Olá Habr! Meu nome é Nikolai e estou envolvido na construção e implementação de modelos de aprendizado de máquina no Sberbank. Hoje vou falar sobre o desenvolvimento de um sistema de recomendação para pagamentos e transferências no aplicativo em seus smartphones.
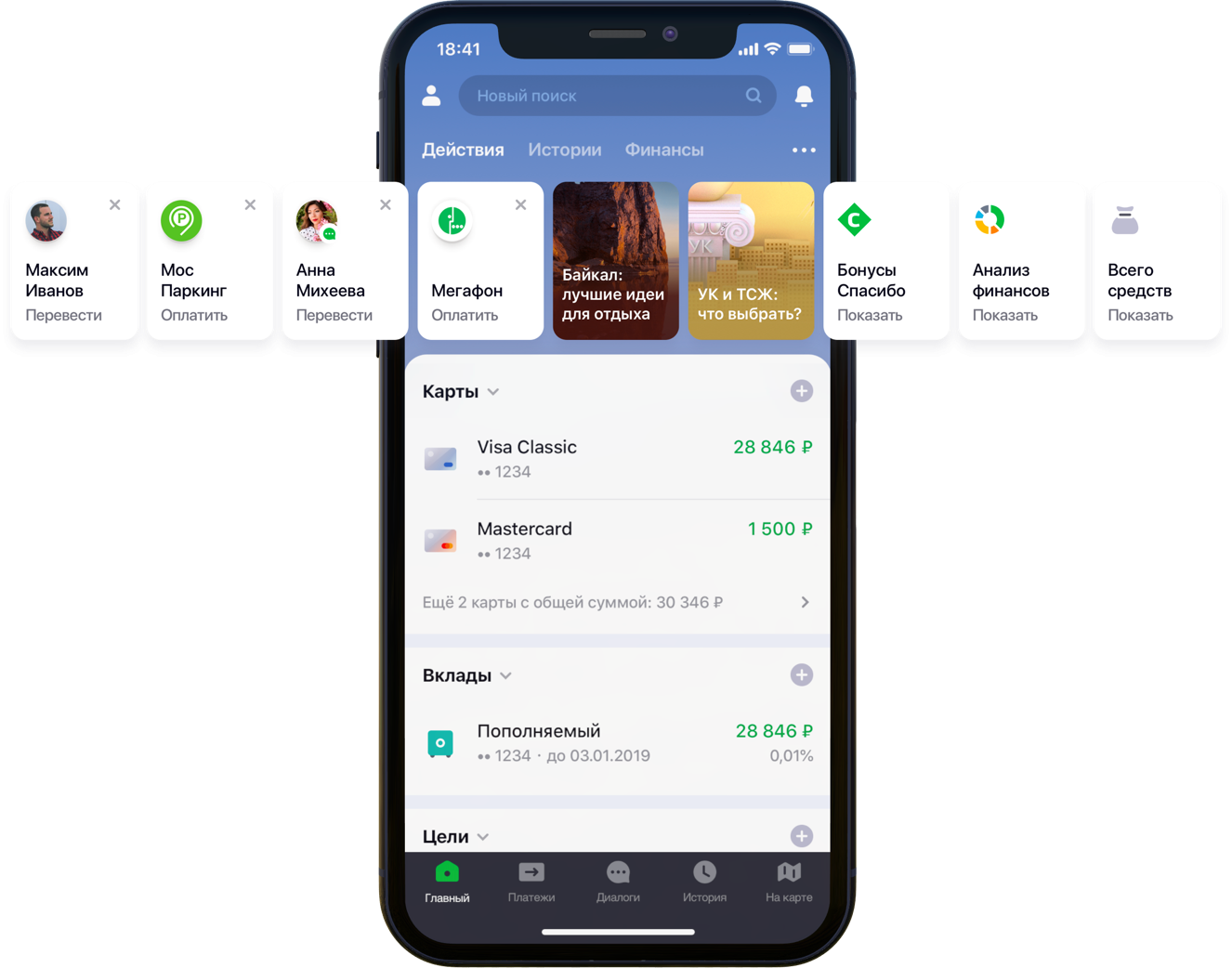 Design da tela principal do aplicativo móvel com recomendações
Design da tela principal do aplicativo móvel com recomendaçõesTínhamos duzentas mil opções de pagamento possíveis, 55 milhões de clientes, 5 fontes bancárias diferentes, meia coluna de desenvolvedor e uma montanha de atividades bancárias, algoritmos e tudo isso, todas as cores, além de um litro de sementes aleatórias, uma caixa de hiperparâmetros, meio litro de fatores de correção e dois dezenas de bibliotecas. Não que tudo isso fosse necessário no trabalho, mas desde que ele começou a melhorar a vida dos clientes, siga seu hobby até o fim. Sob o corte, está a história da batalha pelo UX, a formulação correta do problema, a luta contra a dimensionalidade dos dados, a contribuição para o código aberto e nossos resultados.
Declaração do problema
Conforme o desenvolvimento e a ampliação, o aplicativo Sberbank Online está ganhando recursos úteis e funcionalidades adicionais. Em particular, no aplicativo você pode transferir dinheiro ou pagar por serviços de várias organizações.
“Examinamos cuidadosamente todos os caminhos do usuário dentro do aplicativo e percebemos que muitos deles podem ser significativamente reduzidos. Para isso, decidimos personalizar a tela principal em várias etapas. Primeiro, tentamos remover da tela o que o cliente não usa, começando com cartões bancários. Depois, destacaram as ações que o cliente já havia executado anteriormente e para as quais ele poderia entrar no aplicativo agora. Agora, a lista de ações inclui pagamentos a organizações e transferências para contatos, e a lista de ações será ampliada ”, disse meu colega Sergey Komarov, que está desenvolvendo a funcionalidade do ponto de vista do cliente na equipe do Sberbank Online. É necessário construir um modelo que preencha os slots designados nos widgets Ações (figura acima) com recomendações pessoais de pagamentos e transferências, em vez de regras simples.
Solução
Nós da equipe decompusemos a tarefa em duas partes:
- a recomendação da repetição de operações para pagamento de serviços ou transferência de fundos (bloco "Operações recomendadas")
- recomendação de exemplos de solicitações de pesquisa para pagamento por serviços não utilizados anteriormente por este cliente (bloco "Exemplos de pesquisa")
Decidimos testar a funcionalidade primeiro na guia de pesquisa:
Design da tela de pesquisa recomendadaOperações recomendadas
Otimização de pontuação
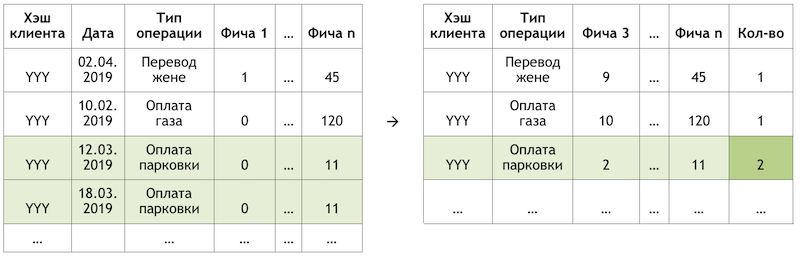
Se definirmos a subtarefa como uma recomendação para repetir operações, isso nos permitirá eliminar o cálculo e a avaliação de trilhões de combinações de todas as operações possíveis para todos os clientes e focar em um número muito mais limitado. Se, de todo o conjunto de operações disponíveis para nossos clientes, o cliente hipotético com o hash YYY utilizasse apenas pagamento por gás e estacionamento, avaliaremos a probabilidade de repetir apenas essas operações para este cliente:
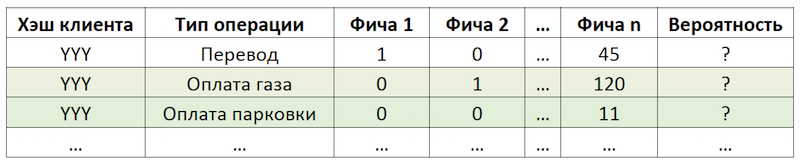 Um exemplo de redução da dimensão dos dados para pontuação
Um exemplo de redução da dimensão dos dados para pontuaçãoPreparando o conjunto de dados
A amostra é uma observação transacional, enriquecida com fatores de demografia de clientes, agregados financeiros e várias características de frequência de uma operação específica.
A variável de destino neste caso é binária e reflete o fato do evento no dia seguinte ao dia em que os fatores são calculados. Assim, movendo iterativamente o dia de calcular os fatores e definir o sinalizador da variável de destino, multiplicamos e marcamos as mesmas operações e as marcamos de maneira diferente, dependendo da posição relativa a esse dia.
Esquema de ObservaçãoCalculando o corte em 17/03/2019 para o cliente “AAA”, obtemos duas observações:
Um exemplo das observações para um conjunto de dados"Recurso 1" pode significar, por exemplo, o saldo em todos os cartões do cliente, "Recurso 2" - a presença desse tipo de operação na última semana.
Realizamos as mesmas transações, mas fazemos observações para treinamento em uma data diferente:
Esquema de ObservaçãoObteremos observações para um conjunto de dados com outros valores de ambos os recursos e a variável de destino:
 Um exemplo das observações para um conjunto de dados
Um exemplo das observações para um conjunto de dadosNos exemplos acima, para maior clareza, são fornecidos os valores reais dos fatores, mas, de fato, os valores são processados por um algoritmo automático: os resultados da
conversão WOE são alimentados na entrada do modelo. Permite trazer as variáveis para um relacionamento monotônico com a variável de destino e, ao mesmo tempo, livrar-se dos efeitos dos outliers. Por exemplo, temos o fator "Número de cartões" e alguma distribuição da variável de destino:
 Exemplo de conversão WOE
Exemplo de conversão WOEA transformação WOE nos permite transformar uma dependência não linear em pelo menos uma dependência monotônica. Cada valor do fator analisado está associado ao seu próprio valor WOE e, assim, um novo fator é formado, e o original é removido do conjunto de dados:
 O efeito da transformação WOE no relacionamento com a variável de destino
O efeito da transformação WOE no relacionamento com a variável de destinoO dicionário para converter valores variáveis em WOE é salvo e usado posteriormente para pontuação. Ou seja, se precisarmos calcular as probabilidades para amanhã, criamos um conjunto de dados como nas tabelas com exemplos de observações acima, convertemos as variáveis necessárias no WOE com o código salvo e aplicamos o modelo nesses dados.
Treinamento
A escolha do método foi estritamente limitada - interpretabilidade. Portanto, para cumprir os prazos, decidiu-se adiar as explicações usando o mesmo
SHAP na segunda metade do problema e testar métodos relativamente simples: regressão e neurônios superficiais. A ferramenta foi o SAS Miner, um software para pré-processamento, análise e criação de modelos em vários dados de forma interativa, o que economiza muito tempo na escrita de código.
 Interface do SAS Miner
Interface do SAS MinerAvaliação da qualidade
A comparação da métrica GINI em uma amostra fora do tempo mostrou que a rede neural lida melhor com a tarefa:
Tabela comparativa de modelos de qualidade e regras de frequênciaO modelo possui dois pontos de saída. As recomendações na forma de cartões de widgets na tela principal incluem operações cuja previsão está acima de um determinado limite (veja a primeira foto na publicação). A borda é selecionada com base em um equilíbrio de qualidade e cobertura, que nessa arquitetura representa metade de todas as operações executadas. As quatro principais operações são enviadas para o bloco “operações recomendadas” da tela de pesquisa (veja a segunda figura).
Exemplos de pesquisa
Passando para a segunda parte da tarefa, voltamos ao problema de um grande número de opções de pagamento possíveis para os serviços de provedores que precisam ser avaliados e classificados em cada cliente - trilhões de pares. Além disso, temos dados implícitos, ou seja, não há informações sobre a avaliação dos pagamentos efetuados ou por que o cliente não efetuou nenhum pagamento. Portanto, para iniciantes, foi decidido testar vários métodos de expansão da matriz de pagamentos de clientes para provedores: ALS e FM.
ALS
ALS (Mínimos Quadrados Alternados) ou Mínimos Quadrados Alternativos - na filtragem colaborativa, um dos métodos para resolver o problema de fatoração da matriz de interação. Apresentaremos nossos dados transacionais sobre pagamento de serviços na forma de uma matriz na qual as colunas são identificadores exclusivos dos serviços de todos os provedores e as linhas são clientes únicos. Nas células, colocamos o número de operações de clientes específicos com provedores específicos por um determinado período de tempo:
 Princípio de decomposição da matriz
Princípio de decomposição da matrizO significado do método é que criamos duas dessas matrizes de menor dimensão, cuja multiplicação dá o resultado mais próximo da matriz grande original nas células preenchidas. O modelo aprende a criar uma descrição fatorial oculta para clientes e fornecedores. Uma implementação do método na biblioteca
implícita foi usada. O treinamento ocorre de acordo com o seguinte algoritmo:
- Matrizes de clientes e provedores com fatores ocultos são inicializadas. O número deles é o hiperparâmetro do modelo.
- A matriz de fatores ocultos dos provedores é fixa e a derivada da função de perda para a correção da matriz do cliente é considerada. O autor usou um método interessante de gradientes conjugados , que permite acelerar bastante essa etapa.
- A etapa anterior é repetida da mesma forma para a matriz de fatores ocultos dos clientes.
- As etapas 2 a 3 se alternam até que o algoritmo converja.
Preparação
Os dados transacionais foram transformados em uma matriz de interações com um grau de escassez de ~ 99%, com grande desigualdade entre os provedores. Para separar os dados em amostras de treinamento e validação, mascaramos aleatoriamente a proporção de células preenchidas:
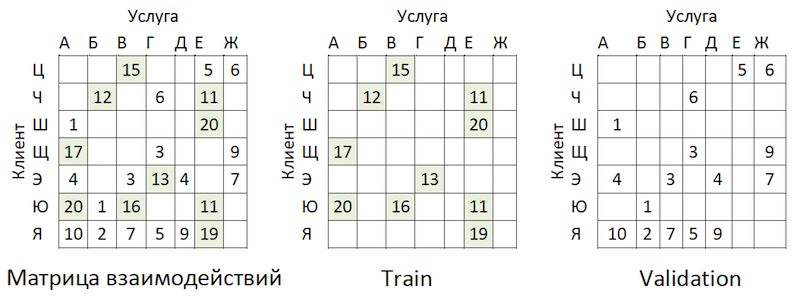 Exemplo de compartilhamento de dados
Exemplo de compartilhamento de dadosAs transações foram realizadas como teste no período subsequente ao treinamento e dispostas em uma matriz do mesmo formato - que ficou fora do tempo.
Treinamento
O modelo possui vários hiperparâmetros que podem ser ajustados para melhorar a qualidade:
- Alfa é o coeficiente pelo qual a matriz é ponderada, ajustando o grau de confiança ( C_iu ) de que o serviço fornecido é realmente "apreciado" pelo cliente.
- O número de fatores nas matrizes ocultas de clientes e provedores é o número de colunas e linhas, respectivamente.
- Coeficiente de regularização L2 λ.
- O número de iterações do método.
Utilizamos a biblioteca
hyperopt , que nos permite avaliar o efeito dos hiperparâmetros na métrica da qualidade usando o método
TPE e selecionar seu valor ótimo. O algoritmo começa com uma partida a frio e faz várias avaliações da métrica da qualidade, dependendo dos valores dos hiperparâmetros analisados. Então, em essência, ele tenta selecionar um conjunto de valores de hiperparâmetros com maior probabilidade de fornecer um bom valor para a métrica de qualidade. Os resultados são salvos em um dicionário a partir do qual você pode criar um gráfico e avaliar visualmente o resultado do otimizador (o azul é melhor):
O gráfico da dependência da métrica de qualidade na combinação de hiperparâmetrosO gráfico mostra que os valores dos hiperparâmetros afetam fortemente a qualidade do modelo. Como é necessário aplicar intervalos para cada um deles à entrada do método, o gráfico pode determinar ainda mais se faz sentido expandir o espaço de valor ou não. Por exemplo, em nossa tarefa, é claro que faz sentido testar grandes valores para o número de fatores. No futuro, isso realmente melhorou o modelo.
Métrica e complexidade da avaliação da qualidade
Como avaliar a qualidade do modelo? Uma das métricas mais comumente usadas para sistemas de recomendação em que a ordem é importante é
MAP @ k ou Precisão Média Média em K. Esta métrica estima a precisão do modelo nas recomendações K, levando em consideração a ordem dos itens na lista dessas recomendações, em média, para todos os clientes.
Infelizmente, uma operação de avaliação da qualidade, mesmo em uma amostra, levou várias horas. Depois de arregaçar as mangas, começamos a criar um perfil da função mean_average_pecision_at_k () com a biblioteca line_profiler. A tarefa foi ainda mais complicada pelo fato de a função usar código cython e ter que ser
levada em consideração corretamente, caso contrário, as estatísticas necessárias simplesmente não foram coletadas. Como resultado, novamente enfrentamos o problema da dimensionalidade de nossos dados. Para calcular essa métrica, é necessário obter todas as estimativas possíveis de cada serviço para cada cliente e selecionar as principais recomendações pessoais de K, classificando a matriz resultante. Mesmo considerando o uso da classificação parcial de numpy.argpartition () com complexidade O (n), classificar as notas acabou sendo o passo mais longo para aumentar a classificação da qualidade ao longo do tempo. Como o numpy.argpartition () não usou todos os kernels do nosso servidor, foi decidido melhorar o algoritmo reescrevendo essa parte no C ++ e no OpenMP via cython. Um algoritmo brevemente novo é o seguinte:
- Os dados são cortados em lotes pelos clientes.
- Uma matriz vazia e ponteiros para a memória são inicializados.
- As sequências de lotes por ponteiros são classificadas de duas maneiras: pela função parcial_sort e, em seguida, pela biblioteca de algoritmos C ++.
- Os resultados são gravados nas células da matriz vazia em paralelo.
- Os dados são retornados em python.
Isso nos permitiu acelerar o cálculo das recomendações várias vezes. A revisão foi
adicionada ao repositório oficial.
Análise de resultados OOT
E agora é hora de avaliar a qualidade do modelo. Por que precisamos de amostragem fora do tempo? Se observarmos a distribuição das operações pelos fornecedores, veremos a seguinte figura:
Distribuição da popularidade dos prestadores de serviçosHá um desequilíbrio. Isso leva ao fato de o modelo estar tentando recomendar serviços populares. De volta à imagem acima:
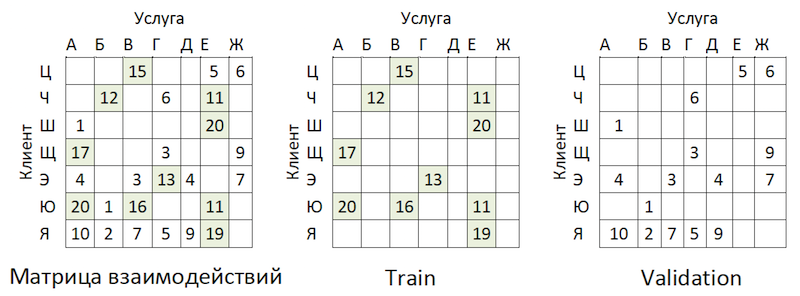
O problema é que, se você verificar a precisão do modelo, mascarando a mesma matriz, como é aconselhável em quase todos os lugares, para a maioria dos clientes (exemplos marginais: "W", "E" e "I") a qualidade das previsões de validação (fingiremos que ela não participou da seleção dos hiperparâmetros) será alta se esses forem os fornecedores mais populares. Como resultado, obtemos uma falsa confiança na força do modelo. Portanto, agimos da seguinte maneira:
- Estimativas formadas de fornecedores por modelo.
- Os pares de serviço ao cliente existentes foram excluídos das classificações (veja a figura abaixo) e das matrizes OOT.
- Formado a partir das classificações restantes das recomendações top-K e classificado como MAP @ k no OOT restante.
 A lógica de preparar a matriz para gerar previsões
A lógica de preparar a matriz para gerar previsõesComo linha de base, compilamos uma lista de fornecedores, classificados por popularidade, e a multiplicamos por todos os clientes, excluindo novamente os pares existentes de atendimento ao cliente. Acabou sendo triste e nem um pouco o que esperávamos e vimos nas amostras de trem \ validação:
Gráfico de comparação de qualidade de referência e modeloPare com isso! Temos fatores e parâmetros do cliente de fornecedores. Temos máquinas de fatoração.
FM
Máquinas de fatoração (máquina de fatoração) - um algoritmo de aprendizado com um professor, projetado para encontrar relações entre fatores que descrevem entidades em interação, que são apresentados na forma de matrizes esparsas. Usamos a implementação FM da biblioteca
LightFM .
Formato de dados
Além da matriz de interação normalizada, o
método usa dois conjuntos de dados adicionais com fatores para clientes e serviços de provedores na forma de matrizes codificadas um a quente conectadas a matrizes únicas:
 A lógica de preparar a matriz para gerar previsões
A lógica de preparar a matriz para gerar previsõesAvaliação da qualidade
A qualidade do modelo FM em nossos dados acabou sendo inferior à ALS:
Tabela comparativa de modelos de qualidade e linha de baseArquitetura do modelo de mudança - Boosting
Foi decidido entrar do outro lado. Recordando a distribuição da popularidade dos serviços, identificamos 300 deles, transações nas quais abrangem 80% de todas as operações, e treinamos um classificador neles. Aqui, os dados representam agregados de transações do cliente enriquecidas com os recursos do cliente:
 Esquema de agregação de transação
Esquema de agregação de transaçãoPor que apenas do lado do cliente, você pergunta? Como nesse caso, para preparar recomendações, será suficiente termos uma linha por cliente. Aplicando o modelo a ele, obtemos o vetor de probabilidades de saída para todas as classes, a partir do qual é fácil escolher as principais recomendações. Se adicionarmos os recursos dos serviços de provedor ao conjunto de treinamento, na fase de aplicação do modelo, seremos obrigados a preparar 300 linhas para cada cliente - um para cada serviço de provedor com recursos que os descrevem ou criar outro modelo para pré-classificar candidatos à pontuação .
A adição de recursos do ALS aos clientes não aumentou nossos dados, pois já levamos em conta a atividade transacional - por exemplo, em seções da MCC ou categorias no estilo de "jogador" ou "teatro". Nesse formato, conseguimos bons resultados:
Tabela comparativa de modelos de qualidade e linha de baseFiltro regional
Apesar da alta qualidade do modelo, mais um problema permanece nesta abordagem. Como a arquitetura dos dados e do modelo não implica o uso de recursos dos serviços dos provedores, o modelo não leva em consideração totalmente a geografia e pode recomendar que as pessoas paguem pelo serviço de um provedor local de outra região. Para minimizar esse risco, desenvolvemos um pequeno filtro para pré-cortar as opções antes de fazer recomendações. Um fluxo fácil de recursão é lançado no algoritmo:
- Coletamos informações sobre a região do cliente a partir de perfis bancários e outras fontes internas.
- Destacamos as principais regiões de presença para cada provedor.
- Esclarecemos / preenchemos as informações sobre a região do cliente pelas regiões dos fornecedores que ele usa.
Após essas manipulações, usando
o índice Herfindahl, separamos os provedores regionais, representados em um conjunto limitado de regiões, dos federais:
Separação de prestadores por presença nas regiõesFormamos uma máscara com fornecedores regionais aceitáveis para clientes e excluímos itens desnecessários das previsões do modelo antes de criar uma lista de recomendações.
Conclusão
Desenvolvemos dois modelos que juntos formam um conjunto completo de recomendações sobre pagamentos e transferências. Foi possível reduzir o caminho do cliente para metade das operações recorrentes em um clique. Nos planos futuros para melhorar o modelo de “operações recomendadas” usando dados de feedback (os cartões podem ser ocultos etc.), o que reduzirá o limite para a seleção de recomendações e aumentará a cobertura. Também está planejado expandir a cobertura dos pagamentos recomendados no modelo de "exemplos de pesquisa" e desenvolver um algoritmo para otimização da pontuação.
Percorremos o caminho difícil de construir um sistema de pagamentos e transferências recomendados. No caminho, tivemos problemas e adquirimos experiência na decomposição e simplificação de tarefas, avaliando corretamente esses sistemas, aplicabilidade de métodos, trabalho ideal com grandes quantidades de dados e expandimos significativamente nosso entendimento das especificidades de tais tarefas. Ao longo do caminho, consegui contribuir com o código aberto, que nós mesmos usamos. Desejo-lhe tarefas interessantes, linhas de base realistas e F1 única. Obrigado pela atenção!