O título deste artigo pode parecer um pouco estranho. De fato: se você trabalha no campo da ciência de dados em 2019, já está em demanda. A demanda por especialistas nesse campo está crescendo constantemente: no momento da redação deste artigo, 144.527 vagas com a palavra-chave "Ciência de dados" eram publicadas no LinkedIn.
No entanto, definitivamente vale a pena acompanhar as últimas notícias e tendências do setor. Para ajudá-lo, a equipe do
CV Compiler e eu analisamos várias centenas de empregos em Data Science em junho de 2019 e determinamos quais habilidades os empregadores mais esperam dos candidatos.
As habilidades mais procuradas em Data Science em 2019
Este gráfico mostra as habilidades que os empregadores mais mencionam nos trabalhos de Ciência de dados em 2019:
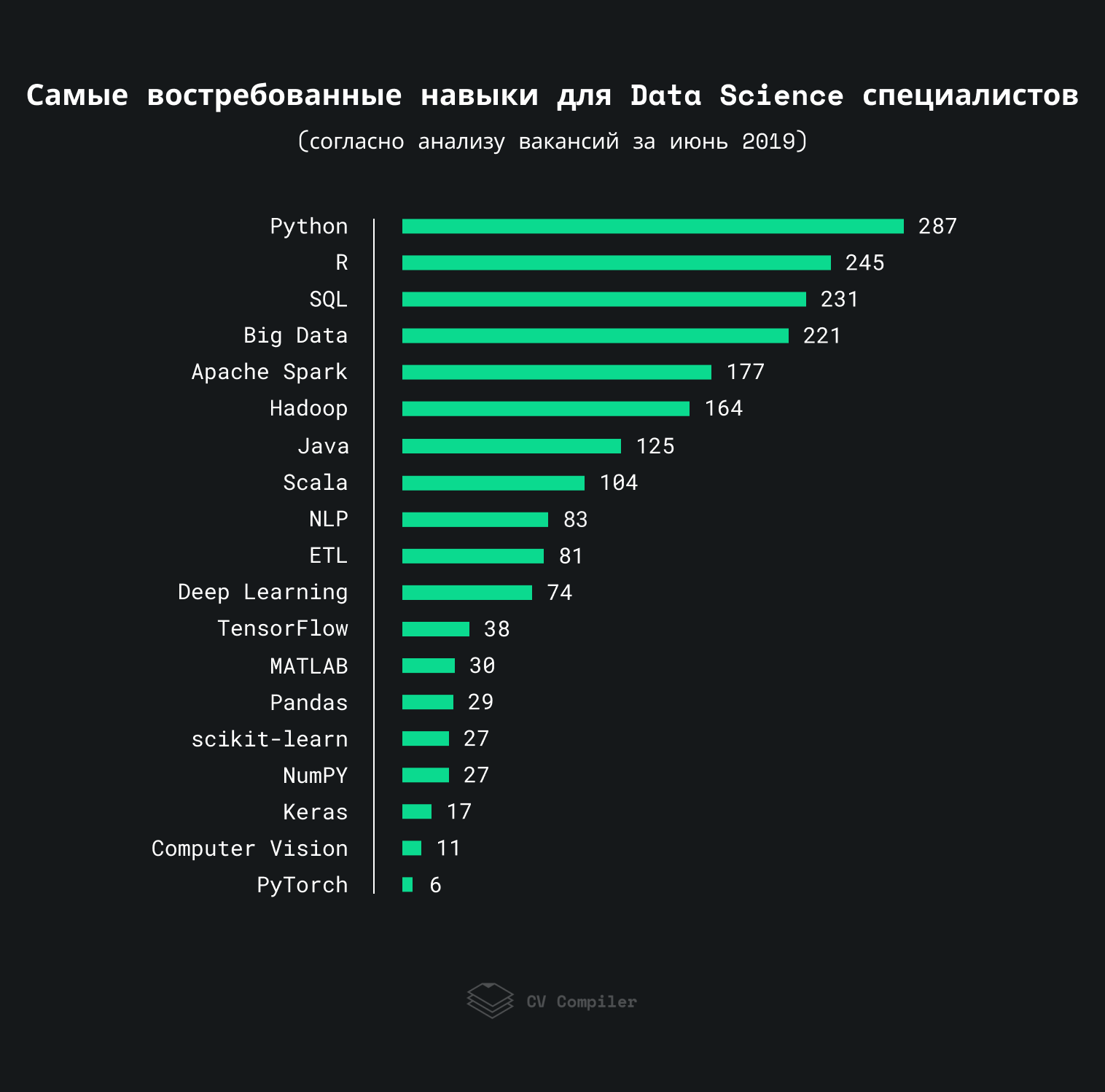
Analisamos aproximadamente 300 trabalhos com StackOverflow, AngelList e recursos semelhantes. Alguns termos podem ser repetidos mais de uma vez na mesma vaga.
Importante: esta classificação demonstra as preferências dos empregadores em vez de especialistas no campo da ciência de dados.
Principais Tendências em Ciência de Dados
Obviamente, a Ciência de Dados não é primariamente estruturas e bibliotecas, mas conhecimento fundamental. No entanto, algumas tendências e tecnologias ainda merecem destaque.
Big data
De acordo com
uma pesquisa de mercado do Big Data em 2018 , o uso do Big Data nas empresas aumentou de 17% em 2015 para 59% em 2018. Consequentemente, a popularidade das ferramentas para trabalhar com o Big Data aumentou. Se você desconsiderar o Apache Spark e o Hadoop (falaremos sobre o último em mais detalhes), as ferramentas mais populares são o
MapReduce (36) e
Redshift (29).
Hadoop
Apesar da popularidade do Spark e do armazenamento em nuvem, a
era do
Hadoop ainda não acabou. Portanto, algumas empresas esperam que os candidatos conheçam o
Apache Pig (30),
HBase (32) e tecnologias semelhantes.
O HDFS (20) também é encontrado em alguns trabalhos.
Processamento de dados em tempo real
Dado o uso onipresente de vários sensores e dispositivos móveis, bem como a popularidade da
IoT (18), as empresas estão tentando aprender como processar dados em tempo real. Portanto, plataformas de encadeamento como o
Apache Flink (21) são populares entre os empregadores.
Engenharia de recursos e ajuste de hiperparâmetro
A preparação dos dados e a seleção dos parâmetros do modelo é uma parte importante do trabalho de qualquer especialista no campo da ciência de dados. Portanto, o termo
Mineração de Dados (128) é bastante popular entre os empregadores. Algumas empresas também prestam atenção ao
ajuste de hiperparâmetro (21) (um termo como
Feature Engineering também não deve ser esquecido ). A seleção dos parâmetros ideais para o modelo é importante, porque o desempenho geral do modelo depende do sucesso dessa operação.
Visualização de dados
A capacidade de processar dados corretamente e exibir os padrões necessários é importante. No entanto,
a visualização de dados (55) é uma habilidade igualmente importante. Você deve poder apresentar os resultados do seu trabalho em um formato compreensível para qualquer membro da equipe ou cliente. Em termos de ferramentas de visualização de dados, os empregadores preferem o
Tableau (54).
Tendências gerais
Nas vagas, também encontramos termos como
AWS (86),
Docker (36) e
Kubernetes (24). Pode-se concluir que as tendências gerais do campo de desenvolvimento de software migraram lentamente para o campo de Ciência de Dados.
Opinião de especialistas
Esta lista de tecnologias realmente reflete o estado real das coisas no mundo da ciência de dados. No entanto, não há coisas menos importantes do que escrever código. Essa é a capacidade de interpretar corretamente os resultados de seu trabalho, além de visualizá-los e apresentá-los de forma compreensível. Tudo depende da audiência - se você falar sobre suas realizações com candidatos da ciência, falar a língua deles, mas se você apresentar os resultados ao cliente, ele não se importará com o código - apenas com o resultado que você alcançou.
Carla Gentry
Cientista de dados, proprietário da
Analytical SolutionLinkedIn |
TwitterEste gráfico mostra as tendências atuais no campo da ciência de dados, mas é bastante difícil prever o futuro com base nele. Estou inclinado a acreditar que a popularidade do R diminuirá (como a popularidade do MATLAB), enquanto a popularidade do Python só aumentará. O Hadoop e o Big Data também acabaram na lista por inércia: o Hadoop desaparecerá em breve (ninguém mais está investindo seriamente nessa tecnologia), e o Big Data deixou de ser uma tendência crescente. O futuro do Scala não é totalmente claro: o Google suporta oficialmente o Kotlin, que é muito mais fácil de aprender. Também sou cético quanto ao futuro do TensorFlow: a comunidade científica prefere o PyTorch, e a influência da comunidade científica no campo da ciência de dados é muito maior do que em todas as outras áreas. (Essa é minha opinião pessoal, que pode não coincidir com a opinião do Gartner).
Andrey Burkov,
Diretor de aprendizado de máquina da Gartner,
autor do
livro de aprendizado de máquina de cem páginas .
LinkedInO PyTorch é a força motriz por trás do aprendizado reforçado, bem como uma estrutura forte para a execução paralela de código em várias GPUs (o que não é o caso do TensorFlow). O PyTorch também ajuda a criar gráficos dinâmicos eficazes ao trabalhar com redes neurais recorrentes. O TensorFlow opera com gráficos estáticos e é mais difícil de estudar, mas é usado por mais desenvolvedores e pesquisadores. No entanto, o PyTorch está mais próximo do Python em termos de código de depuração e bibliotecas para visualização de dados (matplotlib, seaborn). A maioria das ferramentas de depuração de código Python pode ser usada para depurar código PyTorch. O TensorFlow também possui sua própria ferramenta de depuração - tfdbg.
Ganapati Pulipaka,
Chief Data Scientist da Accenture,
Vencedor do prêmio Top 50 Tech Leader.
LinkedIn |
TwitterNa minha opinião, trabalho e carreira em Data Science não são a mesma coisa. Para trabalhar, você precisará do conjunto de habilidades acima, mas, para construir uma carreira de sucesso em Data Science, a habilidade mais importante é a capacidade de aprender. A ciência de dados é um campo instável, e você terá que aprender a dominar novas tecnologias, ferramentas e abordagens para acompanhar o ritmo dos tempos. Coloque constantemente novos desafios e tente não "se contentar com pouco".
Lon Riesberg
Fundador / Curador da
Data Elixir ,
ex-nasa.
Twitter |
LinkedInA ciência de dados é um campo complexo e de rápido desenvolvimento, no qual o conhecimento fundamental é tão importante quanto a experiência com determinadas ferramentas. Esperamos que este artigo o ajude a determinar quais habilidades são necessárias para se tornar um especialista mais procurado na área de Ciência de Dados em 2019. Boa sorte!
Este artigo foi escrito pela equipe do CV Compiler , uma ferramenta para melhorar os currículos da ciência de dados e de outros profissionais de TI.