Este artigo é uma espécie de classe master "DVC para automatizar experimentos de ML e versionamento de dados", que ocorreu em 18 de junho no ML REPA (Machine Learning REPA:
Reprodutibilidade, Experiências e Automação de Dutos) em nosso banco.
Aqui vou falar sobre os recursos do trabalho interno do DVC e como usá-lo em projetos.
Os exemplos de código usados no artigo estão disponíveis
aqui . O código foi testado no MacOS e Linux (Ubuntu).
Conteúdo
Parte 1
Parte 2
Configuração DVC
O Controle de versão de dados é uma ferramenta projetada para gerenciar versões de modelo e dados em projetos de ML. É útil tanto na fase experimental quanto para implantar seus modelos em operação.
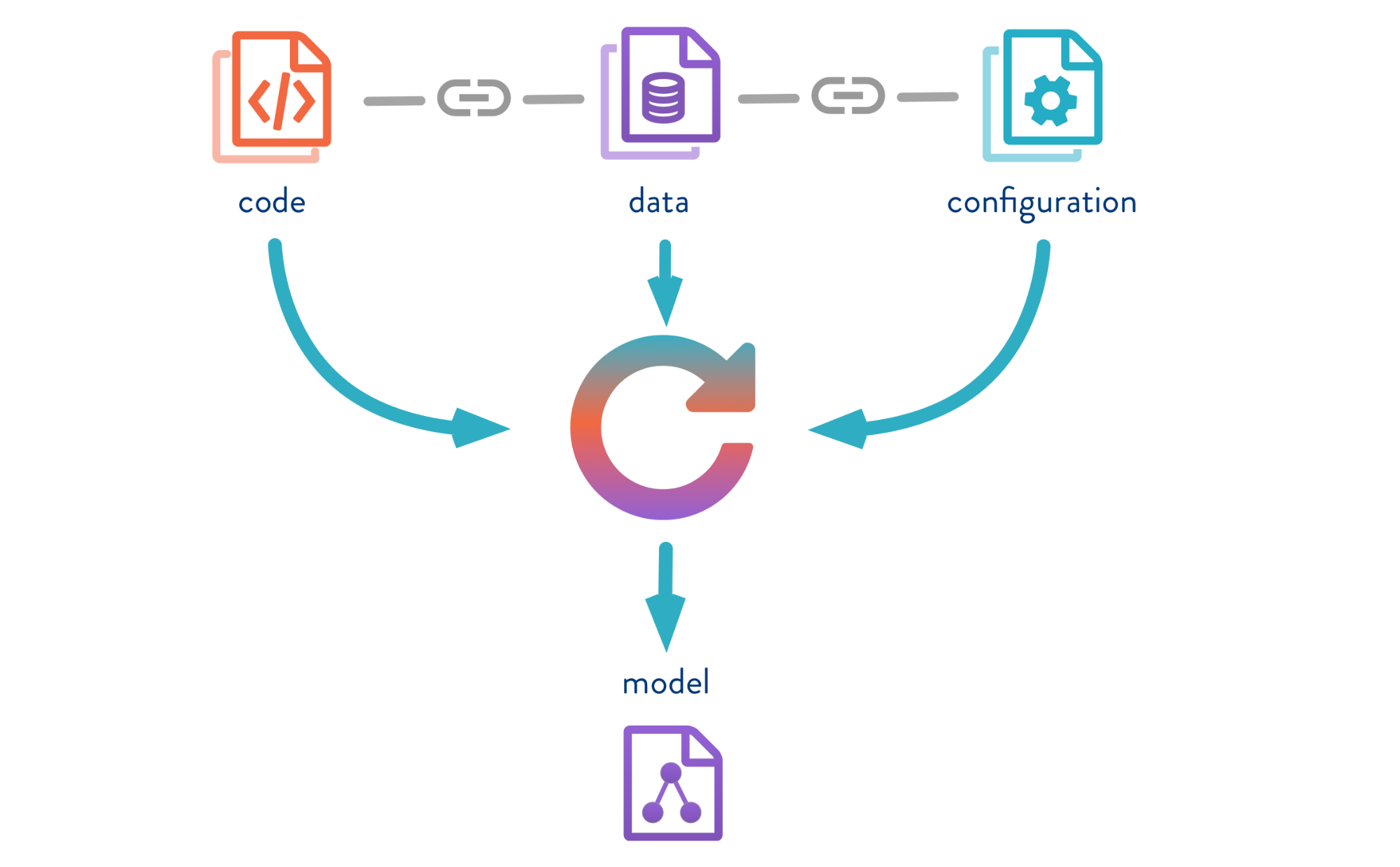
O DVC permite a versão de modelos, dados e pipelines em projetos do DS.
A fonte está
aqui .
Vejamos a operação do DVC usando o exemplo do problema de classificação de cores da íris. Para isso, o
Iris Data Set será usado. Outros
exemplos de trabalho com DVC são mostrados pelo Jupyter Notebook.
O que você precisa fazer:Então, clonamos o repositório, criamos um ambiente virtual e instalamos os pacotes necessários. As instruções de instalação e ativação estão no repositório README.
1. Clone este repositório
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Crie e ative o ambiente virtual
pip install virtualenv virtualenv venv source venv/bin/activate
3. Instale bibliotecas python (incluindo dvc)
pip install -r requirements.txt
Para instalar o DVC, use o comando
pip install dvc . Após a instalação, você deve inicializar o DVC na pasta do projeto
dvc init do
dvc init , que gerará um conjunto de pastas para trabalhos futuros do DVC.
4. faça o checkout do novo branch no repositório demo (para não limpar o conteúdo do master branch)
git checkout -b dvc-tutorial
5. Inicialize o DVC
dvc init commit dvc init git commit -m "Initialize DVC"
O DVC roda em cima do Git, usa sua infraestrutura e possui sintaxe semelhante.
No processo, o DVC cria metarquivos para descrever pipelines e arquivos com versão, que você precisa salvar no Git o histórico do seu projeto. Portanto, após executar o
dvc init você deve executar o
git commit para confirmar todas as configurações feitas.
A pasta
.dvc aparecerá no seu repositório, na qual o
cache e a
config estarão.
O conteúdo de
.dvc ficará assim:
./ ../ .gitignore cache/ config
Config é a configuração do DVC e cache é a pasta do sistema na qual o DVC armazenará todos os dados e modelos que você fará a versão.
O DVC também criará um arquivo
.gitignore , no qual
.gitignore os arquivos e pastas que não precisam ser confirmados no repositório. Quando você transfere um arquivo para o DVC para controle de versão no Git, as versões e os metadados serão salvos e o próprio arquivo será armazenado em cache.
Agora você precisa instalar todas as dependências e, em seguida, fazer um
checkout no novo ramo
dvc-tutorial , no qual trabalharemos. E faça o download do conjunto de dados Iris.
Obter dados
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Recursos DVC
Modelos e dados de versão
A fonte está
aqui .
Deixe-me lembrá-lo que, se você transferir alguns dados sob o controle do DVC, eles começarão a rastrear todas as alterações. E podemos trabalhar com esses dados da mesma maneira que com o Git: salve a versão, envie-a para o repositório remoto, obtenha a versão correta dos dados, altere e alterne entre versões. A interface no DVC é muito simples.
Digite o comando
dvc add e especifique o caminho para o arquivo que precisamos versão. O DVC criará o metarquivo iris.csv com a extensão .dvc e gravará informações sobre ele na pasta de cache. Vamos confirmar essas alterações para que as informações sobre o início do controle de versão apareçam no histórico do Git.
dvc add data/iris.csv
Dentro do arquivo dvc gerado, seu hash é armazenado com parâmetros padrão.
Output - o caminho para o arquivo na pasta dvc, que adicionamos sob o controle do DVC. O sistema pega os dados, os coloca no cache e cria um link para o cache no diretório de trabalho. Este arquivo pode ser adicionado ao histórico do Git e, portanto, versionado. O DVC assume o gerenciamento dos próprios dados. Os dois primeiros caracteres do hash são usados como a pasta dentro do cache e os caracteres restantes são usados como o nome do arquivo criado.
 Automação de gasodutos ML
Automação de gasodutos MLAlém do controle de versão de dados, podemos criar pipelines (pipelines) - cadeias de cálculos entre as quais dependências são definidas. Aqui está o pipeline padrão para treinamento e avaliação de classificadores:
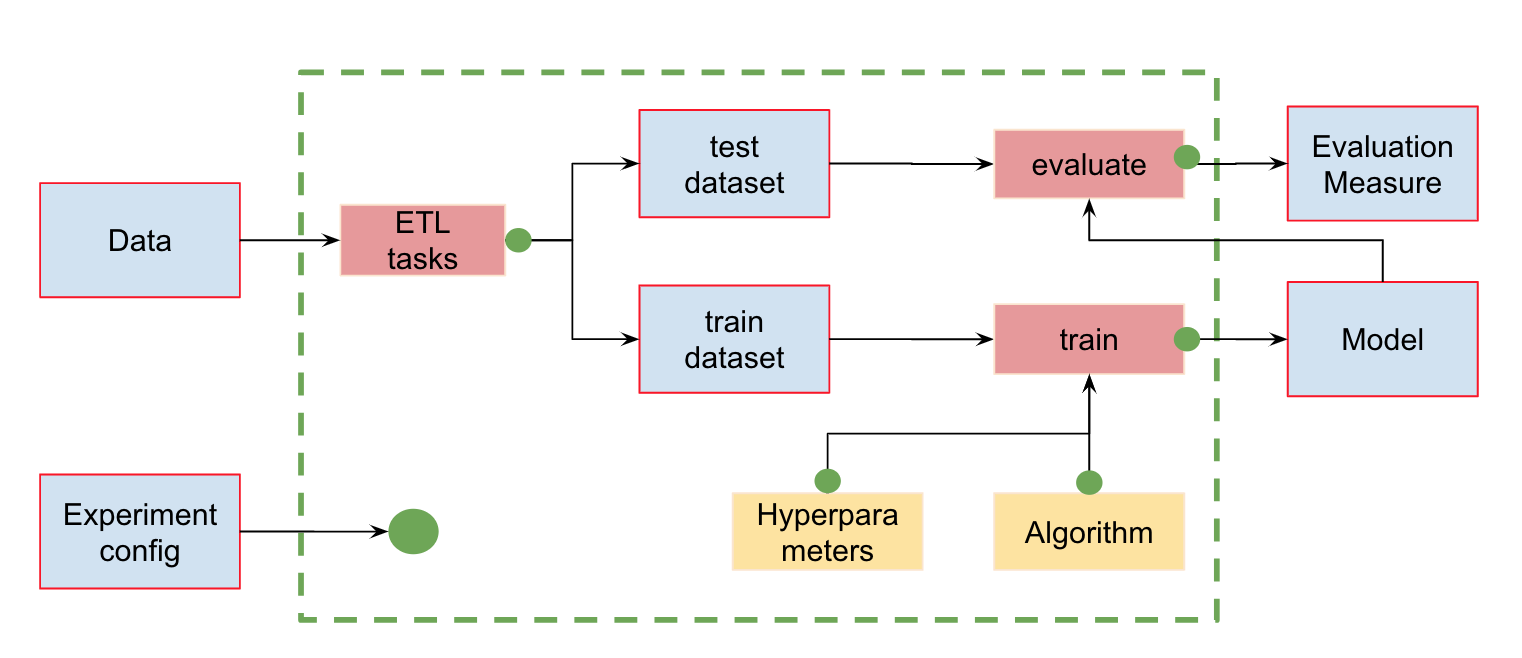
Na entrada, temos dados que devem ser pré-processados, divididos em treinar e testar, calcular as características e somente então treinar o modelo e avaliá-lo. Esse pipeline pode ser dividido em partes separadas. Por exemplo, para distinguir o estágio de carregamento e pré-processamento de dados, divisão de dados, avaliação, etc. e conexão dessas cadeias.
Para fazer isso, o DVC possui um maravilhoso comando
dvc run , no qual passamos certos parâmetros e especificamos o módulo Python que precisamos executar.
Agora - por exemplo, a fase de lançamento do cálculo dos sinais. Primeiro, consulte o conteúdo do módulo featureization.py:
import pandas as pd def get_features(dataset): features = dataset.copy()
Esse código pega o conjunto de dados, calcula as características e as salva em iris_featurized.csv. Deixamos o cálculo de sinais adicionais para a próxima etapa.
Para criar um pipeline, você precisa executar o comando para cada estágio do cálculo
dvc run .

Primeiro, no comando
dvc run , especifique o nome do metarquivo stage_feature_extraction.dvc, no qual o DVC gravará os metadados necessários sobre o estágio de cálculo. Através do argumento
-d , especificamos as dependências necessárias: o módulo featureization.py e o arquivo de dados iris.csv. Também especificamos o arquivo iris_featurized.csv, no qual os sinais são salvos, e o próprio comando python src / featurization.py launch.
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
O DVC criará um metarquivo e acompanhará as alterações no módulo Python e no arquivo iris.csv.
Se ocorrerem alterações, o DVC reiniciará esta etapa de cálculo no pipeline.
O arquivo stage_feature_extraction.dvc resultante conterá seu hash, comando start, dependências e saída (existem parâmetros adicionais para eles que podem ser encontrados nos metadados).
Agora você precisa salvar este arquivo no histórico de confirmações do Git. Assim, podemos criar um novo ramo e enviá-lo para o repositório Git. Você pode se comprometer com uma história do Git criando cada estágio individualmente ou todos os estágios de uma só vez.
Quando construímos essa cadeia para todo o experimento, o DVC cria um gráfico de computação (DAG), pelo qual ele pode iniciar o recálculo de todo o pipeline ou de alguma parte. Os hashes da saída de um estágio vão para os inputs de outro. Segundo eles, o DVC rastreia dependências e constrói um gráfico de cálculos. Se você alterou o código em algum lugar em split_dataset.py, o DVC não carregará os dados e possivelmente recalculará os sinais, mas reiniciará esse estágio e os estágios subsequentes de treinamento e avaliação.
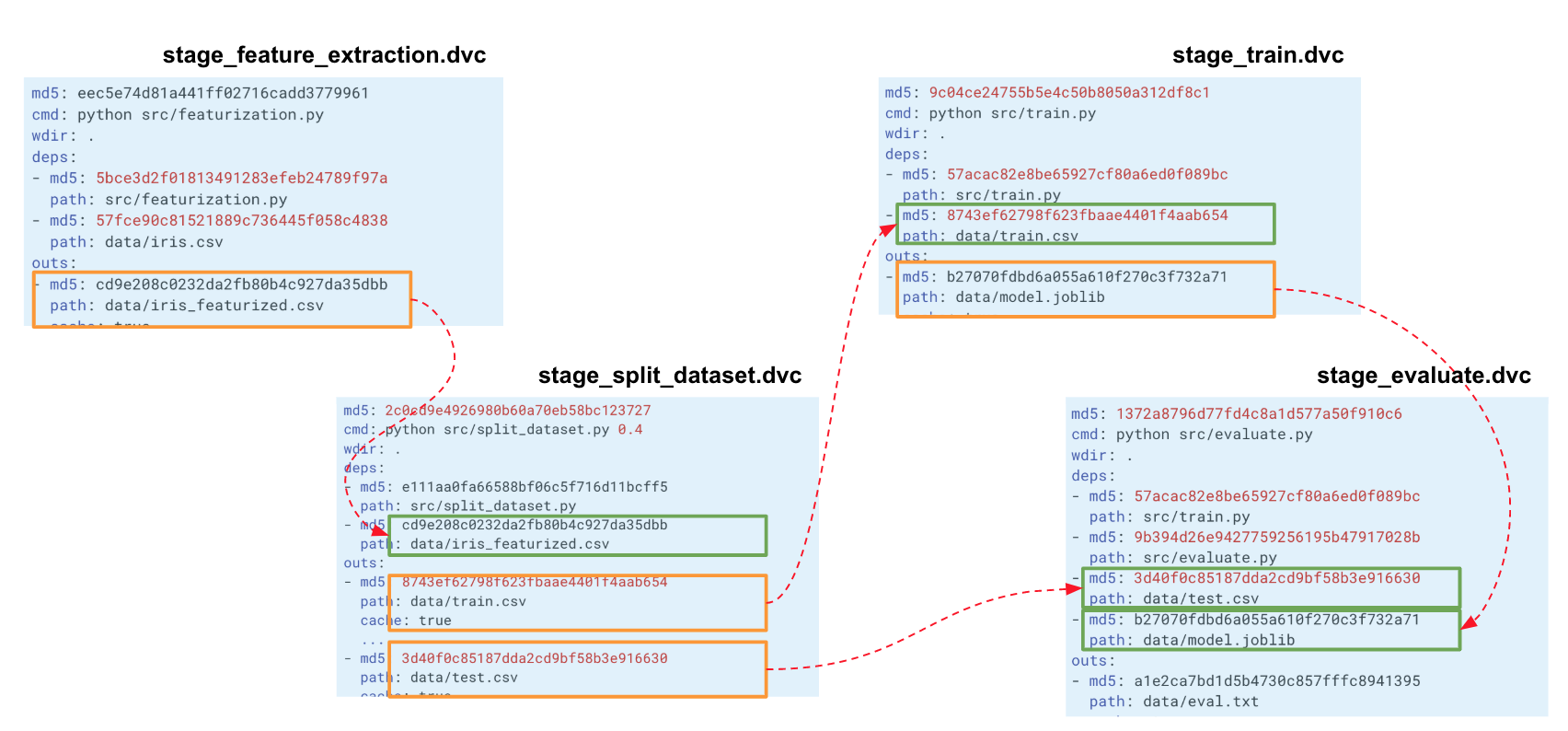 Rastreamento de métricas
Rastreamento de métricasUsando o comando
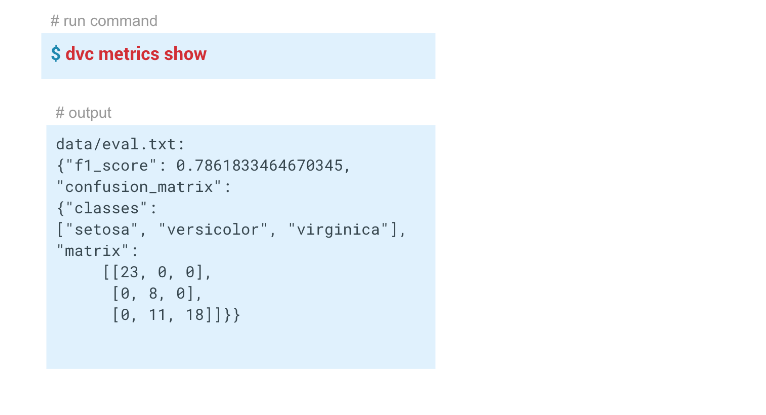
dvc metrics show , é possível exibir as métricas do lançamento atual, a filial em que estamos localizados. E se passarmos a opção
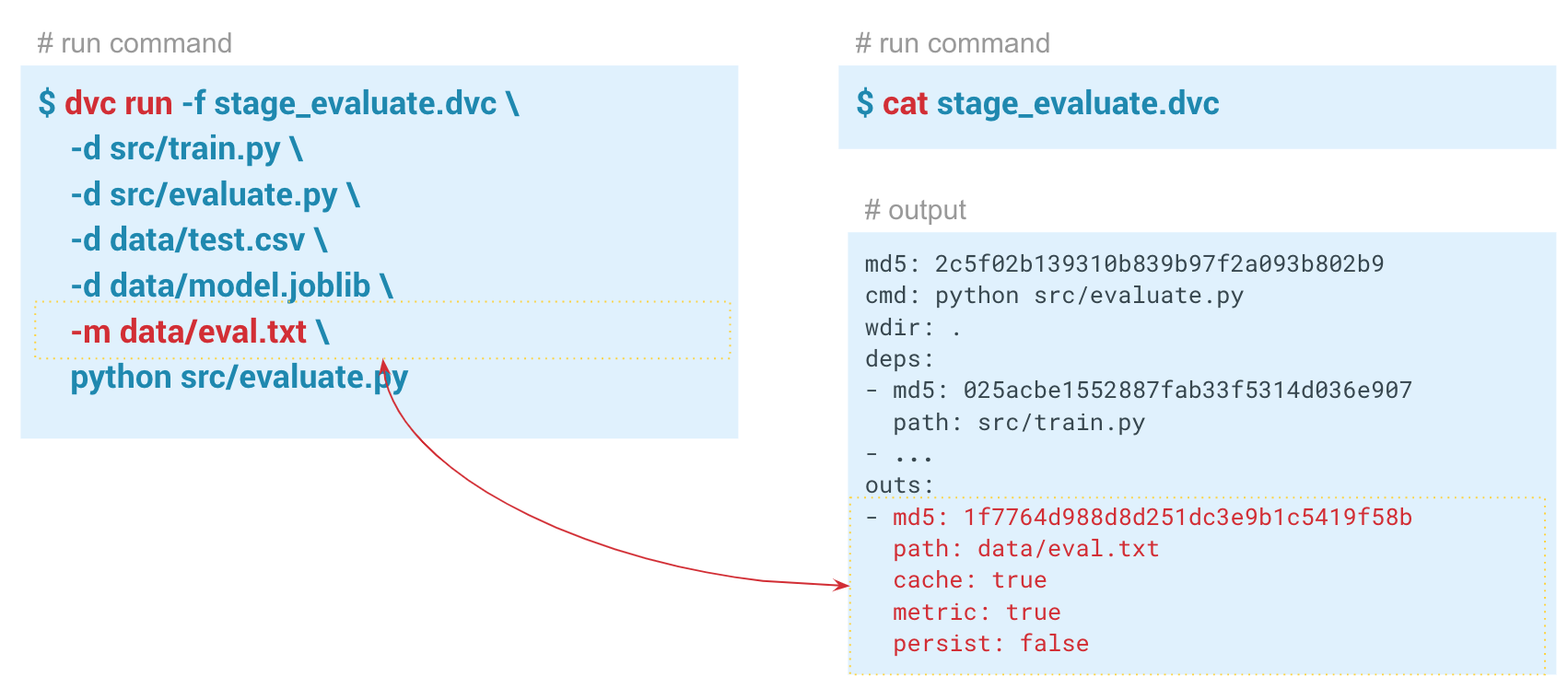
-a , o DVC mostrará todas as métricas que estão no histórico do Git. Para que o DVC comece a rastrear métricas, ao criar a etapa de avaliação, passamos o parâmetro
-m por data / eval.txt. O módulo assessment.py grava métricas nesse arquivo, neste caso,
confusion metrics f1 e
confusion metrics . Na pasta de saída no arquivo dvc desta etapa, o
cache e as
metrics definidos como true. Ou seja, o comando dvc metrics show produzirá o conteúdo do arquivo eval.txt para o console. Além disso, usando os argumentos deste comando, você pode mostrar apenas
f1_score ou apenas
confusion_matrix .
Neste exemplo, obtivemos estes resultados:
 Reprodutibilidade do pipeline
Reprodutibilidade do pipelineQuem trabalhou com esse conjunto de dados sabe que é muito difícil criar um bom modelo nele.
Agora temos um pipeline criado usando o DVC. O sistema rastreia o histórico de dados e o modelo, pode reiniciar-se no todo ou em parte e pode exibir métricas. Concluímos toda a automação necessária.
Tivemos um modelo com f1 = 0,78. Queremos melhorá-lo alterando alguns parâmetros. Para fazer isso, reinicie o pipeline inteiro, idealmente, com um único comando. Além disso, se você estiver trabalhando em equipe, pode passar o modelo e o código aos colegas para que eles possam continuar trabalhando neles.
O
dvc repro permite reiniciar pipelines ou estágios individuais (nesse caso, você precisa especificar o estágio reproduzido após o comando).
dvc repro stage_evaluate , o estágio tentará reiniciar o pipeline inteiro. Mas se fizermos isso no estado atual, o DVC não verá nenhuma alteração e não será reiniciado. E se mudarmos algo, ele encontrará a mudança e reiniciará o pipeline a partir desse momento.
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
Nesse caso, o DVC não viu nenhuma alteração nas dependências do estágio stage_evaluate e recusou-se a reiniciar. E se especificarmos a opção
-f , ela reiniciará todas as etapas preliminares e exibirá um aviso de que exclui versões anteriores dos dados dos quais estava rastreando. Cada vez que o DVC reinicia o estágio, ele exclui o cache anterior, na verdade o substitui para não duplicar os dados. No momento em que o arquivo DVC é iniciado, seu hash será verificado e, se tiver sido alterado, o pipeline será reiniciado e substituirá toda a saída desse pipeline. Se você quiser evitar isso, primeiro execute uma versão específica dos dados em algum repositório remoto.
A capacidade de reiniciar pipelines e rastrear as dependências de cada estágio permite que você experimente modelos mais rapidamente.
Por exemplo, você pode alterar as características ('descomente' as linhas para calcular as características em
featurization.py ). O DVC verá essas alterações e reiniciará todo o pipeline.
Salvando Dados em um Repositório Remoto
O DVC pode funcionar não apenas com o armazenamento da versão local. Se você executar o comando
dvc push , o DVC enviará a versão atual do modelo e os dados para um repositório de repositório remoto pré-configurado. Se o seu colega fizer o
git clone seu repositório e do
dvc pull , ele obterá a versão dos dados e modelos destinados a esse ramo. O principal é que todos tenham acesso a este repositório.
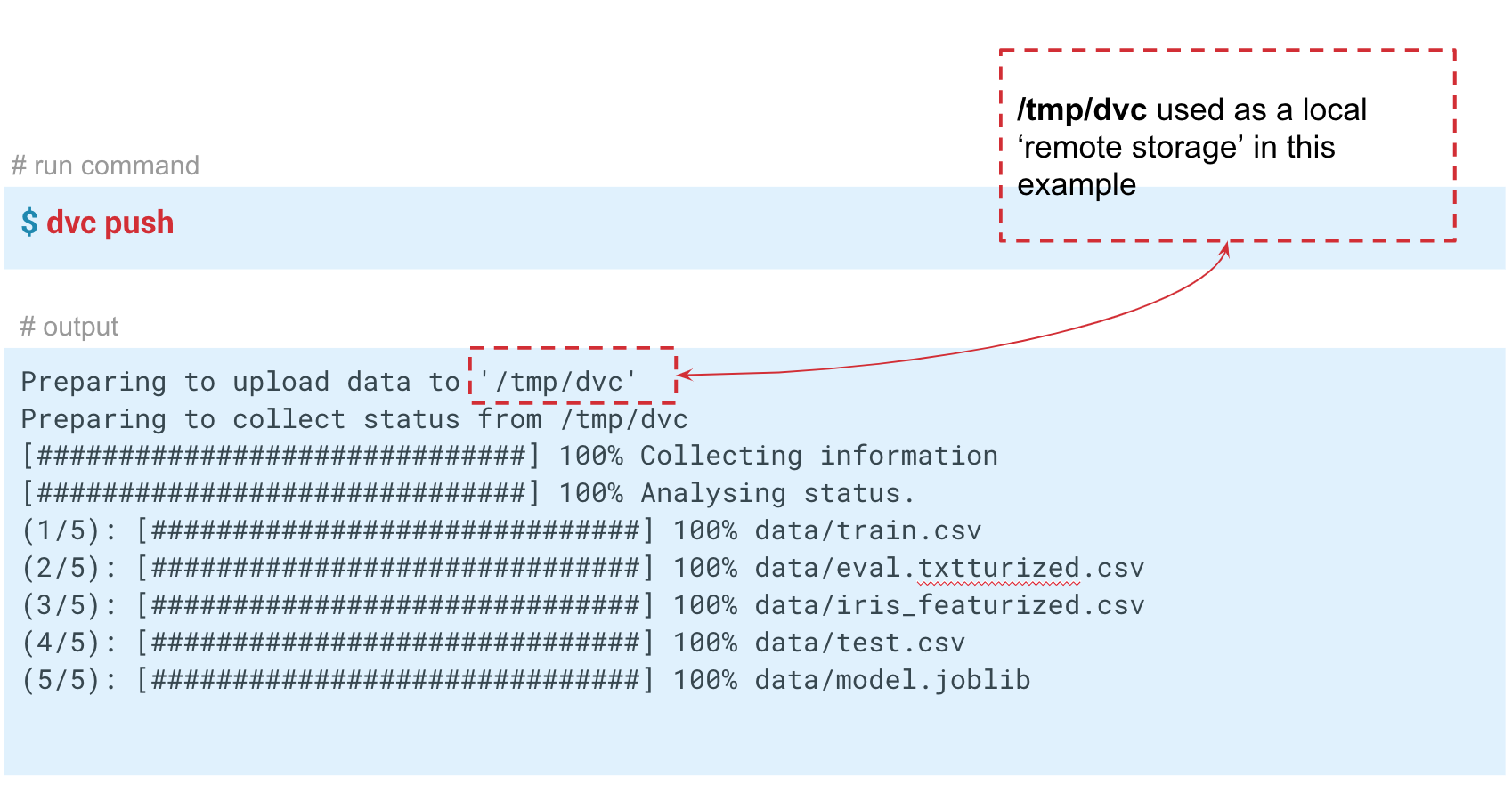
Nesse caso, simulamos o armazenamento "remoto" na pasta temp / dvc. Da mesma maneira, o armazenamento remoto é criado na nuvem. Confirme essa alteração para que ela permaneça na história do Git. Agora podemos fazer o
dvc push para enviar dados para esse armazenamento, e seu colega simplesmente faz o
dvc pull para obtê-lo.
Portanto , examinamos três situações nas quais o DVC e a funcionalidade básica são úteis:
- Dados e modelos de versão . Se você não precisar de pipelines e repositórios remotos, poderá fazer a versão dos dados para um projeto específico, trabalhando na máquina local. O DVC permite que você trabalhe rapidamente com dados em dezenas de gigabytes.
- Troca de dados e modelos entre equipes . Você pode usar soluções em nuvem para armazenar dados. Essa é uma opção conveniente se você tiver uma equipe distribuída ou houver restrições sobre o tamanho dos arquivos enviados por correio. Além disso, essa técnica pode ser usada em situações em que você envia um Notebook, mas eles não iniciam.
- Organização do trabalho em equipe em um servidor grande . A equipe pode trabalhar com a versão local do big data, por exemplo, várias dezenas ou centenas de gigabytes, para que você não os copie de um lado para outro, mas use um armazenamento remoto que enviará e salvará apenas versões críticas de modelos ou dados.
Parte 2
Como implementar o DVC em seus projetos?Para garantir a reprodutibilidade do projeto, certos requisitos devem ser observados.
Aqui estão os principais:
- todos os pipelines são automatizados;
- controle dos parâmetros de lançamento de cada etapa dos cálculos;
- controle de versão de código, dados e modelos;
- controle ambiental;
- a documentação.
Se tudo isso for feito, é mais provável que o projeto seja reproduzível. O DVC permite que você cumpra os três primeiros requisitos desta lista.
Ao tentar implementar o DVC em sua empresa, você pode encontrar relutância: “Por que precisamos disso? Temos um caderno Jupyter. " Talvez alguns de seus colegas trabalhem apenas com o Jupyter Notebook, e é muito mais difícil para eles escrever esses pipelines e códigos no IDE. Nesse caso, você pode passar por uma implementação passo a passo.
- A maneira mais fácil de começar é fazer a versão do código e dos modelos.
E, em seguida, passe a automatizar os pipelines - Primeiro automatize as etapas que geralmente são reiniciadas e alteradas,
e depois todo o pipeline.
Se você tem um novo projeto e alguns entusiastas em uma equipe, é melhor usar o DVC imediatamente. Então, por exemplo, aconteceu em nossa equipe! Ao iniciar um novo projeto, meus colegas me apoiaram e começamos a usar o DVC por conta própria. Então eles começaram a compartilhar com outros colegas e equipes. Alguém assumiu o nosso compromisso. Hoje, o DVC ainda não é uma ferramenta geralmente aceita em nosso banco, mas é usada em vários projetos.