Bem-vindo, Habr!
Ao mesmo tempo, fomos os primeiros a
introduzir o tema
Kafka no mercado russo e continuar a
monitorar seu desenvolvimento. Em particular, o tópico da interação entre Kafka e
Kubernetes parecia interessante para nós. Um artigo de revisão (e bastante cauteloso) sobre esse assunto foi publicado no blog da Confluent em outubro do ano passado, de autoria de Gwen Shapira. Hoje, queremos chamar sua atenção para um artigo mais recente de abril de Johann Gyger, que, apesar de não poder deixar de ter um ponto de interrogação no título, considera o assunto de maneira mais substantiva, acompanhando o texto com links interessantes. Por favor, perdoe-nos a tradução gratuita de "macaco do caos", se puder!
1. Introdução
O Kubernetes foi projetado para lidar com cargas sem estado. Como regra, essas cargas de trabalho são apresentadas na forma de arquitetura de microsserviços, são leves, bem adequadas para a escala horizontal, obedecem aos princípios de aplicativos de 12 fatores e permitem trabalhar com disjuntores e macacos do caos.
O Kafka, localizado por outro lado, atua essencialmente como um banco de dados distribuído. Portanto, ao trabalhar, você precisa lidar com a condição, e ela é muito mais pesada que um microsserviço. Kubernetes suporta cargas com estado, mas como Kelsey Hightower aponta em dois de seus tweets, eles devem ser tratados com cuidado:
Parece para alguns que, se você colocar o Kubernetes em uma carga estável, ele se transformará em um banco de dados totalmente gerenciado que poderá competir com o RDS. Isto não é verdade. Talvez se você apenas trabalhar duro, parafusar componentes adicionais e atrair uma equipe de engenheiros do SRE, poderá instalar o RDS no Kubernetes.
Eu sempre recomendo que todos tenham extrema cautela ao iniciar cargas que preservam o estado no Kubernetes. A maioria das pessoas interessadas em “posso executar cargas com estado no Kubernetes” não possui experiência suficiente trabalhando com o Kubernetes e, geralmente, com a carga sobre a qual estão perguntando.
Então, devo executar o Kafka no Kubernetes? Contra-pergunta: Kafka funcionará melhor sem o Kubernetes? É por isso que quero enfatizar neste artigo como Kafka e Kubernetes se complementam e que armadilhas podem surgir quando combinadas.
Prazo de execução
Vamos falar sobre o básico - o próprio ambiente de tempo de execução
O processoOs agentes Kafka são convenientes ao trabalhar com a CPU. TLS pode incorrer em alguma sobrecarga. Ao mesmo tempo, os clientes Kafka podem carregar mais a CPU se usarem criptografia, mas isso não afeta os intermediários.
A memóriaOs corretores Kafka devoram a memória. O tamanho de heap da JVM geralmente está na moda para limitar de 4 a 5 GB, mas você também precisará de muita memória do sistema, pois o Kafka usa o cache de páginas muito ativamente. No Kubernetes, defina adequadamente os limites do contêiner para recursos e solicitações.
Data warehouseO armazenamento de dados nos contêineres é efêmero - os dados são perdidos na reinicialização. Você pode usar o volume
emptyDir para dados Kafka e o efeito será semelhante: seus dados do broker serão perdidos após a conclusão. Suas mensagens ainda podem ser salvas em outros corretores como réplicas. Portanto, após uma reinicialização, um intermediário com falha deve primeiro replicar todos os dados e esse processo pode levar muito tempo.
É por isso que o armazenamento de dados a longo prazo deve ser usado. Seja armazenamento de longo prazo não local com o sistema de arquivos XFS ou, mais precisamente, ext4. Não use NFS. Eu avisei. As versões NFS v3 ou v4 não funcionarão. Em resumo, o broker Kafka será encerrado se não puder excluir o diretório de dados devido ao problema de "renomeação estúpida" relevante no NFS. Se ainda não o convenci,
leia este artigo com muito cuidado. O armazém de dados deve ser não local para que o Kubernetes possa selecionar com mais flexibilidade um novo nó após uma reinicialização ou realocação.
RedeComo na maioria dos sistemas distribuídos, o desempenho do Kafka depende muito da latência da rede ser mínima e da largura de banda máxima. Não tente colocar todos os intermediários no mesmo nó, pois isso diminuirá a disponibilidade. Se o nó Kubernetes falhar, todo o cluster Kafka também falhará. Além disso, não disperse o cluster Kafka por datacenters inteiros. O mesmo vale para o cluster Kubernetes. Um bom compromisso nesse caso é escolher diferentes zonas de acesso.
Configuração
Manifestos comunsO site do Kubernetes tem um
guia muito bom sobre como configurar o ZooKeeper usando manifestos. Como o ZooKeeper faz parte do Kafka, é com isso que é conveniente começar a se familiarizar com quais conceitos do Kubernetes são aplicáveis aqui. Depois de descobrir isso, você pode usar os mesmos conceitos com o cluster Kafka.
- Sub : sub é a menor unidade implementável no Kubernetes. O pod contém sua carga de trabalho e o próprio pod corresponde ao processo em seu cluster. Uma lareira contém um ou mais contêineres. Cada servidor ZooKeeper no conjunto e cada intermediário no cluster Kafka funcionarão em uma abordagem separada.
- StatefulSet : StatefulSet é um objeto Kubernetes que trabalha com várias cargas de trabalho com estado, que exigem coordenação. StatefulSet fornece garantias em relação à ordenação de lares e sua singularidade.
- Serviços sem cabeça : os serviços permitem desanexar pods de clientes usando um nome lógico. O Kubernetes, nesse caso, é responsável pelo balanceamento de carga. No entanto, ao manter cargas de trabalho com estado, como no ZooKeeper e Kafka, os clientes precisam trocar informações com uma instância específica. É aqui que os serviços sem cabeça são úteis: nesse caso, o cliente ainda terá um nome lógico, mas você não precisará ir diretamente para o final.
- Volume para armazenamento de longo prazo : esses volumes são necessários para a configuração do armazenamento de longo prazo do bloco não local, mencionado acima.
O Yolean fornece um conjunto abrangente de manifestos que facilitam o início do Kafka no Kubernetes.
Gráficos de lemeHelm é um gerenciador de pacotes para um Kubernetes, que pode ser comparado aos gerenciadores de pacotes do sistema operacional, como yum, apt, Homebrew ou Chocolatey. É conveniente usá-lo para instalar pacotes de software predefinidos descritos nos diagramas do Helm. Um diagrama Helm bem escolhido facilita a tarefa difícil: como configurar corretamente todos os parâmetros para usar o Kafka no Kubernetes. Existem vários diagramas Kafka: o oficial está
no estado de incubadora , há um da
Confluent e outro da
Bitnami .
OperadoresComo o Helm tem certas desvantagens, outra ferramenta está ganhando popularidade considerável: os operadores do Kubernetes. O operador não apenas empacota o software para o Kubernetes, mas também permite implantar e gerenciar esse software.
A lista de
operadores impressionantes menciona dois operadores para Kafka. Um deles é
Strimzi . Com a ajuda de Strimzi, é fácil criar um cluster Kafka em minutos. Praticamente nenhuma configuração é necessária; além disso, o próprio operador fornece alguns recursos interessantes, por exemplo, criptografia TLS do tipo "ponto a ponto" dentro do cluster. A Confluent também fornece
seu próprio operador .
DesempenhoÉ muito importante testar o desempenho fornecendo à instância Kafka instalada pontos de controle. Esses testes ajudarão a identificar possíveis gargalos antes do início dos problemas. Felizmente, o Kafka já fornece duas ferramentas de teste de desempenho:
kafka-producer-perf-test.sh e
kafka-consumer-perf-test.sh . Use-os ativamente. Para referência, você pode consultar os resultados descritos
nesta postagem por Jay Kreps ou usar
esta revisão do Stéphane Maarek Amazon MSK.
Operações
MonitoramentoA transparência no sistema é muito importante - caso contrário, você não entenderá o que está acontecendo nele. Hoje, existe um kit de ferramentas sólido que fornece monitoramento com base em métricas no estilo nativo da nuvem. Duas ferramentas populares para esse fim são Prometheus e Grafana. O Prometheus pode coletar métricas de todos os processos Java (Kafka, Zookeeper, Kafka Connect) usando o exportador JMX - da maneira mais simples. Se você adicionar métricas cAdvisor, poderá entender melhor como os recursos são usados no Kubernetes.
Strimzi tem um exemplo de painel Grafana muito conveniente para Kafka. Ele visualiza as principais métricas, por exemplo, sobre setores não replicados ou off-line. Tudo está muito claro lá. Essas métricas são complementadas por informações sobre a utilização e desempenho de recursos, bem como indicadores de estabilidade. Assim, você obtém um monitoramento básico do cluster Kafka sem motivo!
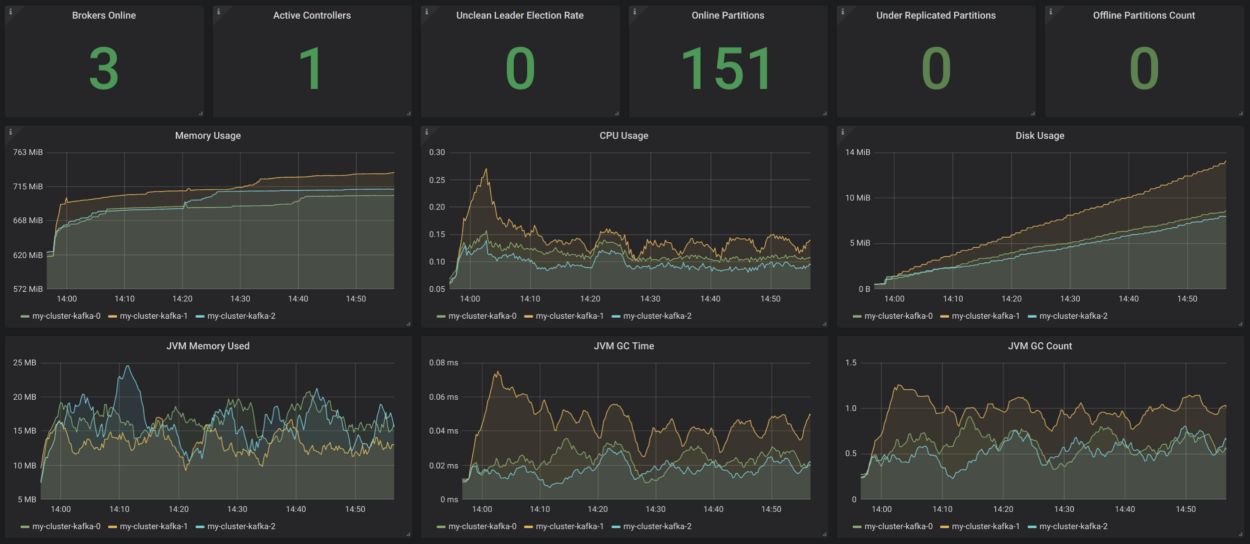
Fonte:
strimzi.io/docs/master/#kafka_dashboardSeria bom complementar tudo isso com o monitoramento do cliente (métricas para consumidores e produtores), bem como o monitoramento de lag (para isso existe
Burrow ) e o monitoramento de ponta a ponta - para isso, use o
Kafka Monitor .
RegistoO log é outra tarefa crítica. Verifique se todos os contêineres na instalação do Kafka estão conectados
stdout e
stderr e se o cluster do Kubernetes agrega todos os logs em uma infraestrutura de
log central, como o
Elasticsearch .
Verificação de integridadeO Kubernetes usa sondas de prontidão e prontidão para verificar se seus pods estão funcionando corretamente. Se o teste ao vivo falhar, o Kubernetes interromperá esse contêiner e o reiniciará automaticamente se a política de reinicialização estiver definida adequadamente. Se a verificação da disponibilidade falhar, o Kubernetes o isolará do serviço de solicitação. Assim, nesses casos, a intervenção manual não é mais necessária, e isso é uma grande vantagem.
Implementando atualizaçõesO StatefulSet suporta atualizações automáticas: ao escolher uma estratégia RollingUpdate, cada uma delas no Kafka será atualizada por sua vez. Dessa forma, o tempo de inatividade pode ser reduzido a zero.
DimensionamentoEscalar um cluster Kafka não é uma tarefa fácil. No entanto, no Kubernetes, é muito fácil dimensionar os pods para um certo número de réplicas, o que significa que você pode identificar declarativamente quantos corretores Kafka desejar. O mais difícil, neste caso, é a reatribuição de setores após aumentar ou diminuir o tamanho. Novamente, o Kubernetes irá ajudá-lo nessa tarefa.
AdministraçãoAs tarefas relacionadas à administração do cluster Kafka, em particular a criação de tópicos e a reatribuição de setores, podem ser realizadas usando scripts de shell existentes, abrindo a interface da linha de comandos em seus pods. No entanto, esta solução não é muito bonita. Strimzi suporta o gerenciamento de tópicos usando outro operador. Há algo para modificar aqui.
Backup e restauraçãoAgora, a disponibilidade do Kafka dependerá da disponibilidade do Kubernetes. Se o cluster Kubernetes cair, no pior dos casos, o cluster Kafka também cairá. Segundo a lei de Murphy, isso acontecerá e você perderá dados. Para reduzir esse tipo de risco, tenha um bom conceito de backup. Você pode usar o MirrorMaker, outra opção é usar o S3 para isso, conforme descrito nesta
publicação do Zalando.
Conclusão
Ao trabalhar com clusters Kafka pequenos ou médios, é definitivamente recomendável usar o Kubernetes, pois fornece flexibilidade adicional e simplifica o trabalho com os operadores. Se você tiver requisitos não funcionais muito sérios em relação à latência e / ou taxa de transferência, talvez seja melhor considerar outra opção de implantação.