Este artigo discute a implementação mais simples da RAM no Verilog.
Antes de prosseguir com a análise de código, é recomendável que você aprenda a sintaxe básica do Verilog.
Aqui você pode encontrar materiais de treinamento .
RAM
Etapa 1: declarar o módulo com os sinais de entrada / saída correspondentes
module ram ( input [word_size - 1:0] data, input [word_size - 1:0] addr, input wr, input clk, output response, output [word_size - 1:0] out ); parameter word_size = 32;
- data - dados para escrever.
- endereço - endereço para a memória na RAM.
- wr - status (leitura / gravação).
- clk - sistema de ciclo de relógio.
- resposta - prontidão da RAM (1 - se a RAM processou a solicitação de leitura / gravação, 0 - caso contrário).
- dados de saída lidos da RAM.
Essa implementação foi integrada ao Altera Max 10 FPGA, que possui uma arquitetura de 32 bits e, portanto, o tamanho dos dados e do endereço (tamanho_da_ palavra) é de 32 bits.
Etapa 2: declarando os registradores dentro do módulo
Uma declaração de matriz para armazenar dados:
parameter size = 1<<32; reg [word_size-1:0] ram [size-1:0];
Também precisamos armazenar os parâmetros de entrada anteriores para rastrear suas alterações no bloco always:
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg;
E os dois últimos registradores para atualizar os sinais de saída após os cálculos no bloco always:
reg [word_size-1:0] out_reg; reg response_reg;
Inicializamos os registros:
initial begin response_reg = 1; data_reg = 0; addr_reg = 0; wr_reg = 0; end
Etapa 3: implementando a lógica sempre do bloco
always @(negedge clk) begin if ((data != data_reg) || (addr%size != addr_reg)|| (wr != wr_reg)) begin response_reg = 0; data_reg = data; addr_reg = addr%size; wr_reg = wr; end else begin if (response_reg == 0) begin if (wr) ram[addr] = data; else out_reg = ram[addr]; response_reg = 1; end end end
Sempre o bloqueio é acionado por negedje, ou seja, no momento, o relógio se move de 1 para 0. Isso é feito para sincronizar corretamente a RAM com o cache. Caso contrário, poderá haver casos em que a RAM não tenha tempo para redefinir o status de pronto de 1 para 0 e, no próximo relógio, o cache decidirá que a RAM processou com êxito sua solicitação, o que é fundamentalmente errado.
A lógica do algoritmo sempre do bloco é a seguinte: se os dados forem atualizados, redefina o status de prontidão para 0 e escreva / leia os dados, se a gravação / leitura for concluída, atualizamos o status de prontidão para 1.
No final, adicione a seguinte seção de código:
assign out = out_reg; assign response = response_reg;
O tipo de sinais de saída do nosso módulo é fio. A única maneira de alterar sinais desse tipo é a atribuição a longo prazo, que é proibida dentro do bloco always. Por esse motivo, o bloco always usa registradores, que são posteriormente atribuídos aos sinais de saída.
Cache de mapeamento direto
O cache de mapeamento direto é um dos tipos mais simples de cache. Nesta implementação, o cache consiste em n elementos e a RAM é dividida condicionalmente em blocos por n; o i-ésimo elemento no cache corresponde a todos esses k-ésimos elementos da RAM que satisfazem a condição i = k% n.
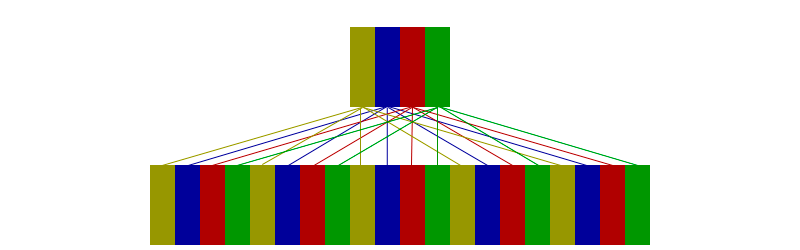
A imagem abaixo mostra um cache de tamanho 4 e RAM de tamanho 16.
Cada elemento do cache contém as seguintes informações:
- bit de validade - se as informações no cache são relevantes.
- tag é o número do bloco na RAM em que esse elemento está localizado.
- dados - informações que escrevemos / lemos.
Quando solicitado a ler, o cache divide o endereço de entrada em duas partes - uma tag e um índice. O tamanho do índice é log (n), em que n é o tamanho do cache.
Etapa 1: declarar o módulo com os sinais de entrada / saída correspondentes
module direct_mapping_cache ( input [word_size-1:0] data, input [word_size-1:0] addr, input wr, input clk, output response, output is_missrate, output [word_size-1:0] out ); parameter word_size = 32;
A declaração do módulo de cache é idêntica à RAM, com exceção do novo sinal de saída is_missrate. Esta saída armazena informações sobre se a última solicitação de leitura foi incorreta.
Etapa 2: declarando os registradores e RAM
Antes de declarar os registradores, determinamos o tamanho do cache e do índice:
parameter size = 64; parameter index_size = 6;
Em seguida, declaramos uma matriz na qual os dados que escrevemos e lemos serão armazenados:
reg [word_size-1:0] data_array [size-1:0];
Também precisamos armazenar bits e tags de validade para cada item no cache:
reg validity_array [size-1:0]; reg [word_size-index_size-1:0] tag_array [size-1:0]; reg [index_size-1:0] index_array [size-1:0];
Registros nos quais o endereço de entrada será dividido:
reg [word_size-index_size-1:0] tag; reg [index_size-1:0] index;
Registros que armazenam os valores de entrada no relógio anterior (para rastrear alterações nos dados de entrada):
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg;
Registra a atualização dos sinais de saída após os cálculos no bloco always:
reg response_reg; reg is_missrate_reg; reg [word_size-1:0] out_reg;
Valores de entrada para RAM:
reg [word_size-1:0] ram_data; reg [word_size-1:0] ram_addr; reg ram_wr;
Valores de saída para RAM:
wire ram_response; wire [word_size-1:0] ram_out;
Declarando um módulo de RAM e conectando sinais de entrada e saída:
ram ram( .data(ram_data), .addr(ram_addr), .wr(ram_wr), .clk(clk), .response(ram_response), .out(ram_out));
Registrar inicialização:
initial integer i initial begin data_reg = 0; addr_reg = 0; wr_reg = 0; for (i = 0; i < size; i=i+1) begin data_array[i] = 0; tag_array[i] = 0; validity_array[i] = 0; end end
Etapa 3: implementando a lógica sempre do bloco
Para começar, para cada relógio, temos dois estados - os dados de entrada são alterados ou não. Com base nisso, temos a seguinte condição:
always @(posedge clk) begin if (data_reg != data || addr_reg != addr || wr_reg != wr) begin end // 1: else begin // 2: end end
Bloco 1. Caso os dados de entrada sejam alterados, a primeira coisa que fazemos é redefinir o status de prontidão para 0:
response_reg = 0;
Em seguida, atualizamos os registradores que armazenavam os valores de entrada do relógio anterior:
data_reg = data; addr_reg = addr; wr_reg = wr;
Dividimos o endereço de entrada em uma tag e um índice:
tag = addr >> index_size; index = addr;
Para calcular a tag, é usado um deslocamento bit a bit para a direita; para o índice, basta atribuí-la simplesmente, porque Bits extras do endereço não são levados em consideração.
O próximo passo é escolher entre escrever e ler:
if (wr) begin // data_array[index] = data; tag_array[index] = tag; validity_array[index] = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end else begin // if ((validity_array[index]) && (tag == tag_array[index])) begin // is_missrate_reg = 0; out_reg = data_array[index]; response_reg = 1; end else begin // is_missrate_reg = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end end
No caso de gravação, inicialmente modificamos os dados no cache e atualizamos os dados de entrada para a RAM. No caso da leitura, verificamos a presença desse elemento no cache e, se ele existe, escrevemos para out_reg, caso contrário, passamos para a RAM.
Bloco 2. Se os dados não foram alterados desde a execução do relógio anterior, temos o seguinte código:
if ((ram_response) && (!response_reg)) begin if (wr == 0) begin validity_array [index] = 1; data_array [index] = ram_out; tag_array[index] = tag; out_reg = ram_out; end response_reg = 1; end
Aqui, aguardamos a conclusão do acesso à RAM (se não houver acesso, ram_response é 1), atualizamos os dados se houver um comando de leitura e configuramos a disponibilidade do cache como 1.
E por último, atualize os valores de saída:
assign out = out_reg; assign is_missrate = is_missrate_reg; assign response = response_reg;