Usando dados de um sistema de gerenciamento de serviços de TI (ITSM) como exemplo.
Em um artigo anterior sobre o
SAP Process Mining ou sobre como entender nossos processos de negócios, falamos sobre o Process Mining e sua aplicação em um ambiente corporativo. Hoje queremos falar mais sobre o modelo de dados e o processo de sua preparação. Examinaremos os componentes, como eles estão interconectados, qual formato de dados solicitar dos proprietários dos dados e qual a abordagem para gerar uma tabela de eventos para o SAP Process Mining by Celonis.
Modelo de dados no SAP PROCESS MINING by CELONIS
A estrutura de dados na ferramenta SAP Process Mining by Celonis é bastante simples:
- "Tabela de eventos". Esta é uma parte necessária do modelo de dados. Essa tabela pode ser apenas uma em cada modelo de dados individual. Um gráfico de processo é gerado automaticamente nele. Veja a figura 1.
- Diretórios são quaisquer outras tabelas que expandem a "tabela de eventos" com informações analíticas adicionais. Ao contrário dela, as informações de referência não mudam com o tempo. Mais precisamente, não deve mudar no intervalo de tempo que analisamos. Por exemplo, pode ser uma tabela com uma descrição das propriedades de contratos, itens de compras, pedidos de algo, funcionários, regulamentos, contratados e outros objetos que de alguma forma estão envolvidos no processo. Nesse caso, o diretório descreverá todos os tipos de propriedades estáticas desses objetos (quantidades, tipos, nomes, nomes, tamanhos, departamentos, endereços e outros tipos de atributos). Diretórios são opcionais. Você pode executar o modelo de dados sem eles. Simplesmente analisar esse processo será menos interessante.
 Figura 1. Modelo de dados no Proces Mining: uma tabela de eventos e uma referência às instâncias do processo
Figura 1. Modelo de dados no Proces Mining: uma tabela de eventos e uma referência às instâncias do processoUma tabela de eventos é uma tabela padrão (armazenamento físico, ao contrário de tabelas lógicas) na plataforma de memória do SAP HANA. Os diretórios podem ser apresentados como tabelas padrão (armazenamento físico) e tabelas de cálculo (vistas de cálculo). Com raras exceções, pode ser necessário adicionar uma pequena referência na forma de CSV ou XLSX ao modelo de dados existente. Esse recurso existe diretamente na interface gráfica.
Abaixo, examinaremos mais de perto esses dois componentes do modelo de dados.
Uma "tabela de eventos" (também conhecida como "log de eventos") contém pelo menos três colunas obrigatórias:
- Um identificador de processo é uma chave exclusiva para cada instância do processo (por exemplo, referência, incidente ou número da tarefa). No exemplo da Figura 2, esta é a coluna "CASE_ID".
- Atividade. Esse é o nome da etapa do processo - algum tipo de evento no qual estamos interessados. É a partir das atividades que o gráfico do processo será composto (coluna "EVENTO").
- Registro de data e hora do evento (coluna "TIMESTAMP").
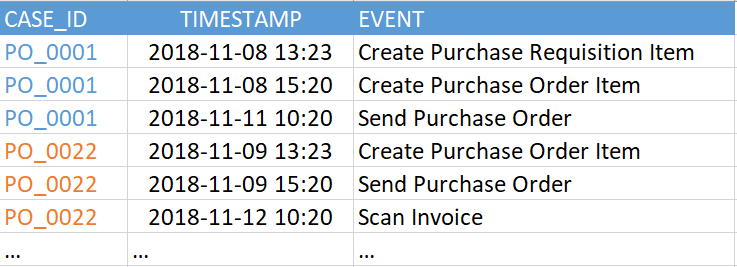 Figura 2. Exemplo de tabela de eventos
Figura 2. Exemplo de tabela de eventosA versão atual do SAP Process Mining by Celonis suporta até 1000 eventos exclusivos em um único modelo de dados. Ou seja, o número de valores exclusivos na coluna "EVENT" no exemplo acima (na sua tabela de eventos pode ser chamada de forma diferente) não deve ser superior a 1000. E os próprios eventos (ou seja, as linhas nesta tabela) podem ser bastante. Vimos exemplos de centenas de milhões de eventos em um modelo de dados.
Um registro de data e hora pode ser representado por uma coluna e, em seguida, é sua tarefa determinar o que isso significa - o início ou o final de uma etapa ou duas colunas, como na Figura 3, quando o início e o final de uma etapa são explicitamente indicados. A diferença fundamental entre a versão de duas colunas é que o sistema poderá reconhecer automaticamente as etapas executadas em paralelo. Isso é visto ao comparar os horários de início e término das várias etapas.
 Figura 3. Tabela de eventos de exemplo com dois registros de data e hora
Figura 3. Tabela de eventos de exemplo com dois registros de data e horaTodas as outras colunas nesta tabela são opcionais. O gráfico do processo também pode ser restaurado com êxito usando as três colunas necessárias, mas será difícil livrar-se da sensação de que algo está faltando. Portanto, é altamente recomendável que você não se limite apenas a um conjunto mínimo de alto-falantes.
Colunas adicionais são todas as informações que lhe interessam, que são alteradas durante o processo ou estão associadas a um evento específico. Por exemplo, o nome do funcionário que fez o evento, o grupo de trabalho, a prioridade atual do aplicativo. A ênfase na dependência do tempo não é acidental aqui. É recomendável que você deixe apenas dados mutáveis na tabela de eventos. Todas as outras informações estáticas são melhor colocadas em diretórios separados. Em outras palavras, o log de eventos deve ser normalizado, se possível. Isso é feito não tanto para reduzir a quantidade de dados, mas para facilitar o trabalho adicional com expressões PQL no estágio de criação de relatórios analíticos.
Deixe tudo estar no lugarO que acontece se você adicionar uma coluna com informações de referência à "tabela de eventos"? Em geral, nada de terrível vai acontecer, pelo menos a princípio. E para testes rápidos de qualquer ideia, essa opção é bastante adequada. Só pode haver duas consequências negativas: reprodução desnecessária de cópias de dados e dificuldades adicionais em algumas fórmulas analíticas. Essas dificuldades poderiam ter sido evitadas se todos os dados adicionais tivessem sido enviados ao diretório. Em geral, é melhor fazê-lo imediatamente.
Um pouco sobre licenciamentoA tabela de eventos está associada ao licenciamento do SAP Process Mining by Celonis. Um modelo de dados = 1 licença = 1 log de eventos. Com uma certa reserva, podemos dizer que 1 log de eventos = 1 processo de negócios. A ressalva será a seguinte: situações podem surgir quando vários processos se encaixam em um log de eventos e vice-versa - vários logs de eventos são criados intencionalmente para um processo. Além disso, o termo “processo de negócios” pode ser interpretado do ponto de vista dos dados de maneira bastante ampla. Portanto, para fins de licenciamento, pelo critério óbvio, o número de logs de eventos foi selecionado. É nesse critério que se deve confiar.
DiretóriosDiretórios são opcionais, adicioná-los ao modelo de dados é opcional. Eles contêm informações adicionais que podem ser úteis para a análise do processo. Mas, diferentemente da tabela de eventos, as informações nos diretórios são estáticas, não dependem da hora em que o evento ocorreu.
Um caso em particular deve ser mencionado aqui. Quando se trata dos dados do usuário executando as etapas do processo de negócios, surge a pergunta: essa informação é referência? Por um lado, sim - são dados estáticos. Seria bom deixar na tabela de eventos apenas um determinado "USER_ID", segundo o qual o nome completo, cargo e departamento do usuário, participação no grupo de trabalho etc. Mas, por outro lado, vamos imaginar que analisamos um processo de negócios em um período de 2 a 3 anos. Durante esse período, o usuário pode alterar várias postagens e alternar entre departamentos ou grupos de trabalho. Acontece que esta é uma informação que já está mudando ao longo do tempo. E, nesse caso, ele deve ser deixado na tabela de eventos, o que, por sua vez, levará ao fato de que, além de "USER_ID" no log de eventos, aparecerão colunas como "grupo de trabalho", "posição", "departamento" e até mesmo "nome completo" (sobrenome também pode mudar durante esse período). Em geral, a questão de normalizar ou não as informações do usuário permanece a critério do cliente.
Os diretórios podem ser adicionados a um modelo de dados existente a qualquer momento.
Para fazer isso é bastante simples:
- Uma tabela é criada no SAP HANA.
- A tabela é adicionada ao modelo de dados geral usando o botão "Importar dados".
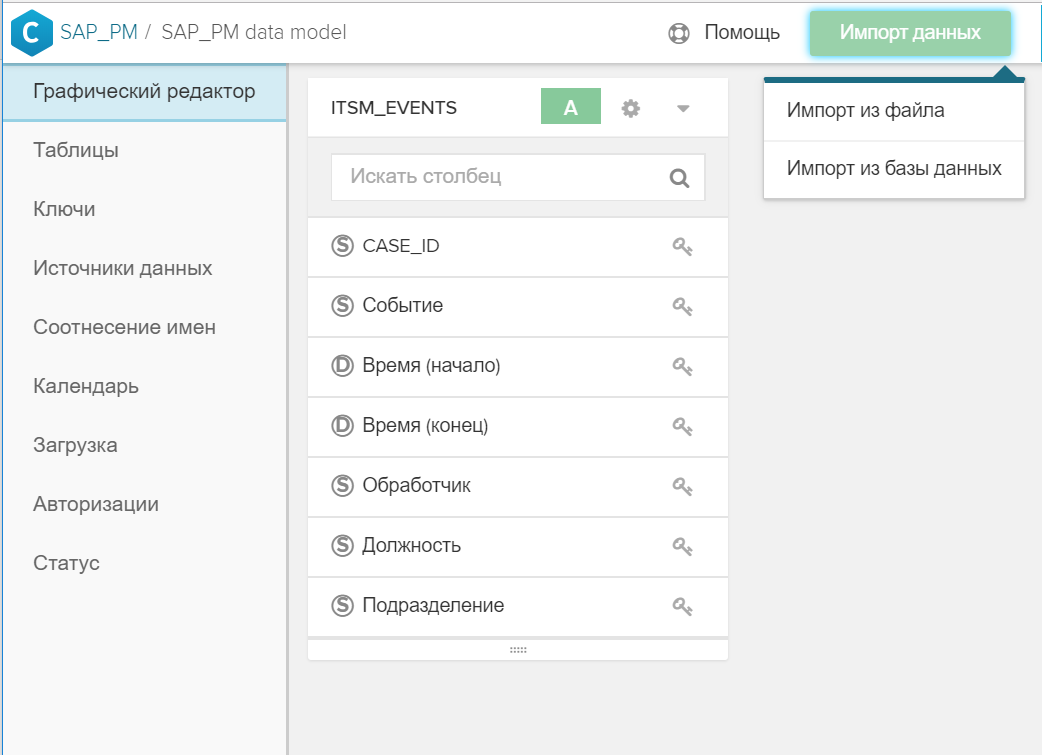
Figura 4. Importar uma tabela ou arquivo para um modelo de dados existente - A chave (ou chaves) é indicada na interface gráfica, pela qual o novo diretório é associado à tabela de eventos e / ou a outros diretórios. Para fazer isso, basta clicar no ícone
 em uma tabela e depois no correspondente em outra mesa.
em uma tabela e depois no correspondente em outra mesa.
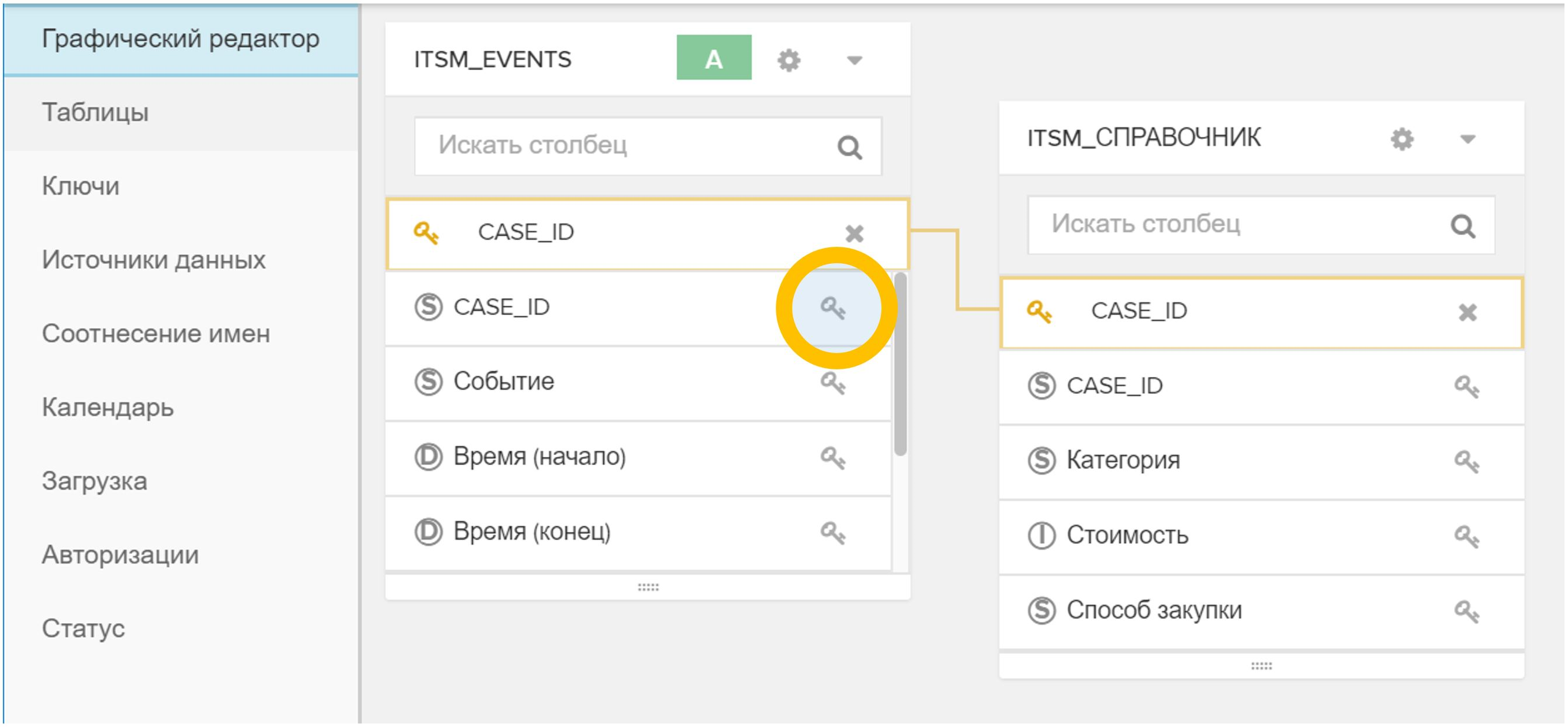
Figura 5. Vinculando tabelas em um modelo de dados por um campo arbitrário (neste caso, CASE_ID) - No menu "Status", clique no botão "Recarregar da fonte". Esse processo geralmente leva alguns segundos.
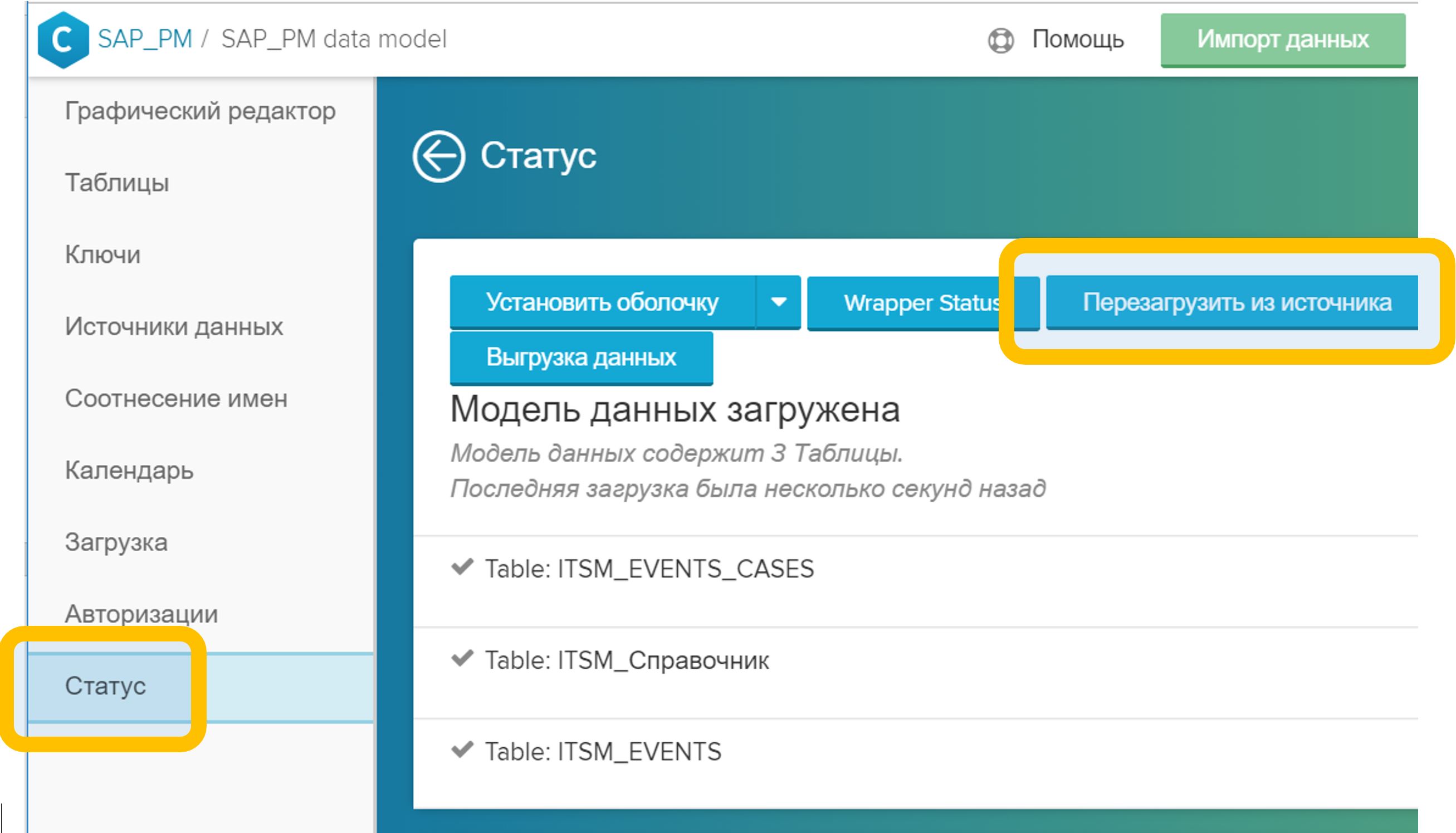 Figura 6. Recarregando o modelo de dados da origem
Figura 6. Recarregando o modelo de dados da origem
Depois de concluir essas etapas, você pode usar imediatamente novas análises, tanto em novos relatórios quanto em existentes. O enriquecimento do modelo de dados não prejudica o trabalho atual dos analistas de forma alguma: todos os relatórios criados continuam funcionando, eles não precisam ser refeitos ou alterados de alguma forma.
Para diretórios relativamente pequenos, há mais uma possibilidade: não uma versão completamente industrial, é claro, mas também pode ser útil. Trata-se de carregar arquivos CSV, XLSX, DBF por meio de uma interface gráfica diretamente no modelo de dados. O procedimento permanece exatamente igual ao descrito acima; somente, em vez das tabelas do banco de dados, é usado um arquivo preparado previamente, carregado com o botão Importar Dados.
Tabela da CA: Referência da instância do processoA conversa anterior sobre livros de referência começou com o fato de serem opcionais. Eles podem ser omitidos completamente do modelo de dados e limitados a uma tabela de eventos. Isso é quase verdade.
Existe uma referência obrigatória. Essa deve ser uma tabela marcada com o status "Tabela da CA". CAs são cadeias de eventos. E, você adivinhou, a chave neste diretório será "CASE_ID" - o identificador exclusivo da instância do processo. Essa referência descreve as propriedades estáticas de instâncias de processos individuais. Um exemplo do ITSM: o autor da apelação, um serviço comercial, a data de fechamento ou o funcionário que resolveu o incidente com sucesso, um sinal de caráter em massa etc.
 Figura 7. Tabela CA de exemplo
Figura 7. Tabela CA de exemploE, no entanto, não te enganei muito. Se, por algum motivo, você decidir não incluir o diretório necessário no modelo de dados, o sistema o gerará. O resultado de seu trabalho pode ser visto na guia Status: se sua tabela de eventos for chamada, digamos, "ITSM_EVENTS", a tabela "ITSM_EVENTS_CASES" será gerada em conjunto com ela, como na Figura 8.
Figura 8. Tabela da cadeia de eventos gerada automaticamenteUma tabela de CA gerada automaticamente será uma descrição muito simples das instâncias do processo: chave, número de eventos, duração do processo (como se você agrupasse uma tabela de eventos por um identificador de processo, calculasse o número de linhas e a diferença entre a hora da primeira e da última etapa). Portanto, faz sentido criar sua própria versão mais interessante da tabela da CA. Ele pode ser adicionado ao modelo de dados a qualquer momento. Ao mesmo tempo, assim que você adicionar sua tabela CA ao modelo, o diretório gerado pelo sistema (no nosso caso, é "ITSM_EVENTS_CASES") será excluído automaticamente do modelo de dados.
Por que a “Tabela CA” é interessante? É ela quem é exibida na interface gráfica como um detalhe do processo. Se o analista, enquanto trabalhava com o modelo de dados, encontrou algo interessante no processo e quis ir para exemplos específicos individuais, ele usará o relatório "Visualizar CA", ou seja, detalhando. Depois de abrir esse relatório, você encontrará nele um diretório do processo (combinado com uma tabela de eventos, é claro). Portanto, adicione à "Tabela CA" tudo o que o analista pode usar para entender as propriedades do processo e as condições de seu curso.
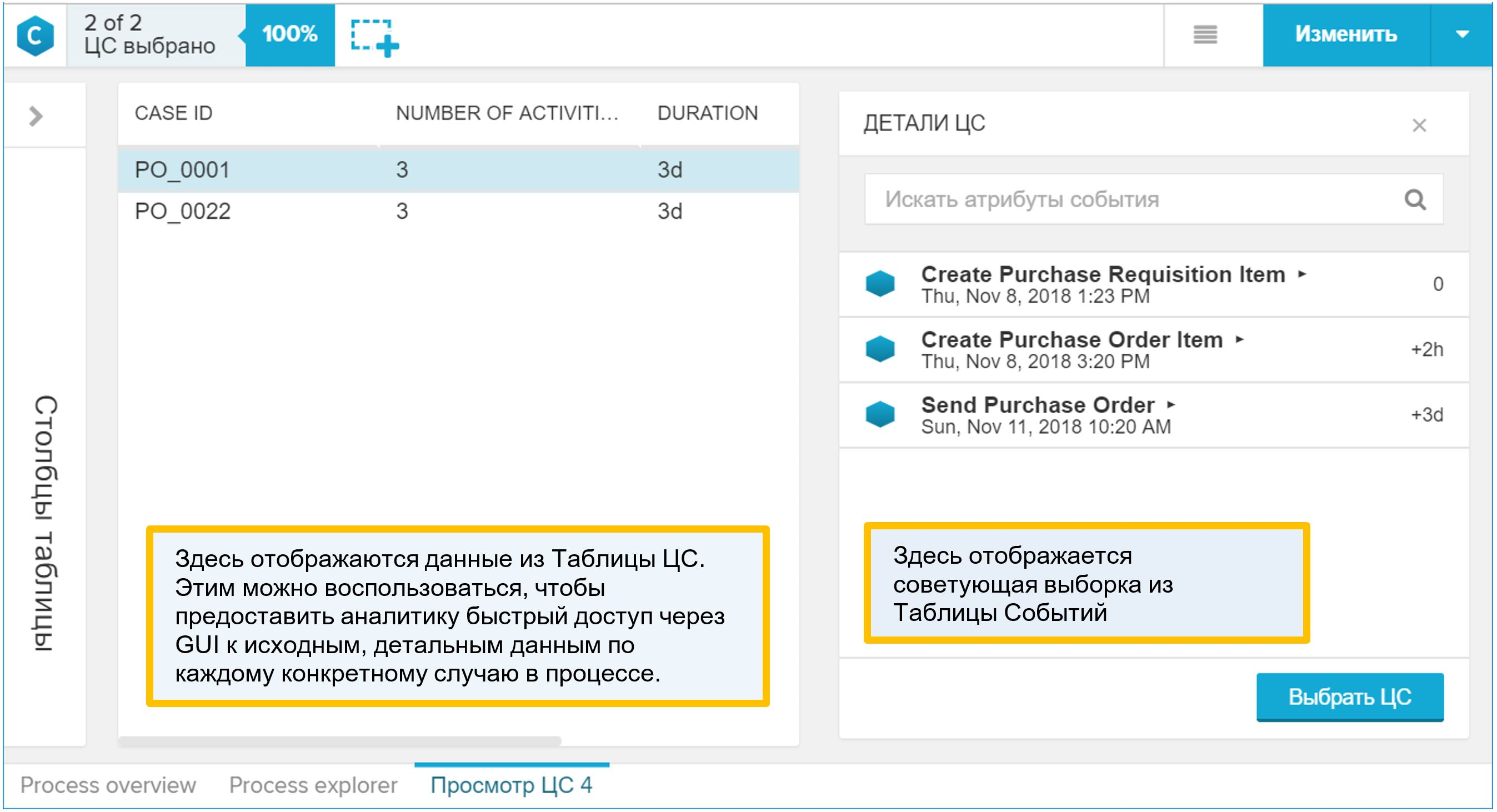 Figura 9. Relatório de exemplo sintético “View CA”
Figura 9. Relatório de exemplo sintético “View CA”Como adicionar sua referência de processo ao modelo de dados:
- Uma tabela é criada no SAP HANA.
- A tabela é adicionada ao modelo de dados geral usando o botão "Importar dados".
- Na interface gráfica, nas propriedades da tabela, você precisa definir a função "Tabela com CA".
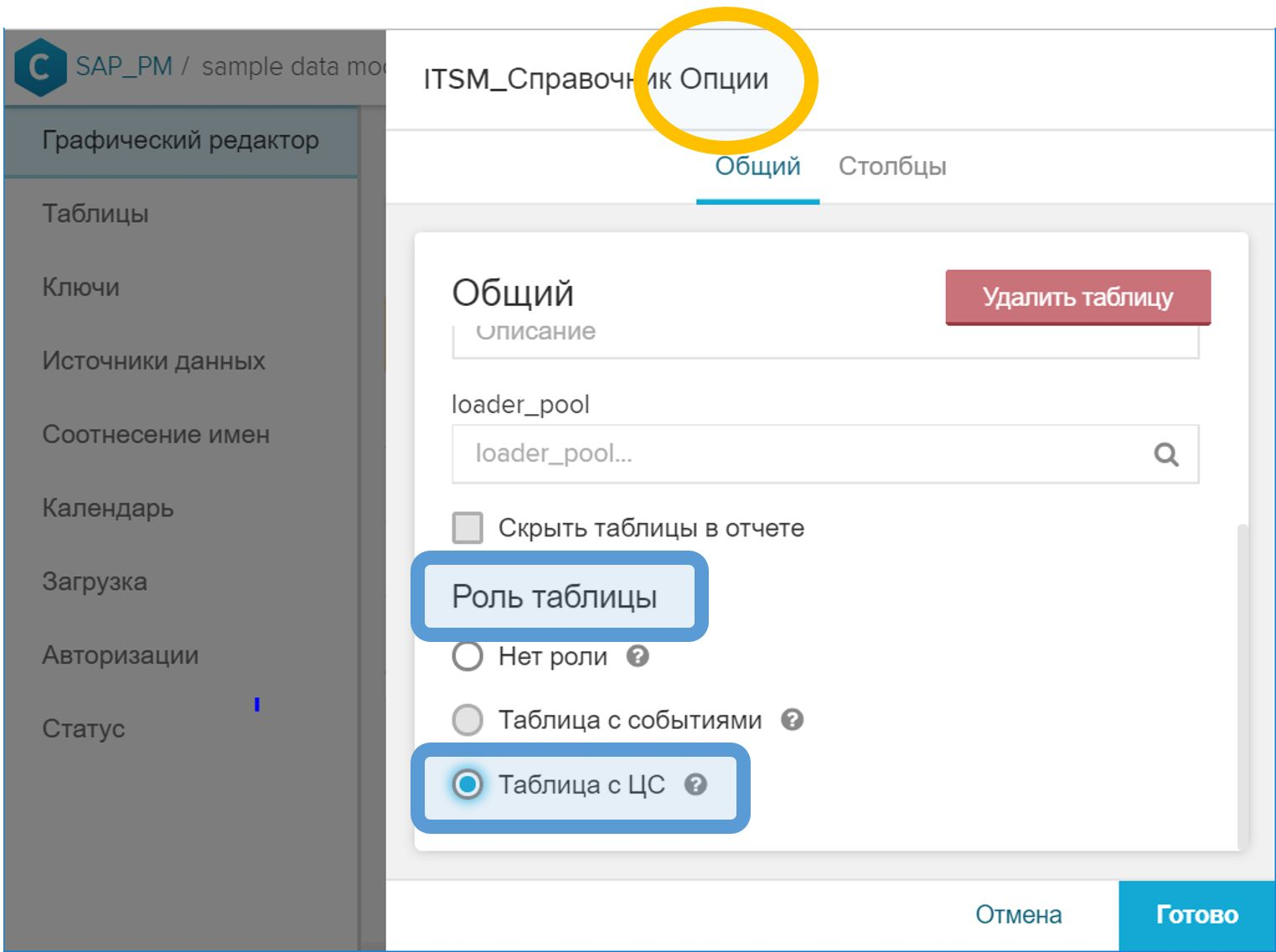
Figura 10. A função de "Tabela com CA" para indicar o diretório de instâncias do processo - Na GUI, associe a tabela CA à tabela de eventos pelo ID do processo. Esta etapa é executada da mesma maneira que no caso de um diretório regular - com a tecla do símbolo de chave ( ) oposto ao campo correspondente.
- No menu "Status", clique no botão "Recarregar da fonte".
Nota importante: a coluna “CASE_ID” (em cada caso, pode ser chamada de outra forma) na tabela CA, que contém o identificador do processo e é usada para associar à tabela de eventos, deve conter apenas valores exclusivos. Isso é bastante lógico. E se, por algum motivo, não for assim, ao carregar o modelo de dados na etapa (5), o erro correspondente será gerado (sobre a impossibilidade de executar a operação "JOIN" na tabela de eventos e na tabela CA).
Criando um modelo de dados a partir do histórico de alterações
Na prática, encontramos fontes de dados muito diferentes para a Mineração de Processos. Sua composição é determinada pelo processo de negócios selecionado e pelos padrões adotados pelo cliente.
Um dos casos mais comuns são os dados do sistema de gerenciamento de serviços de TI (ITSM, IT Service Management), por isso decidimos analisar este exemplo primeiro. De fato, não há uma ligação restrita especificamente ao ITSM nessa abordagem. Pode ser aplicado em outros processos de negócios, nos quais a fonte de dados é um histórico de alterações ou um log de auditoria.
O que perguntar da TI?Se você não é um funcionário de TI ou o especialista que presta serviços de base ao ITSM, esteja preparado para o fato de ser solicitado a formular uma resposta exata para a pergunta "o que você descarrega?" ou "o que você quer de nós?"
E isso nem sempre é conhecido - o que exatamente é necessário. A análise do processo de negócios é um estudo, uma pesquisa de padrões e a busca por "insights". Se soubéssemos antecipadamente que tipo de “insight” estamos procurando, então esse não seria mais um “insight”. Na verdade, eu gostaria de obter "tudo": atributos, relacionamentos, mudanças. Mas, como mostra a prática, nunca foi possível obter uma boa resposta precisa a uma pergunta muito geral.
Existem duas respostas possíveis para a pergunta "o que você descarrega".
A opção está errada: peça à base para descarregar todas as alterações nos status do aplicativo, além de um conjunto de atributos óbvios (por exemplo, prioridade, artista, grupo de trabalho etc.). Em primeiro lugar, você recebe um conjunto limitado de analistas: você já sabe o que medirá no processo (é daí que veio o conjunto de atributos); portanto, a Process Mining se tornará uma ferramenta para calcular o KPI do processo (é muito conveniente, devo dizer, uma ferramenta; mas ainda quero mais).
Em segundo lugar, cada departamento de TI individual interpreta de maneira diferente a solicitação para adicionar atributos de solicitação adicionais ao upload. Por exemplo, tenha prioridade: ele pode mudar durante o trabalho em uma chamada. O recurso é registrado com uma prioridade; o especialista do grupo de trabalho o altera e fecha com um status diferente. E agora a pergunta é: na descarga solicitada por você, que momento corresponde à prioridade? Inicialmente, parece que o valor da prioridade deve corresponder à coluna "Data e hora do evento". Mas, na realidade, muitas vezes acontece que apenas o status da solicitação corresponde à data e hora especificadas e todas as outras colunas são os valores no momento do descarregamento ou no momento do fechamento da solicitação. E você não saberá sobre isso de uma só vez.
Parece-me que existe uma opção melhor. Você pode solicitar dados no formato da tabela a seguir:
- O número da apelação, incidente, tarefa (SD *, IM *, RT *, ...) é o identificador do objeto no sistema ITSM (NVARCHAR)
- Registro de data e hora (TIMESTAMP)
- Nome do atributo (NVARCHAR)
- Valor antigo (NVARCHAR)
- Novo valor (NVARCHAR)
- Quem mudou (NVARCHAR)
De fato, isso nada mais é do que um histórico de alterações em quaisquer atributos. Nas interfaces dos sistemas ITSM, você pode ver essa tabela nas guias com o nome "Histórico" ou "Diário".
As vantagens dessa abordagem são óbvias:
- Formato de upload simples e claro. Ele conhece os profissionais de TI na interface gráfica do próprio sistema. Não deve causar perguntas a partir da base.
- Nós obtemos uma lista de todos os atributos possíveis com todos os valores possíveis. Sim, haverá muitos deles, provavelmente várias centenas. Mas filtrar o desnecessário e o desinteressante é muito simples, mas sempre que solicitar descarregamentos adicionais nem sempre é simples e sempre longo (especialmente quando você não sabe quais atributos estão presentes no sistema).
- Este é um modelo de dados confiável. É difícil estragá-lo, a menos que você faça informações falsas intencionalmente.
- Sabemos exatamente o que cada atributo tinha a cada momento no tempo. Isso é importante porque testamos a nós mesmos e garantimos que o modelo esteja correto. E durante a análise, podemos adicionar etapas intermediárias ao modelo ("ampliar") e determinar os valores de atributo corretos em todos os pontos adicionais no tempo.
As desvantagens da segunda opção também são claras. E eles, ao que me parece, podem ser resolvidos (em oposição ao problema de dados incompletos):
- O script SQL para preparar os dados se torna um pouco mais complicado - comparado à opção quando a equipe de base de TI faz a preparação parcial dos dados para você (consulte a primeira versão da consulta acima), sem suspeitar disso. Sim, ele (o roteiro) é mais complicado, mas ele está sozinho. Eu acho que seria uma má idéia compartilhar a preparação de dados entre a equipe de ITSM e a equipe de Mineração de Processos. Idealmente, toda a transformação deve ser transferida para a equipe do Process Mining, para que eles entendam exatamente o que está acontecendo com os dados e para minimizar a interferência com os dados no lado da fonte. Um formato simples de troca de dados ajuda a atingir esse objetivo.
- O volume de descarga é grande. O pedido pode ser o seguinte: 10 a 30 GB / ano para uma grande empresa. Mas carregar esse volume no HANA não é um problema e nem sequer é considerado uma tarefa. Além disso, falamos sobre "upload" apenas durante o projeto piloto, enquanto a integração ETL / ELT entre a fonte de dados e o HANA (por exemplo, HANA Smart Data Integration) será usada na operação industrial, e esse item deixará de ser importante.
Eu não gostaria de dizer que esta é a única maneira correta de obter dados do sistema ITSM para tarefas de Mineração de Processos. Mas, atualmente, estou inclinado a acreditar que este é o formato mais conveniente para esta tarefa. Provavelmente existem abordagens muito mais interessantes, e ficarei muito feliz em discutir idéias alternativas, se você as compartilhar comigo.
Geração de tabela de eventos
Portanto, na saída, temos um histórico de alterações nos atributos de solicitações, incidentes, chamadas, tarefas e outros objetos ITSM. A partir dessa tabela, é possível gerar os dois principais componentes do modelo de dados do Process Mining: uma tabela de eventos e uma tabela de CA.
Para gerar eventos com base no histórico de alterações, faça o seguinte:
- No histórico de alterações, colete todos os valores exclusivos da coluna (condicionalmente) "nome do atributo".
- Determine a mudança nos atributos que você gostaria de ver no gráfico do processo. O que é um "evento" para nós?
- Crie uma exibição de cálculo apropriada ou escreva um script SQL que filtre as linhas selecionadas do histórico de alterações e gere uma tabela de eventos.
Suponha que a tabela de alterações seja a seguinte:
CREATE COLUMN TABLE "SAP_PM"."ITSM_HISTORY" ( "CASE_ID" NVARCHAR(256), "ATTRIBUTE" NVARCHAR(256), "VALUE_OLD" NVARCHAR(1024), "VALUE_NEW" NVARCHAR(1024), "TS" TIMESTAMP, "USER" NVARCHAR(256) );
Primeiro, veja a lista de todos os atributos presentes. Isso pode ser feito no menu "Abrir visualização de dados" ou com uma simples consulta SQL como esta:
SELECT DISTINCT "ATTRIBUTE" FROM "SAP_PM"."ITSM_HISTORY";
 Figura 11. Menu de contexto com o comando Open Data Preview no SAP HANA Studio
Figura 11. Menu de contexto com o comando Open Data Preview no SAP HANA StudioEm seguida, determinamos a composição dos atributos, cuja mudança é para nós um evento no processo. Aqui está uma lista de candidatos óbvios para essa lista:
- Status
- Foi levado para o trabalho
- Categoria foi alterada
- Prazo violado
- O tempo de reação é violado
- A solicitação foi retornada para revisão.
- Erro na 1ª linha
- Grupo de trabalho
- Prioridade
Os principais eventos aqui, é claro, são as transições entre os status da apelação / incidente \ aplicativo \ tarefa. O valor do atributo "Status" (VALUE_NEW) será o nome da etapa do processo para nós. Por conseguinte, a criação de uma tabela de eventos como primeira aproximação pode ser assim:
CREATE COLUMN TABLE "SAP_PM"."ITSM_EVENTS" ( "CASE_ID" NVARCHAR(256) ,"EVENT" NVARCHAR(1024) ,"TS" TIMESTAMP ,"USER" NVARCHAR(256) ,"VALUE_OLD" NVARCHAR(1024) ,"VALUE_NEW" NVARCHAR(1024) ); INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"VALUE_NEW" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' ;
Alterar o restante dos atributos são nossas etapas adicionais que tornam a pesquisa do processo ainda mais interessante. Sua composição é determinada pela solicitação de um analista de negócios e pode mudar à medida que a prática da Process Mining na empresa se desenvolve.
INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"ATTRIBUTE" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "VALUE_OLD" IS NOT NULL AND "ATTRIBUTE" IN ( ' ' ,' ' ,' ' ,' ' ,' ' ,' 1- ' ,' ' ,'') );
Expandindo a lista de atributos no filtro WHERE "ATTRIBUTE" IN (.....), você aumenta a variedade de etapas exibidas no gráfico do processo. Vale a pena notar que uma grande variedade de etapas nem sempre é uma bênção. Às vezes, detalhes muito detalhados dificultam a compreensão do processo. Penso que após a primeira iteração, você determinará quais etapas são necessárias e quais devem ser excluídas do modelo de dados (e a liberdade de tomar essas decisões e se adaptar rapidamente a elas é outro argumento a favor da transferência do trabalho de transformação de dados para o lado da equipe do Process Mining) .
O filtro "VALUE_OLD" NÃO É NULL, provavelmente você o substituirá por algo mais adequado às suas condições e aos atributos selecionados. Vou tentar explicar o significado desse filtro. Em algumas implementações populares de sistemas ITSM, no momento do registro (abertura) de uma apelação, são inseridas no diário informações sobre a inicialização de todos os atributos do objeto. Ou seja, todos os campos são marcados com alguns valores padrão. Nesse momento, VALUE_NEW conterá o mesmo valor de inicialização e VALUE_OLD não conterá nada - afinal, não havia histórico até o momento. Nós absolutamente não precisamos desses registros no processo. Eles devem ser removidos com um filtro apropriado às suas condições específicas. Esse filtro pode ser:
- "VALUE_OLD" NÃO É NULL
- "VALUE_NEW" = 'sim'
- Você pode se concentrar no carimbo de data / hora (faça apenas os eventos que ocorreram após o registro do objeto).
- Você pode se concentrar no campo "USUÁRIO" se a conta do sistema estiver inicializando.
- Quaisquer outras condições apresentadas.
Geração de tabela CA
O mesmo histórico de alterações que nos serviu como fonte de eventos também será útil para criar um diretório de instâncias de processo (Tabelas da CA). Algoritmo semelhante:
1. Defina uma lista de atributos que:
a. Não altere durante o trabalho no aplicativo, por exemplo, o autor do recurso e seu departamento, a classificação do usuário com base nos resultados do trabalho, a bandeira da violação do prazo.
b. Eles podem mudar, mas estamos interessados apenas nos valores em determinados momentos: no momento do registro, fechamento, contratação, transferência da 2ª linha para a 1ª, etc.
c. Eles podem mudar, mas estamos interessados apenas em valores agregados (máximo, mínimo, quantidade etc.)
2. Crie uma tabela diagonal com o conjunto de colunas desejado. Cada atributo que nos interessa gerará seu próprio conjunto de linhas (de acordo com o número de instâncias do processo), nas quais apenas uma coluna terá um valor e todo o restante ficará vazio (NULL).
3. Recolhemos a tabela diagonal no diretório final usando o agrupamento por identificador de processo.
Exemplos de atributos que faz sentido colocar na tabela da CA (na prática, esta lista pode ser muito mais longa):
- Serviço
- Sistema de TI
- O autor
- Organização do autor
- Classificação do usuário da qualidade da solução
- Número de retornos ao trabalho
- Quando foi levado para o trabalho
- Criado por
- Quem fechou
- Resolvido pela linha 1
- Classificação / roteamento inválido
- Prazo
- Violação de prazo
Um e o mesmo atributo pode ser uma fonte de um evento em um processo ou uma propriedade de uma instância de processo. Por exemplo, o atributo "Prioridade". Por um lado, estamos interessados em sua importância no momento do registro do recurso e, por outro lado, todos os fatos de alterações nesse atributo podem ser submetidos ao gráfico do processo como etapas independentes.
Outro exemplo é o prazo. Essa é uma propriedade de referência óbvia do processo, mas você pode fazer uma etapa virtual no gráfico do processo: uma operação como o "Prazo final" não existe no processo, mas se adicionarmos a entrada correspondente à Tabela de Eventos, a criaremos artificialmente e poderemos visualizar o local em relação a tempo de execução de outras etapas diretamente no gráfico do processo. Isso é conveniente para análise rápida.
Em geral, quando criamos propriedades do processo com base no histórico de alterações de atributos, a fonte de informações úteis para nós pode ser:
- Valor do atributo em si (exemplo: "Classificação do usuário")
- Usuário que mudou
- Mudar tempo
- O horário em que o atributo assumiu um determinado valor (exemplo: o atributo "Prazo violado" não está interessado no próprio valor do atributo, mas no momento em que ele muda para o equivalente da bandeira levantada - por exemplo, 'yes' ou 1)
- O fato de o atributo estar presente no histórico (exemplo: “Incidente em massa” com o valor 'yes')
Esta lista, é claro, pode ser continuada com outras idéias para o uso de atributos e tudo o que está relacionado a eles.
Agora que já decidimos a lista de propriedades de interesse, vejamos um dos cenários possíveis para gerar a tabela de CA. Primeiro, crie a própria tabela com o conjunto de colunas que definimos acima para nós mesmos:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES" ( "CASE_ID" NVARCHAR(256) NOT NULL ,"CATEGORY" NVARCHAR(256) DEFAULT NULL ,"AUTHOR" NVARCHAR(256) DEFAULT NULL ,"RESOLVER" NVARCHAR(256) DEFAULT NULL ,"RAITING" INTEGER DEFAULT NULL ,"OPEN_TIME" TIMESTAMP DEFAULT NULL ,"START_TIME" TIMESTAMP DEFAULT NULL ,"DEADLINE" TIMESTAMP DEFAULT NULL );
Também precisaremos de uma tabela temporária “ITSM_CASES_STAGING”, que nos permitirá classificar uma lista simples de atributos para as colunas de propriedades necessárias no diretório de instâncias do processo:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES_STAGING" LIKE "SAP_PM"."ITSM_CASES" WITH NO DATA;
Essa será uma tabela diagonal - em cada linha, apenas dois campos têm um valor: "CASE_ID", ou seja, identificador de processo e um único campo com uma propriedade de processo. Os campos restantes na linha estarão vazios (NULL). No estágio final, recolhemos facilmente as diagonais em linhas por agregação simples e, assim, obtemos a tabela de CAs necessárias.
Um exemplo para uma categoria de tratamento:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "CATEGORY") SELECT "CASE_ID", LAST_VALUE("VALUE_NEW" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' GROUP BY "CASE_ID" ;
Suponha que o autor seja o primeiro usuário que não seja do sistema no histórico do recurso que registra recursos (no seu caso particular, o critério pode ser mais preciso):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "AUTHOR") SELECT "CASE_ID", FIRST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "USER" != 'SYSTEM' GROUP BY "CASE_ID" ;
Se acreditarmos que o manipulador que colocou o último status "Solução proposta" (e a solução pudesse ser oferecida repetidamente, mas apenas a última foi corrigida) resolveu o problema com êxito, essa propriedade da instância do processo pode ser formulada da seguinte maneira:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RESOLVER") SELECT "CASE_ID", LAST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' AND "VALUE_NEW" = ' ' GROUP BY "CASE_ID" ;
Classificação do usuário (sua satisfação com a decisão):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RAITING") SELECT "CASE_ID", TO_INTEGER(LAST_VALUE("VALUE_NEW" ORDER BY "TS")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND "VALUE_NEW" IS NOT NULL GROUP BY "CASE_ID" ;
O momento do registro (criação) é simplesmente o registro mais antigo da história da circulação:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "OPEN_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" GROUP BY "CASE_ID" ;
O tempo de reação é uma característica importante da qualidade dos serviços. Para calculá-lo, você precisa saber quando a bandeira "Foi levada ao trabalho" foi levantada pela primeira vez:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "START_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' = '' GROUP BY "CASE_ID" ;
O prazo é usado para calcular KPIs para respostas oportunas a recursos ou resolução de incidentes. No processo, o prazo pode mudar repetidamente. Para calcular KPIs, precisamos conhecer a versão mais recente desse atributo. Se quisermos controlar explicitamente como o prazo mudou, ou seja, para exibir esses casos no gráfico do processo, também devemos usar esse atributo para gerar uma entrada na tabela de eventos. Este é um exemplo de atributo, que serve simultaneamente como uma propriedade do processo e a fonte do evento.
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "DEADLINE") SELECT "CASE_ID", MAX(TO_DATE("VALUE_NEW")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' IS NOT NULL GROUP BY "CASE_ID" ;
Todos os exemplos acima são do mesmo tipo. Por analogia com eles, a tabela CA pode ser expandida com quaisquer atributos que lhe interessam. Além disso, isso já pode ser feito após o início do projeto, o sistema permite expandir o modelo de dados durante sua operação.
Quando nossa tabela diagonal temporária é preenchida com as propriedades das instâncias do processo, tudo o que resta é fazer a agregação e obter a tabela CA final:
INSERT INTO "SAP_PM"."ITSM_CASES" SELECT "CASE_ID" ,MAX("CATEGORY") ,MAX("AUTHOR") ,MAX("RESOLVER") ,MAX("RAITING") ,MAX("OPEN_TIME") ,MAX("START_TIME") ,MAX("DEADLINE") FROM "SAP_PM"."ITSM_CASES_STAGING" GROUP BY "CASE_ID" ;
Depois disso, não precisamos mais dos dados na tabela temporária. A tabela em si pode ser deixada para continuar repetindo o processo acima regularmente para atualizar o modelo de dados no Process Mining:
DELETE FROM "SAP_PM"."ITSM_CASES_STAGING";
Dicas para preparar e limpar arquivos CSV para um projeto piloto
Você provavelmente começará a conhecer a disciplina Process Mining com um projeto piloto. Nesse caso, não é possível obter acesso direto à fonte de dados; os funcionários de TI e os responsáveis pela segurança da informação resistirão a isso. Isso significa que, como parte do projeto piloto, teremos que trabalhar com a exportação de dados de sistemas corporativos para arquivos CSV e depois importá-los para o SAP HANA para criar um modelo de dados.
Em uma instalação industrial, não haverá exportações para CSV. Em vez disso, serão utilizadas as ferramentas de integração do SAP HANA, em particular: SDI (Smart Data Integration), SDA (Smart Data Access) ou SLT (SLT). Porém, para testar e familiarizar-se com a tecnologia, exportar para arquivos de texto CSV é um método organizacional mais simples. Portanto, será útil compartilhar com você algumas dicas para preparar dados em CSV para importação rápida e bem-sucedida no banco de dados.
Requisitos de formato recomendados para o próprio arquivo ao exportar:
- Formato de arquivo: CSV
- Codificação: UTF8
- Separador de campo: qualquer caractere conveniente para você. Por exemplo, "|" ou "^" ou "~". A lógica da escolha é simples - devemos tentar evitar a situação em que a “divisão” está contida nos próprios dados.
- É necessário remover o separador dos valores do campo. Sim, você pode dizer que, para isso, de fato, existem aspas. Mas, como mostra a experiência, entre aspas também surgem muitos problemas. Em geral, vamos remover (ou substituir) o caractere separador dos valores do campo. Seu projeto piloto não sofrerá muito com essa imprecisão, mas o tempo para a preparação dos dados é notavelmente economizado.
- Aspas: remova todas as aspas do valor do campo. As aspas são frequentemente encontradas nos nomes das empresas - por exemplo, Kalinka LLC. Mas existem essas opções: MPZ Kalinka LLC. E agora esta é uma grande dificuldade. As aspas nos valores do campo devem ser acompanhadas pelo símbolo "\" ou removidas, substituídas por outra coisa. É mais confiável simplesmente removê-lo. O valor do campo não sofrerá muito com isso.
- Transferências de carro: remova todos os caracteres CHAR (10) e CHAR (13) dos valores do campo. Caso contrário, a importação do CSV será impossível.
Se considerarmos os pontos (4) + (5) + (6), faz sentido usar a seguinte construção na seleção:
REPLACE(REPLACE(REPLACE(REPLACE("COLUMN", '|', ';'), '"', ''), CHAR(13), ' '), CHAR(10), ' ') as "COLUMN"
Além disso, quando os arquivos CSV estiverem prontos, eles precisarão ser copiados para o servidor HANA em uma pasta declarada segura para a importação de arquivos (por exemplo, / usr / sap / HDB / import). A importação de dados no HANA de um arquivo CSV local é um procedimento bastante rápido, desde que o arquivo esteja "limpo":
- cada linha da tabela futura está em uma e apenas uma linha do arquivo;
- o número de colunas em todas as linhas é o mesmo;
- as aspas estão emparelhadas ou ausentes;
- aspas nos valores do campo acompanham o símbolo "escape" "\" ou estão ausentes;
- Codificação UTF-8 (e não UTF8-BOM, como acontece ao exportar para sistemas Windows).
Para verificar os arquivos CSV antes de importá-los e encontrar áreas problemáticas, se elas existirem (e com uma probabilidade de 99%), você pode usar os seguintes comandos:
1. Verifique o caractere da lista técnica no início do arquivo:
arquivo data.csv
Se o resultado do comando for assim: “Texto UTF-8 Unicode (com BOM)”, significa que a codificação é UTF8-BOM e você precisará remover o caractere BOM do arquivo. Você pode removê-lo da seguinte maneira:
sed -i '1s / ^ \ xEF \ xBB \ xBF //' data.csv
2. O número de colunas deve ser o mesmo para cada linha do arquivo:
cat data.csv
| awk -F »;" '{print NF}' | sort | uniqou assim:
para i em $ (ls * .csv); ecoam $ i; gato $ i | awk -F ';' '{print NF}' | classificar | uniq -c; eco; feito;Alterar ';' no parâmetro F, qual é o separador de campos no seu caso.
Como resultado desses comandos, você obtém a distribuição das linhas pelo número de colunas em cada linha. Idealmente, você deve obter algo parecido com isto:
EKKO.csv
79536 200
Aqui, o arquivo contém 79536 linhas e todas elas contêm 200 colunas. Não há linhas com um número diferente de colunas. Deveria ser assim.
E aqui está um exemplo de resultado incorreto:
LFA1.csv
73636 180
7 181
Aqui vemos que a maioria das linhas contém 180 colunas (e, provavelmente, este é o número correto de colunas), mas há linhas com a 181ª coluna. Ou seja, um dos campos contém um sinal separador em seu valor. Tivemos sorte e existem apenas 7 partes dessas linhas - elas podem ser facilmente visualizadas manualmente e de alguma forma corrigidas. Você pode ver as linhas nas quais o número de colunas não é igual a 180, assim:
cat data.csv
| awk -F ";" '{if (NF! = 180) {print $ 0}}'Uma observação sobre o uso dos comandos acima. Esses comandos não prestarão atenção às aspas. Se o sinal do separador estiver contido no campo entre aspas (e isso significa que tudo está bem aqui do ponto de vista da importação para o banco de dados), a verificação com esse método mostrará um problema falso (colunas extras) - isso também deve ser levado em consideração na análise dos resultados.
3. Se as aspas não estiverem emparelhadas e não puderem resolver esse problema, você poderá excluir todas as aspas do arquivo:
sed -i 's / "// g' data.csv
O perigo dessa abordagem é que, se os valores do campo contiverem um caractere separador, o número de colunas na linha será alterado. Portanto, os caracteres separadores devem ser removidos dos valores do campo no estágio de exportação (exclua ou substitua por outro caractere).
4. Campos vazios
Diante de uma situação em que a importação bem-sucedida de dados foi impedida por valores de campos vazios neste formulário:
; ""
Onde ";" É o sinal do separador de campos neste caso. Ou seja, o campo tem duas aspas duplas (sequência vazia). Se de repente você não conseguir importar os dados e suspeitar que o problema possa estar em campos vazios, tente substituir "" por NULL
sed -i 's /; ”” /; NULL / g' data.csv
(substitua ";" pela sua opção de separador)
5. Pode ser útil procurar formatos de número "sujos" nos dados:
; "0" (o número contém um espaço)
; “100.10-” (o sinal “-“ após o número)
O guindaste Bugatti 3/4 "300 - uma dimensão em polegadas é indicada por aspas duplas - e isso automaticamente leva ao problema de aspas não pareadas na exportação.
Infelizmente, essa não é uma lista exaustiva de possíveis problemas com formatos de dados inconvenientes para importação no banco de dados. Seria ótimo conhecer suas opções da prática: que erros curiosos você encontrou? Como você os detectou e eliminou. Compartilhe nos comentários.
Conclusão
Em geral, o modelo de dados para Process Mining é muito simples: uma tabela de eventos mais, opcionalmente, livros de referência adicionais. Mas, como geralmente acontece, só começa a parecer simples quando pelo menos um ciclo completo de tarefas foi concluído - todo o processo é visível na sua totalidade e o plano de trabalho é claro. Espero que este artigo o ajude a entender a preparação de dados para seu primeiro projeto de Process Mining. Em geral, o processo de preparação é assim:
- Solicitando um histórico de alterações do proprietário dos dados
- Verificando e limpando o upload (preparação de arquivos CSV)
- Importar para SAP HANA
- Construção de mesa de eventos
- Construindo uma tabela de CA (referência do processo)
E, de fato, é aqui que a preparação do modelo de dados começa e a parte mais interessante começa - Process Mining. Se você tiver alguma dúvida durante a implementação do projeto de Mineração de Processos, sinta-se à vontade para escrever nos comentários, terei prazer em ajudar. Boa sorte
Fedor Pavlov, especialista em plataforma SAP CIS