O artigo fornece código para gerar relatórios regulares sobre o estado das unidades de armazenamento EMC VNX com abordagens alternativas e histórico de criação.
Tentei escrever código com os comentários mais detalhados e um arquivo. Substitua apenas suas senhas. O formato dos dados de origem também é indicado; portanto, ficarei feliz se alguém tentar aplicá-los em casa.
Antecedentes
Você pode pular se não for interessante de onde as "pernas crescem".
Temos um data center. Não existem sistemas de armazenamento muito novos. Existem muitos sistemas de armazenamento, falhas de disco também. Várias vezes por semana, as pessoas vão ao data center e trocam de unidade no sistema de armazenamento. A decisão de substituir os discos é tomada após um alarme do sistema " Substituição recomendada do disco ".
Nada fora do comum.

Porém, recentemente, LUNs individuais coletados nesses sistemas de armazenamento e apresentados ao ambiente virtual começaram a se degradar seriamente. Após a comunicação com o suporte técnico do fornecedor, ficou claro que os discos já devem ser alterados não apenas quando a mensagem de alarme acima aparecer, mas também quando um grande número de outras mensagens aparecer que o sistema não considera erros críticos.
O monitoramento SNMP por esses sistemas de armazenamento não é suportado. Você precisa usar um software proprietário caro (não o temos) ou o utilitário de console NaviSECCli , que precisa ser conectado a cada controlador (existem dois deles) de cada sistema de armazenamento, mas isso não era muito desejável.
Decidiu-se automatizar a coleta de logs e procurar erros neles. E a decisão de substituir os discos deve ser deixada para os engenheiros responsáveis, com base nos resultados da análise do relatório.
Primeiros passos
Inicialmente, um dos meus colegas escreveu o código do PowerShell que fez o seguinte:
- Tomou uma tabela de entrada que continha os endereços IP dos controladores de armazenamento;
- o ciclo foi para os endereços IP dos controladores A , depois para os endereços IP dos controladores B ;
- no processo, os entrevistou adicionalmente para obter números de série de discos;
- processou todas as linhas dos logs e filtrou o conteúdo das mensagens procuradas;
- criou um objeto do PowerShell e em suas propriedades analisou os dados necessários das linhas obtidas acima;
- mesclou todos os objetos resultantes em uma tabela que foi emitida na forma de csv.
O código está abaixo. Imediatamente faça uma reserva de que ele está trabalhando, mas introduzimos uma solução alternativa.
Fonte do PowerShellcd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
Tudo estava bem, tudo o que restava era adicionar um "brilho" na forma de envio automático de uma carta aos colegas interessados e formatação mínima do csv resultante. Mas (!) Todo esse problema funcionou por muito tempo. Os dados de um mês, por exemplo, foram coletados em cerca de 45 minutos , o que não era muito adequado, pois além dos relatórios regulares, eu queria fazer uma análise para o ano atual, que seria um período muito longo. Mas "rejeitar - oferecer". Eles começaram a pensar.

Obviamente, você precisa otimizar o código e ativar a computação paralela. No PowerShell , não obtivemos sucesso em mais de 5 threads simultâneos usando o fluxo de trabalho e ainda não "fumamos" métodos alternativos. Por isso, foi decidido tentar mudar a lógica do script para R. O utilitário NaviSECCli , que pode ser executado no R , faz o levantamento do armazenamento no código-fonte, de modo que a solução é bastante adequada.
Diz-se - alguns dias - pronto!
Decidimos que, na saída, eu gostaria de receber um boletim diário contendo o número total de erros no texto da carta, algum tipo de cronograma para o número de acidentes (para que houvesse algo para mostrar à gerência) e também um anexo na forma de uma tabela xlsx. Determinamos que na tabela eu quero ter três guias:
- Dados de acidentes por 3 dias, por tipo de disco e acidente
- Uma guia semelhante, mas por 30 dias
- Dados brutos (se alguém quiser executá-los no Excel)
Algoritmo de script
1. Baixe do csv os dados disponíveis nos controladores;
2. executar um ciclo paralelo na computação paralela para todos os controladores, procurando registros das mensagens de alarme necessárias;
3. combinar os resultados em um quadro de dados;
4. faça processamento e conversão de dados;
5. gerar documento xlsx;
6. formamos o cronograma que salvamos em png;
7. formar uma carta contendo os dados coletados;
8. envie uma carta.
Vamos analisar os pontos do algoritmo
1. Faça o download dos dados disponíveis nos controladores do csv
Formato da tabela de origem com parâmetros do VNX Para coletar informações de emergência, é necessário conectar-se em série aos dois controladores ( colunas A e newB ) usando o software EMC especializado - NaviCLI com determinadas chaves.
Por conveniência, reformatamos a tabela resultante após o carregamento, para que os endereços IP dos dois controladores fiquem na mesma coluna, para que você possa fazer um ciclo na lista e não dois consecutivos. Fazemos isso usando a função de coleta . Os problemas de trabalhar com formatos de dados "verticais" ou "horizontais" são muito bem descritos na documentação oficial da biblioteca tidyverse . Você pode ler aqui .
Lemos os dados usando a função read_csv2 , também determinamos manualmente os tipos de colunas através do parâmetro adicional col_types . Essa é uma boa prática, pois acelera bastante o carregamento. No nosso caso, isso não é tão importante, porque O csv original contém menos de 100 linhas, mas nos acostumamos a escrever corretamente.
Na saída, obtemos um quadro de dados (as novas colunas são cntName e cntIP ):
2-3. Executamos cálculos paralelos em um ciclo para todos os controladores com uma busca por registros das mensagens de alarme necessárias. Combine os resultados em um quadro de dados
Em seguida é o mais interessante. Computação paralela .
Em R, existem várias (e até muitas) opções para computação paralela. Gostei mais do link das bibliotecas foreach e doParallel . Você pode ler sobre eles e outras opções de computação paralela em R aqui .
Em resumo, damos apenas 3 etapas :
Etapa 1 Registrar kernels esmeralda pura CPU para trabalhar em computação paralela via registerDoParallel (no nosso caso, primeiro detectamos o número de núcleos no caso)
Registrar núcleos da CPU numCores <- detectCores() registerDoParallel(numCores)
Etapa 2 Iniciamos o ciclo através do foreach (não se esqueça de especificar o operador % dopar% para que o ciclo seja paralelo e indicar, através do parâmetro .combine, a maneira como coletaremos o resultado). No nosso caso .combine = rbind , porque na saída de cada loop teremos um quadro de dados .
Código de recuperação da tabela de erros Etapa 3 Limpamos o cluster de paralelismo criado por meio de stopImplicitCluster ()
Um pouco mais de detalhes sobre como obter uma tabela legível a partir do texto de erro bruto
No formato de texto, os erros são os seguintes:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
Aqui temos valores separados por um espaço, que, à primeira vista, mesmo em csv será inserido normalmente. Mas não é tão simples. A complexidade da análise aqui é a seguinte:
- data e hora também são separadas por um espaço (o menor dos males);
- o texto do erro consiste em "palavras", ou seja, também separado por um espaço;
- por algum motivo, não há espaço entre o número do disco e o código de erro (que está entre colchetes).
Em geral, um paraíso para os amantes de expressões regulares :)

Não vou analisar, porque é uma questão de gosto, mas vou esclarecer que o texto do erro teve que ser dividido, pois os valores localizados entre o parêntese de fechamento do número do erro e o colchete de abertura de algum outro valor. Em um loop, essa é a variável de erros .
Também é um ponto interessante que, para a conveniência de formar o quadro de dados final, nós, desejando percorrer os endereços IP dos controladores, configuramos a sequência não através da coluna com os endereços IP dos controladores (ou seja, i = VNX_ip $ cntIP ), mas através do número da linha (ou seja, e. i = 1: nrow (VNX_ip) ). Isso nos permite, ao formar um quadro de dados com erros já analisados, adicionar o número do cluster e o nome do armazenamento por meio das chamadas VNX_ip $ cl [i] e VNX_ip $ Name [i] respectivamente. Sem isso, as junções teriam que ser feitas, o que seria mais lento e pior no código.
No final, obtemos um quadro de dados (para ser sincero, depois mexer , mas a diferença está além do escopo do artigo), que contém todos os dados de que precisamos. I.e. em qual sistema de armazenamento, em qual disco, quando que erro ocorreu.
Vista final Quadro de dados O mais inteligente é que todo o ciclo de pesquisa paralela de todos os sistemas de armazenamento não leva 30 minutos, mas 30 segundos .
Graças a Deus que esse não é o caso quando 30 segundos são muito rápidos.

Vale esclarecer que o código do PowerShell também coletou os números de série de discos de todos os sistemas de armazenamento em um ciclo e, no momento de reescrever o código no R, esses dados eram redundantes. Portanto, a comparação do tempo de execução não é totalmente honesta, mas ainda é impressionante.
A conversão de dados para documentos xlsx foi reduzida para filtrar a tabela de origem nos últimos 3 dias, bem como no último mês e converter as colunas com os nomes de erro no formato "horizontal", para que cada tipo de erro estivesse em uma coluna separada. Uma função separada foi gravada para isso (para não duplicar as mesmas etapas duas vezes)
Função de filtragem de fonte myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
Para exibir os tipos de erros em uma coluna separada, a função de dispersão foi aplicada com o preenchimento de chave adicional = 0 , com o qual os valores ausentes foram preenchidos com 0 . Sem essa chave, se em algum dia não houvesse algum tipo de erro, a coluna correspondente teria valores de NA .
Além disso, na função, eu queria manter a capacidade de passar o nome da coluna para classificação como variável, mas ao mesmo tempo ter valores padrão para essa variável. Para isso, é usada a sintaxe peculiar dplyr , sobre a qual você pode ler mais aqui .
No nosso caso, ao definir os parâmetros de uma função, definimos um deles para o valor padrão e o cotamos ( orderColname = quo (Soft_Media_Error) ) e, em seguida, quando chamado, coloca caracteres à sua frente !! para organizar (desc (!! orderColname)) .
A aparência da tabela com erros para o mês Analisei a formação do documento xlsx no artigo sobre relatórios sobre o estado da VM , por isso não vou me deter em detalhes. Todo o código é fornecido no final do artigo.

Aqui estão alguns recursos importantes que aumentam a legibilidade do relatório:
- Guias assinadas (por padrão, a mais interessante é aberta);
- Nomes de colunas destacados
- Formatação automática de todas as colunas para que todo o texto seja legível sem a necessidade de expandir as colunas.
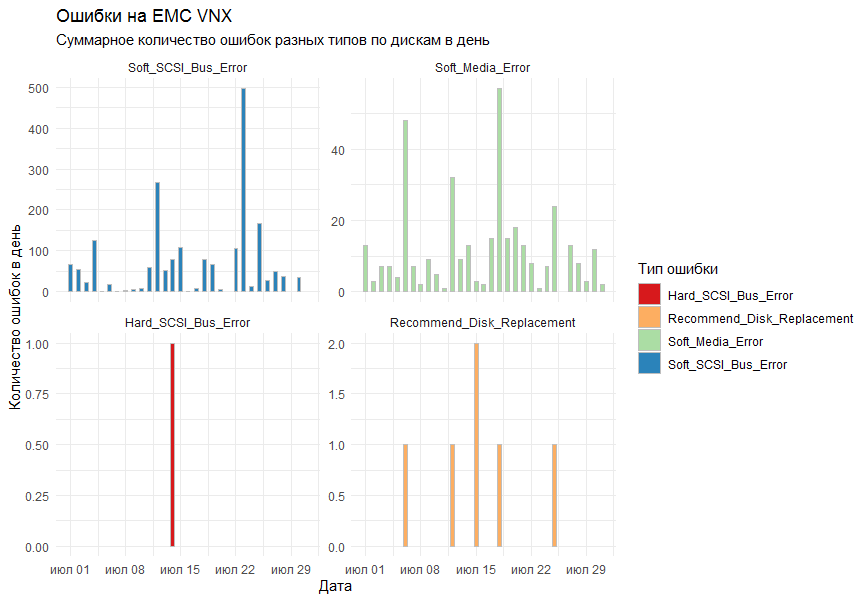
No gráfico, eu queria obter o número total de erros por dia para todos os sistemas de armazenamento por tipo. Como ferramenta de desenho, foi decidido usar a biblioteca ggplot2 padrão.
A primeira versão do gráfico mostrou todos os erros em um gráfico e ficou assim:

Os colegas disseram que ficou ilegível.
O que eles entenderiam? !!!!
Os comentários foram levados em consideração e a função facet_grid foi adicionada às colunas padrão ( geom_bar ) para dividir o resultado em gráficos separados, de acordo com os tipos de erro.
O resultado final foi adequado a todos.

Preparação de dados, representação gráfica, salvamento em arquivo Do interessante na formação do cronograma.
Eu queria que os gráficos estivessem em uma determinada ordem. Para isso, o parâmetro da formação de linhas no facet_grid teve que ser transferido como um fator, ou melhor, como um fator ordenado . O fator é um formato de dados tão astuto em R, que é um conjunto de valores (no nosso caso, seqüências de caracteres, ou seja, caracteres ), e o conjunto desses valores é estritamente definido (chamado de níveis de fator), e mesmo esses níveis são classificados. Parece complicado, mas tudo se encaixa se você disser que os nomes dos meses são um ótimo exemplo de um fator ordenado. I.e. sabemos que nomes os meses podem ter e também sabemos (bem, espero) que primeiro venha janeiro, depois fevereiro, depois março, etc. É no mesmo princípio que criamos um fator.
A formação e envio de cartas, bem como a formação de tarefas no agendador do Windows também foram consideradas no artigo sobre relatórios sobre o estado da VM . Simplesmente colocamos algumas variáveis no texto e formatamos mais ou menos claramente. Não esqueça o anexo.
Conclusões
O R provou mais uma vez ser uma ferramenta universal para executar tarefas diárias e visualizar seus resultados. E com a computação paralela ativada, essa ferramenta também se torna rápida.
A prática também mostrou que o PowerShell é extremamente lento ao analisar logs e convertê-los em um formato legível.
Muito obrigado a todos que leram tantas cartas até o fim.
Código completo do aplicativo
Código de aplicativo R completo - : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3