
Nos últimos anos, os bancos de dados de séries temporais evoluíram de uma coisa curiosa (altamente especializada em sistemas de monitoramento abertos (e vinculados a soluções específicas) ou em projetos de Big Data) em "bens de consumo". No território da Federação Russa, agradecimentos especiais à Yandex e ClickHouse por isso. Até o momento, se você precisava salvar uma grande quantidade de dados de séries temporais, era necessário aceitar a necessidade de criar uma pilha monstruosa do Hadoop e acompanhá-la, ou comunicar-se com protocolos específicos para cada sistema.
Pode parecer que em 2019, um artigo sobre o qual o TSDB deva ser usado consistirá em apenas uma frase: "basta usar o ClickHouse". Mas ... existem nuances.
De fato, o ClickHouse está se desenvolvendo ativamente, a base de usuários está crescendo e o suporte está sendo muito ativo, mas nos tornamos reféns do sucesso público do ClickHouse, que ofusca outras soluções possivelmente mais eficazes / confiáveis?
No início do ano passado, começamos a processar nosso próprio sistema de monitoramento, durante o qual surgiu a questão de escolher a base apropriada para o armazenamento de dados. Eu quero contar sobre a história dessa escolha aqui.
Declaração do problema
Primeiro de tudo, o prefácio necessário. Por que precisamos de nosso próprio sistema de monitoramento e como foi organizado?
Começamos a fornecer serviços de suporte em 2008 e, em 2010, ficou claro que era difícil agregar dados sobre processos que ocorrem na infraestrutura do cliente com as soluções existentes naquele momento (estamos falando, Deus me perdoe, Cacti, Zabbix e o nascente Grafite).
Nossos principais requisitos foram:
- suporte (na época - dezenas e no futuro - centenas) de clientes dentro do mesmo sistema e ao mesmo tempo a presença de um sistema centralizado de gerenciamento de alertas;
- flexibilidade no gerenciamento do sistema de alerta (encaminhamento de alertas entre atendentes, contabilidade de cronograma, base de conhecimento);
- a possibilidade de detalhes detalhados dos gráficos (o Zabbix naquela época estava desenhando gráficos na forma de figuras);
- armazenamento de longo prazo de uma grande quantidade de dados (um ano ou mais) e a capacidade de selecioná-los rapidamente.
Neste artigo, estamos interessados no último ponto.
Falando em armazenamento, os requisitos foram os seguintes:
- o sistema deve funcionar rapidamente;
- é desejável que o sistema tenha uma interface SQL;
- o sistema deve ser estável e ter uma base de usuários e suporte ativos (uma vez que enfrentamos a necessidade de oferecer suporte a sistemas como, por exemplo, o MemcacheDB, que paramos de desenvolver, ou o armazenamento distribuído MooseFS, cujo rastreador de erros foi realizado em chinês: repetindo esta história para o nosso projeto não quis);
- Correspondência para o teorema da PAC: Consitência (necessária) - os dados devem ser relevantes, não queremos que o sistema de gerenciamento de notificações não receba novos dados e cuspa alertas sobre a não chegada de dados para todos os projetos; Tolerância de partição (necessário) - não queremos obter sistemas de cérebro dividido; Disponibilidade (não crítica, no caso de uma réplica ativa) - podemos mudar para o sistema de backup em caso de acidente, com um código.
Curiosamente, naquela época o MySQL era a solução perfeita para nós. Nossa estrutura de dados era extremamente simples: identificação do servidor, contador, carimbo de data e hora e valor; a amostragem rápida de dados quentes foi fornecida por um grande buffer pool e a amostragem de dados históricos foi fornecida pelo SSD.
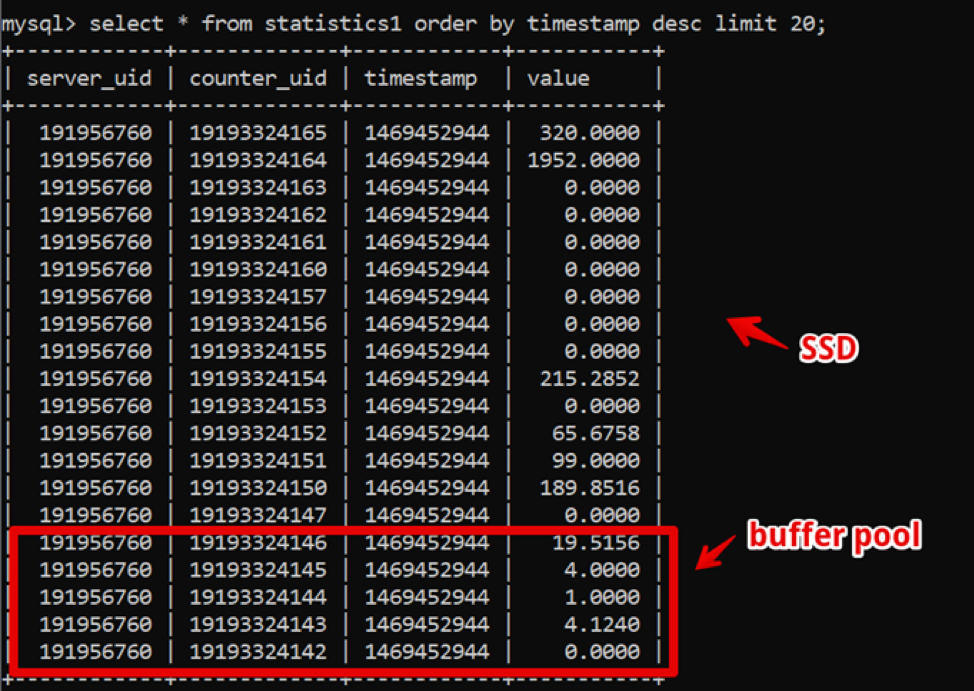
Assim, obtivemos uma amostragem de dados frescos de duas semanas, detalhando até um segundo de 200 ms antes que os dados fossem completamente renderizados e vivemos nesse sistema por algum tempo.
Enquanto isso, o tempo passou e a quantidade de dados aumentou. Em 2016, os volumes de dados atingiram dezenas de terabytes, o que em termos de armazenamento SSD alugado era uma despesa significativa.
Nesse ponto, os bancos de dados colunares estavam se espalhando ativamente, sobre os quais começamos a pensar ativamente: nos bancos de dados colunares, os dados são armazenados, como pode ser entendido, em colunas, e se você olhar para os nossos dados, é fácil ver um grande número de duplicatas que poderiam ser Se estiver usando um banco de dados de coluna, comprima com a compactação.
No entanto, o sistema principal do trabalho da empresa continuava funcionando de maneira estável, e eu não queria experimentar a transição para outra coisa.
Em 2017, na conferência Percona Live em San Jose, provavelmente a primeira vez que os desenvolvedores da Clickhouse se anunciaram. À primeira vista, o sistema estava pronto para produção (bem, o Yandex.Metrica é uma produção dura), o suporte era rápido e simples e, o mais importante, a operação era simples. Desde 2018, iniciamos o processo de transição. Mas, naquela época, havia muitos sistemas TSDB "adultos" e testados pelo tempo, e decidimos alocar um tempo considerável e comparar alternativas para garantir que não houvesse soluções alternativas da Clickhouse, de acordo com nossos requisitos.
Além dos requisitos de armazenamento já indicados, surgiram novos:
- o novo sistema deve fornecer pelo menos o mesmo desempenho que o MySQL, na mesma quantidade de ferro;
- o armazenamento do novo sistema deve ocupar significativamente menos espaço;
- O DBMS ainda deve ser fácil de gerenciar;
- Eu queria minimizar o aplicativo ao alterar o DBMS.
Quais sistemas começamos a considerar
Apache Hive / Apache ImpalaPilha de Hadoop agredida velha. De fato, essa é uma interface SQL criada com base no armazenamento de dados em formatos nativos no HDFS.
Pros.
- Com operação estável, é muito fácil dimensionar os dados.
- Existem soluções de coluna para armazenamento de dados (menos espaço).
- Execução muito rápida de tarefas paralelas na presença de recursos.
Contras
- Este é um Hadoop e é difícil de operar. Se não estamos prontos para tomar uma solução pronta na nuvem (e não estamos prontos para o custo), toda a pilha terá que ser montada e suportada pelos administradores, mas eu realmente não quero isso.
- Os dados são agregados muito rapidamente .
No entanto:

A velocidade é alcançada escalando o número de servidores de computação. Simplificando, se somos uma grande empresa envolvida em análises e negócios, é extremamente importante agregar informações o mais rápido possível (mesmo ao custo de usar um grande número de recursos de computação) - essa pode ser a nossa escolha. Mas não estávamos prontos para multiplicar o parque de ferro para acelerar as tarefas.
Druida / pinotJá há muito mais sobre o TSDB especificamente, mas novamente - Hadoop-stack.
Há um
ótimo artigo comparando os prós e contras de Druid e Pinot em comparação ao ClickHouse .
Em poucas palavras: Druid / Pinot parece melhor que Clickhouse nos casos em que:
- Você tem uma natureza heterogênea dos dados (no nosso caso, registramos apenas séries temporais de métricas de servidor e, de fato, essa é uma tabela. Mas pode haver outros casos: séries temporais de equipamentos, séries econômicas etc. - cada um com sua própria estrutura, que devem ser agregados e processados).
- Além disso, existem muitos desses dados.
- As tabelas e os dados com séries temporais aparecem e desaparecem (ou seja, algum tipo de conjunto de dados entrou, foi analisado e excluído).
- Não há um critério claro pelo qual os dados possam ser particionados.
Em casos opostos, o ClickHouse se mostra melhor, e esse é o nosso caso.
Clickhouse- Como SQL.
- Fácil de gerenciar.
- As pessoas dizem que isso funciona.
Ele se enquadra na lista restrita de testes.
InfluxdbAlternativa estrangeira ao ClickHouse. Das desvantagens: a alta disponibilidade está presente apenas na versão comercial, mas deve ser comparada.
Ele se enquadra na lista restrita de testes.
CassandraPor um lado, sabemos que é usado para armazenar séries temporais métricas por sistemas de monitoramento como, por exemplo,
SignalFX ou OkMeter. No entanto, existem detalhes.
Cassandra não é um banco de dados de colunas no sentido usual. Parece mais uma letra minúscula, mas cada linha pode ter um número diferente de colunas, devido ao qual é fácil organizar uma representação de coluna. Nesse sentido, é claro que, com um limite de 2 bilhões de colunas, é possível armazenar alguns dados nas colunas (sim, a mesma série temporal). Por exemplo, no MySQL, há um limite para 4096 colunas e é fácil encontrar um erro com o código 1117 se você tentar fazer o mesmo.
O mecanismo Cassandra está focado em armazenar grandes quantidades de dados em um sistema distribuído sem um assistente, e no teorema do CAP mencionado acima, Cassandra é mais sobre AP, ou seja, sobre acessibilidade de dados e resistência ao particionamento. Portanto, essa ferramenta pode ser ótima se você precisar apenas gravar neste banco de dados e raramente ler a partir dele. E aqui é lógico usar o Cassandra como um armazenamento "frio". Ou seja, como um local confiável a longo prazo para armazenar grandes quantidades de dados históricos que raramente são necessários, mas que podem ser obtidos se necessário. No entanto, por uma questão de integridade, vamos testá-lo. Mas, como eu disse anteriormente, não há desejo de reescrever ativamente o código da solução de banco de dados selecionada, portanto, vamos testá-lo um pouco limitado - sem adaptar a estrutura do banco de dados às especificações do Cassandra.
PrometeuBem, e sem interesse, decidimos testar o desempenho da loja Prometheus - apenas para entender se somos mais rápidos do que as soluções atuais ou mais lentos e quanto.
Metodologia e Resultados dos Testes
Portanto, testamos 5 bancos de dados nas 6 configurações a seguir: ClickHouse (1 nó), ClickHouse (tabela distribuída de 3 nós), InfluxDB, Mysql 8, Cassandra (3 nós) e Prometheus. O plano de teste é o seguinte:
- preencher os dados históricos da semana (840 milhões de valores por dia; 208 mil métricas);
- gerar uma carga de gravação (foram considerados 6 modos de carga, veja abaixo);
- paralelamente à gravação, periodicamente fazemos amostras, simulando as solicitações de um usuário que trabalha com gráficos. Para não complicar muito as coisas, selecionamos os dados em 10 métricas (da mesma forma que no gráfico da CPU) por semana.
Carregamos emulando o comportamento do nosso agente de monitoramento, que envia valores para cada métrica a cada 15 segundos. Nesse caso, estamos interessados em variar:
- número total de métricas nas quais os dados são gravados;
- intervalo de envio de valores em uma métrica;
- tamanho do lote.
Sobre o tamanho do lote. Como quase todas as nossas bases experimentais não são recomendadas para serem carregadas com inserções únicas, precisaremos de um relé que colete as métricas recebidas e as agrupe o máximo possível e as grave no banco de dados com uma inserção de pacote.
Além disso, para entender melhor como interpretar os dados recebidos posteriormente, imagine que não estamos apenas enviando várias métricas, mas as métricas são organizadas em servidores - 125 métricas por servidor. Aqui, o servidor é apenas uma entidade virtual - apenas para entender que, por exemplo, 10.000 métricas correspondem a aproximadamente 80 servidores.
E assim, levando tudo isso em consideração, nossos 6 modos de carregamento de gravação da base:
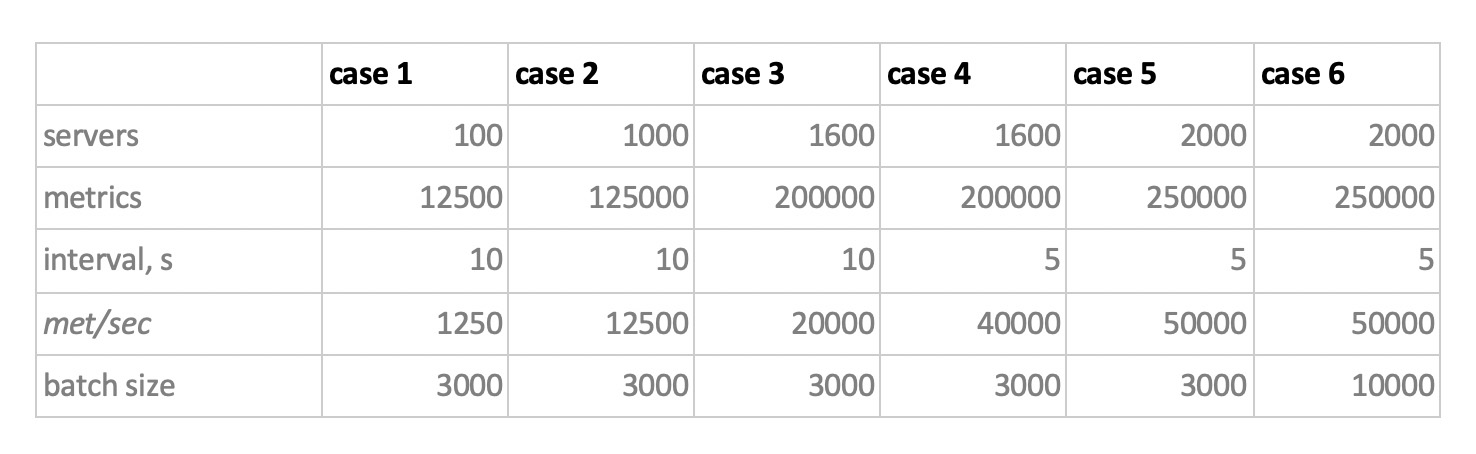
Existem dois pontos. Em primeiro lugar, para cassandra tais tamanhos de lotes eram muito grandes, foram utilizados valores de 50 ou 100. Em segundo lugar, uma vez que o prometeus funciona estritamente no modo pull, ou seja, ele caminha e coleta dados de fontes métricas (e mesmo o pushgateway, apesar do nome, não altera fundamentalmente a situação), as cargas correspondentes foram implementadas usando uma combinação de configurações estáticas.
Os resultados do teste são os seguintes:
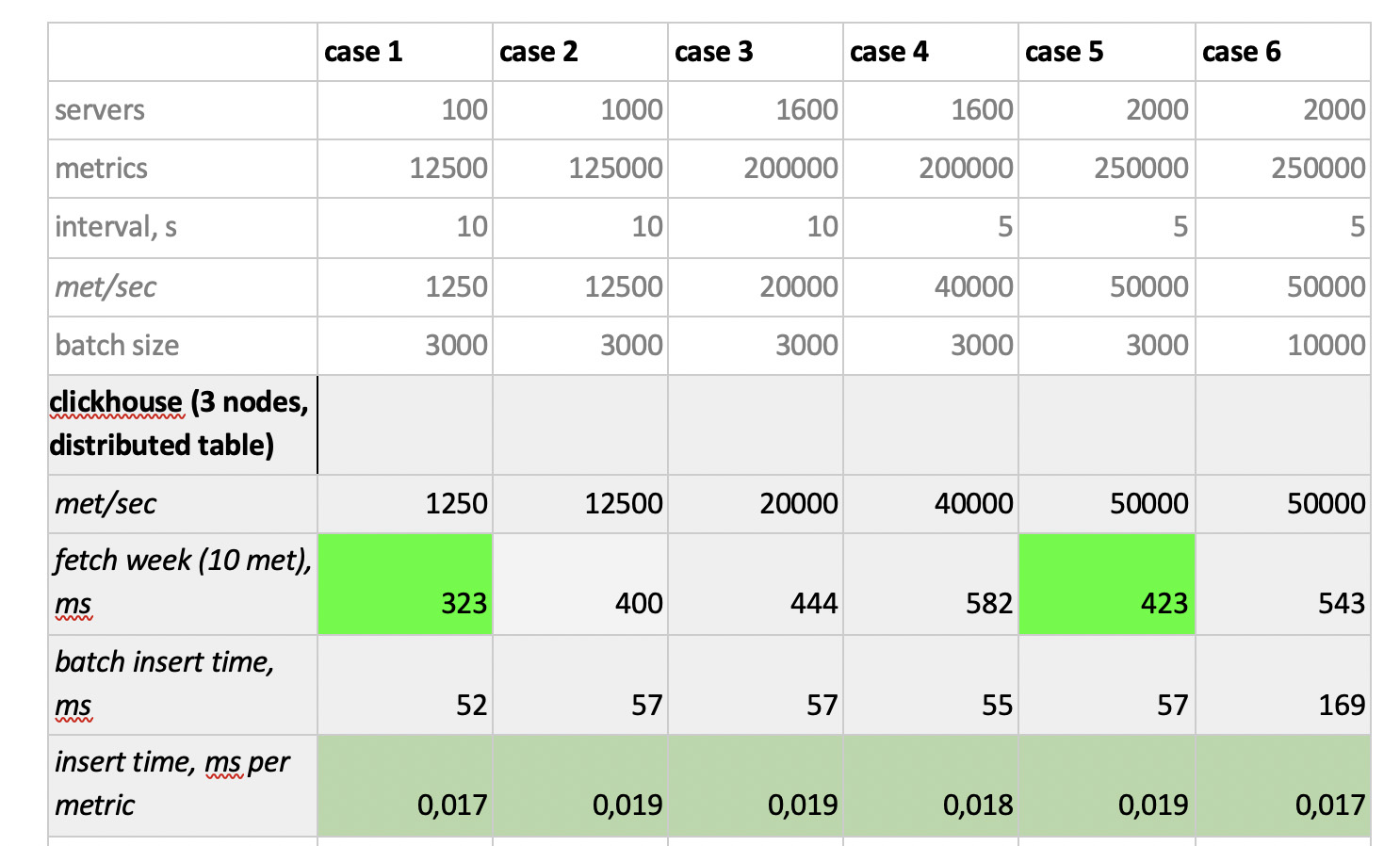
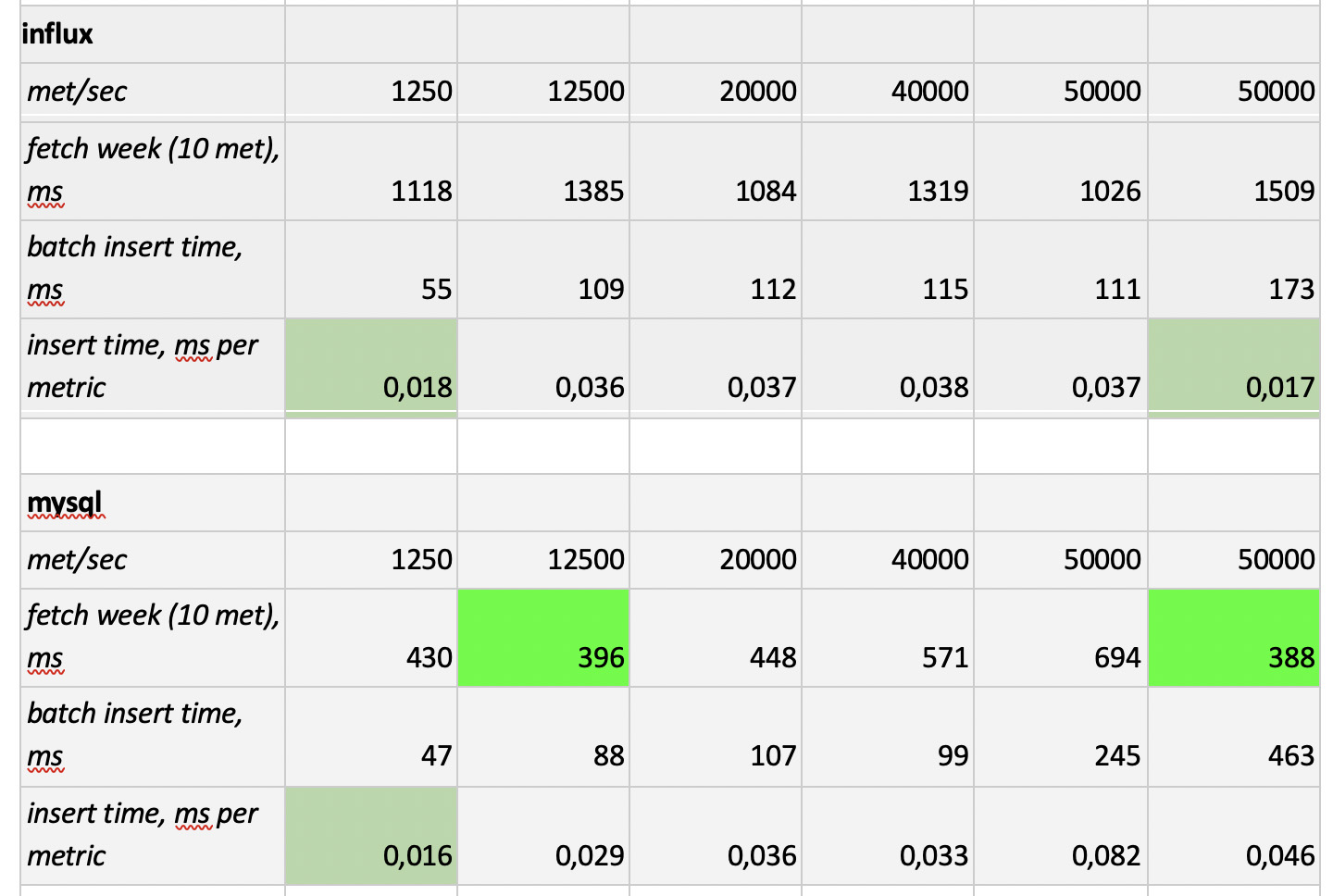
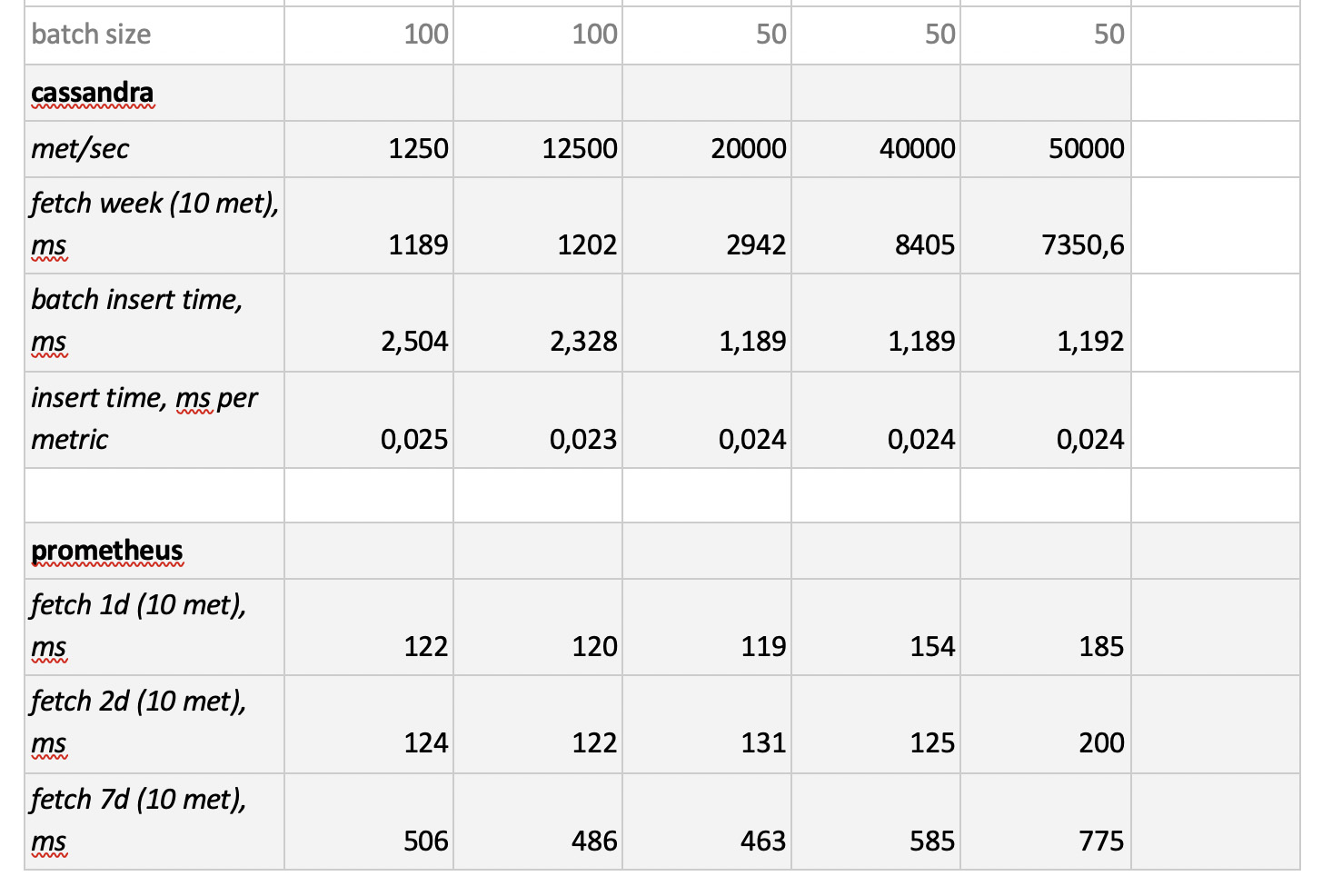 O que vale a pena notar
O que vale a pena notar : amostras fantasticamente rápidas de Prometheus, amostras terrivelmente lentas de Cassandra, amostras inaceitavelmente lentas de InfluxDB; O ClickHouse venceu em termos de velocidade de gravação e o Prometheus não participa da competição, porque insere dentro de si e não medimos nada.
Como resultado : o ClickHouse e o InfluxDB se mostraram o melhor de todos, mas um cluster do Influx só pode ser construído com base na versão Enterprise, que custa dinheiro, e o ClickHouse não custa nada e é fabricado na Rússia. É lógico que, nos EUA, a escolha provavelmente seja a favor do inInfluxDB e, no nosso caso, a favor do ClickHouse.