O InterSystems IRIS DBMS suporta estruturas curiosas de armazenamento de dados - globais. De fato, são chaves de vários níveis com vários benefícios adicionais na forma de transações, funções rápidas para percorrer árvores de dados, bloqueios e sua própria linguagem ObjectScript.
Mais sobre globais na série de artigos “Globals - espadas-pedreiros para armazenamento de dados”:
As árvores Parte 1As árvores Parte 2Matrizes esparsas. Parte 3Tornou-se interessante para mim como as transações são implementadas no mundo, quais recursos existem. Afinal, essa é uma estrutura completamente diferente para armazenar dados do que as tabelas usuais. Nível muito mais baixo.
Como você sabe pela teoria do banco de dados relacional, uma boa implementação de transação deve atender aos requisitos do
ACID :
A - Atômica (atomicidade). Todas as alterações feitas na transação ou nenhuma são registradas.
C - Consistência. Após a conclusão da transação, o estado lógico do banco de dados deve ser consistente internamente. De muitas maneiras, esse requisito se aplica ao programador, mas, no caso de bancos de dados SQL, também se aplica a chaves estrangeiras.
I - isolar (isolamento). Transações paralelas não devem se afetar.
D - Durável. Depois que a transação é concluída com êxito, problemas nos níveis mais baixos (falta de energia, por exemplo) não devem afetar os dados alterados pela transação.
Globals são estruturas de dados não relacionais. Eles foram criados para um trabalho ultra-rápido em hardware muito limitado. Vamos entender a implementação de transações em globais usando a imagem
oficial do docker IRIS .
Para oferecer suporte a transações no IRIS, os seguintes comandos são usados:
TSTART ,
TCOMMIT ,
TROLLBACK .
1. Atomicidade
A maneira mais fácil de verificar a atomicidade. Verificando no console do banco de dados.
Kill ^a TSTART Set ^a(1) = 1 Set ^a(2) = 2 Set ^a(3) = 3 TCOMMIT
Então concluímos:
Write ^a(1), “ ”, ^a(2), “ ”, ^a(3)
Temos:
1 2 3
Está tudo bem. Atomicidade observada: todas as alterações são registradas.
Nós complicamos a tarefa, apresentamos um erro e vemos como a transação é salva, parcialmente ou não.
Vamos verificar a atomicidade mais uma vez:
Kill ^A TSTART Set ^a(1) = 1 Set ^a(2) = 2 Set ^a(3) = 3
Em seguida, pare o recipiente à força, inicie e veja.
docker kill my-iris
Este comando é quase equivalente ao desligamento forçado da energia, pois envia um sinal para interromper imediatamente o processo SIGKILL.
Talvez a transação tenha sido parcialmente salva?
WRITE ^a(1), ^a(2), ^a(3) ^ <UNDEFINED> ^a(1)
- Não, não preservado.
Teste o comando de reversão:
Kill ^A TSTART Set ^a(1) = 1 Set ^a(2) = 2 Set ^a(3) = 3 TROLLBACK WRITE ^a(1), ^a(2), ^a(3) ^ <UNDEFINED> ^a(1)
Nada foi preservado também.
2. Consistência
Como em bancos de dados globais, as chaves também são feitas em globais (lembro-me de que uma global é uma estrutura de nível inferior para armazenar dados que uma tabela relacional), para cumprir o requisito de consistência, você deve incluir a alteração de chave na mesma transação que a alteração global.
Por exemplo, temos uma pessoa global em que armazenamos personalidades e usamos o TIN como chave.
^person(1234567, 'firstname') = 'Sergey' ^person(1234567, 'lastname') = 'Kamenev' ^person(1234567, 'phone') = '+74995555555 ...
Para fazer uma pesquisa rápida por sobrenome e nome, criamos o índice ^ chave.
^index('Kamenev', 'Sergey', 1234567) = 1
Para que a base seja acordada, precisamos adicionar personalidades como esta:
TSTART ^person(1234567, 'firstname') = 'Sergey' ^person(1234567, 'lastname') = 'Kamenev' ^person(1234567, 'phone') = '+74995555555 ^index('Kamenev', 'Sergey', 1234567) = 1 TCOMMIT
Assim, ao excluir, também devemos usar a transação:
TSTART Kill ^person(1234567) ZKill ^index('Kamenev', 'Sergey', 1234567) TCOMMIT
Em outras palavras, o cumprimento do requisito de consistência cabe inteiramente ao programador. Mas quando se trata de globais, isso é normal, devido à sua natureza de baixo nível.
3. Isolamento
É aqui que os selvagens começam. Muitos usuários trabalham simultaneamente no mesmo banco de dados, modificam os mesmos dados.
A situação é comparável à situação em que muitos usuários trabalham simultaneamente com o mesmo repositório com o código e tentam confirmar alterações em muitos arquivos ao mesmo tempo.
O banco de dados deve resolver isso em tempo real. Considerando que, em empresas sérias, existe mesmo uma pessoa especial responsável pelo controle de versão (para mesclar filiais, resolver conflitos etc.), e o banco de dados deve fazer tudo isso em tempo real, a complexidade da tarefa e o design correto do banco de dados. o código que o serve.
O banco de dados não pode entender o significado das ações executadas pelos usuários para evitar conflitos se eles trabalharem nos mesmos dados. Só pode cancelar uma transação contrária a outra ou executá-las sequencialmente.
Outro problema é que, durante a execução da transação (antes da confirmação), o estado do banco de dados pode ser inconsistente; portanto, é desejável que outras transações não tenham acesso ao estado inconsistente do banco de dados, o que é alcançado em bancos de dados relacionais de várias maneiras: criação de instantâneos, linhas multiversões e etc.
Na execução paralela de transações, é importante para nós que elas não interfiram entre si. Essa é a propriedade do isolamento.
O SQL define 4 níveis de isolamento:
- LEIA NÃO COMPROMISSO
- LEIA COMPROMISSO
- LEITURA REPETÍVEL
- SERIALIZABLE
Vamos considerar cada nível separadamente. Os custos de implementação de cada nível estão crescendo quase exponencialmente.
LER NÃO COMPROMISSO é o nível mais baixo de isolamento, mas o mais rápido. As transações podem ler as alterações feitas uma pela outra.
LEIA COMPROMISSO é o próximo nível de isolamento, que é um compromisso. As transações não podem ler as alterações feitas antes da confirmação, mas podem ler as alterações feitas após uma confirmação.
Se tivermos uma transação longa T1, durante a qual houve confirmações nas transações T2, T3 ... Tn que funcionaram com os mesmos dados que T1, quando solicitarmos dados em T1, obteremos resultados diferentes a cada vez. Esse fenômeno é chamado de leitura não repetível.
REPEATABLE READ - neste nível de isolamento, não temos o fenômeno de leitura não repetível, devido ao fato de que, para cada solicitação de leitura de dados, é criado um instantâneo dos dados resultantes e, quando reutilizados na mesma transação, os dados do instantâneo são usados. No entanto, os dados fantasmas podem ser lidos nesse nível de isolamento. Isso se refere à leitura de novas linhas que foram adicionadas por transações confirmadas simultâneas.
SERIALIZABLE é o nível mais alto de isolamento. É caracterizado pelo fato de que os dados utilizados de qualquer forma na transação (leitura ou alteração) ficam disponíveis para outras transações somente após a conclusão da primeira transação.
Primeiro, vamos descobrir se há isolamento de operações em uma transação do thread principal. Vamos abrir 2 janelas de terminal.
Não há isolamento. Um segmento vê o que o segundo que abriu a transação faz.
Vamos ver se transações de diferentes fluxos veem o que está acontecendo dentro deles.
Abrimos 2 janelas de terminal e 2 transações em paralelo.
As transações simultâneas veem os dados um do outro. Portanto, obtivemos o nível de isolamento mais simples, mas também o mais rápido, LEIA NÃO COMPROMISSO.
Em princípio, isso poderia ser esperado para os globais, para os quais a velocidade sempre foi primordial.
Mas e se precisarmos de um nível mais alto de isolamento nas operações globais?
Aqui você precisa pensar sobre por que os níveis de isolamento são necessários e como eles funcionam.
O nível mais alto de isolamento de SERIALIZE significa que o resultado de transações executadas simultaneamente é equivalente à sua execução sequencial, o que garante a ausência de colisões.
Podemos fazer isso com a ajuda de bloqueios competentes no ObjectScript, que possuem diversas formas de aplicação: você pode executar bloqueios regulares, incrementais e múltiplos com o comando
LOCK .
Níveis mais baixos de isolamento são compensações projetadas para aumentar a velocidade do banco de dados.
Vamos ver como podemos alcançar diferentes níveis de isolamento usando bloqueios.
Esse operador permite que você faça não apenas os bloqueios exclusivos necessários para alterar dados, mas também os chamados compartilhados, que podem receber vários encadeamentos ao mesmo tempo, quando eles precisam ler dados que não devem ser alterados por outros processos durante a leitura.
Mais informações sobre o método de bloqueio bifásico em russo e inglês:
→
Bloqueio de duas fases→
Bloqueio bifásicoA dificuldade é que, durante a transação, o estado do banco de dados pode ser inconsistente; no entanto, esses dados inconsistentes são visíveis para outros processos. Como evitar isso?
Usando bloqueios, criaremos essas janelas de visibilidade nas quais o estado do banco de dados será acordado. E todas as chamadas para essas janelas de visibilidade do estado acordado serão controladas por bloqueios.
Bloqueios compartilhados dos mesmos dados são reutilizáveis - vários processos podem executá-los. Esses bloqueios impedem que outros processos alterem dados, ou seja, eles são usados para formar janelas com um estado consistente do banco de dados.
Bloqueios exclusivos são usados para modificar dados - apenas um processo pode aceitar esse bloqueio. O bloqueio exclusivo pode levar:
- Qualquer processo se os dados estiverem livres
- Somente o processo que possui um bloqueio compartilhado nesses dados e o primeiro solicitou um bloqueio exclusivo.
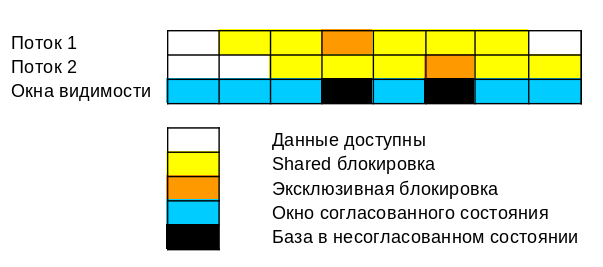
Quanto mais estreita a janela de visibilidade, mais tempo leva para outros processos aguardarem, mas mais consistente pode ser o estado do banco de dados.
READ_COMMITED - a essência desse nível é que apenas vemos dados de outros fluxos que estão bloqueados. Se os dados em outra transação ainda não foram confirmados, vemos a versão antiga.
Isso nos permite paralelizar o trabalho em vez de esperar que o bloqueio seja liberado.
Sem truques especiais, não poderemos ver a versão antiga dos dados no IRIS, portanto, temos a ver com bloqueios.
Assim, teremos que usar bloqueios compartilhados para permitir a leitura de dados apenas em momentos de consistência.
Suponha que tenhamos uma base de usuários ^ pessoa que transfira dinheiro entre si.
O momento da transferência da pessoa 123 para a pessoa 242:
LOCK +^person(123), +^person(242) Set ^person(123, amount) = ^person(123, amount) - amount Set ^person(242, amount) = ^person(242, amount) + amount LOCK -^person(123), -^person(242)
O momento de solicitar a quantia em dinheiro da pessoa 123 antes do débito deve ser acompanhado por um bloqueio exclusivo (por padrão):
LOCK +^person(123) Write ^person(123)
E se você precisar mostrar o status da conta, poderá usar o bloqueio compartilhado ou não usá-lo:
LOCK +^person(123)
No entanto, se assumirmos que as operações do banco de dados são executadas quase instantaneamente (lembro que os globais são uma estrutura de nível muito inferior a uma tabela relacional), a necessidade desse nível diminui.
LEITURA REPETIDA - Nesse nível de isolamento,
supõe -
se que possa haver várias leituras de dados que podem ser modificadas por transações simultâneas.
Assim, teremos de colocar um bloqueio compartilhado na leitura dos dados que estamos alterando e bloqueios exclusivos nos dados que estamos alterando.
Felizmente, o operador LOCK permite que um operador liste em detalhes todos os bloqueios necessários, que podem ser muitos.
LOCK +^person(123, amount)
outras operações (no momento, threads paralelos tentam alterar ^ person (123, quantidade), mas não podem)
LOCK +^person(123, amount) ^person(123, amount) LOCK -^person(123, amount) ^person(123, amount) LOCK -^person(123, amount)
Ao listar bloqueios separados por vírgulas, eles são obtidos sequencialmente e, se você fizer isso:
LOCK +(^person(123),^person(242))
então eles são tomados atomicamente de uma só vez.
SERIALIZE - teremos que definir os bloqueios para que, finalmente, todas as transações que tenham dados comuns sejam executadas seqüencialmente. Para essa abordagem, a maioria dos bloqueios deve ser exclusiva e levada para as menores áreas do mundo para desempenho.
Se falarmos sobre baixas contábeis na pessoa global ^, somente o nível de isolamento SERIALIZE é aceitável para ele, pois o dinheiro deve ser gasto estritamente em sequência, caso contrário, é possível gastar a mesma quantia várias vezes.
4. Durabilidade
Realizei testes com o corte duro do contêiner através
docker kill my-iris
A base os tolerou bem. Nenhum problema foi identificado.
Conclusão
Para globais, o InterSystems IRIS tem suporte a transações. Eles são verdadeiramente atômicos, confiáveis. Para garantir a consistência do banco de dados em globais, são necessários os esforços do programador e o uso de transações, pois não há construções internas complexas, como chaves estrangeiras.
O nível de isolamento de globais sem o uso de bloqueios é LIDO NÃO COMPROMETIDO e, ao usar bloqueios, pode ser garantido até o nível SERIALIZE.
A correção e a velocidade das transações em globais dependem muito da habilidade do programador: quanto mais bloqueios compartilhados forem usados na leitura, maior será o nível de isolamento e mais bloqueios exclusivos serão realizados, maior a velocidade.