Olá pessoal!
Meu nome é Vitaliy Bendik. Sou o líder da equipe de desenvolvimento de aplicativos Android da Lamoda. Em 2018, falei no Mosdroid Aluminium com um
relatório , cuja transcrição quero compartilhar.

Será sobre como mantemos a estabilidade do aplicativo móvel. Isso é muito importante para nós, pois nosso público móvel é de milhões de usuários. Além disso, em termos de participação nos pedidos de nossos clientes, os aplicativos superaram há muito tempo os sites, as versões para computadores e dispositivos móveis no total, e a plataforma iOS se tornou uma líder absoluta, à frente do site para computadores.
No relatório vou dizer:
- o que queremos dizer com estabilidade de aplicativos;
- Sobre a arquitetura do nosso aplicativo móvel;
- sobre os processos, práticas e ferramentas que usamos.
Então, o que é uma
aplicação estável para nós? Este é um aplicativo que não trava, não trava e funciona previsivelmente. Quando digo que não cai, quero dizer que não cai em pelo menos 95% -99% dos usuários.
Arquitetura

Como você deve ter adivinhado, esta imagem mostra uma arquitetura pura, à qual tentamos aderir. Como camada de apresentação, usamos o MVP com algumas adições, as quais discutirei abaixo.
Nosso aplicativo móvel é adaptado para telefones e tablets. Portanto, o layout geralmente é diferente, mas consiste em blocos semelhantes ou idênticos. Nesse sentido, temos uma entidade como Widget. Permite decompor uma atividade ou um fragmento em blocos menores que podem ser reutilizados em outras telas. Isso faz sentido, uma vez que, do ponto de vista do código que está no fragmento ou na atividade, raramente é necessário distinguir entre o contexto em que UI está sendo executada. E esses fragmentos de código podem ser renderizados em algumas abstrações e reutilizados. Essa abordagem lembra um pouco a biblioteca SoundCloud -
LightCycle .


 Página do produto. Exemplos de elementos de widget
Página do produto. Exemplos de elementos de widgetQuanto à interação do apresentador com o modelo, tudo é padrão aqui: o apresentador interage com o restante do aplicativo por meio do interator, seja repositório ou gerenciador.
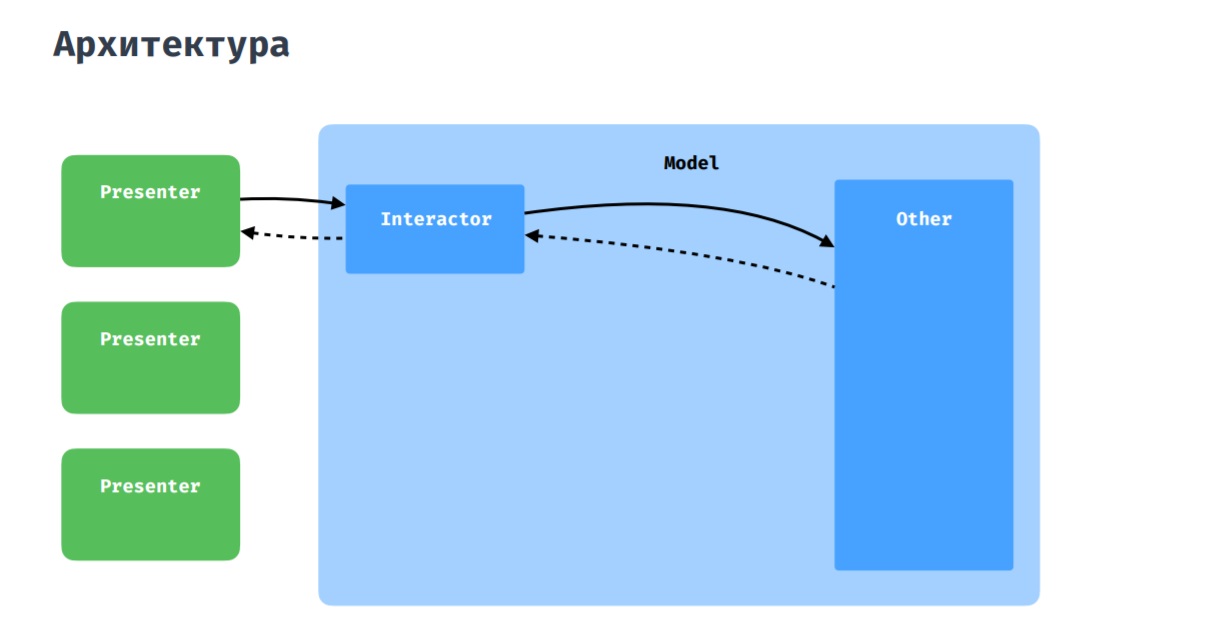
Acontece que vários apresentadores precisam se comunicar, trocar dados. Para isso, temos um coordenador, que pode ser percebido como um interator compartilhado entre vários apresentadores.

Stack
- Escrevemos todo o novo código no Kotlin e usamos o Moxy como a implementação do MVP.
- Como DI, usamos o Dagger2 .
- Para trabalhar com a rede - Retrofit .
- Para trabalhar com fotos - Glide .
- Adicionamos falhas à New Relic .
- Nós também usamos Lottie .
- No momento, estamos usando ativamente a Kotlin Coroutines .
Processo de desenvolvimento
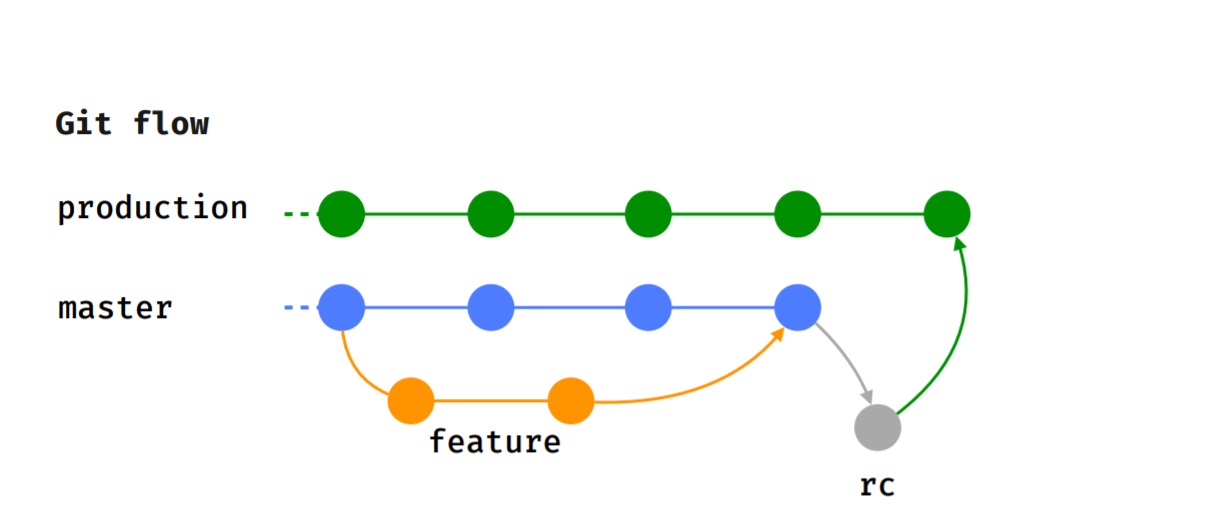
Aderimos ao fluxo Git, ou seja, cada recurso é implementado em um ramo de recurso separado, que, após uma revisão de código, é enviado para teste.
Depois que o testador concluiu com êxito o teste e decidimos a versão para a qual esse recurso passará, ele será mesclado no mestre.
Quando chega o tempo de liberação (seremos liberados a cada 2 semanas), o ramo rc, onde é realizado o teste de fumaça, é alocado, os casos de teste são executados. Depois disso, o recurso é mesclado ao ramo de produção e é publicado no Google Play Beta.
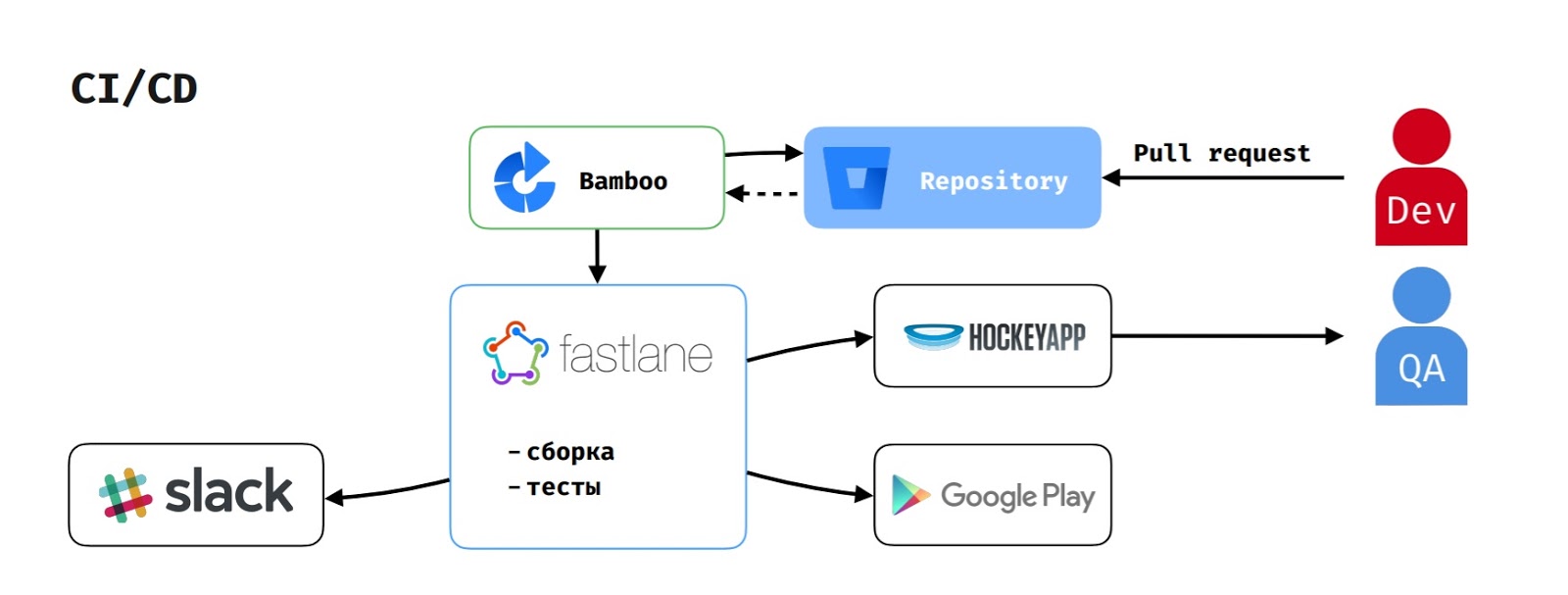
Quanto ao CI / CD, como usamos a pilha Atlassian, o Bamboo atua como um servidor de compilação.
Quando um desenvolvedor cria uma solicitação de recebimento, a tarefa de construção é iniciada no Bamboo. Ela extrai o código do repositório, executa o script na fastlane, que coleta o aplicativo, executa os testes e relata isso ao Slack.
Se o testador iniciou a montagem para testar o recurso, o apk também é carregado no HockeyApp.
Para publicar a versão no Google Play Beta, o gerente de entrega inicia a tarefa correspondente no Bamboo, que executa o mesmo fluxo, mas também carrega a versão no Google Play Beta.
Práticas Aplicadas
Compilação de pré-lançamentoInicialmente, tínhamos dois tipos de montagem, como muitos:
Compilação de depuração na qual ProGuard e SSL Pinning foram desabilitados.
Versão de lançamento na qual ProGuard e SSL Pinning foram incluídos.
O processo ficou assim: o desenvolvedor finaliza o trabalho no recurso e o fornece para teste. O testador coleta o conjunto de depuração, testa os casos de teste e verifica a correção das análises enviadas pelo aplicativo. Se tudo estiver bem, ele envia a tarefa para Pronto para a liberação, e ela aguarda o momento em que começamos a coletar a liberação.
Quando chega a hora do lançamento do aplicativo, o desenvolvedor mescla todas as tarefas no mestre, seleciona o ramo rc e fornece controle de qualidade para o teste de fumaça. O controle de qualidade coleta o conjunto de liberação e começa a executar testes. Mas há momentos em que algo dá errado. Os problemas geralmente acontecem devido ao ProGuard. Obviamente, eles são corrigidos rapidamente, mas isso pode atrasar a liberação ou atrasá-la por algum tempo.
Por esse motivo, criamos uma compilação de pré-lançamento na qual o ProGuard está ativado e a pinagem SSL está desativada. Isso permite que os testadores verifiquem a correção das análises enviadas (esse foi o motivo pelo qual os testadores não criaram inicialmente a versão).
Agora, os QAs estão construindo uma compilação de pré-lançamento. Isso lhes dá a oportunidade de testar análises e enfrentar problemas causados pelo ProGuard o mais cedo possível.
Especificação primeiroEssa é uma abordagem na qual a especificação é primária. Quando desenvolvemos um novo recurso e ele requer um back-end, uma especificação é criada primeiro e, depois, com base nele, o desenvolvimento do recurso começa no back-end e nos clientes. Todas as alterações passam pela especificação e somente então são feitas alterações no back-end e nos clientes. Essa especificação também gera documentação do Swagger sobre métodos de API.
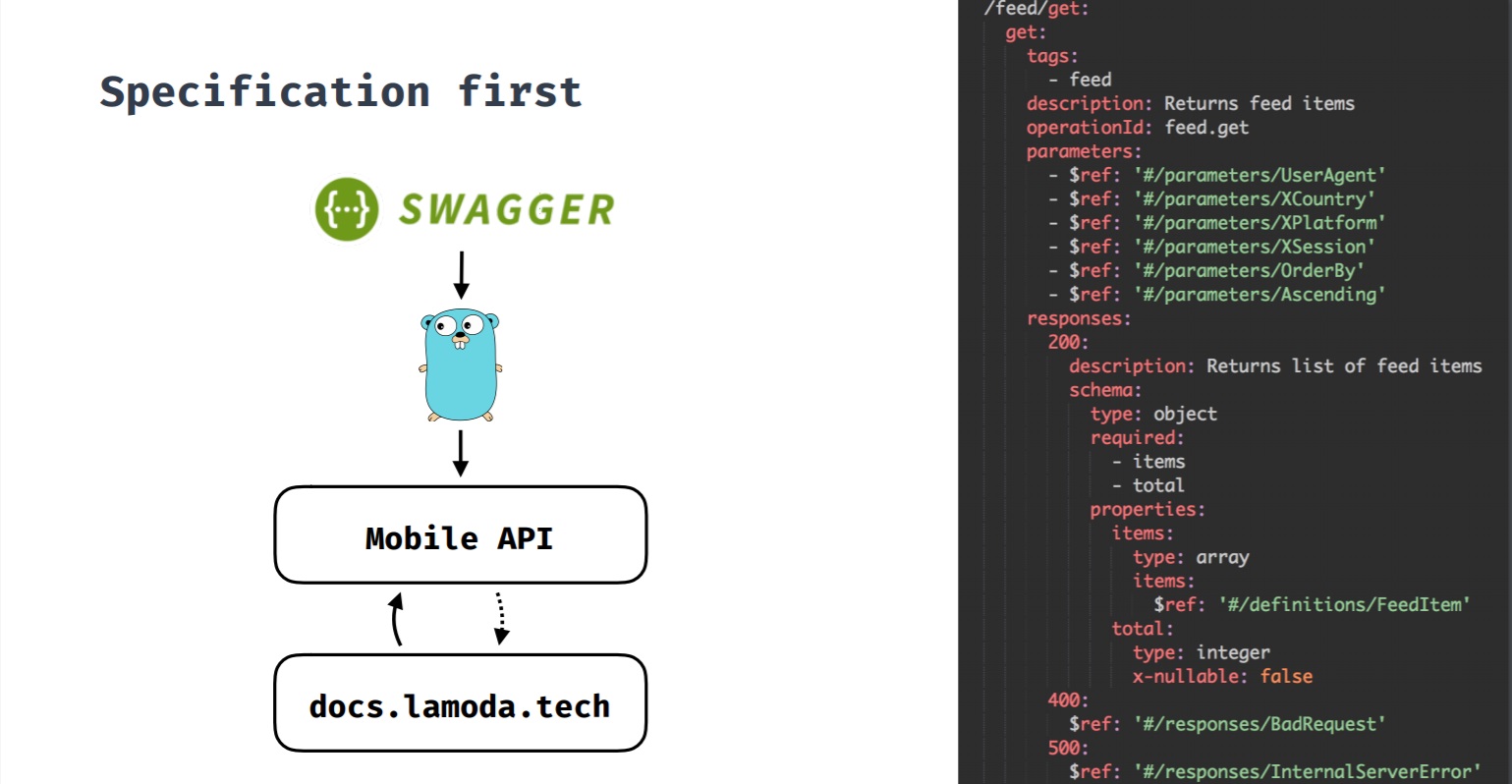
Inicialmente, tínhamos uma API cujos clientes não eram apenas aplicativos móveis. Os métodos de API não eram consistentes entre si, o que geralmente dificultava as alterações.
Também costumava encontrar casos engraçados. Por exemplo, quando o método retorna uma lista de marcas, no caso de várias, retornava uma matriz e, se havia apenas uma marca, retornava um objeto.

Ou, quando na ausência de marcas, nulo foi retornado ou, em geral, 4 caracteres nulos
(não JSON). Nesse caso, o aplicativo foi difícil.

Portanto, com o tempo, chegamos à conclusão de que aplicativos móveis exigem sua própria API, que levaria em conta suas especificidades e associaria o aplicativo móvel a vários sistemas Lamoda internos com os quais você precisa interagir.

Ao mesmo tempo, decidimos tentar a primeira abordagem de especificação (especificação Swagger). Quando um desenvolvedor começa a trabalhar em algum recurso que precisa de um back-end, ele faz uma solicitação de recebimento com um contrato de recurso. Todas as partes interessadas das equipes iOS, Android e back-end são adicionadas a essa solicitação de recebimento. Quando todos estão satisfeitos com o contrato do novo método de API, a solicitação de recebimento é inserida na ramificação de back-end e os desenvolvedores de back-end começam a desenvolver recursos. Os clientes também começam a desenvolver recursos, porque o contrato agora é fixo e você pode confiar nele e, se necessário, fabricar moki.
Alterna entre recursosA empresa possui seu próprio A / B Tool, que permite implementar experimentos e alternâncias de recursos. Alternar entre recursos fechamos funcionalidades não críticas para o usuário, que, se necessário, podem ser desabilitadas. Por exemplo, se algo der errado, ou se precisarmos reduzir a carga no back-end (como opção, na "Black Friday").
A alternância de recursos também nos permite testar bibliotecas para poder ver se outra biblioteca resolverá melhor nosso problema e se comportará de maneira mais estável. Caso contrário, sempre podemos reverter para a nossa biblioteca anterior.
Monitoramento real do usuárioO Real User Monitoring permite medir o desempenho do aplicativo da perspectiva do usuário. Por exemplo, um cliente clicou em um item em um catálogo. Quanto tempo ele precisará esperar antes de ver o resultado de sua ação, ou seja, ele vê um cartão de produto com fotos?
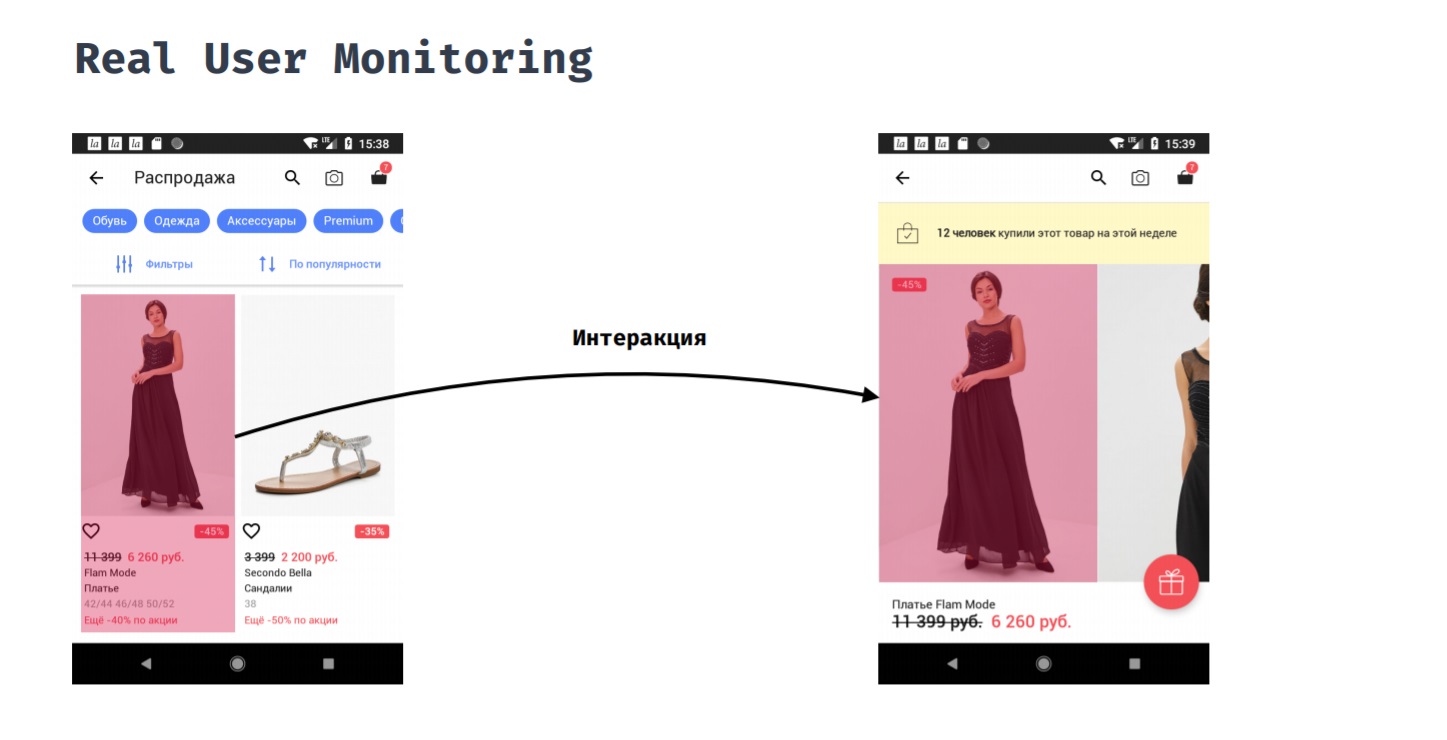
Isso não pode ser feito automaticamente, porque o ponto inicial e final desta medição devem ser definidos manualmente. Somente o desenvolvedor entende quando é possível supor que o usuário está pronto para interagir com a nova tela. No processo dessa interação, podemos estar interessados em coisas como:
1. consumo de memória;
2. consumo de CPU;
3. o que aconteceu no fluxo principal;
4. o que foi carregado da rede;
5. o que aconteceu em outros tópicos.
Isso nos dá a oportunidade de corrigir problemas, se eles surgirem, porque fica claro que realmente levou a maior parte do tempo e que podemos otimizá-lo para que o aplicativo seja mais responsivo ao usuário.
Reembolso de dívida técnica
Antes de lançar a nova versão, corrigimos as falhas que ocorreram na versão anterior. Não se trata de falhas críticas, pois isso definitivamente exigiria hotfixes, mas sobre falhas que não ocorrem com muita frequência, não afetam os indicadores de negócios, mas são desagradáveis para os usuários.
Após o lançamento da versão, a distribuímos por porcentagem, monitoramos indicadores críticos e respondemos a incidentes se eles ocorrerem. Para rolagem em fases, usamos o Google Play Console. A rolagem é realizada da seguinte forma: lançada em 5%, monitoramos o indicador; se tudo estiver em ordem, continue. Se algo aconteceu, faça o hotfix e instale-o já. Em seguida, fazemos um rolamento de 10%, 20% e 50%.
Que locais críticos estamos
monitorando ?
- Solicitações de rede, inclusive de bibliotecas de terceiros: erros, tempo de resposta, carga.
- A queda.
- Exceções tratadas, as chamadas "exceções processadas". Essas são exceções que poderiam ter ocorrido se não as tivéssemos envolvido com o try-catch. Isso permite que o aplicativo não caia se ocorrer uma exceção na funcionalidade não crítica para o usuário. Por exemplo, é ruim cair devido à análise. No entanto, é importante que os produtos entendam que um recurso melhora ou piora a conversão. O uso de exceções manipuladas nos permite responder e corrigir esses problemas.
As ferramentas
- Ferramenta A / B
- NewRelic RPM
- NewRelic Insights.
A A / B Tool é um mecanismo para conduzir experimentos e um mecanismo para rolar variáveis, as mesmas alternâncias de recurso. Este é um desenvolvimento interno, portanto está bem integrado em muitos sistemas: em aplicativos móveis, no site, no back-end. Ele permite transmitir a configuração de alternância de recursos não em uma solicitação separada por trás dela, mas nos cabeçalhos das respostas às solicitações que o aplicativo faz.
Isso nos dá a oportunidade:
- Faça experimentos no escritório quando quisermos testar algum recurso em nosso escritório.
- Inicie uma experiência, bem como alterna entre recursos para um usuário específico.
O sistema é independente de fatores externos. Se usarmos uma ferramenta de terceiros, em algum momento ela poderá ser bloqueada (Olá, Roskomnadzor) ou algo poderá dar errado nela. Para nós, isso seria crítico, pois, nesse caso, não seria possível alternar rapidamente entre os recursos. E como esse é o nosso próprio desenvolvimento, não temos esse problema.
NewRelic é uma ferramenta que permite monitorar muitos indicadores diferentes em tempo real. Da variedade de recursos da New Relic, usamos, por exemplo, instrumentação automática de código. É isso que nos permite monitorar solicitações de rede não apenas para o nosso back-end, mas também todo o resto (inclusive de bibliotecas de terceiros). O NewRelic suporta um determinado conjunto de clientes padrão para trabalhar com a rede. Também permite coletar informações:
1. sobre consumo de memória;
2. sobre o consumo da CPU;
3. sobre operações relacionadas ao JSON;
4. sobre operações relacionadas ao SQlite.
Além disso, usamos o NewRelic para coletar relatórios de falhas, coletar exceções tratadas e para interações do usuário - esse é exatamente o mesmo
Monitoramento Real do Usuário . Nós o implementamos através do mecanismo de interações do usuário NewRelic.
Mas e a estabilidade?
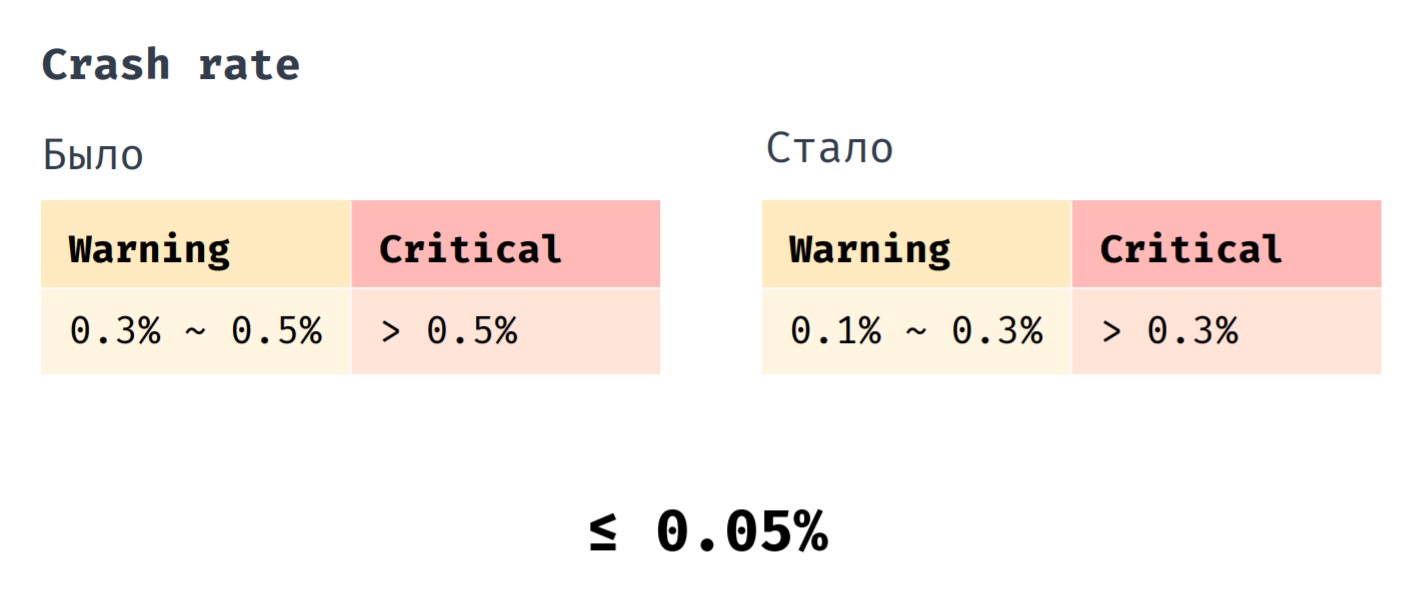
Temos um indicador como Crash rate. Anteriormente, lançamos o hotfix quando seu indicador estava no intervalo de 0,3% a 0,5%. É absolutamente crítico se seu valor se tornar maior que 0,5%. Agora lançamos o hotfix quando a taxa de falhas estiver na faixa de 0,1% a 0,3%. Um valor crítico é superior a 0,3% e, se anteriormente a taxa média de falhas de nosso aplicativo era de 0,1%, agora é de 0,05%.
Concluindo, gostaria de listar as práticas mais importantes que nos ajudam a manter a estabilidade do aplicativo. Testamos o aplicativo o mais próximo possível da versão de produção, fechamos a funcionalidade não crítica das alternâncias de modelos, além de monitorar e responder a indicadores que são importantes para nós.