Nota perev. : Apresentamos à sua atenção detalhes técnicos sobre os motivos da recente interrupção no serviço em nuvem, atendido pelos criadores da Grafana. Este é um exemplo clássico de como um recurso novo e aparentemente extremamente útil projetado para melhorar a qualidade da infraestrutura ... pode causar muito dano se não se prever as inúmeras nuances de sua aplicação nas realidades da produção. É maravilhoso quando esses materiais aparecem, permitindo que você aprenda não apenas com seus erros. Os detalhes estão na tradução deste texto do vice-presidente de produto da Grafana Labs.
Na sexta-feira, 19 de julho, o serviço Hosted Prometheus na Grafana Cloud parou de funcionar por cerca de 30 minutos. Peço desculpas a todos os clientes que sofreram com o fracasso. Nossa tarefa é fornecer as ferramentas necessárias para o monitoramento e entendemos que a inacessibilidade deles complica sua vida. Levamos esse incidente muito a sério. Esta nota explica o que aconteceu, como reagimos a ele e o que estamos fazendo para que isso não aconteça novamente.
Antecedentes
O serviço Grafana Cloud Hosted Prometheus é baseado no
Cortex , um projeto CNCF para criar um serviço Prometheus horizontalmente escalável, altamente acessível e com vários locatários. A arquitetura Cortex consiste em um conjunto de microsserviços separados, cada um dos quais desempenha sua função: replicação, armazenamento, solicitações etc. O Cortex está sendo desenvolvido ativamente, está constantemente tendo novas oportunidades e melhorando a produtividade. Implementamos regularmente novas versões do Cortex em clusters para que os clientes possam aproveitar essas oportunidades - felizmente, o Cortex pode atualizar sem tempo de inatividade.
Para atualizações tranqüilas, o serviço Ingester Cortex requer uma réplica adicional do Ingester durante o processo de atualização.
( Nota : o Ingester é o componente principal do Cortex. Sua tarefa é coletar um fluxo constante de amostras, agrupá-las em partes do Prometheus e armazená-las em um banco de dados como DynamoDB, BigTable ou Cassandra.) Isso permite Ingesters mais antigos. encaminhar dados atuais para novos Ingesters. Vale a pena notar que os Ingesters estão exigindo recursos. Para o trabalho deles, é necessário ter 4 núcleos e 15 GB de memória por pod, ou seja, 25% da energia e memória do processador da máquina base no caso de nossos clusters Kubernetes. Em geral, geralmente temos muito mais recursos não utilizados em um cluster do que 4 núcleos e 15 GB de memória, para que possamos executar facilmente esses Ingesters adicionais durante as atualizações.
No entanto, muitas vezes acontece que durante a operação normal, nenhuma dessas máquinas possui esses 25% de recursos não reclamados. Sim, não nos esforçamos: CPU e memória são sempre úteis para outros processos. Para resolver esse problema, decidimos usar as
prioridades do pod do Kubernetes . A idéia é dar aos Ingesters uma prioridade mais alta que outros microsserviços (sem estado). Quando precisamos executar um Ingester adicional (N + 1), forçamos temporariamente outros pods menores. Esses pods são transferidos para liberar recursos em outras máquinas, deixando um “buraco” suficientemente grande para o lançamento de um Ingester adicional.
Na quinta-feira, 18 de julho, lançamos quatro novos níveis de prioridade em nossos clusters:
crítico ,
alto ,
médio e
baixo . Eles foram testados em um cluster interno sem tráfego de clientes por cerca de uma semana. Por padrão, os pods sem uma determinada prioridade receberam prioridade
média ; uma classe com
alta prioridade foi definida para os Ingesters.
Critical foi reservado para monitoramento (Prometheus, Alertmanager, exportador de nós, métricas de estado de cubo etc.). Nossa configuração está aberta e veja PR
aqui .
Acidente
Na sexta-feira, 19 de julho, um dos engenheiros lançou um novo cluster Cortex dedicado para um grande cliente. A configuração deste cluster não incluiu as novas prioridades de pod, portanto, todos os novos pods receberam a prioridade padrão -
média .
O cluster Kubernetes não tinha recursos suficientes para o novo cluster Cortex, e o cluster de produção existente do Cortex não foi atualizado (os Ingesters foram deixados sem
alta prioridade). Como os Ingesters do novo cluster assumiram como padrão a prioridade
média e os pods existentes na produção funcionaram sem prioridade, os Ingesters do novo cluster expulsaram os Ingesters do cluster de produção Cortex existente.
O ReplicaSet para o Ingester preempted no cluster de produção detectou o pod preempted e criou um novo para manter o número especificado de cópias. O novo pod foi definido como prioridade
média por padrão, e o próximo Ingester "antigo" em produção perdeu recursos. O resultado foi
um processo semelhante a uma avalanche que levou à exclusão de todos os pods do Ingester para os clusters de produção da Cortex.
Os ingestores mantêm o estado e armazenam dados pelas 12 horas anteriores. Isso nos permite compactá-los com mais eficiência antes de gravar no armazenamento de longo prazo. Para fazer isso, o Cortex fragmenta os dados da série usando uma tabela de hash distribuída (DHT) e replica cada série em três Ingesters usando consistência de quorum no estilo Dynamo. O Cortex não grava dados nos Ingesters, que estão desativados. Assim, quando um grande número de Ingesters sai da DHT, o Cortex não pode fornecer replicação suficiente dos registros e eles "caem".
Detecção e eliminação
As novas notificações do Prometheus com base no "
orçamento baseado em erro " (os detalhes
baseados no orçamento do erro aparecerão em um artigo futuro) começaram a soar um alarme 4 minutos após o início do desligamento. Nos cinco minutos seguintes, realizamos diagnósticos e expandimos o cluster Kubernetes subjacente para acomodar clusters de produção novos e existentes.
Cinco minutos depois, os antigos Ingesters registraram com êxito seus dados, os novos foram iniciados e os clusters do Cortex ficaram disponíveis novamente.
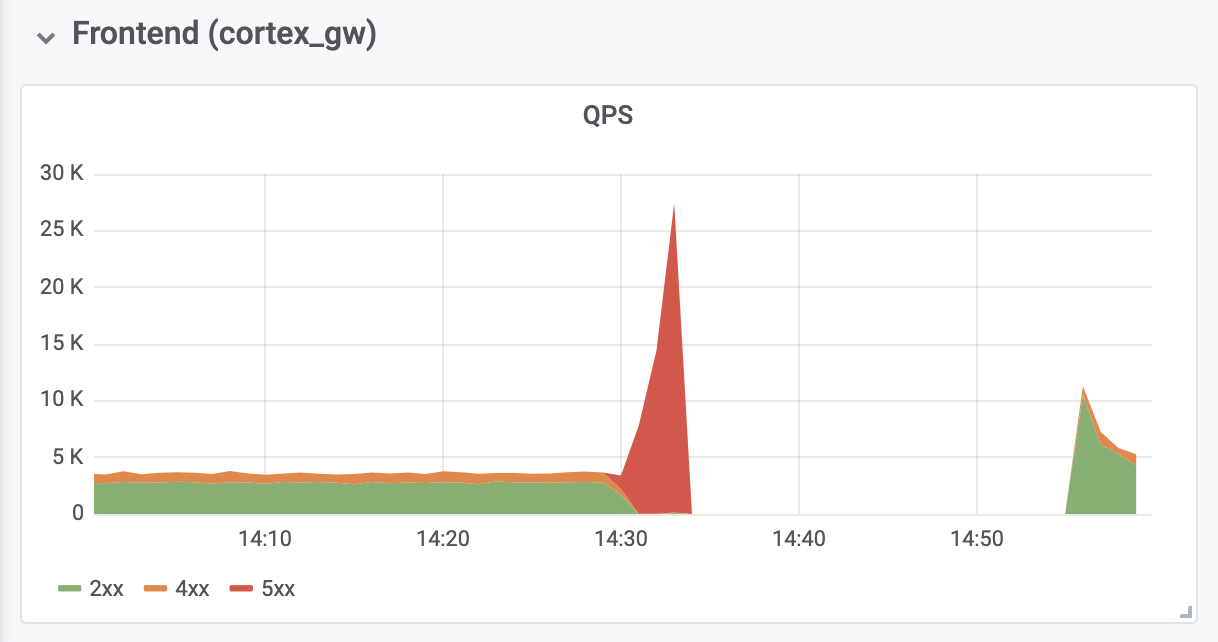
Levou mais 10 minutos para diagnosticar e corrigir erros de falta de memória (OOM) de proxies de autenticação reversa localizados na frente do Cortex. Os erros de OOM foram causados por um aumento de dez vezes no QPS (como acreditamos, devido a solicitações excessivamente agressivas dos servidores clientes do Prometheus).
As consequências
O tempo total de inatividade foi de 26 minutos. Nenhum dado foi perdido. Os ingestores carregaram com êxito todos os dados na memória para armazenamento a longo prazo. Durante um desligamento, os servidores clientes do Prometheus
armazenaram em buffer as entradas usando a
nova API remote_write baseada em
WAL (de
Callum Styan da Grafana Labs) e repetiram as entradas com falha após a falha.
 Operações de gravação de cluster de produção
Operações de gravação de cluster de produçãoConclusões
É importante aprender com esse incidente e tomar as medidas necessárias para evitar uma recorrência.
Olhando para trás, devemos admitir que não devemos definir a prioridade
média padrão, até que todos os Ingesters em produção recebam uma
alta prioridade. Além disso, eles deveriam ter cuidado de sua
alta prioridade com antecedência. Agora tudo está consertado. Esperamos que nossa experiência ajude outras organizações a considerar o uso de prioridades de pod em Kubernetes.
Adicionaremos um nível adicional de controle sobre a implantação de quaisquer objetos adicionais cujas configurações sejam globais para o cluster. A partir de agora, essas mudanças serão avaliadas por mais pessoas. Além disso, a modificação que levou à falha foi considerada insignificante demais para um documento de projeto separado - foi discutida apenas na questão do GitHub. A partir de agora, todas essas alterações de configuração serão acompanhadas pela documentação apropriada do projeto.
Por fim, automatizamos o redimensionamento do proxy de autenticação reversa para impedir o OOM durante o congestionamento, que testemunhamos, e analisamos as configurações padrão do Prometheus relacionadas à reversão e dimensionamento para evitar problemas semelhantes no futuro.
A falha experimentada também teve algumas consequências positivas: depois de receber os recursos necessários, o Cortex se recuperou automaticamente sem nenhuma intervenção adicional. Também adquirimos uma valiosa experiência com o
Grafana Loki , nosso novo sistema de agregação de logs, que ajudou a garantir que todos os Ingesters se comportassem adequadamente durante e após o acidente.
PS do tradutor
Leia também em nosso blog: