Em grandes sistemas em nuvem, a questão do balanceamento automático ou do balanceamento de carga nos recursos de computação é especialmente aguda. A Tionics também cuidou dessa questão (desenvolvedora e operadora de serviços em nuvem, fazemos parte do grupo de empresas Rostelecom).
E, como nossa plataforma principal de desenvolvimento é o Openstack, e nós, como todas as pessoas, somos preguiçosos, foi decidido escolher algum tipo de módulo pronto que já faz parte da plataforma. Nossa escolha recaiu sobre o Watcher, que decidimos usar para nossas necessidades.

Primeiro, vamos lidar com termos e definições.
Termos e definições
Um objetivo é um resultado final legível, observável e mensurável, que deve ser alcançado. Para atingir cada objetivo, há uma ou mais estratégias. Uma estratégia é uma implementação de um algoritmo capaz de encontrar uma solução para um determinado objetivo.
Uma Ação é uma tarefa elementar que altera o estado atual de um recurso gerenciado de destino de um cluster do OpenStack, como: migrar uma máquina virtual (migração), alterar o estado da energia de um nó (change_node_power_state), alterar o estado de um serviço nova (change_nova_service_state), alterar um sabor (redimensionar) , registro de mensagens NOP (nop), ausência de ações durante um certo período de tempo - pausa (suspensão), transferência de disco (migração de volume).
Plano de Ação (Plano de Ação) - um fluxo específico de ações realizadas em uma ordem específica para atingir uma meta específica. O plano de ação também contém um desempenho global estimado com um conjunto de indicadores de desempenho. O plano de ação é gerado pelo Watcher durante uma auditoria bem-sucedida, como resultado da qual a estratégia utilizada encontra uma solução para atingir a meta. Um plano de ação consiste em uma lista de ações seqüenciais.
Auditoria é uma solicitação para otimização de cluster. A otimização é realizada para atingir um objetivo em um determinado cluster. Para cada auditoria bem-sucedida, o Watcher gera um plano de ação.
Escopo de auditoria é um conjunto de recursos dentro dos quais uma auditoria é realizada (zona (s) de disponibilidade, agregadores de nós, nós de computação individuais ou nós de armazenamento, etc.). Um escopo de auditoria é definido em cada modelo. Se o escopo da auditoria não for especificado, todo o cluster será auditado.
Modelo de auditoria - um conjunto salvo de configurações para iniciar uma auditoria. São necessários modelos para executar auditorias com as mesmas configurações várias vezes. O modelo deve necessariamente conter o objetivo da auditoria; se as estratégias não forem indicadas, as estratégias existentes mais adequadas serão selecionadas.
Um Cluster é um conjunto de máquinas físicas que fornecem recursos de computação, armazenamento e rede e são gerenciados pelo mesmo nó de controle do OpenStack.
O CDM (Modelo de Dados de Cluster) é uma representação lógica do estado atual e da topologia dos recursos gerenciados por cluster.
Indicador de eficiência (Indicador de eficácia) - um indicador que indica como a solução criada usando esta estratégia é implementada. Os indicadores de desempenho são específicos para um objetivo específico e são comumente usados para calcular a eficácia global de um plano de ação final.
A Especificação de Eficácia é um conjunto de recursos específicos associados a cada Objetivo, que define vários indicadores de desempenho que a estratégia que garante a consecução do objetivo correspondente deve fornecer em sua decisão. De fato, cada solução proposta pela estratégia será verificada quanto à conformidade com a especificação antes de calcular sua eficácia global.
Um "mecanismo de pontuação" é um arquivo executável que possui dados de entrada claramente definidos, dados de saída claramente definidos e executa uma tarefa puramente matemática. Portanto, o cálculo não depende do ambiente em que é executado - ele fornecerá o mesmo resultado em qualquer lugar.
O Watcher Planner faz parte do mecanismo de decisão do Watcher. Este módulo aceita o conjunto de ações geradas pela estratégia e cria um plano de fluxo de trabalho que define como planejar essas várias ações no tempo e, para cada ação, quais são os pré-requisitos.
Objetivos e estratégias do observador
Objetivo simulado - um objetivo de reserva usado para fins de teste.
Estratégias relacionadas: Estratégia fictícia, Estratégia fictícia usando mecanismos de pontuação de amostra e estratégia fictícia com redimensionamento. Estratégia dummy é uma estratégia fictícia usada para testes de integração através do Tempest. Essa estratégia não fornece nenhuma otimização útil; seu único objetivo é usar os testes Tempest.
Estratégia dummy usando mecanismos de pontuação de amostra - a estratégia é semelhante à anterior, difere apenas no uso da amostra "mecanismo de avaliação", que conta usando métodos de aprendizado de máquina.
Estratégia dummy com redimensionamento - a estratégia é semelhante à anterior, difere apenas no uso de alterar o sabor (migração e redimensionamento).
Não usado na produção.
Economia de energia - minimize o consumo de energia. Estratégia para esse objetivo A Economia de energia em conjunto com a VM Workload Consolidation Strategy (Server Consolidation) é capaz de executar funções de gerenciamento dinâmico de energia (DPM), que economizam energia ao consolidar dinamicamente cargas de trabalho, mesmo durante períodos de baixa carga de recursos: as máquinas virtuais são transferidas para menos nós , e nós desnecessários são desconectados. Após a consolidação, a estratégia oferece a decisão de ativar / desativar os nós de acordo com os parâmetros fornecidos: “min_free_hosts_num” - o número de nós incluídos gratuitos que estão aguardando carregamento e “free_used_percent” - a porcentagem de nós incluídos gratuitos para o número de nós ocupados pelas máquinas. Para que a estratégia
funcione, o Ironic deve estar
ligado e configurado para funcionar com a alimentação ligada / desligada nos nós.Opções de estratégia
Deve haver pelo menos dois nós na nuvem. O método usado está alterando o estado de energia do nó (change_node_power_state).
A estratégia não requer coleta de métricas.Consolidação do servidor - minimize o número de nós de computação (consolidação). Ele tem duas estratégias: Consolidação básica de servidor offline e Estratégia de consolidação de carga de trabalho da VM.
A estratégia básica de consolidação offline de servidores minimiza o número total de servidores usados e também minimiza o número de migrações.
A estratégia básica requer as seguintes métricas:
Parâmetros da estratégia: migration_attempts - o número de combinações para procurar possíveis candidatos a desligamento (padrão, 0, sem restrições), período - intervalo de tempo em segundos para obter agregação estática da fonte de dados métrica (700 por padrão).
Métodos utilizados: migração, mudança de estado do serviço nova (change_nova_service_state).
A estratégia de consolidação de carga de trabalho da VM é baseada no algoritmo heurístico de primeiro ajuste, que se concentra na carga medida da CPU e tenta minimizar os nós com carga muito ou muito baixa, levando em consideração as limitações de capacidade de recursos. Essa estratégia fornece uma solução que leva a um uso mais eficiente dos recursos do cluster usando as quatro etapas a seguir:
- Fase de descarregamento - processamento de recursos superutilizados;
- Fase de consolidação - processamento de recursos subutilizados;
- Otimização da solução - reduzindo o número de migrações;
- Desativando nós de computação não utilizados.
A estratégia requer as seguintes métricas:
As métricas a seguir são opcionais, mas melhoram a precisão da estratégia, se disponível:
Parâmetros da estratégia: período - intervalo de tempo em segundos para obter agregação estática da fonte de dados métrica (3600 por padrão).
Usa os mesmos métodos da estratégia anterior. Mais detalhes
aqui .
Balanceamento de carga de trabalho - equilibra a carga de trabalho entre os nós de computação. O objetivo tem três estratégias: Estratégia de Migração de Balanço de Carga de Trabalho, Estabilização de Carga de Trabalho, Estratégia de Equilíbrio de Capacidade de Armazenamento.
A Estratégia de Migração de Equilíbrio de Carga de Trabalho lança migrações de máquinas virtuais com base na carga de trabalho das máquinas virtuais do host. A decisão de transferir é tomada sempre que a% de utilização da CPU ou RAM do nó exceder o limite especificado. Nesse caso, a máquina virtual movida deve aproximar o nó da carga de trabalho média de todos os nós.
Exigências
- Uso de processadores físicos;
- Pelo menos dois nós de computação física;
- O componente Ceilometer instalado e configurado é o ceilometer-agent-computute trabalhando em cada nó de computação e a API Ceilometer, além de coletar as seguintes métricas:
Opções de estratégia:
O método usado é a migração.
Estabilização de carga de trabalho - uma estratégia que visa estabilizar a carga de trabalho usando a migração ao vivo. A estratégia é baseada no algoritmo de desvio padrão e determina se há congestionamento no cluster e responde a ele acionando uma migração de máquina para estabilizar o cluster.
Exigências
- Uso de processadores físicos;
- Pelo menos dois nós de computação física;
- O componente Ceilometer instalado e configurado é o ceilometer-agent-computute trabalhando em cada nó de computação e a API Ceilometer, além de coletar as seguintes métricas:
Estratégia de equilíbrio da capacidade de armazenamento (uma estratégia implementada desde o Queens) - a estratégia transfere discos dependendo da carga dos conjuntos de cinzas. A decisão de transferência é tomada sempre que a utilização do conjunto exceder o limite especificado. Um disco móvel deve aproximar o pool da carga média de todos os pools do Cinder.
Requisitos e Limitações
- Pelo menos duas piscinas de cinzas;
- Capacidade de migrar discos.
- Coletor de modelo de dados de cluster.
Opções de estratégia:
O método usado é a migração de disco (volume_migrate).
Vizinho ruidoso - identifique e migre um “vizinho ruidoso” - uma máquina virtual de baixa prioridade que afeta adversamente o desempenho de uma máquina virtual de alta prioridade do ponto de vista do IPC, usando demais o cache de último nível. Estratégia própria: vizinho ruidoso (o parâmetro de estratégia usado é cache_threshold (o valor padrão é 35), a migração começa quando o desempenho cai para o valor especificado.Para a estratégia funcionar, as
métricas LLC (Last Level Cache) incluídas
, o mais recente servidor Intel com suporte a CMT e também coleção das seguintes métricas:
Modelo de dados de cluster (padrão): coletor de modelo de dados de cluster Nova. O método aplicado é a migração.
O trabalho para esse fim no Dashboard não é totalmente implementado no Queens.
Otimização térmica - otimize as condições de temperatura. A temperatura de saída (ar de exaustão) é um dos importantes sistemas de telemetria térmica para medir o estado da carga térmica / de trabalho do servidor. Para isso, existe uma estratégia - a estratégia baseada na temperatura da tomada, que toma decisões sobre a transferência de cargas de trabalho para nós com condições de temperatura favoráveis (a temperatura mais baixa na saída) quando a temperatura na saída dos hosts originais atinge um limite personalizado.
Para que a estratégia funcione, você precisa de um servidor com e instalado o Intel Power Node Manager
3.0 ou posterior , além de coletar as seguintes métricas:
Opções de estratégia:
O método usado é a migração.
Otimização do fluxo de ar - otimize o modo de ventilação. Estratégia própria - Fluxo de ar uniforme usando migração ao vivo. A estratégia inicia a migração da máquina virtual sempre que o fluxo de ar do ventilador do servidor exceder o limite especificado.
Para funcionar, a estratégia requer:
- Hardware: nós de computação <com suporte ao NodeManager 3.0;
- Pelo menos dois nós de computação;
- Os componentes ceilometer-agent-computute e Ceilometer API instalados e configurados em cada nó de computação podem relatar com êxito métricas como fluxo de ar, energia do sistema e temperatura de entrada:
Para que a estratégia funcione, você precisa de um servidor com o Intel Power Node Manager 3.0 ou posterior instalado e configurado.
Limitações: O conceito não se destina à produção.
É proposto o uso desse algoritmo com auditorias contínuas, pois apenas uma máquina virtual está planejada para ser migrada por iteração.
Migrações ao vivo são possíveis.
Opções de estratégia:
O método usado é a migração.
Manutenção de Hardware - manutenção de hardware. Uma estratégia relacionada a esse objetivo é a migração da zona. A estratégia é uma ferramenta para migração automática e mínima eficiente de máquinas e discos virtuais em caso de manutenção de hardware. A estratégia cria um plano de ação de acordo com os pesos: um conjunto de ações com maior peso será planejado à frente dos demais. Existem duas opções de configuração: pesos de ação (pesos_da_ação) e paralelização.
Limitações: é necessário ajustar as escalas de ações e paralelização.
Opções de estratégia:
Elementos de uma matriz de nós de computação:
Elementos de uma matriz de nós de armazenamento:
Elementos dos objetos prioritários:
Métodos usados - migração de máquinas virtuais, migração de discos.
Não classificado é um objetivo de apoio usado para facilitar o desenvolvimento de uma estratégia. Ele não contém especificações e pode ser usado sempre que a estratégia ainda não estiver conectada a uma meta existente. Esse objetivo também pode ser usado como um estágio de transição. Uma estratégia relacionada é o Atuador.
Crie uma nova meta
O Watcher Decision Engine possui uma interface de plug-in "objetivo externo" que permite integrar um objetivo externo que pode ser alcançado usando a estratégia.
Antes de criar uma nova meta, verifique se nenhuma das metas existentes atende às suas necessidades.
Crie um novo plugin
Para criar um novo destino, você deve: estender a classe de destino, implementar o método da classe
get_name () para retornar um identificador exclusivo para o novo destino que você deseja criar. Esse identificador exclusivo deve corresponder ao nome do ponto de entrada que você declara posteriormente.
Em seguida, é necessário implementar o método de classe
get_display_name () para retornar o nome de exibição traduzido do destino que você deseja criar (não use a variável para retornar a sequência traduzida, para que possa ser coletada automaticamente pela ferramenta de tradução.).
Implemente o método da classe
get_translatable_display_name () para retornar a chave de conversão (na verdade, o nome de exibição em inglês) do seu novo destino. O valor de retorno deve corresponder à string traduzida em get_display_name ().
Implemente seu método
get_efficacy_specification () para retornar uma especificação de desempenho para seu propósito. O método get_efficacy_specification () retorna a instância Unclassified () fornecida pelo Watcher. Essa especificação de desempenho é útil no processo de desenvolvimento de seu objetivo, pois atende à especificação vazia.
→
Mais detalhes aquiObservador de arquitetura (mais informações
aqui ).
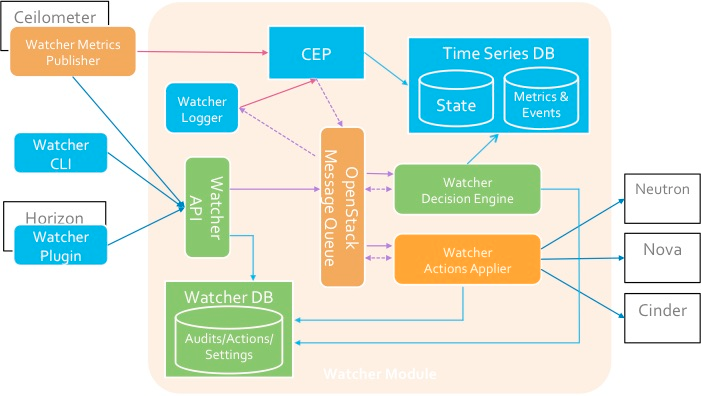
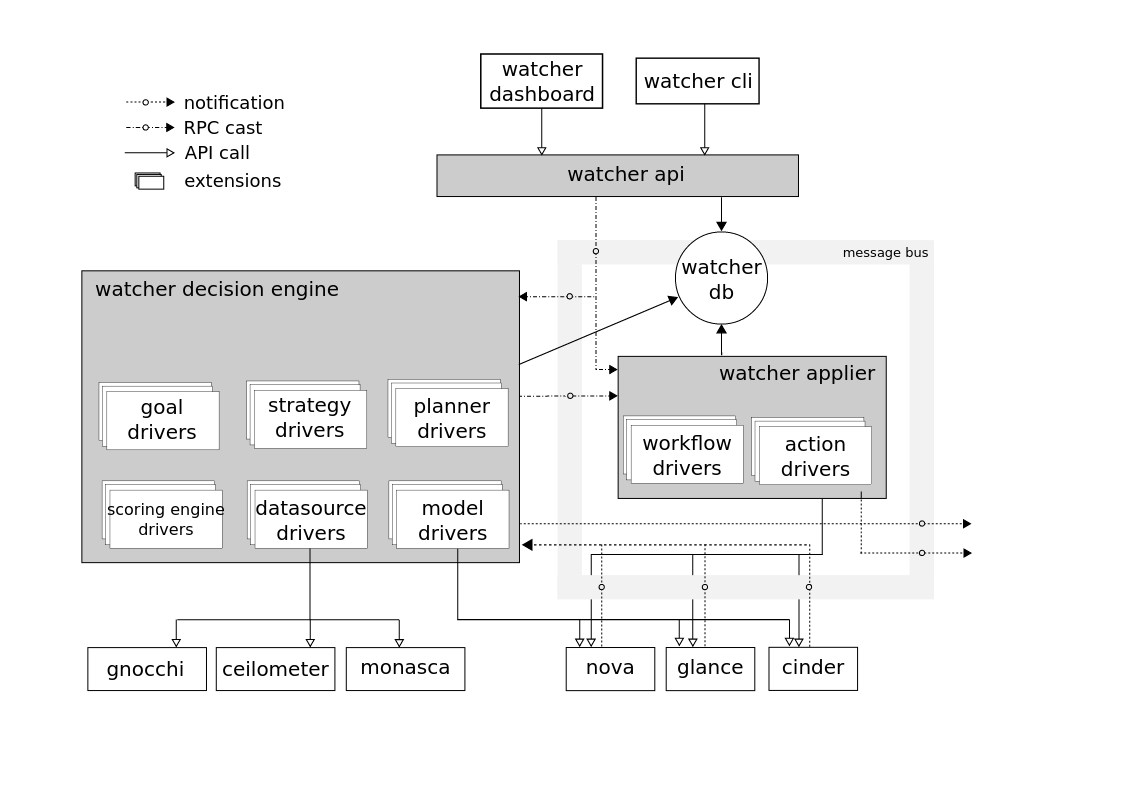
Componentes
 API do Watcher
API do Watcher - um componente que implementa a API REST fornecida pelo Watcher. Mecanismos de interação: CLI, plugin Horizon, Python SDK.
Watcher DB - banco de dados do Watcher.
Watcher Applier - um componente que implementa a implementação do plano de ação criado pelo componente Watcher Decision Engine.O Watcher Decision Engine é um componente responsável pelo cálculo de um conjunto de possíveis ações de otimização para cumprir uma meta de auditoria. Se uma estratégia não for especificada, o componente seleciona independentemente a mais adequada.O Watcher Metrics Publisher é um componente que coleta e calcula algumas métricas ou eventos e os publica no terminal do CEP. A funcionalidade do recurso também pode ser fornecida pelo editor Ceilometer.Mecanismo de processamento de eventos complexos (CEP)- mecanismo para processamento de eventos complexos. Por motivos de desempenho, pode haver várias instâncias do CEP Engine em execução ao mesmo tempo, cada uma das quais lida com um tipo específico de métrica / evento. No sistema Watcher, o CEP lança dois tipos de ações: - grava os eventos / métricas correspondentes no banco de dados de séries temporais; - envie eventos relevantes ao componente Watcher Decision Engine quando esse evento puder afetar o resultado da estratégia de otimização atual, pois o cluster Openstack não é um sistema estático.A interação dos componentes é realizada de acordo com o protocolo AMQP.→ Configurando o WatcherEsquema de interação com o Watcher

Resultados do teste do observador
- Optimization — Action plans 500 ( Queens, ), , , .
- Action details , ( Queens, ).
- Dummy () , .
- Unclassified , .
- Workload Balancing ( Storage Capacity balance) , . .
- Workload Balancing ( Workload Balance Migration Strategy) , .
- Workload Balancing ( Workload Stabilization Strategy) .
- Noisy Neighbor , .
- Hardware maintenance , ( , ).
- nova.conf ( default compute_monitors = cpu.virt_driver) .
- Server Consolidation ( Basic) .
- Server Consolidation ( VM workload consolidation) . . , , .
- Watcher ( — Optimization, - ):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Saving Energy . , - Ironic, baremetal service.
- Thermal Optimization . , Server Consolidation ( VM workload consolidation) ( )
- As auditorias para otimização do fluxo de ar falham.
Os seguintes erros de conclusão de auditoria também são encontrados. Traceback nos logs do decision-engine.log (o estado do cluster não está definido).→ Discussão do erro aquiConclusão
O resultado de nossa pesquisa de dois meses foi a conclusão inequívoca de que, para obter um sistema de balanceamento de carga de trabalho completo, teremos que trabalhar de perto na finalização das ferramentas da plataforma Openstack.O Watcher provou ser um produto sério e de rápido desenvolvimento, com enorme potencial, para o uso completo do qual será necessário muito trabalho sério.Mas mais sobre isso nos próximos artigos do ciclo.