Como você sabe, os índices desempenham um papel importante no DBMS, fornecendo uma pesquisa rápida dos registros necessários. Portanto, é muito importante atendê-los em tempo hábil. Muito material foi escrito sobre análise e otimização, inclusive na Internet. Por exemplo, uma revisão recente deste tópico foi feita
nesta publicação .
Existem muitas soluções gratuitas e pagas para isso. Por exemplo, existe uma
solução pronta
para uso com base em um método de otimização de índice adaptável.
Em seguida, considere o utilitário
SQLIndexManager gratuito, de autoria de
AlanDenton .
A principal diferença técnica entre o SQLIndexManager e vários outros análogos é feita pelo próprio autor
aqui e
aqui .
No mesmo artigo, examinamos o projeto e as possibilidades de uso desta solução de software.
Discuta este utilitário
aqui .
Com o tempo, a maioria dos comentários e bugs foram corrigidos.
Então, agora vamos ao próprio utilitário SQLIndexManager.
O aplicativo é escrito em C # .NET Framework 4.5 no Visual Studio 2017 e usa o DevExpress para formulários:
e fica assim:
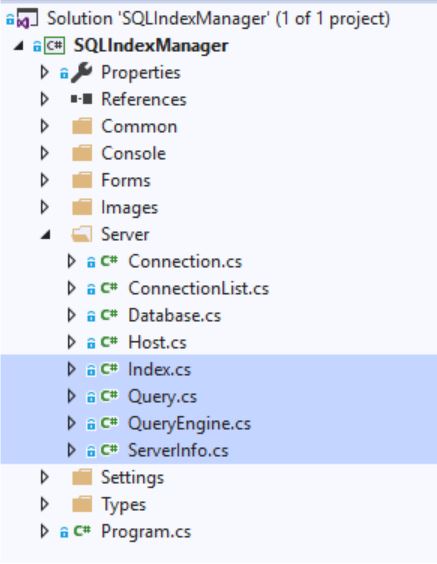
Todas as solicitações são geradas nos seguintes arquivos:
- Índice
- Consulta
- Queryengine
- ServerInfo
Ao conectar-se ao banco de dados e enviar solicitações ao DBMS, o aplicativo é assinado da seguinte maneira:
ApplicationName=”SQLIndexManager”
Quando o aplicativo é iniciado, uma janela modal é aberta para adicionar uma conexão:
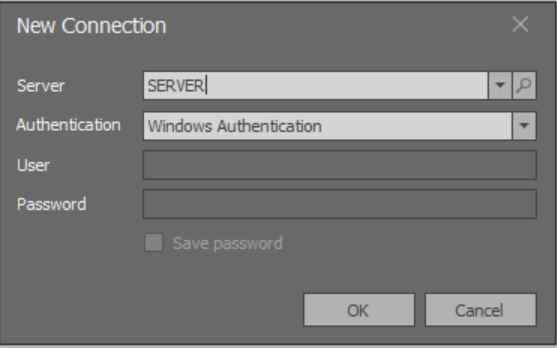
Aqui, o carregamento da lista completa de todas as instâncias do MS SQL Server disponíveis em redes locais ainda não funciona.
Você também pode adicionar uma conexão usando o botão mais à esquerda no menu principal:
Em seguida, as seguintes consultas DBMS serão iniciadas:
Obtendo informações do DBMS SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
Obtendo uma lista de bancos de dados disponíveis com suas breves propriedades SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
Após a execução dos scripts acima, aparece uma janela contendo informações breves sobre os bancos de dados da instância selecionada do MS SQL Server:
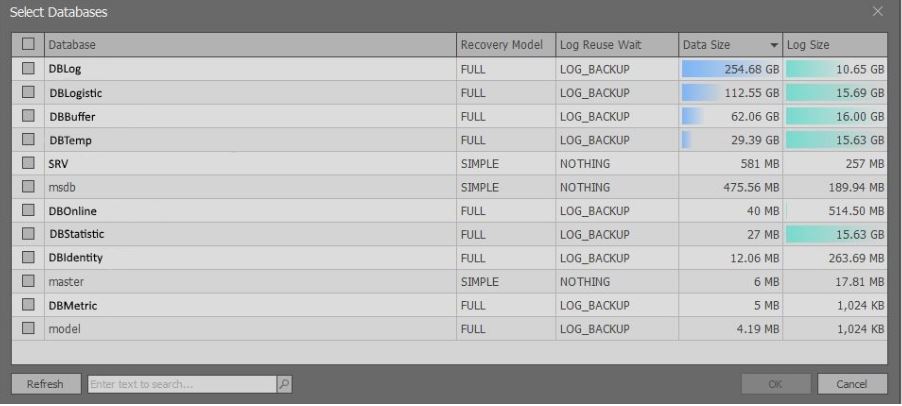
Vale ressaltar que as informações estendidas são exibidas com base nos direitos. Se houver
sysadmin , você poderá selecionar dados na
visualização sys.master_files . Se não houver tais direitos, menos dados serão retornados para não retardar a solicitação.
Aqui você precisa selecionar o banco de dados de interesse e clicar no botão "OK".
Em seguida, o seguinte script será executado para cada banco de dados selecionado para analisar o status dos índices:
Análise de Status do Índice declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
Como você pode ver pelas próprias consultas, tabelas temporárias são frequentemente usadas. Isso é feito para que não haja recompilação e, no caso de um esquema grande, o plano pode ser gerado paralelamente ao inserir dados, pois a inserção com variáveis de tabela é possível em apenas um fluxo.
Depois de executar o script acima, uma janela com a tabela de índice aparecerá:

Aqui você também pode exibir outras informações detalhadas, como:
- um banco de dados
- número de seções
- data e hora da última chamada
- compressão
- grupo de arquivos
etc.
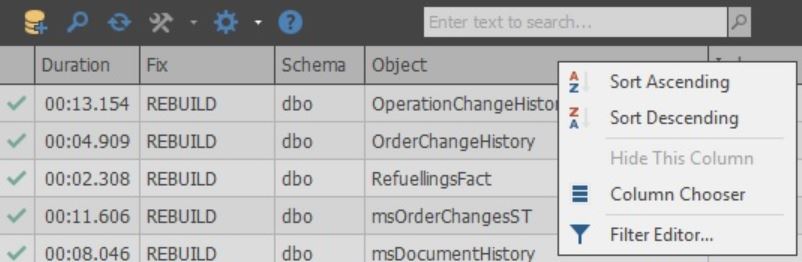
As próprias colunas podem ser personalizadas:
Nas células da coluna Correção, você pode escolher qual ação será executada durante a otimização. Além disso, quando a verificação é concluída, a ação padrão é selecionada com base nas configurações selecionadas:
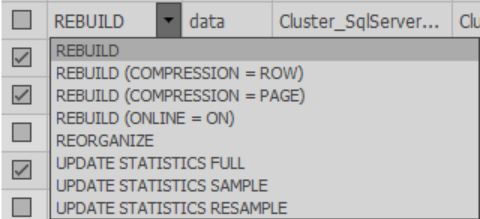
Você deve selecionar os índices desejados para processamento.
Usando o menu principal, você pode salvar o script (o mesmo botão inicia o processo de otimização de índice):
salve a tabela em diferentes formatos (o mesmo botão permite abrir configurações detalhadas para análise e otimização de índices):

Além disso, as informações podem ser atualizadas clicando no terceiro botão à esquerda no menu principal ao lado da lupa.
Um botão com uma lupa permite selecionar o banco de dados desejado para consideração.
Atualmente, não existe um sistema de ajuda completo. Portanto, pressionando o botão "?" simplesmente causará o aparecimento de uma janela modal contendo informações básicas sobre o produto de software:
Além de todas as opções acima, o menu principal possui uma barra de pesquisa:

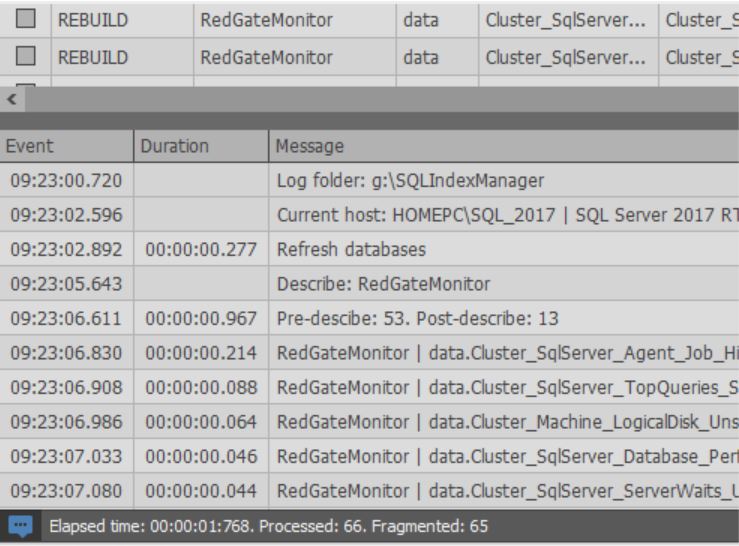
Ao iniciar o processo de otimização de índice:

Também na parte inferior da janela, você pode ver o log das ações executadas:
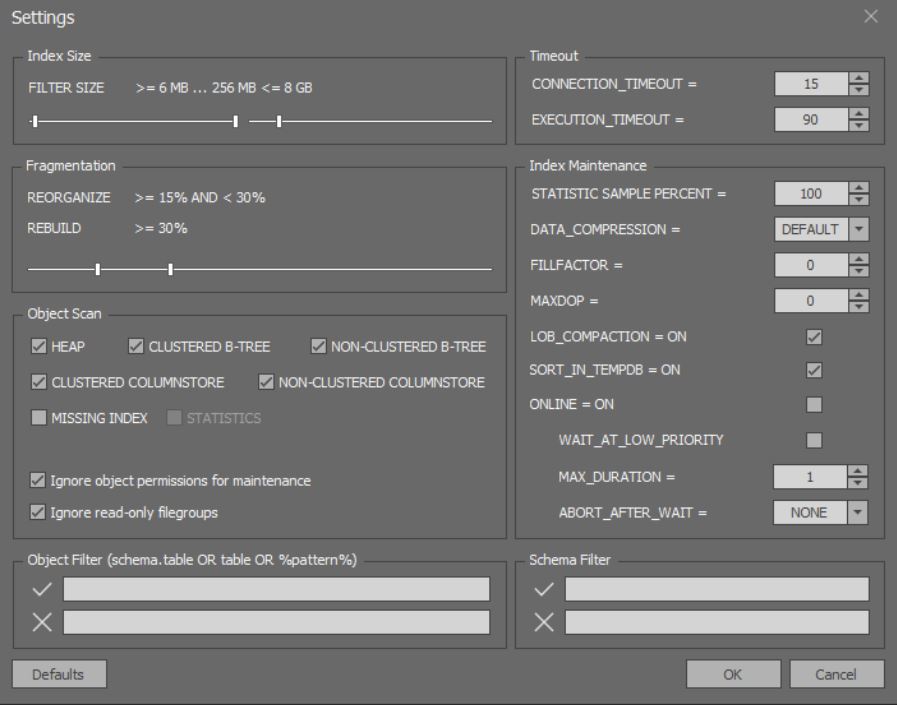
Na janela para análise detalhada e otimização de índices, você pode configurar opções mais sutis:
 Sugestões para a aplicação:
Sugestões para a aplicação:- possibilitar a atualização seletiva de estatísticas, não apenas para índices, mas também de maneiras diferentes (atualização completa ou parcial)
- possibilita não apenas selecionar o banco de dados, mas também servidores diferentes (isso é muito conveniente quando há muitas instâncias do MS SQL Server)
- para maior flexibilidade no uso, propõe-se agrupar comandos nas bibliotecas e enviá-los para os comandos do PowerShell, como é feito, por exemplo, aqui: dbatools.io/commands
- possibilitar salvar e alterar configurações pessoais para todo o aplicativo e, se necessário, para cada instância do MS SQL Server e cada banco de dados
- das cláusulas 2 e 4, segue-se o desejo de criar grupos em bancos de dados e grupos em instâncias do MS SQL Server, cujas configurações sejam as mesmas
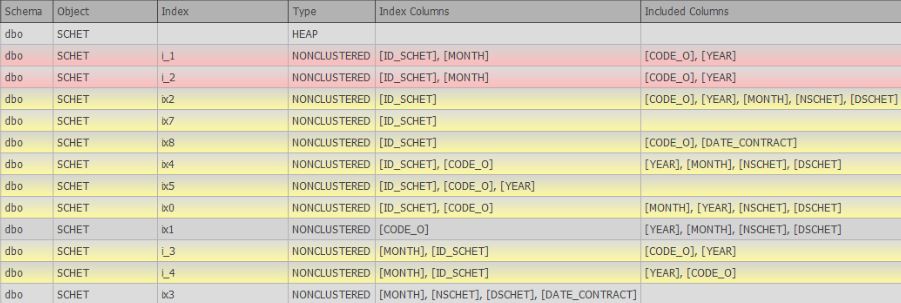
- procure por índices duplicados (completos e incompletos, que diferem ligeiramente ou diferem apenas nas colunas incluídas)
- Como SQLIndexManager é usado apenas para o DBMS do MS SQL Server, é necessário refletir isso no nome, por exemplo, da seguinte maneira: SQLIndexManager para MS SQL Server
- Remova todas as partes do aplicativo da GUI em módulos separados e reescreva-os no .NET Core 2.1
No momento da redação deste artigo, o artigo 6 dos desejos está sendo desenvolvido ativamente e já existe suporte na forma de uma busca por duplicatas completas e similares:
Fontes