
Quanto mais rápido o processo de desenvolvimento, mais rápida a empresa de tecnologia está se desenvolvendo.
Infelizmente, aplicativos modernos funcionam contra nós - nossos sistemas devem ser atualizados em tempo real e ao mesmo tempo para não incomodar ninguém e não levar a tempo de inatividade e interrupções. A implantação em tais sistemas se torna uma tarefa complexa e requer pipelines de entrega contínua complexos, mesmo em equipes pequenas.
Esses oleodutos costumam ter uma aplicação estreita, funcionam lentamente e não são confiáveis. Os desenvolvedores devem primeiro criá-los manualmente e depois gerenciá-los, e as empresas costumam contratar equipes inteiras de DevOps para isso.
A velocidade do desenvolvimento depende da velocidade desses oleodutos. Para as melhores equipes, a implantação leva de 5 a 10 minutos, mas geralmente leva muito mais tempo e, para uma implantação, leva várias horas.
No escuro, são necessários 50 ms. Cinquenta Milissegundos O Dark é uma solução completa com uma linguagem de programação, editor e infraestrutura projetada especificamente para entrega contínua, e todos os aspectos do Dark, incluindo o próprio idioma, são construídos com a visão de implantação instantânea segura.
Por que os transportadores contínuos são tão lentos?
Digamos que temos um aplicativo da Web Python e já criamos um pipeline de entrega contínua maravilhoso e moderno. Para um desenvolvedor que está ocupado com esse projeto todos os dias, a implantação de uma alteração menor será algo como isto:
Fazendo alterações
- Criando uma nova ramificação no git
- Fazendo alterações atrás da chave de função
- Teste de unidade para verificar alterações com e sem chave de função
Pedido de piscina
- Confirmar confirmação
- Publicando alterações em um repositório remoto no github
- Pedido de piscina
- O IC é criado automaticamente em segundo plano
- Revisão de código
- Mais algumas críticas, se necessário
- Mesclar alterações com o assistente git.
O IC é executado no assistente
- Definindo dependências de front-end via npm
- Construindo e otimizando recursos HTML + CSS + JS
- Execute no front end dos testes de unidade e função
- Instale dependências do Python a partir do PyPI
- Executar no back-end de testes de unidade e funcionais
- Teste de integração nas duas extremidades
- Enviar recursos de front-end para CDN
- Construindo um contêiner para um programa Python
- Enviando um contêiner para o registro
- Atualização do manifesto do Kubernetes
Substituindo código antigo por novo
- Kubernetes lança várias instâncias de um novo contêiner
- O Kubernetes está aguardando instâncias se tornarem operacionais
- Kubernetes adiciona instâncias ao balanceador de carga HTTP
- Kubernetes aguarda que instâncias antigas deixem de ser usadas
- Kubernetes interrompe instâncias antigas
- O Kubernetes repete essas operações até que novas instâncias substituam todas as antigas
Ligue o novo interruptor de função
- O novo código é incluído apenas para mim, para garantir que está tudo bem
- Novo código é incluído para 10% dos usuários; as métricas operacionais e de negócios são rastreadas
- Novo código é incluído para 50% dos usuários; as métricas operacionais e de negócios são rastreadas
- O novo código é incluído para 100% dos usuários, as métricas operacionais e de negócios são rastreadas
- Por fim, repita todo o procedimento para remover o código antigo e alternar
O processo depende das ferramentas, linguagem e uso de arquiteturas orientadas a serviços, mas, em termos gerais, parece com isso. Não mencionei as implantações de migração de banco de dados porque isso exige um planejamento cuidadoso, mas abaixo descreverei como o Dark lida com isso.
Existem muitos componentes aqui, e muitos deles podem facilmente desacelerar, travar, causar concorrência temporária ou derrubar o sistema de trabalho.
E como esses pipelines são quase sempre criados para uma ocasião especial, é difícil confiar neles. Muitas pessoas têm dias em que o código não pode ser implantado, porque há problemas no Dockerfile, uma das dezenas de serviços travou ou o especialista certo nas férias.
Pior ainda, muitos desses passos não fazem nada. Nós precisávamos deles antes, quando implantamos o código imediatamente para os usuários, mas agora temos opções para o novo código, e esses processos são divididos. Como resultado, a etapa na qual o código é implantado (o antigo é substituído pelo novo) agora se tornou apenas um risco extra.
Obviamente, este é um pipeline muito atencioso. A equipe que criou levou tempo e dinheiro para implantar rapidamente. Geralmente, os pipelines de implantação são muito mais lentos e menos confiáveis.
Implementando a entrega contínua no escuro
A entrega contínua é tão importante para a Dark que chegamos a tempo em menos de um segundo. Passamos por todas as etapas do pipeline para remover tudo o que era desnecessário e lembramos o resto. Foi assim que removemos as etapas.
Jessie Frazelle cunhou a nova palavra deployless na conferência Future of Software Development em Reykjavik
Decidimos imediatamente que Dark seria baseado no conceito de “deployless” (obrigado a Jesse Frazel pelo neologismo). Implantação significa que qualquer código é implantado instantaneamente e pronto para uso na produção. Obviamente, não perderemos um código com defeito ou incompleto (descreverei os princípios de segurança abaixo).
Na demo Dark, muitas vezes nos perguntam como conseguimos acelerar a implantação. Pergunta estranha. As pessoas provavelmente pensam que criamos algum tipo de supertecnologia que compara o código, o compila, o empacota em um contêiner, lança uma máquina virtual, lança um contêiner em um frio e coisas assim - e tudo isso em 50 ms. Isso dificilmente é possível. Mas criamos um mecanismo de implantação especial, que não precisa de tudo isso.
Dark lança intérpretes na nuvem. Suponha que você escreva código em uma função ou manipulador para HTTP ou eventos. Enviamos diff para a árvore de sintaxe abstrata (a implementação do código usado internamente por nosso editor e servidores) para nossos servidores e, em seguida, executamos esse código quando as solicitações são recebidas. Portanto, a implantação se parece com um registro modesto no banco de dados - instantâneo e elementar. A implantação é tão rápida porque inclui o mínimo necessário.
No futuro, planejamos criar um compilador de infraestrutura fora do Dark, que criará e executará a infraestrutura ideal para alto desempenho e confiabilidade dos aplicativos. A implantação instantânea, é claro, não vai a lugar nenhum.
Implantação segura
Editor Estruturado
O código no Dark está escrito no editor Dark. O editor estruturado não comete erros de sintaxe. De fato, Dark nem sequer tem um analisador. Enquanto você digita, trabalhamos diretamente com a Árvore de sintaxe abstrata (AST), como Paredit , Esboço e esboço , Tofu , Prune e MPS .
Qualquer código incompleto no Dark possui semântica de execução válida, como os buracos digitados no Hazel . Por exemplo, se você alterar uma chamada de função, mantemos a função antiga até que a nova se torne utilizável.
Cada programa no Dark tem seu próprio significado, portanto, o código incompleto não interfere no trabalho final.
Modos de edição
Você escreve código no Dark em dois casos. Primeiro: você escreve um novo código e é o único usuário. Por exemplo, ele está no REPL e outros usuários nunca terão acesso a ele, ou é uma nova rota HTTP à qual você não se refere em nenhum lugar. Você pode trabalhar aqui sem nenhuma precaução e agora está trabalhando aproximadamente no ambiente de desenvolvimento.
Segunda situação: o código já está em uso. Se o tráfego passar pelo código (funções, manipuladores de eventos, bancos de dados, tipo), deve-se tomar cuidado. Para fazer isso, bloqueamos todo o código usado e exigimos o uso de ferramentas mais estruturadas para editá-lo. A seguir, falarei sobre ferramentas estruturais: comutadores de função para HTTP e manipuladores de eventos, uma poderosa plataforma de migração para bancos de dados e um novo método de controle de versão para funções e tipos.
Interruptores de função
Uma maneira de remover a complexidade extra no Dark é corrigir vários problemas com uma solução. Os comutadores de função executam muitas tarefas diferentes: substituição do ambiente de desenvolvimento local, ramificações git, código de implantação e, é claro, a liberação lenta e controlada tradicional do novo código.
A criação e a implantação de um comutador de função são realizadas em nosso editor em uma operação. Ele cria um espaço vazio para o novo código e fornece controles de acesso ao código antigo e novo, além de botões e comandos para transição gradual para o novo código ou sua exclusão.
Os comutadores de função são incorporados ao idioma Escuro, e até comutadores incompletos realizam sua tarefa - se a condição no comutador não for atendida, o código bloqueado antigo será executado.
Ambiente de desenvolvimento
As chaves de função substituem o ambiente de desenvolvimento local. Hoje, é difícil para as equipes garantir que todos usem as mesmas versões de ferramentas e bibliotecas (formatadores de código, linters, gerenciadores de pacotes, compiladores, pré-processadores, ferramentas de teste etc.) Com o Dark, você não precisa instalar dependências localmente, controlar a instalação local do Docker ou tomar outras medidas para garantir pelo menos uma aparência de igualdade entre o ambiente de desenvolvimento e a produção. Dado que essa igualdade ainda é impossível , nem fingiremos que estamos lutando por ela.
Em vez de criar um ambiente local clonado, os switches no Dark criam uma nova sandbox na produção que substitui o ambiente de desenvolvimento. No futuro, também planejamos criar uma caixa de proteção para outras partes do aplicativo (por exemplo, clones de banco de dados instantâneos), embora, por enquanto, isso não pareça tão importante.
Ramos e implantações
Agora, existem várias maneiras de inserir novo código nos sistemas: ramificações git, fase de implantação e comutadores de funções. Eles resolvem um problema em diferentes partes do fluxo de trabalho: git - nos estágios antes da implantação, na implantação - no momento da transição do código antigo para o novo e nos comutadores de função - para a liberação controlada do novo código.
A maneira mais eficaz é a troca de funções (ao mesmo tempo, a mais fácil de entender e usar). Com eles, você pode abandonar completamente os outros dois métodos. É especialmente útil remover a implantação - se usarmos as opções de função para incluir o código de qualquer maneira, a etapa de transferir os servidores para o novo código criará apenas riscos desnecessários.
O Git é difícil de usar, especialmente para iniciantes, e realmente o limita, mas possui ramificações convenientes. Nós eliminamos muitas das falhas do Git. O Dark é editado em tempo real e oferece a capacidade de trabalhar em conjunto no estilo do Google Docs, para que você não precise enviar o código e com menos frequência realize a realocação e a mesclagem.
Os comutadores de recursos sustentam a implantação segura. Juntamente com implantações instantâneas, eles permitem que você teste rapidamente conceitos em pequenos fragmentos com baixo risco, em vez de aplicar uma grande mudança que pode derrubar o sistema.
Versionamento
Para alterar funções e tipos, usamos versionamento. Se você deseja alterar uma função, o Dark cria uma nova versão dessa função. Em seguida, você pode invocar esta versão usando a opção no HTTP ou no manipulador de eventos. (Se essa função estiver no fundo do gráfico de chamadas, uma nova versão de cada função será criada no processo. Pode parecer muito, mas as funções não interferem se você não as usar, por isso você nem notará.)
Pelas mesmas razões, somos tipos de versão. Falamos sobre nosso sistema de tipos em detalhes em um post anterior .
Ao versionar funções e tipos, você pode fazer alterações no aplicativo gradualmente. Você pode verificar se cada manipulador individual trabalha com a nova versão; não é necessário fazer imediatamente todas as alterações nos aplicativos (mas temos ferramentas para fazer isso rapidamente, se você quiser).
Isso é muito mais seguro do que implantar totalmente tudo de uma vez, como é agora.
Novas versões de pacotes e biblioteca padrão
Quando você atualiza um pacote no Dark, não substituímos imediatamente o uso de cada função ou tipo em toda a base de código. Isso não é seguro. O código continua a usar a mesma versão usada e você atualiza o uso de funções e tipos para uma nova versão para cada caso individual usando as opções.

Uma captura de tela de uma parte de um processo automático no Dark mostrando duas versões da função Dict :: get. Dict :: get_v0 retornou o tipo Any (que recusamos) e Dict :: get_v1 retornou o tipo Option.
Nós geralmente fornecemos um novo recurso na biblioteca padrão e excluímos versões mais antigas. Usuários com versões antigas no código reterão acesso a eles, mas novos usuários não poderão obtê-los. Forneceremos ferramentas para transferir usuários de versões antigas para novas em uma etapa e novamente usando as opções de função.
O Dark também oferece uma oportunidade única: uma vez que executamos seu código de trabalho, podemos testar as novas versões, comparando a saída de solicitações novas e antigas para informá-lo das alterações. Como resultado, as atualizações de pacotes, que geralmente são realizadas às cegas (ou exigem testes rigorosos de segurança), apresentam muito menos riscos e podem ocorrer automaticamente.
Novas versões escuras
A transição do Python 2 para o Python 3 se estendeu por mais de uma década e ainda permanece um problema. Depois que criamos o Dark para entrega contínua, essas alterações de idioma precisam ser consideradas.
Quando fazemos pequenas alterações no idioma, criamos uma nova versão do Dark. O código antigo permanece na versão antiga do Dark, e o novo código é usado na nova versão. Para mudar para a nova versão do Dark, você pode usar as opções ou versões de funções.
Isso é especialmente útil, considerando que o Dark apareceu recentemente. Muitas alterações no idioma ou na biblioteca podem falhar. O versionamento gradual do idioma nos permite fazer pequenas atualizações, ou seja, não podemos nos apressar e adiar muitas decisões sobre o idioma até termos mais usuários e, portanto, mais informações.
Migrações de banco de dados
Existe uma fórmula padrão para migração segura de banco de dados:
- Reescreva o código para suportar formatos novos e antigos
- Converta todos os dados para um novo formato
- Excluir acesso antigo a dados
Como resultado, a migração do banco de dados está atrasada e requer muitos recursos. E estamos acumulando esquemas desatualizados, porque mesmo tarefas simples, como corrigir o nome de uma tabela ou coluna, não valem o esforço.
O Dark tem uma plataforma eficaz de migração de banco de dados que (esperamos) simplificará tanto o processo que você não terá mais medo dele. Todos os armazenamentos de dados no Escuro (pares de valores-chave ou tabelas de hash persistentes) são do tipo. Para migrar um data warehouse, você simplesmente atribui a ele um novo tipo e uma função de reversão e reversão para converter valores entre os dois tipos.
O acesso aos data warehouses no Dark é por meio de nomes de variáveis com versão. Por exemplo, o armazenamento de dados Usuários seria chamado inicialmente Usuários-v0. Quando uma nova versão com um tipo diferente é criada, o nome muda para Usuários-v1. Se os dados são salvos por meio de Users-v0 e você os acessa por meio de Users-v1, a função de rollover é aplicada. Se os dados são salvos através do Users-v1 e você os acessa através do Users-v0, a função de reversão é usada.
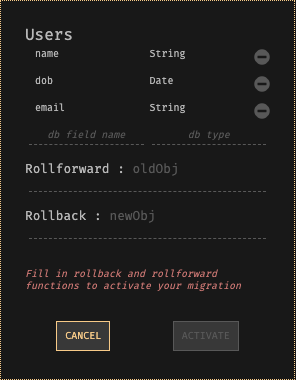
Tela de migração de banco de dados com nomes de campo para o banco de dados antigo, expressões de reversão e reversão e instruções para ativar a migração.
Use os comutadores de função para rotear chamadas para Usuários-v0 para Usuários-v1. Você pode fazer esse manipulador HTTP de cada vez para reduzir riscos, e os comutadores também funcionam para usuários individuais, para que você possa verificar se tudo está funcionando conforme o esperado. Quando o Users-v0 não é deixado, o Dark converte todos os dados restantes em segundo plano do formato antigo para o novo. Você nem percebe.
Teste
Dark é uma linguagem de programação funcional com tipagem estática e valores imutáveis; portanto, sua superfície de teste é significativamente menor em comparação com linguagens orientadas a objetos com tipagem dinâmica. Mas você ainda precisa testar.
No escuro, o editor executa automaticamente testes de unidade em segundo plano para código editável e, por padrão, executa esses testes para todas as opções de função. No futuro, queremos usar os tipos estáticos para confundir automaticamente o código e encontrar bugs.
Além disso, o Dark executa sua infraestrutura em produção, e isso abre novas possibilidades. Salvamos automaticamente as solicitações HTTP na infraestrutura Dark (por enquanto, salvamos todas as solicitações, mas queremos mudar para a busca). Testamos um novo código neles e realizamos testes de unidade e, se desejar, você pode facilmente converter consultas interessantes em testes de unidade.
Do que nos livramos
Como não temos uma implantação, mas há comutadores de funções, cerca de 60% do pipeline de implantação permanece no mar. Não precisamos de solicitações de ramos ou pool de git, criando recursos e contêineres de back-end, enviando recursos e contêineres para registros ou etapas de implantação no Kubernetes.
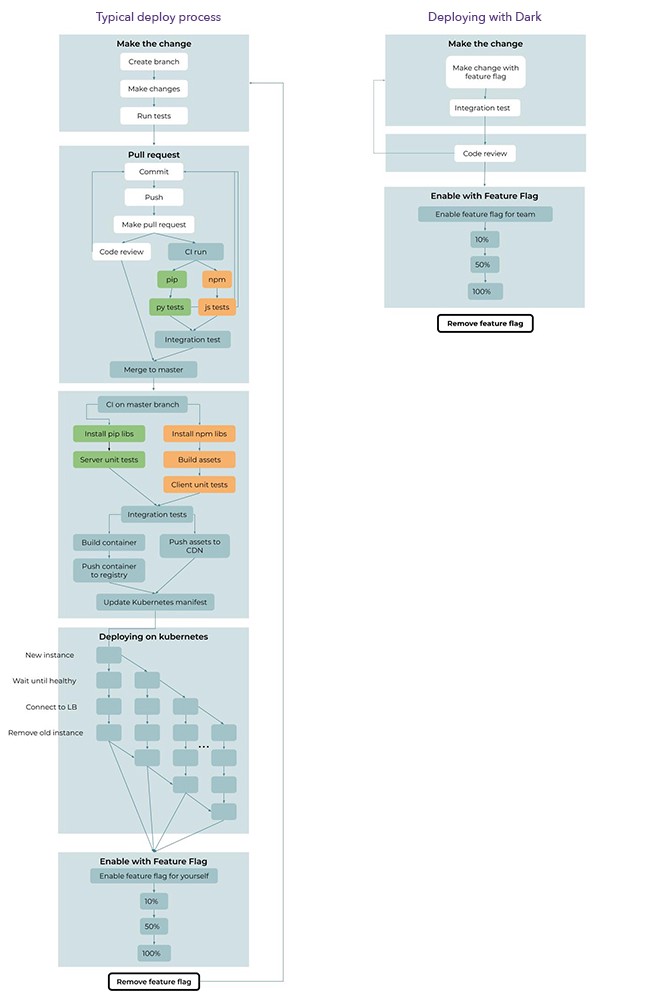
Comparação do pipeline de entrega contínua padrão (esquerda) e do fornecimento contínuo de Dark (direita). No escuro, a entrega consiste em 6 etapas e um ciclo, enquanto a versão tradicional inclui 35 etapas e 3 ciclos.
No Dark, existem apenas 6 etapas e 1 ciclo na implantação (etapas repetidas várias vezes), enquanto o pipeline de suprimento contínuo moderno consiste em 35 etapas e 3 ciclos. No escuro, os testes são executados automaticamente e você nem vê; dependências são instaladas automaticamente; nada relacionado ao git ou github não é mais necessário; Não é necessário coletar, testar e enviar contêineres do Docker; A implantação do Kubernetes não é mais necessária.
Até as etapas restantes no Dark se tornaram mais fáceis. Como as comutações de funções podem ser controladas em uma ação, você não precisa passar pelo pipeline de implantação inteiro uma segunda vez para remover o código antigo.
Simplificamos a entrega do código o máximo possível, reduzindo o tempo e os riscos da entrega contínua. Também simplificamos bastante as atualizações de pacotes, as migrações de bancos de dados, os testes, o controle de versão, a instalação de dependências, a igualdade entre o ambiente e a produção de desenvolvimento e as atualizações rápidas e seguras de versões de idiomas.
Eu respondo perguntas sobre isso no HackerNews .
Para saber mais sobre o dispositivo Dark, leia o artigo Dark , siga-nos no Twitter (ou em mim ) ou inscreva-se em uma versão beta e receba notificações das seguintes postagens . Se você vier ao StrangeLoop em setembro, venha ao nosso lançamento .