Os sistemas de informação modernos são bastante complexos. Por último, mas não menos importante, sua complexidade se deve à complexidade dos dados processados neles. A complexidade dos dados geralmente reside na variedade de modelos de dados usados. Assim, por exemplo, quando os dados se tornam "grandes", uma das características inconvenientes é considerada não apenas seu volume ("volume"), mas também sua variedade ("variedade").
Se você ainda não encontrar uma falha no raciocínio, continue lendo.

Persistência poliglota
O precedente leva ao fato de que, às vezes, mesmo na estrutura de um sistema, é necessário usar vários DBMSs diferentes para armazenar dados e resolver vários problemas no processamento deles, cada um dos quais suporta seu próprio modelo de dados. Com a mão leve de M. Fowler, autor de vários livros conhecidos e um dos coautores do Agile Manifesto, essa situação foi chamada de armazenamento multivariado ("persistência poliglota").
Fowler também possui o seguinte exemplo de organização de armazenamento de dados em um aplicativo totalmente funcional e altamente carregado no campo do comércio eletrônico.

É claro que este exemplo é um pouco exagerado, mas algumas considerações a favor da escolha de um ou outro DBMS para o objetivo correspondente podem ser encontradas, por exemplo, aqui .
É claro que ser ministro em um zoológico assim não é fácil.
- A quantidade de código que executa o armazenamento de dados cresce proporcionalmente ao número de DBMSs usados; a quantidade de código que sincroniza os dados é boa, se não proporcional ao quadrado desse número.
- Um múltiplo do número de DBMSs usados está aumentando os custos de fornecer características da empresa (escalabilidade, tolerância a falhas, alta disponibilidade) para cada um dos DBMSs usados.
- Não é possível fornecer as características corporativas do subsistema de armazenamento como um todo - especialmente transacional.
Do ponto de vista do diretor do zoológico, tudo fica assim:
- Um aumento múltiplo no custo de licenças e suporte técnico do fabricante do DBMS.
- Os funcionários incham e levam mais tempo.
- Perdas ou penalidades financeiras diretas devido a dados inconsistentes.
Há um aumento significativo no custo total de propriedade do sistema (TCO). Existe alguma maneira de sair da situação de "armazenamento multivariado"?
Multimodel
O termo "armazenamento multivariado" entrou em uso em 2011. A conscientização dos problemas da abordagem e a busca por uma solução levaram vários anos e, até 2015, a resposta foi formulada pela boca dos analistas do Gartner:
Parece que desta vez os analistas do Gartner não se enganaram com a previsão. Se você for para a página com a classificação principal do DBMS nos DB-Engines, poderá ver que a maioria de seus líderes se posiciona precisamente como DBMSs multimodais. O mesmo pode ser visto na página com qualquer classificação privada.
A tabela abaixo mostra o DBMS - os líderes em cada uma das classificações privadas, declarando seu multi-modelo. Para cada DBMS, o modelo suportado inicial (antes o único) é indicado e, junto com ele, os modelos suportados agora. Também são apresentados DBMSs que se posicionam como “inicialmente multimodelos” e não possuem nenhum modelo herdado original, de acordo com os criadores.
Notas da tabelaAsteriscos na tabela marcam instruções que exigem reservas:
- O PostgreSQL não suporta um modelo de dados gráficos, mas é suportado por um produto baseado nele , como, por exemplo, AgensGraph.
- Com relação ao MongoDB, é mais correto falar mais sobre a presença de operadores de gráfico na linguagem de consulta (
$lookup , $graphLookup ) do que sobre o suporte ao modelo de gráfico, embora, é claro, sua introdução exigisse algumas otimizações no nível de armazenamento físico na direção de suportar o modelo de gráfico. - Para Redis, isso se refere à extensão RedisGraph .
Além disso, para cada uma das classes, mostraremos como o suporte de vários modelos no DBMS dessa classe é implementado. Consideraremos os modelos relacionais, de documentos e gráficos mais importantes e mostraremos com exemplos de DBMS específico como os "ausentes" são implementados.
DBMS multimodal com base em um modelo relacional
Os principais DBMSs atualmente são relacionais; a previsão do Gartner não poderia ser considerada verdadeira se os RDBMSs não mostrassem movimento na direção da multimodelidade. E eles demonstram. Agora, a idéia de que um DBMS multimodal é como uma faca suíça, que não pode ser bem executada, pode ser enviada imediatamente para Larry Ellison.
O autor, no entanto, gosta da implementação de multimodeling no Microsoft SQL Server, no exemplo do qual o suporte ao RDBMS para modelos de documento e gráfico será descrito.
Modelo de documento no MS SQL Server
Sobre como o MS SQL Server suporta o modelo de documento, já havia dois excelentes artigos sobre Habré. Vou me limitar a uma breve recontagem e comentário:
A maneira de oferecer suporte ao modelo de documento no MS SQL Server é bastante típica para DBMSs relacionais: propõe-se que os documentos JSON sejam armazenados em campos de texto sem formatação. O suporte ao modelo de documento é fornecer operadores especiais para analisar este JSON:
O segundo argumento para os dois operadores é uma expressão na sintaxe semelhante ao JSONPath.
Pode-se dizer abstratamente que os documentos armazenados dessa maneira não são "entidades de primeira classe" em um DBMS relacional, diferentemente das tuplas. Especificamente, o MS SQL Server atualmente não possui índices nos campos dos documentos JSON, o que dificulta a associação de tabelas pelos valores desses campos e até a seleção de documentos por esses valores. No entanto, é possível criar uma coluna computável e um índice nela neste campo.
Além disso, o MS SQL Server fornece a capacidade de construir convenientemente um documento JSON a partir do conteúdo de tabelas usando a instrução FOR JSON PATH , um recurso que, em certo sentido, é o oposto do armazenamento comum anterior. É claro que não importa a rapidez com que o RDBMS seja, essa abordagem contradiz a ideologia dos DBMSs de documentos, que de fato armazenam respostas prontas para consultas populares e só podem resolver problemas de conveniência de desenvolvimento, mas não de velocidade.
Por fim, o MS SQL Server permite resolver o problema, o inverso do design do documento: você pode decompor o JSON em tabelas usando OPENJSON . Se o documento não estiver completamente plano, você precisará usar o CROSS APPLY .
Modelo de gráfico no MS SQL Server
O suporte para modelos de gráfico ( LPG ) implementados no Microsoft SQL Server também é bastante previsível : propõe-se o uso de tabelas especiais para armazenar nós e para armazenar arestas de gráfico. Essas tabelas são criadas usando as expressões CREATE TABLE AS NODE e CREATE TABLE AS EDGE respectivamente.
As tabelas do primeiro tipo são semelhantes às tabelas comuns para armazenar registros com a única diferença externa de que a tabela contém o campo do sistema $node_id - um identificador exclusivo do nó do gráfico no banco de dados.
Da mesma forma, as tabelas do segundo tipo têm os campos do sistema $from_id e $to_id , os registros nessas tabelas definem claramente os relacionamentos entre os nós. Uma tabela separada é usada para armazenar relacionamentos de cada tipo.
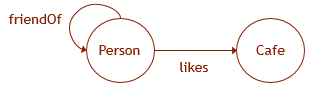 Ilustramos o que foi dito pelo exemplo. Deixe que os dados do gráfico tenham um esquema, como mostrado na figura. Em seguida, para criar a estrutura correspondente no banco de dados, é necessário executar as seguintes consultas DDL:
Ilustramos o que foi dito pelo exemplo. Deixe que os dados do gráfico tenham um esquema, como mostrado na figura. Em seguida, para criar a estrutura correspondente no banco de dados, é necessário executar as seguintes consultas DDL:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
A principal especificidade dessas tabelas é que é possível usar padrões de gráficos com sintaxe semelhante ao Cypher em consultas para elas (no entanto, “ * ” etc., ainda não são suportados). Além disso, com base nas medições de desempenho, pode-se supor que o método de armazenamento de dados nessas tabelas seja diferente do mecanismo de armazenamento de dados em tabelas comuns e seja otimizado para executar essas consultas gráficas.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
Além disso, é bastante difícil não usar esses padrões gráficos ao trabalhar com essas tabelas, pois em consultas SQL comuns para resolver problemas semelhantes, serão necessários esforços adicionais para obter identificadores de nó do "gráfico" do sistema ( $from_id , $to_id , $from_id , $to_id ; para isso pelo mesmo motivo, as solicitações de inserção de dados não são fornecidas aqui como muito complicadas).
Resumindo a descrição das implementações dos modelos de documento e gráfico no MS SQL Server, eu observaria que essas implementações de um modelo em cima de outro não parecem bem-sucedidas principalmente do ponto de vista do design de linguagem. É necessário expandir um idioma com outro, os idiomas não são completamente "ortogonais", as regras de compatibilidade podem ser bastante bizarras.
DBMS multimodelo com base em um modelo de documento
Nesta seção, gostaria de ilustrar a implementação do multimodelo nos DBMSs de documentos usando o exemplo dos não mais populares deles, o MongoDB (como foi dito, ele contém apenas condicionalmente operadores de gráfico $lookup e $graphLookup que não funcionam em coleções de shard), mas no exemplo é mais maduro e “ Empresa »DBMS MarkLogic .
Portanto, deixe a coleção conter um conjunto de documentos XML do seguinte formato (o MarkLogic também permite armazenar documentos JSON):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
Modelo Relacional na MarkLogic
Uma representação relacional de uma coleção de documentos pode ser criada usando um modelo de exibição (o conteúdo dos elementos de value no exemplo abaixo pode ser XPath arbitrário):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
Uma consulta SQL pode ser endereçada à visualização criada (por exemplo, via ODBC):
SELECT name, surname FROM Person WHERE name="John"
Infelizmente, a visão relacional criada usando o modelo de exibição é somente leitura. Ao processar uma solicitação, o MarkLogic tentará usar índices de documentos . Costumava haver visualizações relacionais limitadas no MarkLogic que eram inteiramente baseadas em índices e graváveis, mas agora elas são consideradas obsoletas.
Modelo de gráfico no MarkLogic
Com o suporte ao modelo de gráfico ( RDF ), as coisas são praticamente as mesmas. Novamente, usando o modelo de exibição, você pode criar uma representação RDF da coleção de documentos a partir do exemplo acima:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
O gráfico RDF resultante pode ser endereçado com uma consulta SPARQL:
PREFIX : <http://example.org/example
Diferente do relacional, o modelo gráfico MarkLogic suporta de duas outras maneiras:
- O DBMS pode ser um repositório separado completo de dados RDF (os trigêmeos nele serão chamados gerenciados, em oposição à extração extraída acima).
- RDF em serialização especial pode simplesmente ser inserido em documentos XML ou JSON (e os trigêmeos serão chamados de não gerenciados ). Provavelmente, essa é uma alternativa aos mecanismos de
idref etc.
A API do Optic fornece uma boa idéia de como "realmente" tudo funciona no MarkLogic; nesse sentido, é de baixo nível, embora seu objetivo seja o oposto - tentar abstrair do modelo de dados usado, garantir trabalho consistente com dados em diferentes modelos, transacionalidade e pr
DBMS multimodal “sem o modelo principal”
Os DBMSs também estão disponíveis no mercado, posicionando-se inicialmente como multi-modelos, sem nenhum modelo básico herdado. Isso inclui ArangoDB , OrientDB (desde 2018, a empresa de desenvolvimento pertence à SAP) e CosmosDB (um serviço incluído na plataforma em nuvem Microsoft Azure).
De fato, existem modelos "básicos" no ArangoDB e no OrientDB. Nos dois casos, esses são modelos de dados proprietários, que são generalizações de documentos. As generalizações são principalmente para facilitar a capacidade de produzir consultas gráficas e relacionais.
Esses modelos são os únicos disponíveis para uso nos DBMSs indicados; suas próprias linguagens de consulta foram projetadas para trabalhar com eles. Obviamente, esses modelos e DBMSs são promissores, mas a falta de compatibilidade com modelos e linguagens padrão torna impossível o uso desses DBMSs em sistemas legados - substituindo-os pelo DBMS que eles já usam.
Sobre o ArangoDB e o OrientDB no Habré, já havia um artigo maravilhoso: JOIN nos bancos de dados NoSQL .
Arangodb
O ArangoDB reivindica suporte para um modelo de dados gráficos.
Os nós de gráfico no ArangoDB são documentos comuns e as bordas são documentos de um tipo especial que possuem, juntamente com os campos usuais do sistema ( _key , _id , _rev ), os campos _from e _to do sistema. Os documentos nos DBMSs de documentos são tradicionalmente combinados em coleções. Coleções de documentos que representam bordas são chamadas coleções de bordas no ArangoDB. A propósito, os documentos de coleções de arestas também são documentos, portanto as arestas no ArangoDB também podem atuar como nós.
Dados de origemSuponha que tenhamos uma coleção de persons cujos documentos são assim:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
Vamos também ter uma coleção de cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
Em seguida, a coleção de likes pode ficar assim:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
Consultas e ResultadosUma consulta em estilo gráfico no AQL usada no ArangoDB que retorna informações de forma legível por humanos sobre quem gosta de qual café se parece com isso:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
Em um estilo relacional, quando é mais provável que "calculemos" os relacionamentos, em vez de armazená-los, essa consulta pode ser reescrita assim (a propósito, você poderia fazer sem a coleção de likes ):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
O resultado em ambos os casos será o mesmo:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
Mais consultas e resultadosSe parece que o formato do resultado acima é mais típico para um DBMS relacional do que para um documento, você pode tentar esta consulta (ou pode usar COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
O resultado será o seguinte:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
Oriententb
A implementação do modelo de gráfico na parte superior do modelo de documento no OrientDB baseia-se na capacidade dos campos de documento de ter, além de valores escalares mais ou menos padrão, valores de tipos como LINK , LINKLIST , LINKSET , LINKMAP e LINKBAG . Os valores desses tipos são links ou coleções de links para identificadores de documentos do sistema .
O identificador de documento atribuído pelo sistema tem um "significado físico", indicando a posição do registro no banco de dados, e se parece com isso: @rid : #3:16 . Assim, os valores das propriedades de referência são realmente mais prováveis (como em um modelo de gráfico), em vez de condições de seleção (como em um modelo relacional).
Como no ArangoDB, no OrientDB, as bordas são representadas como documentos separados (embora, se a borda não tiver suas próprias propriedades, ela poderá ficar leve e um documento separado não corresponderá a ela).
Dados de origemEm um formato próximo ao formato de despejo de banco de dados do OrientDB, os dados do exemplo anterior do ArangoDB se pareceriam com isso:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
Como podemos ver, os vértices também armazenam informações sobre as arestas de entrada e saída. Ao usar a API do documento, você deve seguir a integridade referencial e a API do Graph cuida disso. Mas vamos ver como é a chamada para o OrientDB em "limpa", não integrada a linguagens de programação e linguagens de consulta.
Consultas e ResultadosUma consulta de propósito semelhante à consulta do exemplo para ArangoDB no OrientDB se parece com isso:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
O resultado será obtido da seguinte forma:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
Se o formato do resultado novamente parecer muito "relacional", você precisará remover a linha com UNWIND() :
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
A linguagem de consulta do OrientDB pode ser descrita como SQL com inserções semelhantes ao Gremlin. A versão 2.2 introduziu um formulário de solicitação semelhante ao Cypher, MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
O formato do resultado será o mesmo da consulta anterior. Pense no que precisa ser removido para torná-lo mais "relacional", como na primeira consulta.
Azure CosmosDB
Em menor grau, o que foi dito acima sobre o ArangoDB e o OrientDB refere-se ao Azure CosmosDB. O CosmosDB fornece as seguintes APIs de acesso a dados: SQL, MongoDB, Gremlin e Cassandra.
A API SQL e a API MongoDB são usadas para acessar dados no modelo de documento. API Gremlin e Cassandra API - para acessar dados em gráfico e coluna, respectivamente. Os dados em todos os modelos são salvos no formato do modelo interno do CosmosDB: ARS (“atom-record-sequence”), que também está próximo do documento.

Mas o modelo de dados selecionado pelo usuário e a API usada são corrigidos no momento da criação da conta no serviço. É impossível acessar os dados carregados em um modelo no formato de outro modelo, o que seria ilustrado por algo assim:

Portanto, hoje, o multimodelo no Azure CosmosDB é apenas uma oportunidade de usar vários bancos de dados que oferecem suporte a modelos diferentes do mesmo fabricante, o que não resolve todos os problemas do armazenamento multivariado.
DBMS multimodal com base em um modelo de gráfico?
Vale ressaltar que no mercado não existem DBMSs multimodais baseados em um modelo gráfico (exceto no suporte multimodelo para dois modelos gráficos simultaneamente: RDF e LPG; veja isso em uma publicação anterior ). As maiores dificuldades são a implementação no topo do modelo gráfico do documento, em vez do relacional.
A questão de como implementar um modelo relacional sobre um modelo de gráfico foi considerada mesmo no momento da formação do último. Como David McGovern disse , por exemplo:
Não há nada inerente à abordagem de gráfico que impeça a criação de uma camada (por exemplo, por indexação adequada) em um banco de dados de gráficos que permita uma visão relacional com (1) recuperação de tuplas dos pares de valores-chave usuais e (2) agrupamento de tuplas por tipo de relação.
Ao implementar o modelo de documento na parte superior do gráfico, lembre-se, por exemplo, do seguinte:
- Os elementos da matriz JSON são considerados ordenados, vindos da parte superior da borda do gráfico - não;
- Os dados no modelo de documento geralmente são desnormalizados, você ainda não deseja armazenar várias cópias do mesmo documento anexado e os subdocumentos geralmente não têm identificadores;
- Por outro lado, a ideologia dos DBMSs de documentos é que os documentos são “unidades” prontas que não precisam ser reconstruídas todas as vezes. É necessário fornecer no modelo gráfico a capacidade de obter rapidamente o subgrafo correspondente ao documento final.
Alguma publicidadeO autor do artigo está relacionado ao desenvolvimento do NitrosBase DBMS, cujo modelo interno é gráfico, e os modelos externos - relacionais e documentais - são suas representações. Todos os modelos são iguais: quase todos os dados estão disponíveis em qualquer um deles, usando a linguagem de consulta natural para ele. Além disso, em qualquer representação, os dados estão sujeitos a alterações. As mudanças serão refletidas no modelo interno e, consequentemente, em outras representações.
Qual a aparência do modelo no NitrosBase - descreverei, espero, em um dos seguintes artigos.
Conclusão
Espero que os contornos gerais do chamado multimodelo se tornem mais ou menos claros para o leitor. DBMSs bastante diferentes são chamados de multimodelos e o "suporte para vários modelos" pode parecer diferente. Para entender o que é chamado de "multi-modelo" em cada caso, é útil responder às seguintes perguntas:
- Trata-se de suportar modelos tradicionais ou de um único modelo híbrido?
- Os modelos são "iguais" ou um deles está sujeito aos outros?
- Os modelos são "indiferentes" um ao outro? Os dados gravados em um modelo podem ser lidos em outro ou até substituídos?
Penso que já é possível dar uma resposta positiva à questão da relevância dos SGBDs multimodelos, mas a questão interessante é qual de suas variedades será mais popular no futuro próximo. Parece que os DBMSs multimodais que suportam modelos tradicionais, principalmente relacionais, serão mais procurados; , , , — .