
Olá, sou Andrey Shalnev, líder de automação de controle de qualidade no projeto Skyeng Vimbox. Ao longo do ano, eu e a equipe nos empenhamos em otimizar os processos de testes automáticos e agora estamos muito perto de sua etapa final. E esse é um bom motivo para expirar, revisar a lista de pendências e obter alguns resultados intermediários. Para Habra, decidi fazer uma seleção das dez coisas mais úteis e ao mesmo tempo simples que nos ajudaram a lidar com a tarefa de otimizar os autotestes. Espero que o artigo seja útil para as equipes de controle de qualidade em empresas em crescimento, onde os antigos processos de teste não podem mais lidar com a carga e a questão da reorganização está se tornando um problema.
Como organizamos os autotestes
O Vimbox usa Angular para o frontend, então escrevemos testes na pilha bastante clássica para esta solução - Transferidor + Jasmine + JS / Typescript. Ao longo do ano, redesenhamos significativamente o conjunto de testes de regressão. Em sua forma inicial, era redundante e não muito conveniente - testes de várias centenas de linhas com um tempo de passagem de 5 a 10 minutos, com essa duração de um cenário de teste separado, muitas vezes não chega ao fim devido a um arquivo falso. Agora dividimos os testes em cenários mais curtos e mais estáveis, usamos failFast para que o tempo de execução seja aceitável (um teste que trava no meio não tenta concluir cada próxima etapa e aguarda o tempo limite). Além disso, nos livramos das verificações redundantes: garantimos que um recurso específico seja funcional em geral, mas não tentamos verificá-lo em todas as variações possíveis.
Os autotestes são priorizados. Um pequeno conjunto de prioridades - teste de aceitação do usuário (UAT) - é executado a cada hora no produto, após a implantação dos principais projetos e ao testar tarefas em bancadas de teste.
O processo nas bancadas se parece com o seguinte: o desenvolvedor transfere a tarefa para o teste, o controle de qualidade a implanta na bancada e executa os testes - UAT e regressão. No UAT, temos cerca de 150 casos, regressão - cerca de 700 testes, é constantemente atualizado. Na maioria dos casos importantes e críticos, esse conjunto cobre cerca de 80% e é executado a cada iteração.
Ten Life Hacks
Especifique explicitamente a função da instância do navegador . A especificidade dos testes do Vimbox é que, na grande maioria dos casos, são usadas duas ou mais instâncias do navegador, uma vez que a lição tem pelo menos dois lados - um professor e um aluno. Havia um problema: uma instância do navegador era indicada por um número, entendia-se que todos entendiam que o browser1 era um professor e o browser2 e além eram estudantes. Mas nem sempre é esse o caso, aconteceu que o navegador do aluno foi o primeiro. Além disso, existem testes em que os próprios alunos são diferentes - por exemplo, precisamos garantir que você não possa entrar acidentalmente na lição de outra pessoa. Para deixar claro para todos que usuário está em qual instância do navegador, eles começaram a indicar explicitamente a função em seu nome: wrongStudent.browser , wrongStudent.browser , wrongStudent.browser etc. Tem scripts de teste mais legíveis.
Usamos funções de seta: () => , não function() . Em primeiro lugar, esse registro é mais curto. Em segundo lugar, uma sintaxe mais moderna, tentamos nos afastar do arcaico. Terceiro, as funções de seta evitam problemas com o ponteiro this do JavaScript. A função de seta não cria seu escopo lexical ; portanto, é possível fazer referência a algo definido fora this . Livre-se da clássica muleta self = this .
Usamos seqüências de caracteres de modelo em vez de concatenações com vantagens: `Student $ {studentName}`, e não "Student" + studentName . Tentamos usar seqüências de caracteres padrão em vez de concatenações com vantagens.
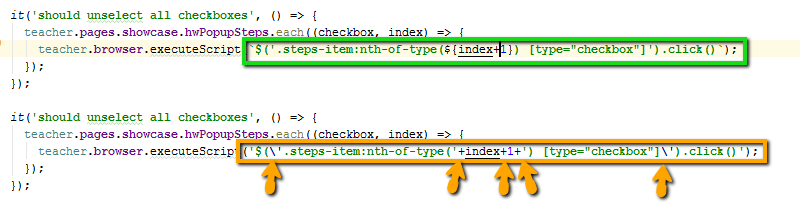
Essa é uma sintaxe moderna, é mais legível. Dentro da string, você pode usar os dois tipos de aspas (simples e duplas) e não escapa a nenhuma delas.
Nós usamos o TypeScript . Principalmente para obter dicas mais adequadas do ambiente de desenvolvimento e navegação normal do código. Agora, na maioria dos casos, em vez de algumas dicas, é possível uma transição direta para o método / campo. Ao mesmo tempo, a mudança para o TypeScript não exigia muita refatoração ao mesmo tempo: para iniciantes, você pode simplesmente alterar as extensões de arquivo de .js para .ts, o projeto permanece viável. Altere gradualmente a sintaxe de require para Import , a navegação é aprimorada.
Divida objetos de página grandes em subclasses para facilitar a manutenção desses objetos. Nossa maior lição de Objeto de Página alcançou quatro mil linhas de código; era difícil folhear, lembre-se do que foi iniciado, do que não foi. Agora, o código mais longo tem cerca de 1300 linhas. Podemos dizer que, ao fazê-lo, nos livramos da classe grande antipadrão. Além disso, eles removeram comentários desnecessários e trabalharam na conveniência e compreensibilidade dos nomes dos métodos: na maioria dos casos, se o método for nomeado de acordo com a convenção, claro para todos, um comentário explicando seu trabalho simplesmente não é necessário.
Executamos o UAT em paralelo em vários threads para facilitar o trabalho com o UAT no prod. O fato é que, conosco, esse teste é executado uma vez por hora e é executado em um thread por 15 minutos. Se ocorrer um arquivo, ele será reiniciado e, no final, funcionará por meia hora. Durante uma implantação, isso pode ser um problema porque a fila está atrasada. O resultado do uso do paralelo é de 2 a 3 minutos no UAT (ou 6 com reinicialização). A fila se move mais rapidamente, informações sobre o problema ou que o arquivo acabou sendo falso chegam mais rapidamente.
Executamos regularmente UAT e regressão em bancos de teste . Cada um de nossos testadores manuais possui seu próprio servidor. Costumávamos executar testes de regressão no prod depois que o testador manual encontrava uma parte significativa dos bugs - na verdade, acabamos de verificar. Agora, executamos autotestes a cada iteração de teste manual da tarefa, o que, em primeiro lugar, facilita o trabalho de um testador manual (ele não precisa perfurar o que é automaticamente) e, em segundo lugar, reduz o ciclo de feedback. Se o desenvolvedor quebrou alguma coisa, ele saberá sobre isso meia hora depois de lançar a tarefa, e não no dia seguinte. Além disso, na bancada de testes, você pode fazer muitas coisas indesejáveis na produção: alterar o número da versão do produto, excluir / adicionar conteúdo do teste, editar sem medo o banco de dados para preparar a situação do teste, etc.
Exclua arquivos vazios . Tentamos manter a consistência entre a estrutura de diretórios nos autotestes e no Testrail. Mas, ao mesmo tempo, em algum momento, encontramos um problema - no Testrail, há um grande número de casos com baixa prioridade (apenas mais de 9000 casos), porque É usado como uma base de conhecimento do projeto. Ao mesmo tempo, apenas cerca de mil dos casos mais importantes são cobertos com autotestes. Se conseguirmos uma combinação perfeita, obteremos um grande número de arquivos e diretórios não utilizados. Isso complica a navegação do projeto e prejudica a compreensão do que realmente está sendo testado. Como resultado, apenas as pastas e arquivos necessários foram deixados, o restante foi excluído.
Corrigimos os erros encontrados . A principal tarefa dos autotestes não é encontrar erros, mas garantir rapidamente que eles não estejam lá, para que algo raramente seja detectado. A fixação resolve dois problemas: em primeiro lugar, vemos estatísticas onde os problemas permanecem com mais freqüência e quais, e em segundo lugar, nos livramos da sensação de que estamos fazendo algo errado. Quando os testes não encontram nada, surge a pergunta: estamos fazendo tudo certo, talvez nossos testes não sejam úteis? E há um tablet mostrando isso quando eles foram capazes de capturar: mais de 60 bugs por ano. Ao mesmo tempo, o significado de executar testes nos servidores prod e test tornou-se óbvio. O lançamento frequente no produto - a cada hora - ajuda a detectar problemas de infraestrutura (um serviço externo não está disponível, nosso servidor foi desativado), o lançamento antes do teste manual detecta falhas introduzidas pelo novo código.
Atributos data-qa-id implementados , por exemplo, [data-qa-id="btn-login"] . Objetivo: seletores mais estáveis. Concordamos com a equipe de desenvolvimento que se você alterar a implementação de alguns elementos, se eles virem o atributo data-qa-id lá, eles entenderão que isso é para autotestes, eles não o alteram e o transferem com precisão. Este atributo tem um nome lógico, que por si só é capaz de dizer por que o elemento é responsável. Além disso, não somos dependentes da implementação específica do elemento - qual ID comum depende dele, qual classe, tag, diferencial, link depende dele. Tornou-se mais calmo: os seletores quebram com menos frequência; em alguns casos, informações adicionais podem ser exibidas com esse atributo. Por exemplo, você precisa do nome de uma etapa de uma lição. Se você observar o nome da etapa no XPath, o seletor poderá ser longo, de vários níveis e de baixa leitura, e se você trabalhar com o modelo html no código Angular, poderá exibir o mesmo nome em um pequeno atributo compreensível, ignorando o XPath longo.
Compartilhe sua vida hacks e pensamentos nos comentários!