Antes de cada serviço gerar pelo menos 1 Mb / s de tráfego na Internet, surge a pergunta: “Como? sobre TCP ou sobre UDP? " Nas áreas de aplicação, incluindo plataformas de entrega, as preferências e tradições de tomar essas decisões já foram desenvolvidas.
Em teoria, se, por exemplo, uma vez que um desenvolvedor preguiçoso não tentasse implantar seu ML em Python (porque ele sabia disso), o mundo provavelmente nunca ficaria cheio de tanto amor pela desprezível linguagem dos "codificadores super-Java". E hoje, os pontos fracos dessa linguagem no contexto passado de aplicação fornecem incondicionalmente a primazia na implantação e no lançamento de numerosos A / B. de mineração.
Você pode comparar muito: ARM com Intel, iOS e Android e Mortal Kombat com Injustice. E entre em um holivar espacial, voltando ao tópico de oferecer grandes volumes de conteúdo em vários formatos.
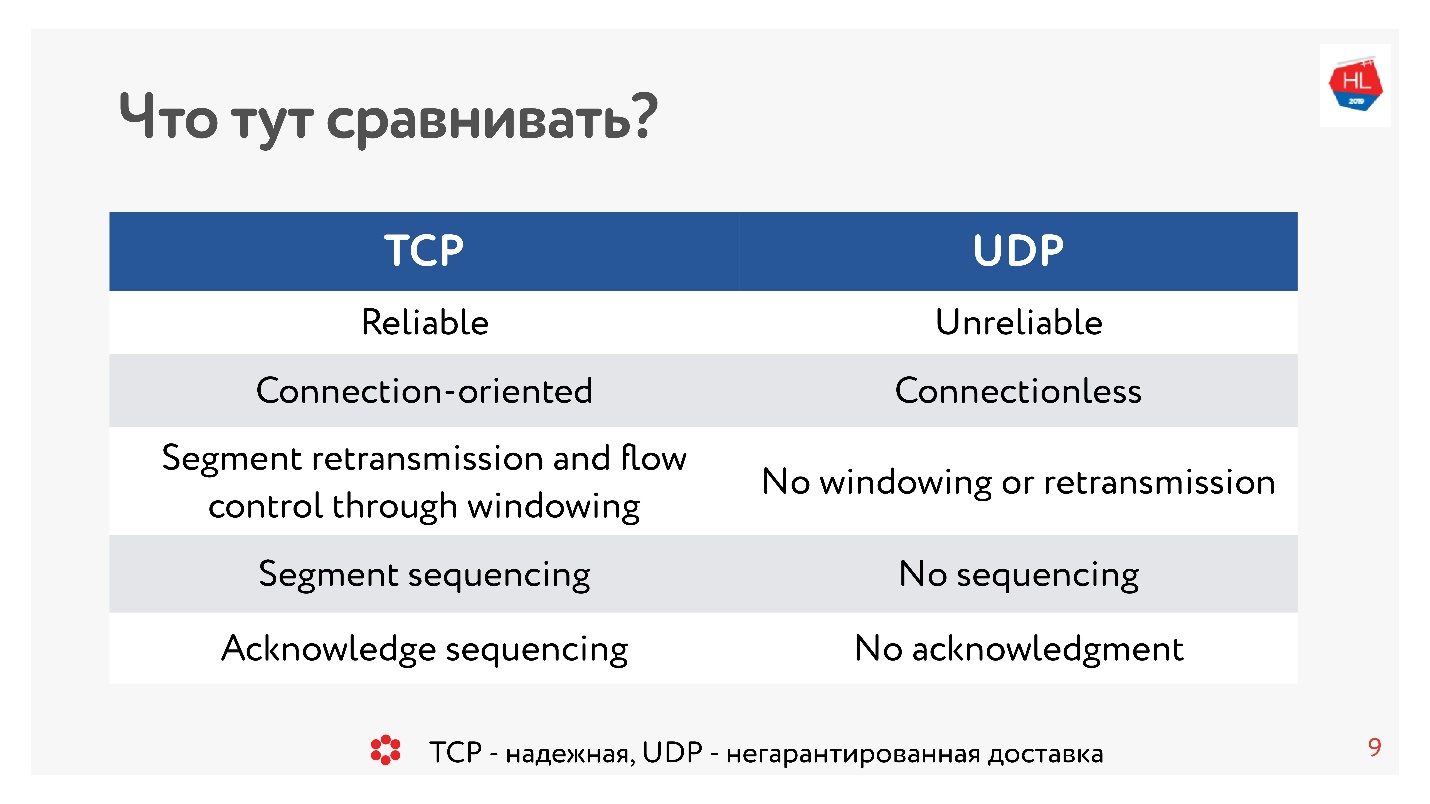
Dez anos atrás, todo mundo tinha certeza absoluta de que o UDP era algo sobre entrega não garantida. Se você precisa de um protocolo confiável, é o TCP. E, contrariamente à tradição deste artigo, compararemos coisas aparentemente incomparáveis como TCP e UDP.
 Cuidado, abaixo do corte 99 ilustrações e diagramas e tudo importante.
Cuidado, abaixo do corte 99 ilustrações e diagramas e tudo importante.A comparação é realizada pelo chefe de desenvolvimento das plataformas de vídeo e fita em OK
Alexander Tobol (
alatobol ). Os serviços de vídeo e feed de notícias na rede social OK - exclusivamente sobre o conteúdo e sua entrega a todas as plataformas de clientes existentes em quaisquer condições de rede ruins ou excelentes, e a questão de como entregá-lo - via TCP ou UDP - é crucial.
TCP vs UDP. Teoria mínima
Para chegar à comparação, precisamos de um pouco de teoria básica.
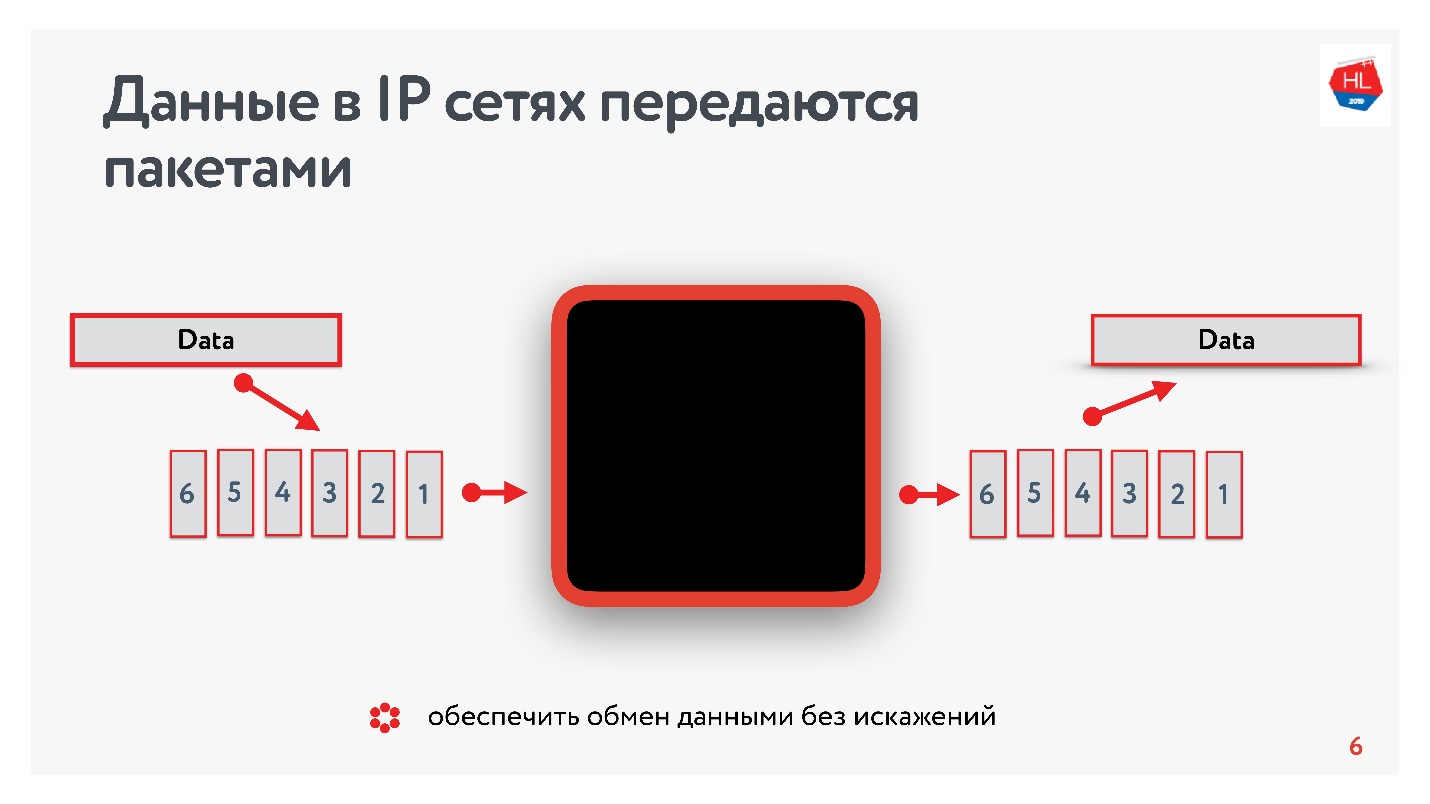
O que sabemos sobre redes IP? O fluxo de dados que você envia é dividido em pacotes, algum tipo de caixa preta entrega esses pacotes ao cliente. O cliente coleta pacotes e recebe um fluxo de dados. Geralmente tudo isso é transparente e não há necessidade de pensar o que está nos níveis mais baixos.
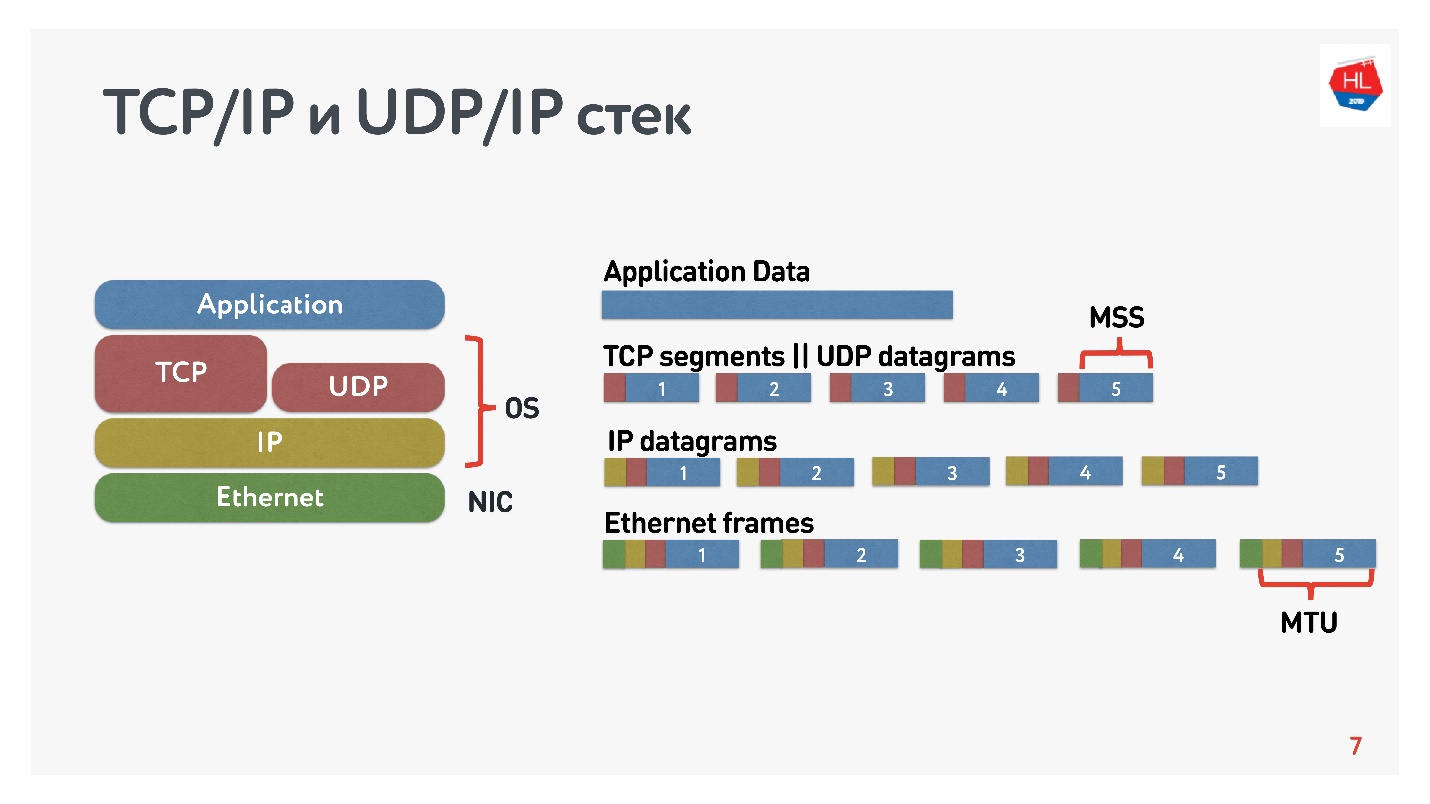
O diagrama mostra a pilha TCP / IP e UDP / IP. Na parte inferior, existem pacotes Ethernet, pacotes IP e, além disso, no nível do sistema operacional, TCP e UDP. TCP e UDP nesta pilha não são muito diferentes um do outro. Eles são encapsulados em pacotes IP e os aplicativos podem usá-los. Para ver as diferenças, é necessário olhar dentro dos pacotes TCP e UDP.
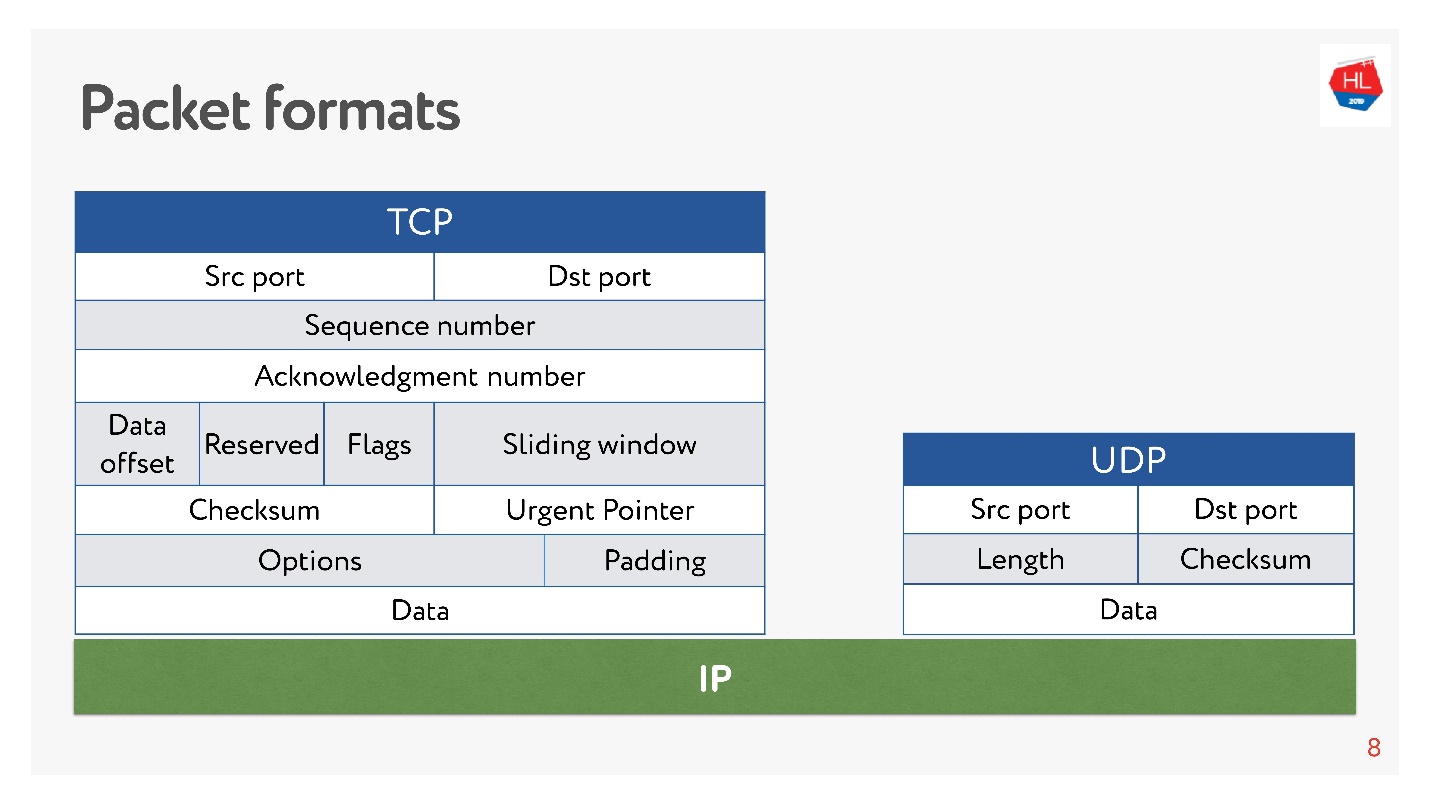
Lá e há portos. Mas
no UDP há apenas uma soma de verificação - o tamanho do pacote, esse protocolo é o mais simples possível. E no TCP, existem muitos dados que indicam claramente a janela, confirmação, sequência, pacotes e assim por diante. Obviamente, o
TCP é mais complexo .
Em termos gerais, o TCP é um protocolo de entrega confiável e o UDP não é confiável.
E, no entanto, apesar da suposta falta de confiabilidade do UDP, descobriremos se é possível fornecer dados mais rápido e mais confiável do que o uso do TCP. Vamos tentar olhar para a rede por dentro e entender como ela funciona. Ao longo do caminho, abordaremos as seguintes perguntas:
- por que comparar o TCP ou o que há de errado com ele;
- com o que e com o que você deve comparar o TCP;
- o que o Google fez e que decisão tomou;
- o que o futuro dos protocolos de rede nos espera.
Este artigo não terá uma teoria: níveis e modelos OSI, modelos matemáticos complexos, embora tudo possa ser contado através deles. Analisaremos ao máximo como tocar a rede não em teoria, mas com nossas próprias mãos.
Por que comparar o TCP ou o que há de errado com ele
O TCP foi inventado em 1974 e, 20 anos depois, quando fui para a escola, comprei placas de Internet, apaguei o código e liguei para algum lugar. Além disso, se você telefonava de 2 noites às 7 da manhã, a Internet era gratuita, mas era difícil passar.
Outros 20 anos se passaram e os usuários de redes móveis sem fio começaram a prevalecer sobre os usuários "conectados", enquanto o TCP não mudou conceitualmente.
O mundo móvel venceu, os protocolos sem fio apareceram e o TCP ainda não foi alterado.
Hoje, 80% dos usuários usam Wi-Fi ou uma rede sem fio 3G-4G.

Nas redes sem fio, existem:
- perda de pacotes - aproximadamente 0,6% dos pacotes que enviamos são perdidos ao longo do caminho;
- reordenação - rearranjo de pacotes em locais, na vida real é um fenômeno bastante raro, mas ocorre em 0,2% dos casos;
- tremulação - quando os pacotes são enviados uniformemente e chegam nas filas com um atraso de cerca de 50 ms.
O TCP oculta com êxito todos os recursos de transferência de dados em redes heterogêneas e você não precisa mergulhar nele.
Abaixo no mapa está a taxa média de dados do TCP na Rússia. Se você remover a parte ocidental, fica claro que a velocidade é medida mais em kilobits do que em megabits.
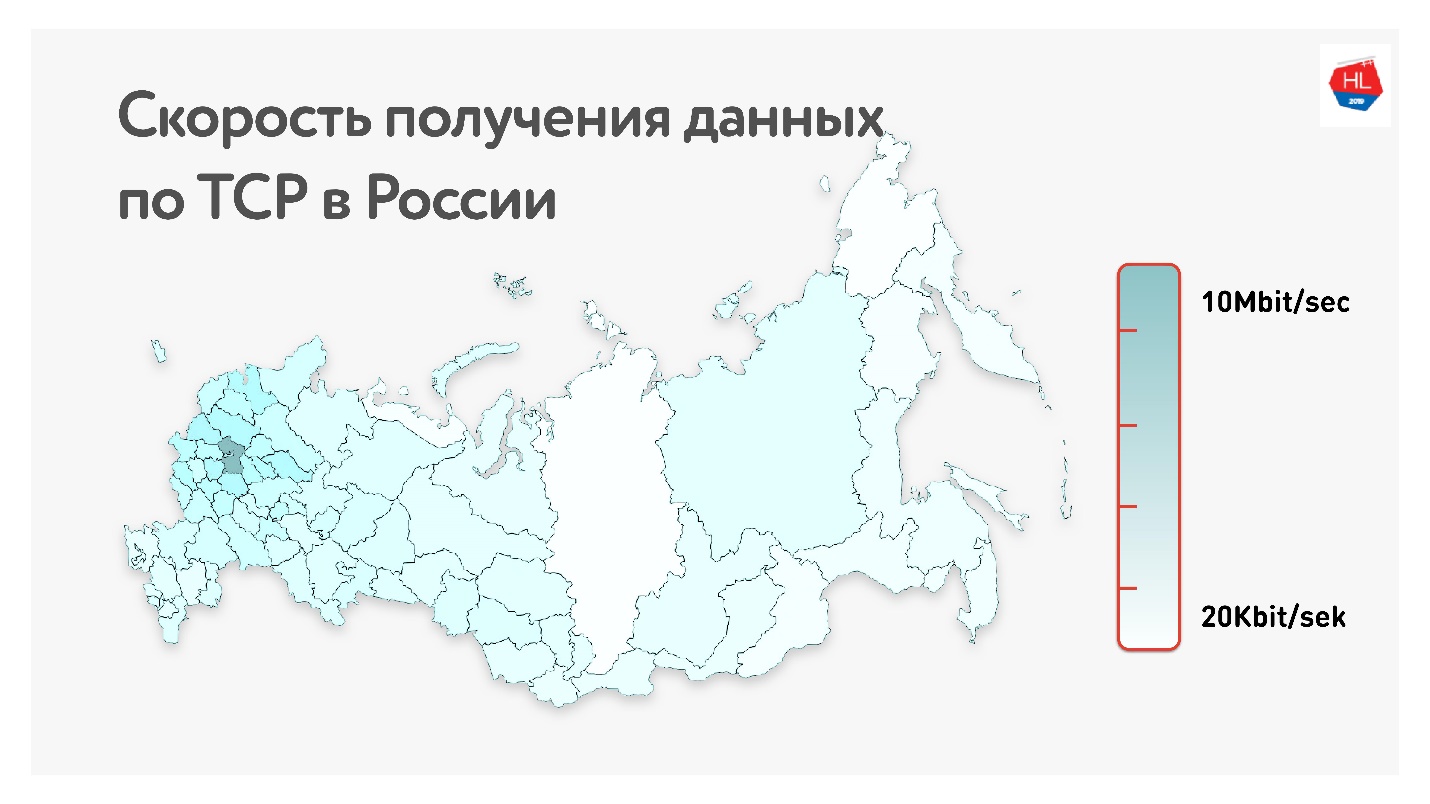
Ou seja, em média, para nossos usuários (excluindo a parte ocidental da Rússia): taxa de transferência de 1,1 Mbps, perda de pacotes de 0,6%, RTT (tempo de ida e volta) da ordem de 200 ms.
Como calcular o RTT
Quando vi a média de 200ms, pensei que havia um erro nas estatísticas e decidi medir o RTT para nossos servidores no MSC de uma maneira alternativa usando o RIPE Atlas. Este é um sistema para coletar dados sobre o estado da Internet. A sonda
RIPE Atlas está disponível gratuitamente.
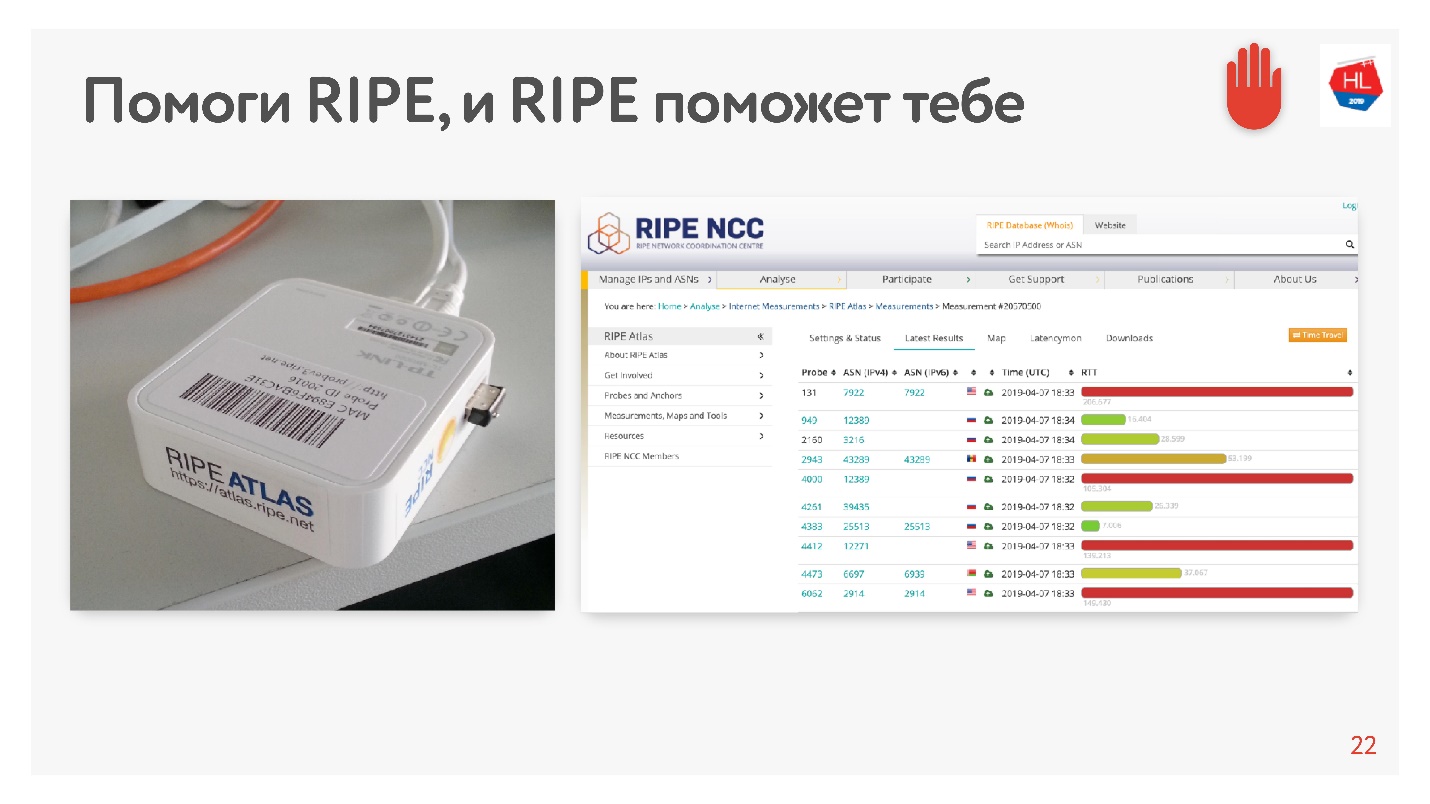
O ponto principal é que você o conecta à Internet da sua casa e coleta "karma". Ela trabalha há dias, algumas pessoas cumprem alguns de seus pedidos. Depois, você mesmo pode definir várias tarefas. Um exemplo dessa tarefa: pegue acidentalmente 30 pontos na Internet e peça para medir a RTT, ou seja, execute o comando ping no site do Odnoklassniki.
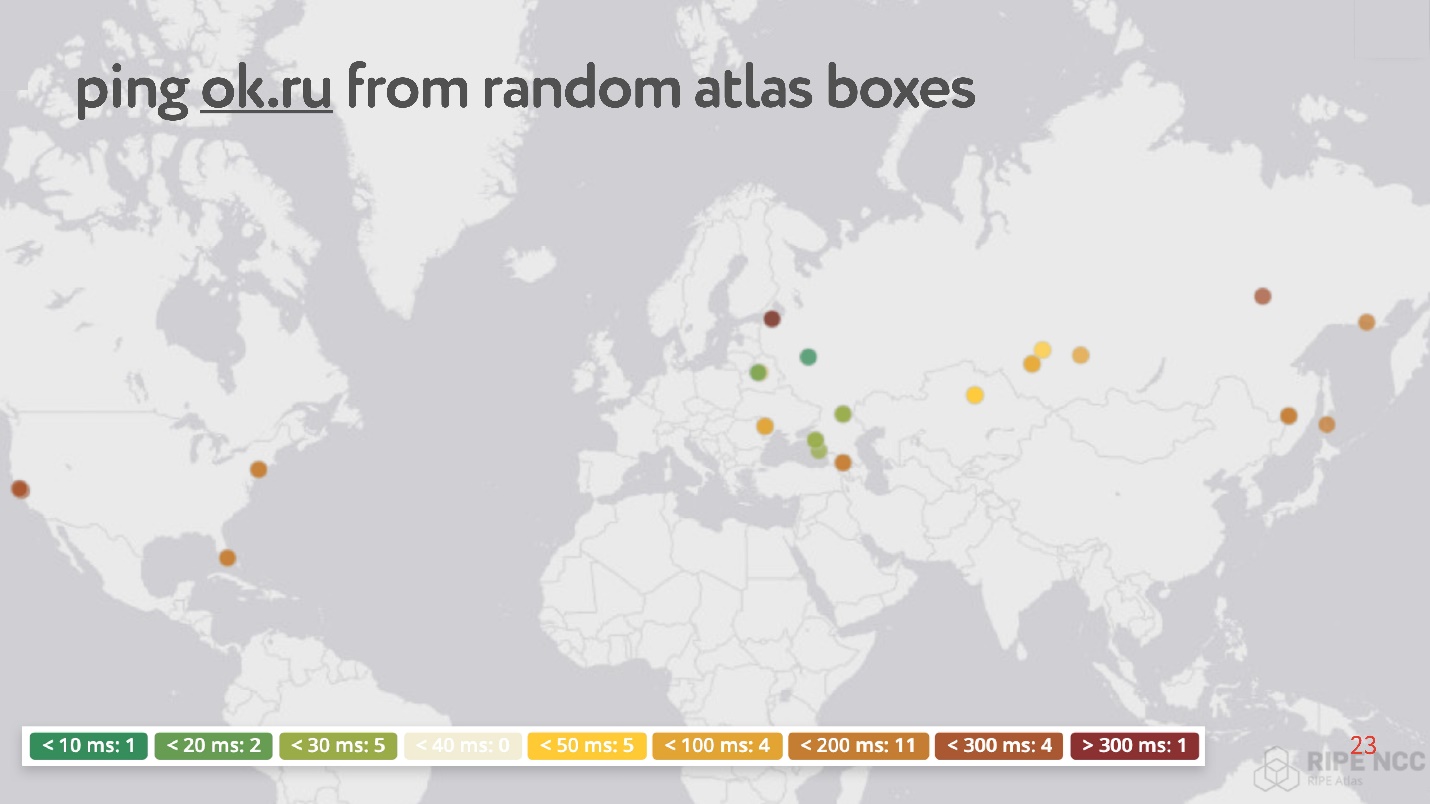
Curiosamente, entre os pontos aleatórios, existem muitos que têm ping de 200 a 300 ms.
No total,
as redes sem fio são populares e instáveis (embora a última seja geralmente ignorada, pois acredita-se que o TCP possa lidar com isso):
- Mais de 80% dos usuários usam internet sem fio;
- Os parâmetros das redes sem fio mudam dinamicamente dependendo, por exemplo, do fato de o usuário ter dobrado a esquina;
- As redes sem fio têm altas taxas de perda de pacotes, instabilidade, reordenação;
- Canal assimétrico fixo, mudança de endereço IP.
O consumo de conteúdo depende da velocidade da Internet
Isso é muito fácil de verificar - existem muitas estatísticas. Tirei
estatísticas do vídeo, que diz que quanto maior a velocidade da Internet no país, mais usuários assistem ao vídeo.
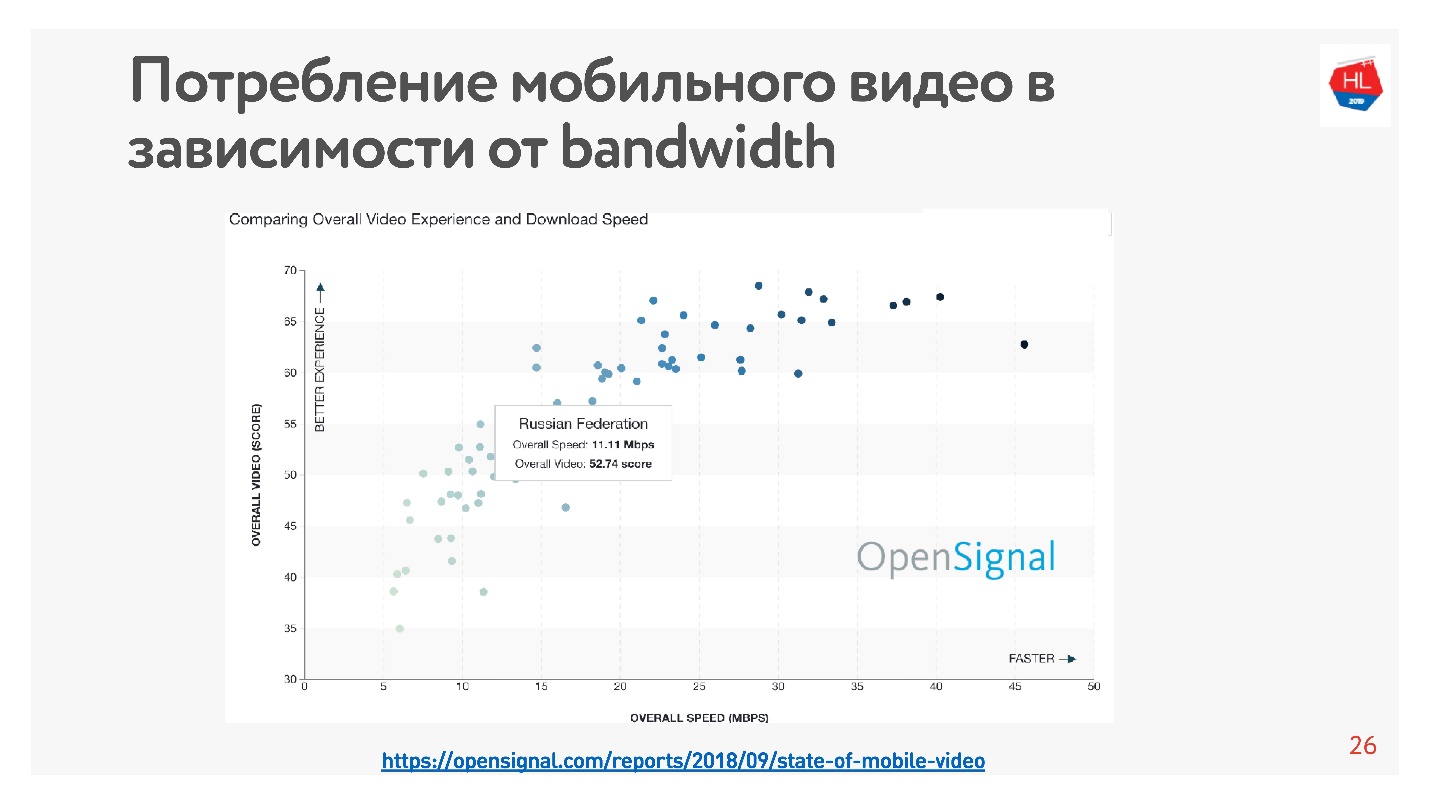
Segundo essas estatísticas, a Rússia tem uma Internet bastante rápida, mas, de acordo com nossos dados internos, a velocidade média é um pouco menor.
A favor do fato de que a velocidade da Internet como um todo é insuficiente, diz que todos os criadores de grandes aplicativos, redes sociais, serviços de vídeo e outros estão otimizando seus serviços para trabalhar em uma rede ruim. Após 10 Kb de dados recebidos, você pode ver um mínimo de informações na fita e, a uma velocidade de 500 Kb, pode assistir ao vídeo.
Como acelerar o carregamento
No processo de desenvolvimento da plataforma de vídeo, percebemos que o TCP não é muito eficaz em redes sem fio. Como você chegou a essa conclusão?
Decidimos acelerar o download e fizemos o próximo truque.
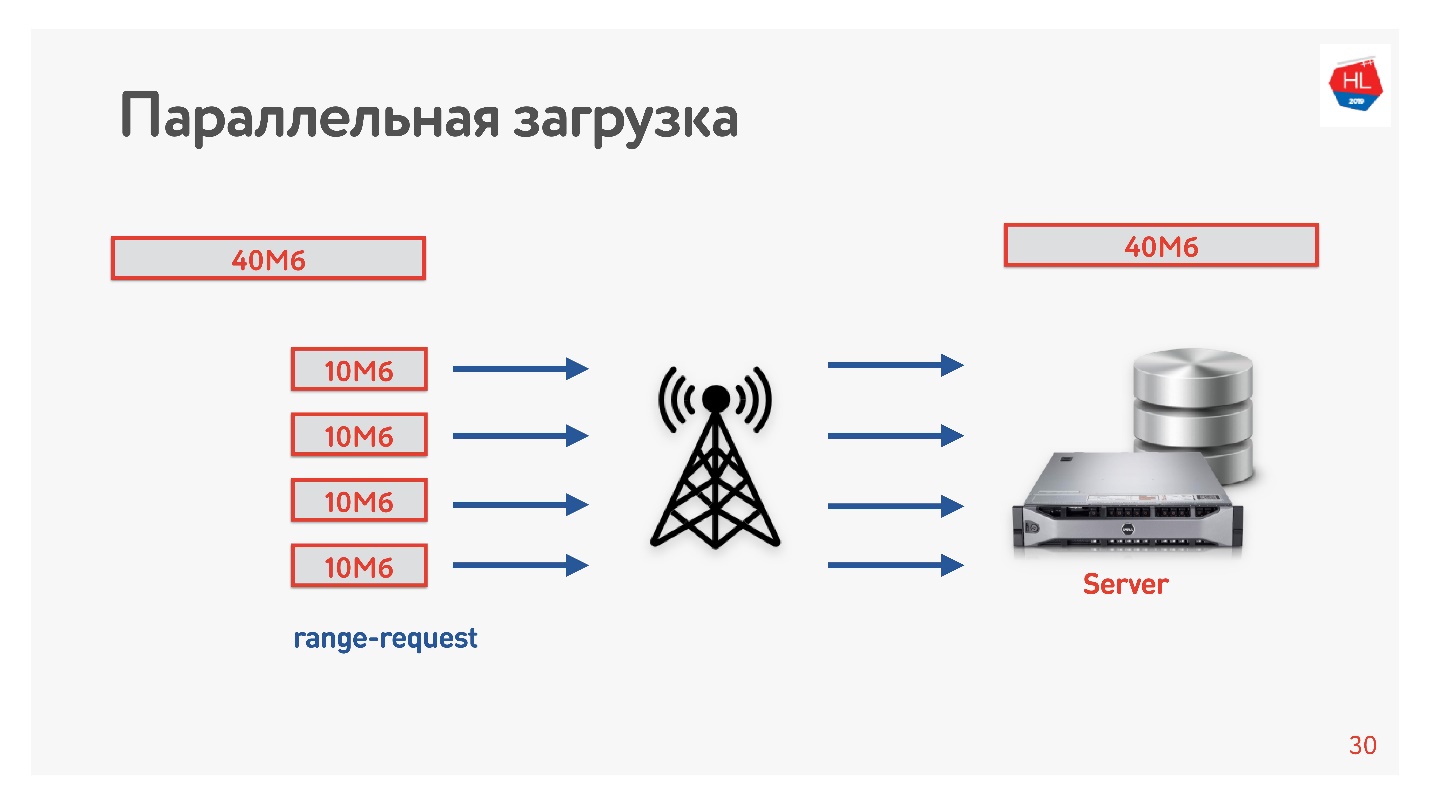
Baixamos o vídeo do cliente para o servidor em vários fluxos, ou seja, 40 MB são divididos em 4 partes de 10 MB e carregados em paralelo. Iniciamos no Android e carregamos em paralelo mais rápido do que em uma conexão (
demonstração no relatório). O mais interessante é que, quando lançamos downloads paralelos na produção, vimos que em algumas regiões a velocidade do download aumentou três vezes!
Quatro conexões TCP podem realmente carregar dados para o servidor três vezes mais rápido.
Por isso, aumentamos a velocidade de download do vídeo e concluímos que o download precisa ser paralelo.
TCP em redes instáveis
Um efeito incrível com paralelismo pode ser tocado. Basta usar um medidor de velocidade para receber / enviar dados (por exemplo, Teste de velocidade) e modelador de tráfego (por exemplo, Condicionador de link de rede, se você tiver um Mac). Restringimos a rede a parâmetros de 1 Mbps para upload e download e começamos a aumentar a perda de pacotes.

A tabela mostra RTT e perdas. Pode-se observar que, no caso de perda de 0%, a rede é utilizada 100%.
Na próxima iteração, aumentamos a perda de pacotes em 5% e vemos que a rede é utilizada em apenas 74%. Parece bom - com uma perda de pacotes de 5%, 26% da rede está perdida. Mas se você também aumentar o ping,
menos da metade do canal permanecerá.
Se o canal estiver com alta RTT e grande perda de pacotes, uma conexão TCP não utilizará completamente a rede.
Um truque adicional mostra que, se você começar a usar conexões TCP paralelas (poderá executar vários testes de velocidade ao mesmo tempo), poderá ver o crescimento inverso da utilização do canal.
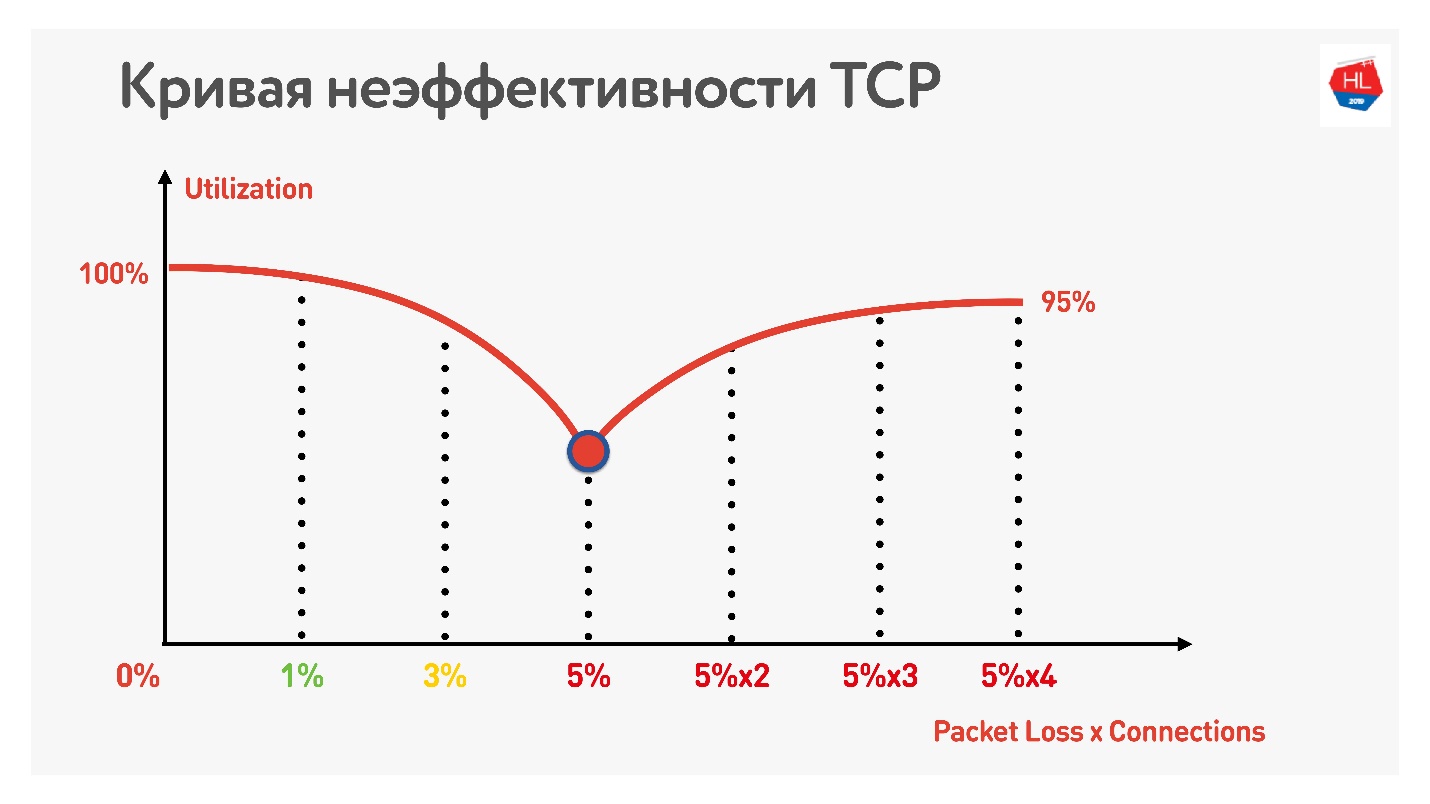
Com um aumento no número de conexões TCP paralelas, a utilização da rede se torna quase igual à taxa de transferência, menos a porcentagem de perdas.
Assim, descobriu-se:
- As redes móveis sem fio venceram e são instáveis.
- O TCP não utiliza totalmente o canal em redes instáveis.
- O consumo de conteúdo depende da velocidade da Internet: quanto maior a velocidade da Internet, mais usuários assistem, e nós realmente amamos nossos usuários e queremos que eles assistam mais.
Obviamente, você precisa se mudar para algum lugar e considerar alternativas ao TCP.
TCP vs não TCP
Como comparar o quente? Existem duas opções.
A primeira opção - no nível do IP, há TCP e UDP, podemos pagar por outro protocolo acima. Obviamente, se você iniciar seu próprio protocolo paralelamente ao TCP e UDP, o Firewall, Brandmauer, roteadores e o resto do mundo envolvido na entrega de pacotes não saberão disso. Como resultado, você terá que esperar anos quando todo o equipamento for atualizado e começar a trabalhar com o novo protocolo.
A segunda opção é criar seu próprio protocolo confiável de entrega de dados, além de UDP não confiável. Obviamente, você pode esperar um longo tempo até que Linux, Android e iOS adicionem um novo protocolo ao seu kernel, portanto, é necessário cortar o protocolo no Espaço do Usuário.
Esta solução parece interessante, chamaremos de protocolo UDP de fabricação própria. Para começar a desenvolvê-lo, você não precisa de nada de especial: basta abrir o soquete UDP e enviar os dados.
Vamos desenvolvê-lo, enquanto estudamos como a rede funciona.
TCP vs UDP auto-fabricado
Bem, e sobre o que comparar?
Redes são diferentes:
- Com o congestionamento, quando há muitos pacotes e alguns deles caem devido ao congestionamento de canais ou equipamentos.
- Alta velocidade com ida e volta grande (por exemplo, quando o servidor está relativamente distante).
- Estranho - quando nada parece estar acontecendo na rede, mas os pacotes ainda desaparecem simplesmente porque o ponto de acesso Wi-Fi está atrás do muro.
Você sempre pode tocar em perfis de rede: selecione um ou outro perfil no seu telefone e execute o Teste de velocidade.

Além dos perfis de rede, você também precisa determinar o perfil de consumo de tráfego. Aqui estão os que usamos:
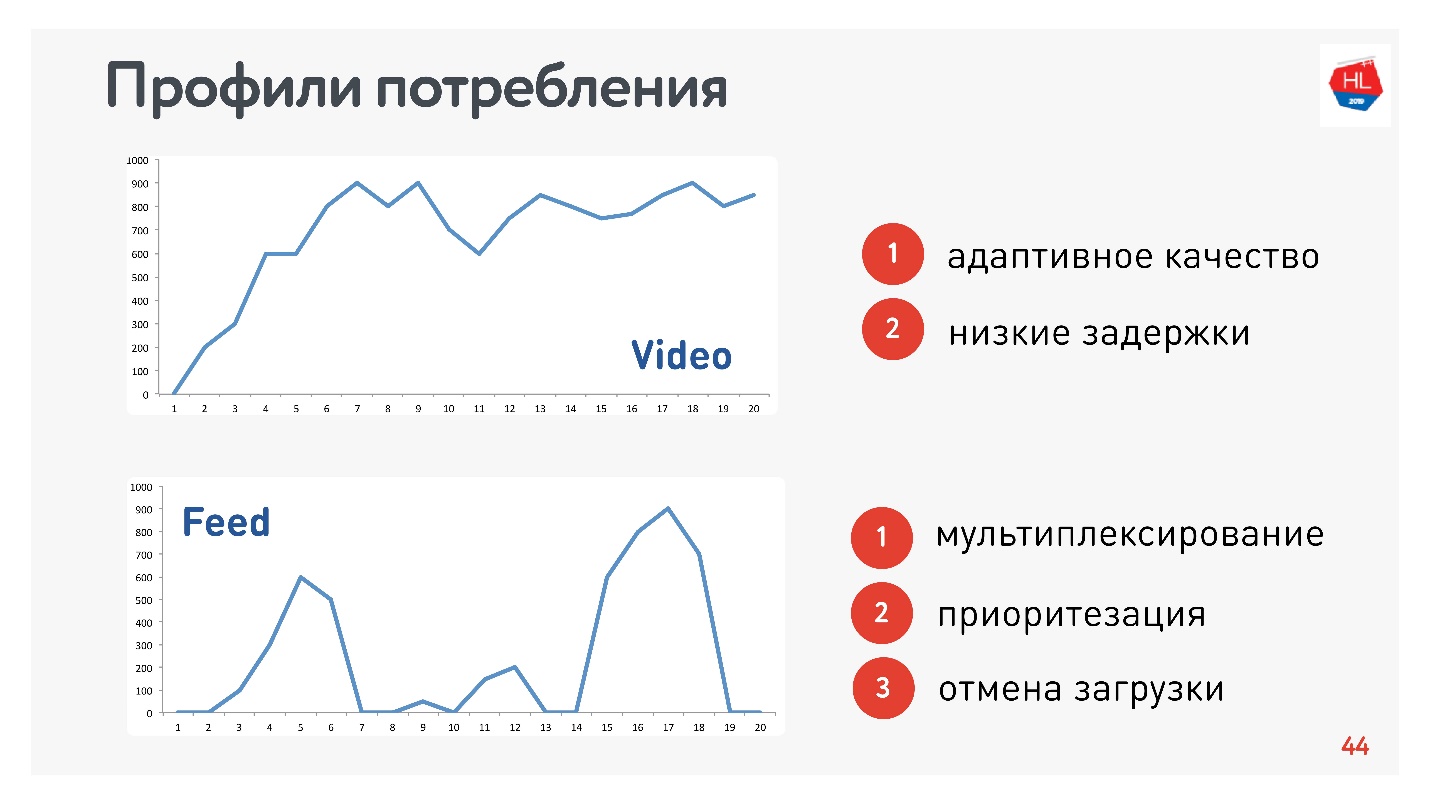
Como sou responsável pelo vídeo e pelo fluxo, os perfis são adequados:
- Perfil de vídeo, quando você conecta e transmite este ou aquele conteúdo. A velocidade da conexão aumenta, como no gráfico superior. Requisitos para este protocolo: baixa latência e adaptação à taxa de bits.
- Opção de exibição de fita: carregamento de dados por impulso, consultas em segundo plano, tempo de inatividade. Requisitos para este protocolo: os dados recebidos são multiplexados e priorizados, a prioridade do conteúdo do usuário é superior aos processos em segundo plano, há um cancelamento do download.
Obviamente, você precisa comparar os protocolos no HTTP mais popular.
HTTP 1.1 e HTTP 2.0
A pilha padrão dos anos 2000 parecia HTTP 1.1 sobre SSL. A pilha moderna é HTTP 2.0, TLS 1.3 e tudo em cima do TCP.
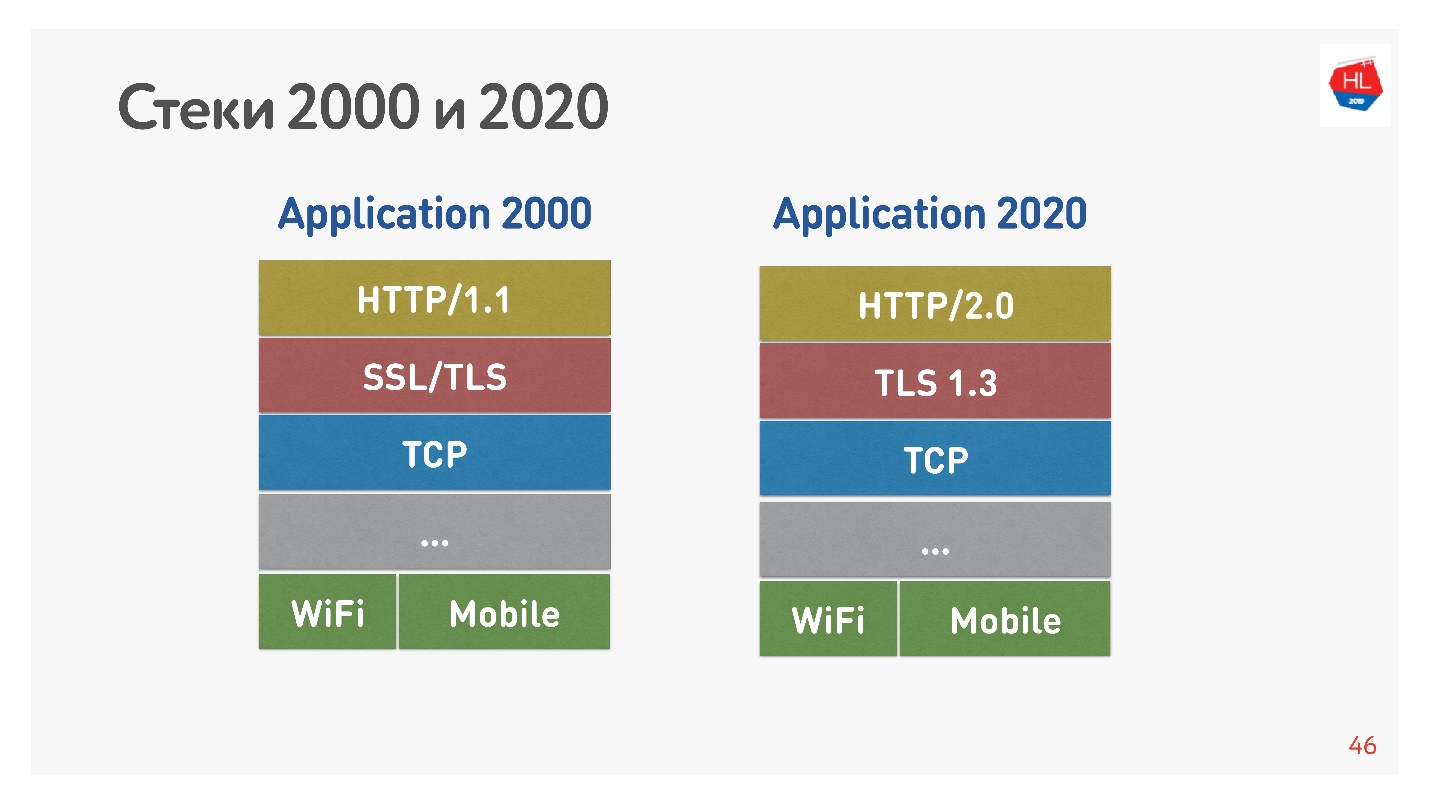
A principal diferença é que o HTTP 1.1 usa um conjunto limitado de conexões no navegador para um domínio, para que eles criem um domínio separado para imagens, dados e assim por diante. O HTTP 2.0 oferece uma conexão multiplexada na qual todos esses dados são transmitidos.
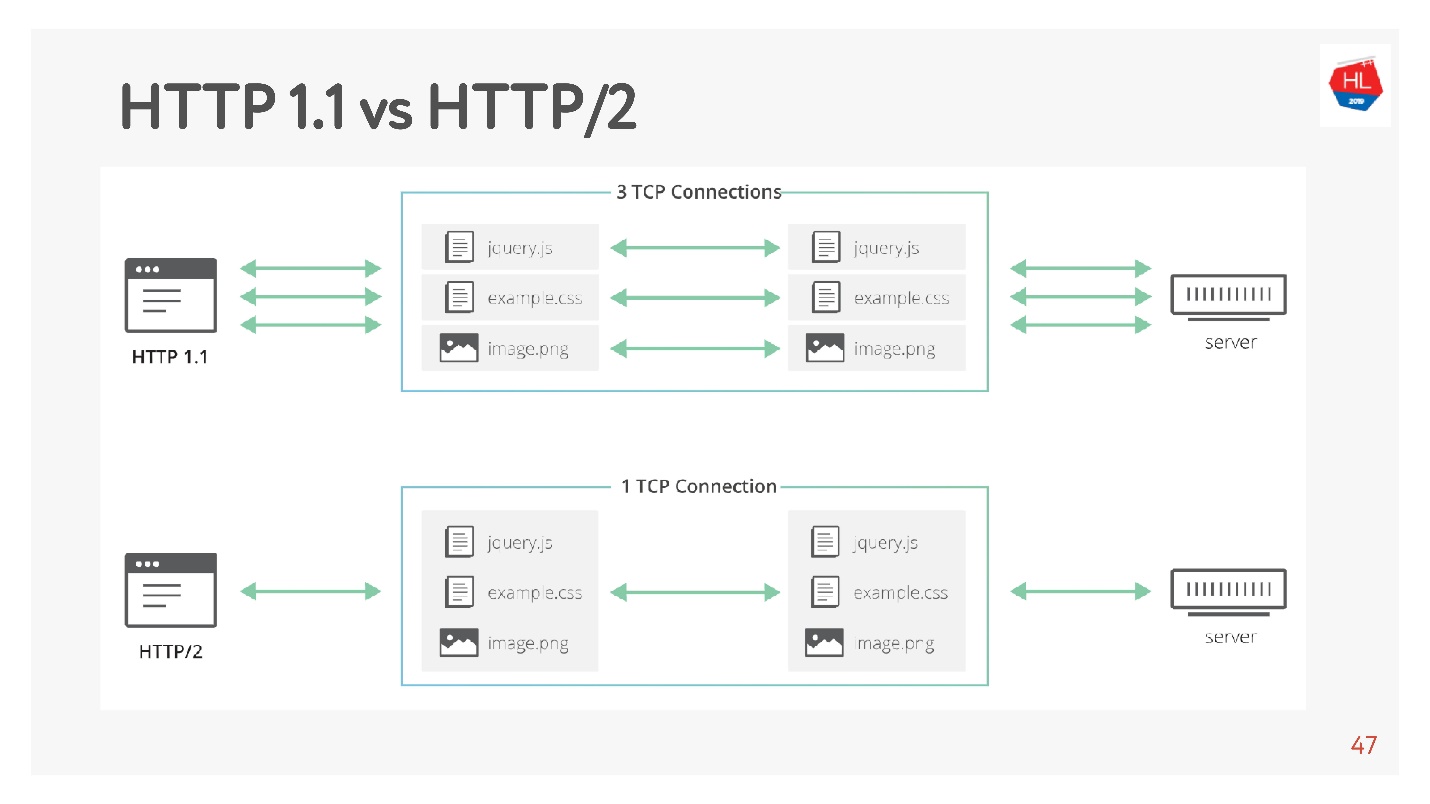
O HTTP 1.1 funciona assim: faça uma solicitação, obtenha dados, faça uma solicitação, obtenha dados.
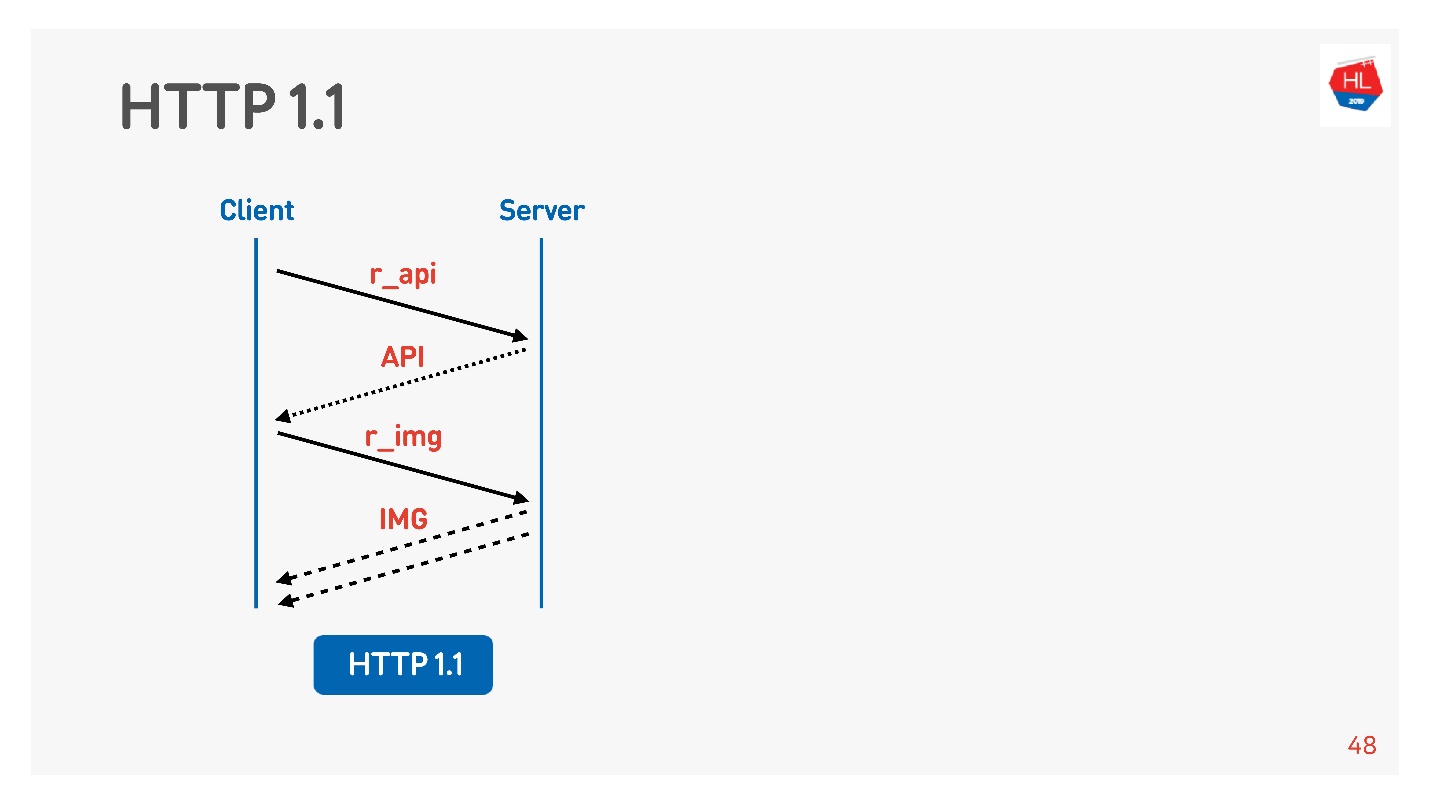
Normalmente, um navegador ou um aplicativo móvel é um marcador, ou seja, uma conexão para receber imagens, dados pela API e você executa simultaneamente uma solicitação de imagem, API, vídeo e assim por diante.
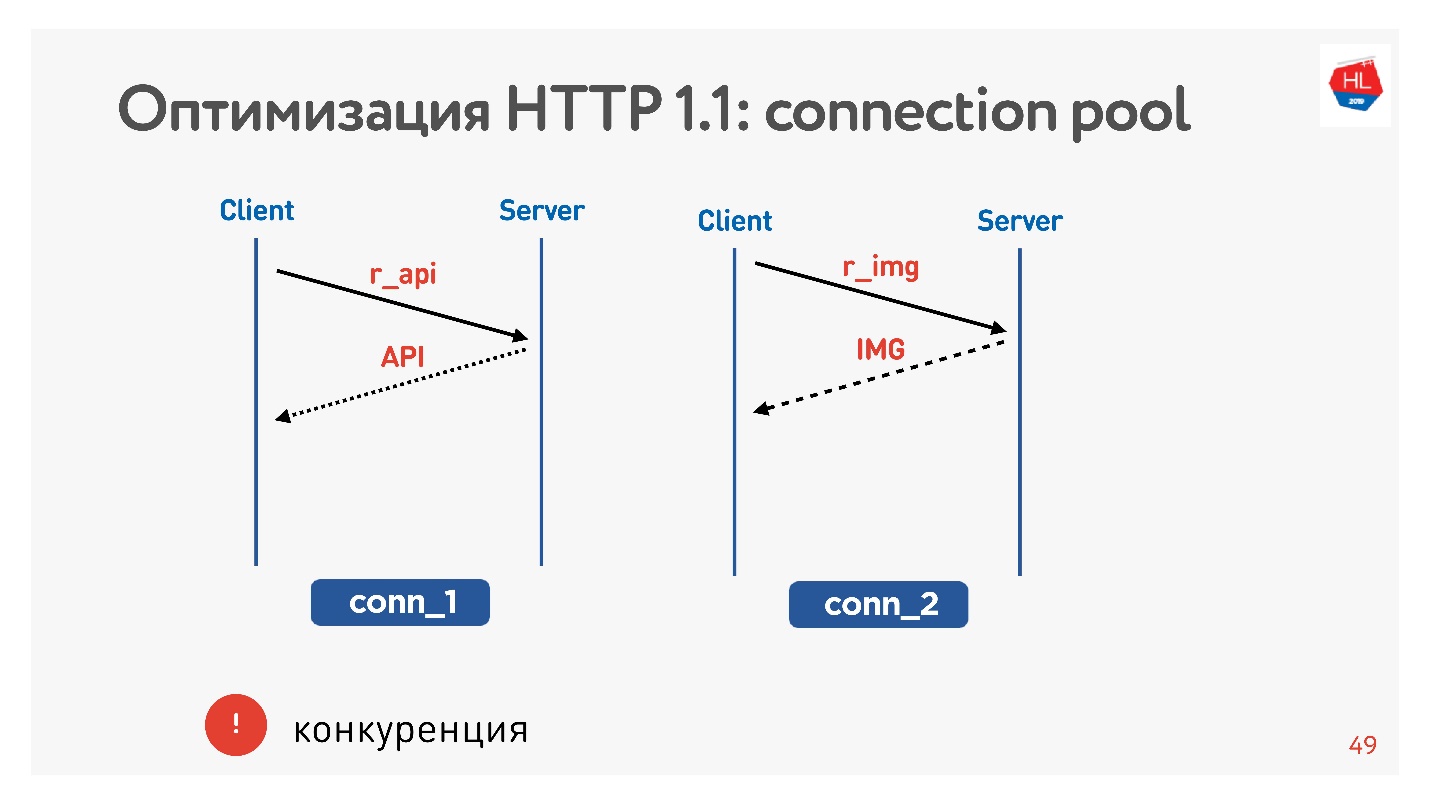
O principal problema é a concorrência. Você não tem controle sobre as solicitações enviadas. Você entende que o usuário não precisa mais da imagem que ele exibiu, mas não pode fazer nada.
Com o HTTP 1.1, você ainda recebe o que solicitou, é difícil cancelar o download.
A única chance de soquete é fechar a conexão. Então vamos ver por que isso é ruim.
Diferenças no HTTP 2.0
O HTTP 2.0 resolve estes problemas:
- binário, compactação de cabeçalho;
- multiplexação de dados;
- priorização;
- cancelando o download;
- push do servidor
Vamos considerar pontos mais importantes para nós.
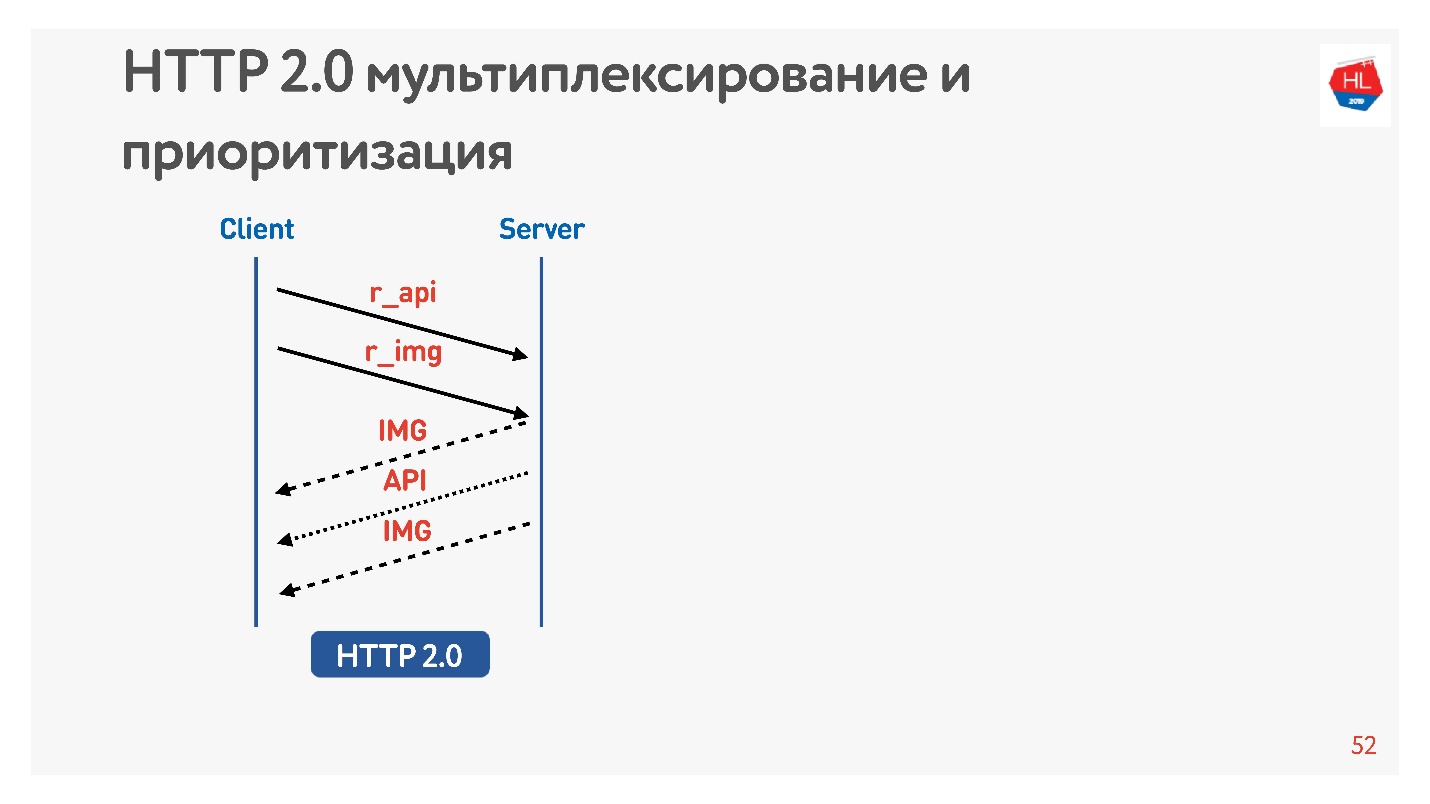
Solicite uma foto e API. A imagem é dada imediatamente, a API preparada depois de um tempo. A API foi dada - a imagem foi dada até o fim. Tudo isso acontece de forma transparente.
O conteúdo de alta prioridade é baixado anteriormente.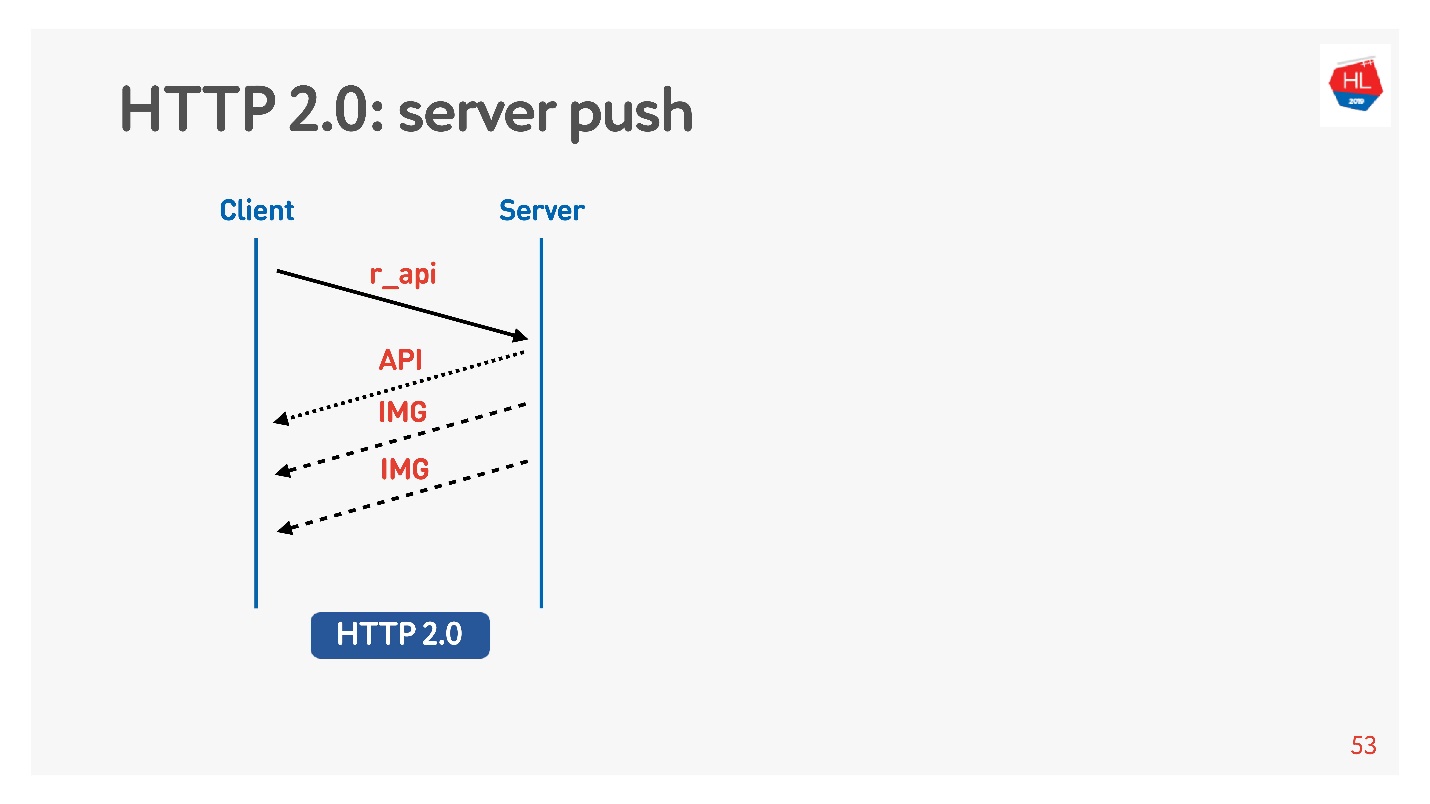 O envio de servidor
O envio de servidor é uma coisa dessas quando você solicita algo específico, como uma API, mas mesmo com a carga nas fotos do cliente em cache, isso seria definitivamente necessário para exibir, por exemplo, uma fita.
Há também um comando
Redefinir fluxo que o navegador executa automaticamente se você alternar entre páginas, etc. Para um cliente móvel, com sua ajuda, você pode recusar o recebimento de dados sem perder a conexão.
Assim, compararemos o TCP em diferentes:
- Perfis de rede: Wi-Fi, 3G, LTE.
- Perfis de consumo: streaming (vídeo), multiplexação e priorização com o cancelamento do download (HTTP / 2) para receber o conteúdo da fita.
Modelo sem perdas
Vamos começar a comparação com uma rede simples, na qual existem apenas dois parâmetros: tempo de ida e volta e largura de banda.
RTT é ping, o tempo de entrega de um pacote, o recebimento da confirmação ou o tempo de eco da resposta.
Para medir a
largura de banda -
largura de banda da rede - enviamos um pacote de pacotes e contamos o número de pacotes transmitidos em um determinado intervalo de tempo.
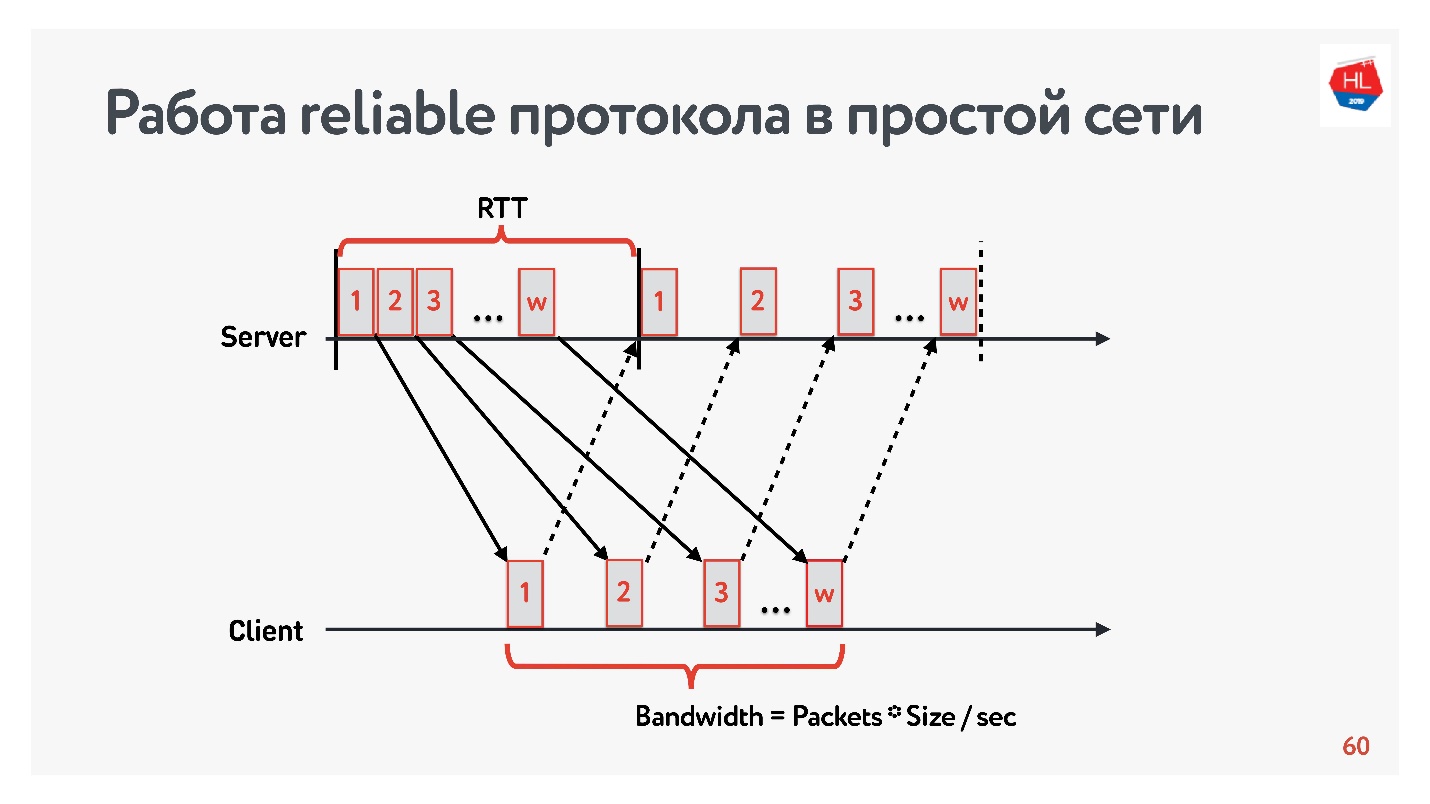
Como trabalhamos com protocolos confiáveis, é claro, há um reconhecimento - enviamos pacotes e recebemos a confirmação do recebimento.
O problema da Internet lenta
No início do desenvolvimento do nosso serviço de vídeo em 2013, meu amigo foi para a Califórnia e decidiu assistir a uma nova série de suas séries favoritas no Odnoklassniki. Ele tinha um RTT de 250 ms, Wi-Fi perfeito de 400 Mbps no campus do Google, queria ver a nova série em FullHD.
Você acha que ele foi capaz de assistir ao vídeo? A resposta depende da configuração do buffer de envio / recv em nossos servidores.
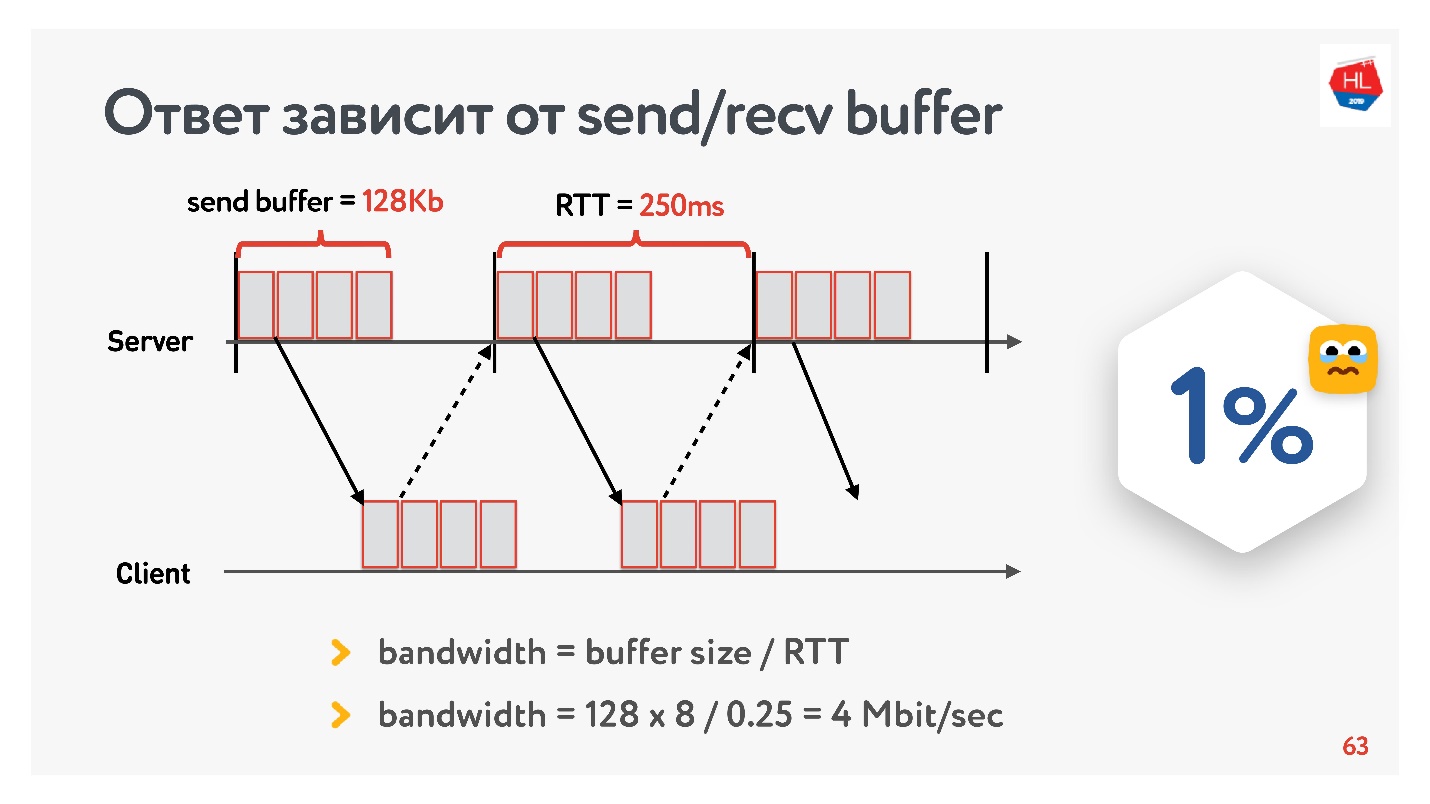
Como temos um protocolo com reconhecimento, todos os dados que não receberam uma confirmação de entrega são armazenados em um buffer. Se o buffer de envio estiver limitado a 128 Kb, esses 128 Kb serão menores que para o RTT, não poderemos enviar. Assim, da nossa rede de 400 Mbit / s, restam 4 Mbit / s. Isso não é suficiente para assistir a vídeos online em FullHD.
Então puxei o tamanho do buffer e observei como a velocidade de saída de um segmento de vídeo realmente muda dependendo da alteração no tamanho do buffer. Faça imediatamente uma reserva de que o buffer de recv foi ajustado automaticamente, ou seja, o que o servidor enviou, o cliente sempre poderia aceitar.

Uma receita TCP óbvia: se você transmitir dados de alta velocidade por longas distâncias, precisará aumentar o buffer de envio.
Tudo parece estar bem. Você pode acessar o serviço fast.com, que mede a velocidade da sua Internet nos servidores Netflix. Do escritório, obtive uma velocidade de 210 Mbps. E então, através do shaper de rede, configurei as condições da tarefa e fui para este site novamente. Magia - eu tenho exatamente 4 Mbps.
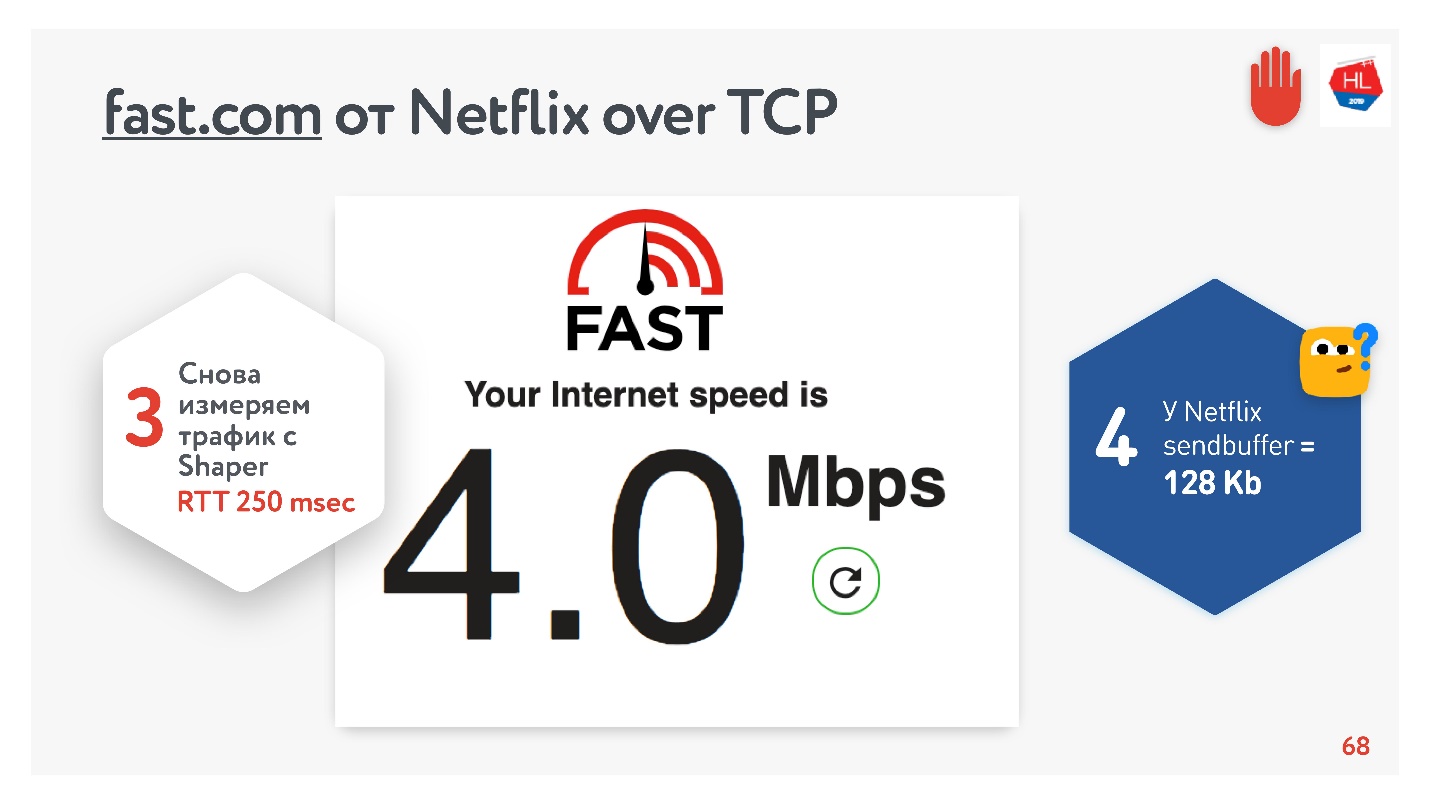
Não importa como eu torça, a Netflix não conseguiu obter um buffer maior que 128 KB.
Tamanho do buffer
Para descobrir o tamanho ideal do buffer, você precisa entender o que são pacotes On-the-fly.
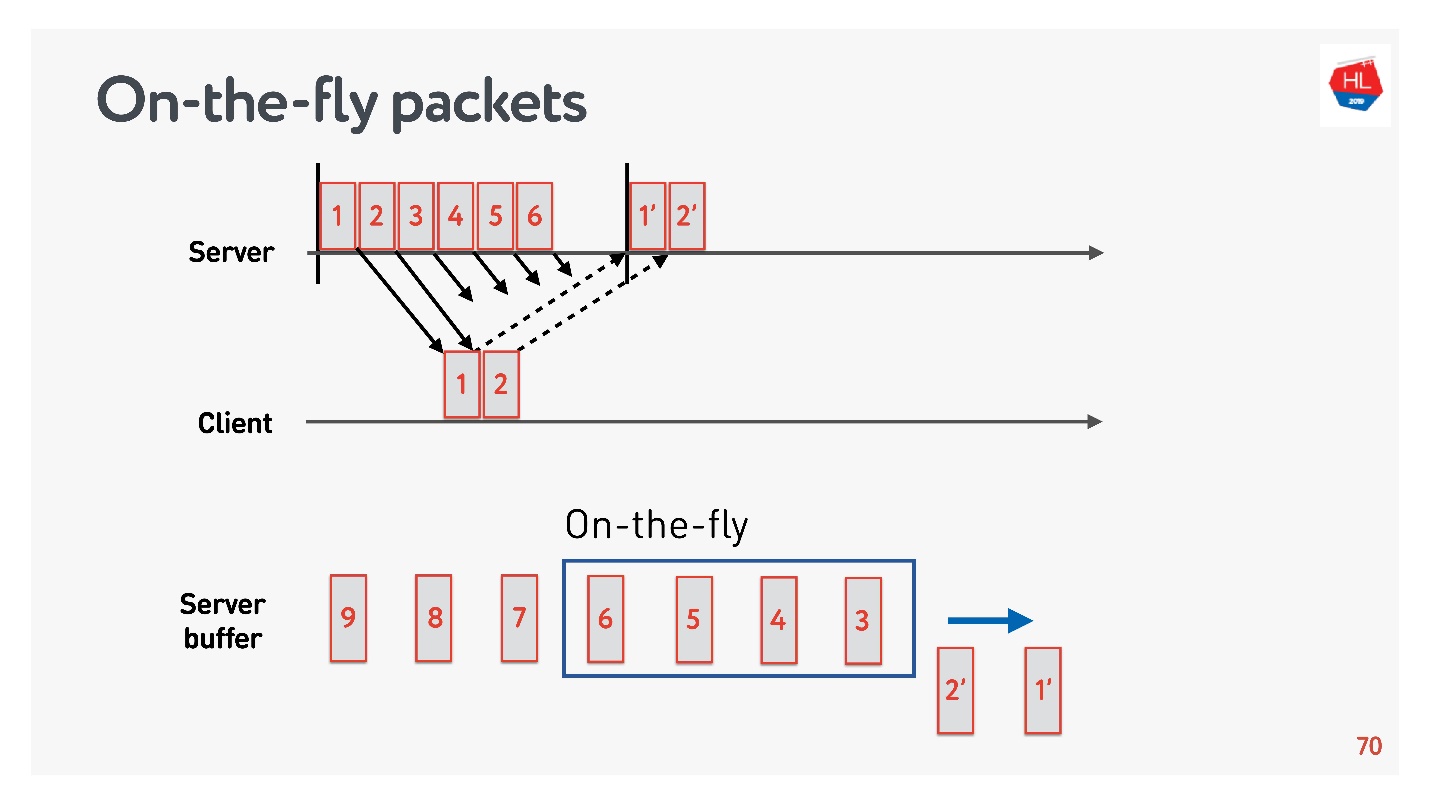
Há um status de rede:
- os pacotes 1 e 2 já foram enviados, uma confirmação foi recebida por eles;
- os pacotes 3, 4, 5, 6 foram enviados, mas o resultado da entrega é desconhecido (pacotes on-the-fly);
- outros pacotes estão na fila.
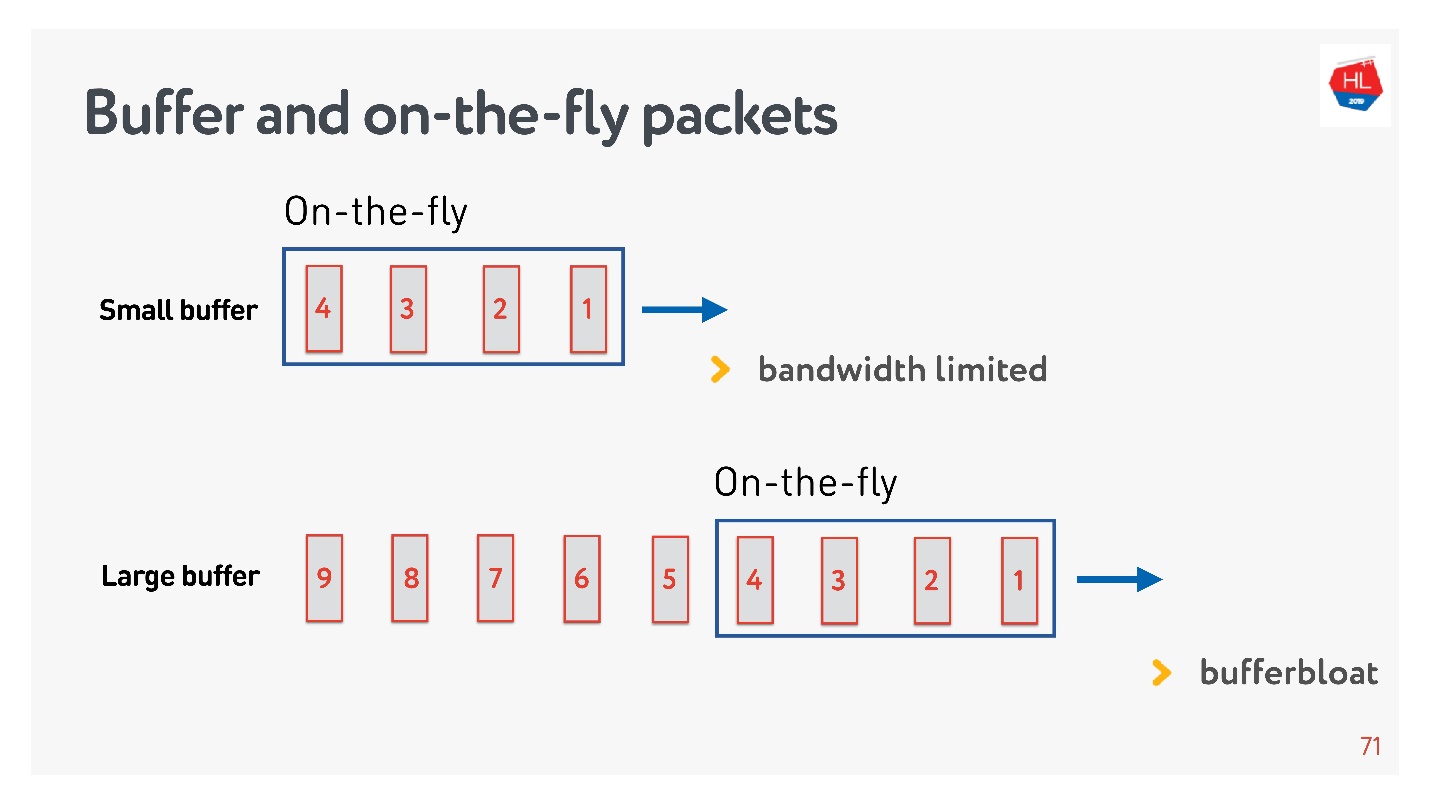
Se o número de pacotes On-the-fly for igual ao tamanho do buffer, ele não será grande o suficiente. Nesse caso, a rede está passando fome, não sendo totalmente utilizada.
A situação inversa é possível - o buffer é muito grande. Nesse caso, o buffer aumenta. Por que isso é ruim?

Se falamos sobre multiplexação de dados e enviamos várias solicitações ao mesmo tempo, por exemplo, imagens para a mesma conexão e API, quando toda a enorme imagem de megabytes entra no buffer e tentamos fazer o push da API de alta prioridade também, o buffer aumenta. Você tem que esperar muito tempo quando a imagem desaparecer.
Uma solução simples é ajustar automaticamente o tamanho do buffer. Agora está disponível em muitos clientes e funciona mais ou menos assim.
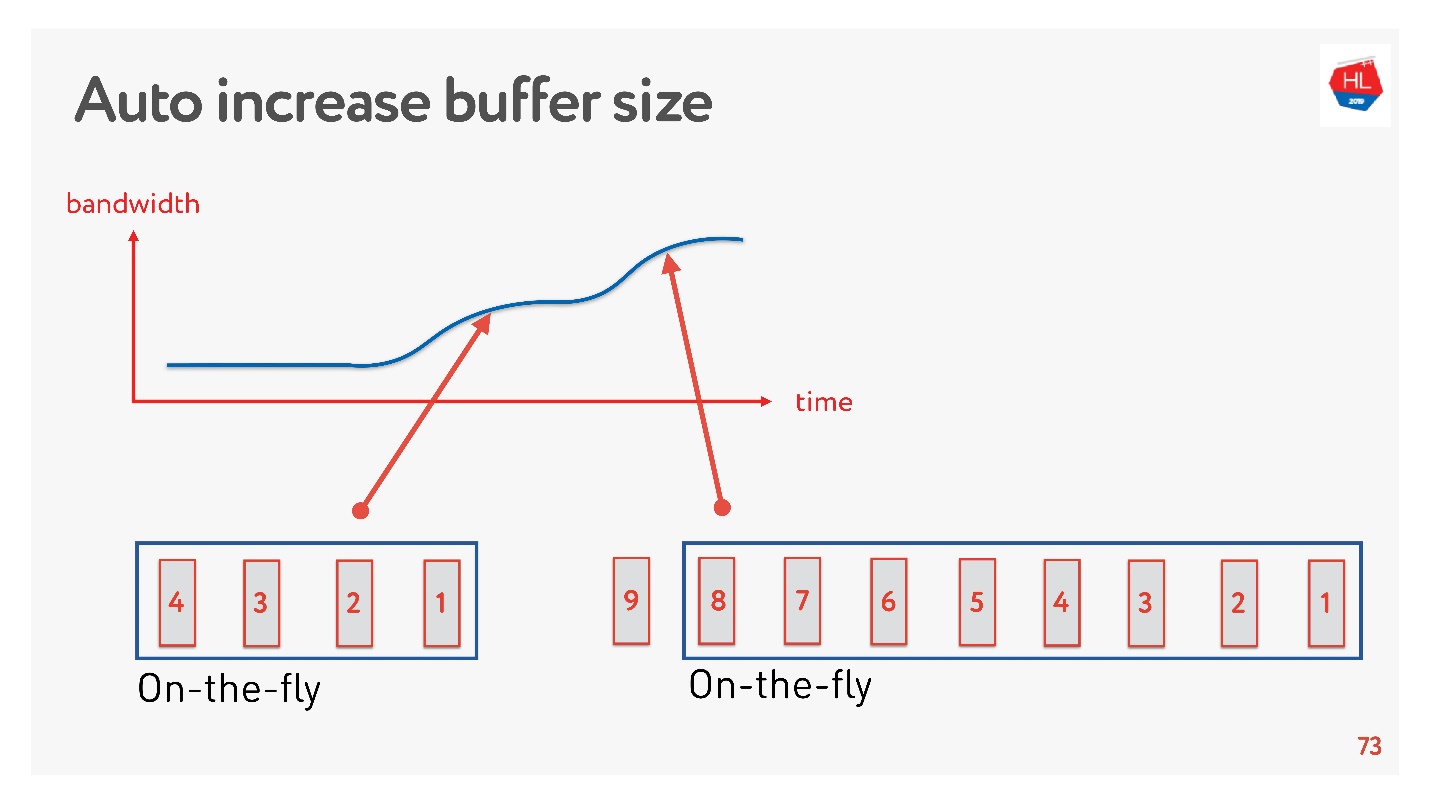
Se muitos pacotes podem ser enviados agora, o buffer está aumentando, a transferência de dados está acelerando, o tamanho do buffer está aumentando, tudo parece ótimo.
Mas há um problema. Se o buffer aumentou, não pode ser reduzido com tanta facilidade. Esta é uma tarefa mais difícil. Se a velocidade diminuir, ocorre o mesmo inchaço do buffer. O buffer é bastante grande e cheio, precisamos esperar até que todos os dados sejam enviados ao cliente.
Se escrevermos nosso próprio protocolo UDP, tudo será muito simples - teremos acesso ao buffer.
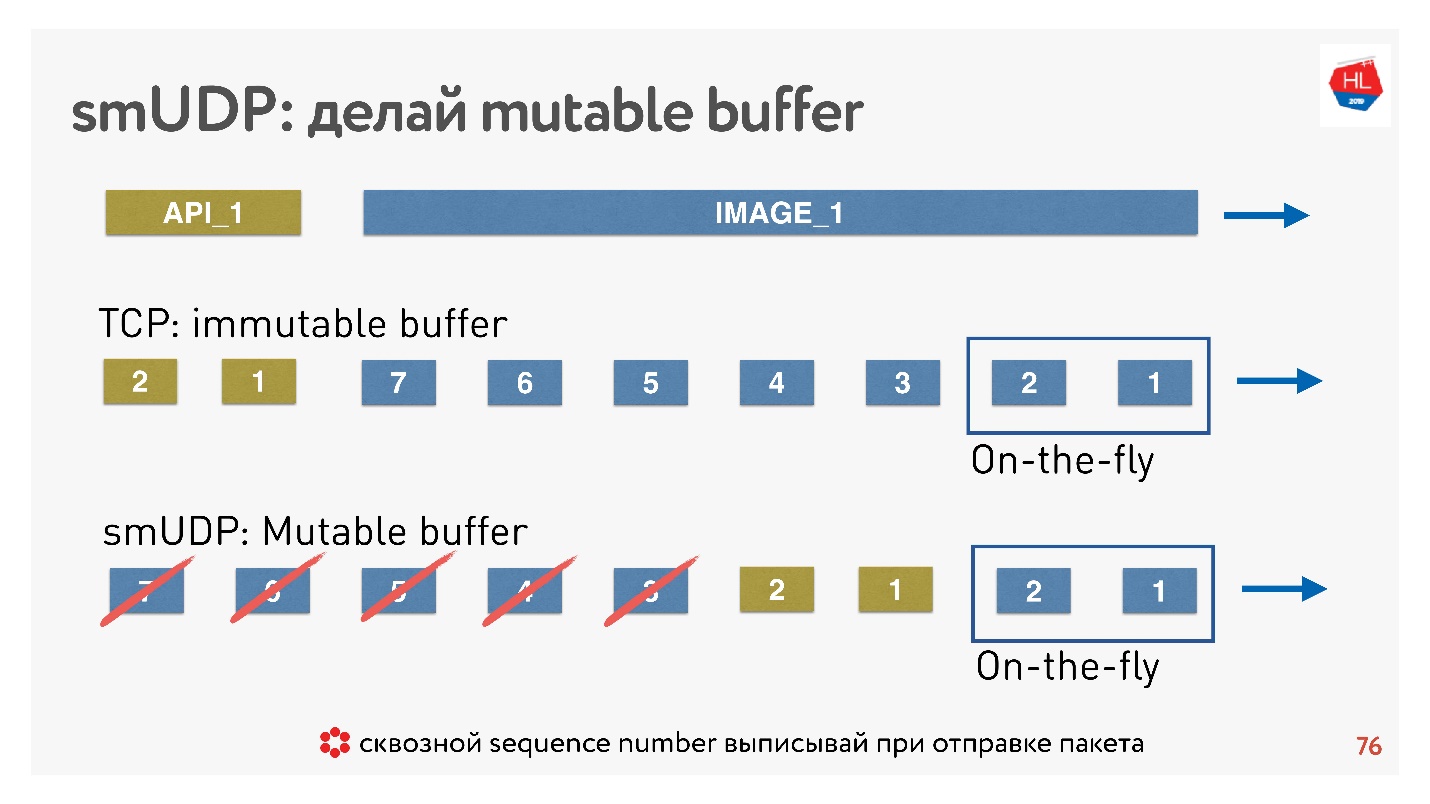
Se o TCP em tais situações simplesmente adicionar dados ao final e você não puder fazer nada, em um protocolo criado por você poderá colocar os dados, por exemplo, encaminhar imediatamente após os pacotes dinâmicos.
E se o cancelamento ocorrer, e o cliente disser que essa imagem não é mais necessária, ele precisa dos dados da API, ele rolou o conteúdo ainda mais, você pode jogar tudo isso fora do buffer e enviar a desejada.
Como isso é feito? É sabido que, para restaurar pacotes, gerenciar a entrega, receber confirmações, você precisa de um sequence_id de pacotes. Sequence_id, estamos gravados apenas para pacotes dinâmicos, ou seja, apenas o emitimos quando enviamos pacotes. Tudo o mais no buffer pode ser movido como queremos até que os pacotes acabem.
Conclusão: o buffer TCP deve estar configurado corretamente, pegar a balança para não encostar na rede e não inflar o buffer. Para o seu próprio protocolo UDP, tudo é simples - isso pode ser controlado.
Modelo de rede com perdas
Passamos para um nível superior, a rede se torna um pouco mais complicada, a perda de pacotes aparece nela. Para redes móveis, essa é uma situação comum. Alguns dos pacotes enviados não chegam ao cliente. O algoritmo de recuperação de retransmissão padrão funciona mais ou menos assim:
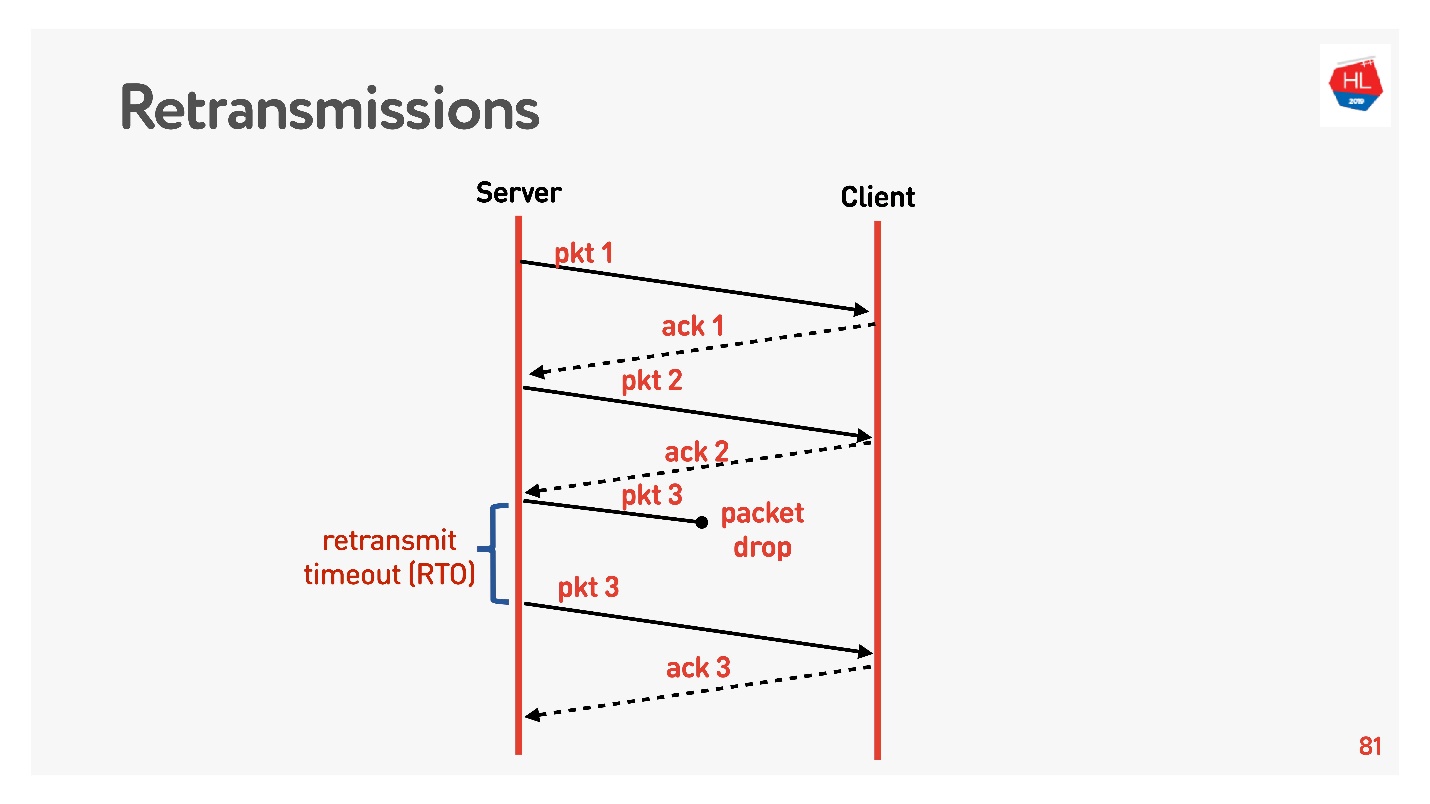
Envia pacotes, pois cada pacote recebe reconhecimento. Retransmit timeout (RTO) RTT , .
TCP, 5% , 50%.
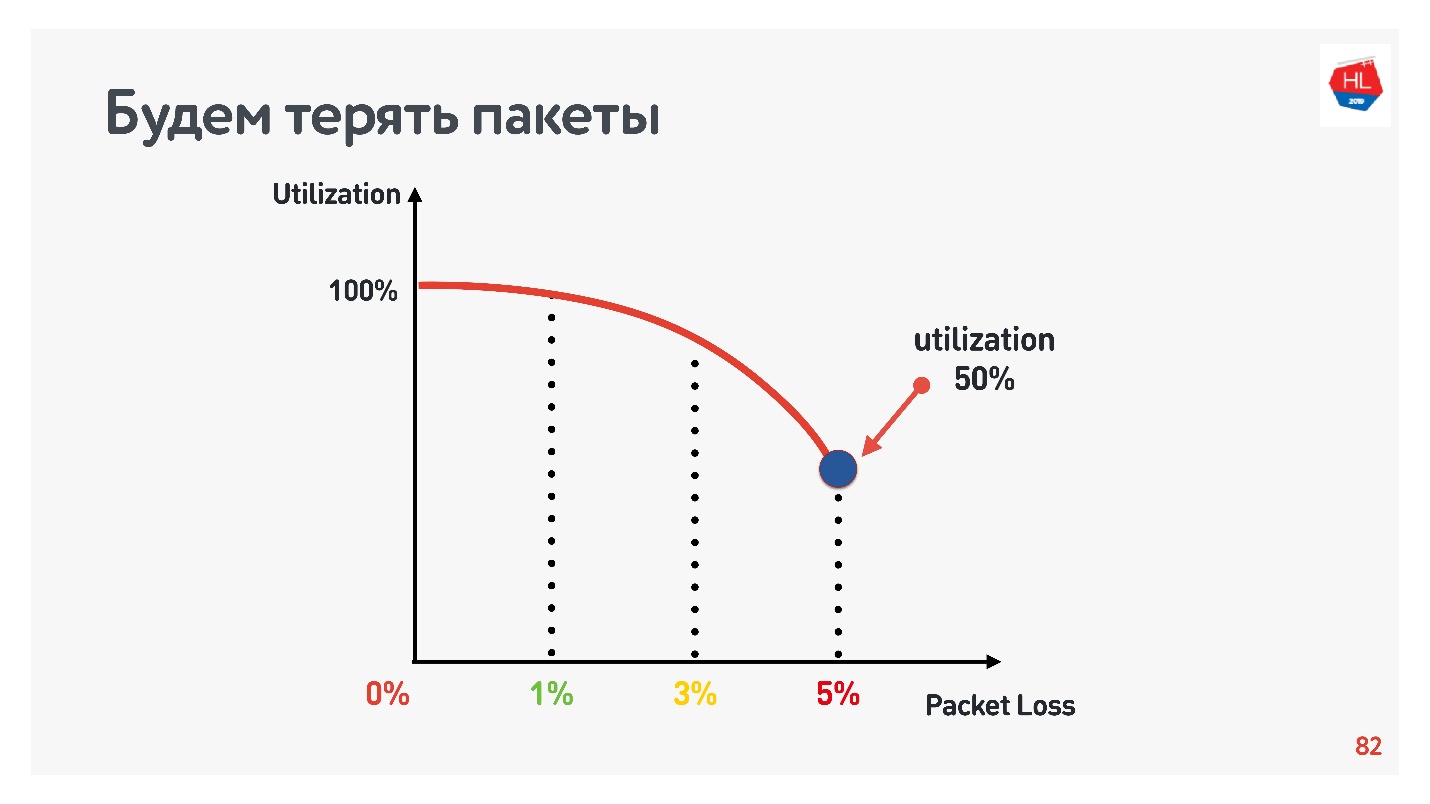
retransmit, , . , , Congestion control.
Congestion control
flow control, .
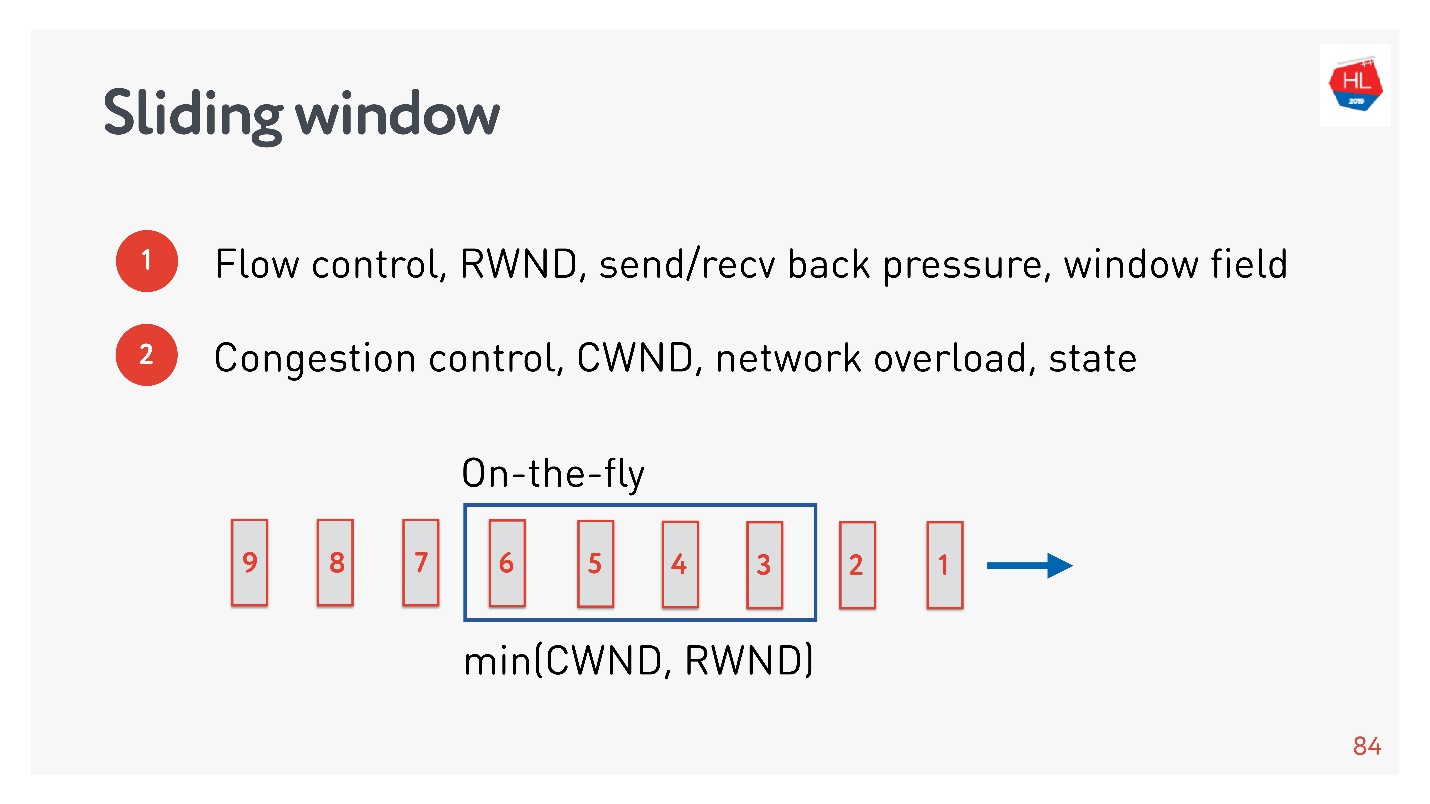
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
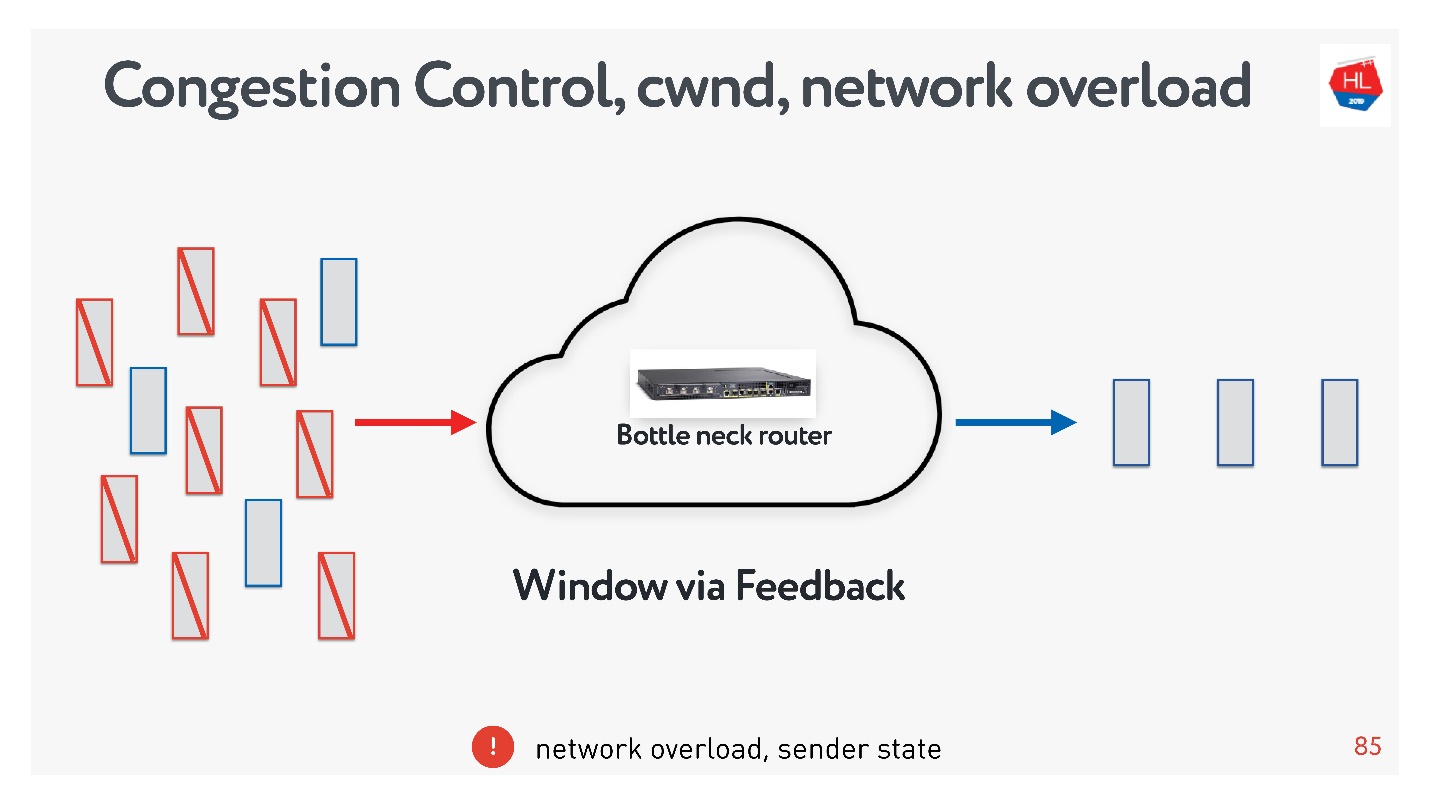
, : , , , . , congestion control.
TCP window.
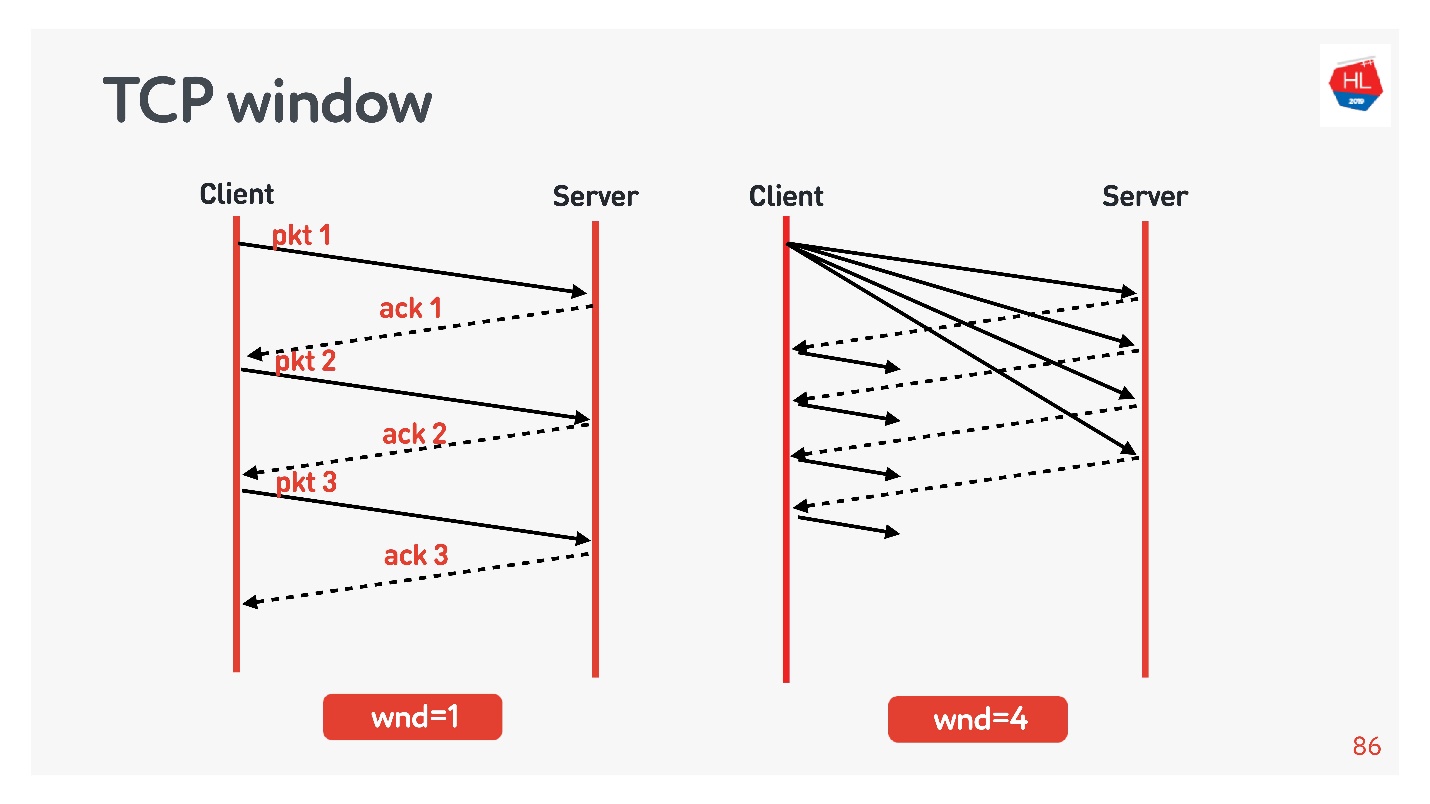
flow control congestion control, .
:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
, , .
?
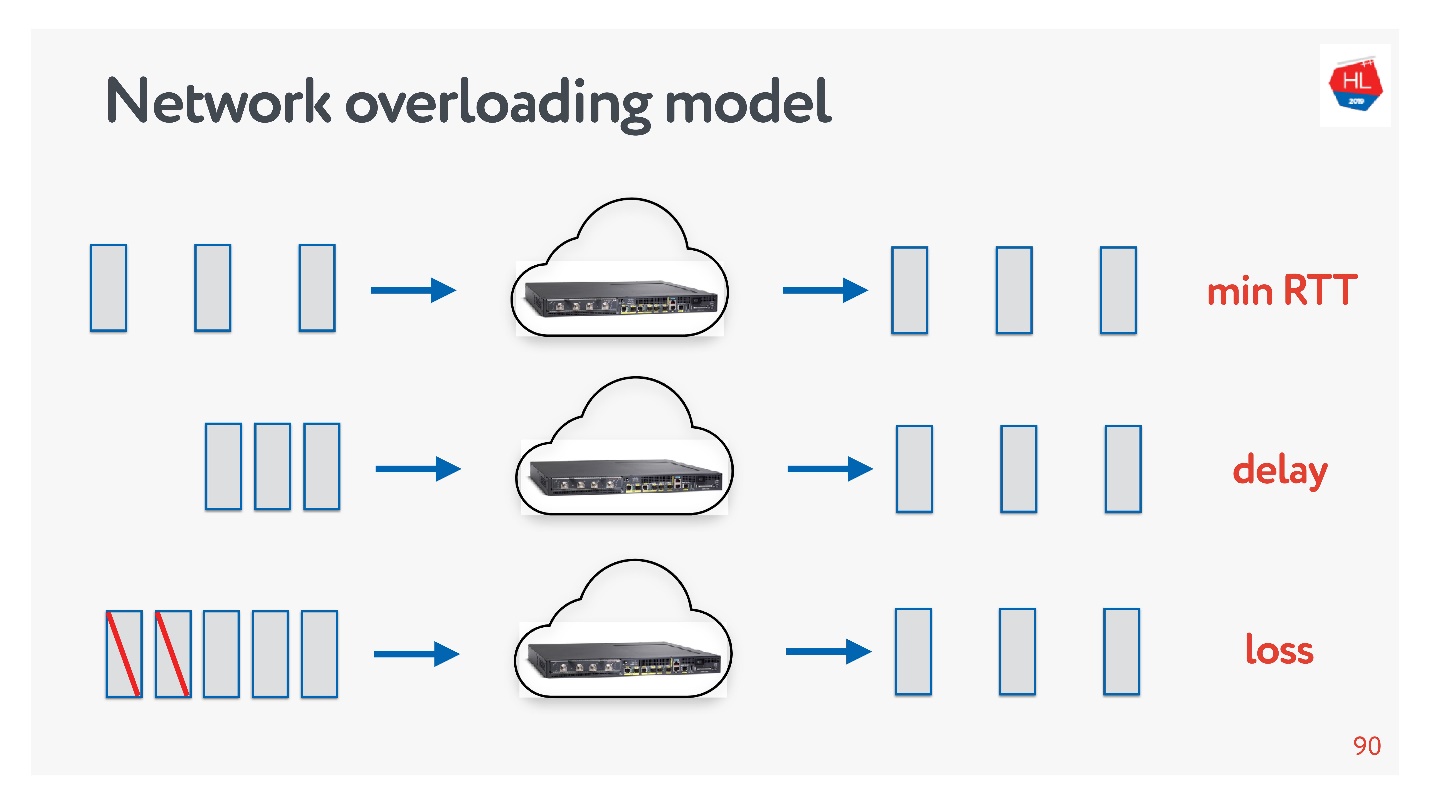
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
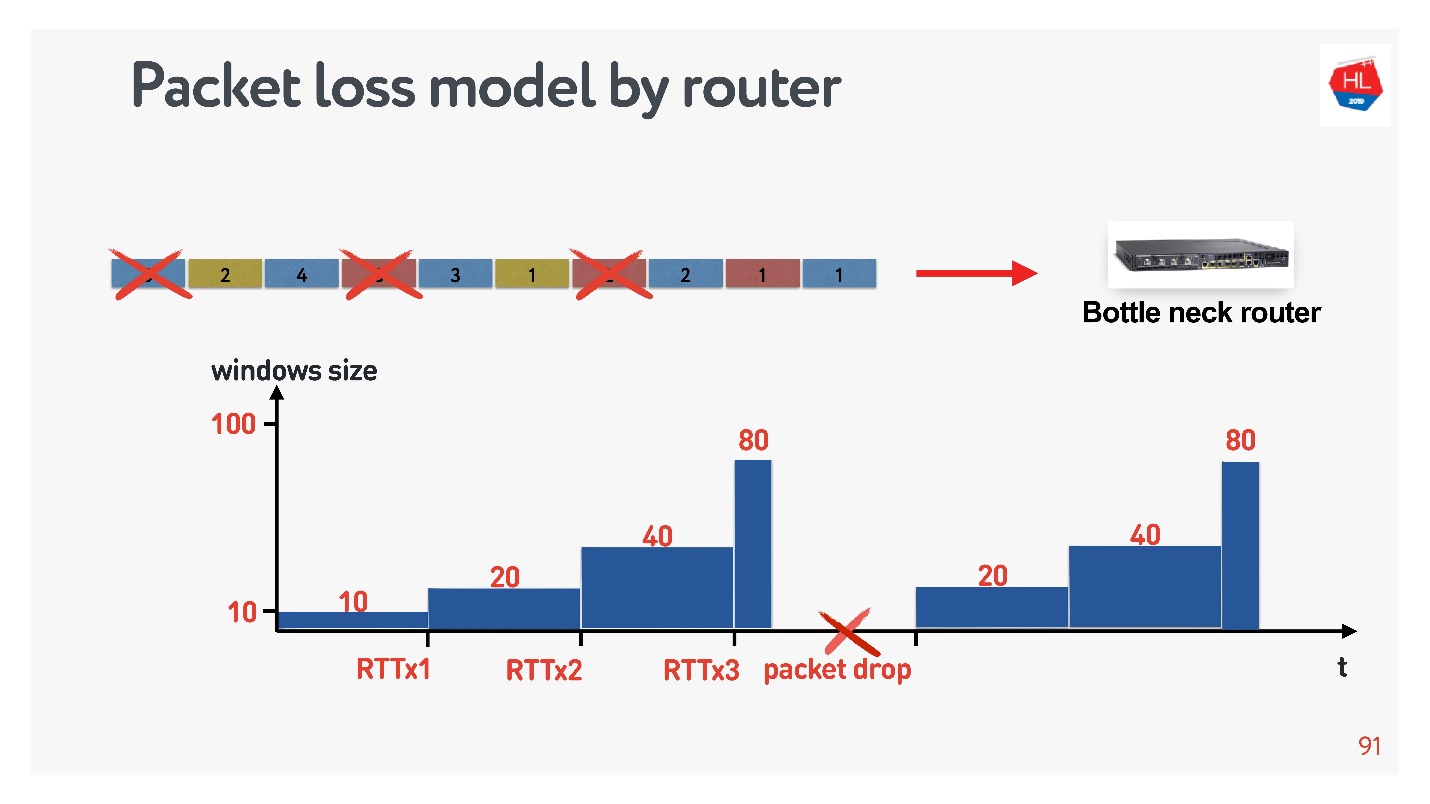
, , . : , .. , . congestion control, TCP window, , .
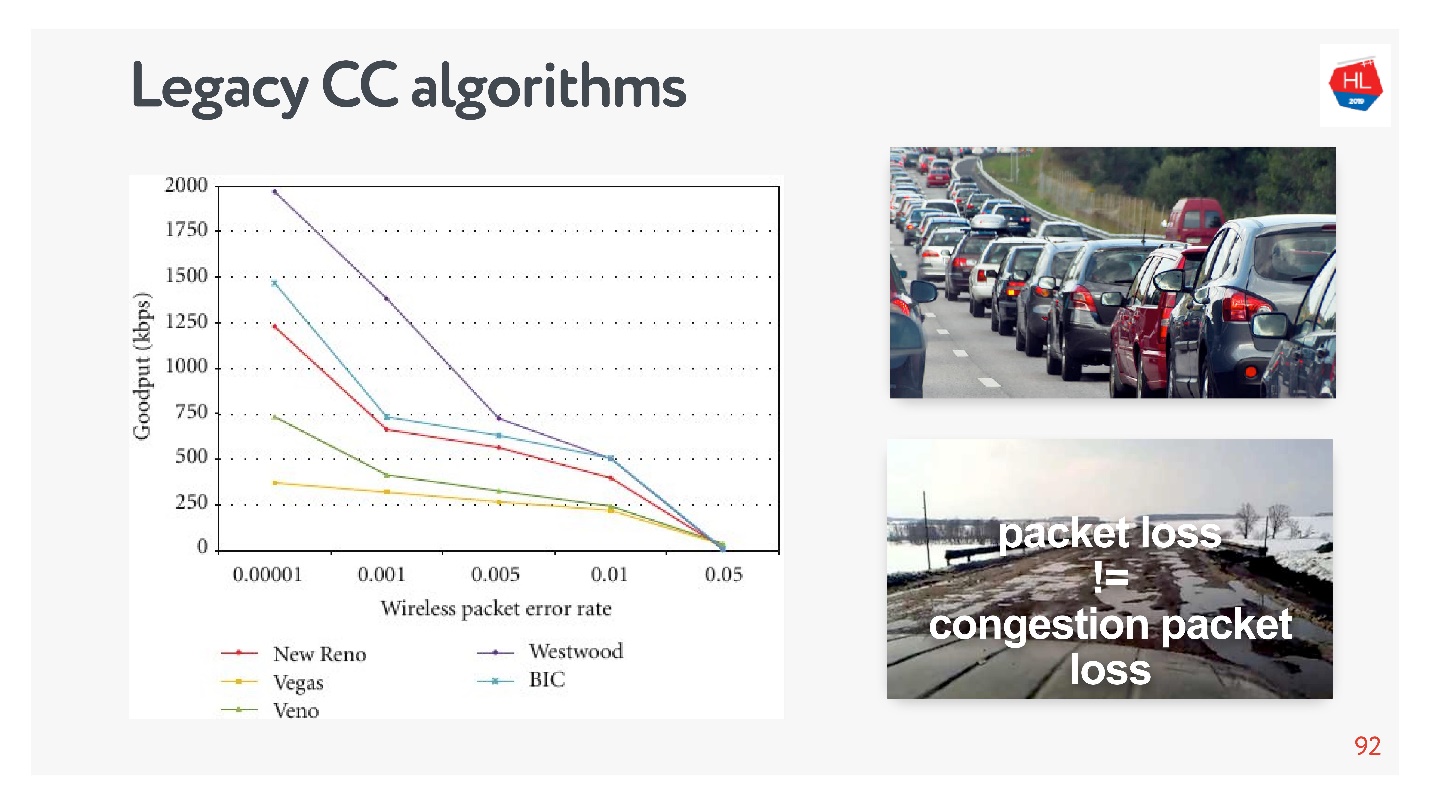
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
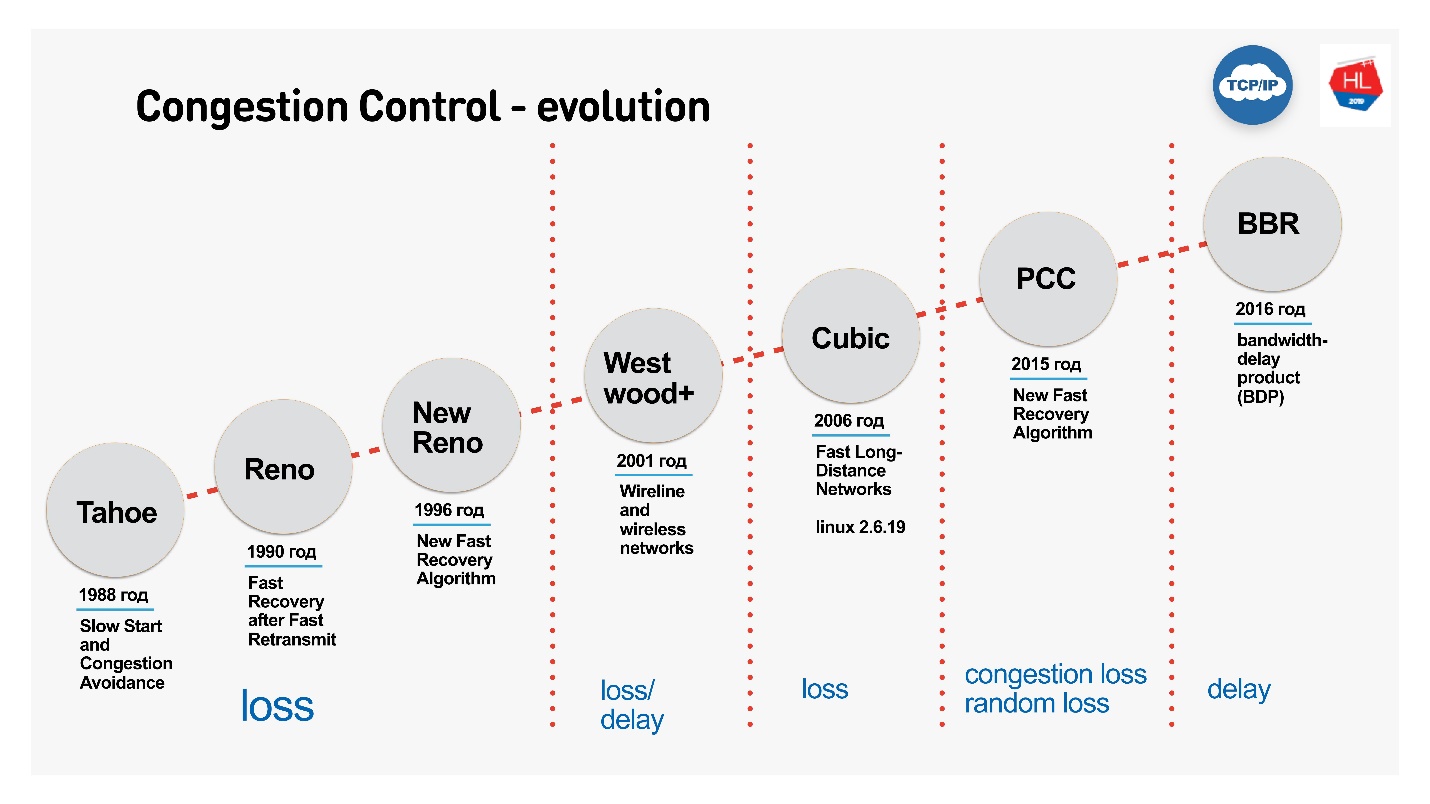
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
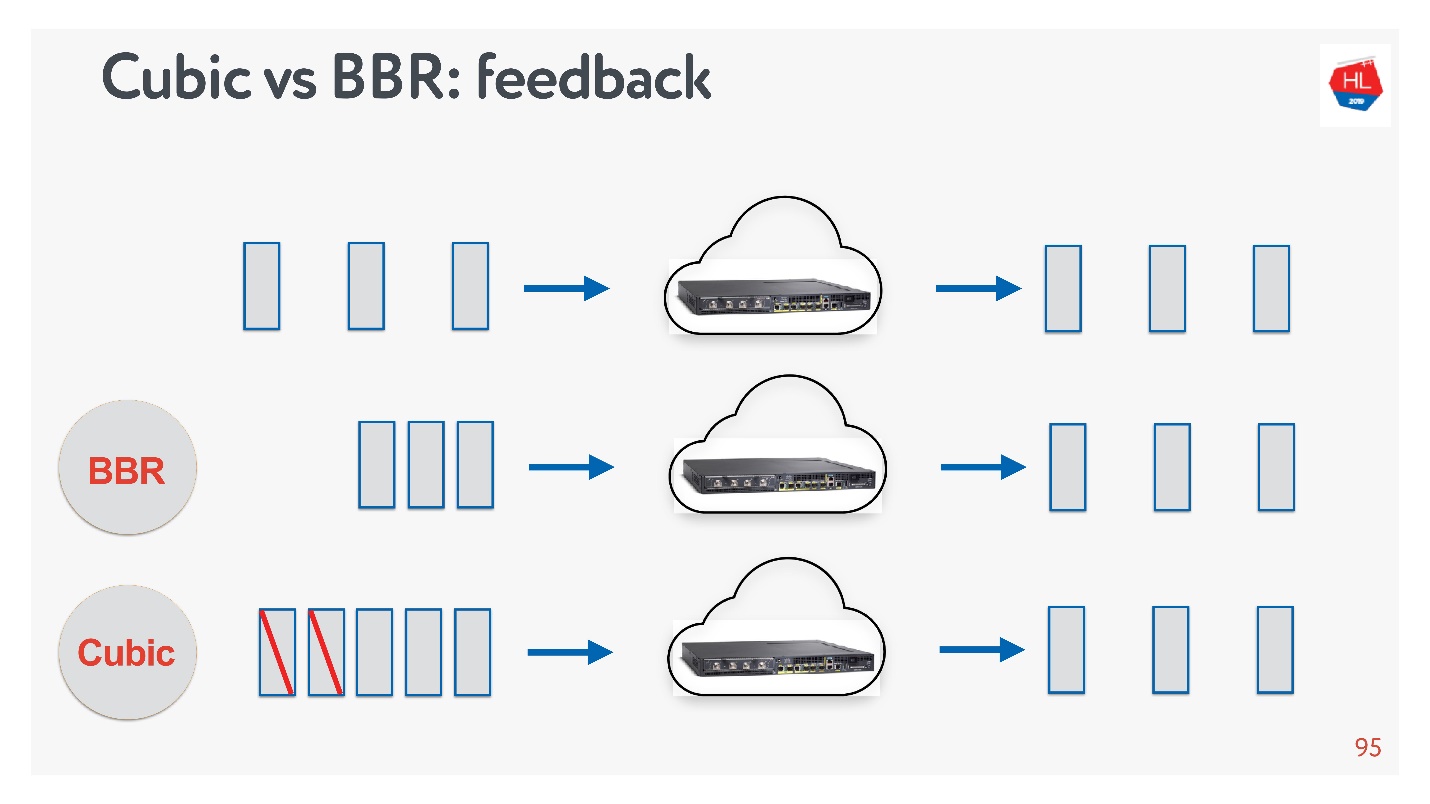
, — acknowledgement . :
Abaixo está um gráfico do atraso versus o tempo de conexão, que mostra o que acontece em diferentes controles de congestionamento.
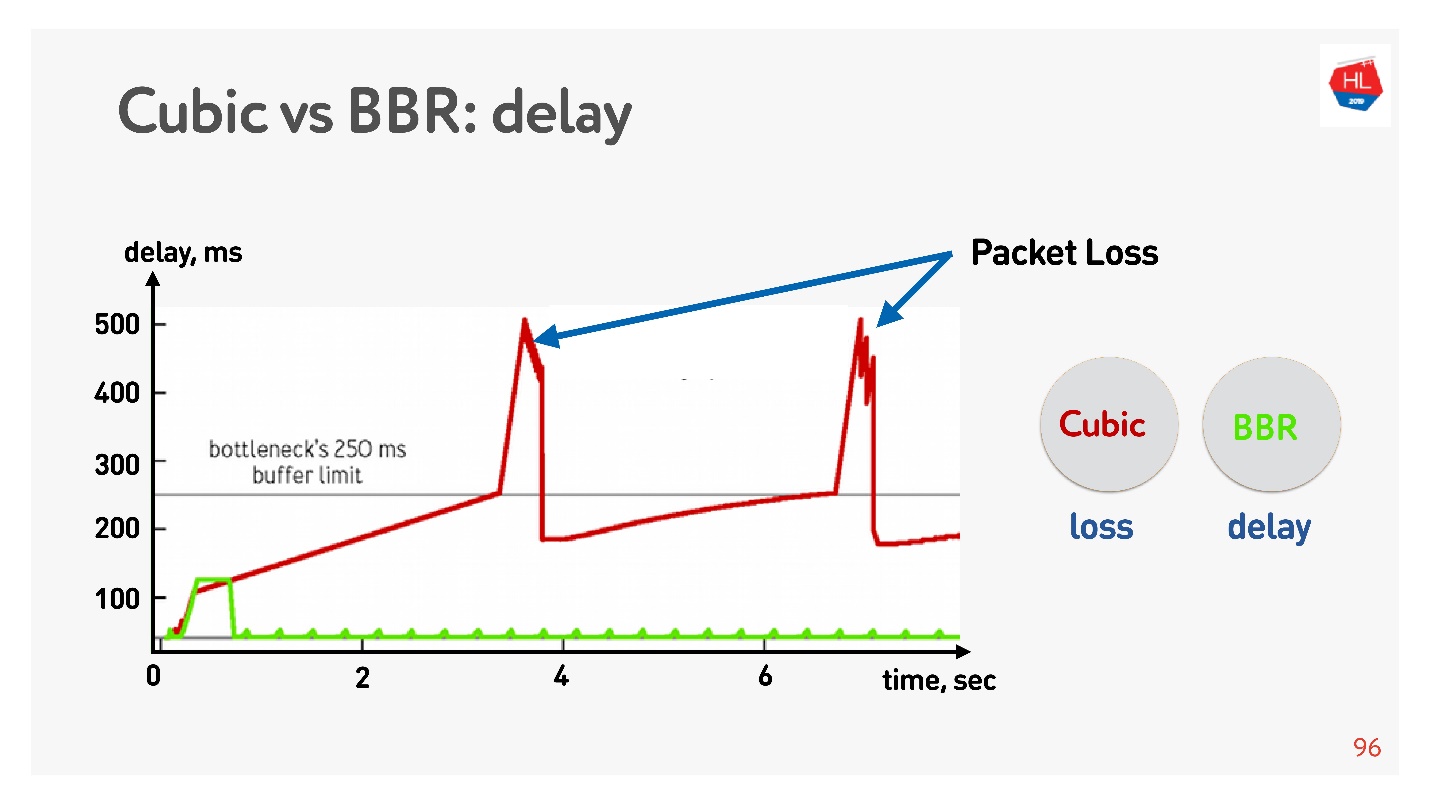
O BBR detecta primeiro o tempo de ida e volta, envia mais e mais pacotes, percebe que o buffer está entupido e entra no modo de operação com um atraso mínimo.
O Cubic trabalha agressivamente - ele excede o buffer inteiro e, quando o buffer excede e a perda de pacotes ocorre, o cubic reduz a janela.
Parece que com a ajuda do BBR seria possível resolver todos os problemas, mas há
instabilidade nas redes - os pacotes às vezes atrasam, outras vezes são agrupados em pacotes. Você os envia com uma certa frequência, e eles vêm em grupos. Pior ainda, quando você recebe agradecimentos de volta a esses pacotes, e eles também de alguma forma "tremem".
Como prometi que tudo poderia ser tocado
manualmente , fazemos o ping, por exemplo, no site
HighLoad ++ , analisamos o ping e consideramos o jitter entre os pacotes.
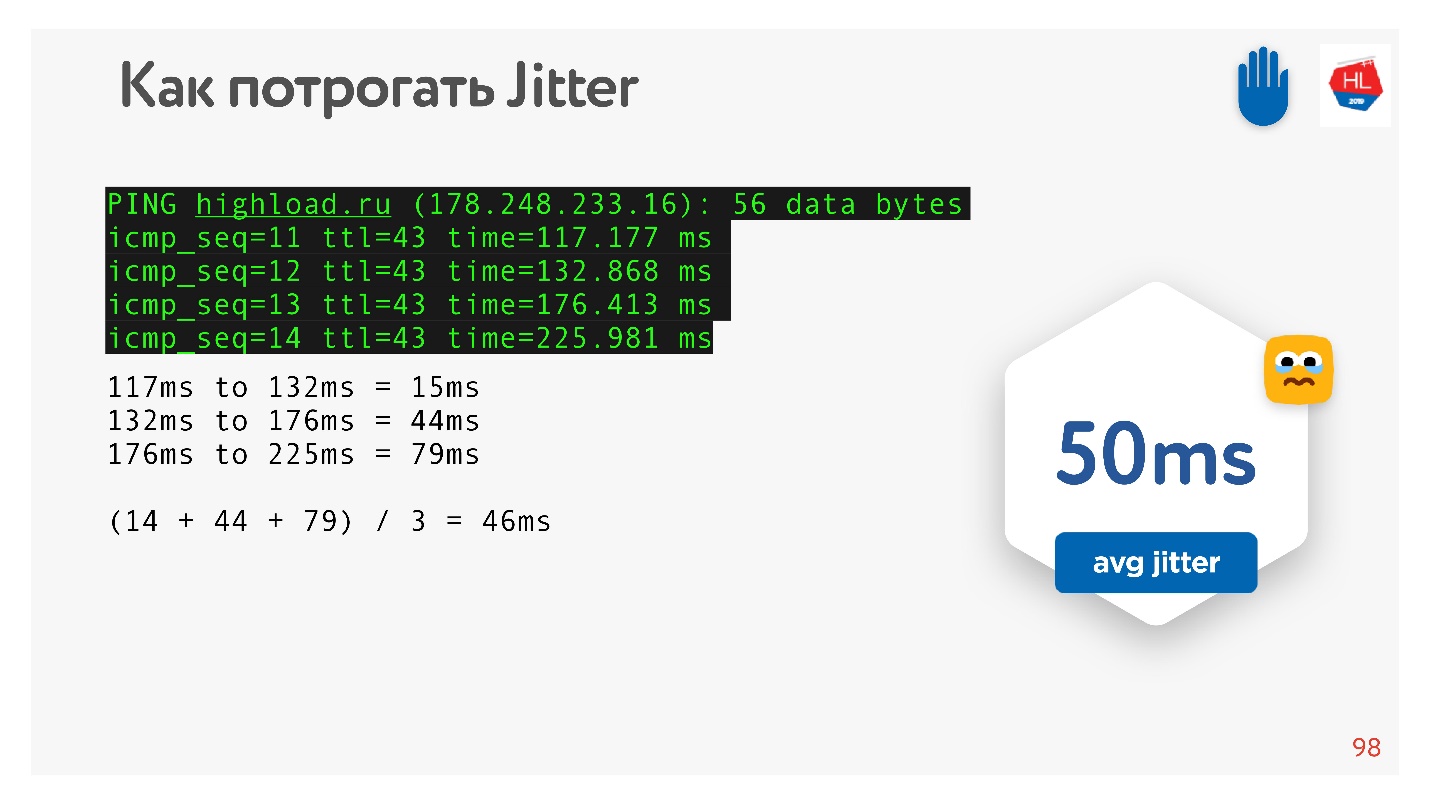
Pode-se ver que os pacotes vêm desigualmente, o jitter médio é de cerca de 50 ms. Naturalmente, o BBR pode estar errado.
O BBR é bom porque distingue entre: perda real de congestionamento, perda de pacotes devido a estouros de buffer do dispositivo e perda aleatória devido a má rede sem fio. Mas não funciona bem em caso de tremulação alta. Como posso ajudá-lo?
Como melhorar o controle de congestionamento
De fato, o TCP não possui informações suficientes em reconhecimento, apenas os pacotes que viu. Há também reconhecimento seletivo, que indica quais pacotes são confirmados e que ainda não chegaram. Mas essa informação não é suficiente.
Se você tiver a oportunidade de aumentar o reconhecimento, ainda poderá economizar o tempo todo - não apenas enviando esses pacotes, mas também chegando ao cliente. Isso é, de fato, no servidor para coletar o cliente jitter.
Por que geralmente é eficaz aumentar o reconhecimento? Porque as redes móveis são assimétricas. Por exemplo, geralmente com 3G ou LTE, 70% da largura de banda é alocada para o download de dados e 30% para o upload. O transmissor muda: upload - download, upload - download e você não o afeta de forma alguma. Se você não descarregar nada, está simplesmente ocioso. Portanto, se você tiver alguma idéia interessante, aumente o reconhecimento, não seja tímido - isso não é um problema.
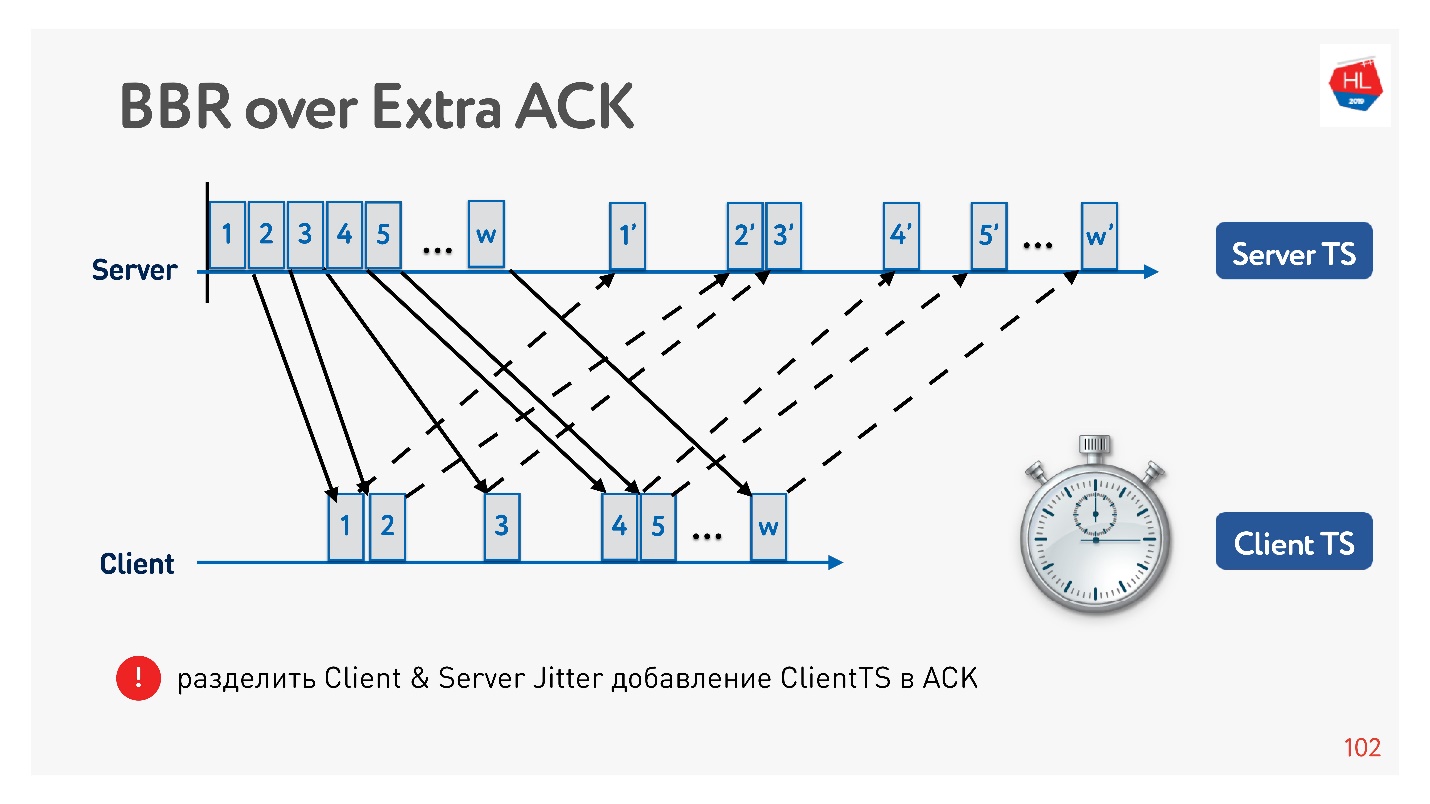
Um exemplo de como você pode usar uma confirmação para dividir o tremor em envio e o tremor em receber e rastreá-los separadamente. Então nos tornamos mais flexíveis e entendemos quando ocorreu perda de congestionamento e quando ocorreu perda aleatória. Por exemplo, você pode entender a quantidade de tremulação em cada direção e configurar a janela com mais precisão.

Qual controle de congestionamento escolher
Os colegas de classe são uma grande rede com muito tráfego diferente: vídeo, API, fotos. E há estatísticas sobre qual controle de congestionamento é melhor escolher.
O BBR é sempre eficaz para o vídeo, pois reduz os atrasos. Em outros casos, o Cubic geralmente é usado - é bom para fotografias. Mas existem outras opções.

Existem dezenas de opções diferentes de controle de congestionamento. Para escolher o melhor, você pode coletar estatísticas no cliente e tentar um ou outro controle de congestionamento para diferentes tipos de perfis de carga.
Por exemplo, esse é o efeito de iniciar o BBR em um vídeo.
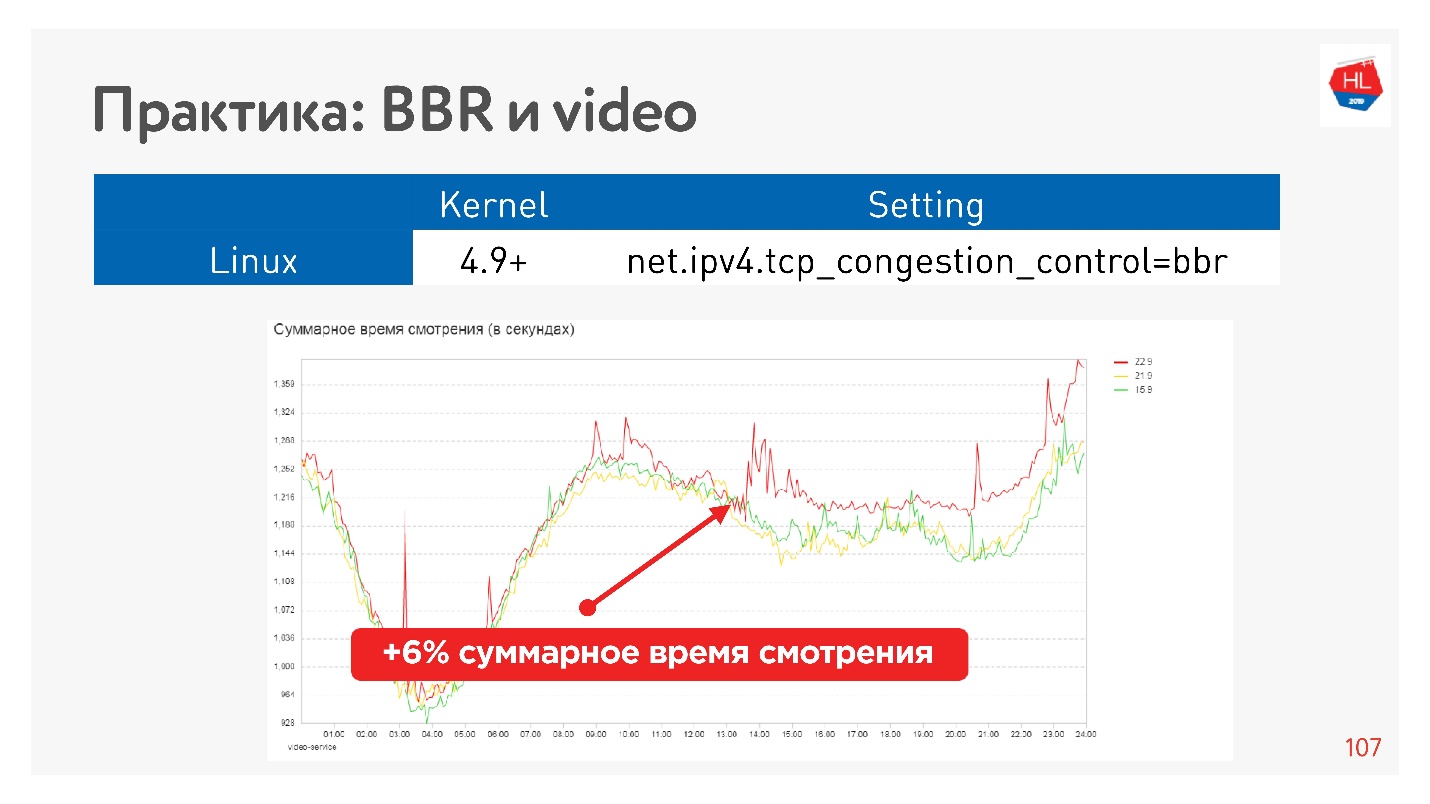
Conseguimos aumentar seriamente a profundidade da visualização. O Google diz que eles têm cerca de 10% menos buffer no player ao usar o BBR.
Ótimo, mas e nossos clientes?

Os clientes são um pouco lentos, todos eles têm Cubic, e você não pode influenciá-lo. Mas tudo bem, às vezes você pode paralelizar dados, e será bom.
Conclusões sobre o controle de congestionamentos:- BBR é sempre bom para vídeo.
- Em outros casos, se usarmos nosso próprio protocolo UDP, você poderá assumir o controle de congestionamento.
- Do ponto de vista do TCP, você pode usar apenas o controle de congestionamento, que está no kernel. Se você deseja implementar seu controle de congestionamento no kernel, deve cumprir a especificação TCP. É impossível inflar reconhecimento, fazer alterações, porque elas simplesmente não estão no cliente.
Se você criar seu protocolo UDP, terá muito mais liberdade em termos de controle de congestionamento.
Multiplexação e Priorização
Esta é uma nova tendência, todo mundo está fazendo isso agora. Que problemas existem? Se usarmos o TCP, certamente todos (ou quase todos) conhecerão a situação de bloqueio do cabeçalho da linha.
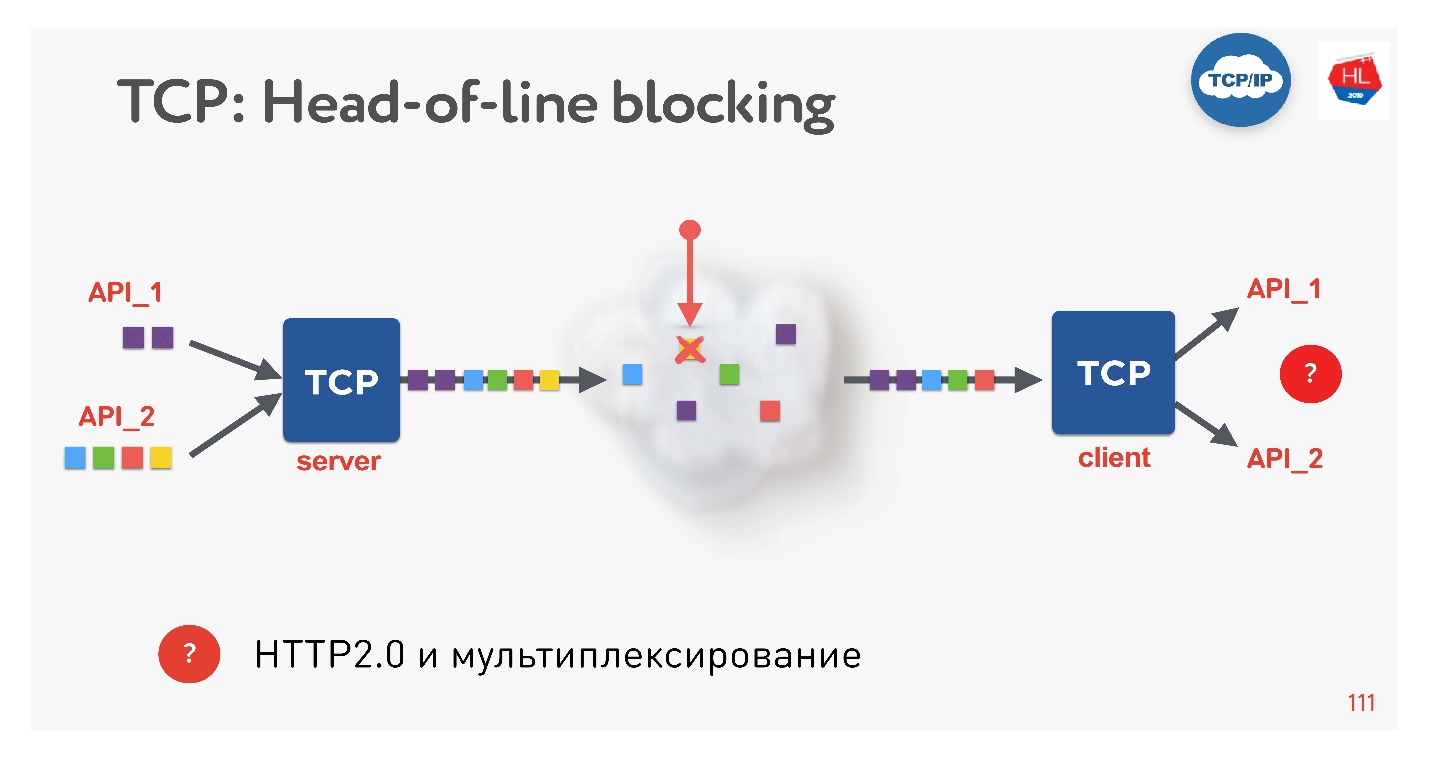
Existem várias solicitações que são multiplexadas em uma única conexão TCP. Nós os enviamos para a rede, mas faltava algum pacote. Uma conexão TCP retransmitirá esse pacote e retransmitirá em um tempo próximo ao RTT ou mais. No momento, não podemos obter nada, embora o buffer TCP contenha dados de outra solicitação que esteja completamente pronta para ser selecionada.
Acontece que a multiplexação por TCP, se você usa HTTP 2.0, nem sempre é eficaz em redes ruins.
O próximo problema é o inchaço do buffer.

Quando uma imagem é enviada ao cliente, o buffer aumenta. Nós o enviamos por um longo tempo e, em seguida, uma solicitação de API é exibida e não pode ser priorizada. Nesses casos, a priorização de TCP não funciona.
Portanto, se a perda de pacotes ocorrer, haverá um bloqueio no cabeçalho da linha e, quando o cliente tiver uma taxa de bits variável (e isso acontece frequentemente com clientes móveis), o efeito bufferbloat será exibido. Como resultado, nem multiplexação, nem priorização, nem envio de servidor, nem tudo o mais funciona, porque temos buffers ou o cliente está esperando alguma coisa.
Se fizermos nossa própria multiplexação, podemos colocar vários dados lá.
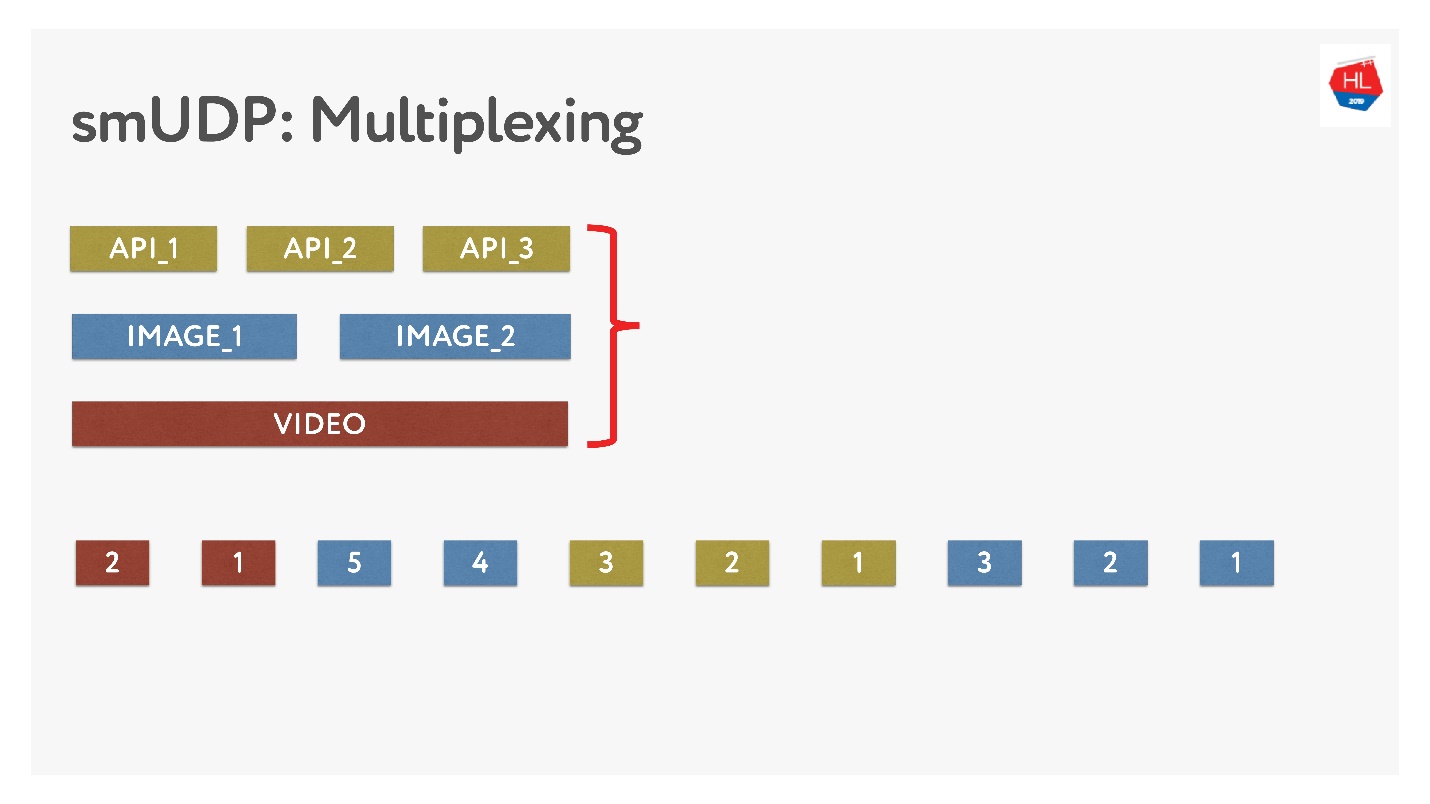
Isso não é difícil, basta adicionar pacotes com números ao buffer. On-the-fly - não toque no que já foi enviado, mas o que ainda não foi enviado pode ser reorganizado. Parece assim.
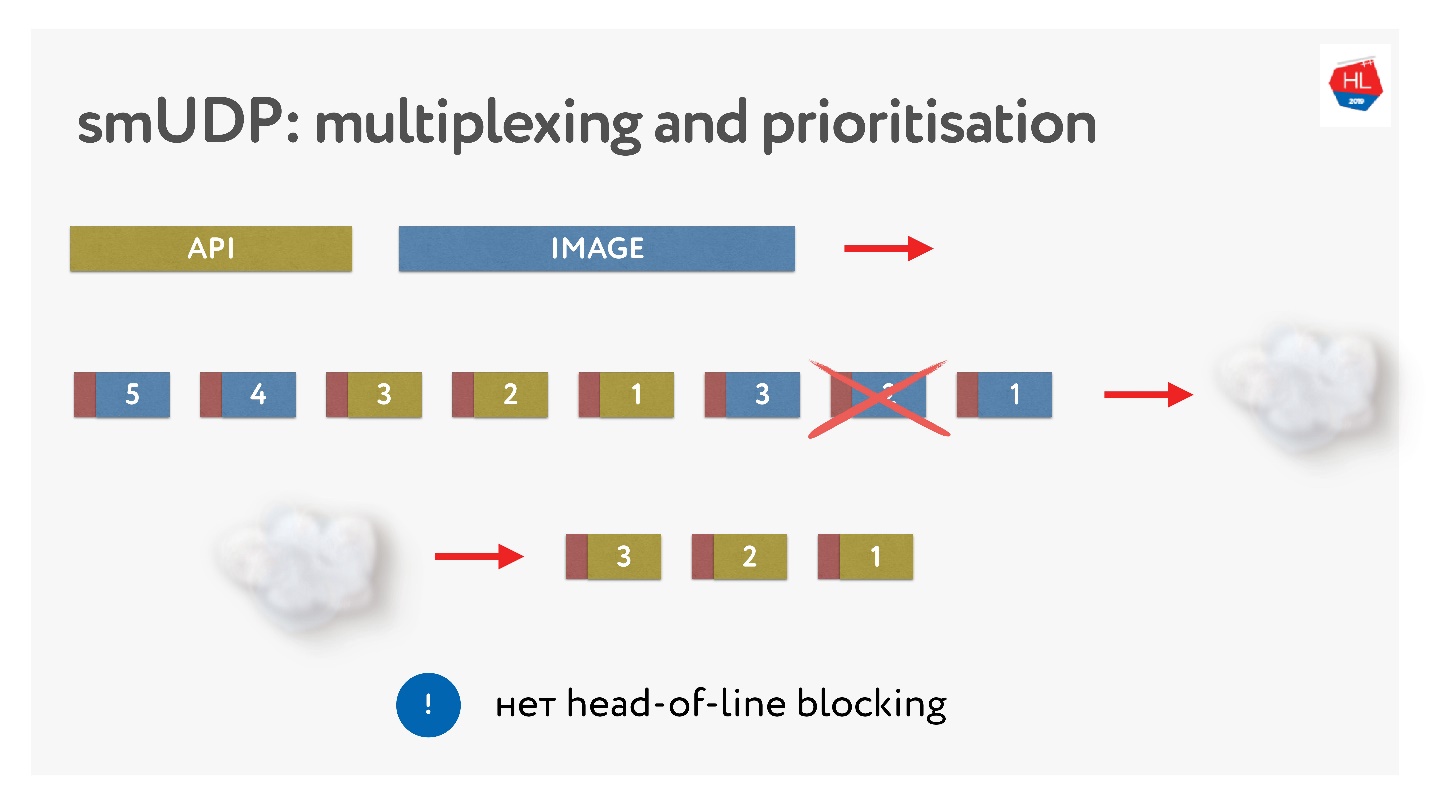
Eles enviaram fotos, dividiram-nos em pacotes, vieram uma solicitação prioritária da API: eles inseriram, enviaram a foto. Mesmo se um pacote estiver faltando, podemos obter uma solicitação de API pronta do buffer, é de alta prioridade e chegará rapidamente ao cliente. No TCP, por definição, a transferência de dados por streaming não é possível.
Estabelecer uma conexão
Se criarmos um perfil de nosso aplicativo, veremos que na maioria das vezes a rede está ociosa no início do aplicativo, porque a conexão é estabelecida antes da API, obtemos os dados e a conexão é estabelecida antes das fotos, o download desses dados etc. Isso sempre acontece - a rede é utilizada por picos.

Para lidar com isso, vamos ver como a conexão é estabelecida.
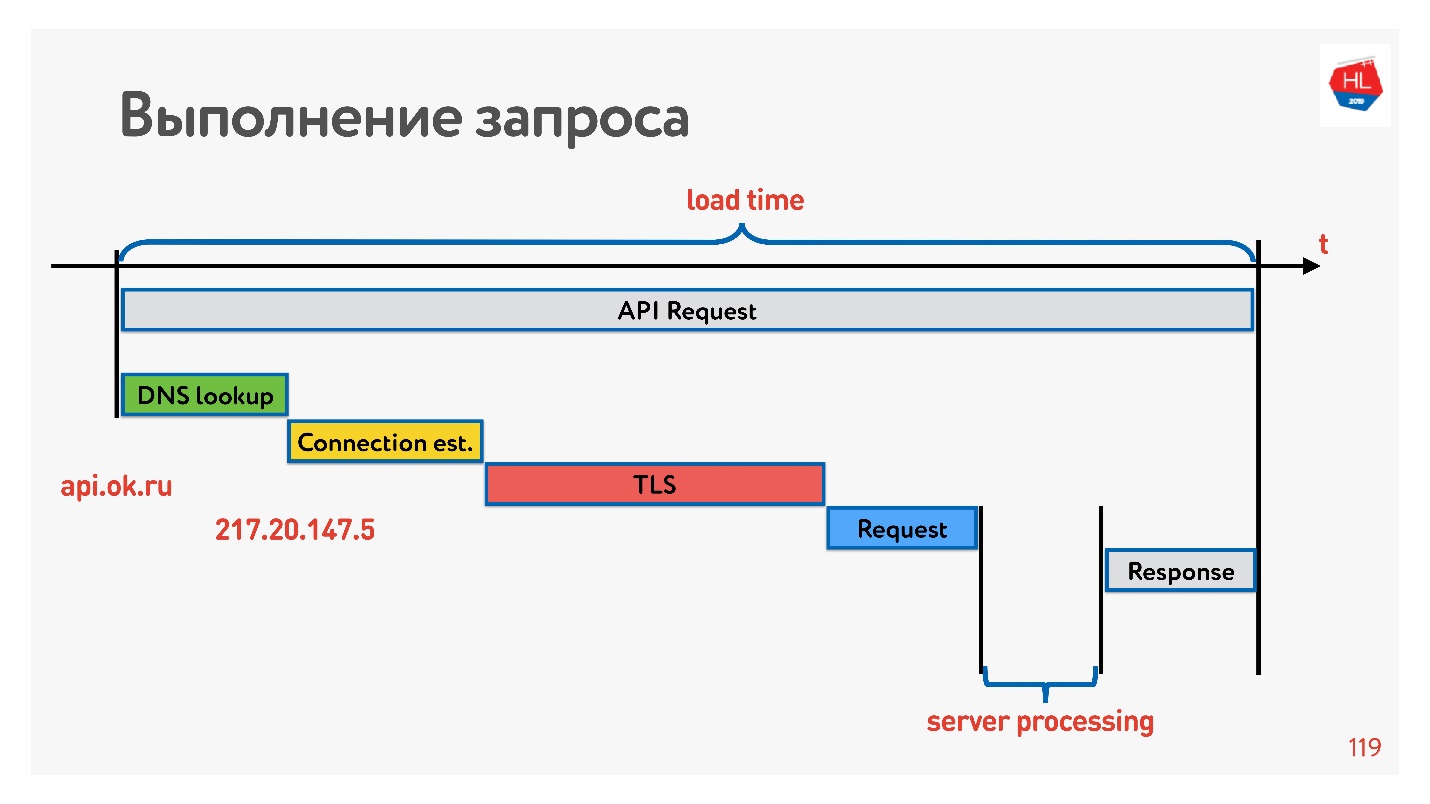
O primeiro é resolver o DNS - não podemos fazer nada com isso. Em seguida, estabeleça uma conexão TCP, estabeleça uma conexão segura, execute a solicitação e receba uma resposta. O mais interessante é que parte do trabalho que o servidor realiza ao responder a uma solicitação geralmente leva menos tempo do que estabelecer uma conexão.
Agora está na moda medir números de latência para memória, discos e outras coisas. Você pode medi-los para uma rede 3G, 4G e ver quanto tempo leva, no pior caso, para estabelecer uma conexão TCP com o TLS.
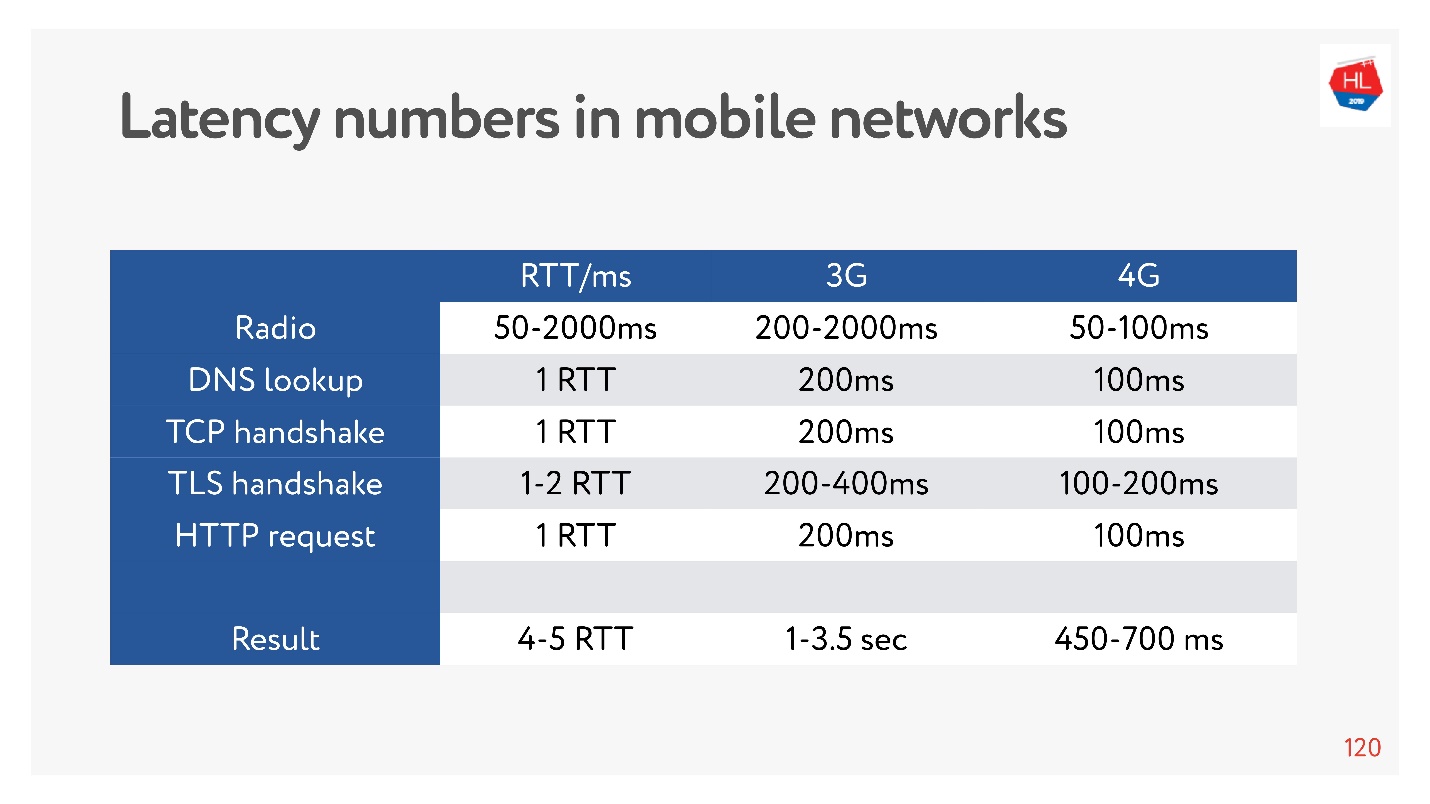
E isso pode ser segundos! Mesmo em 4G de até 700 ms também é significativo. Mas o TCP não conseguiu viver tão facilmente esse tempo todo.
A conexão é baseada no algoritmo básico
de handshake de 3 vias TCP . Faça syn, syn + ack e corrija a solicitação mais tarde (à esquerda no diagrama).
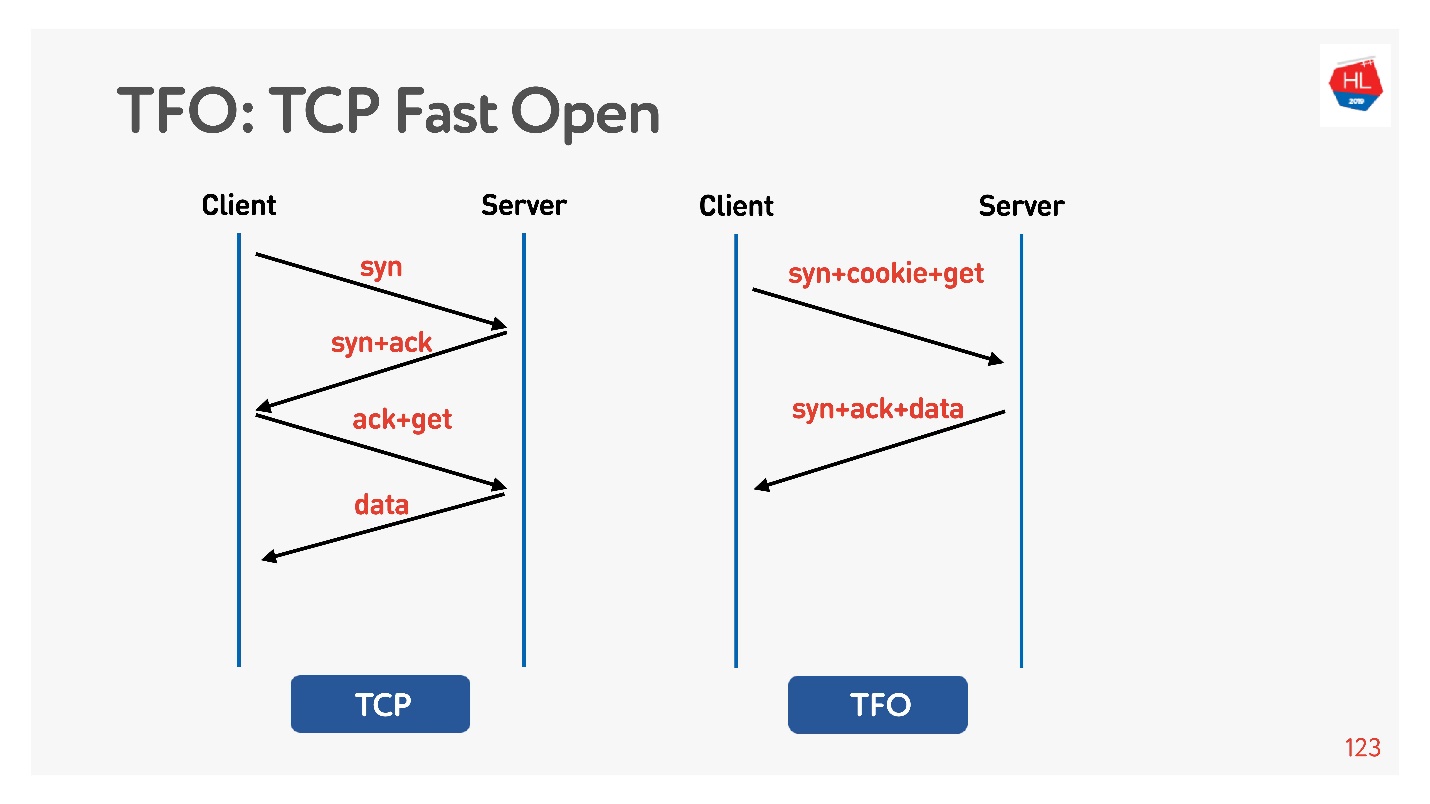
Existe o
TCP Fast Open (à direita). Se você já tiver um handshake com este servidor, houver um cookie, poderá enviar sua solicitação imediatamente para zero-RTT. Para usar isso, você precisa criar um soquete, fazer sendto () os primeiros dados, dizer que deseja FASTOPEN.

O Nginx pode fazer tudo isso - basta ativá-lo, tudo funcionará (ou ativá-lo no kernel).
TLS
Vamos verificar se o TLS está ruim.
Eu configurei o shaper líquido para 200 ms novamente, executei ping no google.com e vi que RTT = 220 é o meu shaper RTT + RTT. Então eu fiz uma solicitação via HTTP e HTTPS. Eu descobri que por HTTP é possível obter uma resposta durante o RTT, ou seja, o TFO funciona para o Google no meu computador. Para HTTPS, isso levou mais tempo.

Essa é uma sobrecarga TLS tão comum que requer mensagens para estabelecer uma conexão segura.
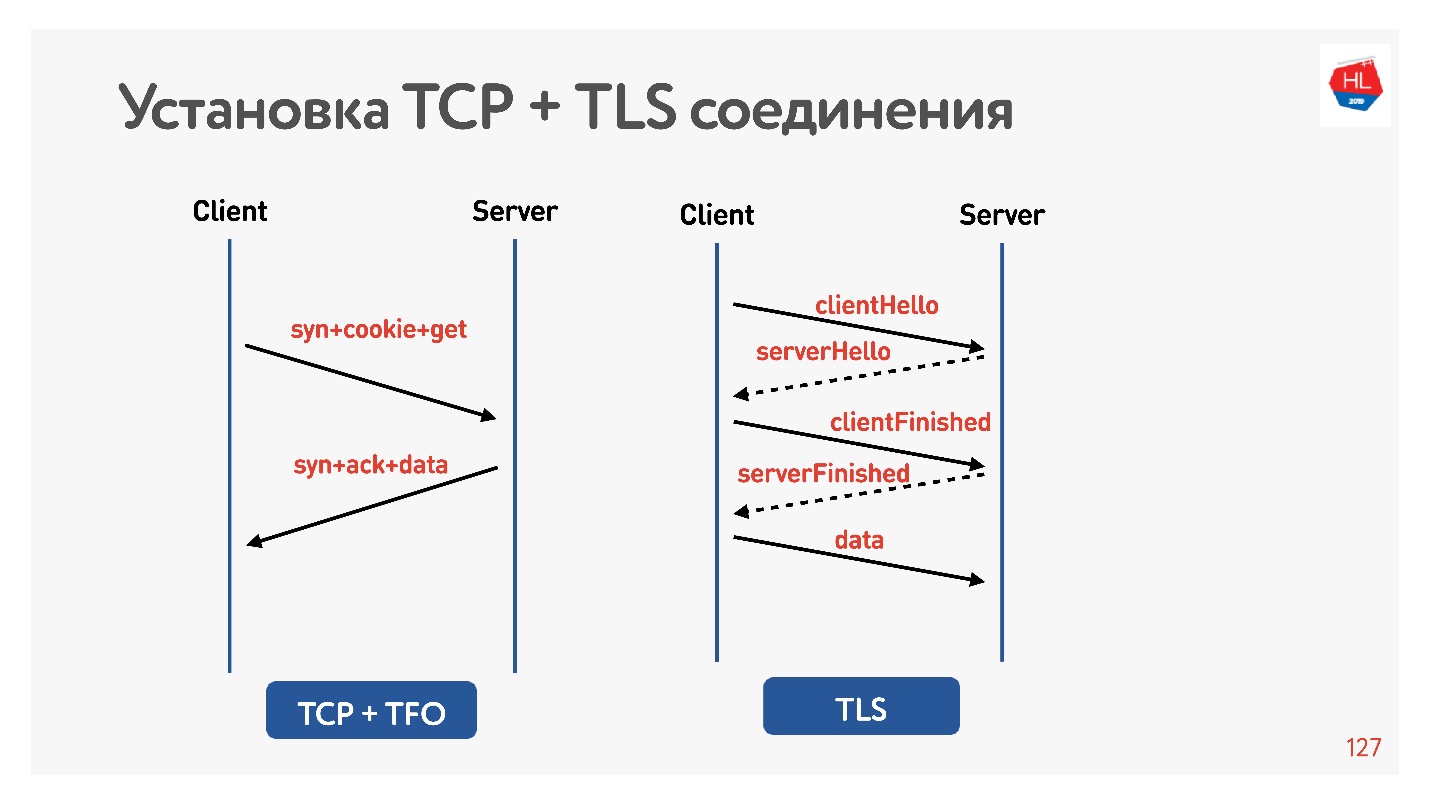
Para fazer isso, eles pensaram para nós, adicionou o TLS 1.3. Também é fácil de incluir no nginx.
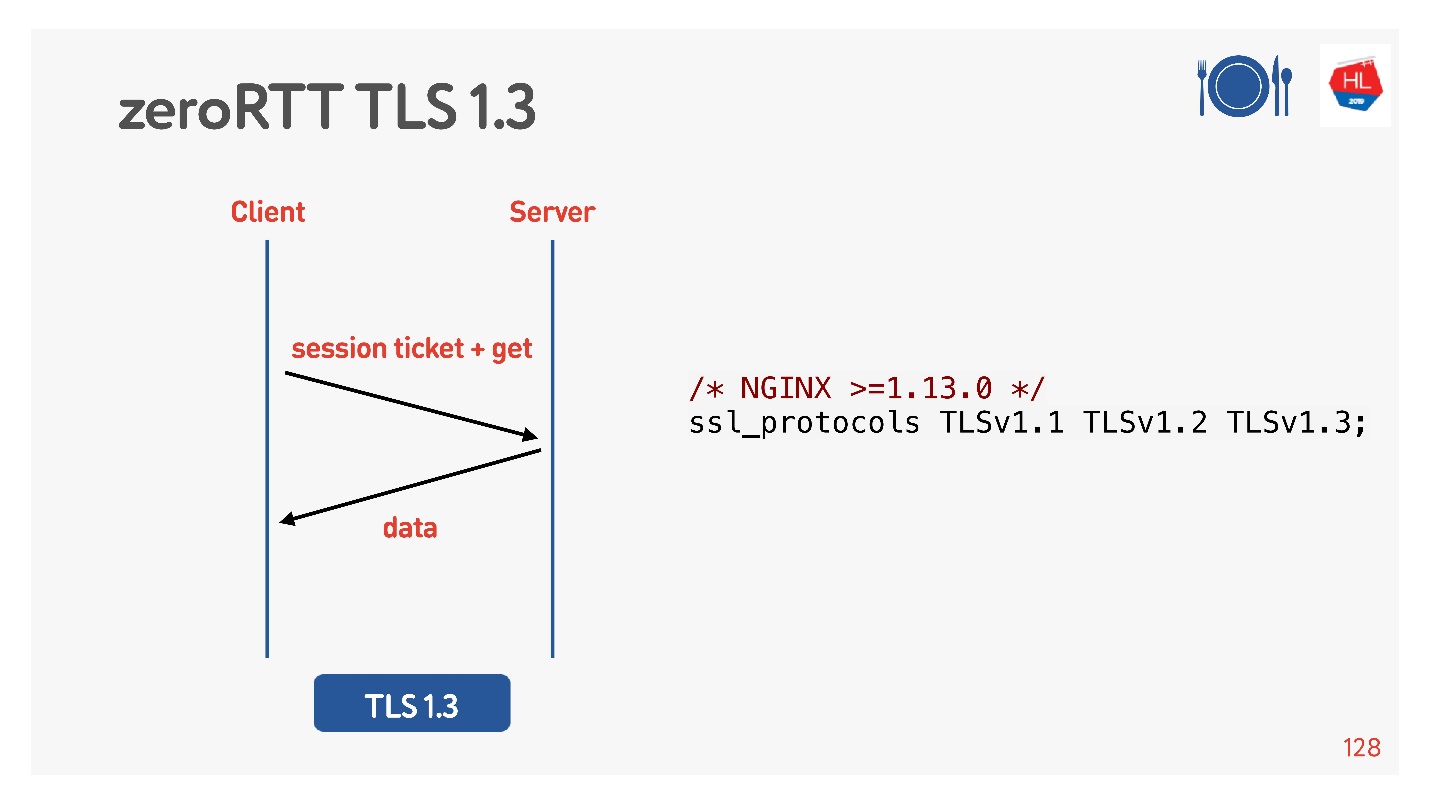
Tudo parece funcionar. Mas vamos ver o que há em nossos clientes móveis que aproveitam tudo isso.
O que há com os clientes
O TCP Fast Open é uma coisa interessante. Segundo as estatísticas.
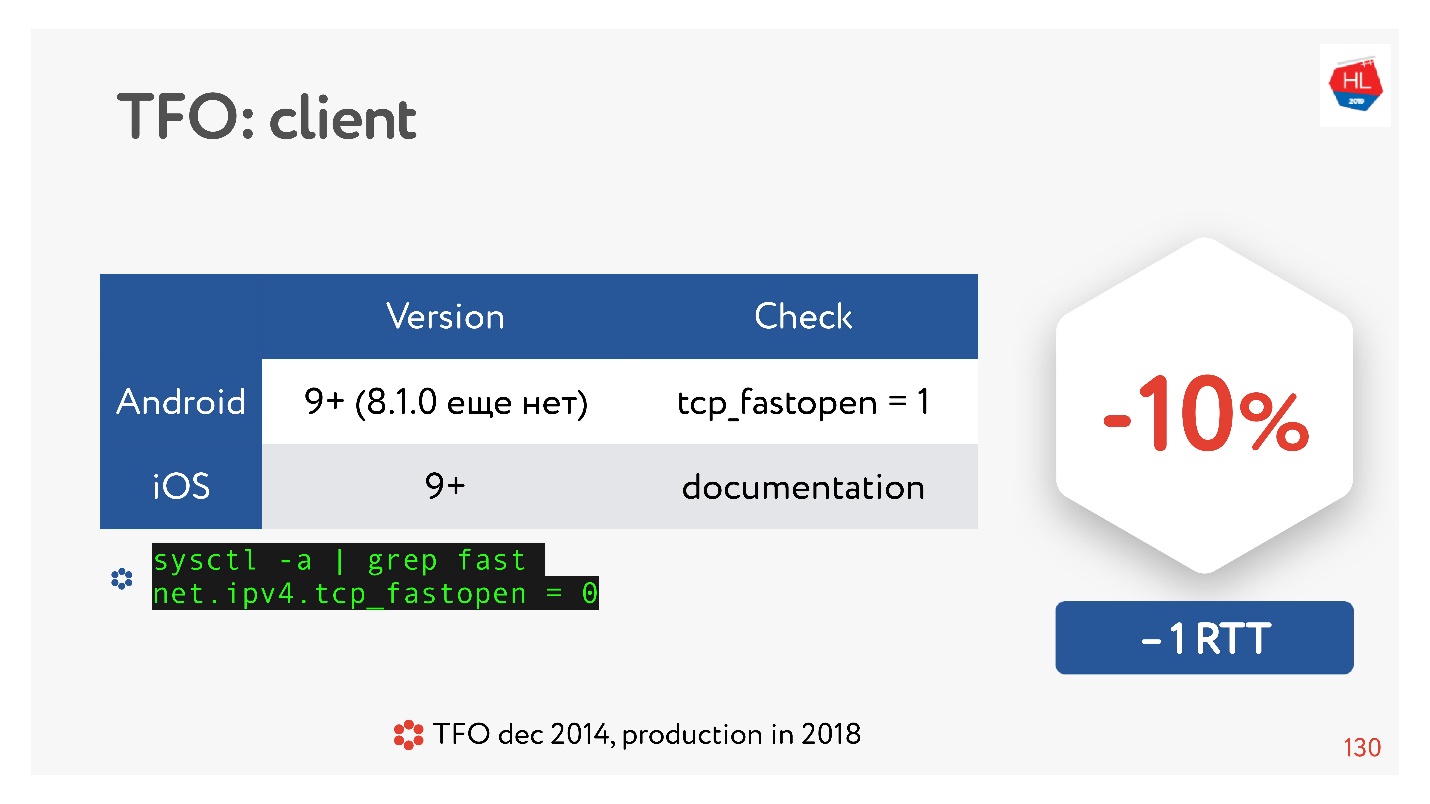
Existem muitos artigos que afirmam que o estabelecimento de uma conexão passa 10% mais rápido. Mas no Android 8.1.0 (eu assisti vários dispositivos) ninguém tem TFO. No Android 9, vi o TFO no emulador, mas não em dispositivos reais. IOS é um pouco melhor. Aqui você pode ver:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
Por que isso aconteceu? O TCP Fast Open foi proposto em 2014, agora já é um padrão, é suportado no Linux e está tudo ótimo. Mas existe um problema tão grande que o aperto de mão do TFO começou a desmoronar em algumas redes. Isso ocorre porque alguns provedores (ou alguns dispositivos) estão acostumados a inspecionar o TCP, fazendo suas otimizações e não esperavam que o handshake TFO estivesse lá. Portanto, sua implementação levou muito tempo e, até agora, os clientes móveis não a incluem por padrão, pelo menos no Android.
Com o TLS 1.3, o que nos promete configuração zero de conexão RTT é ainda melhor. Não encontrei nenhum dispositivo Android em que funcionasse. Portanto, o Facebook criou a biblioteca
Fizz . Há alguns meses, ele ficou disponível em código aberto, você pode arrastá-lo com você e usar o TLS 1.3. Acontece que mesmo a segurança precisa ser arrastada, nada aparece no centro disso.
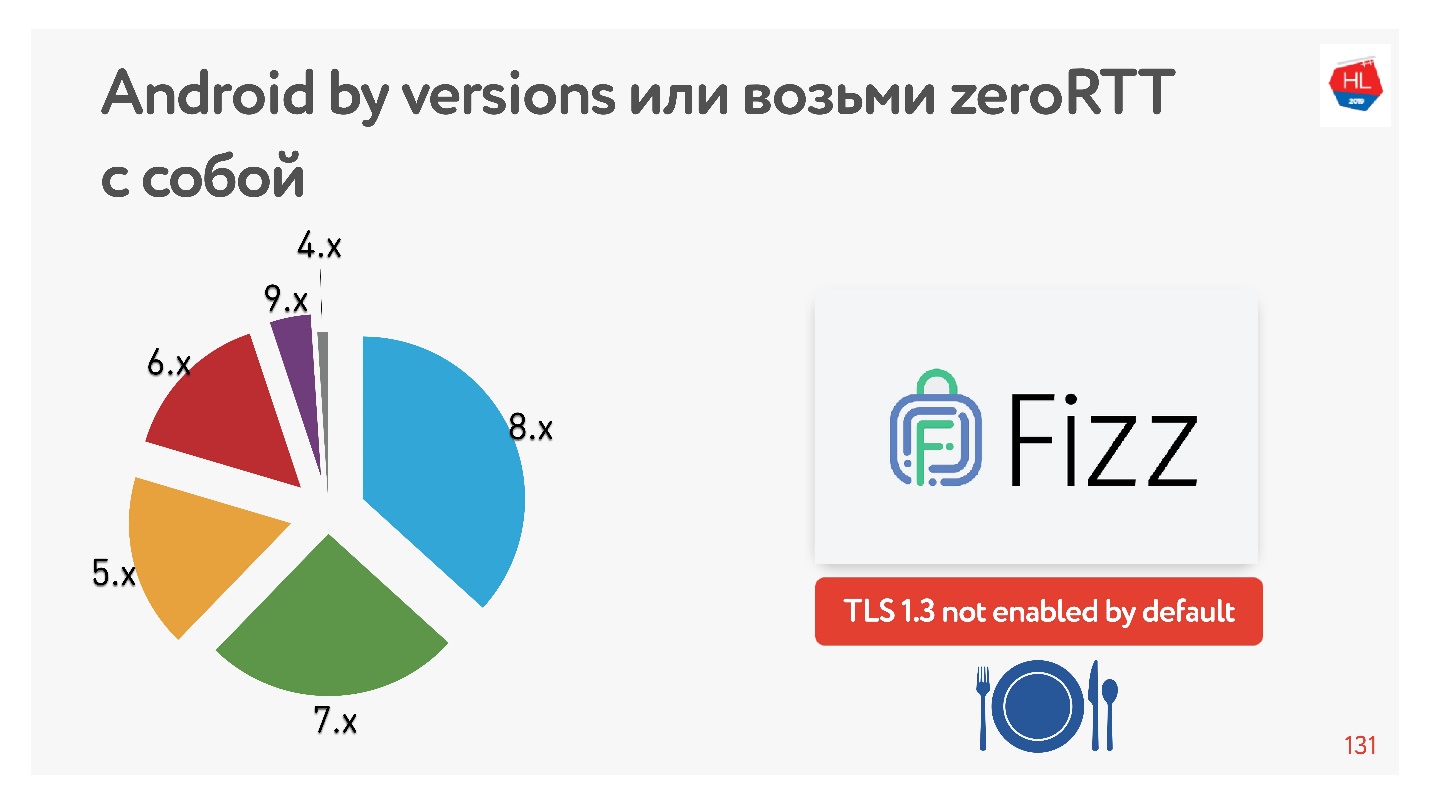
O diagrama mostra o uso de várias versões do Android por nossos clientes móveis. V 9.x é bastante - onde TFO pode aparecer e TLS1.3 não é encontrado em nenhum outro lugar.
Conclusões sobre o estabelecimento de uma conexão:- O TFO não está disponível para 95% dos dispositivos.
- O TLS1.3 precisa ser trazido consigo.
- Se você precisar repetir isso no UDP, transfira tudo para o UDP e repita.
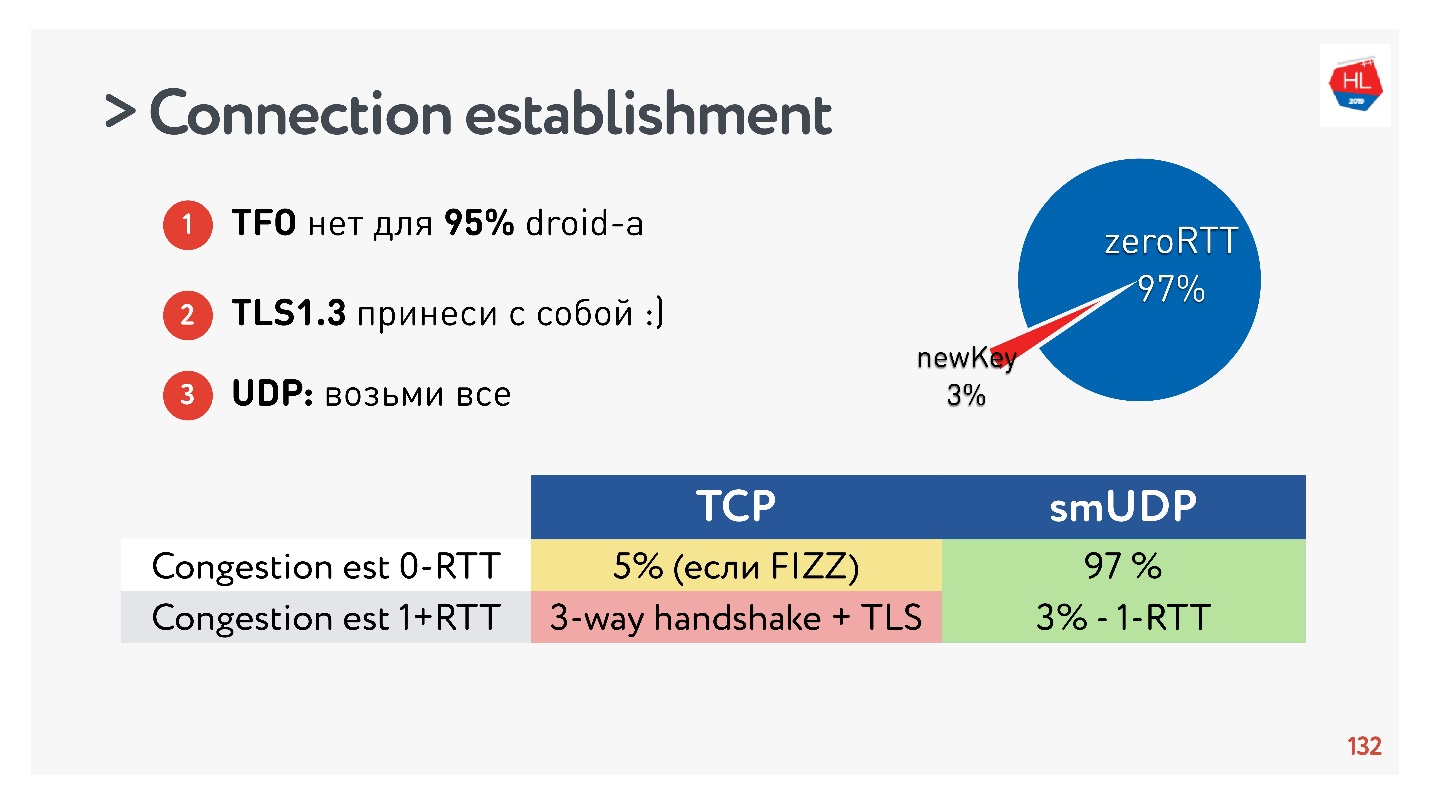
Verificou-se que 97% das conexões criadas usam a chave existente, ou seja, 97% são criadas para zero RTT e apenas 3% são novas. A chave é armazenada no dispositivo por algum tempo.
O TCP não pode se gabar. Em um máximo de 5% dos casos, se você fizer tudo certo, poderá obter o RTT zero zero real de que todos estão falando agora.
Alteração de endereço IP
Muitas vezes, quando você sai de casa, seu telefone muda de Wi-Fi para 4G.
O TCP funciona assim: o endereço IP mudou - a conexão falhou.
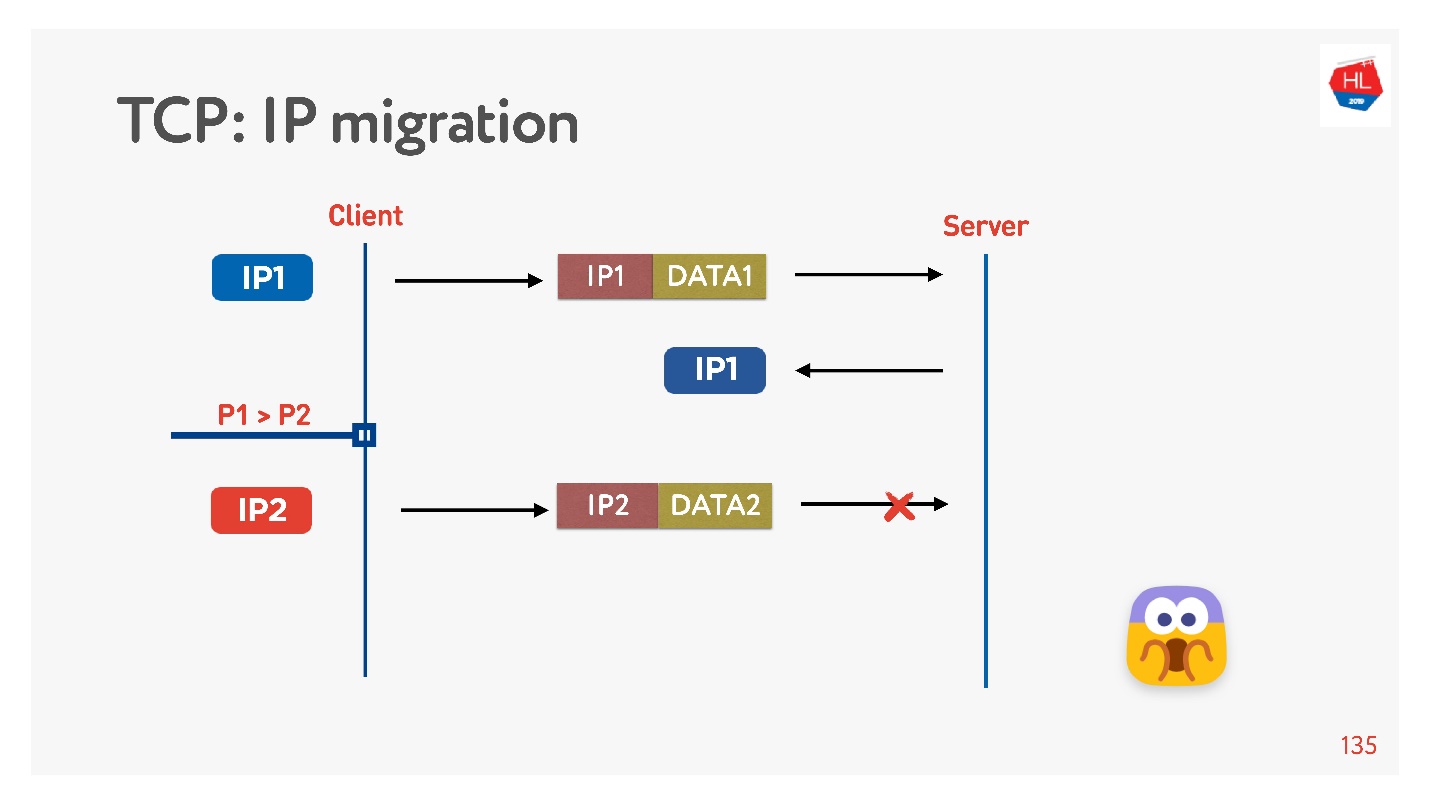
Se você escrever seu protocolo UDP, é muito simples, implementando um ID de conexão (CUID) em cada pacote, você poderá identificá-lo mesmo se vier de um endereço IP diferente.

É claro que você precisa ter certeza de que possui a chave correta, tudo é descriptografado etc. Mas, em princípio, você pode começar a responder a este endereço, não haverá problemas com isso.
No TCP, a migração de IP é uma coisa impossível.
Se você criar seu UDP e vier para o mesmo servidor, precisará fazer um pouco de mágica, incluir o CID em cada pacote e poderá usar a conexão estabelecida ao alterar o endereço IP.
Reutilização de conexão
Todo mundo diz que você precisa reutilizar conexões porque as conexões são muito caras.

Mas existem armadilhas na reutilização de compostos.
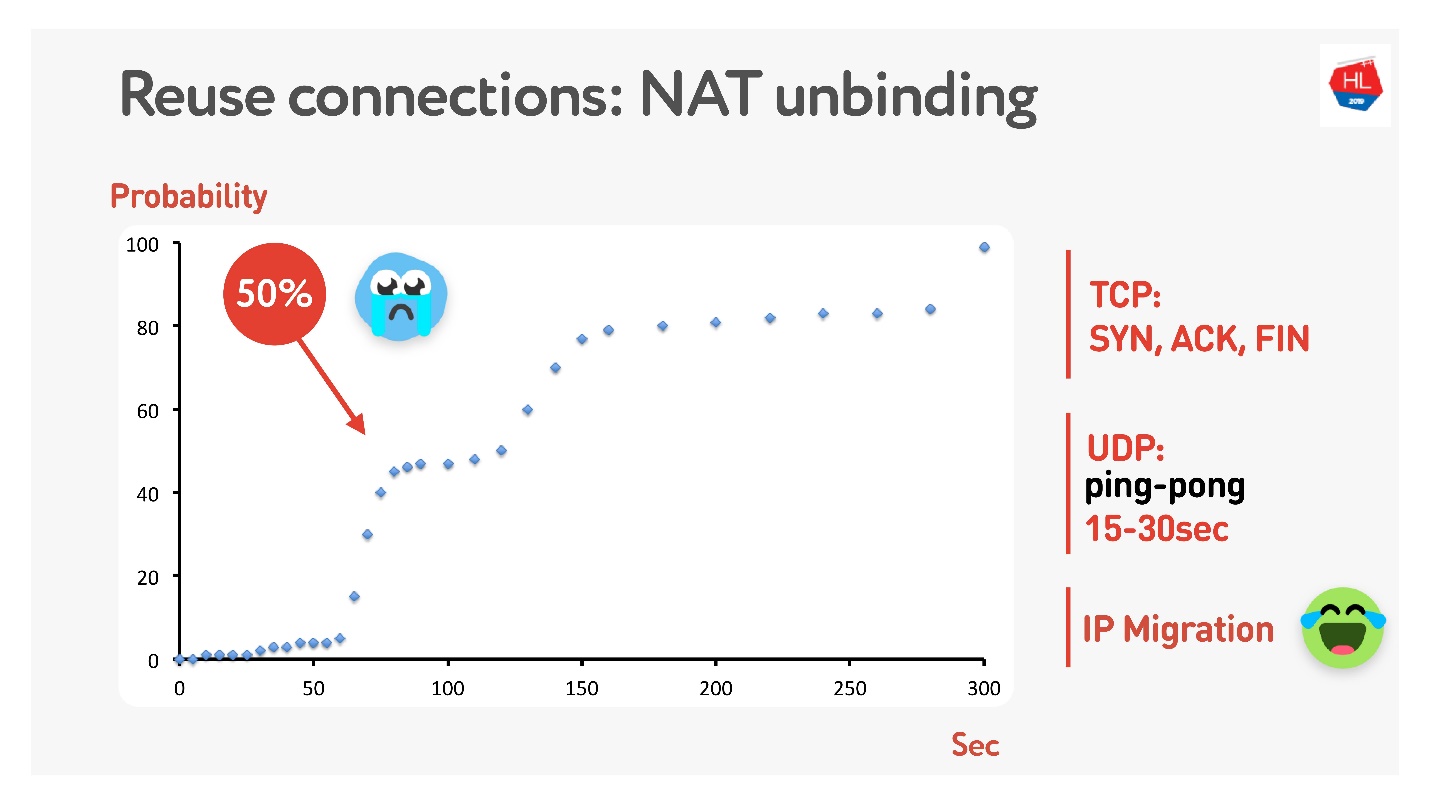
Provavelmente, muitas pessoas lembram (se não, então veja
aqui ) que nem todo mundo tem endereços públicos, mas existe o NAT, que normalmente armazena o mapeamento por algum tempo no roteador doméstico. Para o TCP, é claro quanto armazenar, mas para o UDP, não é claro. O NAT opera com um tempo limite; se você medir cuidadosamente esse tempo limite, obtemos que em cerca de 15 a 30 segundos mais de 50% das conexões começarão a falhar.
Tudo bem - faremos um pacote de pingue-pongue por 15 s. Nos casos em que a conexão ainda está interrompida, há a Migração de IP, que permite alterar de forma barata a porta no roteador.
Ritmo de pacote
Isso é muito importante se você estiver executando seu protocolo UDP.

Se for muito simples, quanto mais você enviar pacotes continuamente para a rede, maior a probabilidade de perda de pacotes. Se você filtrar pacotes, a perda de pacotes será menor.
Existem muitas teorias diferentes sobre como isso funciona, mas eu gosto dessa.
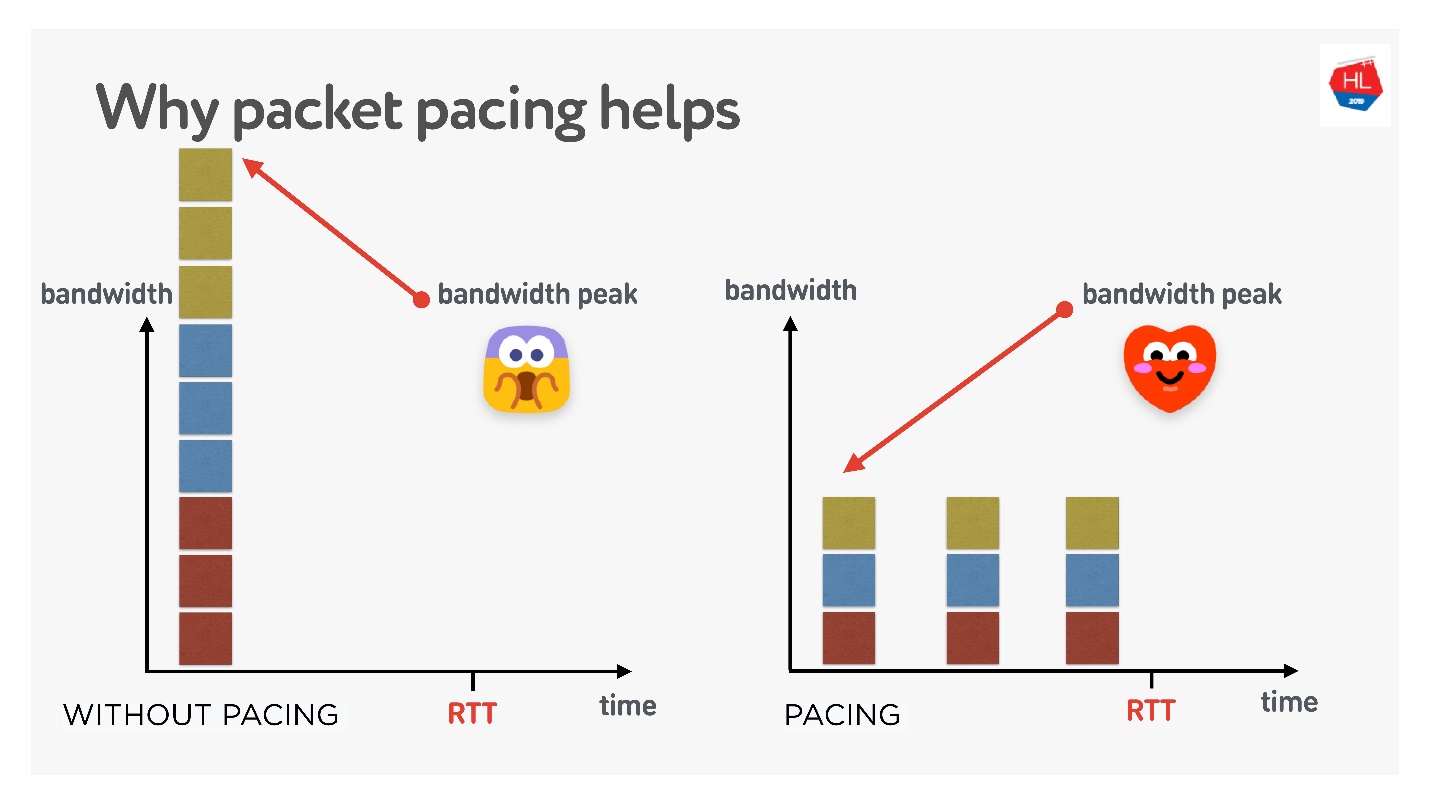
Existem 3 conexões criadas ao mesmo tempo. Você tem a chamada janela inicial - 10 pacotes criados ao mesmo tempo. Obviamente, a largura de banda pode não ser suficiente neste momento. Mas se você distribuí-los cuidadosamente, separe-os, tudo ficará bem, como na figura certa.
Portanto, se você definir uma taxa uniforme para o envio de pacotes, diminua-os, então a probabilidade de haver um estouro de buffer único será menor. Isso não está provado, mas teoricamente acontece assim.

Quando você precisar cortar pacotes (faça o ritmo):
- Quando você cria uma janela.
- Quando você amplia a janela, por exemplo, é recomendável adicionar quantos pacotes podem ser enviados para o RTT / 2. Isso não prejudicará o tempo de entrega, mas reduzirá a perda de pacotes.
- No caso de perda de congestionamento, para reduzir a janela, você precisa manchar os pacotes ainda mais. 4/5 RTT é uma figura empiricamente selecionada.
MTU
Ao escrever seu protocolo UDP, lembre-se do MTU. MTU é o tamanho dos dados que você pode encaminhar.
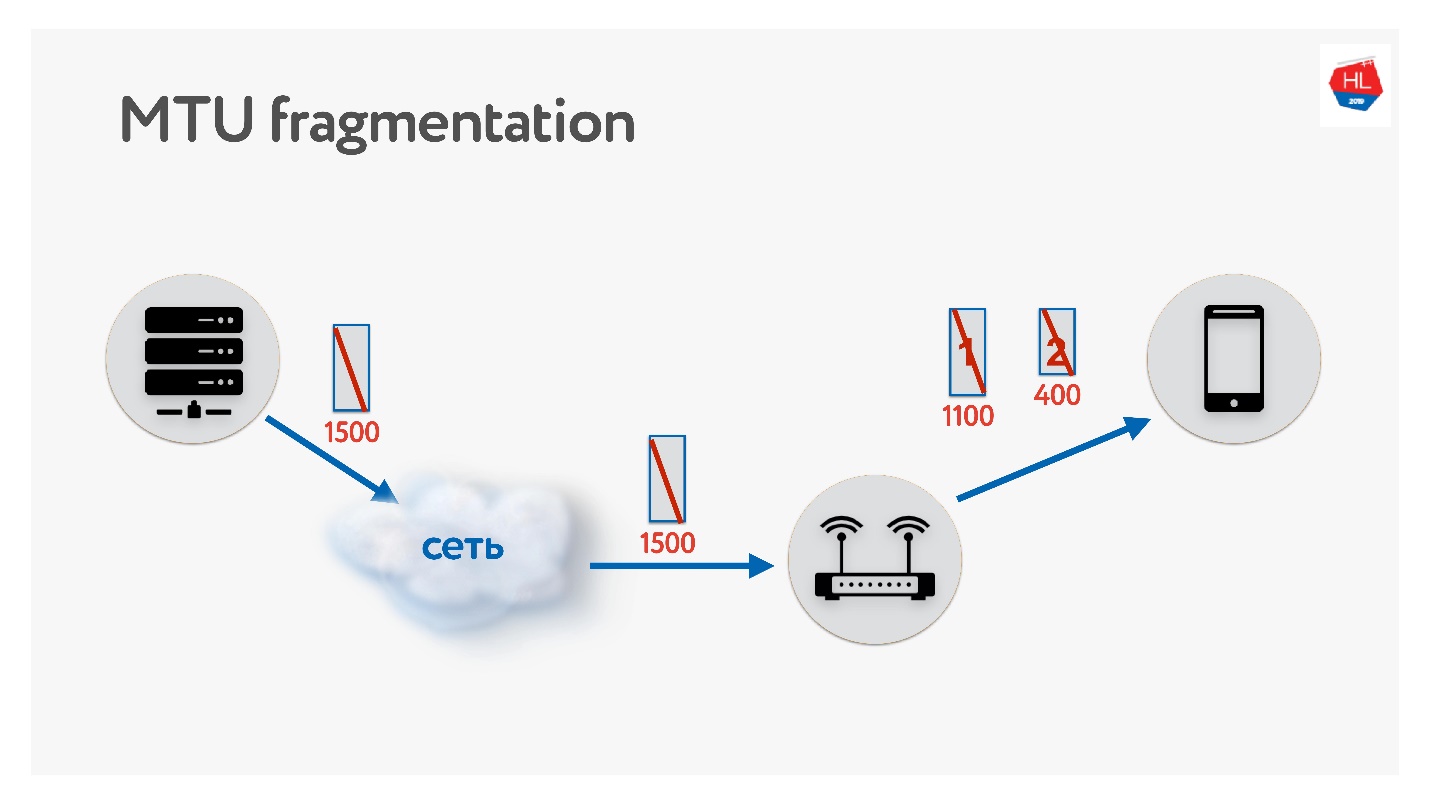
Enviamos pacotes do servidor para o cliente, por exemplo, com um tamanho de 1500. Se houver um roteador no caminho que não suporte esse tamanho de MTU, ele será fragmentado. O único problema de fragmentação é que, se um pacote for perdido, ambos serão perdidos e tudo isso precisará ser retransmitido. Portanto, o TCP possui um algoritmo para determinar o MTU - PMTU.

Cada roteador examina o MTU de sua interface, envia para um cliente, o outro envia para seu cliente, todos sabem quantos MTU eles têm no cliente. Em seguida, a fragmentação é proibida pelo sinalizador e os pacotes de tamanho MTU são enviados. Se neste momento alguém dentro da rede perceber que ele tem menos MTU, então via ICMP ele dirá: "Desculpe, o pacote foi perdido porque é necessária fragmentação" e indica o tamanho da MTU. Alteraremos esse tamanho e continuaremos enviando. Na pior das hipóteses, nossa pequena sobrecarga é RTT / 2. Isso está no TCP.
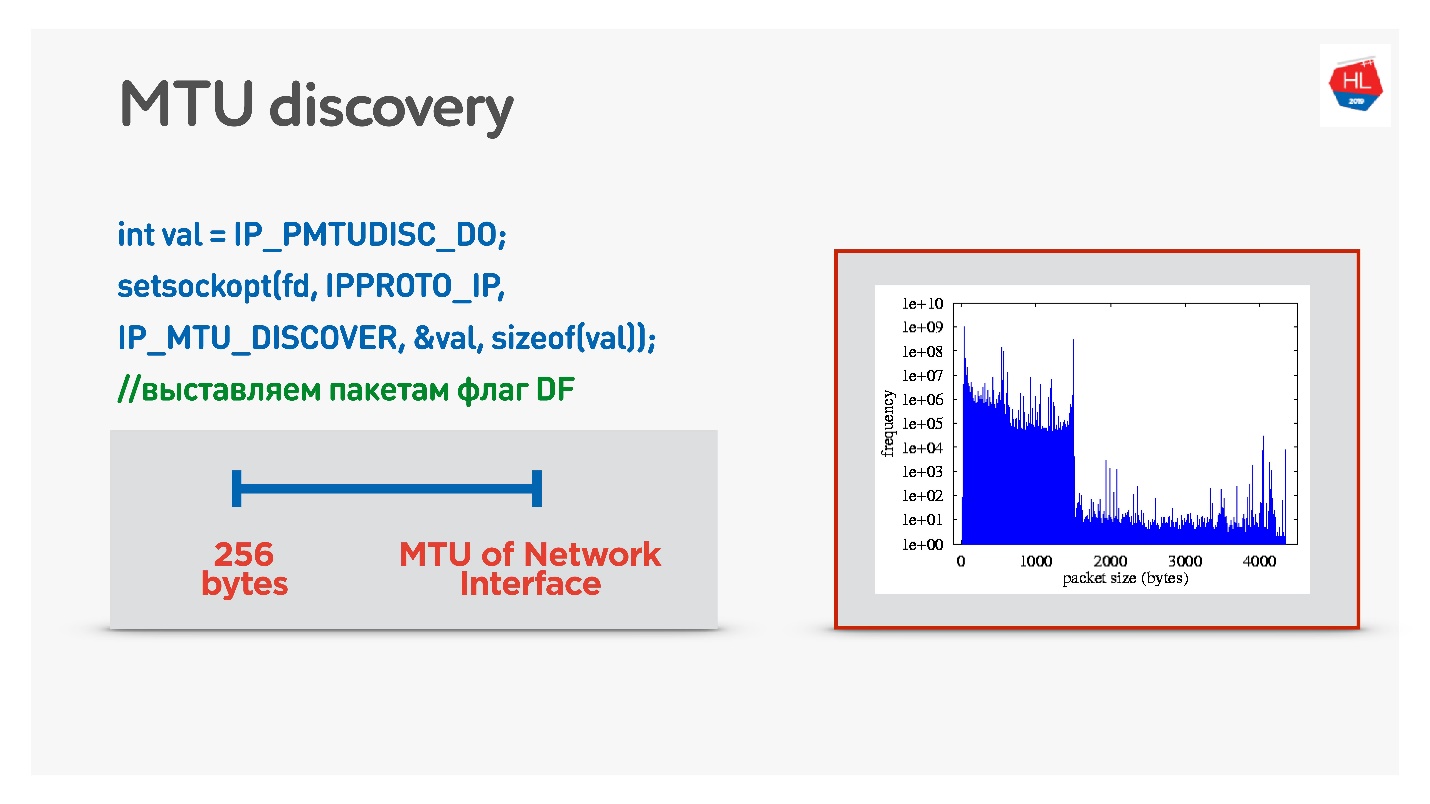
Se no UDP você não quiser se preocupar com o ICMP, faça o seguinte: permita a fragmentação ao enviar dados normais. Ou seja, para enviar pacotes fragmentados - deixe-os funcionar. E, paralelamente, para iniciar um processo que proíbe a fragmentação, uma pesquisa binária selecionará o MTU ideal, para o qual iremos então. Isso não é totalmente eficaz, porque a princípio o MTU parece aquecer.
Uma opção mais complicada é observar a distribuição do MTU entre clientes móveis.

De todos os clientes, enviamos pacotes de vários tamanhos com a proibição de fragmentação. Ou seja, se o pacote não atingir, ele cairá e o menor MTU deverá atingir 100%. Mas há uma pequena perda de pacotes, então existem dois slides no gráfico:
- 1350 bytes - em vez de 98%, obtemos 95% de entrega imediatamente.
- 1500 bytes - MTU, após o qual já 80% dos clientes não receberão esses pacotes.
De fato, podemos dizer o seguinte: negligenciamos 1-2% de nossos clientes, deixamos que eles vivam em pacotes fragmentados. Mas começaremos imediatamente do que precisamos - é de 1350.
Correção de erros (SACK, NACK, FEC)
Se você estiver criando seu protocolo, precisará corrigir os erros. Se o pacote estiver ausente (isso é normal para redes sem fio), ele precisará ser restaurado.
No caso mais simples (mais detalhes
aqui ), há um relé através do Retransmit Time Out (RTO). Se o pacote estiver faltando, aguarde o tempo de retransmissão e envie-o novamente.
O próximo algoritmo é a
retransmissão rápida . Todos esses são algoritmos TCP, mas podem ser facilmente portados para o UDP.
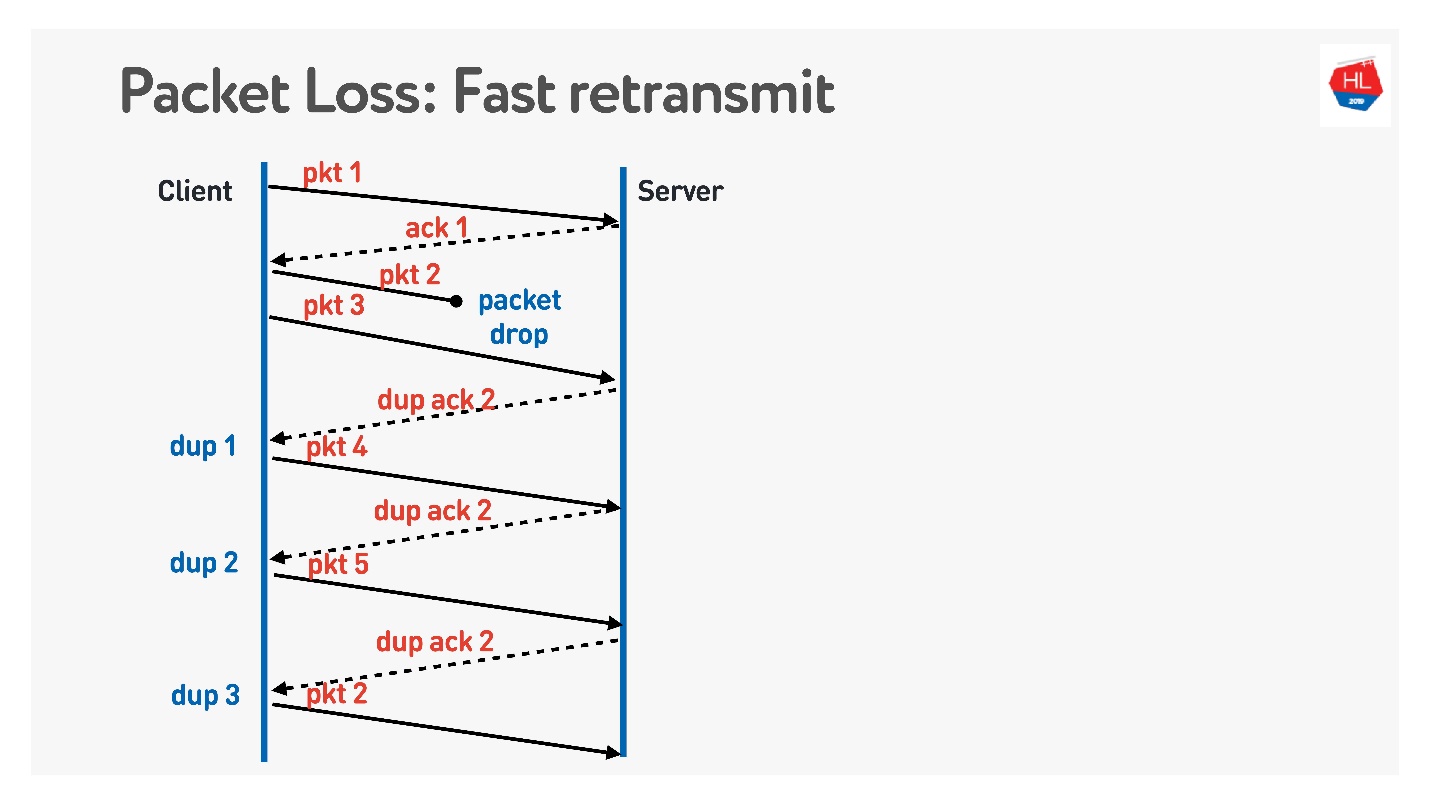
Quando o pacote acabar, continuamos a enviar - há uma transmissão de outros pacotes. No momento, o servidor diz que recebeu o próximo pacote, mas não havia um pacote anterior. Para fazer isso, ele faz um reconhecimento complicado, que é igual ao número do pacote + 1, e define o sinalizador de confirmação duplicado. Ele envia esses dups assim, e no terceiro geralmente entendemos que o pacote desapareceu e o envia novamente.
O que mais você deseja fazer com classe, o que não está no TCP e o que eles sugerem fazer no UDP é a
Correção de erro de encaminhamento .

Parece que se sabemos que os pacotes podem ser perdidos, podemos pegar um conjunto de pacotes, adicionar um pacote XOR e corrigir o problema sem retransmissões adicionais imediatamente no cliente ao receber dados. Mas há um problema se vários pacotes desaparecerem. Parece que pode ser resolvido através da proteção de paridade, Reed-Solomon, etc.
Tentamos dessa maneira, e de fato os pacotes desaparecem em pacotes.
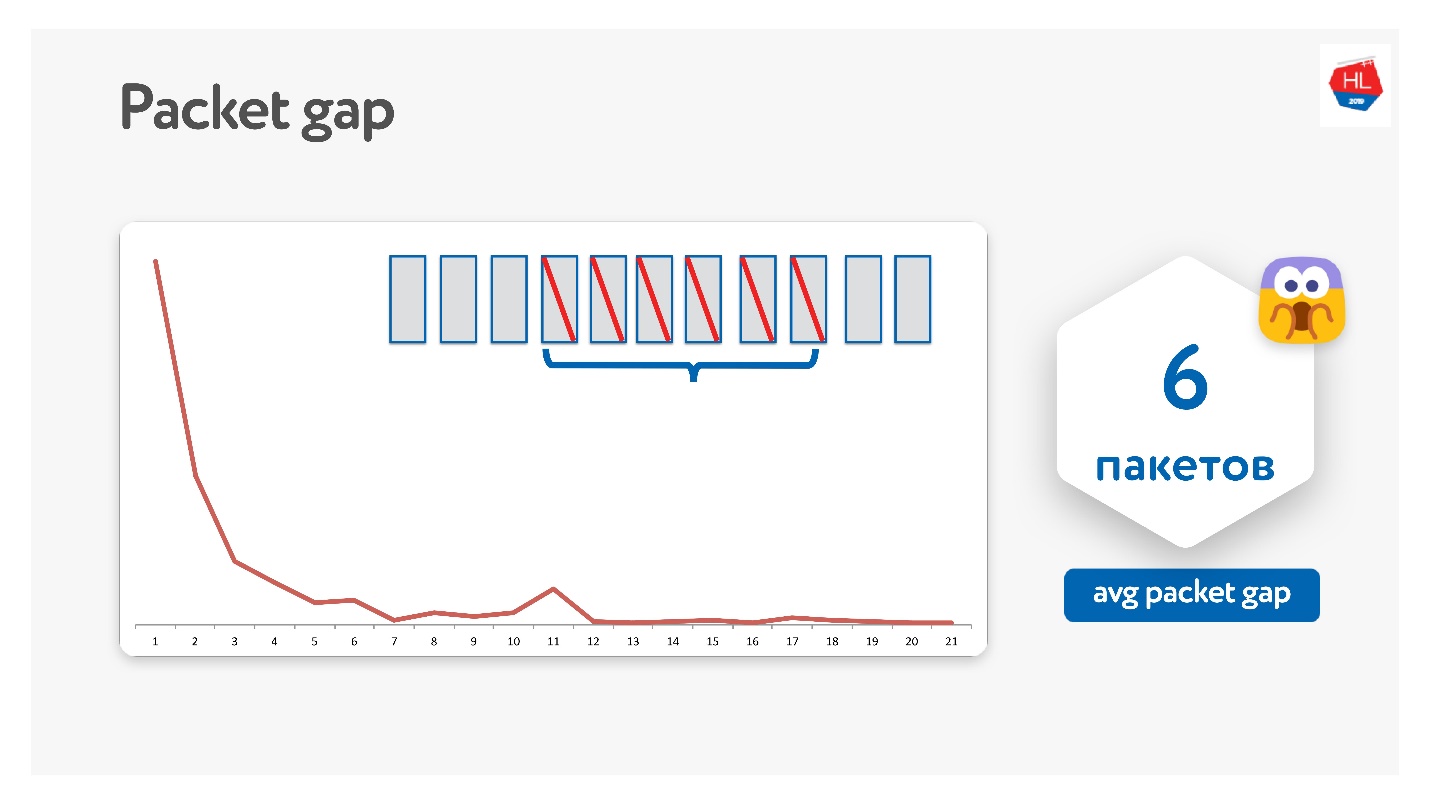
O intervalo médio de pacotes acabou por ser 6. Este é um intervalo muito inconveniente de pacotes - você precisa de muitos códigos de correção de erros. Ao mesmo tempo, há algum tipo de pico em 11 - não sei por que, mas às vezes os pacotes desaparecem em pacotes de 11. Devido a essa lacuna de pacote, isso não funciona.
O Google também tentou isso, todo mundo sonha com o FEC, mas até agora ninguém trabalhou.
Há outra opção quando o FEC pode ajudar.

Além de retransmitir por Retransmit Time Out, Fast Retransmit, também há uma
sonda de perda de cauda . Isso acontece quando você envia dados e a cauda desaparece. Ou seja, você enviou parte dos dados, enviou o quinto pacote - ele chegou. Os pacotes começaram a desaparecer, por exemplo, porque a rede falhou. Pacotes desaparecem, desaparecem e você recebeu uma confirmação apenas para o quinto pacote.
Para entender se esses dados chegaram, depois de um tempo você começa a executar o TLP (probe de perda da cauda), pergunte se o final foi recebido. O fato é que a transferência de dados terminou e você não está enviando nada; a Retransmissão Rápida não funcionará. Para corrigir isso, faça um TLP.
Você pode adicionar o FEC aos TLPs. Você pode olhar para todos os pacotes que não chegaram, contar com paridade e enviar TLPs com algum pacote de paridade.
Tudo isso é legal, parece funcionar. Mas existe um problema.
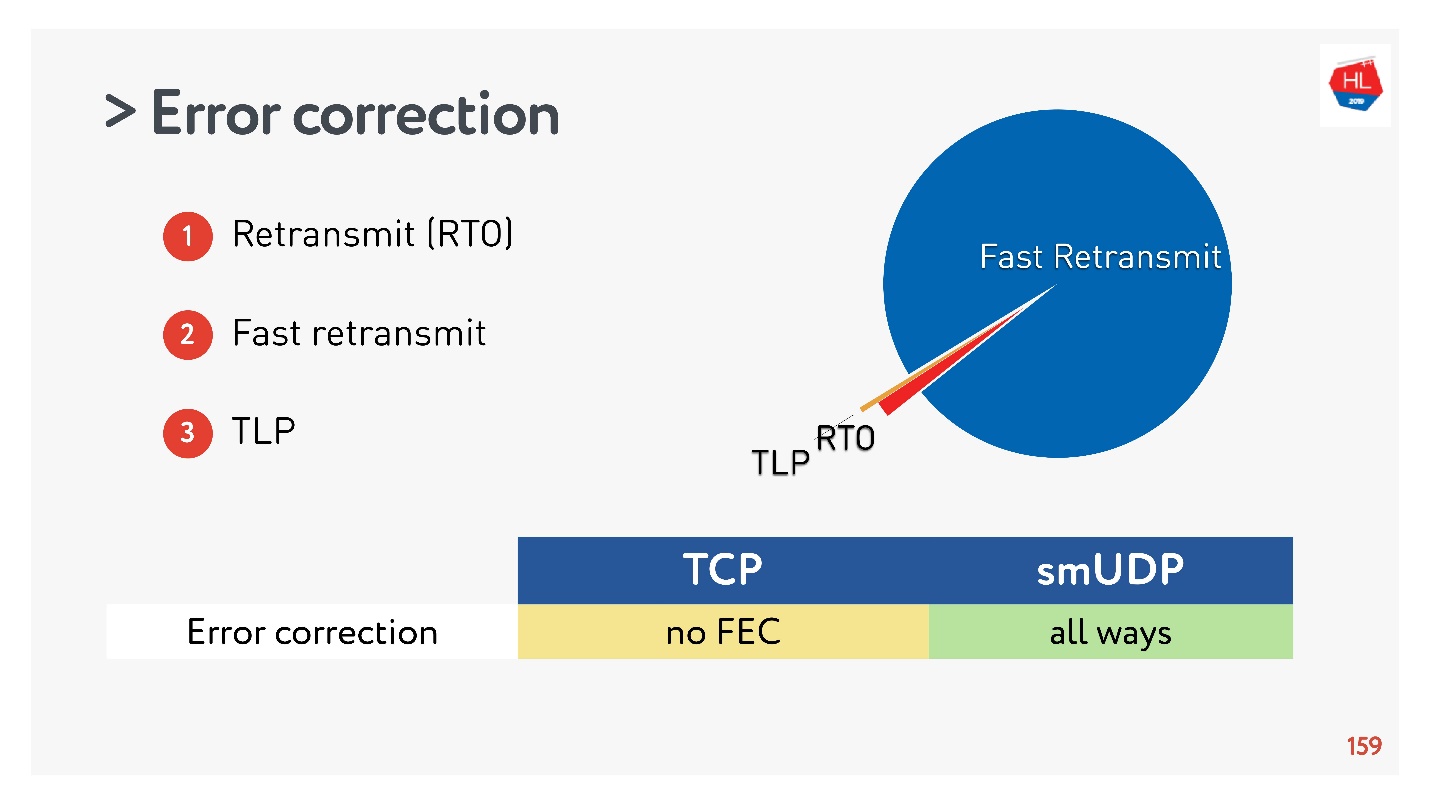
Coletamos estatísticas e verificamos que 98% dos erros são reparados através da Retransmissão Rápida. O restante é reparado via Retransmit Time Out e menos de 1% através do TLP. Se você consertar outra coisa, o FEC será menor que 0,5%.
O TCP não suporta FEC. No UDP, não é difícil fazer isso, mas no caso geral, os algoritmos de recuperação TCP padrão são suficientes.
Desempenho
Seria possível não prejudicar o desempenho comparando o TCP com o UDP.
O TCP é um protocolo muito antigo com várias otimizações diferentes, por exemplo, LSO (descarga de grandes segmentos) e zerocópia. Agora, para o UDP, tudo está indisponível. Portanto, o desempenho do UDP é de apenas 20% em relação ao TCP dos mesmos servidores. Mas já existem soluções prontas (
UDP GSO ,
zerocopy ) que permitem ao Linux suportar isso.
O principal problema de suporte à otimização para zerocópia e LSO é que a estimulação é perdida.

Tempo para o mercado ou o que matou o TCP
Recentemente, quando as redes sem fio móveis se tornaram populares, surgiram muitos padrões TCP diferentes: TLP, TFO, novo controle de congestionamento, RACK, BBR e muito mais.

Mas o principal problema é que muitos deles não estão sendo implementados, porque se diz que o TCP é ossificado. Em muitos casos, os operadores examinam os pacotes TCP e esperam ver o que esperam. Portanto, é muito difícil mudar.
Além disso, os clientes móveis são atualizados por um longo tempo e não podemos fornecer essas atualizações. Se você observar quais as atualizações recentes mais recentes estão disponíveis no cliente e o que está no servidor, pode dizer que não há quase nada no cliente.
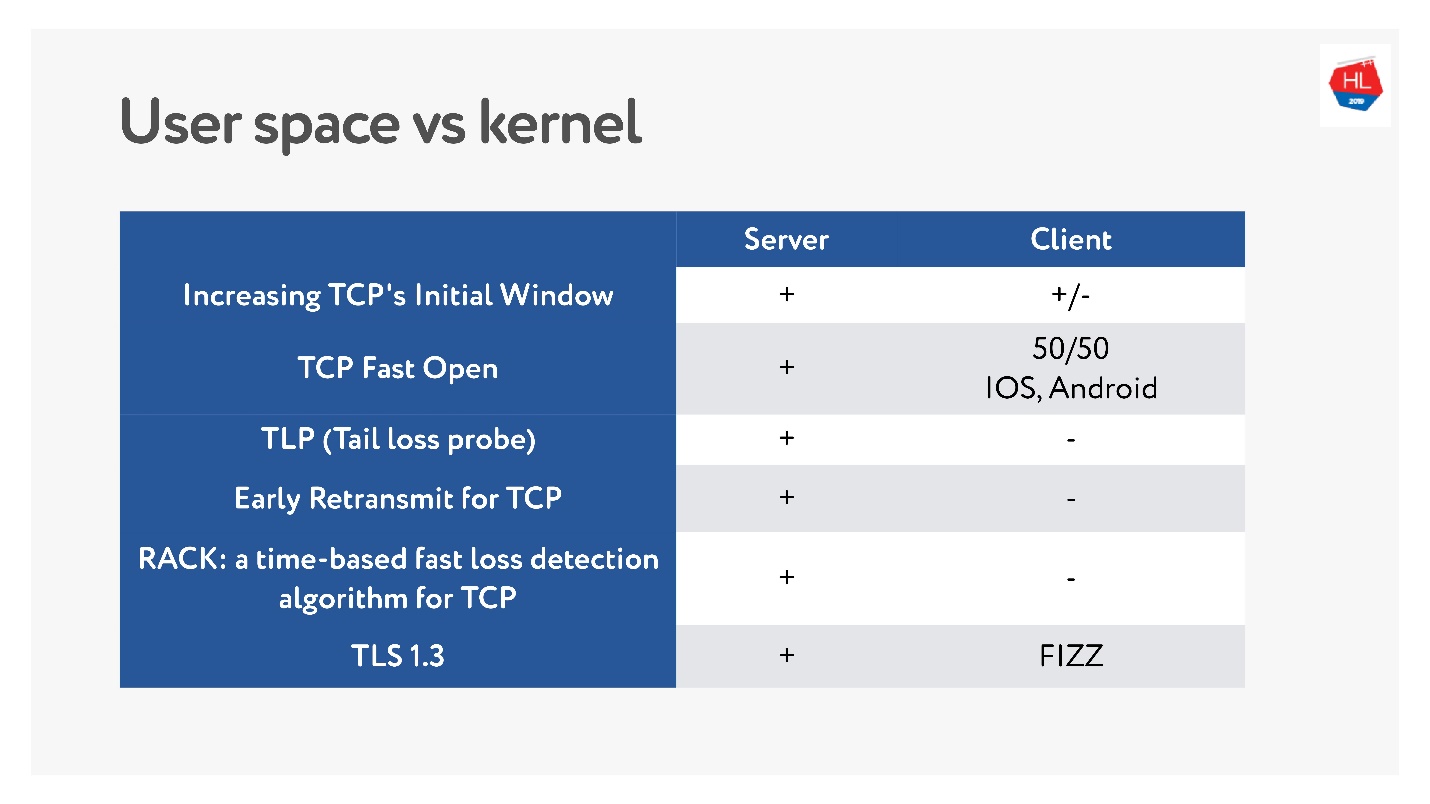
Portanto, a decisão de escrever um protocolo no espaço do usuário, pelo menos desde que você acumule todos esses recursos, não parece tão ruim.

Com o TCP, os recursos vêm rolando há anos. Para o seu protocolo UDP, você pode atualizar a versão literalmente em uma atualização do cliente e do servidor. Mas você precisará adicionar a negociação de versão.
TCP vs UDP self-made. Luta final
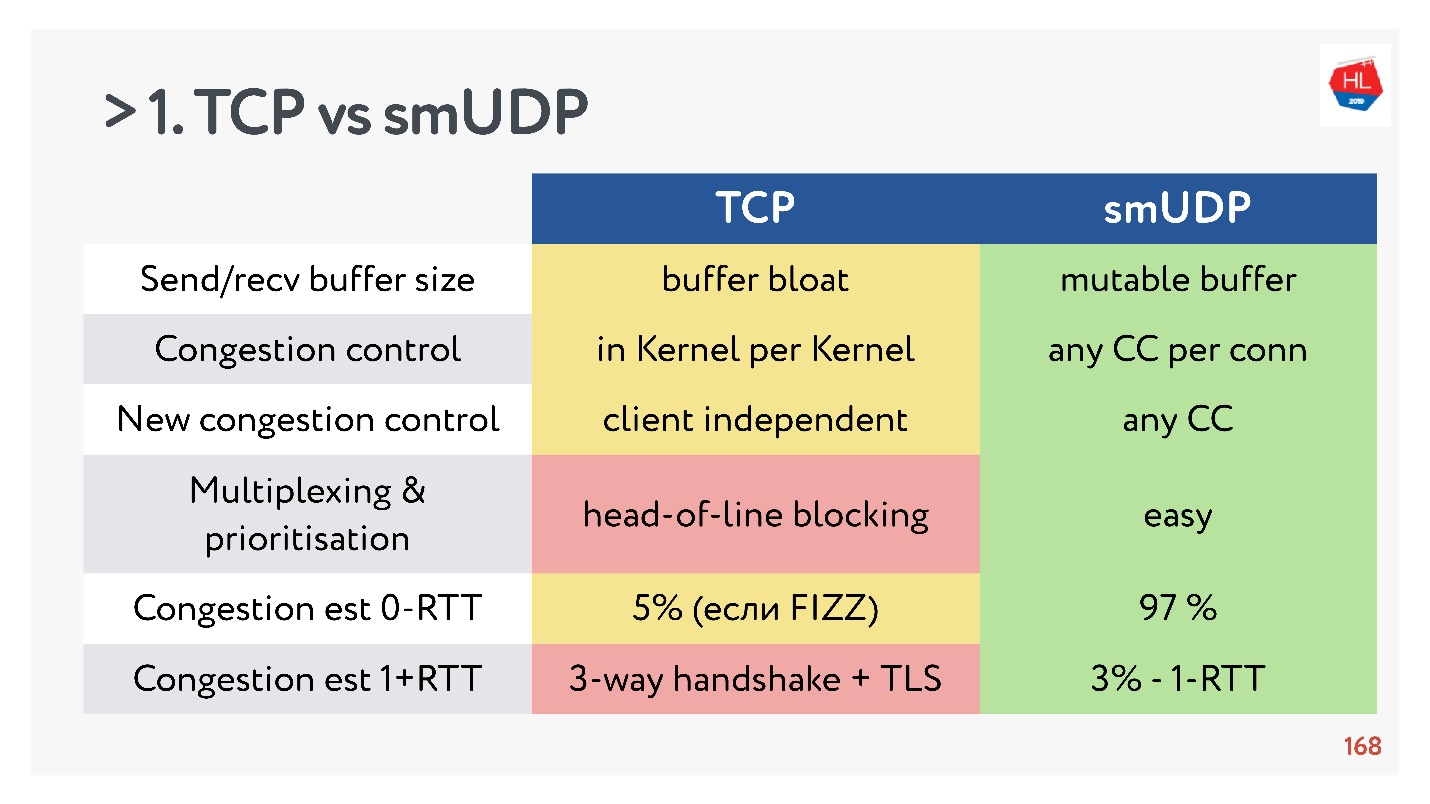
- Enviar / recuperar buffer: buffer mutável pode ser feito para o seu protocolo, haverá problemas com o inchaço do buffer com o TCP.
- Controle de congestionamento que você pode usar existente. Na UDP eles são.
- É difícil adicionar o novo controle de congestionamento ao TCP, porque você precisa modificar a confirmação, não é possível fazer isso no cliente.
- A multiplexação é uma questão crítica. O bloqueio do cabeçalho da linha acontece; quando você perde um pacote, não pode multiplexar para o TCP. Portanto, o HTTP2.0 sobre TCP não deve dar um aumento sério.
- Os casos em que você pode obter uma configuração de conexão para 0-RTT no TCP são extremamente raros, cerca de 5% e cerca de 97% para UDP auto-criado.

- A migração de IP não é um recurso tão importante, mas, no caso de assinaturas complexas e estado de armazenamento no servidor, é definitivamente necessário, mas não é implementado no TCP de forma alguma.
- Nat unbinding não é a favor do UDP. Nesse caso, o UDP geralmente precisa executar pacotes de ping-pong.
- O ritmo de pacotes no UDP é simples, embora não haja otimização, no TCP essa opção não funciona.
- MTU e correção de erros são comparáveis.
- A velocidade do TCP, é claro, é mais rápida que o UDP agora, se você estiver distribuindo uma tonelada de tráfego. Mas algumas otimizações levam muito tempo para serem entregues.
Se você coletar tudo o mais importante, o UDP, mais provavelmente, terá mais prós do que contras.
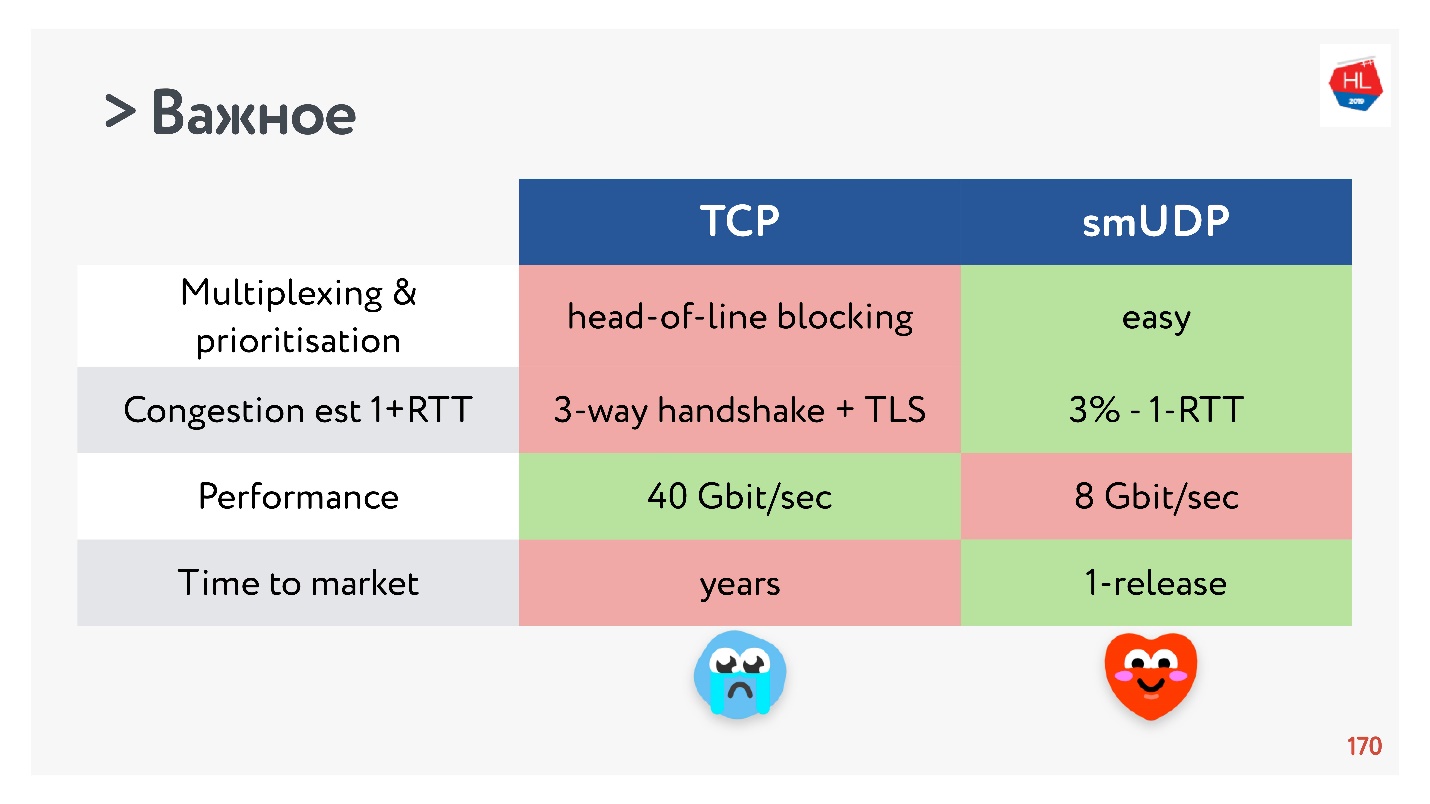 Escolha UDP!
Escolha UDP!Testando UDP auto-criado em usuários
Reunimos uma bancada de testes.
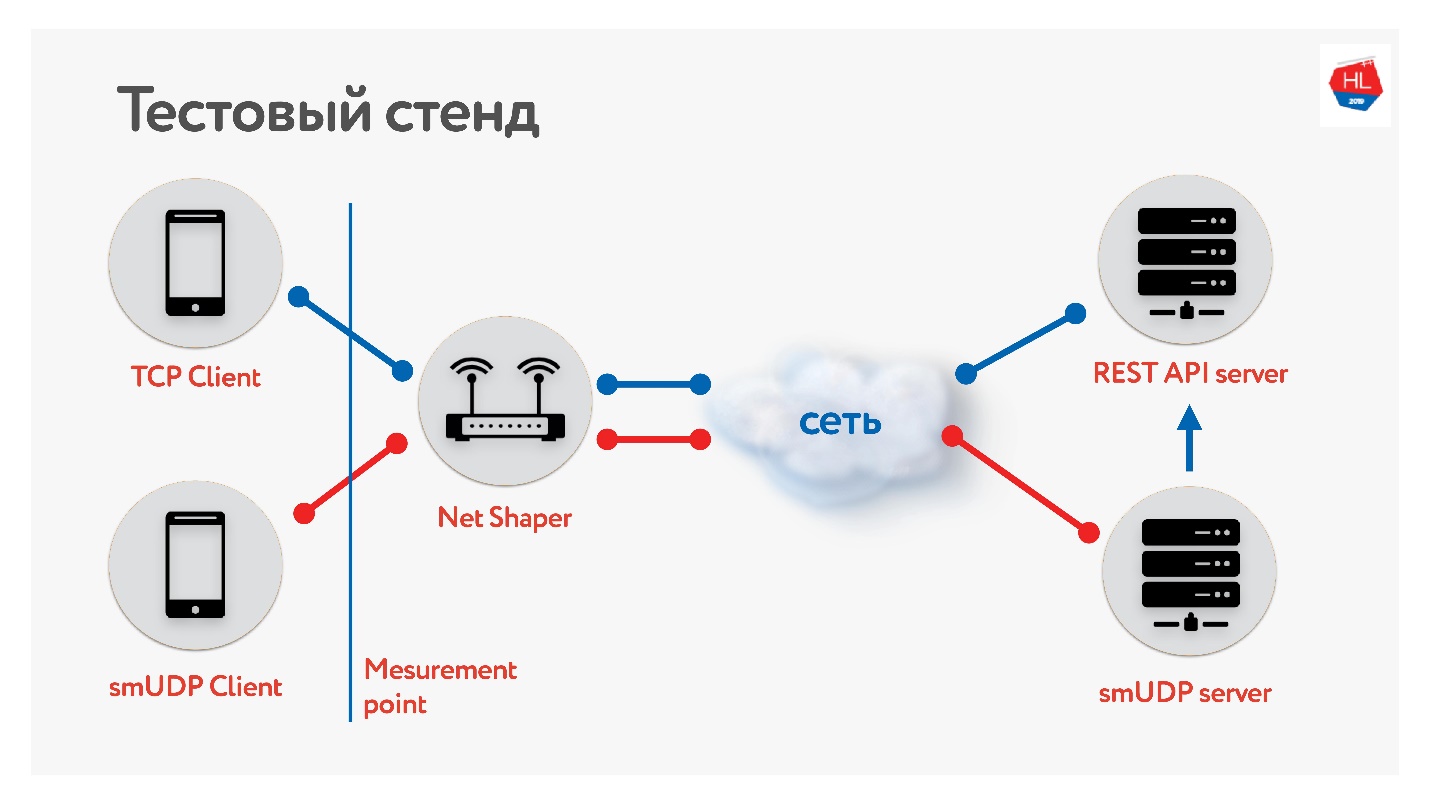
Há um cliente no TCP e UDP. Normalizamos o tráfego por meio do modelador de rede, enviado à Internet e ao servidor. Um serviço de API REST, o segundo com UDP. E o UDP vai para a mesma API REST dentro do mesmo datacenter para verificar os dados. Coletamos diferentes perfis de nossos clientes móveis e
lançamos o teste .

Medindo a média do portal, vimos que conseguimos reduzir o tempo de chamada da API em 10%, as imagens em 7%. A atividade do usuário cresceu apenas 1%, mas não desistimos, achamos que será melhor.

Em termos de cargas, agora temos cerca de 10 milhões de usuários em nosso UDP de fabricação própria, tráfego de até 80 Gb / s, 6 milhões de pacotes por segundo e 20 servidores todos atendem a isso.
Lista de verificação UDP
Se você escrever seu protocolo, precisará de uma lista de verificação:
- Pacing
- Descoberta MTU.
- Correções de bugs necessárias .
- Controle de fluxo e controle de congestionamento.
- Opcionalmente, você pode oferecer suporte à migração de IP, o TLP é fácil.
Lembre-se de que os canais são assimétricos e, enquanto você recebe dados do servidor, seu upload pode ficar ocioso, tente usá-lo.
QUIC
Seria desonesto dizer que o Google não.

Existe um protocolo QUIC que o Google implementou no HTTP 2.0, que suporta quase a mesma coisa.
Por que o QUIC não é tão rápido
Quando o QUIC foi lançado, havia muito ódio pelo fato de o Google dizer que tudo funciona mais rápido e "eu o medi em casa em um computador - funciona mais devagar".

Este
artigo tem várias fotos e medidas.
Bem, acontece que fizemos tudo isso em vão, as pessoas mediram por nós? Existem medições domésticas reais, mesmo com exemplos de código.

De fato, não haverá melhorias até que você paralelize solicitações, trabalhe em redes reais e até que as perdas de pacotes sejam divididas em perda de congestionamento e perda aleatória. Precisamos de uma emulação real de uma rede real.
Mas há um ponto positivo, dizem eles, QUIC não é nem melhor nem pior. Assim, em redes perfeitas, o QUIC funciona bem.
O futuro
O Google recentemente nomeou HTTP 2.0 sobre o QUIC HTTP 3, para não confundir, porque o HTTP 2.0 pode estar sobre o TCP e sobre o QUIC. Agora é HTTP 3.
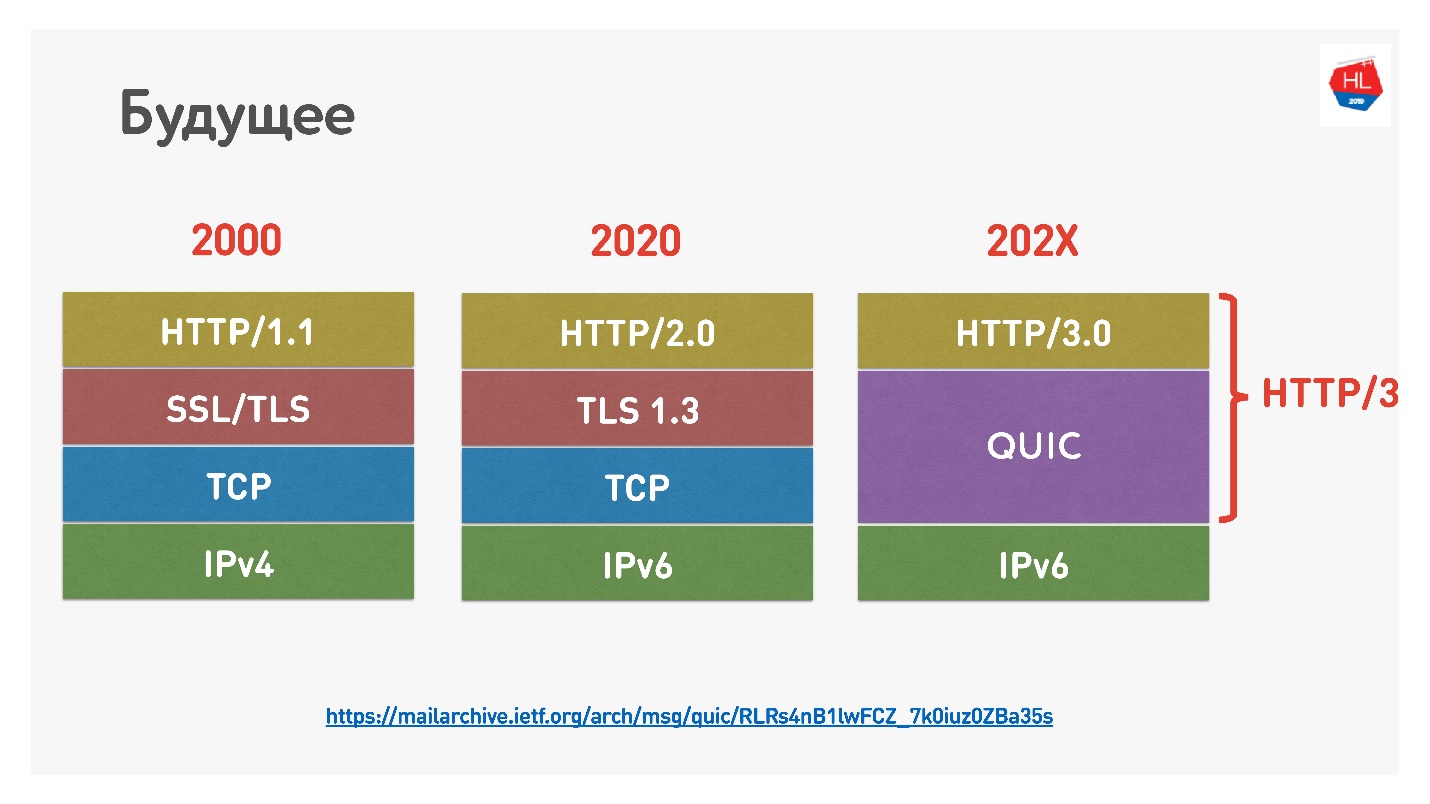
Havia também o
Google QUIC - este é o QUIC, implementado no Chrome, e o iQUIC - um QUIC padronizado. Na verdade, o QUIC padronizado nunca foi implementado em nenhum lugar; os servidores iQUIC padrão não foram cumpridos com o Google QUIC. Agora eles prometem resolver esse problema, e em breve ele estará disponível.
QUIC está em toda parte
Se você ainda não acredita que o TCP está morto, digo-lhe que quando você usa o Chrome, Android e em breve o iOS, e
acessa o google, youtube e assim por diante, usa QUIC e UDP (
prooflink ).
QUIC agora é:
- 1,9% de todos os sites;
- 12% de todo o tráfego;
- 30% do tráfego de vídeo em redes móveis.
Como verificar se você usa o QUIC se não acredita? Abra no Chrome Wireshark. Eu estava procurando pelo iQUIC, não o encontrei em nenhum lugar, mas o GQUIC acontece.
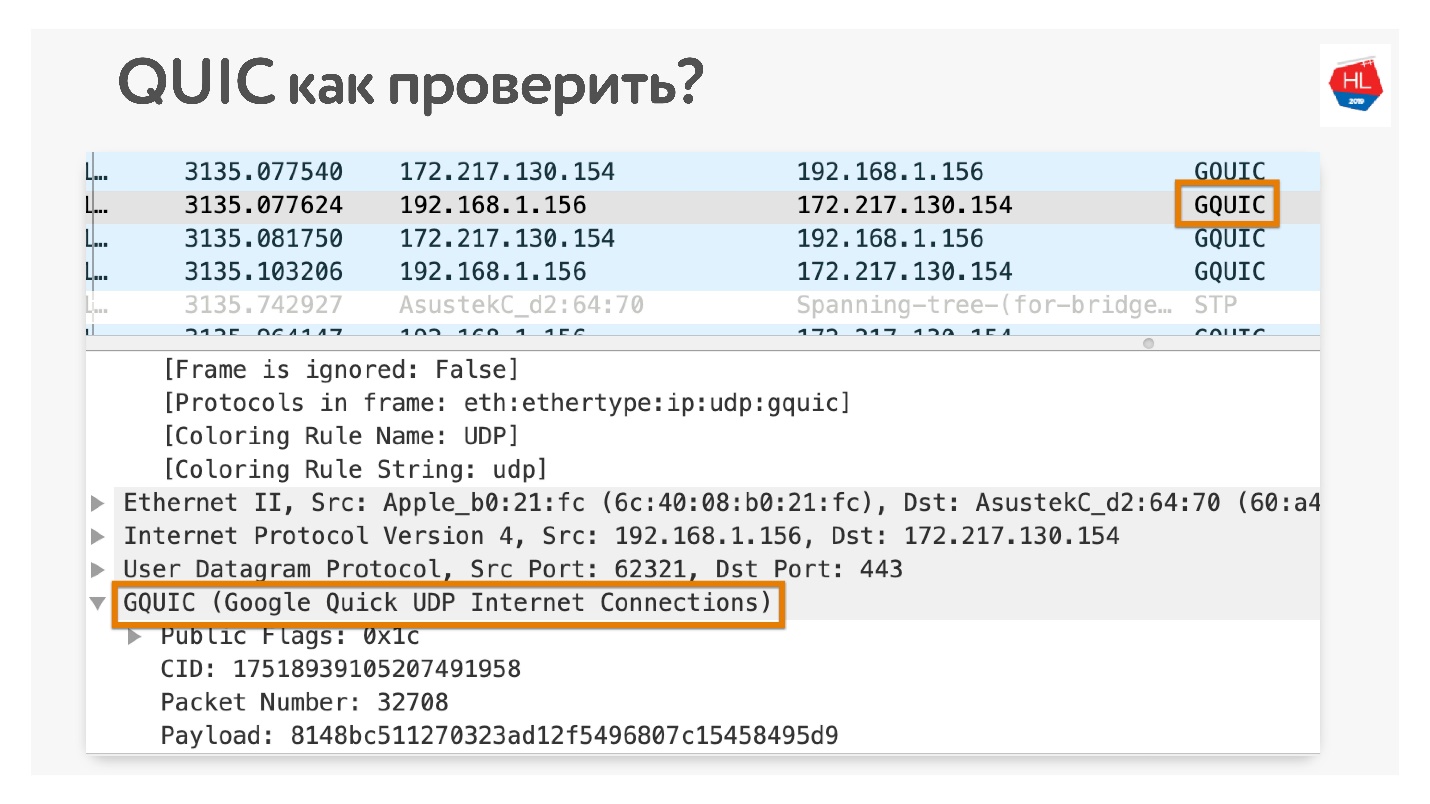
Você também pode ficar online no seu navegador e também ver o que o GQUIC está lá.

Um pouco mais de futuro
Multipath está esperando por nós em breve.
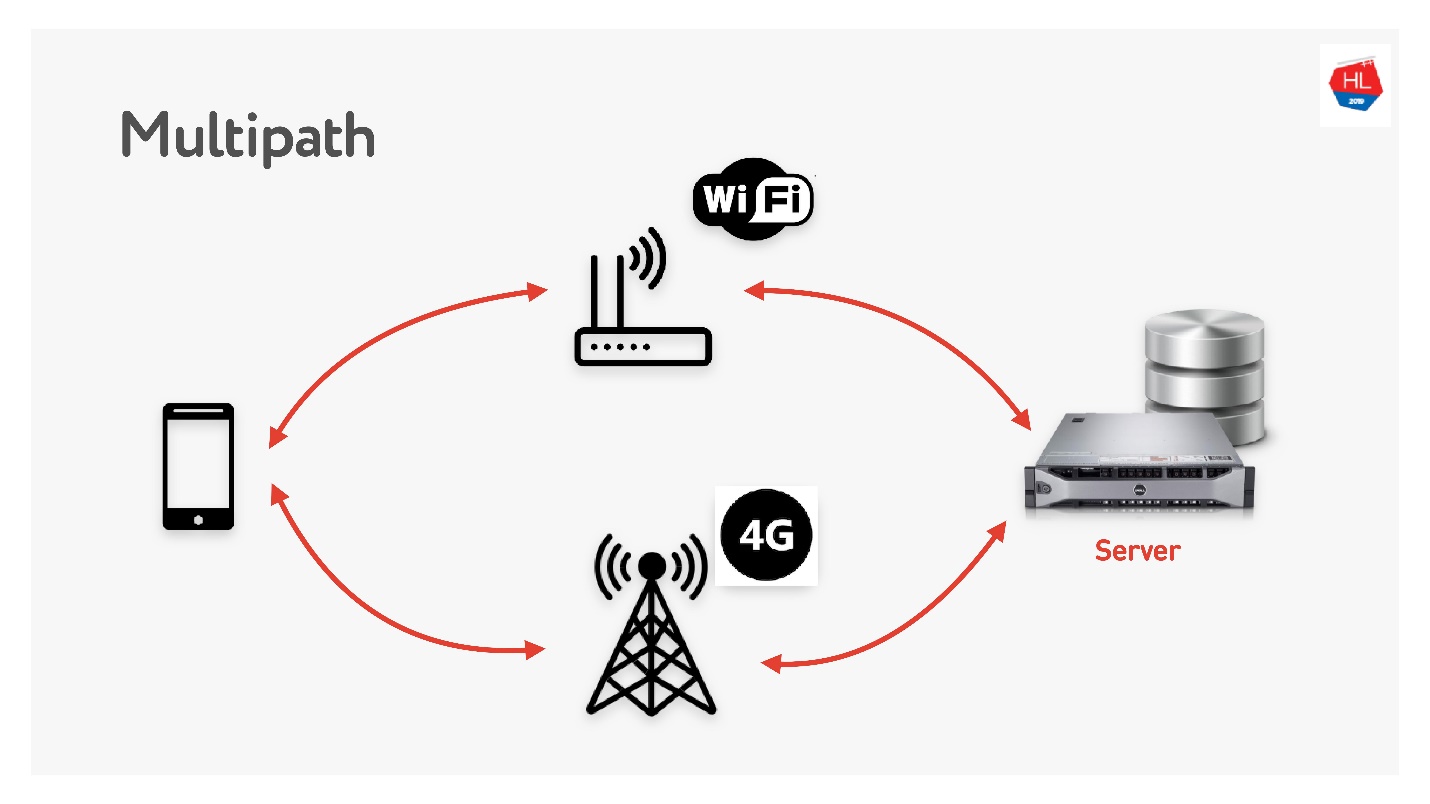
Quando você tem um cliente móvel com Wi-Fi e 3G, pode usar os dois canais. O TCP de caminhos múltiplos está agora em desenvolvimento e estará disponível em breve no kernel do Linux. Obviamente, não chegará a clientes em breve, acho que isso pode ser feito no UDP muito mais rapidamente.
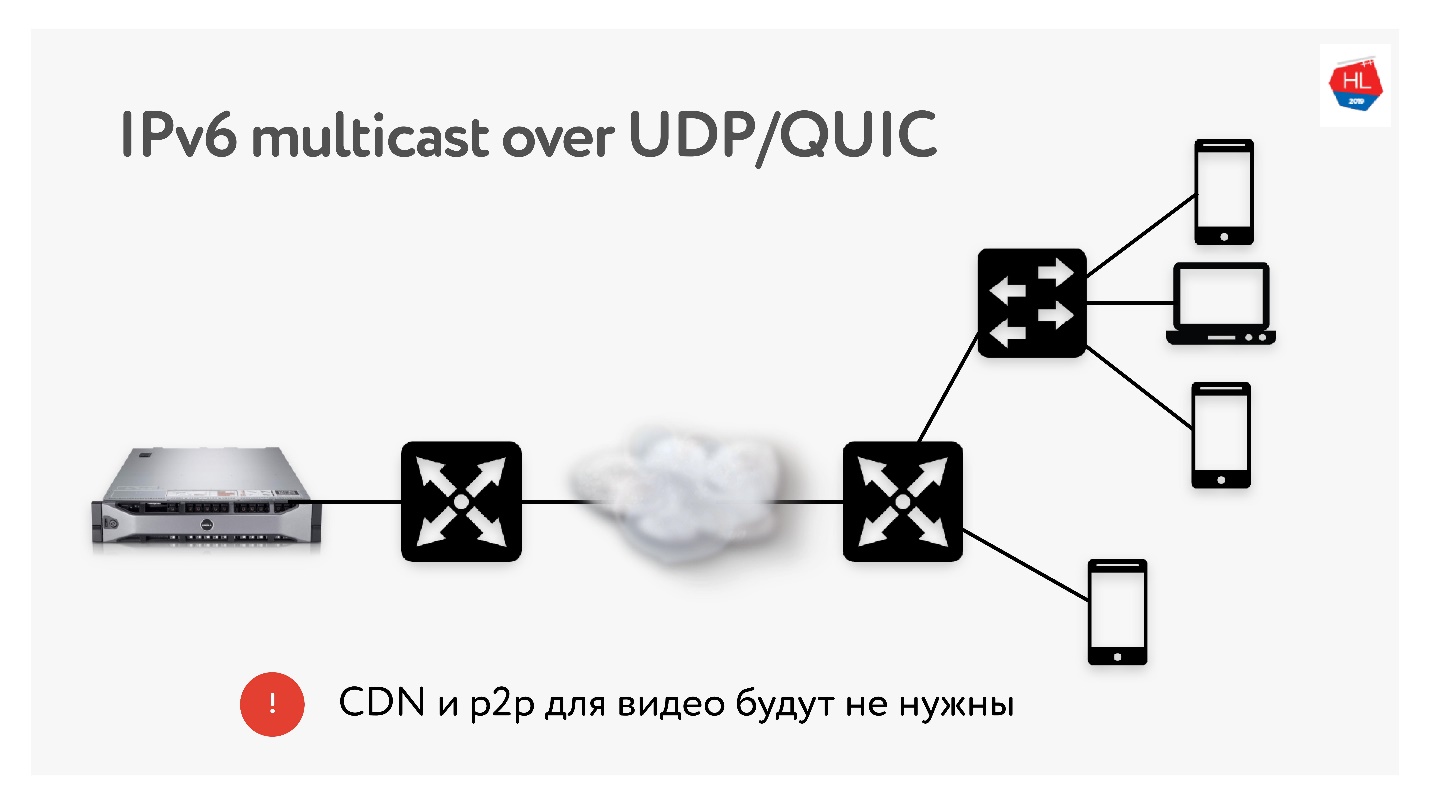
Como realizamos muitas traduções de 3 TB cada uma, frequentemente utilizamos tecnologias como a distribuição CDN e p2p, quando o mesmo conteúdo precisa ser entregue a muitos usuários em todo o mundo.
No IPv6, há multicast com UDP, o que permitirá a entrega de pacotes a vários usuários inscritos ao mesmo tempo. Portanto, acho que as tecnologias CDN e p2p não serão necessárias no futuro próximo se entregarmos todo o conteúdo usando multicast ao IPv6.
Conclusões
Espero que você entenda:
- Como a rede realmente funciona e que o TCP pode ser repetido em UDP e feito melhor.
- Esse TCP não é tão ruim se você o configurar corretamente, mas realmente desistiu e quase não está mais se desenvolvendo.
- Não confie nos odiadores de UDP que dizem que não funcionarão no espaço do usuário. Todos esses problemas podem ser resolvidos. Experimente - este é o futuro próximo.
- Se você não acredita, pode e deve tocar na rede com as mãos. Eu mostrei como quase tudo pode ser verificado.
Você leu tudo e descobriu o que vem depois?
- Configure o protocolo (TCP, UDP - não importa) para a situação (perfil de rede + perfil de carga).
- Use as receitas TCP que eu lhe disse: TFO, send / recv buffer, TLS1.3, CC ...
- Faça seus protocolos UDP se você tiver os recursos.
- Se você fez o seu UDP, verifique na lista de verificação do UDP que você fez tudo o que precisa. Esquecendo qualquer bobagem como ritmo, não vai funcionar.
Se você não tiver os recursos, prepare sua infraestrutura para o QUIC. Mais cedo ou mais tarde ele virá até você.
Estamos determinando o futuro. Decidimos quais protocolos usar. Se você quiser usar o QUIC - use-o, se quiser o seu UDP ou permanecer no TCP - decida você mesmo o futuro.
Links úteis
Até 7 de setembro, você ainda pode enviar uma inscrição para o Moscow HighLoad ++ e compartilhar como você prepara seus serviços para altas cargas. Mas o programa já está sendo gradualmente preenchido, dos relatórios do Odnoklassniki foram recebidos na nova arquitetura do gráfico de amigos, na otimização do serviço de presentes para altas cargas e no que fazer se você otimizou tudo e os dados não chegam ao usuário com rapidez suficiente.