Você acha que é difícil escrever seu próprio chatbot em Python que possa apoiar a conversa? Acabou sendo muito fácil se você encontrar um bom conjunto de dados. Além disso, isso pode ser feito mesmo sem redes neurais, embora ainda seja necessária alguma mágica matemática.
Iremos em pequenos passos: primeiro, lembre-se de como carregar dados no Python, depois aprenda a contar palavras, conecte gradualmente álgebra linear e teorizador e, no final, criamos um bot para o Telegram a partir do algoritmo de bate-papo resultante.
Este tutorial é adequado para quem já tocou um pouco em Python, mas não está particularmente familiarizado com o aprendizado de máquina. Intencionalmente, não usei nenhuma biblioteca nlp-sh para mostrar que algo funcionando pode ser montado no sklearn.
Procure uma resposta no conjunto de dados da caixa de diálogo
Um ano atrás, me pediram para mostrar aos caras que não haviam se envolvido anteriormente na análise de dados algum aplicativo inspirador de aprendizado de máquina que você pode criar por conta própria. Tentei trazer um falador de bot com eles, e realmente o fizemos em uma noite. Gostamos do processo e do resultado e escrevemos sobre isso no
meu blog . E agora eu pensei que Habru seria interessante.
Então aqui vamos nós. Nossa tarefa é criar um algoritmo que dê uma resposta apropriada a qualquer frase. Por exemplo, em "como você está?" responda "excelente, e você?". A maneira mais fácil de conseguir isso é encontrar um banco de dados pronto de perguntas e respostas. Por exemplo, tire legendas de um grande número de filmes.
No entanto, vou agir de forma ainda mais trapaceira e tirar os dados da
competição Yandex.Algorithm 2018 - esses são os mesmos diálogos dos filmes para os quais os funcionários da Toloka marcaram boas e boas sequências. Yandex coletou esses dados para treinar Alice (artigos sobre suas tripas
1 ,
2 ,
3 ). Na verdade, eu fui inspirado por Alice quando criei esse bot. A
tabela do Yandex mostra as três últimas frases e a resposta para elas (resposta), mas usaremos apenas a mais recente (context_0).
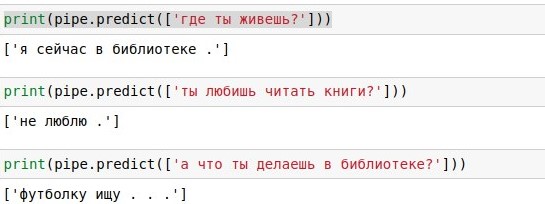
Com esse banco de dados de diálogos, você pode simplesmente pesquisar cada réplica do usuário e fornecer uma resposta pronta (se houver muitas dessas réplicas, escolha aleatoriamente). Com "como vai você?" ficou ótimo, como evidenciado pela captura de tela em anexo. Este, se é que
existe algo, é um
bloco de anotações jupyter no Python 3. Se você quiser repetir isso sozinho, a maneira mais fácil é instalar o
Anaconda - ele inclui o Python e vários pacotes úteis para ele. Ou você não pode instalar nada, mas execute um notebook
em uma nuvem do Google .

O problema com pesquisas textuais é que ele tem baixa cobertura. Para a frase "como vai você?" no banco de dados de 40 mil respostas, não houve correspondência exata, embora tenha o mesmo significado. Portanto, na próxima seção, suplementaremos nosso código usando diferentes matemáticas para implementar uma pesquisa aproximada. E antes disso, você pode ler sobre a biblioteca do
pandas e descobrir o que cada uma das 6 linhas do código acima faz.
Vetorização de texto
Agora, estamos falando sobre como transformar textos em vetores numéricos para realizar uma pesquisa aproximada neles.
Já conhecemos a biblioteca de pandas em Python - ela permite carregar tabelas, pesquisar nelas, etc. Agora, vamos tocar na biblioteca scikit
-learn (sklearn), que permite manipulação de dados mais complicada - o que é chamado de aprendizado de máquina. Isso significa que qualquer algoritmo deve primeiro mostrar os dados (ajuste) para que ele aprenda algo importante sobre eles. Como resultado, o algoritmo "aprende" a fazer algo útil com esses dados - transformá-lo (transformar) ou até prever valores desconhecidos (prever).
Nesse caso, queremos converter textos ("perguntas") em vetores numéricos. Isso é necessário para que seja possível encontrar textos “próximos” um do outro, usando o conceito matemático de distância. A distância entre dois pontos pode ser calculada pelo teorema de Pitágoras - como a raiz da soma dos quadrados das diferenças de suas coordenadas. Em matemática, isso é chamado de métrica euclidiana. Se podemos transformar textos em objetos que possuem coordenadas, podemos calcular a métrica euclidiana e, por exemplo, encontrar no banco de dados uma pergunta que mais se assemelha a “o que você está pensando?”.
A maneira mais fácil de especificar as coordenadas do texto é numerar todas as palavras do idioma e dizer que a i-ésima coordenada do texto é igual ao número de ocorrências da i-ésima palavra nele. Por exemplo, para o texto "Não consigo evitar de chorar", a coordenada da palavra "não" é 2, as coordenadas das palavras "I", "posso" e "choro" são 1 e as coordenadas de todas as outras palavras (dezenas de milhares de quais) são 0. Esta representação perde informações sobre a ordem das palavras, mas ainda funciona muito bem.
O problema é que, para as palavras frequentemente encontradas (por exemplo, partículas “e” e “a”), as coordenadas serão desproporcionalmente grandes, embora tenham pouca informação. Para atenuar esse problema, a coordenada de cada palavra pode ser dividida pelo logaritmo do número de textos em que essa palavra ocorre - isso é chamado tf-idf e também funciona bem.

Existe apenas um problema: em nosso banco de dados de 60 mil “perguntas” textuais, que contêm 14 mil palavras diferentes. Se você transformar todas as perguntas em vetores, obtém uma matriz de 60k * 14k. Não é muito legal trabalhar com isso, então falaremos sobre reduzir a dimensão mais tarde.
Redução dimensional
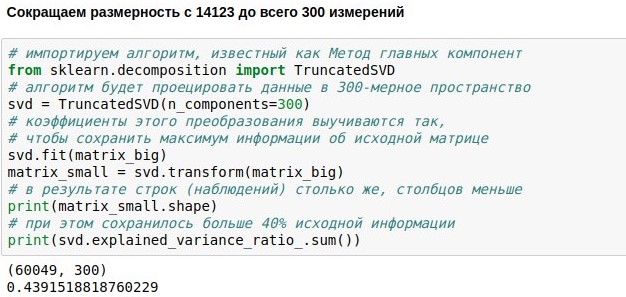
Já definimos a tarefa de criar um chatbot de bate-papo, baixar e vetorizar dados para seu treinamento. Agora temos uma matriz numérica representando réplicas de usuários. Consiste em 60 mil linhas (havia tantas réplicas no banco de dados de diálogos) e 14 mil colunas (havia tantas palavras diferentes nelas). Nossa tarefa agora é torná-lo menor. Por exemplo, para apresentar cada texto não como um vetor 14123-dimensional, mas apenas um vetor 300-dimensional.
Isso pode ser conseguido multiplicando nossa matriz de tamanho 60049x14123 por uma matriz de projeção especialmente selecionada de tamanho 14123x300, como resultado, obtemos o resultado 60049x300. O algoritmo PCA (
método do componente principal ) seleciona a matriz de projeção para que a matriz original possa ser reconstruída com o menor erro padrão. No nosso caso, foi possível manter cerca de 44% da matriz original, embora a dimensão tenha sido reduzida em quase 50 vezes.
O que torna essa compactação eficaz possível? Lembre-se de que a matriz original contém contadores para mencionar palavras individuais nos textos. Mas as palavras, em regra, são usadas não independentemente uma da outra, mas no contexto. Por exemplo, quanto mais vezes a palavra "bloqueio" ocorre no texto das notícias, mais vezes é provável que a palavra "telegramas" também seja encontrada neste texto. Mas a correlação da palavra "bloqueio", por exemplo, com a palavra "caftan" é negativa - elas são encontradas em diferentes contextos.
Assim, verifica-se que o método dos componentes principais lembra não todas as 14 mil palavras, mas 300 contextos típicos pelos quais essas palavras podem ser tentadas para serem restauradas. As colunas da matriz de projeção correspondentes a palavras sinônimas geralmente são semelhantes entre si, porque essas palavras são frequentemente encontradas no mesmo contexto. Isso significa que é possível reduzir medições redundantes sem perder informações.
Em muitas aplicações modernas, a matriz de projeção de palavras é calculada por redes neurais (por exemplo,
word2vec ). Mas, de fato, a álgebra linear simples já é suficiente para um resultado praticamente útil. O método dos componentes principais é reduzido computacionalmente para SVD e é para calcular os vetores próprios e os valores próprios da matriz. No entanto, isso pode ser programado sem ao menos conhecer os detalhes.
Procurar vizinhos próximos
Nas seções anteriores, carregamos a caixa de diálogo para python, a vetorizamos e reduzimos a dimensão, e agora queremos finalmente aprender a procurar nossos vizinhos mais próximos em nosso espaço tridimensional e, finalmente, responder a perguntas de maneira significativa.
Como aprendemos a mapear perguntas para o espaço euclidiano de dimensão não muito alta, a busca por vizinhos pode ser realizada rapidamente. Usaremos o algoritmo de busca de vizinhos
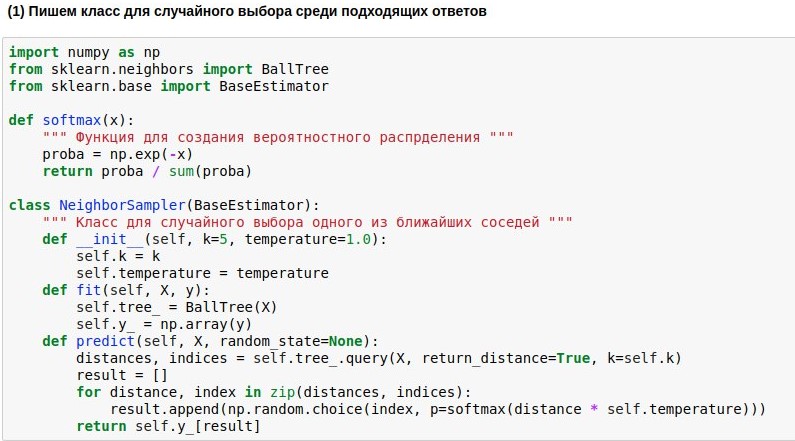
BallTree pronto. Mas escreveremos nosso modelo de invólucro, que escolheria um dos k vizinhos mais próximos e, quanto mais próximo o vizinho, maior a probabilidade de sua escolha. Pois sempre é chato ter um dos vizinhos mais próximos, mas não é amarrado à semelhança.
Portanto, queremos transformar as distâncias encontradas da consulta para os textos de referência na probabilidade de escolher esses textos. Para fazer isso, você pode usar a função softmax, que muitas vezes ainda fica na saída das redes neurais. Ela transforma seus argumentos em um conjunto de números não negativos, cuja soma é 1 - exatamente o que precisamos. Além disso, podemos usar as "probabilidades" obtidas para uma escolha aleatória de resposta.
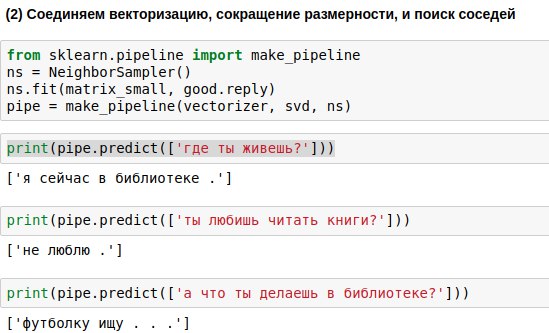
As frases que o usuário digitará devem ser passadas pelos três algoritmos - o vetorizador, o método do componente principal e o algoritmo de seleção de resposta. Para escrever menos código, você pode vinculá-los em uma única cadeia (pipeline), aplicando os algoritmos sequencialmente.
Como resultado, obtivemos um algoritmo que, na pergunta de um usuário, é capaz de encontrar uma pergunta semelhante a ela e dar uma resposta a ela. E, às vezes, essas respostas até parecem quase significativas.
Publicando um bot no Telegram
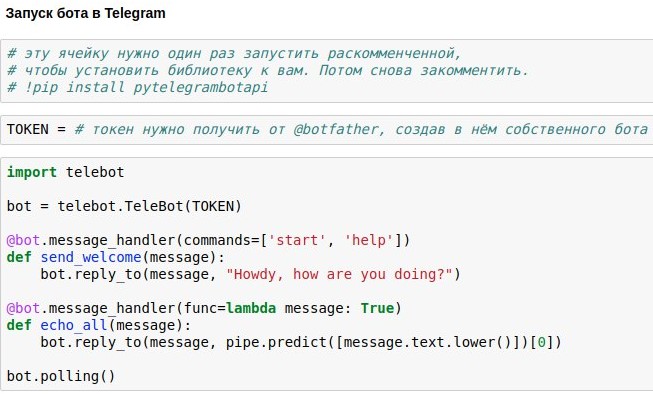
Já descobrimos como criar uma sala de bate-papo do chatbot que daria respostas aproximadamente relevantes às solicitações do usuário. Agora estou mostrando como lançar um chatbot no Telegram.
A maneira mais fácil de usar isso é a API do Telegram do wrapper pronta para python - por exemplo,
pytelegrambotapi . Então, instruções passo a passo:
- Registre seu futuro bot com @botfather e obtenha um token de acesso, que você precisará inserir no seu código.
- Execute o comando de instalação uma vez - pip install pytelegrambotapi na linha de comando (ou via! Diretamente no bloco de notas).
- Execute o código como na captura de tela. A célula entrará no modo de execução (*) e, enquanto estiver nesse modo, você poderá se comunicar com seu bot o quanto quiser. Para parar o bot, pressione Ctrl + C. A triste, mas importante verdade: se você estiver na Rússia, provavelmente antes de iniciar esta célula, será necessário ativar a VPN para evitar erros ao conectar-se a telegramas. Uma alternativa mais simples à VPN é escrever todo o código não no seu computador local, mas no google colab ( algo como isto ).
- Se você deseja que o bot funcione permanentemente, é necessário colocar seu código em algum serviço de nuvem - por exemplo, AWS, Heroku, now.sh ou Yandex.Cloud. Você pode aprender sobre como executá-los nos mínimos detalhes nos sites desses serviços ou em artigos ali mesmo no Habré. Por exemplo, um nabo com um pequeno exemplo de um bot sendo executado no heroku e colocando logs no mongodb.
Eu não intencionalmente não carrego o código completo do artigo - você terá muito mais prazer e experiência útil ao imprimi-lo e obter um bot funcionando como resultado de seus próprios esforços. Bem, ou se você estiver com preguiça de fazer isso, você pode conversar com a
minha versão do bot.