A primeira tarefa mais frequentemente enfrentada pelos desenvolvedores que começam a programar em JavaScript é como registrar eventos no log do console usando o método
console.log . Em busca de informações sobre a depuração do código JavaScript, você encontrará centenas de artigos de blog, além de instruções no StackOverflow, aconselhando a "simplesmente" saída de dados para o console através do método
console.log . Essa é uma prática tão comum que tive que introduzir regras para o controle de qualidade do código, como
no-console , para não deixar entradas de log aleatórias no código de produção. Mas e se você precisar registrar especificamente um evento para fornecer informações adicionais?
Este artigo discute várias situações nas quais você precisa manter logs; Ele mostra a diferença entre os métodos
console.error e
console.error no Node.js e demonstra como passar a função de log para bibliotecas sem sobrecarregar o console do usuário.

Fundamentos teóricos do trabalho com o Node.js
Os métodos
console.error e
console.error podem ser usados no navegador e no Node.js. No entanto, ao usar o Node.js, há uma coisa importante a ser lembrada. Se você criar o seguinte código no Node.js usando um arquivo chamado
index.js ,

e execute-o no terminal usando o
node index.js , os resultados da execução do comando serão localizados um acima do outro:

Apesar de parecerem semelhantes, o sistema as processa de maneira diferente. Se você observar a seção sobre operação do
console na
documentação do
Node.js. , o
console.log imprime o resultado via
stdout e o
console.error imprime através do
stderr .
Cada processo pode trabalhar com três fluxos (
stream ) por padrão:
stdin ,
stdout e
stderr . O fluxo
stdin processa a entrada de um processo, por exemplo, cliques no botão ou saída redirecionada (mais sobre isso abaixo). O fluxo de saída
stdout padrão é para a saída de dados do aplicativo. Finalmente, o fluxo de erros
stderr padrão é projetado para exibir mensagens de erro. Se você precisar descobrir para que
stderr o
stderr e quando usá-lo, leia
este artigo .
Em resumo, ele pode ser usado para usar os operadores de redirecionamento (
> ) e pipeline (
| ) para trabalhar com erros e informações de diagnóstico separadamente dos resultados reais do aplicativo. Se o operador
> permitir que você redirecione a saída do resultado do comando para um arquivo, usando o operador
2> você poderá redirecionar a saída do fluxo de erros
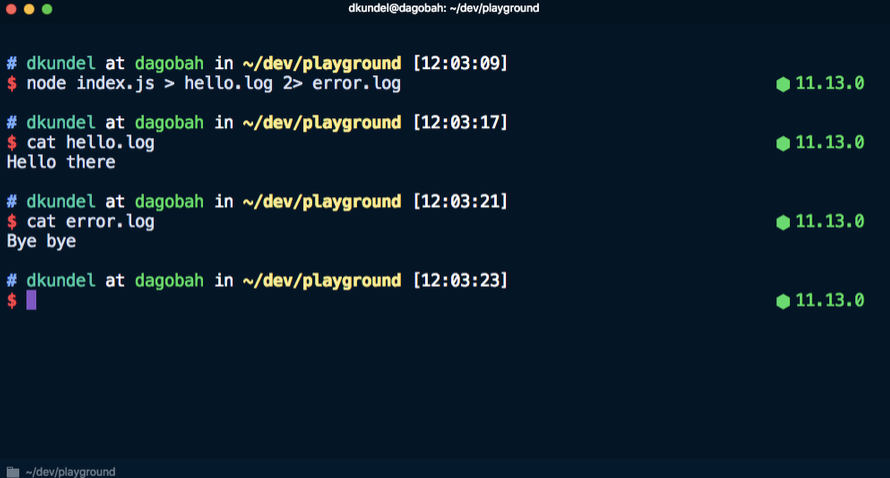
stderr para um arquivo. Por exemplo, este comando envia
Olá para o arquivo
hello.log e
Adeus ao arquivo
error.log .

Quando preciso gravar eventos no log?
Agora que analisamos os aspectos técnicos subjacentes ao registro, vamos para vários cenários em que você precisa registrar eventos. Normalmente, esses cenários se enquadram em uma de várias categorias:
Este artigo descreve apenas os três últimos cenários com base no Node.js.
Log para aplicativos de servidor
Há vários motivos para registrar eventos que ocorrem no servidor. Por exemplo, o registro de solicitações recebidas permite obter estatísticas sobre a frequência com que os usuários encontram erros 404, qual poderia ser o motivo disso ou qual aplicativo cliente do
User-Agent está sendo usado. Você também pode descobrir a hora em que o erro ocorreu e sua causa.
Para experimentar o material fornecido nesta parte do artigo, você precisa criar um novo catálogo para o projeto. No diretório do projeto, crie
index.js para o código a ser usado e execute os seguintes comandos para iniciar o projeto e instalar o
express :

Configuramos um servidor com middleware, que registrará cada solicitação no console usando o método
console.log . Colocamos as seguintes linhas no arquivo
index.js :
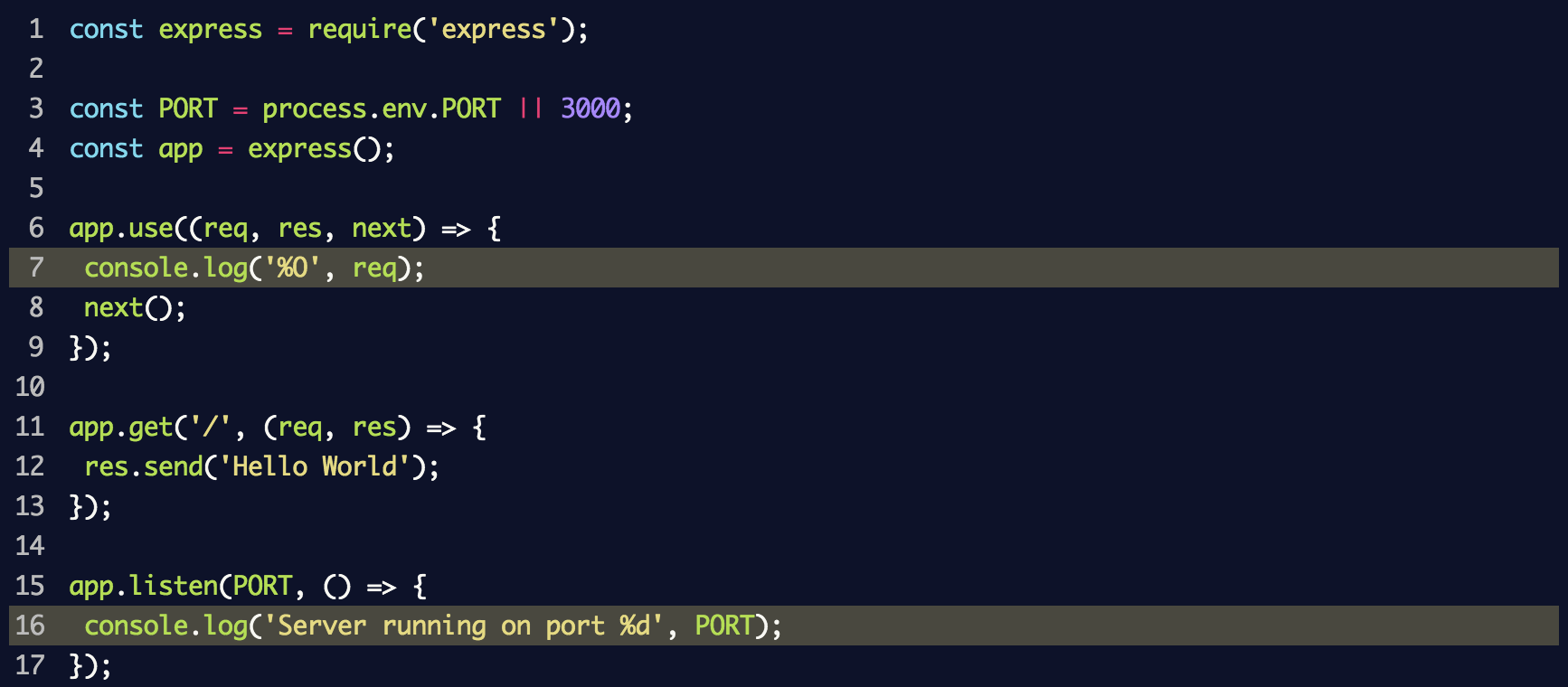
Isso usa
console.log('%O', req) para registrar o objeto inteiro no log. Do ponto de vista da estrutura interna, o método
console.log usa
util.forma t, que, além de
%O suporta outros espaços reservados. Informações sobre eles podem ser encontradas na
documentação do
Node.js.Ao executar o
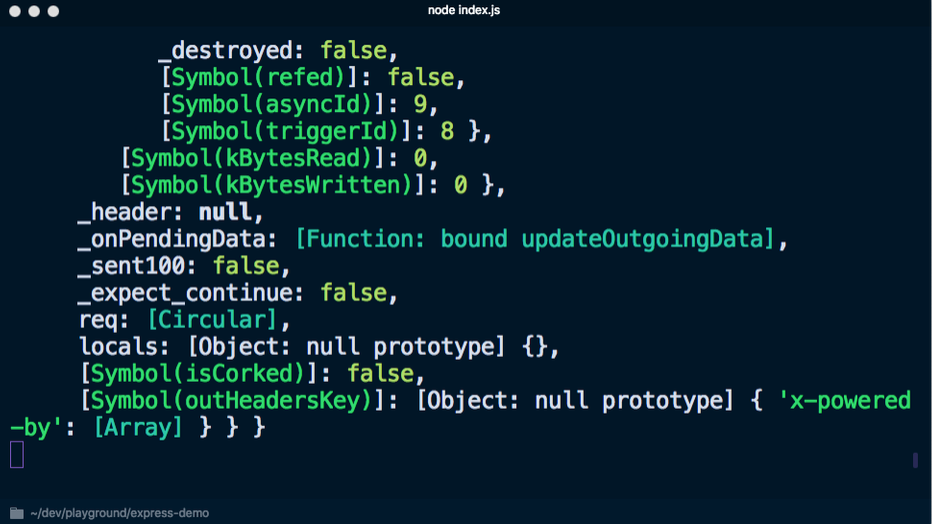
node index.js para iniciar o servidor e alternar para
localhost : 3000, o console exibe muitas informações desnecessárias:
Se, em vez disso, usar
console.log('%s', req) para não exibir o objeto completamente, você não receberá muitas informações:
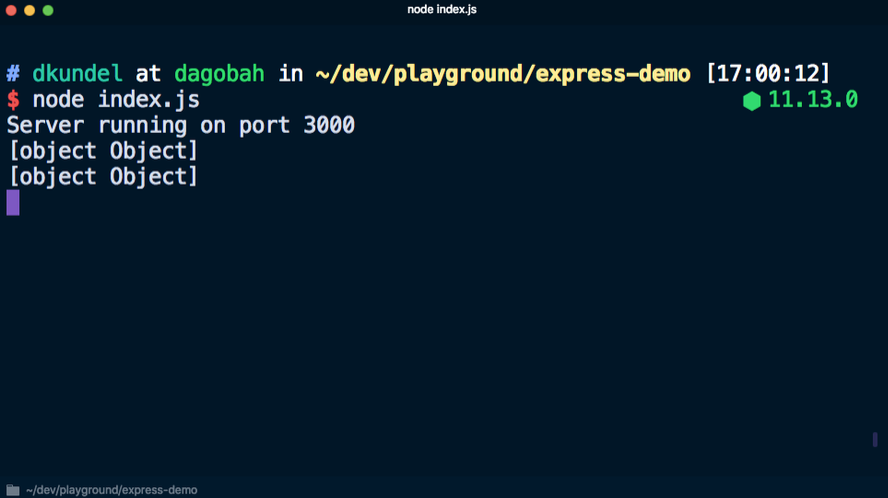
Você pode escrever sua própria função de registro, que produzirá apenas os dados necessários, mas primeiro você precisa decidir quais informações são necessárias. Apesar de o foco estar geralmente no conteúdo da mensagem, na realidade é frequentemente necessário obter informações adicionais, que incluem:
- registro de data e hora - para saber quando os eventos ocorreram;
- nome do computador / servidor - se um sistema distribuído estiver em execução;
- identificador de processo - se vários processos do Nó estiverem sendo executados usando, por exemplo,
pm2 ; - mensagem - uma mensagem real com algum conteúdo;
- rastreamento de pilha - se um erro for registrado;
- variáveis / informações adicionais.
Além disso, dado que, em qualquer caso, tudo é gerado nos fluxos
stdout e
stderr , é necessário manter um diário em níveis diferentes, além de configurar e filtrar as entradas de diário, dependendo do nível.
Isso pode ser alcançado obtendo acesso a diferentes partes do
process e escrevendo várias linhas de código em JavaScript. No entanto, o Node.js é notável por já ter um ecossistema
npm e várias bibliotecas que podem ser usadas para esses fins. Estes incluem:
pino ;winston ;- roarr ;
- bunyan (esta biblioteca não foi atualizada por dois anos).
O Pino é frequentemente preferido porque é rápido e tem seu próprio ecossistema. Vamos ver como o
pino pode ajudar no registro. Outra vantagem dessa biblioteca é o pacote
express-pino-logger , que permite registrar solicitações.
Instale o
pino e o
express-pino-logger :

Depois disso, atualizamos o arquivo
index.js para usar o log de eventos e o middleware:
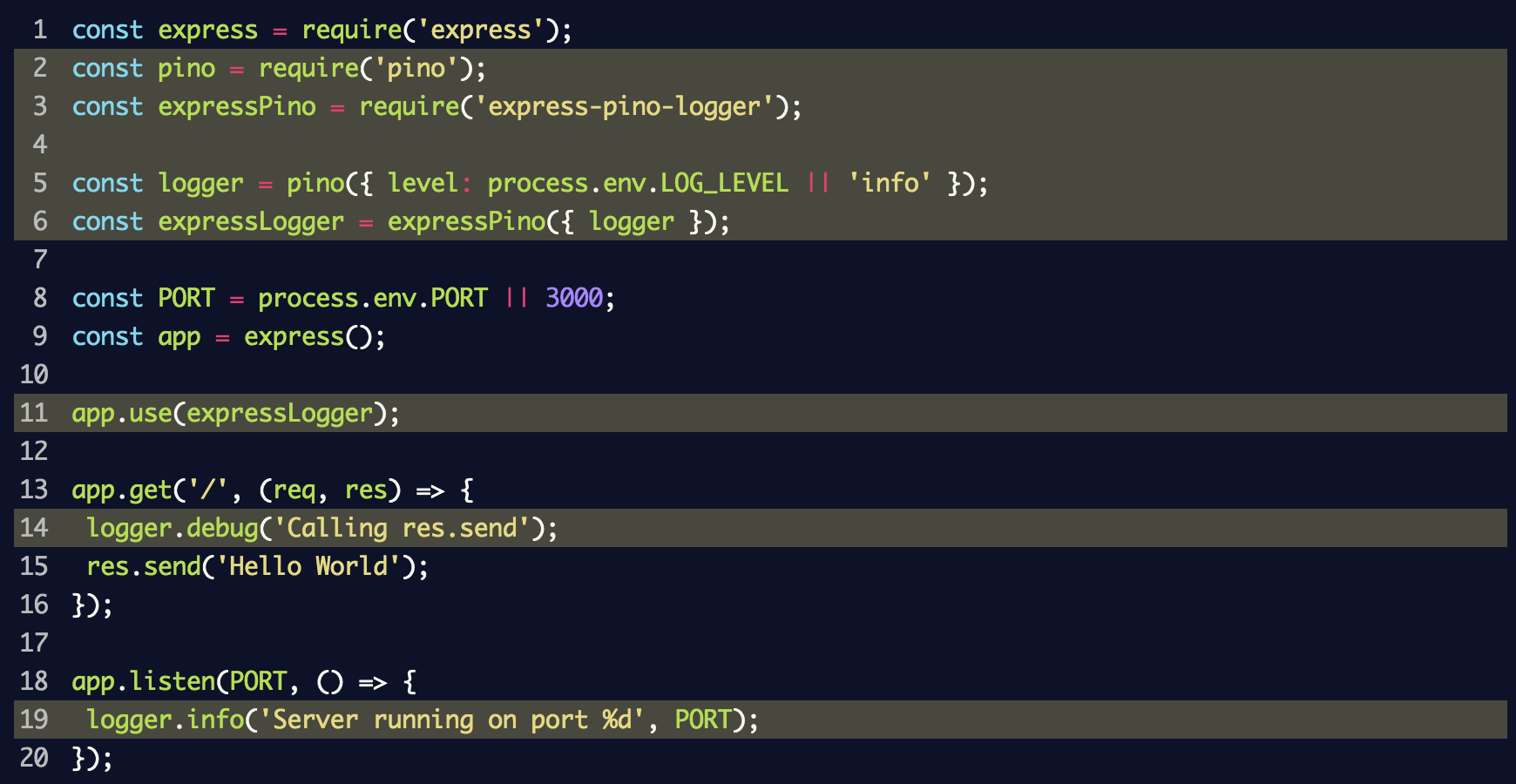
Nesse fragmento, criamos uma instância do
logger eventos para
pino e a passamos para
express-pino-logger para criar um novo software de log de eventos de plataforma cruzada com o qual você pode chamar
app.use . Além disso, o
console.log substituído no
logger.info por
logger.info e o
logger.debug adicionado à rota para exibir diferentes níveis do log.
Se você reiniciar o servidor executando repetidamente o
node index.js , obterá um resultado diferente na saída, no qual cada linha / linha será impressa no formato JSON. Mais uma vez, vá para
localhost : 3000 para ver outra nova linha no formato JSON.
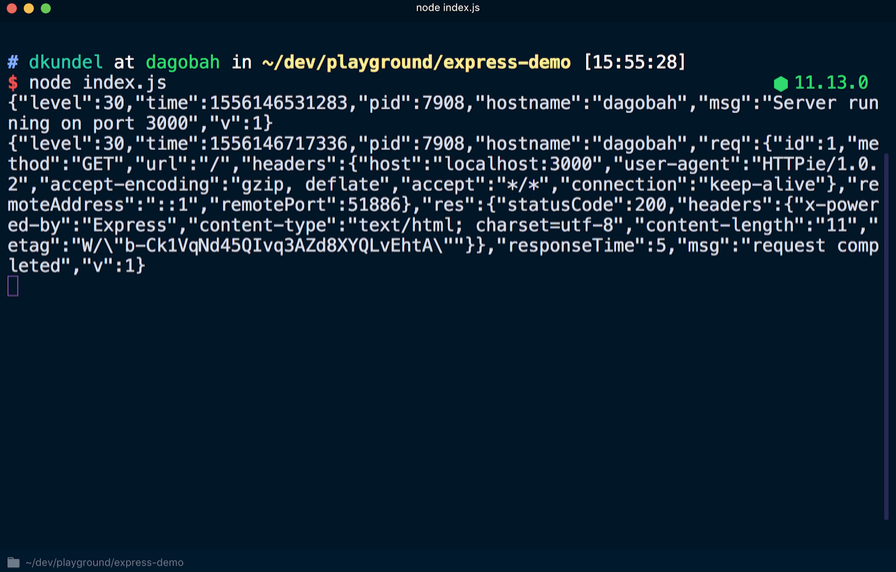
Entre os dados no formato JSON, você pode encontrar as informações mencionadas anteriormente, como um carimbo de data / hora. Observe também que a mensagem
logger.debug não
logger.debug exibida. Para torná-lo visível, você precisa alterar o nível de log padrão. Após criar uma instância do registro de eventos do criador de logs, o valor
process.env.LOG_LEVEL foi definido. Isso significa que você pode alterar o valor ou aceitar o valor padrão das
info .
LOG_LEVEL=debug node index.js executar
LOG_LEVEL=debug node index.js ,
LOG_LEVEL=debug node index.js o nível do log.
Antes de fazer isso, é necessário resolver o problema do formato de saída, o que não é muito conveniente para a percepção no momento. Este passo é intencional. De acordo com a filosofia
pino , por razões de desempenho, é necessário transferir o processamento de lançamentos contábeis manuais para um processo separado, passando a saída (usando o operador
| ). O processo envolve converter a saída em um formato mais conveniente para a percepção humana ou carregá-la na nuvem. Essa tarefa é realizada por ferramentas de transferência chamadas
transports . Confira a
documentação do kit de ferramentas de transports e veja por que os erros do
pino não são
stderr pelo
stderr .
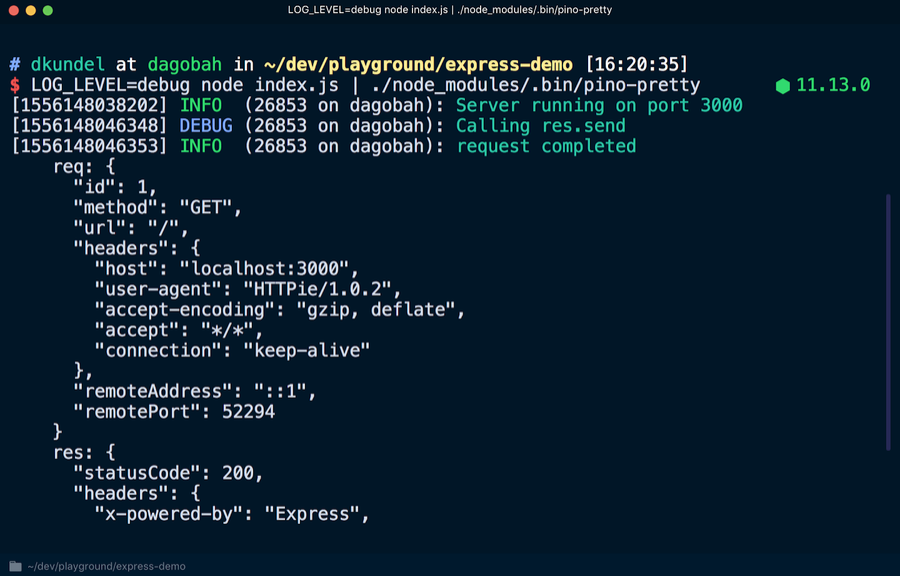
Para visualizar uma versão mais legível da revista, use a ferramenta
pino-pretty . Execute no terminal:

Todas as entradas de log são transferidas usando o
| à disposição de
pino-pretty , devido ao qual a saída é "limpa", que conterá apenas informações importantes exibidas em cores diferentes. Se você consultar
localhost : 3000 novamente, uma mensagem de depuração deve aparecer.
Para tornar os lançamentos no diário mais legíveis ou convertê-los, existem muitas ferramentas de transmissão. Eles podem até ser exibidos usando emojis usando
pino-colada . Essas ferramentas serão úteis para o desenvolvimento local. Quando o servidor está em produção, pode ser necessário transferir dados de log usando
outra ferramenta , gravá-los em disco usando
> para processamento adicional ou executar duas operações ao mesmo tempo usando um comando específico, por exemplo,
tee .
O
documento também fala sobre rotação de arquivos de log, filtragem e gravação de dados de log em outros arquivos.
Diário da biblioteca
Explorando maneiras de organizar com eficiência o log para aplicativos de servidor, você pode usar a mesma tecnologia para suas próprias bibliotecas.
O problema é que, no caso da biblioteca, pode ser necessário manter um log para fins de depuração sem carregar o aplicativo cliente. Pelo contrário, o cliente deve poder ativar o log se a depuração for necessária. Por padrão, a biblioteca não deve gravar a saída, concedendo ao usuário esse direito.
Um bom exemplo disso é a estrutura
express . Muitos processos ocorrem na estrutura interna da estrutura
express , o que pode causar interesse em estudá-lo mais profundamente durante a depuração do aplicativo. A
documentação para a estrutura express diz que você pode adicionar
DEBUG=express:* ao início do comando da seguinte maneira:

Se você aplicar este comando a um aplicativo existente, poderá ver muitas saídas adicionais que ajudarão na depuração:
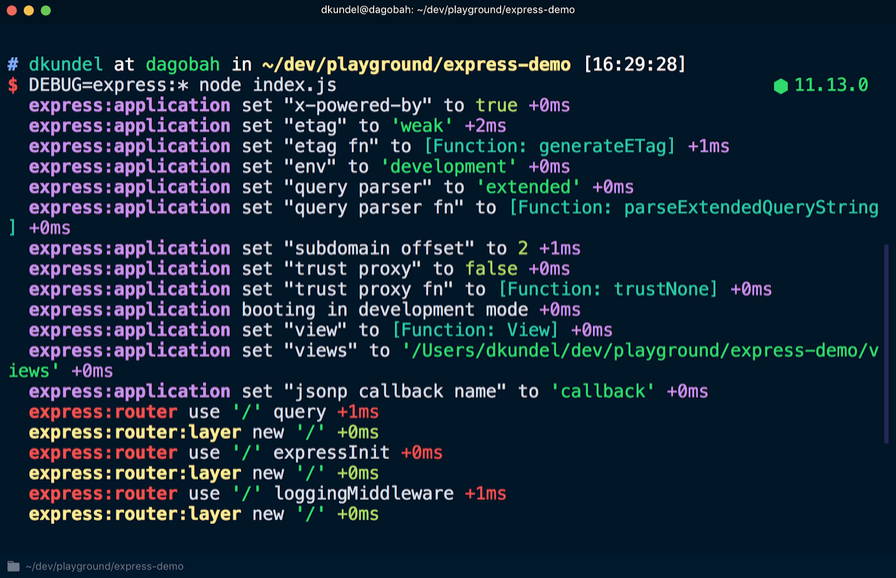
Esta informação não pode ser vista a menos que o log de depuração esteja ativado. Existe um pacote de
debug para isso. Ele pode ser usado para gravar mensagens no "espaço para nome" e, se o usuário da biblioteca incluir esse espaço para nome ou um curinga que corresponda a ele na
variável de ambiente DEBUG , as mensagens serão exibidas. Primeiro você precisa instalar a biblioteca de
debug :

Crie um novo arquivo chamado
random-id.j s que simule a biblioteca e coloque o seguinte código nele:
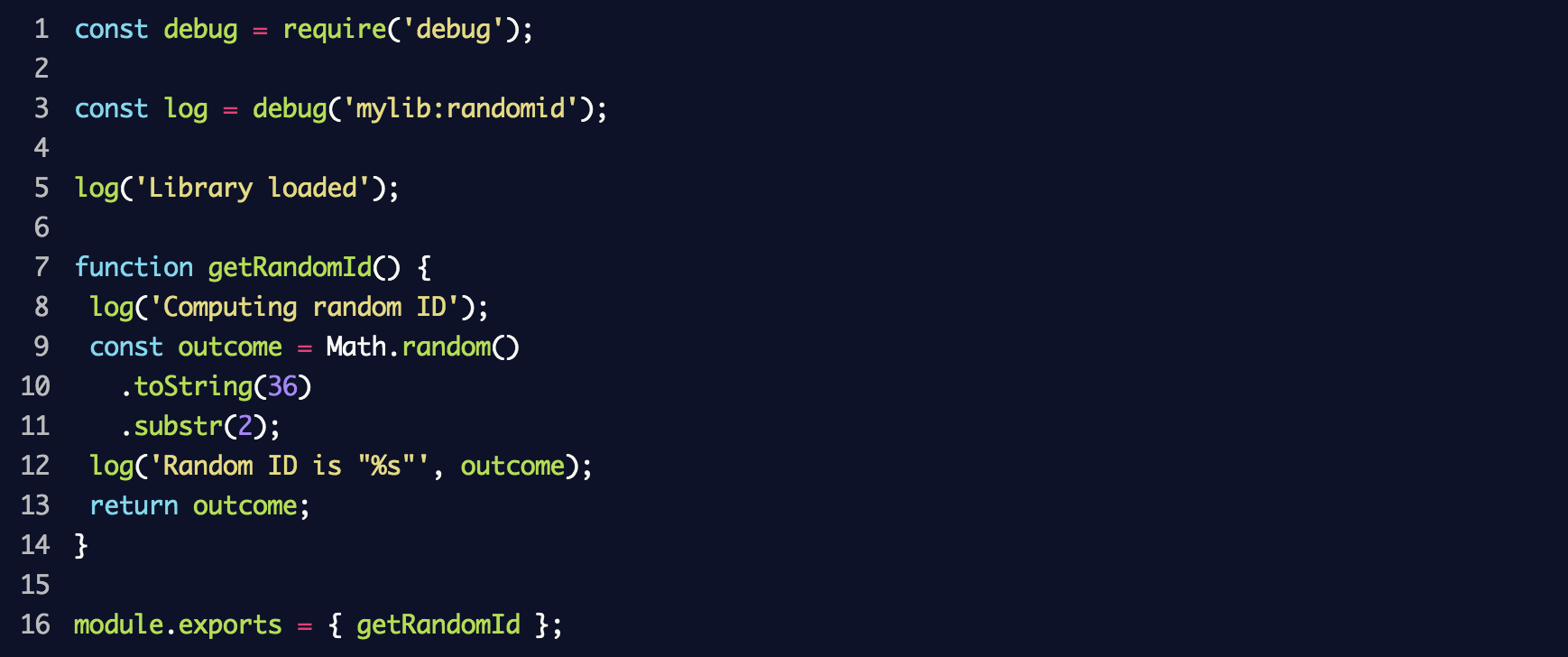
Como resultado, um novo log de eventos de
debug será criado com o
mylib:randomid , no qual duas mensagens serão registradas. Nós o usamos no
index.js da seção anterior:
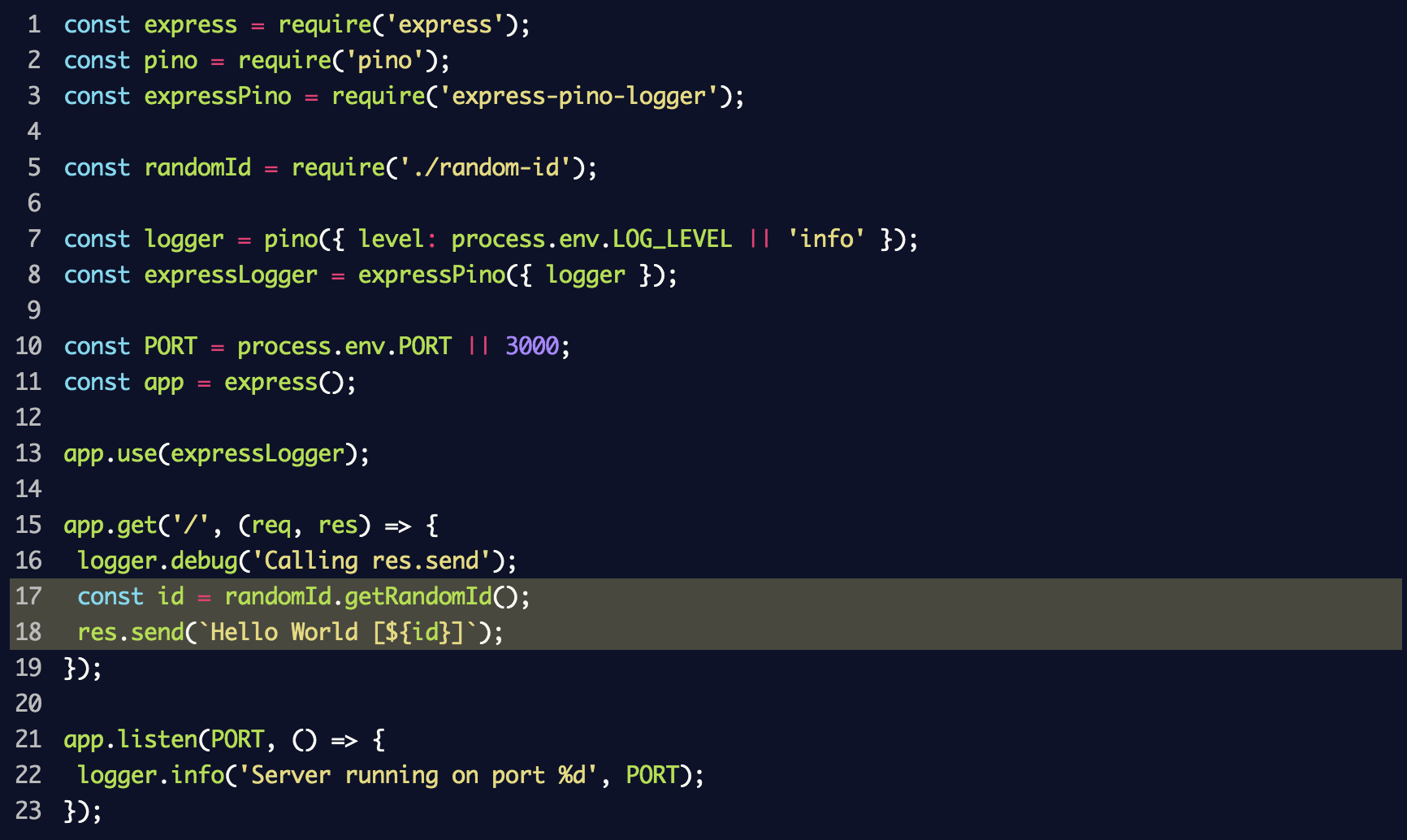
Se você iniciar o servidor novamente, adicionando
DEBUG=mylib:randomid node index.js dessa vez, as entradas do log de depuração da nossa "biblioteca" serão exibidas:
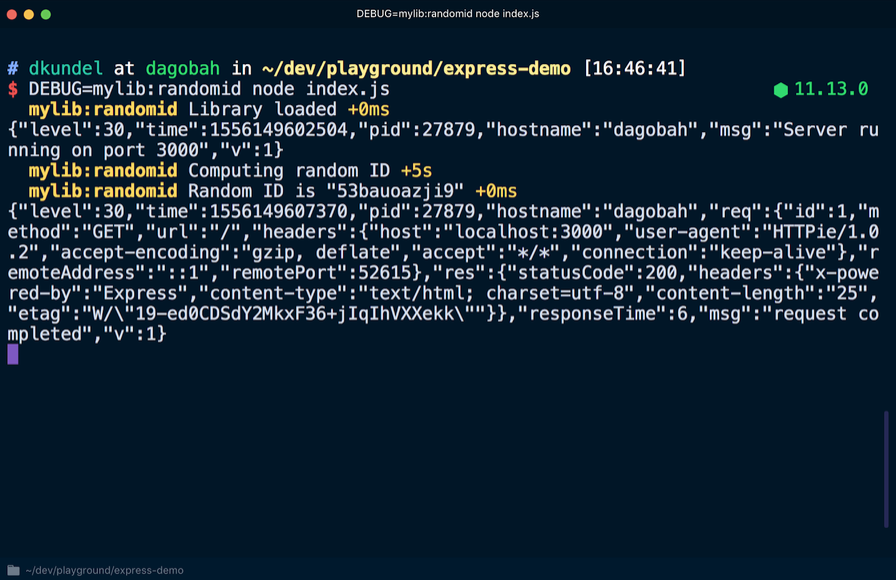
Se os usuários da biblioteca quiserem colocar informações de depuração nas entradas de log do
pino , eles poderão usar uma biblioteca chamada
pino-debug criada pelo comando
pino para formatar essas entradas corretamente.
Instale a biblioteca:

Antes de usar
debug pela primeira vez, o
pino-debug deve ser inicializado. A maneira mais fácil de fazer isso é usar os
sinalizadores -r ou --require para solicitar um módulo antes de executar o script. Reiniciamos o servidor usando o comando (desde que o
pino-colada instalado):

Como resultado, as entradas do log de depuração da biblioteca serão exibidas da mesma maneira que no log do aplicativo:
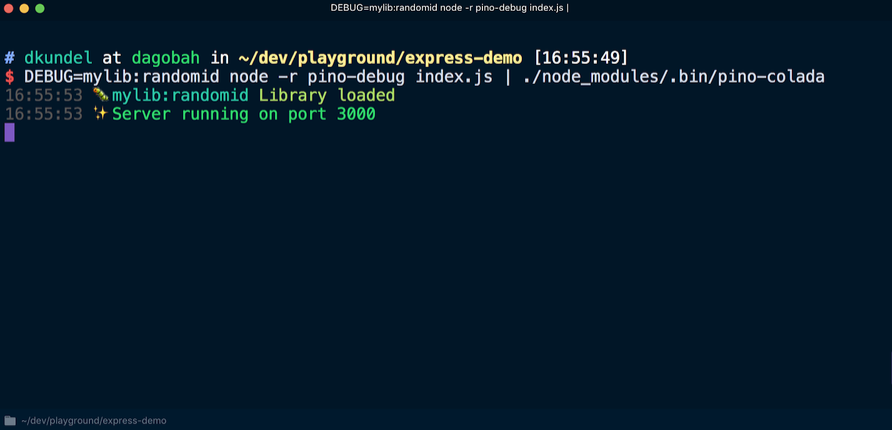
Saída da interface da linha de comandos (CLI)
O caso final discutido neste artigo é o log da interface da linha de comandos. De preferência, o log que registra eventos relacionados à lógica do programa é mantido separado do log para registrar dados da interface da linha de comandos. Para registrar quaisquer eventos relacionados à lógica do programa, você precisa usar uma biblioteca específica, por exemplo,
debug . Nesse caso, você pode reutilizar a lógica do programa sem se limitar a um cenário usando a interface da linha de comandos.
Ao criar uma interface de linha de comando usando o Node.js. , você pode adicionar várias cores, blocos de valores variáveis ou ferramentas de formatação para dar à interface uma aparência visualmente atraente. No entanto, você precisa ter em mente vários cenários.
De acordo com um deles, a interface pode ser usada no contexto de um sistema de integração contínua (IC); nesse caso, é melhor abandonar a formatação de cores e a apresentação visualmente sobrecarregada dos resultados. Alguns sistemas de integração contínua têm o sinalizador de
CI definido. Você pode verificar se está em um sistema de integração contínua usando o pacote
is-ci , que suporta vários desses sistemas.
Algumas bibliotecas, como
chalk , definem sistemas de integração contínua e substituem a saída de texto colorido no console. Vamos ver como isso funciona.
Instale o
chalk com o
install chalk npm
install chalk e crie um arquivo chamado
cli.js Coloque as seguintes linhas no arquivo:

Agora, se você executar esse script usando o
node cli.js , os resultados serão apresentados usando cores diferentes:
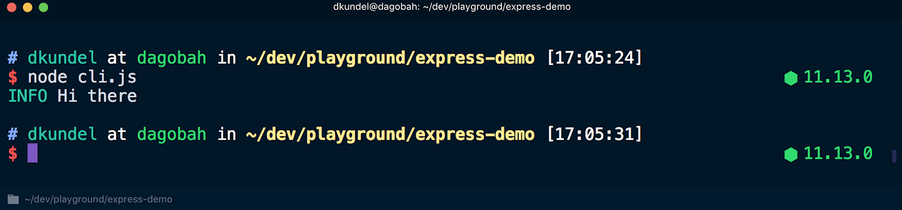
Mas se você executar o script usando
CI=true node cli.js , a formatação de cores dos textos será cancelada:
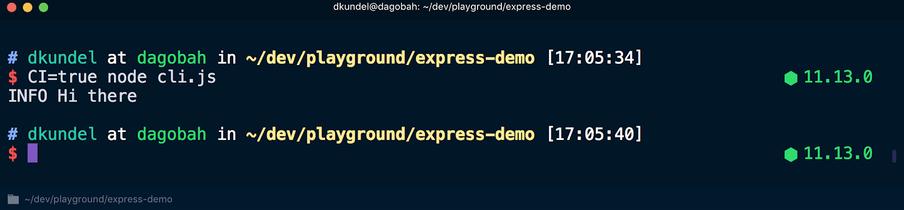
Em outro cenário que vale a pena lembrar, o
stdout sendo executado no modo terminal, ou seja, os dados são enviados para o terminal. Nesse caso, os resultados podem ser bem exibidos usando
boxen . Caso contrário, a saída provavelmente será redirecionada para um arquivo ou para outro lugar.
Você pode verificar a operação dos fluxos
stdin ,
stdout ou
stderr no modo terminal, observando o atributo
isTTY do fluxo correspondente. Por exemplo,
process.stdout.isTTY .
TTY significa "teletypewriter" e, neste caso, foi projetado especificamente para o terminal.
Os valores podem variar para cada um dos três segmentos, dependendo de como os processos do Node.js. foram iniciados. Informações detalhadas sobre isso podem ser encontradas na
documentação do
Node.js., na seção "Entrada / saída de processos" .
Vamos ver como o valor de
process.stdout.isTTY varia em diferentes situações.
cli.js arquivo
cli.js para verificar:

Agora execute o
node cli.js no terminal e veja a palavra
true , após o qual a mensagem é exibida em fonte colorida:

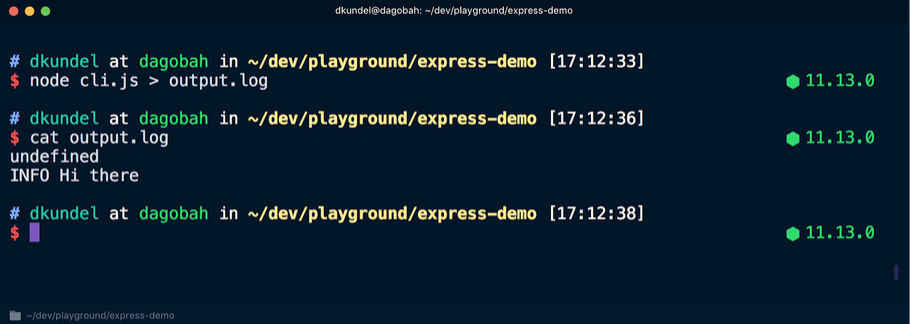
Depois disso, reexecutamos o comando, mas redirecionamos a saída para um arquivo e exibimos o conteúdo:

Dessa vez, a palavra
undefined apareceu no terminal, seguida por uma mensagem exibida em uma fonte incolor, pois o fluxo
stdout redirecionou para fora do modo terminal. Aqui o
chalk usa a ferramenta de
supports-color , que, do ponto de vista da estrutura interna, verifica o
isTTY fluxo correspondente.
Ferramentas como
chalk fazem essas coisas por conta própria. No entanto, ao desenvolver uma interface de linha de comandos, você deve sempre estar ciente de situações em que a interface funciona em um sistema de integração contínua ou a saída é redirecionada. Essas ferramentas ajudam a usar a interface da linha de comandos em um nível superior. Por exemplo, os dados no terminal podem ser organizados de uma maneira mais estruturada e, se
isTTY estiver
undefined , mude para uma maneira mais simples de análise.
Conclusão
Começar a usar JavaScript e inserir a primeira linha no log do console usando
console.log bastante simples. Porém, antes de implantar o código na produção, considere vários aspectos do uso do log. Este artigo é apenas uma introdução aos vários métodos e soluções usados na organização do log de eventos. Não contém tudo o que você precisa saber. Portanto, é recomendável prestar atenção a projetos de código aberto bem-sucedidos e monitorar como eles resolveram o problema de log e quais ferramentas são usadas. E agora tente se registrar sem gerar dados para o console.
Se você conhece outras ferramentas que valem a pena mencionar, escreva sobre elas nos comentários.