
A tradução do artigo foi preparada para os alunos do curso "MS SQL Server Developer"
Os bancos de dados relacionais são um dos bancos de dados mais usados até hoje e, portanto, são necessárias habilidades SQL para a maioria das postagens. Neste artigo, com perguntas sobre SQL das entrevistas, apresentarei as perguntas mais frequentes sobre SQL (Structured Query Language - Structured Query Language - Structured Query Language). Este artigo é um guia ideal para explorar todos os conceitos relacionados ao SQL, Oracle, MS SQL Server e banco de dados MySQL.
Nosso artigo de perguntas sobre SQL é um recurso universal com o qual você pode acelerar a preparação para uma entrevista. Consiste em um conjunto de 65 das perguntas mais comuns que um entrevistador pode fazer durante uma entrevista. Geralmente começa com perguntas básicas de SQL e depois passa para as mais complexas, com base na discussão e nas suas respostas. Essas perguntas da entrevista SQL ajudarão você a maximizar seus benefícios em vários níveis de entendimento.
Vamos começar!
Perguntas da entrevista SQL
Pergunta 1. Qual é a diferença entre DELETE e TRUNCATE?
Não. Pergunta 2. Quais são os subconjuntos do SQL?
- DDL (Data Definition Language) - permite executar várias operações com o banco de dados, como CREATE (criar), ALTER (alterar) e DROP (excluir objetos).
- DML (Data Manipulation Language) - permite acessar e manipular dados, por exemplo, inserir, atualizar, excluir e recuperar dados de um banco de dados.
- DCL (Data Control Language) - permite controlar o acesso ao banco de dados. Um exemplo é GRANT (conceder direitos), REVOKE (revogar direitos).
Pergunta 3. O que se entende por DBMS? Que tipos de DBMS existem?
Banco de dados é uma coleta de dados estruturada. Sistema de Gerenciamento de Banco de Dados (DBMS) - software que interage com o usuário, aplicativos e o próprio banco de dados para coletar e analisar dados. O DBMS permite ao usuário interagir com o banco de dados. Os dados armazenados no banco de dados podem ser modificados, recuperados e excluídos. Eles podem ser de qualquer tipo, como seqüências de caracteres, números, imagens etc.
Existem dois tipos de DBMS:
- Sistema de gerenciamento de banco de dados relacional: os dados são armazenados em relacionamentos (tabelas). Um exemplo é o MySQL.
- Sistema de gerenciamento de banco de dados não relacional: não há conceito de relações, tuplas e atributos. Um exemplo é o Mongo.
Pergunta 4. O que se entende por tabela e campo no SQL?
Uma tabela é um conjunto de dados organizado na forma de linhas e colunas. Um campo é uma coluna em uma tabela. Por exemplo:
Tabela: Student_Information
Campo: Stu_Id, Stu_Name, Stu_Marks
Pergunta 5. O que são junções no SQL?
O operador JOIN é usado para unir linhas de duas ou mais tabelas com base em uma coluna conectada entre elas. É usado para juntar duas tabelas ou obter dados a partir daí. Existem 4 tipos de conexão no SQL, a saber:
- Junção interna
- Right Join
- Junção esquerda
- Junção completa
Pergunta 6. Qual é a diferença entre os tipos de dados CHAR e VARCHAR no SQL?
Char e Varchar servem como tipos de dados de caracteres, mas varchar é usado para cadeias de caracteres de comprimento variável, enquanto Char é usado para cadeias de comprimento fixo. Por exemplo, char (10) pode armazenar apenas 10 caracteres e não pode armazenar uma sequência de qualquer outro comprimento, enquanto varchar (10) pode armazenar uma sequência de qualquer tamanho até 10, ou seja, por exemplo, 6, 8 ou 2.
Pergunta 7. O que é uma chave primária?

- Uma chave primária é uma coluna ou conjunto de colunas que identifica exclusivamente cada linha de uma tabela.
- Identifica exclusivamente uma linha em uma tabela
- Valores nulos não permitidos
_Exemplo: na tabela Student Stu, a chave primária é.
Pergunta 8. O que são restrições?
Restrições são usadas para indicar restrições no tipo de dados de uma tabela. Eles podem ser especificados ao criar ou modificar uma tabela. Restrições de exemplo:
- NÃO NULO
- VERIFICAR
- PADRÃO
- UNIQUE
- CHAVE PRIMÁRIA
- CHAVE ESTRANGEIRA
Pergunta 9. Qual é a diferença entre SQL e MySQL?
SQL é a linguagem de consulta estruturada padrão, baseada na língua inglesa, enquanto o MySQL é um sistema de gerenciamento de banco de dados. SQL é uma linguagem de banco de dados relacional usada para acessar e gerenciar dados, MySQL é um DBMS relacional (sistema de gerenciamento de banco de dados), bem como SQL Server, Informix, etc.
Pergunta 10. O que é uma chave exclusiva?
- Identifica exclusivamente uma linha em uma tabela.
- Muitas chaves exclusivas são permitidas em uma tabela.
- Valores NULL são permitidos ( nota de tradução: depende do DBMS; no SQL Server, NULL pode ser adicionado apenas uma vez em um campo com UNIQUE KEY ).
Pergunta 11. O que é uma chave estrangeira?
- Uma chave estrangeira mantém a integridade referencial fornecendo um link entre os dados em duas tabelas.
- A chave estrangeira na tabela filho refere-se à chave primária na tabela pai.
- Uma restrição de chave estrangeira impede ações que quebram os relacionamentos entre as tabelas filho e pai.
Pergunta 12. O que se entende por integridade de dados?
A integridade dos dados determina a precisão e a consistência dos dados armazenados no banco de dados. Ele também define restrições de integridade para aplicar regras de negócios aos dados quando eles são inseridos em um aplicativo ou banco de dados.
Pergunta 13. Qual é a diferença entre índices clusterizados e não clusterizados no SQL?
- Diferenças entre índices agrupados e não agrupados no SQL:
Um índice clusterizado é usado para recuperar dados de um banco de dados de maneira fácil e rápida, enquanto a leitura de um índice não clusterizado é relativamente mais lenta. - Um índice em cluster altera a maneira como os registros são armazenados no banco de dados - classifica as linhas pela coluna definida como o índice em cluster, enquanto em um índice não em cluster não altera o método de armazenamento, mas cria um objeto separado dentro da tabela que aponta para as linhas da tabela original durante a pesquisa.
- Uma tabela pode ter apenas um índice em cluster, enquanto pode ter muitos índices não clusterizados.
Pergunta 14. Escreva uma consulta SQL para exibir a data atual.
O SQL possui uma função interna GetDate () que ajuda a retornar a data / hora atual.
Pergunta 15. Liste os tipos de conexões
Existem vários tipos de junções usadas para extrair dados entre tabelas. Basicamente, eles são divididos em quatro tipos, a saber:
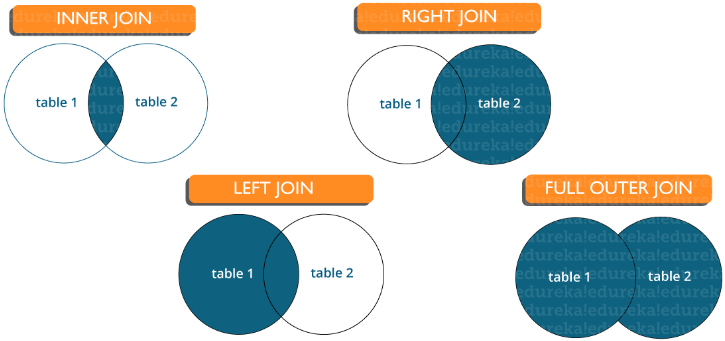
Junção interna : No MySQL, o tipo mais comum. É usado para retornar todas as linhas de várias tabelas para as quais a condição de junção é atendida.
Associação Esquerda : no MySQL, é usado para retornar todas as linhas da tabela esquerda (primeira) e apenas as linhas correspondentes da tabela direita (segunda) para as quais a condição de associação é atendida.
Junta Direita : no MySQL, é usado para retornar todas as linhas da tabela da direita (segunda) e apenas as linhas correspondentes da tabela da esquerda (primeira) para as quais a condição de junção é atendida.
Junção completa : retorna todos os registros para os quais há uma correspondência em qualquer uma das tabelas. Portanto, ele retorna todas as linhas da tabela esquerda e todas as linhas da tabela direita.
Pergunta 16. O que você quer dizer com desnormalização?
A desnormalização é uma técnica usada para converter de formas normais superiores para inferiores. Ajuda os desenvolvedores de banco de dados a melhorar o desempenho de toda a infraestrutura, introduzindo redundância na tabela. Ele adiciona dados redundantes à tabela, dadas as consultas frequentes ao banco de dados que combinam dados de diferentes tabelas em uma tabela.
Pergunta 17. O que são entidades e relacionamentos?
Entidades: uma pessoa, local ou objeto no mundo real, cujos dados podem ser armazenados em um banco de dados. As tabelas armazenam dados que representam um tipo de entidade. Por exemplo, um banco de dados bancário possui uma tabela de clientes para armazenar informações do cliente. A tabela do cliente armazena essas informações como um conjunto de atributos (colunas na tabela) para cada cliente.
Relações: relações ou relacionamentos entre entidades que de alguma forma estão relacionadas entre si. Por exemplo, o nome de um cliente está associado a um número de conta e informações de contato, que podem estar na mesma tabela. Também pode haver relacionamentos entre tabelas individuais (por exemplo, cliente para contas).
Pergunta 18. O que é um índice?
Os índices estão relacionados a um método de ajuste de desempenho que permite a recuperação mais rápida de registros de uma tabela. O índice cria uma estrutura separada para o campo indexado e, portanto, permite uma recuperação mais rápida dos dados.
Pergunta 19. Descreva os diferentes tipos de índices.
Existem três tipos de índices, a saber:
- Índice exclusivo: esse índice evita que o campo tenha valores duplicados se a coluna for indexada exclusivamente. Se uma chave primária for definida, um índice exclusivo poderá ser aplicado automaticamente.
- Índice agrupado: esse índice altera a ordem física da tabela e as pesquisas com base nos valores-chave. Cada tabela pode ter apenas um índice em cluster.
- Índice não clusterizado: não altera a ordem física da tabela e mantém a ordem lógica dos dados. Cada tabela pode ter muitos índices não agrupados em cluster.
Pergunta 20. O que é normalização e quais são suas vantagens?
Normalização é o processo de organização de dados, cujo objetivo é evitar duplicação e redundância. Alguns dos benefícios:
- Melhor organização de banco de dados
- Mais tabelas com pequenas linhas
- Acesso efetivo aos dados
- Maior flexibilidade para consultas
- Pesquisa rápida de informações
- Mais fácil de implementar segurança de dados
- Permite fácil modificação
- Reduza dados redundantes e duplicados
- Banco de dados mais compacto
- Garante a consistência dos dados após as alterações
Pergunta 21. Qual a diferença entre DROP e TRUNCATE?
O comando DROP exclui a tabela em si, e você não pode executar comandos Rollback, enquanto o comando TRUNCATE exclui todas as linhas da tabela ( tradução: observe: no SQL Server, o Rollback normalmente funcionará e reverterá a DROP ).
Pergunta 22. Explique os diferentes tipos de normalização.
Existem muitos níveis consecutivos de normalização. Estas são as chamadas formas normais. Cada forma normal subsequente inclui a anterior. As três primeiras formas normais são geralmente suficientes.
- Primeiro formulário normal (1NF) - sem grupos duplicados nas linhas
- A segunda forma normal (2NF) - cada valor de coluna sem chave (de suporte) depende de toda a chave primária
- Terceira forma normal (3NF) - cada valor não chave depende apenas da chave primária e não depende de outro valor não chave da coluna
Pergunta 23. Qual é a propriedade ACID no banco de dados?
ÁCIDO significa Atomicidade, Consistência, Isolamento, Durabilidade. É usado para fornecer processamento confiável de transações de dados em um sistema de banco de dados.
Atomicidade. Garante que a transação seja totalmente concluída ou falhe, onde a transação representa uma única operação de dados lógicos. Isso significa que, se uma parte de qualquer transação falhar, a transação inteira falhará e o estado do banco de dados permanecerá inalterado.
Coerência. Garante que os dados devem cumprir todas as regras de validação. Simplificando, você pode dizer que sua transação nunca deixará seu banco de dados em um estado inválido.
Isolamento. O principal objetivo do isolamento é controlar o mecanismo de alterações de dados paralelos.
Longevidade. A durabilidade implica que, se a transação foi confirmada (COMMIT), as alterações que ocorreram na transação serão preservadas independentemente do que possa atrapalhar (por exemplo, perda de energia, falha ou erros de qualquer tipo).
Pergunta 24. O que você quer dizer com "gatilho" no SQL?
Um acionador no SQL é um tipo especial de procedimento armazenado projetado para ser executado automaticamente quando ou após a alteração dos dados. Isso permite que você execute um pacote de códigos quando uma inserção, atualização ou qualquer outra consulta é executada em uma tabela específica.
Pergunta 25. Quais instruções estão disponíveis no SQL?
Três tipos de instruções estão disponíveis no SQL, a saber:
- Operadores aritméticos
- Operadores lógicos
- Operadores de comparação
Pergunta 26. Os valores NULL correspondem a zero ou espaço?
NULL não é zero ou espaço. Um valor NULL representa um valor que não está disponível, desconhecido, atribuído ou não aplicável, enquanto zero é um número e espaço é um caractere.
Pergunta 27. Qual é a diferença entre uma junção cruzada e uma junção natural?
Uma junção cruzada cria um produto cruzado ou cartesiano de duas tabelas, enquanto uma junção natural é baseada em todas as colunas que têm o mesmo nome e tipos de dados nas duas tabelas.
Pergunta 28. O que é uma subconsulta no SQL?
Uma subconsulta é uma consulta dentro de outra consulta que define uma consulta para recuperar dados ou informações de um banco de dados. Em uma subconsulta, a consulta externa é chamada de consulta principal, enquanto a consulta interna é chamada de subconsulta. As subconsultas são sempre executadas primeiro e o resultado da subconsulta é passado para a consulta principal. Pode ser aninhado em SELECT, UPDATE ou qualquer outra consulta. Uma subconsulta também pode usar qualquer operador de comparação, como>, <ou =.
Pergunta 29. Quais são os tipos de subconsultas?
Existem dois tipos de subconsultas, a saber: correlacionados e não correlacionados.
- Subconsulta correlacionada: é uma consulta que seleciona dados de uma tabela com um link para uma consulta externa. Não é considerada uma consulta independente porque se refere a outra tabela ou coluna na tabela.
- Subconsulta não correlacionada: essa consulta é uma consulta independente na qual a saída da subconsulta é substituída na consulta principal.
Pergunta 30. Liste as maneiras de obter o número de registros na tabela?
Para contar o número de registros em uma tabela, você pode usar os seguintes comandos:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Vamos publicar outras 35 perguntas com respostas na próxima parte ... Acompanhe as novidades!