A coleta, armazenamento, conversão e apresentação de dados são os principais desafios enfrentados pelos engenheiros de dados. O departamento de Business Intelligence Badoo recebe e processa mais de 20 bilhões de eventos enviados a partir de dispositivos do usuário por dia, ou 2 TB de dados recebidos.
O estudo e a interpretação de todos esses dados nem sempre são uma tarefa trivial, às vezes é necessário ir além das capacidades dos bancos de dados prontos. E se você tiver a coragem e decidiu fazer algo novo, primeiro se familiarize com os princípios de trabalho das soluções existentes.
Em uma palavra, desenvolvedores curiosos e perspicazes, este artigo é abordado. Nele, você encontrará uma descrição do modelo tradicional de execução de consultas em bancos de dados relacionais, usando a linguagem de demonstração PigletQL como exemplo.
Conteúdo
Antecedentes
Nosso grupo de engenheiros está envolvido em back-end e interfaces, oferecendo oportunidades para análise e pesquisa de dados dentro da empresa (a propósito, estamos expandindo ). Nossas ferramentas padrão são um banco de dados distribuído de dezenas de servidores (Exasol) e um cluster Hadoop para centenas de máquinas (Hive e Presto).
A maioria das consultas a esses bancos de dados é analítica, ou seja, afeta de centenas de milhares a bilhões de registros. Sua execução leva minutos, dezenas de minutos ou até horas, dependendo da solução usada e da complexidade da solicitação. Com o trabalho manual do usuário-analista, esse tempo é considerado aceitável, mas não é adequado para pesquisa interativa através da interface do usuário.
Com o tempo, destacamos as consultas e consultas analíticas populares, difíceis de definir em termos de SQL, e desenvolvemos pequenos bancos de dados especializados para eles. Eles armazenam um subconjunto de dados em um formato adequado para algoritmos de compactação leves (por exemplo, streamvbyte), que permitem armazenar dados em uma única máquina por vários dias e executar consultas em segundos.
As primeiras linguagens de consulta para esses dados e seus intérpretes foram implementadas rapidamente, precisávamos refiná-las constantemente e cada vez que levava um tempo inaceitavelmente longo.
Os idiomas de consulta não eram suficientemente flexíveis, embora não houvesse razões óbvias para limitar seus recursos. Como resultado, voltamos à experiência dos desenvolvedores de intérpretes SQL, graças à qual conseguimos resolver parcialmente os problemas que surgiram.
Abaixo, falarei sobre o modelo de execução de consulta mais comum em bancos de dados relacionais - Volcano. O código fonte do intérprete do dialeto SQL primitivo, PigletQL , está anexado ao artigo , para que todos os interessados possam se familiarizar facilmente com os detalhes no repositório.
Estrutura do interpretador SQL
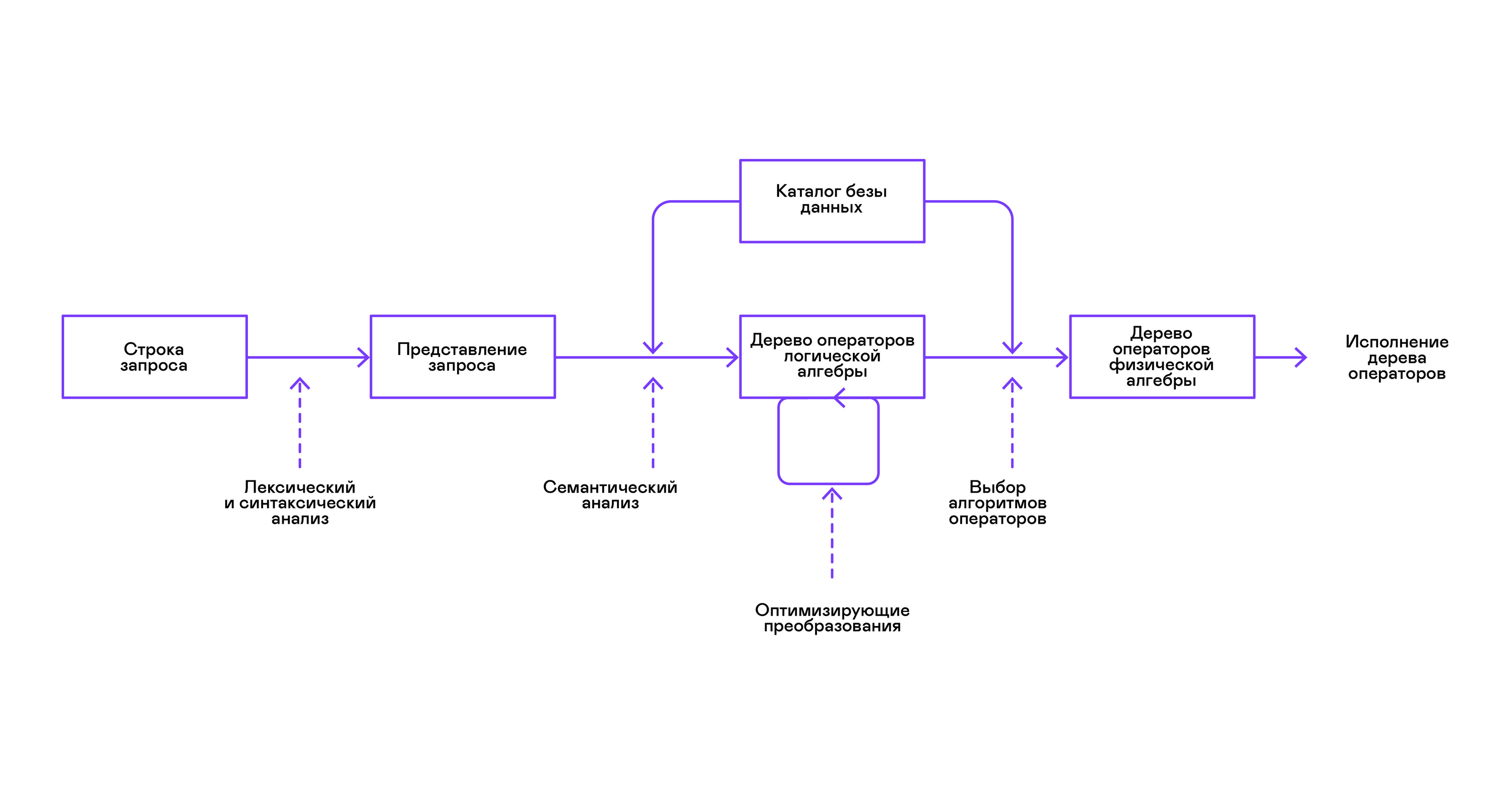
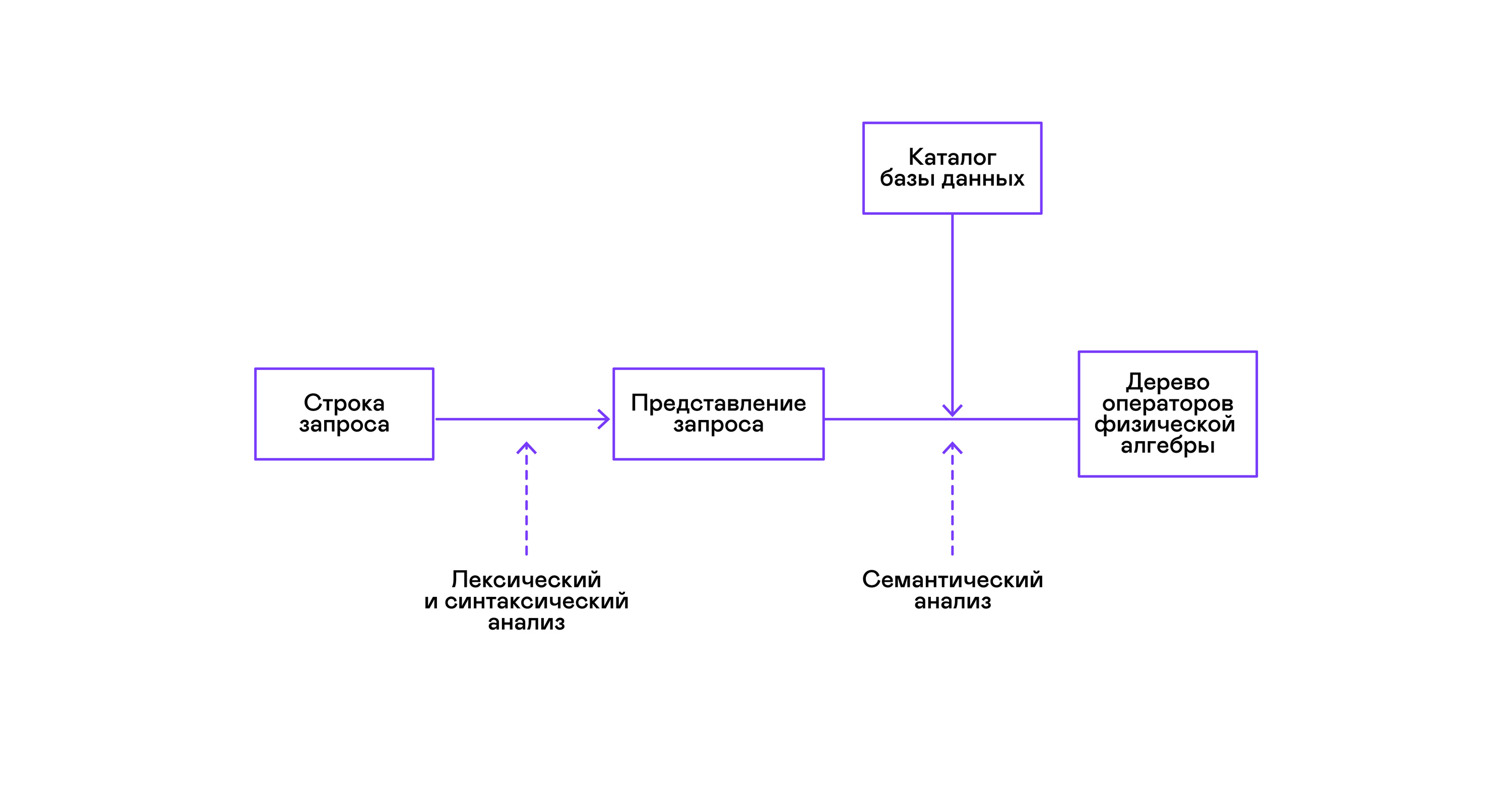
Os bancos de dados mais populares fornecem uma interface para dados na forma de uma linguagem de consulta SQL declarativa. Uma consulta na forma de uma sequência é convertida pelo analisador em uma descrição da consulta, semelhante a uma árvore de sintaxe abstrata. É possível executar consultas simples já neste estágio; no entanto, para otimizar transformações e execução subseqüente, essa representação é inconveniente. Nos bancos de dados conhecidos por mim, representações intermediárias são introduzidas para esses fins.
A álgebra relacional tornou-se um modelo para representações intermediárias. É uma linguagem na qual as transformações ( operadores ) executadas nos dados são explicitamente descritas: selecionando um subconjunto dos dados de acordo com um predicado, combinando dados de diferentes fontes, etc. Além disso, a álgebra relacional é uma álgebra no sentido matemático, ou seja, um grande número equivalente de transformações. Portanto, é conveniente realizar transformações otimizadas sobre uma consulta na forma de uma árvore de operadores de álgebra relacional.
Existem diferenças importantes entre as representações internas nos bancos de dados e a álgebra relacional original; portanto, é mais correto chamá-la de álgebra lógica .
A verificação da validade de uma consulta geralmente é realizada ao compilar a representação inicial da consulta em operadores de álgebra lógica e corresponde ao estágio de análise semântica nos compiladores convencionais. O papel da tabela de símbolos nos bancos de dados é desempenhado pelo diretório do banco de dados , que armazena informações sobre o esquema e os metadados do banco de dados: tabelas, colunas da tabela, índices, direitos do usuário etc.
Comparados com os intérpretes de uso geral, os intérpretes de banco de dados têm mais uma peculiaridade: diferenças no volume de dados e meta-informações sobre os dados nos quais as consultas devem ser feitas. Em tabelas ou relações em termos de álgebra relacional, pode haver uma quantidade diferente de dados; em algumas colunas ( atributos de relacionamento), índices podem ser construídos, etc. Ou seja, dependendo do esquema do banco de dados e da quantidade de dados nas tabelas, a consulta deve ser realizada por algoritmos diferentes. e use-os em uma ordem diferente.
Para resolver este problema, outra representação intermediária é introduzida - álgebra física . Dependendo da disponibilidade de índices nas colunas, da quantidade de dados nas tabelas e da estrutura da árvore da álgebra lógica, são oferecidas diferentes formas da árvore da álgebra física, dentre as quais a melhor opção é escolhida. É essa árvore que é mostrada no banco de dados como um plano de consulta. Nos compiladores convencionais, esse estágio corresponde condicionalmente aos estágios de alocação de registro, planejamento e seleção de instruções.
O último passo no trabalho do intérprete é diretamente a execução da árvore de operadores de álgebra física.
Modelo de vulcão e execução de consultas
Intérpretes de álgebra física sempre foram usados em bancos de dados comerciais fechados, mas a literatura acadêmica geralmente se refere ao otimizador experimental Volcano, desenvolvido no início dos anos 90.
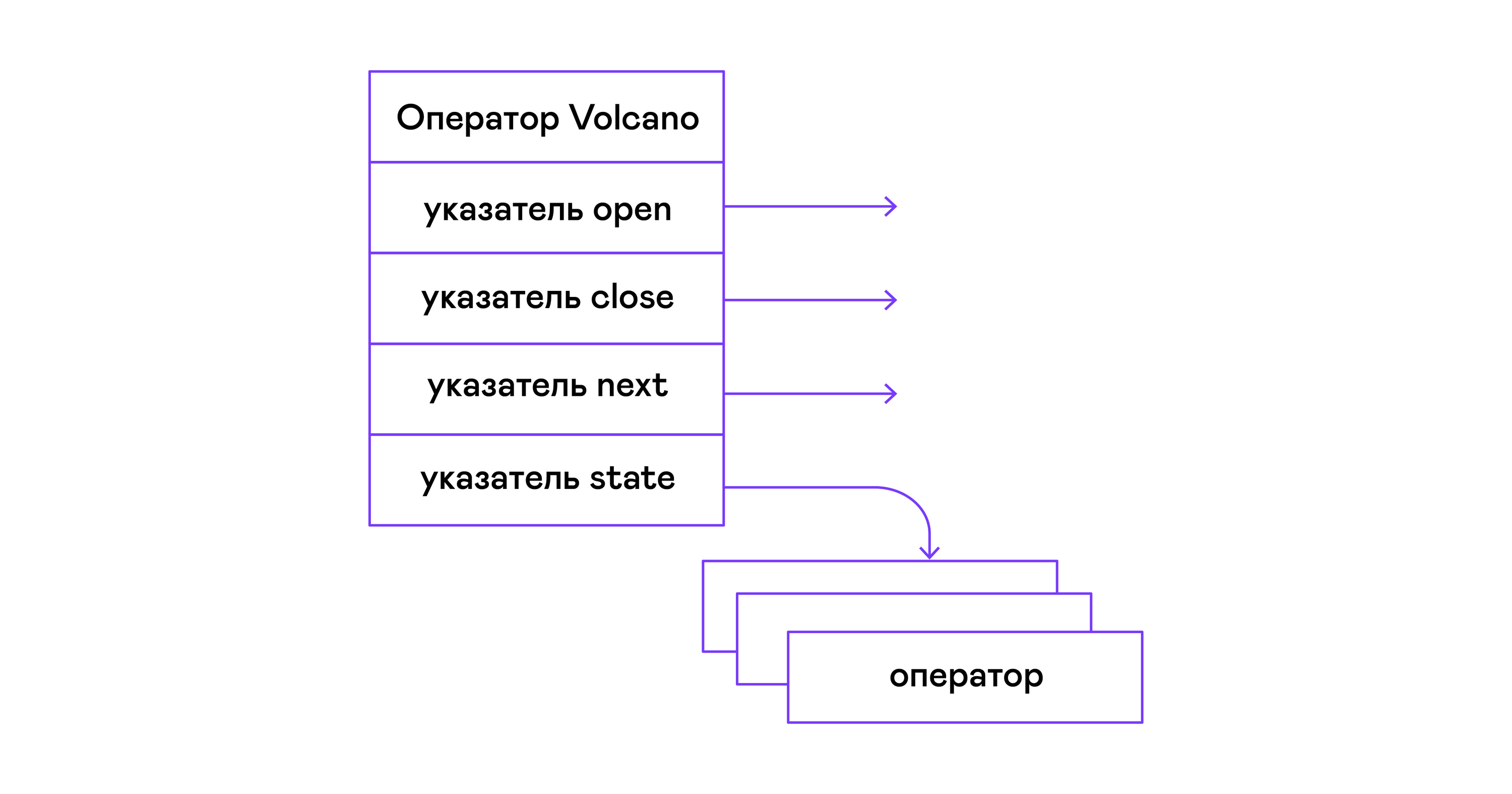
No modelo Volcano, cada operador de uma árvore de álgebra física se transforma em uma estrutura com três funções: abrir, fechar, fechar. Além das funções, o operador contém um estado operacional - estado. A função aberta inicia o estado da instrução, a próxima função retorna a próxima tupla (tupla em inglês) ou NULL, se não houver tuplas restantes, a função fechar encerra a instrução:
Os operadores podem ser aninhados para formar uma árvore de operadores de álgebra física. Cada operador, portanto, itera sobre as tuplas de uma relação existente em um meio real ou de uma relação virtual formada pela enumeração das tuplas de operadores aninhados:
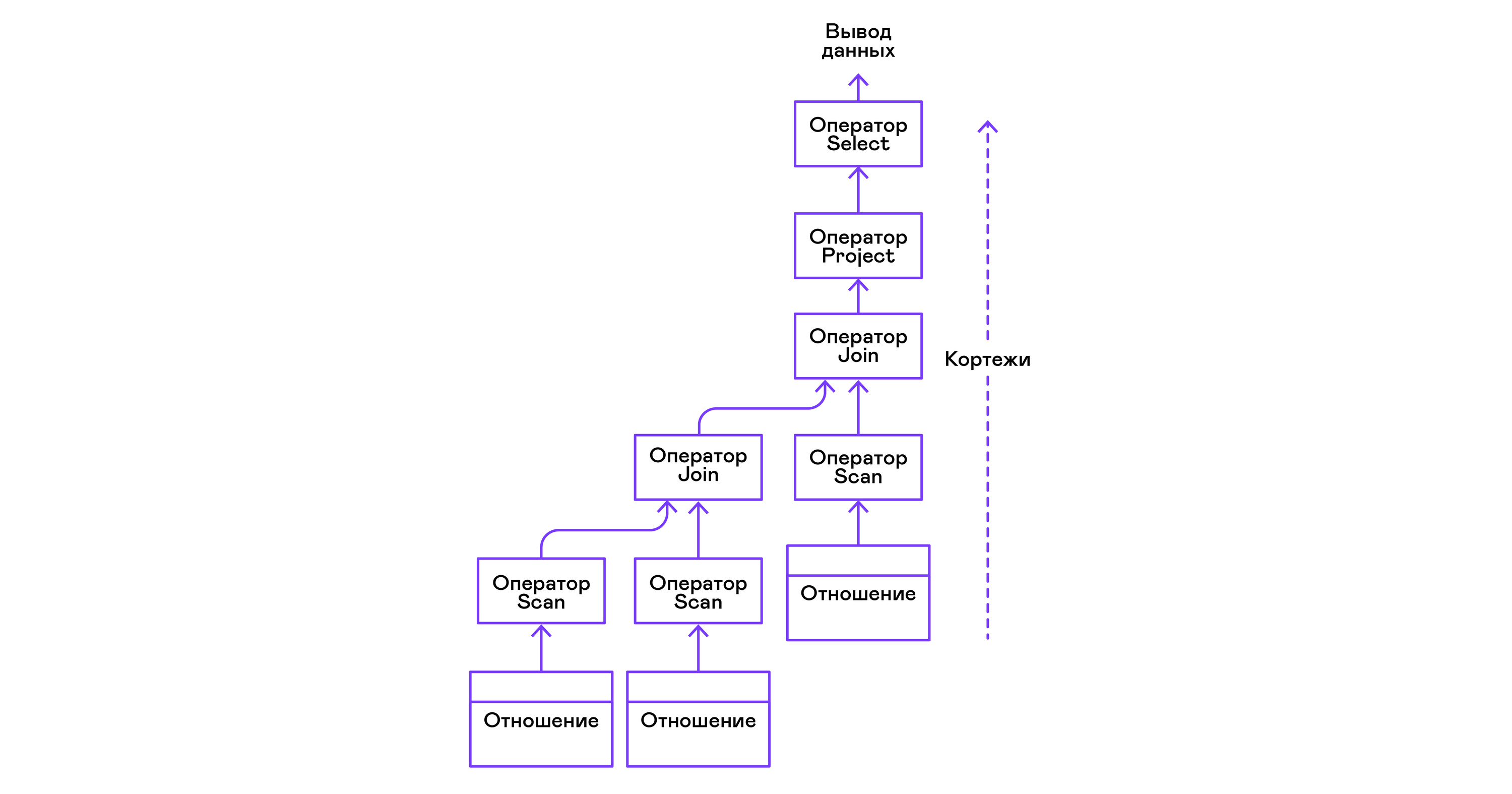
Em termos de linguagens modernas de alto nível, a árvore desses operadores é uma cascata de iteradores.
Até os intérpretes de consulta industrial no DBMS relacional são repelidos do modelo Volcano, foi por isso que tomei isso como base do interpretador PigletQL.
PigletQL
Para demonstrar o modelo, desenvolvi o intérprete da linguagem de consulta limitada PigletQL . Está escrito em C, suporta a criação de tabelas no estilo SQL, mas está limitado a um único tipo - números inteiros positivos de 32 bits. Todas as tabelas estão na memória. O sistema opera em um único encadeamento e não possui um mecanismo de transação.
Não há otimizador no PigletQL, e as consultas SELECT são compiladas diretamente na árvore do operador da álgebra física. O restante das consultas (CREATE TABLE e INSERT) funciona diretamente das visualizações internas principais.
Exemplo de sessão do usuário no PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
Lexical e parser
O PigletQL é uma linguagem muito simples e sua implementação não foi necessária nas etapas de análise lexical e de análise.
O analisador lexical é escrito à mão. Um objeto analisador ( scanner_t ) é criado a partir da string de consulta, que fornece tokens um por um:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
A análise é feita usando o método de descida recursiva. Primeiro, é criado o objeto parser_t , que, após receber o analisador lexical (scanner_t), preenche o objeto query_t com informações sobre a solicitação:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
O resultado da análise em query_t é um dos três tipos de consulta suportados pelo PigletQL:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
O tipo mais complexo de consulta no PigletQL é SELECT. Corresponde à estrutura de dados query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
A estrutura contém uma descrição da consulta (uma matriz de atributos solicitados pelo usuário), uma lista de fontes de dados - relacionamentos, uma matriz de predicados, filtrando tuplas e informações sobre o atributo usado para classificar os resultados.
Analisador semântico
A fase de análise semântica no SQL regular envolve a verificação da existência das tabelas listadas, colunas nas tabelas e verificação de tipo nas expressões de consulta. Para verificações relacionadas a tabelas e colunas, é usado o diretório do banco de dados, onde todas as informações sobre a estrutura de dados são armazenadas.
Não há expressões complexas no PigletQL, portanto, a verificação de consultas é reduzida à verificação de metadados de catálogo de tabelas e colunas. As consultas SELECT, por exemplo, são validadas pela função validate_select . Vou trazê-lo de forma abreviada:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
Se a solicitação for válida, a próxima etapa é compilar a árvore de análise em uma árvore do operador.
Compilando consultas em uma exibição intermediária
Em intérpretes SQL completos, geralmente existem duas representações intermediárias: álgebra lógica e física.
Um interpretador PigletQL simples executa consultas CREATE TABLE e INSERT diretamente de suas árvores de análise, ou seja, estruturas query_create_table_t e query_insert_t . As consultas SELECT mais complexas são compiladas em uma única representação intermediária, que será executada pelo intérprete.
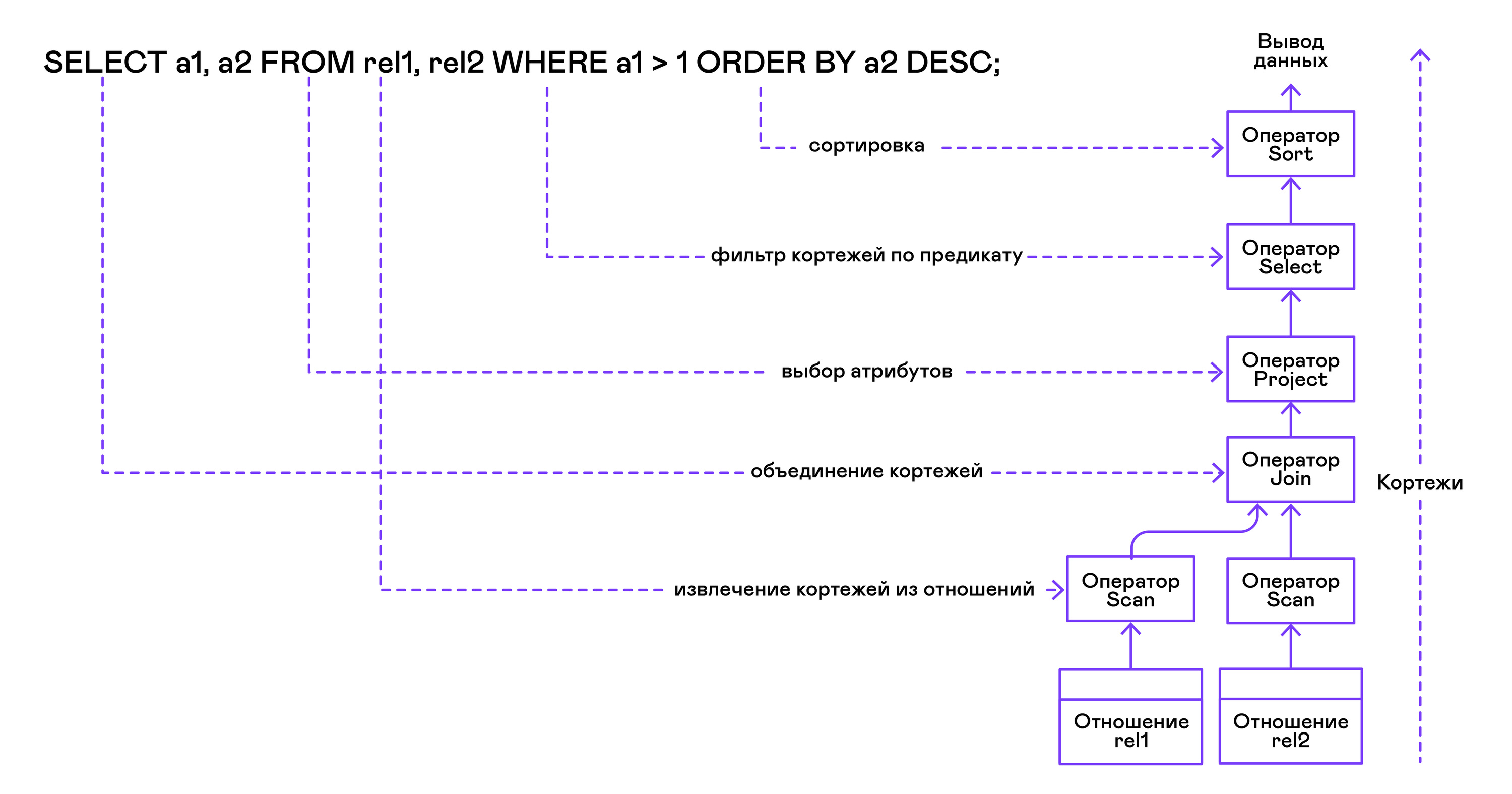
A árvore do operador é criada das folhas para a raiz na seguinte sequência:
Na parte direita da consulta ("... FROM relação1, relação2, ..."), são obtidos os nomes das relações desejadas, para cada uma das quais uma instrução de varredura é criada.
Extraindo tuplas das relações, os operadores de verificação são combinados em uma árvore binária do lado esquerdo através do operador de junção.
Os atributos solicitados pelo usuário ("SELECT attr1, attr2, ...") são selecionados pela instrução do projeto.
Se algum predicado for especificado ("... WHERE a = 1 AND b> 10 ..."), a instrução select será adicionada à árvore acima.
Se o método para classificar o resultado for especificado ("... ORDER BY attr1 DESC"), o operador de classificação será adicionado à parte superior da árvore.
Compilação no código PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
Depois que a árvore é formada, geralmente são realizadas transformações otimizadas, mas o PigletQL continua imediatamente para o estágio de execução da representação intermediária.
Execução de uma apresentação intermediária
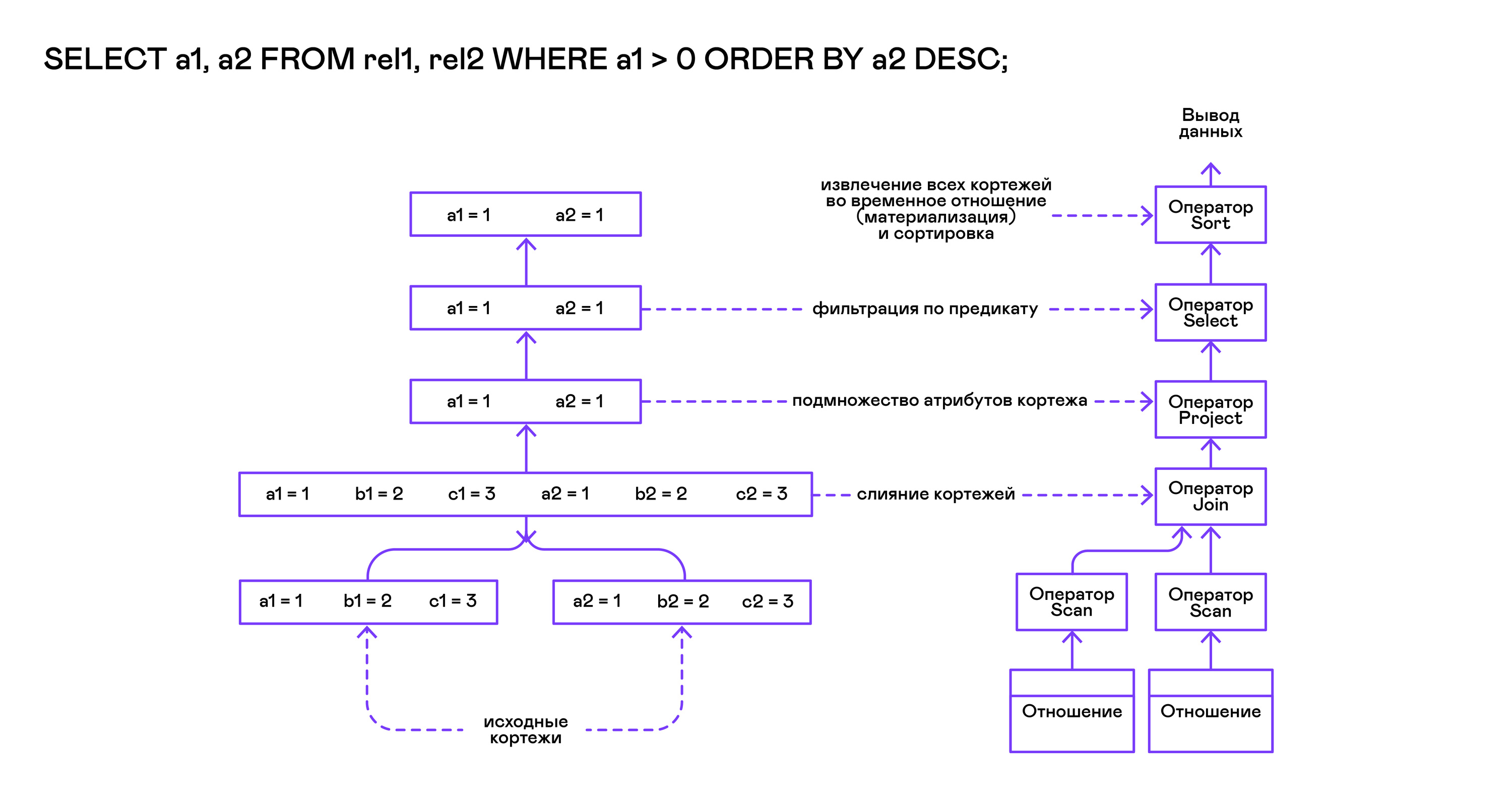
O modelo Volcano implica uma interface para trabalhar com operadores por meio de três operações comuns de abrir / próximo / fechar. Em essência, cada declaração do Volcano é um iterador do qual as tuplas são "puxadas" uma a uma, portanto, essa abordagem de execução também é chamada de modelo pull.
Cada um desses iteradores pode chamar as mesmas funções de iteradores aninhados, criar tabelas temporárias com resultados intermediários e converter as tuplas recebidas.
Executando consultas SELECT no PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
A solicitação é compilada primeiro pela função compile_select, que retorna a raiz da árvore do operador, após a qual as mesmas funções de abrir / fechar / fechar são chamadas no operador raiz. Cada chamada para a próxima retorna a próxima tupla ou NULL. No último caso, isso significa que todas as tuplas foram extraídas e a função de iterador próximo deve ser chamada.
As tuplas resultantes são recalculadas e produzidas pela tabela no fluxo de saída padrão.
Operadores
A coisa mais interessante sobre o PigletQL é a árvore do operador. Vou mostrar o dispositivo de alguns deles.
Os operadores têm uma interface comum e consistem em ponteiros para a função abrir / próximo / fechar e uma função de destruição adicional, que libera os recursos de toda a árvore do operador de uma só vez:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
Além das funções, o operador pode conter um estado interno arbitrário (ponteiro de estado).
Abaixo, analisarei o dispositivo de dois operadores interessantes: a varredura mais simples e a criação de um tipo de relação intermediária.
Declaração de digitalização
A instrução que inicia qualquer consulta é varredura. Ele apenas passa por todas as tuplas do relacionamento. O estado interno da varredura é um ponteiro para a relação de onde as tuplas serão recuperadas, o índice da próxima tupla na relação e uma estrutura de link para a tupla atual passada ao usuário:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
Para criar um estado de instrução de verificação, você precisa de uma relação de origem; tudo o resto (ponteiros para as funções correspondentes) já é conhecido:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
Operações de abertura / fechamento no caso de links de redefinição de varredura de volta ao primeiro elemento do relacionamento:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
A próxima chamada retorna a próxima tupla ou NULL se não houver mais tuplas na relação:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
Instrução de classificação
A instrução de classificação produz tuplas na ordem especificada pelo usuário. Para fazer isso, crie uma relação temporária com tuplas obtidas de operadores aninhados e classifique-a.
O estado interno do operador:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
A classificação é realizada de acordo com os atributos especificados na solicitação (sort_attr_name e sort_order) ao longo da razão de tempo (tmp_relation). Tudo isso acontece quando a função aberta é chamada:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
A enumeração dos elementos do relacionamento temporário é realizada pelo operador temporário tmp_relation_scan_op:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
O relacionamento temporário é desalocado na função close:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
Aqui você pode ver claramente por que as operações de classificação em colunas sem índices podem demorar bastante tempo.
Exemplos de trabalho
Vou dar alguns exemplos de consultas PigletQL e as árvores correspondentes da álgebra física.
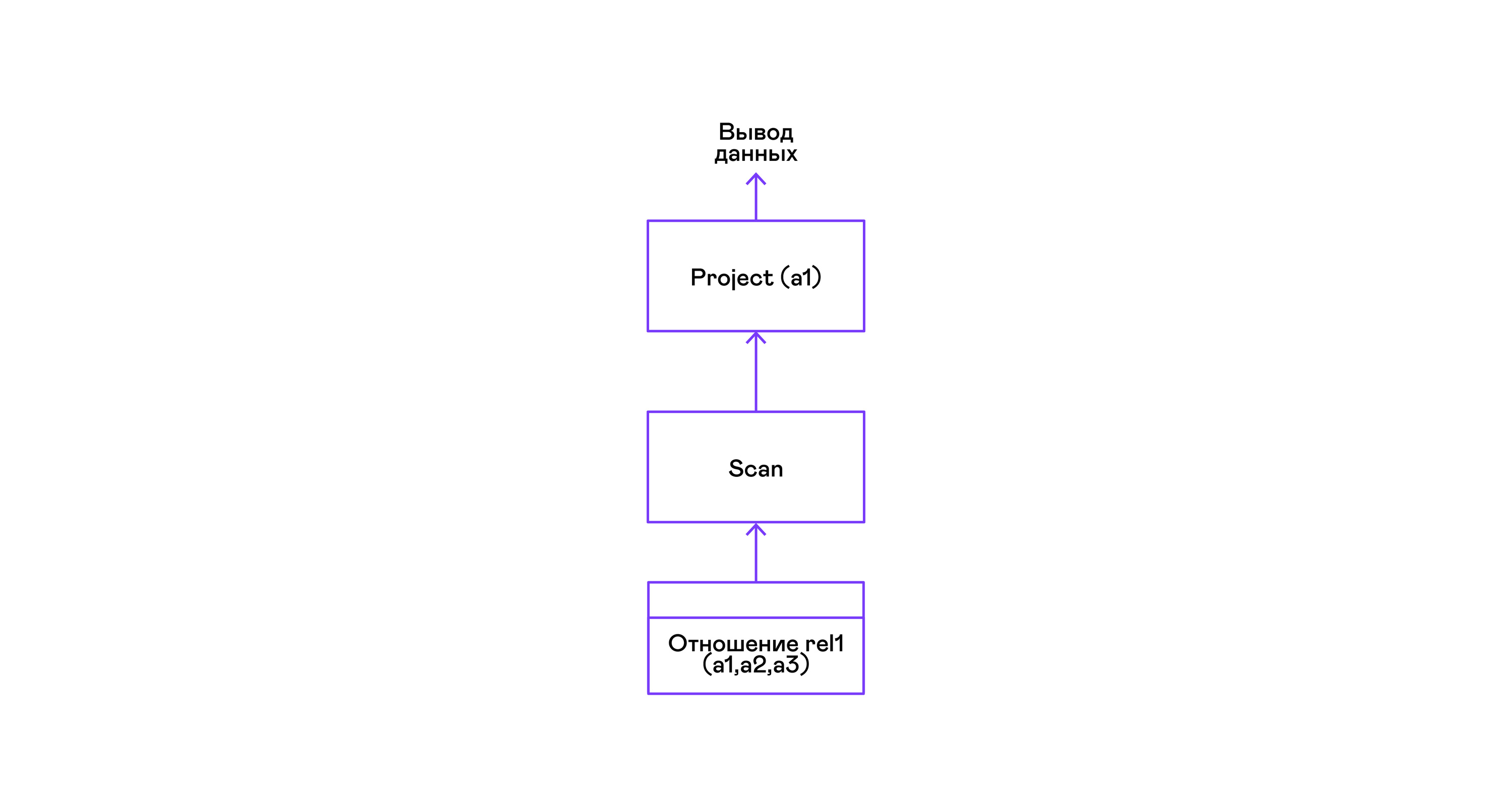
O exemplo mais simples em que todas as tuplas de uma relação são selecionadas:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
Para as consultas mais simples, são usadas apenas recuperando tuplas da relação de varredura e selecionando o único atributo de projeto das tuplas:
Escolhendo tuplas com um predicado:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
Predicados são expressos pela instrução select:
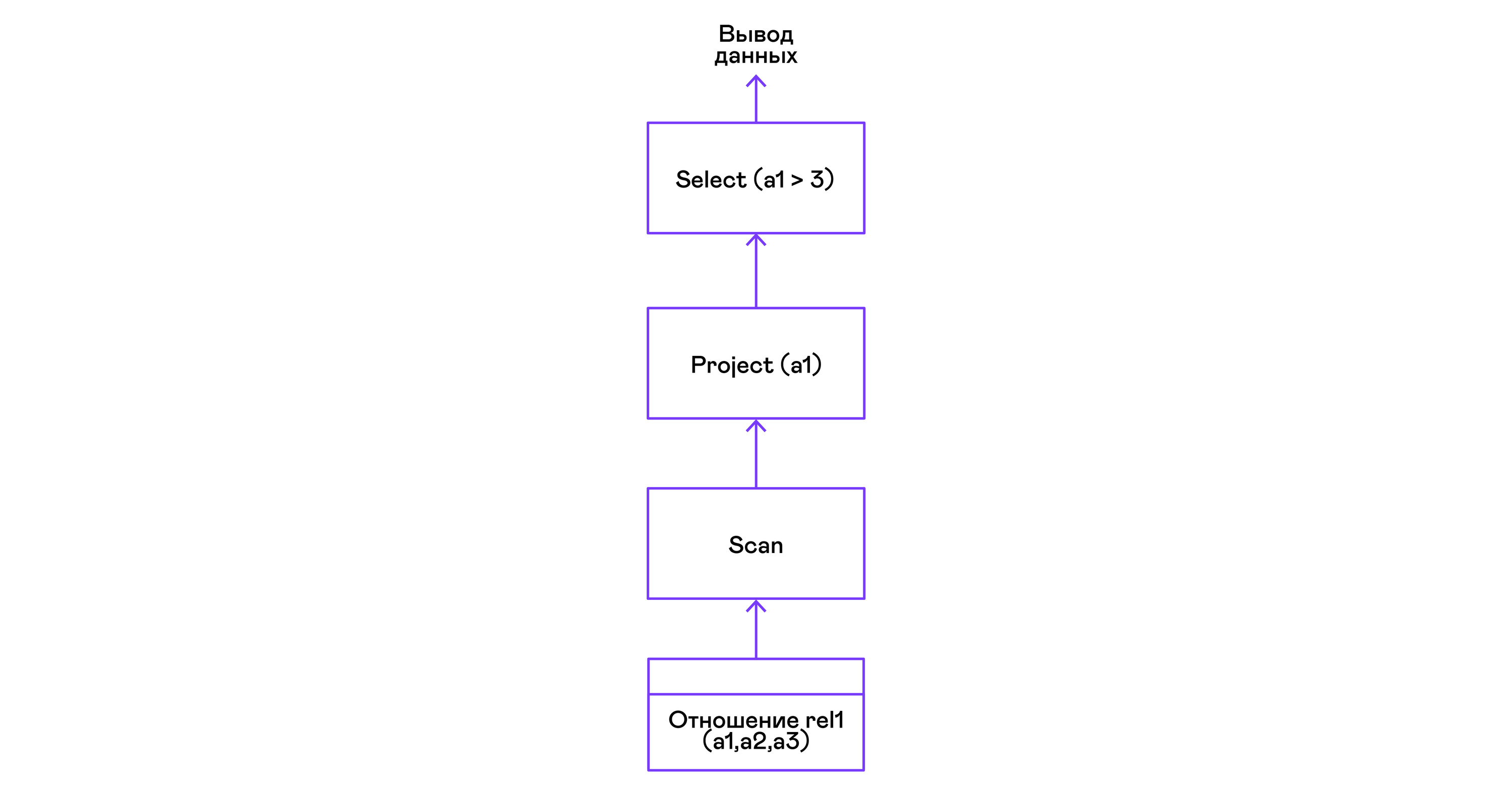
Seleção de tuplas com classificação:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
O operador de classificação de varredura na chamada aberta cria ( materializa ) um relacionamento temporário, coloca todas as tuplas recebidas lá e classifica o todo. Depois disso, nas próximas chamadas, infere as tuplas da relação temporária na ordem especificada pelo usuário:

Combinando tuplas de duas relações com um predicado:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
O operador de junção no PigletQL não usa algoritmos complexos, mas simplesmente forma um produto cartesiano a partir dos conjuntos de tuplas das subárvores esquerda e direita. Isso é muito ineficiente, mas para um intérprete de demonstração, ele fará:
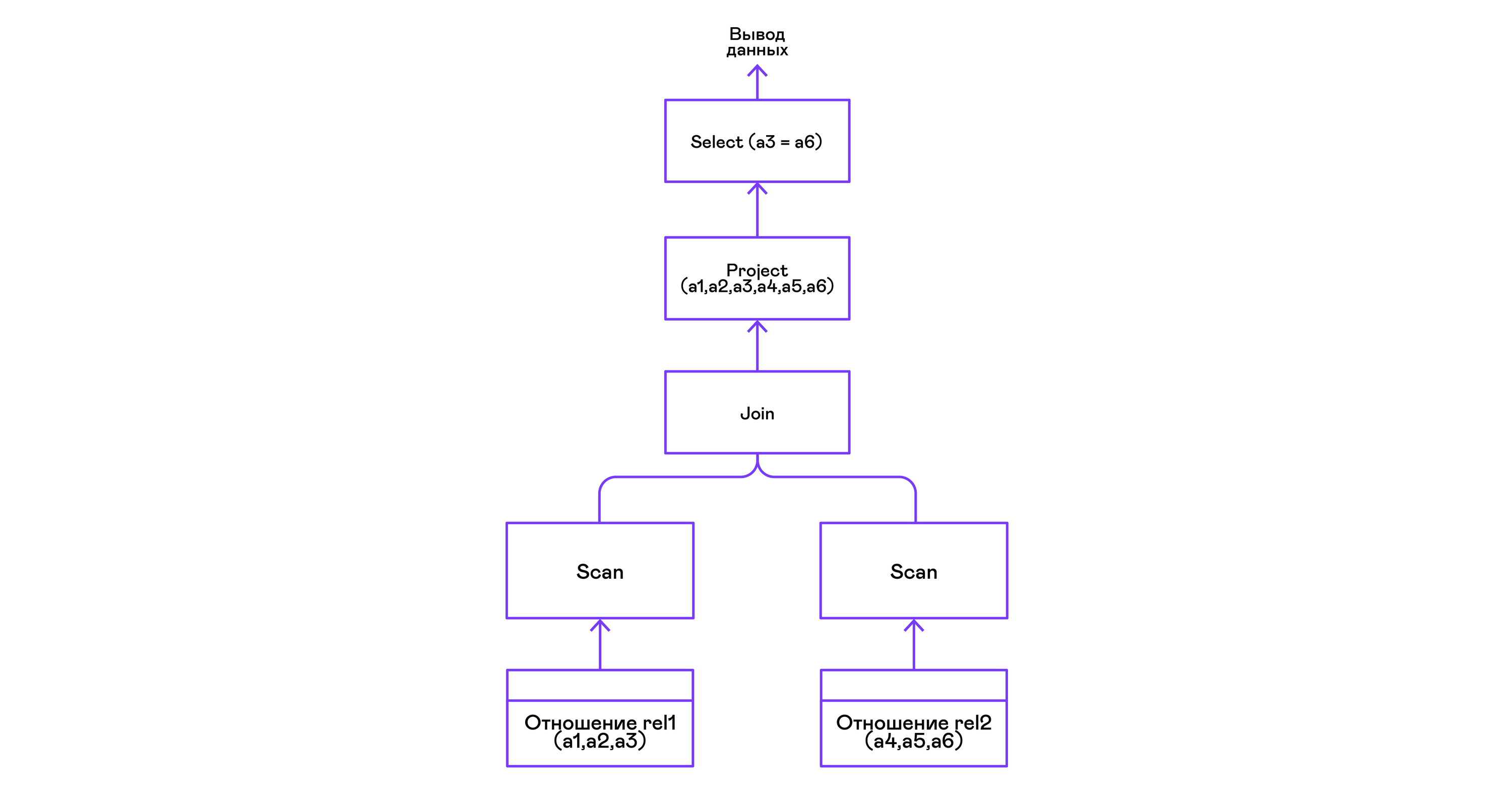
Conclusões
Concluindo, observo que, se você estiver criando um intérprete de uma linguagem semelhante ao SQL, provavelmente deverá usar qualquer um dos muitos bancos de dados relacionais disponíveis. Milhares de pessoas / ano foram investidas em otimizadores modernos e intérpretes de consulta de bancos de dados populares, e leva anos para desenvolver até os bancos de dados de uso geral mais simples.
A linguagem de demonstração PigletQL imita o trabalho do intérprete SQL, mas, na realidade, usamos apenas elementos individuais da arquitetura Volcano e apenas para aqueles (raros!) Tipos de consultas que são difíceis de expressar na estrutura do modelo relacional.
No entanto, repito: mesmo um conhecimento superficial da arquitetura de tais intérpretes é útil nos casos em que é necessário trabalhar de maneira flexível com fluxos de dados.
Literatura
Se você está interessado nas questões básicas do desenvolvimento de banco de dados, os livros são melhores que "Implementação do sistema de banco de dados" (Garcia-Molina H., Ullman JD, Widom J., 2000), você não encontrará.
Sua única desvantagem é uma orientação teórica. Pessoalmente, gosto quando exemplos concretos de código ou mesmo um projeto de demonstração são anexados ao material. Para isso, você pode consultar o livro “Design e implementação de banco de dados” (Sciore E., 2008), que fornece o código completo para um banco de dados relacional em Java.
Os bancos de dados relacionais mais populares ainda usam variações sobre o tema Volcano. A publicação original é escrita em uma linguagem muito acessível e pode ser facilmente encontrada no Google Scholar: “Volcano - um sistema extensivo e paralelo de avaliação de consultas” (Graefe G., 1994).
Embora os intérpretes SQL tenham mudado bastante em detalhes nas últimas décadas, a estrutura geral desses sistemas não mudou por um longo tempo. Você pode ter uma idéia disso em um artigo de revisão do mesmo autor, “Técnicas de avaliação de consultas para grandes bancos de dados” (Graefe G. 1993).