
Continuamos a publicar análises das tarefas propostas no campeonato recente. Em seguida, são realizadas tarefas da rodada de qualificação para especialistas em aprendizado de máquina. Esta é a terceira faixa de quatro (back-end, front-end, ML, análises). Os participantes precisavam criar um modelo para corrigir erros de digitação nos textos, propor uma estratégia para jogar em máquinas caça-níqueis, lembrar um sistema de recomendações de conteúdo e compor vários outros programas.
A. Erros de digitação
Condição
(epígrafe) (de um fórum)
- Quem compôs esse absurdo?
Astrofísicos. Eles também são pessoas.
- Você cometeu 10 erros na palavra "jornalistas".
Muitos usuários cometem erros de digitação, alguns por pressionar teclas e outros por causa de analfabetismo. Queremos verificar se o usuário realmente pode ter em mente alguma outra palavra além da que ele digitou.
Mais formalmente, suponha que ocorra o seguinte modelo de erro: o usuário começa com uma palavra que deseja escrever e, posteriormente, comete vários erros. Cada erro é uma substituição de alguma substring da palavra por outra substring. Um erro corresponde à substituição apenas em uma posição (ou seja, se o usuário deseja cometer um único erro pela regra “abc” → “cba”, a partir da cadeia “abcabc” ele pode obter “cbaabc” ou “abccba”). Após cada erro, o processo se repete. A mesma regra pode ser usada várias vezes em etapas diferentes (por exemplo, no exemplo acima, “cbacba” pode ser obtido em duas etapas).
É necessário determinar o número mínimo de erros que um usuário poderia cometer se tivesse em mente uma determinada palavra e escrevesse outra.
Formatos de E / S e exemploFormato de entrada
A primeira linha contém a palavra que, de acordo com nossa suposição, o usuário tinha em mente (consiste em letras do alfabeto latino em letras minúsculas, o comprimento não excede 20).
A segunda linha contém a palavra que ele realmente escreveu (também consiste em letras do alfabeto latino em letras minúsculas, o comprimento não excede 20).
A terceira linha contém um único número N (N <50) - o número de substituições que descrevem vários erros.
As próximas N linhas contêm possíveis substituições no formato & lt "correta" seqüência de letras & gt <espaço> <"incorreta" sequência de letras>. As sequências não têm mais que 6 caracteres.
Formato de saída
É necessário imprimir um número - o número mínimo de erros que o usuário pode cometer. Se esse número exceder 4 ou for impossível obter outro de uma palavra, imprima -1.
Exemplo
Solução
Vamos tentar gerar a partir da ortografia correta todas as palavras possíveis, com no máximo 4 erros. No pior dos casos, pode haver O ((L﹒N)
4 ). Nas limitações do problema, esse é um número bastante grande, portanto, você precisa descobrir como reduzir a complexidade. Em vez disso, você pode usar o algoritmo meet-in-the-middle: gere palavras com não mais que 2 erros, bem como palavras com as quais você pode obter uma palavra escrita pelo usuário com não mais que 2 erros. Observe que o tamanho de cada um desses conjuntos não excederá 10
6 . Se o número de erros cometidos pelo usuário não exceder 4, esses conjuntos se cruzarão. Da mesma forma, podemos verificar se o número de erros não excede 3, 2 e 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
B. Bandido de muitas armas
Condição
Esta é uma tarefa interativa.
Você mesmo não sabe como aconteceu, mas se viu em um salão com máquinas caça-níqueis com um saco inteiro de fichas. Infelizmente, nas bilheterias, eles se recusam a aceitar os tokens de volta e você decidiu tentar a sorte. Existem muitas máquinas caça-níqueis no salão que você pode jogar. Para um jogo com uma slot machine, você usa um token. Em caso de vitória, a máquina oferece um dólar, em caso de perda - nada. Cada máquina tem uma probabilidade fixa de ganhar (que você não conhece), mas é diferente para máquinas diferentes. Tendo estudado o site do fabricante dessas máquinas, você descobriu que a probabilidade de ganhar para cada máquina é selecionada aleatoriamente no estágio de fabricação a partir da
distribuição beta com determinados parâmetros.
Você deseja maximizar seus ganhos esperados.
Formatos de E / S e exemploFormato de entrada
Uma execução pode consistir em vários testes.
Cada teste começa com o fato de seu programa conter dois números inteiros em uma linha, separados por um espaço: o número N é o número de fichas na sua bolsa e M é o número de máquinas na sala (N ≤ 10
4 , M ≤ min (N, 100) ) A próxima linha contém dois números reais α e β (1 ≤ α, β ≤ 10) - os parâmetros da distribuição beta da probabilidade de vitória.
O protocolo de comunicação com o sistema de verificação é o seguinte: você faz exatamente N pedidos. Para cada solicitação, imprima em uma linha separada o número da máquina que você reproduzirá (de 1 a M inclusive). Como resposta, em uma linha separada, haverá "0" ou "1", significando, respectivamente, uma perda e uma vitória em um jogo com o caça-níqueis solicitado.
Após o último teste, em vez dos números N e M, haverá dois zeros.
Formato de saída
A tarefa será considerada concluída se sua decisão não for muito pior que a decisão do júri. Se sua decisão for significativamente pior que a decisão do júri, você receberá o veredicto "resposta errada".
É garantido que, se sua decisão não for pior que a decisão do júri, a probabilidade de receber o veredicto "resposta errada" não excederá
10-6 .
Anotações
Exemplo de interação:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
Solução
Este problema é bem conhecido, poderia ser resolvido de diferentes maneiras. A principal decisão do júri implementou a estratégia de
amostragem Thompson , mas como o número de etapas era conhecido no início do programa, existem estratégias mais ótimas (por exemplo, UCB1). Além disso, pode-se conviver com a estratégia epsilon-gananciosa: com uma certa probabilidade ε toca uma máquina aleatória e com uma probabilidade (1 - ε) toca uma máquina com as melhores estatísticas de vitória.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. Alinhamento das frases
Condição
Uma das tarefas mais importantes para o treinamento de um bom modelo de tradução automática é um bom caso de frases paralelas. Normalmente, a fonte de ofertas paralelas são documentos paralelos. Acontece que, muitas vezes, para construir um certo corpus de frases paralelas, você não precisa saber nada além de seus comprimentos. Em particular, você pode notar que, quanto mais longa a frase no idioma de origem, mais provavelmente será traduzida. Alguma dificuldade reside no fato de que, durante a tradução, o número de frases no texto pode mudar: algumas vezes duas frases adjacentes na tradução podem ser combinadas em uma ou vice-versa - uma frase pode ser dividida em duas. Em alguns casos raros, as frases podem ser omitidas inteiramente em uma tradução ou uma tradução pode aparecer em uma tradução que não estava no original.
Mais formalmente, suponha que o seguinte modelo generativo para gabinetes paralelos seja verdadeiro. Em cada etapa, fazemos um dos seguintes:
1. PareCom probabilidade p
h, a geração dos cascos termina.
2. [1-0] Ignorando ofertasCom probabilidade p
d, atribuímos uma frase ao texto original. Não atribuímos nada à tradução. O comprimento da frase no idioma original L ≥ 1 é selecionado a partir da distribuição discreta:
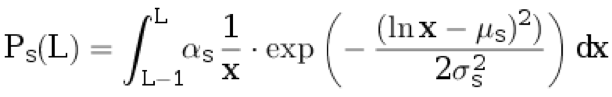
.
Aqui
μ s ,
σ s são os parâmetros de distribuição e
α s é o coeficiente de normalização escolhido para que

.
3. [0-1] Inserir propostaCom probabilidade p
i, atribuímos uma frase à tradução. Não atribuímos nada ao original. O comprimento de uma frase em um idioma de tradução L ≥ 1 é selecionado a partir de uma distribuição discreta:

.
Aqui
μ t ,
σ t são os parâmetros de distribuição e
α t é o coeficiente de normalização escolhido para que

.
4. TraduçãoCom probabilidade (1 - p
d - p
i - p
h ), tomamos o comprimento da sentença no idioma original L
s ≥ 1 da distribuição p
s (com arredondamento para cima). Em seguida, geramos o comprimento da sentença no idioma de tradução L
t ≥ 1 a partir da distribuição discreta condicional:
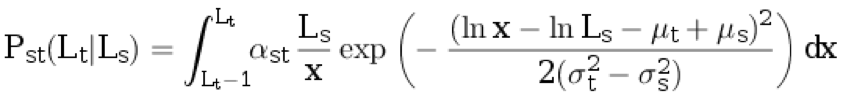
.
Aqui,
α st é o coeficiente de normalização, e os demais parâmetros são descritos nos parágrafos anteriores.
O próximo passo é outro:
1. [2-1] Com probabilidade p
dividida s, a sentença gerada no idioma original se divide em duas não vazias, de modo que o número total de palavras
aumenta exatamente uma . A probabilidade de uma sentença de comprimento L
s se dividir em partes do comprimento L
1 e L
2 (isto é, L
1 + L
2 = L
s + 1) é proporcional a P
s (L
1 ) ⋅ P
s (L
2 ).
2. [1-2] Com probabilidade p
dividida t, a sentença gerada no idioma de destino se divide em duas sentenças não vazias, de modo que o número total de palavras aumenta exatamente uma. A probabilidade de uma sentença de comprimento L
t se dividir em partes do comprimento L1 e L2 (ou seja, L
1 + L
2 = L
t + 1) é proporcional a P
t (L
1 ) ⋅ P
t (L
2 ).
3. 3. [1-1] Com uma probabilidade de (1 - p
dividir s - p
dividir t ), nenhum dos pares de sentenças geradas decairá.
Formatos de E / S, exemplos e notasFormato de entrada
A primeira linha do arquivo contém os parâmetros de distribuição: p
h , p
d , p
i , p
split s , p
split t , μ
s , σ
s , μt, σt. 0,1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s , μ
t ≤ 5.
A próxima linha contém os números N
s e N
t - o número de frases no caso no idioma original e no idioma de destino, respectivamente (1 ≤ N
s , N
t ≤ 1000).
A próxima linha contém N
s inteiros - os comprimentos das frases no idioma original. A próxima linha contém N
t inteiros - os comprimentos das sentenças no idioma de destino.
A próxima linha contém dois números: j e k (1 ≤ j ≤ N
s , 1 ≤ k ≤ N
t ).
Formato de saída
É necessário derivar a probabilidade de que sentenças com índices j e k nos textos sejam respectivamente paralelas (ou seja, geradas em uma etapa do algoritmo e nenhuma delas seja resultado de decaimento).
Sua resposta será aceita se o erro absoluto não exceder 10
–4 .
Exemplo 1
Exemplo 2
Exemplo 3
Anotações
No primeiro exemplo, a sequência inicial de números pode ser obtida de três maneiras:
• Primeiro, com probabilidade p
d adicione uma frase ao texto original, depois com probabilidade p
i adicione uma frase à tradução e, em seguida, com probabilidade p
h termine a geração.
A probabilidade deste evento é P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• Primeiro, com probabilidade p
d adicione uma frase ao texto original, depois com probabilidade p
i adicione uma frase à tradução e, em seguida, com probabilidade p
h termine a geração.
A probabilidade desse evento é igual a P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• Com probabilidade (1 - p
h - p
d - p
i ) gere duas frases, depois com probabilidade (1 - p
split s - p
split t ) deixe tudo como está (ou seja, não divida o original ou a tradução em duas frases) ) e depois com probabilidade p
h terminar a geração.
A probabilidade deste evento é

.
Como resultado, a resposta é calculada como

.
Solução
A tarefa é um caso especial de alinhamento usando modelos de Markov ocultos (alinhamento HMM). A idéia principal é que você possa calcular a probabilidade de gerar um par específico de documentos usando esse modelo e
o algoritmo forward : nesse caso, o estado é um par de prefixos de documentos. Consequentemente, a probabilidade requerida de alinhamento de um par específico de sentenças paralelas pode ser calculada pelo algoritmo de
avanço para trás .
Código #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
D. Fita de recomendações
Condição
Considere um feed de recomendações para conteúdo heterogêneo. Ele mistura objetos de vários tipos (fotos, vídeos, notícias etc.). Esses objetos geralmente são ordenados por relevância para o usuário: quanto mais relevante (interessante) o objeto para o usuário, mais próximo ao topo da lista de recomendações. No entanto, com essa ordem, surgem frequentemente situações em que vários objetos do mesmo tipo aparecem na lista de recomendações. Isso piora bastante a variedade externa de nossas recomendações e, portanto, os usuários não gostam. É necessário implementar um algoritmo que, de acordo com a lista de recomendações, constitua uma nova lista que estará livre desse problema e será mais relevante.
Seja dada uma lista inicial de recomendações a = [a
0 , a
1 , ..., a
n - 1 ] de comprimento n> 0. Um objeto com o número i possui um tipo com o número b
i ∈ {0, ..., m - 1}. Além disso, um objeto sob o número i tem relevância r (a
i ) = 2
−i . Considere a lista que é obtida a partir da inicial escolhendo um subconjunto de objetos e reorganizando-os: x = [a
i 0 , a
i 1 , ..., a
i k - 1 ] de comprimento k (0 ≤ k ≤ n). Uma lista é chamada admissível se não houver dois objetos consecutivos coincidentes no tipo, ou seja, b
i j ≠ b
i j + 1 para todos os j = 0, ..., k - 2. A relevância da lista é calculada pela fórmula
. Você precisa encontrar a lista de relevância máxima entre todas as válidas.
Formatos e exemplos de E / SFormato de entrada
Na primeira linha, os números n e m são escritos com um espaço (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). As próximas n linhas contêm os números b
i para i = 0, ..., n - 1 (0 ≤ b
i ≤ m - 1).
Formato de saída
Anote, com um espaço, os números de objetos na lista final: i
0 , i
1 , ..., i
k - 1 .
Exemplo 1
Exemplo 2
Exemplo 3
Solução
Usando cálculos matemáticos simples, pode ser demonstrado que o problema pode ser resolvido por uma abordagem “gananciosa”, ou seja, na lista ideal de recomendações, cada item tem o objeto mais relevante de todos os que são válidos no mesmo início da lista. A implementação dessa abordagem é simples: pegamos objetos em uma linha e os adicionamos à resposta, se possível. Quando um objeto inválido é encontrado (cujo tipo coincide com o tipo do anterior), o colocamos de lado em uma fila separada, da qual o inserimos na resposta o mais rápido possível. Observe que, a todo momento, todos os objetos nessa fila terão um tipo correspondente. No final, vários objetos podem permanecer na fila, eles não serão mais incluídos na resposta.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. Clusterização de seqüências de caracteres
Existe um alfabeto finito A = {a
1 , a
2 , ..., a
K - 1 , a
K = S}, a
i ∈ {a, b, ..., z}, S é o fim da linha.
Considere o seguinte método para gerar seqüências aleatórias sobre o alfabeto A:
1. O primeiro caractere x
1 é uma variável aleatória com a distribuição P (x
1 = a
i ) = q
i (sabe-se que q
K = 0).
2. Cada caractere seguinte é gerado com base no anterior, de acordo com a distribuição condicional P (x
i = a
j || x
i - 1 = a
l ) = p
jl .
3. Se x
i = S, a geração para e o resultado é x
1 x
2 ... x
i - 1 .
O conjunto de linhas geradas a partir de uma mistura de dois modelos descritos com diferentes parâmetros é dado. É necessário que cada linha forneça o índice da cadeia da qual foi gerada.
Formatos de E / S, exemplo e anotaçõesFormato de entrada
A primeira linha contém dois números 1000 ≤ N ≤ 2000 e 3 ≤ K ≤ 27 - o número de linhas e o tamanho do alfabeto, respectivamente.
A segunda linha contém uma linha que consiste em K - 1 letras minúsculas diferentes do alfabeto latino, indicando os primeiros elementos K - 1 do alfabeto.
Cada uma das N linhas a seguir é gerada de acordo com o algoritmo descrito na condição.
Formato de saída
N linhas, a i-ésima linha contém o número do cluster (0/1) para a sequência na i + 1-ésima linha do arquivo de entrada. A coincidência com a resposta verdadeira deve ser de pelo menos 80%.
Exemplo
Anotações
Nota para o teste da condição: nele, as 50 primeiras linhas são geradas a partir da distribuição
P (x
i = a | x
i - 1 = a) = 0,5, P (x
i = S | x
i - 1 = a) = 0,5, P (x
1 = a) = 1; segundo 50 - da distribuição
P (x
i = b | x
i - 1 = b) = 0,5, P (x
i = S | x
i - 1 = b) = 0,5, P (x
1 = b) = 1.
Solução
O problema é resolvido usando o
algoritmo EM : supõe-se que a amostra apresentada seja gerada a partir de uma mistura de duas cadeias de Markov cujos parâmetros são restaurados durante as iterações. Uma restrição de 80% das respostas corretas é feita para que a correção da solução não seja afetada por exemplos com alta probabilidade nas duas cadeias. Esses exemplos, portanto, quando restaurados adequadamente, podem ser atribuídos a uma cadeia incorreta em termos da resposta gerada.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.