Nota perev. : O que hoje é chamado de SRE (Site Reliability Engineering - "garantia da confiabilidade dos sistemas de informação") inclui uma ampla gama de medidas para a operação de produtos de software destinados a atingir o nível de confiabilidade necessário. O monitoramento é um dos principais eventos, e os "sinais de ouro" formam as principais métricas que devem ser levadas em consideração. Como não encontramos nenhum material sobre eles no Habré, decidimos traduzir uma breve nota dos autores da plataforma de gerenciamento de incidentes (VictorOps), que fornece uma idéia da idéia geral dessa abordagem.
A engenharia de confiabilidade do site (
SRE ) é baseada em um profundo entendimento da arquitetura e infraestrutura de serviços subjacentes. Aumentar a transparência do estado do aplicativo e da infraestrutura é apenas o começo de um trabalho proativo na criação de sistemas confiáveis. Ao mesmo tempo, os chamados "quatro sinais de ouro" SRE são considerados o melhor ponto de partida para monitorar o status dos sistemas. Tendo estabelecido esses quatro métodos básicos de monitoramento, podemos prosseguir para aumentar ainda mais a transparência do sistema.
O aumento da transparência, juntamente com métodos eficazes de colaboração, permite às equipes de SRE monitorar rapidamente os sistemas e tomar medidas para eliminar as conseqüências dos incidentes, aumentando a eficácia geral dos métodos de
monitoramento e aviso . Os sinais Gold SRE ajudam as equipes a identificar possíveis fraquezas na confiabilidade, permitindo que se concentrem na solução de problemas de infraestrutura. Vamos examinar a relação entre métodos de monitoramento e comandos do SRE e ver qual efeito os sinais de ouro têm no processo.
Monitoramento e SRE
Na Parte III do nosso
dicionário DevOps, exploramos a Internet, tentando encontrar uma definição de SRE. Segundo um
artigo relacionado da
Wikipedia ,
“Ben Treynor, o fundador da Equipe de Confiabilidade do Site do Google [diz] que SRE é“ o que acontece quando um engenheiro de software faz o que costumava ser chamado de manutenção “” . O SRE combina os desafios e os recursos da engenharia de software com os desafios da TI operacional e ajuda a encontrar soluções para problemas de confiabilidade. Entende-se que as equipes de SRE devem monitorar seus serviços para identificar áreas em que a confiabilidade pode ser melhorada.
É exatamente essa a tarefa de monitoramento para as equipes de SRE. Ocupa apenas uma pequena parte da
criação de sistemas altamente transparentes , mas esse é um elemento importante para entender o estado dos aplicativos e da infraestrutura. Quatro sinais de monitoramento dourados e SRE fornecem um nível básico de transparência em relação à confiabilidade de tudo o que você cria. Tendo atingido um nível confortável de observabilidade do estado dos sinais de ouro, você pode usar essas informações adicionais para uma análise mais aprofundada usando ferramentas de monitoramento.
Agora que decidimos sobre a importância de monitorar os sinais SRE dourados, vejamos as métricas reais que os compõem.
Quatro sinais de monitoramento dourados
No início do caminho para melhorar os esforços de monitoramento, pode ser difícil entender por onde começar. Os quatro sinais dourados de SRE e monitoramento foram citados pela primeira vez no
livro do Google sobre SRE e agora são usados ativamente por muitas equipes. É ótimo começar com eles, porque eles ajudam a destacar as principais métricas que sempre devem ser rastreadas.
Então, vejamos os sinais de ouro e vejamos por que o monitoramento deles é um elemento essencial para garantir a confiabilidade de qualquer sistema.
1. Latência
Quanto tempo leva para processar uma solicitação? Defina um ponto de referência para atrasos típicos de solicitações bem-sucedidas e compare-o com atrasos para solicitações malsucedidas. Atrasos no rastreamento causados por erros permitem resolver problemas relacionados à velocidade de detecção e resposta a incidentes.
2. Tráfego
Este sinal não requer nenhuma explicação especial. Que efeito o número de usuários ou o número de transações que passam pelo serviço têm no sistema? Dependendo da funcionalidade do serviço, a medição do tráfego pode diferir significativamente de empresa para empresa. Ao rastrear interações com usuários e tráfego reais, você pode entender melhor como os usuários finais percebem o serviço e ter uma idéia de como os sistemas se comportam sob estresse.
3. Erros
Obviamente, toda equipe deve acompanhar os erros. Independentemente de os erros serem acionados manualmente ou autônomos (como uma solicitação HTTP com falha), os comandos do SRE devem rastreá-los. Muitas equipes de SRE usam
software especial de
gerenciamento de incidentes para notificá-los sobre erros críticos, encontrar suas causas e tomar ações corretivas.
4. Saturação
Cada equipe deve monitorar a carga do seu sistema. É importante definir uma métrica para a saturação, o que significa que o serviço atingiu o máximo de seus recursos. A maioria dos serviços começa a perder desempenho mesmo antes de a carga atingir 100%, portanto, é importante entender a funcionalidade do seu próprio sistema para determinar as diretrizes de saturação que fazem sentido.
Ao configurar regras de monitoramento e alerta para os quatro sinais de ouro, você cobrirá a maioria dos principais incidentes no sistema. No entanto, para começar a criar um sistema de monitoramento proativo e o SRE, você precisa se aprofundar ainda mais.
Nota perev. : Como exemplo de ilustração de um painel com gráficos de "sinais dourados", apresentamos o resultado da configuração de monitoramento correspondente para o Kubernetes deste artigo do Sysdig :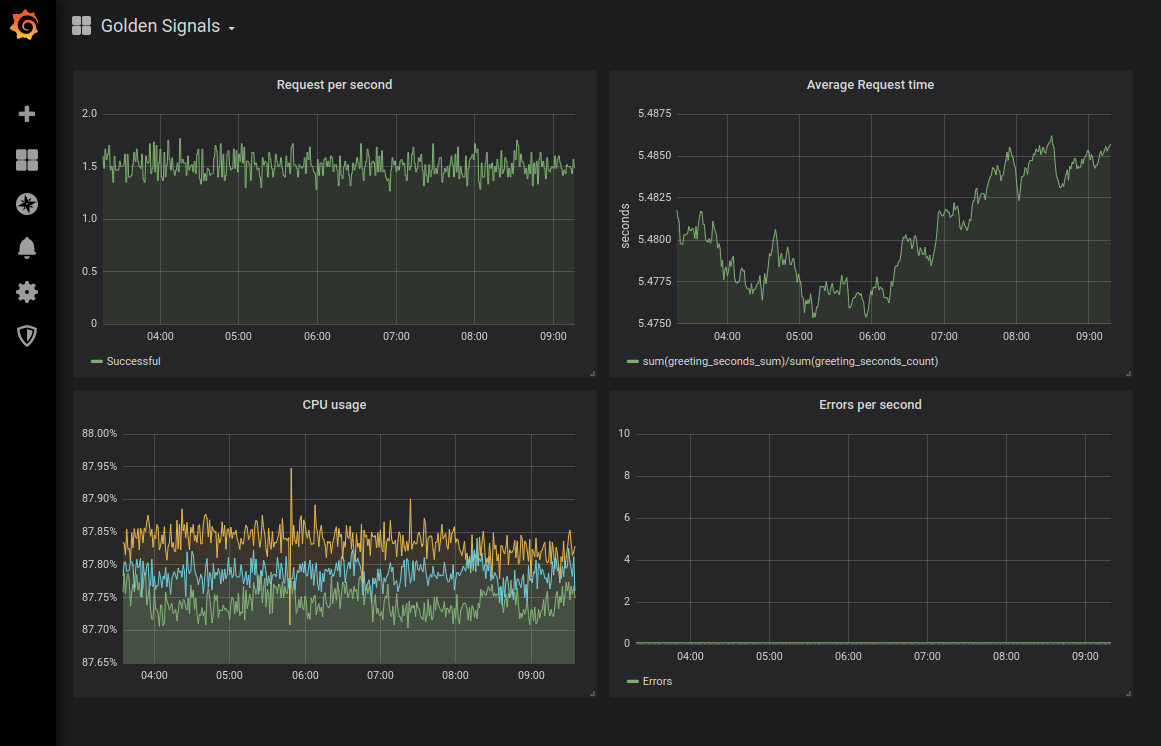 Nota perev. : E aqui está uma representação mais visual dos sinais de ouro de Denise Yu , que podem ser usados como um memorando conveniente:
Nota perev. : E aqui está uma representação mais visual dos sinais de ouro de Denise Yu , que podem ser usados como um memorando conveniente:
SRE proativo vai além dos sinais de ouro
O monitoramento de sinais dourados é um ótimo começo para analisar incidentes no serviço, mas não é suficiente. As equipes experientes de SRE exploram proativamente seus sistemas com vários métodos adicionais. Realizando testes organizados nas etapas preparatórias e na produção, as equipes de SRE estudam ativamente seus sistemas e usam as informações recebidas para aumentar a confiabilidade dos serviços.
Engenharia do caos
A engenharia do caos é uma disciplina que as equipes usam para testar seus sistemas para detectar proativamente fraquezas e vulnerabilidades. Introduzindo manualmente o caos no serviço, você pode ver como o sistema responde a várias circunstâncias.
Nota perev. : Leia mais sobre essa abordagem no artigo “Engenharia do caos: a arte da destruição intencional” ( parte 1 e parte 2 ).Dias de jogo
Enquanto a engenharia do caos se concentra na compreensão do sistema,
os dias de jogos ajudam a equipe a entender. Eles são usados para testar a resiliência da equipe quando se trata de responder a incidentes e eliminar suas consequências. Os resultados dos dias de jogos podem ser usados para desenvolver processos mais eficientes ou para determinar a necessidade de novas ferramentas que aumentem a eficiência da equipe.
Monitoramento sintético
O monitoramento sintético permite que as equipes criem usuários artificiais e simulem seu comportamento usando o serviço. Você pode definir padrões comportamentais específicos e observar como o sistema se comporta sob uma determinada carga. O monitoramento sintético é um excelente método para testes detalhados e para determinar a confiabilidade de serviços específicos em todo o sistema.
...
Qualquer equipe que procura monitorar visualmente o status do sistema é obrigada a monitorar os sinais dourados do SRE. Mas a idéia do estado e da confiabilidade geral do sistema não é a mesma coisa que trabalhar para aumentar sua confiabilidade. Em um ecossistema moderno de sistemas altamente distribuídos e implantação rápida, as equipes de SRE enfrentam uma tarefa assustadora. Sinais dourados de monitoramento e SRE podem ser o ponto de partida a partir do qual novas
melhorias no SRE começarão.
PS do tradutor
Leia também em nosso blog: