Breve artigo sobre mineração de processos de negócios no contexto de crescente interesse no conceito de "gêmeo digital". Devido ao surgimento periódico deste tópico, considero apropriado compartilhar abordagens da solução.
Declaração do problema
A situação é extremamente simples.
- Existe a empresa X (Y, Z, ...).
- A empresa possui processos de negócios automatizados por vários sistemas de TI.
- Existem analistas de negócios que desenharam diagramas de bpmn para esses processos. Mais especificamente, sua própria "idéia bpmn" de como esses processos deveriam ter sido.
- Os usuários corporativos desejam ter algum tipo de representação (KPI) desses processos.
Como chegar à verdade e contar essas métricas?
É uma continuação de publicações anteriores .
Postulados básicos:
- Existe um log de eventos temporário (vários logs de sistemas de TI, cdr \ xdr, apenas registros de eventos no banco de dados) com vários graus de pureza, integridade e consistência.
- Os sistemas de TI atuam como uma máquina de estados e “andam” entre diferentes estados, de acordo com as ações dos usuários e a lógica de negócios estabelecida pelos programadores neles.
- A interação do usuário é realizada de forma transacional.
Correções do mundo físico:
- O número de alterações feitas no sistema de TI é tal que os diagramas bpmn dos analistas de negócios quase nada têm a ver com a realidade.
- Os dados podem ser muito desestruturados (por exemplo, logs de aplicativos).
- "Transacional" é um conceito lógico. Os próprios registros de eventos contêm apenas atributos inerentes a esse estado e não há identificador de transação de ponta a ponta.
- O número de registros por dia é de dezenas, centenas, milhares de milhões de peças .
Solução Set-Count
Para resolver esses problemas, é necessário:
- Reconstruir transações
- Reconstrua processos de negócios reais
- faça cálculos;
- gerar resultados em formato legível por humanos.
Você pode começar a procurar soluções de fornecedores e pagar milhões. Mas temos a R. nas mãos e nos permite resolver esse problema perfeitamente. Breves considerações abaixo.
Tudo parece simples e o R possui um bom conjunto consistente de pacotes bupaR . Mas uma mosca na pomada está presente e envenena tudo. Esse conjunto em um tempo aceitável pode lidar apenas com um pequeno número de eventos (centenas de milhares - vários milhões).
Para grandes volumes, outras abordagens devem ser usadas.
Adicione velocidade!
Emular um conjunto de dados de entrada
Para demonstrar idéias, é necessário formar algum tipo de conjunto de dados de teste. Vamos dar um exemplo de uma cadeia federal de lojas como fonte física de um modelo matemático. Felizmente, isso é compreensível para todos. Embora com o mesmo sucesso, podem ser caixas eletrônicos, call centers, transporte público, abastecimento de água, etc.
- Existem lojas de vários tamanhos (pequenos, médios e grandes).
- Nas lojas existem balcões de caixa (terminais POS).
- Os números das lojas podem ser alfanuméricos; os números dos terminais podem ser digitais.
- Os compradores vão às lojas e compram algo enquanto pagam com um cartão.
- A interação do terminal POS com o cartão e o banco é descrita por um determinado conjunto de estados e pelas regras para a transição entre eles.
- As transações são bem-sucedidas, malsucedidas, adiadas e incompletas (o banco não está disponível, por exemplo).
- As transações têm tempos limite.
Tome o seguinte conjunto de padrões de transações comerciais:
"INIT-REQUEST-RESPONSE-SUCCESS" "INIT-REQUEST-RESPONSE-ERROR" "INIT-REQUEST-RESPONSE-DEFFERED" "INIT-REQUEST" "INIT"
Para demonstrar a abordagem, criaremos uma pequena amostra, mas tudo funcionará bem em bilhões de registros (para um volume sem otimização super profunda, o tempo característico é medido em apenas centenas de segundos em um único servidor com desempenho muito medíocre).
Spoilers diretos para grandes volumes:
- em muitos lugares,
tidyverse significa que tidyverse não pode obter uma resposta; - otimizar até microsteps é útil e pode dar uma contribuição significativa.
Código de simulação de amostra library(tidyverse) library(datapasta) library(tictoc) library(data.table) library(stringi) library(anytime) library(rTRNG) data.table::setDTthreads(0) # data.table data.table::getDTthreads() # set.seed(46572) RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1) # -- -, # 5 -, 2 -- bo_pattern <- tibble::tribble( # , , ~pattern, ~prob, ~mean_duration, "INIT-REQUEST-RESPONSE-SUCCESS", 0.7, 5, "INIT-REQUEST-RESPONSE-ERROR", 0.15, 5, "INIT-REQUEST-RESPONSE-DEFFERED", 0.07, 8, "INIT-REQUEST", 0.05, 2, "INIT", 0.03, 0.5 ) # + checkmate::assertTRUE(sum(bo_pattern$prob) == 1) df <- bo_pattern %>% separate_rows(pattern) %>% # mutate(coeff = sum(prob)) %>% group_by(pattern) %>% # summarise(event_prob = sum(prob/coeff)*100) %>% ungroup() checkmate::assertTRUE(sum(df$event_prob) == 100) # 3 : (4 ), (12 ), (30 ) df1 <- tribble( ~type, ~n_pos, ~n_store, "small", 4, 10, "medium", 12, 5, "large", 30, 2 ) %>% # mutate(store = map2(row_number(), n_store, ~sample(x = .x * 1000 + 1:.y, size = .y, replace = FALSE))) %>% unnest(store) %>% # mutate(pos = map(n_pos, ~sample(x = .x, size = .x, replace = FALSE))) %>% unnest(pos) %>% mutate(pattern = sample(bo_pattern$pattern, n(), replace = TRUE, prob = bo_pattern$prob)) tic("Generate transactions") # , # , df2 <- df1 %>% # select(-matches("duration")) %>% left_join(bo_pattern, by = "pattern") %>% # sample_frac(size = 200, replace = TRUE) %>% mutate(duration = rnorm(n(), mean = mean_duration, sd = mean_duration * .25)) %>% select(-prob, -mean_duration) %>% # , > # 30 filter(duration > 0.5 & duration < 30) %>% # POS mutate(session_id = row_number()) %>% # , separate_rows(pattern) %>% rename(event = pattern) toc() tic("Generate time markers, data.table way") samples_tbl <- data.table::as.data.table(df2) %>% # setkey(session_id, duration, physical = FALSE) %>% # # 1- , , 5 # .[, ticks := base::sort(runif(.N, 5, 5 + duration)), by = .(session_id, duration)] %>% # match.arg base::order!! # # 0 1 # # .[, tshift := runif(.N, 0, 1)] %>% # trng ( ) # , .[, trand := runif_trng(.N, 0, 1, parallelGrain = 100L) * duration] %>% # , # .[, ticks := sort(tshift), by = .(session_id)] %>% # , session_id, , .[, t_idx := session_id + trand / max(trand)/10] %>% # # session_id . .[, tshift := (sort(t_idx) - session_id) * 10 * max(trand)] %>% # , POS (60 ) .[event == "INIT", tshift := tshift + runif_trng(.N, 0, 60, parallelGrain = 100L)] %>% # .[, `:=`(duration = NULL, trand = NULL, t_idx = NULL, n_store = NULL, n_pos = NULL, timestamp = as.numeric(anytime("2019-03-11 08:00:00 MSK")))] %>% # , 01.03.2019 .[, timestamp := timestamp + cumsum(tshift), by = .(store, pos)] %>% # .[timestamp <= as.numeric(anytime("2019-04-11 23:00:00 MSK")), ] %>% # .[, timestamp := anytime(timestamp, tz = "Europe/Moscow")] %>% as_tibble() %>% select(store, pos, event, timestamp, session_id) toc()
Para a pureza do experimento, deixamos apenas os parâmetros significativos e misturamos tudo. Na vida real, ainda é necessário jogar aleatoriamente parte dos fragmentos (possivelmente em blocos de tempo separados), simulando assim perdas no recebimento de dados.
# log_tbl <- samples_tbl %>% select(store, pos, state = event, timestamp_msk = timestamp) %>% sample_n(n()) # log_tbl %>% mutate(timegroup = lubridate::ceiling_date(timestamp_msk, unit = "10 mins")) %>% ggplot(aes(timegroup)) + # geom_bar(width = 0.7*600) + geom_bar(colour = "white", size = 1.3) + theme_bw()
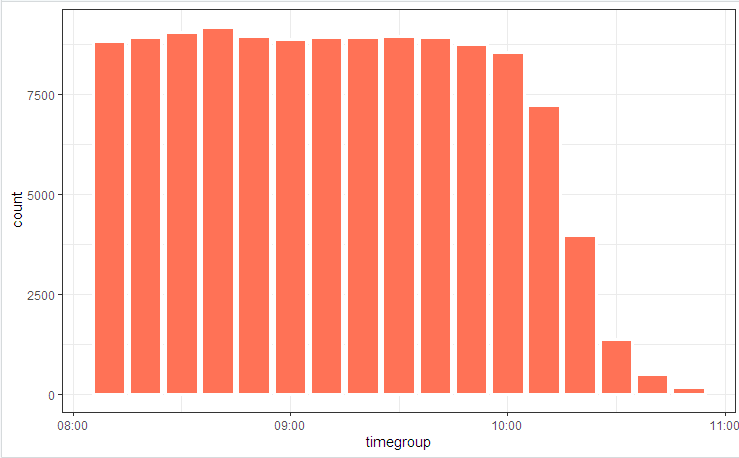
Ilustramos o diagrama do processo com uma figura

e distribuição estadual

Pequenas flutuações são devidas ao fato de a tabela ser considerada no início (incluída no código) e o bupaR::process_map funcionou no final quando alguns dos dados gerados aleatoriamente que não se encaixavam nas restrições integrais foram cortados pelos elementos de filtragem.
Reconstrução de Transações
A primeira coisa que geralmente é oferecida quando você precisa coletar / desmontar / comparar séries temporais é agrupamentos e ciclos de comparação. Em demonstrações com 100 entradas, essa caminhada funcionará, mas milhões de listas não. Para lidar com essa tarefa, você precisa localizar os pontos de perda de tempo (loops internos, alocações intermediárias de memória e cópia) e tentar eliminá-los ao mínimo.
Como resultado, esse problema pode ser reduzido para dez linhas.
código de reconstrução de transações clean_dt <- as.data.table(log_tbl) %>% # INIT .[, start := (state == "INIT")] %>% # session_id , # .[, event_date := lubridate::as_date(timestamp_msk)] %>% .[, date_str := format(.BY[[1]], "%y%m%d"), by = event_date] %>% # # timestamp_msk setorder(store, pos, timestamp_msk) %>% # -- .[, session_id := paste(date_str, store, pos, cumsum(start), sep = "_")] %>% # ( 30 ) # .[, time_shift := timestamp_msk - shift(timestamp_msk), by = .(store, pos)] %>% # , INIT .[, time_locf := cummax(as.numeric(timestamp_msk) * as.numeric(start)), by = .(store, pos)] %>% .[, time_shift := as.numeric(timestamp_msk) - time_locf] %>% # , 30 .[, lost_chain := time_shift > 30] %>% # .[, time_shift := as.numeric(!start) * as.numeric(timestamp_msk - shift(timestamp_msk, fill = 0))] %>% # INIT # .[, time_accu := cumsum(time_shift)] %>% .[, date_str := NULL] # # tidyverse , dt <- as.data.table(clean_dt) %>% # !!! .[lost_chain != TRUE] %>% # 1- .[order(timestamp_msk, store, pos)] %>% .[, bp_pattern := stri_join(state, collapse = "-"), by = session_id] # as_tibble(dt) %>% distinct(session_id, bp_pattern) %>% count(session_id, sort = TRUE)
Em alguns segundos, temos uma imagem reconstruída dos processos de negócios.
E (quem pensaria !!!), na verdade, os processos de negócios automatizados nos sistemas de TI funcionam de maneira um pouco diferente (ou nem um pouco), pois os analistas de negócios convenceram a todos. As maravilhas e argumentos dos "proprietários do processo" acompanharão o estudo da figura final.
Aplique ativamente truques
Quando a velocidade de computação se torna uma quantidade importante, escrever um código de trabalho não é suficiente. É necessário prestar atenção a todos os níveis. Há também vários truques algorítmicos que podem reduzir significativamente o tempo de execução.
Em particular, nesta tarefa, podemos mencionar o seguinte:
- Para o processamento principal, apenas
data.table (velocidade, trabalho em links), + contabilizando a otimização de consultas internas. POSIXct pode conter milissegundos (embora não seja exibido normalmente, mas pode ser corrigido usando as options(digits.secs=X) ), nós os options(digits.secs=X) lá, será mais fácil comparar e classificar.- Evite a classificação física dentro de grupos! Uma única classificação física de todo o vetor garante a classificação dos dados em grupos.
- Evite calcular dentro de grupos. Tentamos fazer tudo o que é possível nos dados de origem (aplicamos vetorização, reduzimos as faturas para chamadas de função).
- Usamos um tempo limite de transação para lidar com intervalos de tempo.
- Os métodos locf (Última observação realizada) são lentos. Para transferir propriedades em uma linha do tempo, use
cumsum , cummax . - Operações demoradas, como POSIX -> conversão de cadeias, pesquisa regular etc. Não o fazemos elemento a elemento, mas em convoluções. As despesas gerais na indexação interna e no agrupamento do campo convertido são incomparavelmente menores.
- Utilizamos ativamente multithreading (incluindo dentro de pacotes).
- Não negligencie a microoptimização. Por exemplo,
stri_c é várias vezes mais rápido que paste0 .
# 1 log <- getLog(fileName) bench::mark( paste0 = paste0(log$value, collapse = "\n"), stringi = stri_c(log$value, collapse = "\n") ) # # A tibble: 2 x 13 # expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time # <bch:expr> <bch:> <bch:> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> # 1 paste0 58ms 59.1ms 16.9 496KB 0 9 0 533ms # 2 stringi 16.9ms 17.5ms 57.1 0B 0 29 0 508ms
Post anterior - Faca suíça de processamento json .