Imagine uma situação típica no primeiro ano: você leu
sobre o algoritmo Dinits , implementou-o, mas não funcionou e não sabe o porquê. A solução padrão é iniciar a depuração em etapas, sempre desenhando o estado atual do gráfico em um pedaço de papel, mas isso é extremamente inconveniente. Tentei corrigir a situação como parte de um projeto de semestre em Engenharia de Software e, em um post, vou contar como acabei com um plug-in para o Visual Studio. Você pode fazer o download
aqui , o código fonte e a documentação podem ser encontrados
aqui . Aqui está uma captura de tela do gráfico obtido para o algoritmo Dinits.
Sobre mim
Meu nome é Olga, me formei no terceiro ano da direção "Matemática Aplicada e Ciência da Computação" no HSE de São Petersburgo com um diploma em Engenharia de Software. Antes de entrar na universidade, eu não estava envolvido em programação.
Pesquisa: requisitos
No nosso corpo docente, trabalha no trabalho de pesquisa semestral. Geralmente isso acontece assim: no início do semestre, ocorre uma apresentação de trabalhos de pesquisa - representantes de diferentes empresas oferecem vários projetos. Em seguida, os alunos escolhem seus projetos favoritos, os supervisores escolhem seus alunos favoritos e assim por diante. No final, todo aluno encontra um projeto para si mesmo.
Mas há outra maneira: você pode encontrar de forma independente um supervisor e um projeto e, em seguida, convencer o curador de que esse projeto pode realmente ser um P&D completo. Para fazer isso, prove que:
- Você vai fazer algo novo. Obviamente, o projeto pode ter análogos, mas sua opção deve ter algumas vantagens sobre eles.
- A tarefa deve ser bastante difícil, ou seja, o trabalho que deve haver por um semestre e não por um dia. Ao mesmo tempo, é necessário que o projeto seja realmente realizado em um semestre.
- Seu projeto deve ser útil para o mundo. Ou seja, quando perguntado por que isso é necessário, você não deve responder: "Bem, eu preciso fazer algum tipo de pesquisa".
Eu escolhi o segundo caminho. A primeira coisa a fazer depois que concordei com o supervisor foi encontrar o tópico do projeto. A lista de idéias incluía: verificador de estilo de código para Lua, um depurador que permite calcular expressões em partes e uma ferramenta para olimpíadas / treinamento em programação, que permite visualizar o que está acontecendo no código. Ou seja, um visualizador para estruturas de dados arbitrárias combinadas com um depurador. Por exemplo, uma pessoa escreve uma
árvore cartesiana e, no processo, vértices, arestas, o vértice atual e assim por diante são desenhados. No final, decidi me debruçar sobre essa opção.
Plano de trabalho do projeto
Meu trabalho no projeto consistiu nas seguintes etapas:
- O estudo da área de estudo foi necessário para entender se esse problema já havia sido resolvido (o tópico do projeto teria que ser alterado), quais são seus análogos, quais são suas vantagens e desvantagens, que eu poderia levar em consideração no meu trabalho.
- Definir a funcionalidade específica que a ferramenta criada possuirá. O tema do projeto foi declarado de maneira bastante abstrata, e isso foi necessário para garantir que a tarefa seja bastante complicada, mas, ao mesmo tempo, pode ser concluída em um semestre.
- A criação de uma interface do usuário protótipo foi necessária para demonstrar como a ferramenta criada pode ser usada. Acrescentou ainda mais especificidade do que um conjunto de recursos descritos por palavras.
- Escolha de dependências - você precisa entender como tudo será organizado do ponto de vista do desenvolvedor e decidir sobre as ferramentas que serão usadas no processo de escrever código.
- Criando um protótipo (prova de conceito) , ou seja, um exemplo mínimo no qual a maioria seria codificada. Com este exemplo, eu tive que lidar com todas as ferramentas que iria usar e também aprender como resolver todas as dificuldades que surgiram ao longo do caminho, para que a versão final já estivesse escrita "limpa".
- Trabalhe na parte de conteúdo , ou seja, no desenvolvimento e implementação da lógica da ferramenta.
- A proteção do projeto é necessária para poder falar rapidamente sobre o trabalho realizado e dar a oportunidade de avaliá-lo a todos, mesmo às pessoas que não remexem no assunto. É um treinamento antes da formatura. Ao mesmo tempo, um projeto bem elaborado não garante que o relatório seja bom, pois exige outras habilidades, por exemplo, a capacidade de falar com o público.
Sempre realizei planejamento com meu supervisor. Também sempre tínhamos ideias e discutíamos todas as idéias que surgiram ao longo do caminho. Além disso, o supervisor me deu conselhos sobre o código e ajudou no gerenciamento do tempo. Sobre todos os problemas técnicos (bugs incompreensíveis etc.) também sempre relatei, mas na maioria das vezes consegui resolvê-los pessoalmente.
Pesquisa de assunto
Para começar, nossa liderança deveria estar convencida de que esse tópico merece ser meu trabalho de pesquisa. E para começar do primeiro ponto: a busca por análogos.
Como se viu, existem muitos análogos. Mas a maioria deles foi projetada para visualização da memória. Ou seja, eles teriam feito um ótimo trabalho com a visualização da árvore cartesiana, mas não conseguem entender que a
pilha na matriz não deve ser desenhada como uma matriz, mas como uma árvore. Entre esses análogos estavam
gdbgui ,
Data Display Debugger , um plug-in para o Eclipse
jGRASP e um plug-in para o Visual Studio
Data Structures Visualizer . O último também foi criado para os problemas de programação das olimpíadas, mas conseguiu visualizar apenas estruturas de dados nos ponteiros.
Havia mais algumas ferramentas:
Algojammer para python (e queríamos vantagens, como a linguagem mais popular entre as olimpíadas) e a ferramenta
Lens , desenvolvida em 1994. O último, a julgar pela descrição, fez quase o necessário, mas, infelizmente, foi criado no Sun OS 4.1.3 (um sistema operacional de 1992). Portanto, apesar da disponibilidade de códigos-fonte, foi decidido não perder tempo com essa arqueologia dúbia.
Então, depois de algumas pesquisas, verificou-se que Tula, que faria exatamente o que queríamos, e ao mesmo tempo trabalhava em máquinas modernas, ainda não está na natureza.
Definição de funcionalidade
O segundo passo foi provar que esta tarefa é bastante complicada, mas factível. Para isso, foi necessário propor algo mais específico do que "quero uma imagem bonita e que tudo fique claro imediatamente".
Neste projeto, decidimos nos concentrar apenas na visualização de gráficos: existem muitos algoritmos em gráficos que podem ser implementados de maneiras diferentes e, mesmo que restritos, a tarefa ainda permanece não trivial.
Também é mais ou menos óbvio que a ferramenta deve, de alguma forma, ser integrada ao depurador. Precisamos ser capazes de visualizar os valores de variáveis e expressões e desenhar uma imagem final desses valores.
Depois disso, foi necessário criar uma determinada linguagem que nos permitisse construir um gráfico de acordo com o estado atual do programa da maneira que desejamos. Além do próprio gráfico, era necessário fornecer a capacidade de alterar a cor dos vértices e arestas, adicionar rótulos arbitrários a eles e alterar outras propriedades. Nesse sentido, a primeira ideia foi:
- Determine o que temos vértices, por exemplo, números de 0 a n.
- Determine a presença de uma aresta entre os vértices usando a condição booleana. Nesse caso, as arestas são de tipos diferentes e cada tipo tem seu próprio conjunto de propriedades.
- Além disso, podemos definir propriedades de vértices, como cores, também usando a condição booleana.
- Siga as etapas com o depurador: todas as expressões são calculadas, todas as condições são verificadas e, dependendo disso, um gráfico é desenhado.
Prototipagem da interface do usuário
Eu desenhei o protótipo da interface do usuário no
NinjaMock . Isso foi necessário para entender melhor a aparência da interface do ponto de vista do usuário e quais ações ele precisará executar. Se houvesse problemas com o protótipo, entenderíamos que existem algumas inconsistências lógicas, e essa ideia deve ser descartada. Por fidelidade, peguei alguns algoritmos. A figura abaixo mostra exemplos de como imaginei as configurações de visualização do
DFS e
o algoritmo de Floyd .
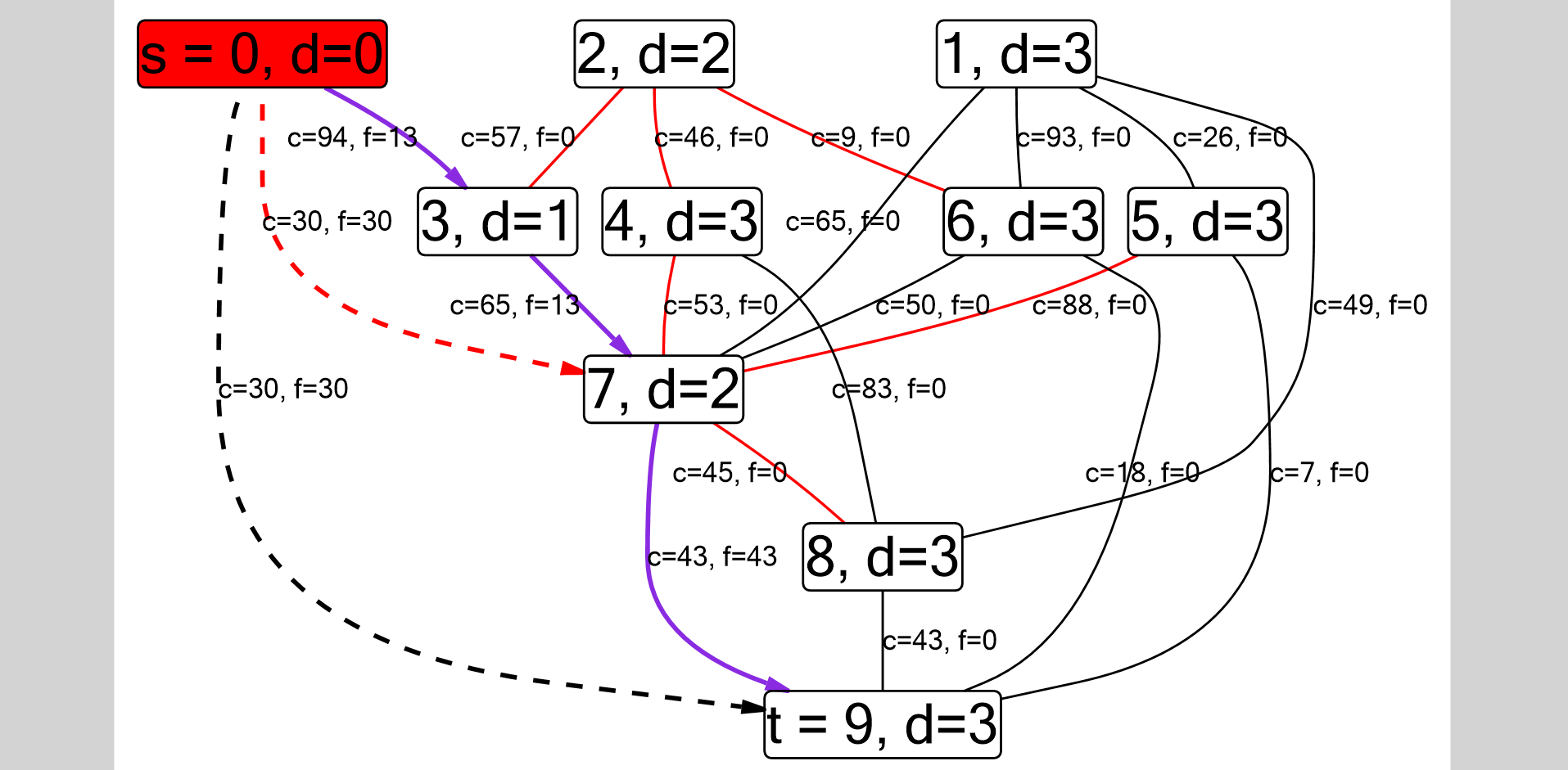
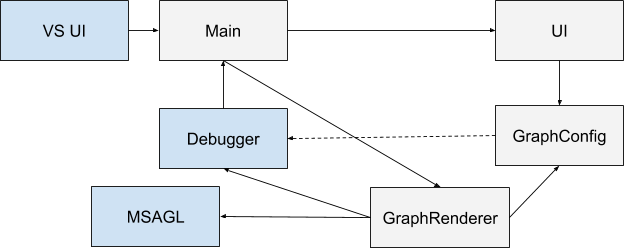
 Como eu imaginei configurações para o DFS. O gráfico é armazenado como uma lista de adjacência; portanto, a aresta entre os vértices
Como eu imaginei configurações para o DFS. O gráfico é armazenado como uma lista de adjacência; portanto, a aresta entre os vértices g[i].find() != g[i].end() é determinada pela condição g[i].find() != g[i].end() (de fato, para não duplicar as arestas, é necessário verificar se i <= j ) O caminho DFS é mostrado separadamente: p[j] == i . Essas arestas serão orientadas.
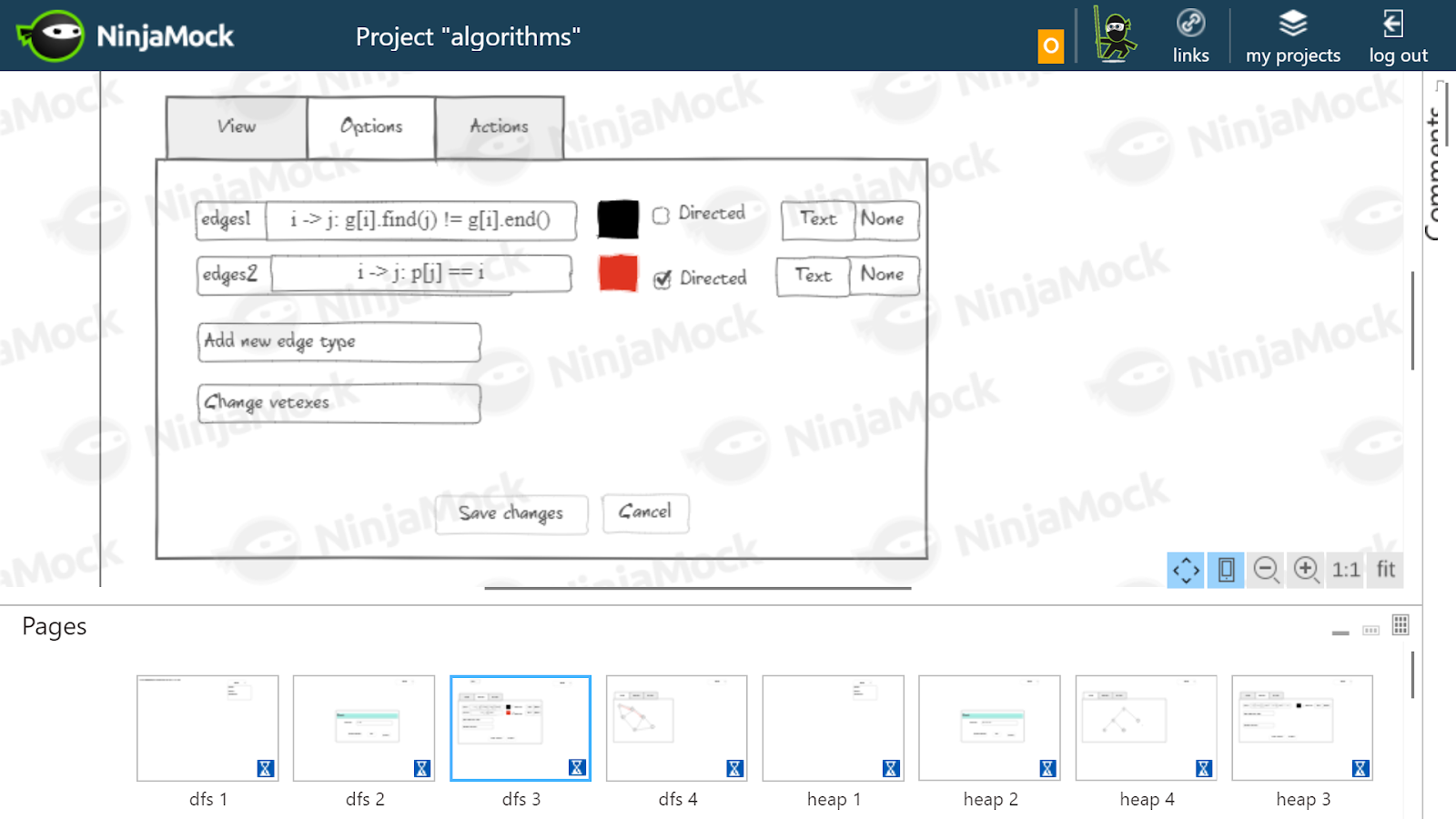
Eu assumi que, para o algoritmo de Floyd, seria necessário desenhar em preto as bordas reais armazenadas na matriz c cinza - os caminhos mais curtos encontrados neste estágio, armazenados na matriz d . Para cada borda e caminho mais curto, seu peso é gravado.Seleção de Dependências
Para o próximo passo, foi necessário entender como fazer tudo isso. Antes de tudo, era necessária a integração com um depurador. A primeira coisa que vem à mente quando a palavra "depurador" é gdb, mas você precisa criar toda a interface gráfica do zero, o que é realmente difícil para um aluno fazer em um semestre. A segunda idéia óbvia é criar um plugin para algum ambiente de desenvolvimento existente. Como opções, considerei o QTCreator, o CLion e o Visual Studio.
A opção CLion foi descartada quase imediatamente, porque, em primeiro lugar, fechou o código-fonte e, em segundo lugar, tudo está muito ruim com a documentação (e ninguém precisa de dificuldades adicionais). O QTCreator, diferentemente do Visual Studio, é multiplataforma e de código aberto e, portanto, no início, decidimos nos concentrar nele.
No entanto, o QTCreator está pouco adaptado para extensão usando plugins. O primeiro passo na criação de um plugin para o QTCreator é construir a partir do código-fonte. Levei uma semana e meia. No final, enviei dois relatórios de erros (
aqui e
ali ) sobre o processo de montagem. Sim, esse foi o esforço para criar o QTCreator apenas para descobrir que o depurador no QTCreator não possui uma API pública. Voltei para outra opção, o Visual Studio.
E essa foi a decisão certa: o Visual Studio possui não apenas uma ótima API, mas também uma excelente documentação para ela. A
_debugger.GetExpression(...).Value expressão
_debugger.GetExpression(...).Value simplificada chamando
_debugger.GetExpression(...).Value . O Visual Studio também fornece a capacidade de iterar sobre os quadros e avaliar a expressão no contexto de qualquer um deles. Para fazer isso, altere a propriedade
CurrentStackFrame para a necessária. Você também pode acompanhar as atualizações do concurso do depurador para redesenhar a imagem ao alterar.
Obviamente, não era de se supor que eu estivesse envolvido na visualização de gráficos do zero - existem muitas bibliotecas especiais para isso. O mais famoso deles é o
Graphviz , e planejamos usá-lo primeiro. Mas, para um plug-in do Visual Studio, seria mais lógico usar a biblioteca para C #, já que eu iria escrever nele. Pesquisei um pouco no Google e encontrei a biblioteca
MSAGL : tinha todas as funcionalidades necessárias e tinha uma interface simples e intuitiva.
Prova de conceito
Agora, com um mecanismo para calcular expressões arbitrárias, por um lado, e uma biblioteca para visualizar gráficos, por outro, era necessário fazer um protótipo. O primeiro protótipo foi feito para o DFS, depois o
algoritmo Dinits,
o algoritmo Kuhn , a
busca por componentes duplamente conectados , a árvore cartesiana e o
SNM foram tomados como exemplos. Peguei minhas implementações antigas desses algoritmos do primeiro ao segundo ano, criei um novo plug-in, desenhei um gráfico correspondente a essa tarefa (todos os nomes de variáveis foram codificados permanentemente). Aqui está um exemplo de um gráfico que obtive para o algoritmo Kuhn:
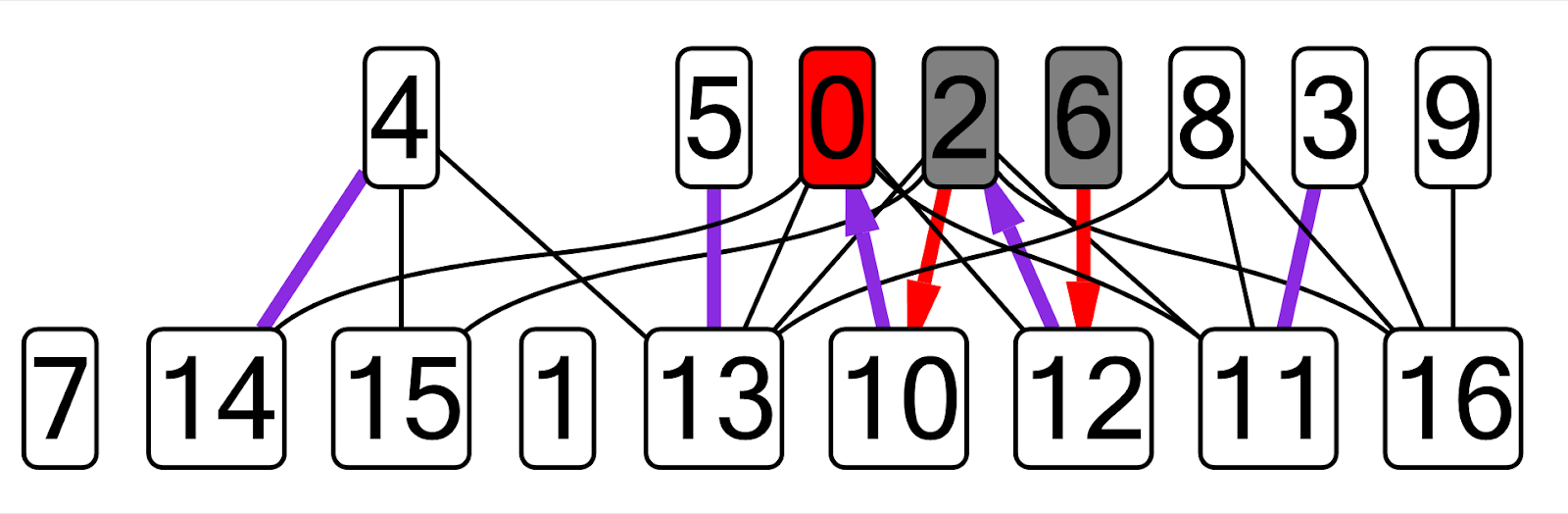 Neste gráfico, as arestas correspondentes atuais são mostradas em roxo, o vértice dfs atual é mostrado em vermelho, os vértices visitados são cinza, as arestas de uma cadeia alternada que não são correspondentes são mostradas em vermelho.
Neste gráfico, as arestas correspondentes atuais são mostradas em roxo, o vértice dfs atual é mostrado em vermelho, os vértices visitados são cinza, as arestas de uma cadeia alternada que não são correspondentes são mostradas em vermelho.Eu considerei permitido modificar ligeiramente o código do algoritmo para facilitar a visualização. Por exemplo, no caso da árvore cartesiana, descobriu-se que é mais fácil adicionar todos os nós criados a um vetor do que ignorar a árvore dentro do plug-in.
Uma descoberta desagradável foi que o depurador no Visual Studio não oferece suporte a métodos e funções de chamada do STL. Isso significava que não era possível verificar a presença de um elemento no contêiner usando
std::find , como originalmente assumido. Esse problema pode ser resolvido criando uma função definida pelo usuário ou duplicando a propriedade "o elemento está contido no contêiner" em uma matriz booleana.
Nos meus plugins de avaliação, aconteceu algo como o seguinte (se o gráfico foi armazenado como uma lista de adjacências):
- Primeiro, vem o loop
for de 0 a _debugger.GetExpression("n").Value , que adicionou todos os vértices ao gráfico, cada um com seu próprio número.
- Existem dois aninhados
for _debugger.GetExpression($"g[{i}].size()").Value , o primeiro para i - de 0 a n , o segundo para j - de 0 a _debugger.GetExpression($"g[{i}].size()").Value e a borda {i, _debugger.GetExpression($"g[{i}][{j}]").Value} .
- Se necessário, algumas informações adicionais foram adicionadas aos rótulos dos vértices e arestas. Por exemplo, o valor da matriz
d , responsável pela distância ao vértice selecionado.
- Se o algoritmo foi baseado em dfs, um loop percorreu todos os quadros e todos os vértices na pilha (
stackFrame.FunctionName.Equals("dfs") && stackFrame.Arguments.Item(1) == v ) foram destacados em cinza.
- Então, para cada
i de 0 a n , denotando o número dos vértices, algumas condições foram verificadas e, se satisfeitas, algumas propriedades foram alteradas no vértice, geralmente na cor.
Naquele momento, escrevi o código "conforme necessário", sem tentar criar um esquema geral para todos os algoritmos, ou escrever o código pelo menos de alguma maneira bonita. A criação de cada novo plug-in começou com a copiar e colar do anterior.
Configuração de gráfico
Após a pesquisa, foi necessário elaborar um esquema geral que pudesse ser aplicado a todos os algoritmos. A primeira coisa que foi introduzida foram os índices dos vértices e arestas. Cada índice possui um nome exclusivo e o intervalo termina, calculado usando
_debugger.GetExpression . Para acessar o valor do índice, use seu nome entre __ (ou seja, __x__). Expressões com locais para substituir valores de índice, bem como o nome da função atual (__CURRENT_FUNCTION__) e os valores de seus argumentos (__ARG1__, __ARG2__, ...), são chamados de modelos.
Os índices são substituídos por cada vértice ou aresta e depois são calculados no depurador. Os modelos foram usados para filtrar alguns valores de índice (se o gráfico for armazenado como a matriz de adjacência
c , os índices serão aeb de 0 a n, e o modelo para validação será
c[__a__][__b__] ). Os limites do intervalo de índices também são modelos, pois podem conter índices anteriores.
Um gráfico pode ter diferentes tipos de vértices e arestas. Por exemplo, no caso de procurar a correspondência máxima em um gráfico bipartido, cada fração pode ser indexada separadamente. Portanto, o conceito de família foi introduzido para vértices e arestas. Para cada família, a indexação e todas as propriedades são determinadas independentemente. Nesse caso, as arestas podem conectar vértices de famílias diferentes.
Você pode atribuir propriedades específicas a uma família de vértices ou arestas que serão aplicadas seletivamente aos elementos da família. A propriedade é aplicada se a condição for atendida. A condição consiste em um modelo que é avaliado como
true ou
false e em uma expressão regular para o nome da função. A condição é verificada apenas para a armação de vidro atual ou para todas as armações de vidro (e, em seguida, é considerada cumprida se for atendida por pelo menos uma).
Propriedades são muito diversas. Para vértices: etiqueta, cor do preenchimento, cor da borda, largura da borda, forma, estilo da borda (por exemplo, linha pontilhada). Para arestas: etiqueta, cor, largura, estilo, orientação (você pode especificar duas setas - do começo ao fim ou vice-versa; nesse caso, pode haver duas setas ao mesmo tempo).
É importante que cada vez que o gráfico seja desenhado do zero, e o estado anterior não seja levado em consideração de forma alguma. Isso pode ser um problema se o gráfico mudar dinamicamente durante o algoritmo - os vértices e as arestas podem mudar drasticamente sua posição e, então, é difícil entender o que está acontecendo.
Uma descrição detalhada da configuração do gráfico pode ser encontrada
aqui .
Interface do usuário
Com a interface, decidi não me incomodar muito. A janela principal com as configurações (
ToolWindow ) contém área de texto para a
configuração serializada em JSON e uma lista de famílias de vértices e arestas. Cada família possui sua própria janela com configurações e cada propriedade da família possui mais uma janela (três níveis de aninhamento são obtidos). O próprio gráfico é desenhado em uma janela separada. Não funcionou para colocá-lo no ToolWindow, então enviei um
relatório de bug aos desenvolvedores do MSAGL, mas eles responderam que esse não era o caso de uso de destino.
Outro relatório de bug foi enviado ao Visual Studio, pois as caixas de texto às vezes pendiam nas janelas de configurações adicionais.
Plugin
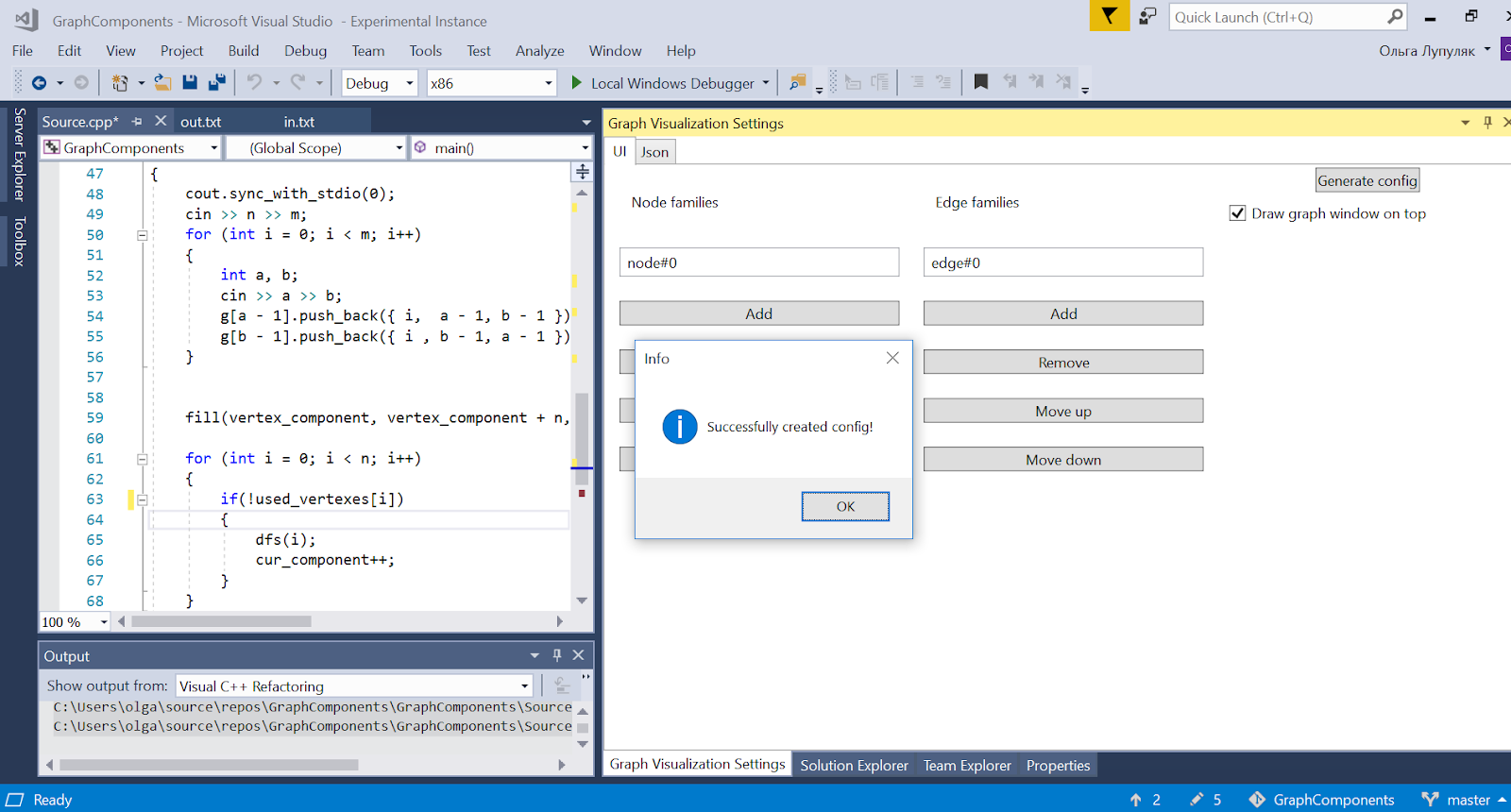
Para configurar o gráfico, o plug-in possui uma interface com o usuário e a capacidade de (des) serializar a configuração no JSON. O esquema geral de interação de todos os componentes é o seguinte:
Azul mostra os componentes que existiam originalmente, cinza - que eu criei. Quando o Visual Studio é iniciado, a extensão é inicializada (aqui o componente principal é designado como Principal). O usuário tem a oportunidade de especificar a configuração por meio da interface. Cada vez que o contexto do depurador é alterado, o componente principal é notificado. Se a configuração for definida e o programa que estiver sendo depurado for executado, o GraphRenderer será iniciado. Ele recebe uma entrada de configuração e, com a ajuda de um depurador, cria um gráfico, que é exibido em uma janela especial.
Exemplos
Como resultado, criei uma ferramenta que permite visualizar algoritmos de gráficos e requer pequenas alterações no código. Foi testado em oito tarefas diferentes. Aqui estão algumas fotos resultantes:
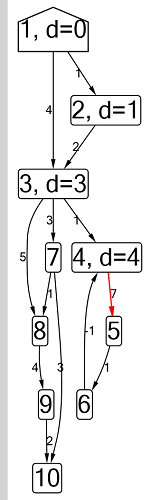 Algoritmo Ford-Bellman : o vértice para o qual contamos os caminhos mais curtos é indicado por uma casa, a menor distância atual encontrada para os vértices é d, vermelho indica a aresta ao longo da qual o relaxamento passa.
Algoritmo Ford-Bellman : o vértice para o qual contamos os caminhos mais curtos é indicado por uma casa, a menor distância atual encontrada para os vértices é d, vermelho indica a aresta ao longo da qual o relaxamento passa.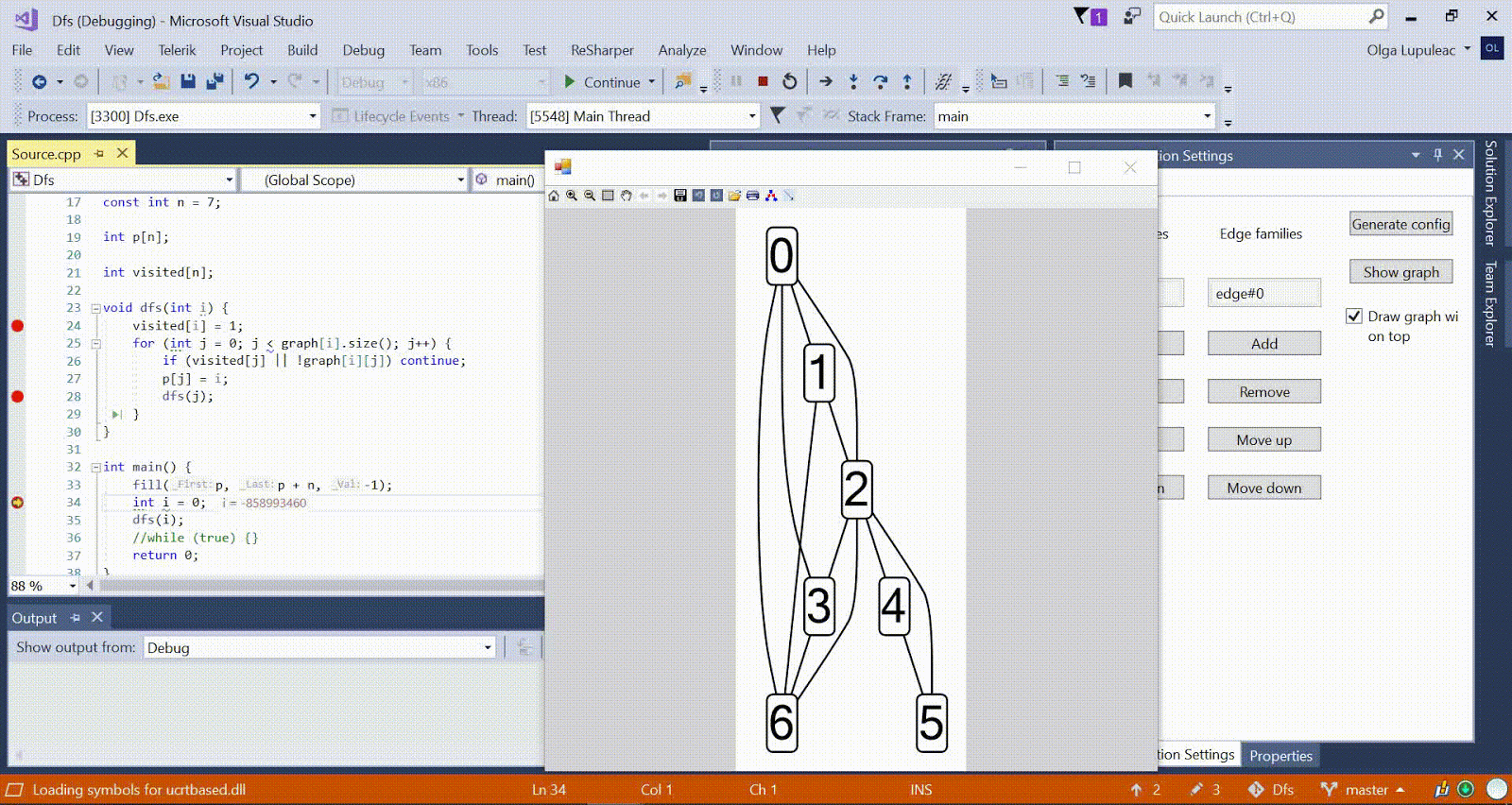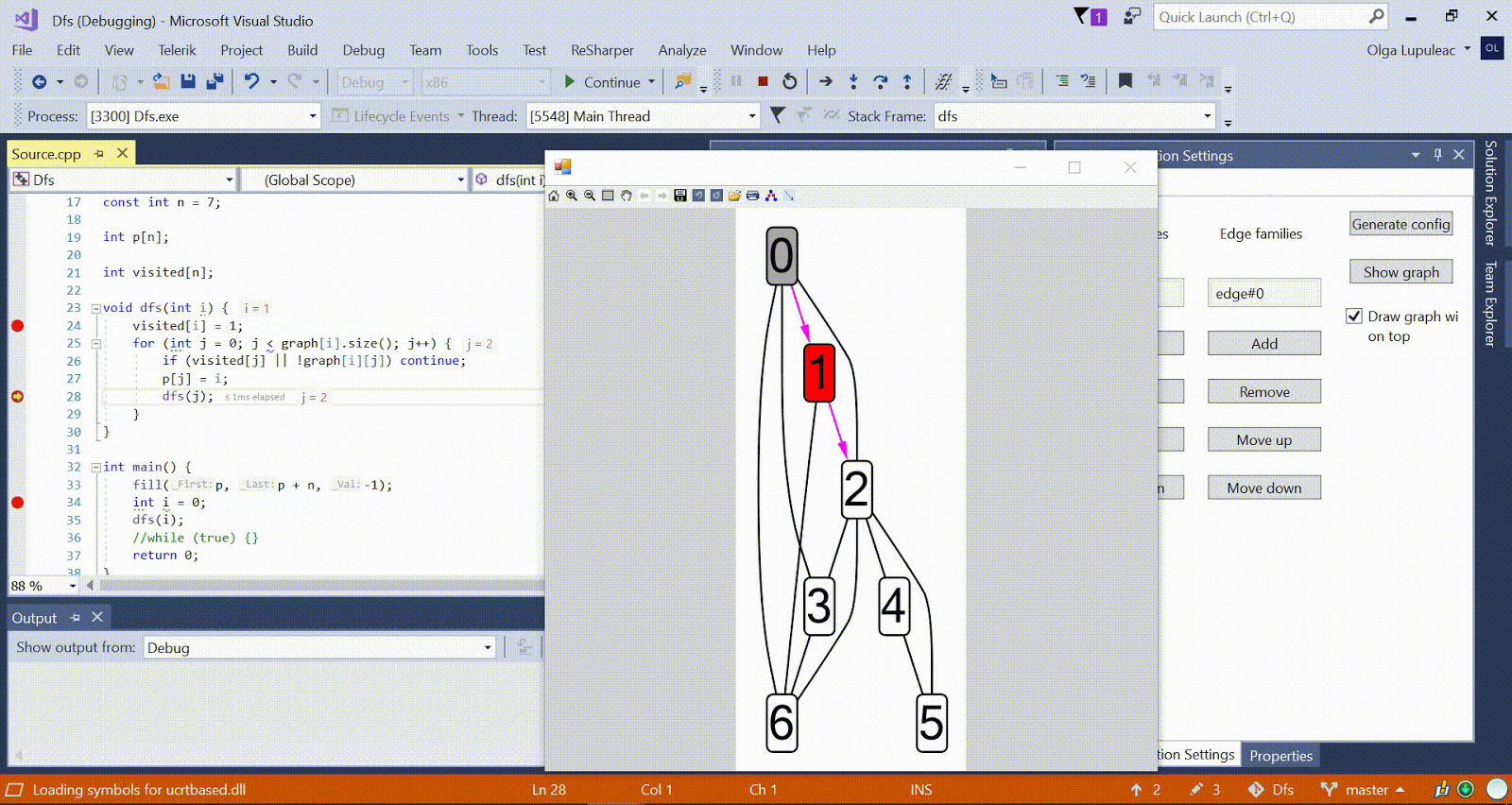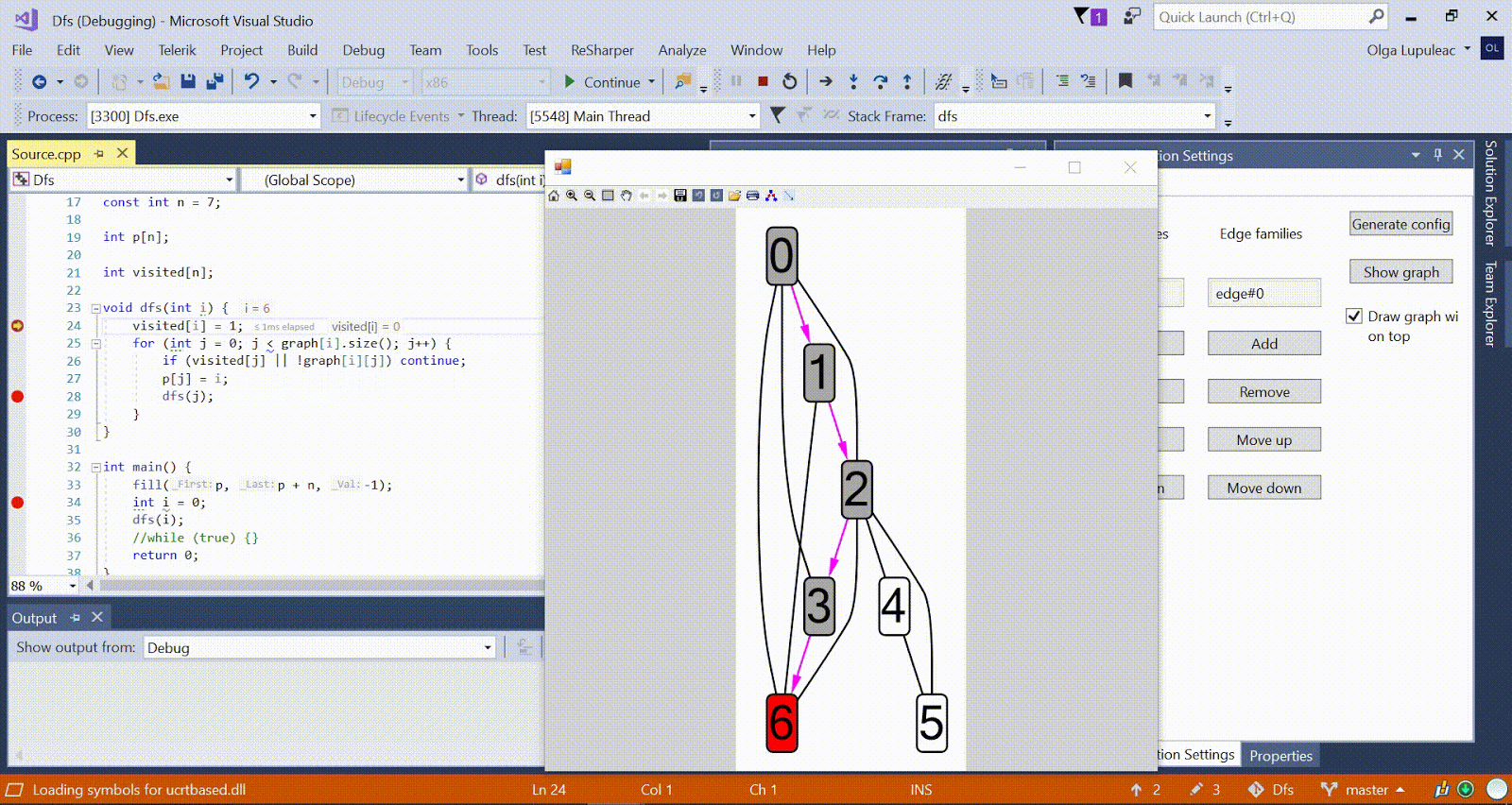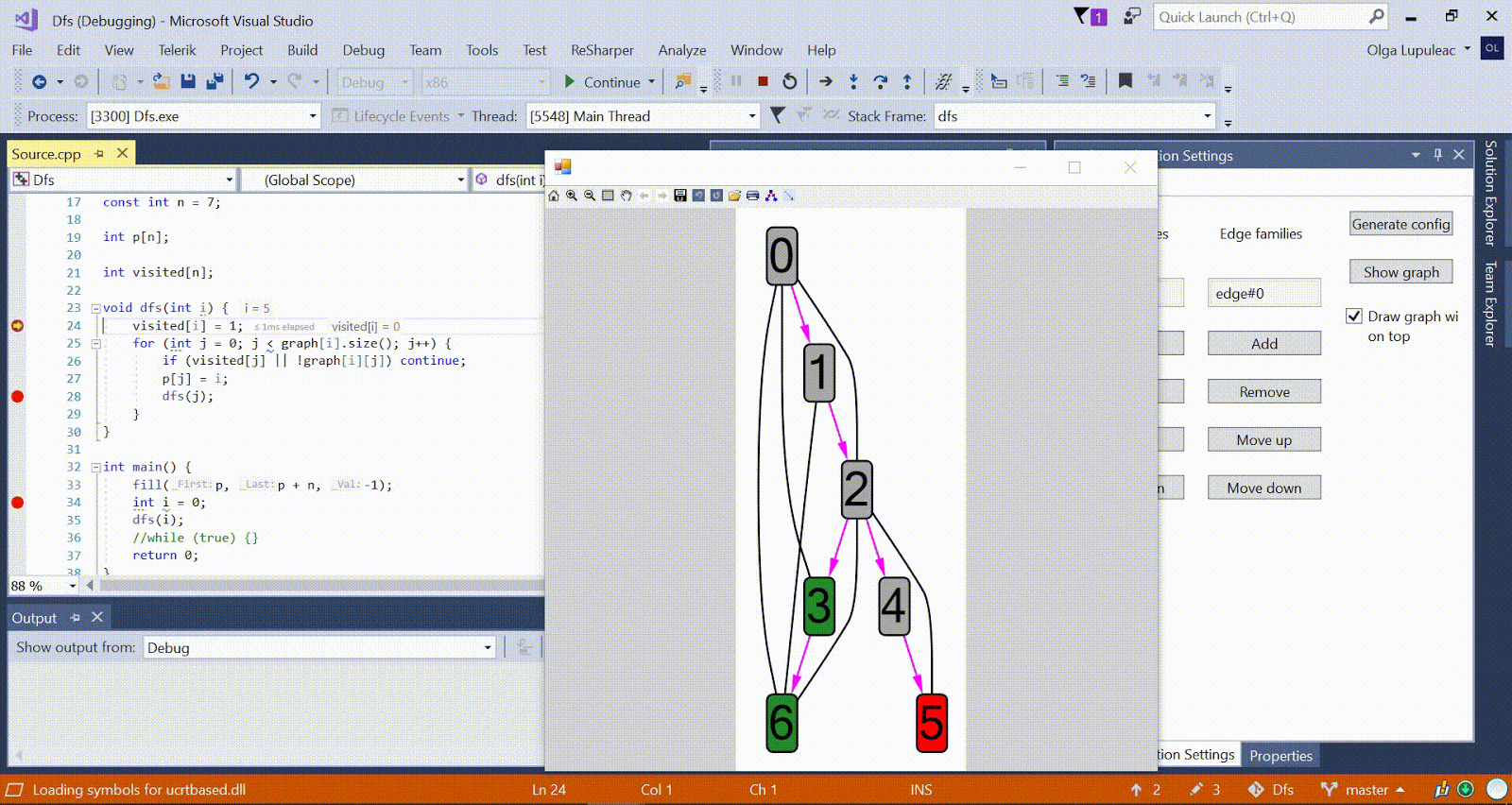 Animação com DFS - o vértice atual é mostrado em vermelho, os vértices da pilha são cinza e os outros vértices visitados são verdes. Costelas de framboesa indicam a direção do desvio.
Animação com DFS - o vértice atual é mostrado em vermelho, os vértices da pilha são cinza e os outros vértices visitados são verdes. Costelas de framboesa indicam a direção do desvio.Mais algoritmos de amostra estão disponíveis
aqui.Proteção NIR
Para proteger o trabalho de pesquisa, os alunos são obrigados em sete minutos a contar sobre seu trabalho por um semestre. Ao mesmo tempo, independentemente de o tópico ter sido proposto como parte da apresentação dos trabalhos de pesquisa ou de o aluno ter encontrado por conta própria, você precisa responder para justificar por que o tópico do projeto se enquadra nos requisitos descritos no início. Normalmente, um relatório é estruturado da seguinte forma: primeiro há motivação, depois uma revisão de análogos, é dito sobre por que eles não nos convêm, depois são estabelecidas metas e objetivos, e então cada uma das tarefas é descrita como foi resolvida. No final, há um slide com os resultados, que mais uma vez afirma que o objetivo foi alcançado e que todas as tarefas foram resolvidas.
Como já havia decidido sobre a motivação e a revisão dos análogos no estágio inicial, eu só precisava coletar todas as informações e compactá-las em sete minutos. No final, consegui, a defesa correu bem, recebi a pontuação máxima para pesquisa.
Referências