Este é um resumo em inglês de dois artigos absolutamente notáveis, escritos por
Vitaliy Malkin de "Informzashita", cuja equipe, True0xA3, se tornou a vencedora da prestigiada competição de chapéu preto The Standoff durante o
Positive Hack Days 9 em maio de 2019.
Vitaliy publicou três artigos detalhados sobre o Habr, dois dos quais dedicados à descrição das estratégias que a equipe True0xA3 usou antes e durante a competição para garantir a esta equipe o título dos vencedores. Senti que a única coisa que faltava nesses dois artigos era um resumo em inglês para que um público mais amplo de leitores pudesse apreciá-los. Então, abaixo está o resumo de dois artigos de
Vitaliy Malkin , juntamente com imagens que Vitaliy publicou para esclarecer seus pontos. Vitaliy me deu permissão para fazer a tradução e publicá-la.
PARTE I. Preparando-se para a batalha
Artigo original está aquiI. Objetivos iniciais
A equipe consistia em 16 defensores testados e comprovados e 4 estagiários, armados com 6 servidores e nossa própria estação CUDA, além da disposição de percorrer a distância.
Os preparativos ativos começaram 8 dias antes do início do The Standoff. Esta foi a nossa terceira tentativa de vencer o Standoff, então alguns de nós tiveram experiência suficiente para saber o que precisava ser feito. Desde o início, discutimos as seguintes prioridades para a equipe:
- Coordenação suave entre os membros da equipe
- Coleta de frutas baixas
- Exploração de vulnerabilidades não típicas para nós, como Sistemas de Controle de Processo Automatizado (APCS), Sistemas de Controle Distribuído (DCS), IoT, GSM
- Configurando nossa própria infraestrutura e equipamentos com antecedência
- Desenvolvendo alguma estratégia para persistência e fortalecimento
Coordenação:
Esta é a fraqueza de todos os novatos no Standoff: as tarefas não estão sendo distribuídas de maneira eficaz; várias pessoas estão trabalhando na mesma tarefa; não está claro quais tarefas já foram concluídas; os resultados de uma tarefa não são encaminhados aos membros apropriados da equipe etc. Quanto maior a equipe, menos eficaz é a coordenação entre os membros da equipe. Mais importante, deve haver pelo menos uma pessoa que entenda toda a visão do ponto de vista da infraestrutura e que possa reunir várias vulnerabilidades em um vetor de ataque focado.
Este ano, usamos a plataforma de colaboração Discord. É semelhante ao bate-papo com IRC, mas com recursos adicionais, como upload de arquivos e chamadas de voz. Para cada destino no mapa Standoff, criamos um canal separado no qual todos os dados seriam coletados. Dessa forma, um novo membro da equipe atribuído a uma tarefa pode ver facilmente todas as informações que já foram reunidas para essa tarefa, os resultados das implantações etc. Todos os canais informativos tinham um limite de 1 mensagem por minuto para evitar inundações. Cada objeto no Standoff tinha seu próprio espaço de bate-papo dedicado.
Cada membro da equipe recebeu um escopo de trabalho claramente definido. Para melhorar a coordenação, uma pessoa foi designada para tomar decisões finais em todas as tarefas. Isso nos impediu de entrar em longas discussões e desacordos durante a competição.
Coleta de frutas baixas
Acredito que o fator mais importante no jogo acabou sendo a capacidade de gerenciar vários projetos e priorizar adequadamente os objetivos. No jogo do ano passado, fomos capazes de assumir um escritório e ficar lá simplesmente porque usamos vulnerabilidades conhecidas. Este ano, decidimos fazer uma lista dessas vulnerabilidades com antecedência e organizar nosso conhecimento:
ms17-010; ms08-67; SMBCRY LibSSH RCE; Protectoer HP DATA; HP iLo; ipmi Instalação inteligente da Cisco Java RMI JDWP; JBOSS; drupalgeddon2; weblogic com coração shellshock; ibm websphere iis-webdav; serviços; vnc; ftp-anon; NFS smb-null; TomcatEm seguida, criamos dois serviços, verificador e penetrador, que automatizaram o teste de vulnerabilidades e a implantação das explorações e metasploits publicamente disponíveis. Os serviços utilizaram os resultados do nmap para agilizar nosso trabalho.
Exploração de vulnerabilidades não típicas para nós
Não tínhamos muita experiência com a análise de vulnerabilidades dos Sistemas de Controle Automatizado de Processos (APCS). Aproximadamente oito dias antes do impasse, começamos a investigar o assunto. A situação com IoT e GSM foi ainda pior. Nunca tivemos experiência com esses sistemas fora dos impasses anteriores.
Portanto, na fase de preparação, selecionamos duas pessoas para estudar os Sistemas de Controle de Processo Automatizado (APCS) e mais duas para estudar GSM e IoT. A primeira equipe, em uma semana, criou uma lista de abordagens típicas para reprovar os sistemas SCADA e estudou em detalhes os vídeos da infraestrutura do ano anterior no Standoff. Eles também baixaram aproximadamente 200 GB de vários HMI, drivers e outros softwares relacionados aos controladores. A equipe da IoT preparou algum hardware e leu todos os artigos disponíveis sobre GSM. Esperávamos que fosse o suficiente (alerta de spoiler: não era!)
Configurando nossa própria infraestrutura e equipamentos
Como tínhamos uma equipe muito grande, decidimos que precisaríamos de equipamento adicional. Isto é o que levamos conosco:
- Servidor CUDA
- Laptop de backup
- Roteador wifi
- Switch
- Variedade de cabos de rede
- WiFi Alfa
- Patinhos de borracha
No ano passado, entendemos a importância do uso de servidores CUDA durante a invasão de alguns handshakes. É importante observar que este ano, assim como nos anos anteriores, todos os teamers vermelhos estavam por trás de um NAT, portanto não pudemos usar conexões reversas da DMZ. No entanto, presumimos que todos os hosts, exceto o APCS (Automated Process Control Systems), tivessem uma conexão com a Internet. Com isso em mente, decidimos criar 3 ouvintes de servidor disponíveis na Internet. Para facilitar a rotação, usamos nosso próprio servidor OpenVPN com o cliente para cliente ativado. Infelizmente, a criação automatizada de canais não foi possível; portanto, por 12 horas em 28, um dos membros da equipe foi dedicado apenas ao gerenciamento dos canais.
Desenvolvendo alguma estratégia para persistência e fortalecimento
Nossa experiência anterior com o Standoff já nos ensinou que não bastava assumir um cargo. Era igualmente importante impedir que outras equipes também se firmassem. Portanto, passamos um tempo significativo no RAT (Ferramenta de Administração Remota) com novas assinaturas e scripts para proteger os sistemas Windows. Usamos um RAT padrão, mas alteramos ligeiramente o método de ofuscação. As regras apresentaram uma dificuldade maior. No geral, desenvolvemos a seguinte lista de scripts:
- Fechando as portas SMB (bloco de mensagens do servidor) e RPC (chamada de procedimento remoto)
- Movendo o RDP (protocolo de área de trabalho remota) para portas não padrão
- Desativando criptografia reversível, contas de convidado e outros problemas típicos da linha de base de segurança
Para sistemas Linux, desenvolvemos um script init especial que fechava todas as portas, movia o SSH para uma porta não padrão e criava chaves públicas para o acesso da equipe ao SSH
II Briefing
Em 17 de maio, 5 dias antes do impasse, os organizadores forneceram o briefing para as equipes vermelhas. Eles forneceram muitas informações que afetaram nossa preparação. Eles publicaram o mapa da rede, o que nos permitiu dividir a rede em zonas e atribuir responsabilidades para cada zona a um membro da equipe. A informação mais importante que os organizadores forneceram foi que o APCS seria acessível apenas a partir de um segmento da rede e esse segmento não está protegido. Além disso, divulgou que os pontos mais altos serão concedidos para o APCS e para os escritórios garantidos. Eles também disseram que recompensariam a capacidade das equipes vermelhas de se derrubarem da rede.
Nós interpretamos isso como o seguinte: "Quem capturar o grande grupo provavelmente vencerá o jogo". Isso ocorre porque nossa experiência anterior nos ensinou que, não importa como os organizadores penalizem a perda de serviço, as equipes azuis matarão os servidores vulneráveis se não puderem corrigi-los com rapidez suficiente. Isso ocorre porque suas respectivas empresas estão muito mais preocupadas com publicidade de um sistema totalmente hackeado do que com alguns pontos perdidos em um jogo. Nosso palpite estava correto, como veremos em breve.
Portanto, decidimos dividir a equipe em 4 partes:
I. Biggrogroup . Decidimos priorizar essa tarefa acima de todas as outras, por isso colocamos nossos pentesters mais experientes nesse grupo. Essa mini-equipe era composta por 5 pessoas, e seu principal objetivo era dominar o domínio e impedir que outras equipes obtivessem acesso ao APCS.
II Redes sem fio . Essa equipe foi responsável por assistir ao Wifi, rastrear novos WAPs, capturar os apertos de mão e forçá-los com força bruta. Eles também eram responsáveis pelo GSP, mas seu principal objetivo era impedir que outras equipes assumissem o Wifi.
III Redes desprotegidas . Essa equipe passou as primeiras 4 horas testando todas as redes desprotegidas e analisando vulnerabilidades. Entendemos que nas primeiras 4 horas nada de interesse poderia acontecer nos segmentos protegidos, pelo menos nada que as equipes azuis não pudessem derrubar; portanto, decidimos passar essas primeiras horas protegendo as redes desprotegidas, onde as coisas poderiam ser mudadas. E, como se viu, foi uma boa abordagem.
IV Grupo de scanners . As equipes azuis nos informaram antecipadamente que a topologia da rede mudaria constantemente; portanto, dedicamos duas pessoas à varredura da rede e à detecção de alterações. A automação desse processo acabou sendo difícil, pois tínhamos várias redes com várias configurações. Por exemplo, na primeira hora, nosso nmap funcionava no modo T3, mas ao meio-dia mal funcionava no modo T1.
Outro vetor importante foi a lista do software e das tecnologias que os organizadores forneceram durante o briefing. Criamos um grupo de competências para cada uma das tecnologias que podem avaliar rapidamente as vulnerabilidades típicas. Para alguns serviços, encontramos vulnerabilidades conhecidas, mas não conseguimos encontrar explorações publicadas. Este foi, por exemplo, um caso com o RCE pós-exploração Redis. Tínhamos certeza de que essa vulnerabilidade estaria presente na infraestrutura do Standoff; portanto, decidimos escrever nossa própria exploração de 1 dia. Obviamente, não conseguimos escrever a exploração inteira, mas no geral reunimos 5 explorações não publicadas que estávamos prontas para implantar.
Infelizmente, não conseguimos investigar todas as tecnologias, mas acabou não sendo tão crítico. Como examinamos as de prioridade mais alta, isso acabou sendo suficiente. Também preparamos a lista de controladores para o APCS, que também investigamos em detalhes.
Durante a fase de preparação, reunimos várias ferramentas para a conexão clandestina à rede APCS. Por exemplo, preparamos uma versão barata de um abacaxi usando uma framboesa. Ele se conectaria à Ethernet da rede de produção e via GSM ao serviço de controle. Poderíamos então configurar remotamente uma conexão Ethernet e depois transmiti-la através de um módulo wifi embutido. Infelizmente, durante o jogo, os organizadores deixaram claro que a conexão física com o APCS seria proibida, portanto, acabamos não sendo capazes de usar o módulo.
Encontramos muitas informações sobre o trabalho do banco, contas offshore e antifraude. No entanto, também descobrimos que o banco não tinha muito dinheiro, então decidimos não gastar tempo se preparando para esse objeto e apenas jogá-lo de ouvido durante o jogo.
Em resumo, fizemos um pouco de trabalho durante a fase de preparação. Gostaria de observar que, além do óbvio benefício de sermos os vencedores da competição Standoff, obtivemos benefícios menos perceptíveis, mas não menos importantes, como
- Fizemos uma pausa nas minúcias diárias do trabalho e tentamos algo que há muito esperávamos fazer
- Esta foi a nossa primeira experiência em que toda a equipe de teste estava trabalhando em uma única tarefa; portanto, o efeito de formação de equipe foi muito visível
- Muitas informações que reunimos durante a preparação do jogo que podemos usar para nossos projetos de pentest na vida real, aumentamos nosso nível de competência e criamos novas ferramentas prontas para uso
Olhando para trás, estou percebendo que nossa vitória no Standoff provavelmente foi garantida muito antes do início do jogo, durante a fase de preparação. Agora, o que realmente aconteceu durante o Standoff será descrito na Parte II desta série
Parte II Vencendo o impasse. Compartilhando a vida
O artigo original está aquiDe Vitaliy Malkin, o chefe da equipe vermelha da empresa InformZachita e o capitão da equipe True0xA3. True0xA3 venceu uma das competições de chapéu branco mais prestigiadas da Rússia - o Standoff na PHDays 2019.
Primeiro dia
9:45 MSKO dia começou recebendo os resultados do MassScan. Começamos listando todos os hosts com 445 portas abertas e, exatamente às 10h, implantamos o verificador para o metasploit MS17-010. De acordo com nosso plano, nosso principal objetivo era capturar o controlador de domínio do grande grupo de domínios; portanto, duas pessoas de nossa equipe foram dedicadas apenas a isso. Abaixo, você verá as atribuições iniciais de cada grupo.
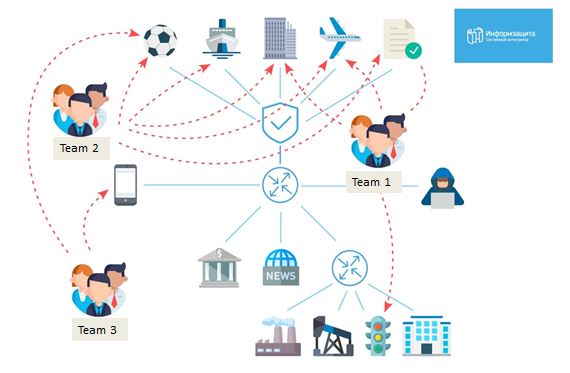
Como você pode ver, tentamos penetrar em todos os escritórios do jogo, e o fato de termos 20 pessoas estava fazendo uma grande diferença.
10:15Um dos membros da equipe da Team1 encontra um host no domínio bigbrogroup.phd, vulnerável ao MS17-010. Implementamos a exploração com muita pressa. Há alguns anos, tivemos a situação em que conseguimos levar o shell meterpreter (ataque de phishing com o código de execução remota) a um alvo importante, mas fomos expulsos em 10 segundos. Este ano estávamos mais preparados. Assumimos o controle do host, fechamos a porta SMB e alteramos o RDP para a porta 50002. Estamos prestando muita atenção ao processo de persistência no domínio, portanto, criamos algumas contas de administrador local e implantamos nossas próprias Ferramentas de Administração Remota (RAT) . Somente depois disso passamos para a próxima tarefa
10:25Continuamos analisando os resultados das informações que coletamos do host. Além do acesso à rede interna e da conexão com o controlador de domínio, também encontramos o token do administrador do domínio. Antes de ficarmos muito animados com isso, verificamos se o token ainda é válido. E então nos alegramos. O primeiro domínio caiu. O tempo total gasto é de 27 min 52 segundos
Meia hora após o início, visitamos o portal do jogador para entender as regras de entrega de bandeiras e pontos de recebimento. Vemos a lista padrão: os logins de administrador do domínio, administradores locais, administradores de troca e alguns outros administradores. Do domínio, baixamos o ntds.dit e, ao mesmo tempo, preparamos nossa estação CUDA. Então descobrimos que a criptografia reversível é essa no domínio, para que agora possamos obter todas as senhas necessárias. Para entender quais senhas precisamos, formamos uma equipe de 2 pessoas que começam a analisar a estrutura do AD e seus grupos. 5 minutos depois, eles entregam os resultados. Nós entregamos nossas bandeiras e esperamos. Já era hora de pegar nosso Primeiro Sangue, pelo menos para aumentar o moral da equipe, se nada mais. Mas nada. Demoramos uma hora tentando entender que o verificador funciona assim:
- É automatizado
- Tem um formato muito inflexível
- Se você ativar suas bandeiras na verificação e não receber uma resposta em alguns segundos, seu formato não corresponderá ao formato do verificador
Finalmente, descobrimos o formato certo e, por volta das 11 horas, recebemos o nosso primeiro sangue. Ufa!
11:15A equipe 1 está sendo dividida em duas subequipes. A subequipe 1 continua fortalecendo o domínio: eles obtêm o krbtgt, fortalecem a linha de base e alteram senhas para os serviços de diretório. Os organizadores do Standoff nos disseram durante o briefing que os primeiros no domínio tocam como querem. Então, alteramos as senhas de administrador para que, mesmo que alguém entre e consiga nos expulsar, não será possível fazer com que os logins entreguem suas bandeiras por pontos.
A equipe 2 continua investigando a estrutura do domínio e encontra outro sinalizador. Na área de trabalho do CFO, eles encontram um relatório financeiro. Infelizmente, é compactado e protegido por senha. Então, ligamos a estação CUDA. Transformamos o zip em um hash e o enviamos para o hashcat.
A equipe 2 continua a encontrar serviços interessantes com o RCE (execução remota de código) e começa a analisá-los. Um deles é um serviço de monitoramento para o domínio cf-media construído na base do Nagios. Outro é o gerente de programação de uma companhia de navegação construída com base em uma tecnologia estranha que nunca vimos antes. Existem também alguns serviços interessantes, como conversores DOC para DPF.
A segunda subequipe da equipe 1 já começou a trabalhar no banco e encontrou um banco de dados interessante no MongoDB, que contém, entre muitas outras coisas, o nome da nossa equipe e de outras equipes e seus saldos. Alteramos o saldo da nossa equipe para 50 milhões e seguimos em frente.
14:00A sorte nos deixou. Primeiro, os dois serviços para os quais tínhamos RCE nos segmentos protegidos ficaram indisponíveis. A equipe azul simplesmente os desligou. Obviamente, reclamamos com os organizadores sobre violações das regras, mas sem efeito. No impasse, não há processos de negócios para proteger! Segundo, não conseguimos encontrar uma lista de clientes. Suspeitamos que ele esteja oculto em algum lugar nas profundezas de 1C, mas não temos bancos de dados, nem arquivos de configuração. Beco sem saída.
Estamos tentando configurar o canal VPN entre nossos servidores remotos e os Sistemas de controle de processo automatizados (APCS). Por alguma estranha razão, não fazemos isso no controlador de domínio do bigbrogroup, e a conexão entre as interfaces é interrompida. Agora o controlador de domínio não está acessível. A parte da equipe responsável pelo acesso ao domínio quase sofre um ataque cardíaco. A tensão entre os membros da equipe aumenta e começa a apontar com os dedos.
Então percebemos que o controlador de domínio está acessível, mas a conexão VPN é instável. Retrocedemos cuidadosamente em nossas etapas, via RDP, desligamos a VPN e pronto, o controlador de domínio está acessível novamente. A equipe exala coletivamente. No final, configuramos a VPN a partir de outro servidor. O controlador de domínio está sendo tratado e mimado. Todas as equipes concorrentes ainda têm 0 pontos, e isso é tranquilizador.
16:50Os organizadores finalmente publicam um mineiro. Usando psexec, configuramos em todos os pontos de extremidade que controlamos. Isso traz um pouco de fluxo de renda estável.
A equipe 2 ainda está trabalhando na vulnerabilidade do Nagios. Eles têm a versão com vulnerabilidade
<= 5.5.6 CVE-2018-15710 CVE-2018-15708. Uma exploração pública está disponível, mas é necessária uma conexão reversa para baixar o shell da web. Como estamos por trás do NAT, temos que reescrever a exploração e dividi-la em duas partes. A primeira parte força o Nagios a se conectar ao nosso servidor remoto via Internet, e a segunda parte, localizada no próprio servidor, fornece ao Nagios o shell da web. Isso nos dá acesso via proxy ao domínio cf-media. Mas a conexão é instável e difícil de usar, por isso decidimos vender a exploração pelos dólares do BugBounty, enquanto tentamos elevar nosso acesso ao root.
18:07Aí vêm as prometidas "surpresas" dos organizadores. Eles anunciam que o BigBroGroup acabou de comprar CF-media. Não estamos terrivelmente surpresos. Durante nossa investigação do domínio de grandes grupos, notamos as relações de confiança entre os domínios de grandes grupos e cf-media.
No momento em que a aquisição da mídia CF foi anunciada, ainda não tínhamos conexão com a rede deles. Mas após o anúncio, o acesso apareceu. Isso nos salvou de girar as rodas tentando girar a partir de Nagios. As credenciais do Bigbrogroup funcionam no domínio cf-media, mas os usuários não têm privilégios. Ainda não foram encontradas vulnerabilidades facilmente exploráveis, mas estamos bastante otimistas de que algo irá aparecer.
18:30De repente, somos expulsos do domínio dos grandes grupos. Por quem? Como Parece que a equipe TSARKA é a culpada! Eles estão alterando a senha do administrador, mas temos outras 4 contas de administrador nas reservas. Mudamos a senha de administrador do domínio novamente, redefinimos todas as senhas. Mas minutos depois somos expulsos novamente! Naquele exato momento, encontramos um vetor no domínio cf-media. Em um de seus servidores, o nome de usuário e a senha correspondem aos que encontramos anteriormente no domínio do grande grupo. Oh, reutilização de senha! O que faríamos sem você? Agora só precisamos de um hash. Usamos hashkiller e obtemos a senha P @ ssw0rd. Seguindo em frente.
19:00A luta pelo controle do grupo de lances está se tornando um problema sério. TSARKA mudou a senha para krbtgt duas vezes, perdemos todas as contas de administrador ... o que vem a seguir? Beco sem saída?
19:30Finalmente obtemos os privilégios de administrador de domínio no cf-media e começamos a exibir nossas bandeiras. Apesar do fato de ser um domínio seguro, vemos a criptografia reversível. Portanto, agora temos os logins e senhas e prosseguimos com as mesmas etapas do grupo grande. Criamos administradores adicionais, fortalecemos nossa posição, fortalecemos a linha de base, alteramos senhas, criamos uma conexão VPN. Encontramos um segundo relatório financeiro, também como um zip protegido. Verificamos com a equipe responsável pelo primeiro relatório. Eles conseguiram brutalidade, mas os organizadores não aceitarão. Acontece que ele precisava ser entregue como um 7zip protegido! Então, nós nem tivemos que fazer isso! 3 horas de trabalho por nada.
Entregamos ambos os relatórios como arquivos 7zip protegidos. Até agora, nosso saldo total é de 1 milhão de pontos, e a TSARKA tem 125.000, e eles estão começando a exibir suas bandeiras do domínio dos grandes grupos. Percebemos que temos que impedi-los de virar suas bandeiras, mas como?
19:30Nós encontramos uma solução! Ainda temos as credenciais dos administradores locais. Efetuamos login, assumimos o ticket e simplesmente desligamos o controlador de domínio. O controlador está desligando. Fechamos todas as portas do servidor, exceto o RDP, e alteramos as senhas de todos os nossos administradores locais. Agora estamos no nosso pequeno espaço e eles estão no deles. Se apenas a conexão VPN permaneceria estável! A equipe exala coletivamente.
Enquanto isso, configuramos mineradores em todos os pontos de extremidade no domínio cf-media. A TSARKA está à nossa frente no volume geral, mas não estamos muito atrás e temos mais potência.
Noite
Aqui você pode ver as alterações que fizemos na equipe durante a noite.

Alguns membros da equipe precisam sair para passar a noite. À meia-noite, reduzimos para 9 pessoas. A produtividade cai para quase zero. A cada hora nos levantamos para lavar o rosto com água e sair para tomar um ar, apenas para sacudir a sonolência.
Agora, finalmente, estamos chegando aos Sistemas de Controle de Processo Automatizado (APCS)
02.00As últimas horas foram muito desanimadoras. Encontramos vários vetores, mas eles já estão fechados. Não podemos dizer se eles estavam fechados para começar ou se TSARKA já esteve aqui. Estudando lentamente o APCS, encontramos um controlador NetBus vulnerável. Usamos um módulo metasploit que não entendemos completamente como ele funciona. De repente, as luzes da cidade se apagam. Os organizadores anunciam que contarão isso se pudermos acender a luz novamente. Nesse momento, nossa VPN cai. O servidor que gerencia a VPN foi assumido pelo TSARKA! Parece que estávamos discutindo o APCS muito alto e eles conseguiram assumir o controle.
03,30Até os mais dedicados de nós estão começando a cochilar. Apenas 7 ainda estão trabalhando. De repente, sem nenhuma explicação, a VPN está de volta. Repetimos rapidamente o truque com as luzes da cidade e vemos nosso saldo subir 200.000 pontos !!!
Uma parte da equipe ainda está procurando vetores adicionais, enquanto outra está trabalhando no APCS. Lá encontramos duas vulnerabilidades adicionais. Um deles somos capazes de explorar. Mas o resultado da exploração pode ser uma reescrita do firmware do microcontrolador. Discutimos isso com os organizadores e decidimos que esperaremos o restante de nossa equipe se juntar a nós pela manhã e depois decidiremos coletivamente o que fazer.
05:30Nossa VPN funciona cerca de 10 minutos a cada hora e, em seguida, desconecta novamente. Nesse período, tentamos trabalhar. Mas a produtividade está próxima de zero. Eventualmente, decidimos tirar uma hora cada uma para tirar uma soneca. Alerta de spoiler - má ideia!
5 pessoas ainda estão trabalhando no APCS.
Manhã
De manhã, de repente percebemos que estamos à frente de outras equipes em quase 1 milhão de pontos. A TSARKA conseguiu entregar duas bandeiras da APCS, além de várias bandeiras do provedor de telecomunicações e do grande grupo. Além disso, eles têm mineradores trabalhando e precisam ter alguma criptografia que ainda não entregaram. Estimamos que eles tenham um mínimo de 200 a 300 mil pontos a mais em criptografia. Isso é enervante. Temos a sensação de que eles podem ter mais algumas bandeiras que estão segurando estrategicamente até as horas finais. Mas nossa equipe está voltando online. A verificação do som da manhã na arena principal é um pouco chata, mas afugenta o sono.
Ainda estamos trabalhando para tentar entrar no APCS, mas a esperança está diminuindo. A diferença de pontos entre o primeiro e o segundo time e o restante dos times é gigantesca. Estamos preocupados que os organizadores decidam lançar mais algumas "surpresas" para agitar as coisas.
Após uma conferência de imprensa com a TSARKA na arena principal, decidimos mudar nossa estratégia de "obter mais bandeiras" para "impedir que a TSARKA gire mais bandeiras".
Em um de nossos servidores, acionamos Caim e Abel e redirecionamos todo o tráfego para o nosso servidor. Encontramos algumas VPNs do Cazaquistão e as matamos. Depois, decidimos eliminar todo o tráfego em qualquer lugar, por isso criamos um firewall local no canal VPN para eliminar todo o tráfego na rede APCS. É assim que você protege um APCS! Os organizadores agora estão reclamando que perderam a conexão com o APCS. Abrimos o acesso a seus endereços IP (NÃO é assim que você protege o APCS).
12:47Estávamos certos em nos preocupar com os organizadores tentando agitar as coisas. Do nada, existe um despejo de dados contendo 4 logins para cada domínio. Mobilizamos toda a equipe.
Objetivos:
Equipe 1 : domine imediatamente todos os segmentos protegidos.
Equipe 2 : use o Outlook Web Access para alterar todas as senhas para os logons.
Algumas equipes azuis, sentindo muita atividade, simplesmente desligam a VPN. Outros são mais complicados e alteram o idioma do sistema para chinês. Tecnicamente, o serviço ainda está ativo! Mas é claro que, na prática, não é utilizável (organizadores, preste atenção!). Via VPN, podemos conectar a 3 das redes. Em um deles, duramos apenas 1 minuto antes de sermos expulsos.
 12:52
12:52Localizamos um servidor não saudável com a vulnerabilidade MS17-010 (supostamente um segmento protegido?). Nós o exploramos rapidamente, sem encontrar resistência. Obtemos o hash do administrador do domínio e, via Pth, acessamos o controlador de domínio. E adivinhe o que encontramos lá? Criptografia reversível!
Quem estava protegendo esse segmento não fez sua lição de casa. Coletamos todas as bandeiras, exceto a parte relacionada a 1C. Há uma boa chance de conseguirmos isso se passarmos mais 30 a 40 minutos lá, mas decidimos simplesmente desativar o controlador de domínio não saudável. Quem precisa de concorrência?
13:20Nós entregamos nossas bandeiras. Agora temos 2.900.000 pontos, além de algumas recompensas pendentes. TSARKA tem pouco mais de 1 milhão. Eles entregam sua criptomoeda e ganham outros 200.000. Agora temos certeza de que eles não serão capazes de recuperar o atraso, seria quase impossível.
13:55As pessoas estão chegando e nos parabenizando. Ainda estamos preocupados com alguma surpresa dos organizadores, mas parece que estamos realmente sendo anunciados como vencedores!
Esta é a crônica das 28 horas de True0xA3. Claro, eu deixei muito de fora. Por exemplo, as coletivas de imprensa na arena, as torturas que foram o Wi-Fi e o GSM, a interação com os repórteres ... mas espero ter capturado os momentos mais interessantes.
Essa foi uma das experiências mais animadoras para nossa equipe, e espero poder dar a você um pouco de uma sensação de como é a atmosfera do Standoff e incentivá-lo a tentar participar também !
Em seguida, publicarei a última parte desta série, onde analisarei nossos erros e as maneiras de corrigi-los no futuro. Porque aprender com os erros de outra pessoa é o melhor tipo de aprendizagem, certo?