do servidor são monitorados automaticamente, como as tarefas são priorizadas.
O Data Egret usa experiência generalizada no Wiki com receitas, listas de verificação - esta é a base para futuros artigos e relatórios. Eles usam um banco de dados de incidentes com uma descrição dos problemas e soluções - isso economiza recursos significativamente. Lançados vários utilitários para trabalhar com o PostgreSQL, forneça links para eles.
 Evgeny Sokolov (Yandex.Market)
Evgeny Sokolov (Yandex.Market)Relatório sobre a arquitetura de um aplicativo Yandex.Market complexo, altamente acessível e distribuído e sobre os processos e ferramentas para seu desenvolvimento, teste, atualização e monitoramento. Do interessante:
- "Stop-crane" é a sua solução para aplicação rápida e reversão de configuração; ajuda a testar novas funcionalidades.
- O tráfego é redirecionado do data center atual pelo balanceador para outro data center em caso de problemas.
- Grafite e Grafana são usados para monitoramento.
- Há um monitoramento básico duplicado em outra pilha de tecnologia.
- Um cluster Shadow é usado para desenvolvedores, que duplica parte do tráfego do usuário. Os usuários não veem as respostas do cluster Shadow.
- Um cálculo automático da qualidade é realizado durante o teste A / B.
 Anton Alekseev (2GIS)
Anton Alekseev (2GIS)Informe sobre o que o ClickHouse é bom e como cozinhá-lo em conjunto com o Grafana. O principal interessante:
- Se não houver velocidade suficiente, você deve usar amostragem (argumenta-se que a precisão dos dados após a amostragem é suficiente). Amostragem no ClickHouse - amostragem parcial de dados com agregação, mantendo a proporção de vários valores na chave da tabela, permite acelerar a agregação às vezes e, ao mesmo tempo, ter um resultado muito próximo do real.
- O ClickHouse pode ser usado para investigar incidentes rapidamente (um exemplo interessante no relatório).
- O ClickHouse também possui um MaterializedView para acelerar a busca.
- A interface HTTP do ClickHouse para consulta e carregamento de dados é descrita.
Para concluir a revisão dos relatórios, gostaria de observar que também gostamos muito do relatório
“Videochamadas: de milhões por dia a 100 participantes em uma conferência” (
Alexander Tobol / Odnoklassniki), incluído na lista dos melhores relatórios da conferência, de acordo com os resultados da votação. Esta é uma ótima visão geral de como a videoconferência funciona para um grupo de participantes. O relatório se distingue por uma apresentação sistêmica compreensível. Se você precisar fazer chamadas de vídeo repentinamente, poderá ver o relatório para obter rapidamente informações sobre a área de assunto.
Estrutura de Flashback da Conferência Plesk
E agora, como sobremesa, sobre como escrevemos uma retrospectiva dentro da empresa. Primeiro, tentamos escrever retro na primeira semana depois de assistir à conferência, enquanto nossas memórias ainda estão frescas. A propósito, o material retrospectivo pode servir como base para o artigo, como você pode imaginar;)
O objetivo de escrever uma retrospectiva não é apenas consolidar o conhecimento, mas também compartilhá-lo com aqueles que não estiveram na conferência, mas querem acompanhar as últimas tendências, soluções interessantes. Uma lista pronta ajuda a reduzir o tempo para procurar relatórios interessantes para exibição. Escrevemos as lições que aprendemos para nós mesmos, marcamos pessoas específicas com uma nota, por que você precisa ver o relatório e pensar nas idéias e decisões dos outros. As lições escritas ajudam a focar e a não perder o que queríamos fazer. Observando as gravações em 3 a 6 meses, entenderemos se esquecemos algo importante.
Armazenamos documentação na empresa em Confluence. Para conferências, temos uma árvore de páginas separada, um pedaço de madeira:
Como pode ser visto na captura de tela, organizamos os materiais por ano para facilitar a navegação.
Dentro da página dedicada a uma conferência específica, armazenamos as seguintes seções: visão geral com links para o site do evento, programação, vídeos e apresentações, lista de participantes (pessoalmente e em transmissões), impressão geral (impressão geral) e visão geral detalhada (visão geral detalhada) ) A propósito, geramos uma página para retro a partir de um modelo no qual toda a estrutura já existe. Também criamos o conteúdo dos títulos para que você possa visualizar rapidamente a lista de relatórios e passar para o desejado.
A seção Impressão geral fornece uma breve avaliação da conferência e fornece as impressões dos participantes. Se os participantes estiveram na conferência nos últimos anos, eles podem comparar seus níveis e geralmente entender a utilidade de participar do evento.
A seção Visão geral detalhada contém uma tabela:

Um exemplo de preenchimento de uma tabela:

Gostaríamos de saber sobre os relatórios que você gostou na Highload Siberia 2019, bem como sobre sua experiência na condução de retrospectivas.