Olá pessoal. Compartilhamos a tradução da parte final do artigo, preparada especialmente para os alunos do curso de
Engenharia de Dados . A primeira parte pode ser encontrada
aqui .
Apache Beam e DataFlow para pipelines em tempo real
Configuração do Google Cloud
Nota: usei o Google Cloud Shell para iniciar o pipeline e publicar os dados do log do usuário, porque tive problemas ao executar o pipeline no Python 3. O Google Cloud Shell usa o Python 2, que é melhor compatível com o Apache Beam.
Para iniciar o transportador, precisamos nos aprofundar um pouco nas configurações. Para aqueles que não usaram o GCP antes, você deve concluir as 6 etapas a seguir nesta
página .
Depois disso, precisaremos enviar nossos scripts para o Google Cloud Storage e copiá-los para o Google Cloud Shel. O upload para o armazenamento na nuvem é bastante trivial (uma descrição pode ser encontrada
aqui ). Para copiar nossos arquivos, podemos abrir o Google Cloud Shel na barra de ferramentas clicando no primeiro ícone à esquerda na Figura 2 abaixo.
 Figura 2
Figura 2Os comandos que precisamos para copiar arquivos e instalar as bibliotecas necessárias estão listados abaixo.
Criando nosso banco de dados e tabela
Depois de concluir todas as etapas de configuração, a próxima coisa que precisamos fazer é criar um conjunto de dados e uma tabela no BigQuery. Existem várias maneiras de fazer isso, mas o mais fácil é usar o console do Google Cloud criando primeiro um conjunto de dados. Você pode seguir as etapas no
link a seguir para criar uma tabela com um esquema. Nossa tabela terá
7 colunas correspondentes aos componentes de cada log do usuário. Por conveniência, definiremos todas as colunas como strings (tipo string), com exceção da variável timelocal, e as nomearemos de acordo com as variáveis que geramos anteriormente. O layout da nossa tabela deve se parecer com a Figura 3.
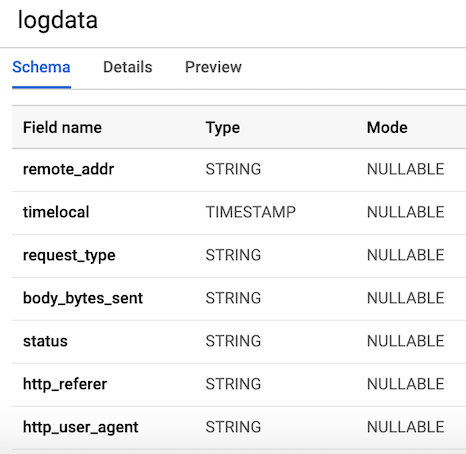 Figura 3. Layout da tabela
Figura 3. Layout da tabelaPublicar dados do log do usuário
Pub / Sub é um componente crítico do nosso pipeline, pois permite que vários aplicativos independentes interajam. Em particular, ele funciona como um intermediário que nos permite enviar e receber mensagens entre aplicativos. A primeira coisa que precisamos fazer é criar um tópico. Basta ir a Pub / Sub no console e pressionar CREATE TOPIC.
O código abaixo chama nosso script para gerar os dados de log definidos acima e, em seguida, conecta e envia os logs para Pub / Sub. A única coisa que precisamos fazer é criar um objeto
PublisherClient , especificar o caminho para o tópico usando o método
topic_path e chamar a função de
publish com
topic_path e data. Observe que importamos
generate_log_line do nosso script
stream_logs ; portanto, verifique se esses arquivos estão na mesma pasta, caso contrário, você receberá um erro de importação. Em seguida, podemos executar isso no console do Google usando:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
Assim que o arquivo é iniciado, podemos observar a saída dos dados de log para o console, conforme mostrado na figura abaixo. Este script funcionará até usarmos
CTRL + C para completá-lo.
 Figura 4. Saída de
Figura 4. Saída de publish_logs.py
Escrevendo código para nosso pipeline
Agora que preparamos tudo, podemos prosseguir para a parte mais interessante - escrevendo o código do nosso pipeline usando Beam e Python. Para criar um pipeline de viga, precisamos criar um objeto de pipeline (p). Depois de criar o objeto de pipeline, podemos aplicar várias funções uma após a outra usando o operador
pipe (|) . Em geral, o fluxo de trabalho se parece com a imagem abaixo.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
Em nosso código, criaremos duas funções definidas pelo usuário. A função
regex_clean , que verifica os dados e recupera a linha correspondente com base na lista PATTERNS usando a função
re.search . A função retorna uma string separada por vírgula. Se você não é um especialista em expressões regulares, recomendo que você leia este
tutorial e pratique no bloco de notas para verificar o código. Depois disso, definimos uma função ParDo personalizada chamada
Split , que é uma variação da transformação Beam para processamento paralelo. No Python, isso é feito de uma maneira especial - precisamos criar uma classe que herda da classe DoFn Beam. A função Split pega uma string analisada da função anterior e retorna uma lista de dicionários com chaves correspondentes aos nomes das colunas em nossa tabela do BigQuery. Há algo que vale a pena notar sobre essa função: tive que importar a
datetime dentro da função para fazê-la funcionar. Eu recebi um erro de importação no início do arquivo, o que foi estranho. Essa lista é então passada para a função
WriteToBigQuery , que simplesmente adiciona nossos dados à tabela. O código para o Trabalho em DataFlow em lote e o Trabalho em fluxo de dados DataFlow é mostrado abaixo. A única diferença entre o lote e o código do fluxo é que, no processamento em lote, lemos o CSV de
src_path usando a função
ReadFromText do Beam.
Trabalho DataFlow em lote (processamento de pacotes)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Trabalho de fluxo de dados DataFlow
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Início do transportador
Podemos iniciar o pipeline de várias maneiras diferentes. Se quiséssemos, poderíamos executá-lo localmente a partir do terminal, efetuando login remotamente no GCP.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
No entanto, vamos lançá-lo usando o DataFlow. Podemos fazer isso usando o comando abaixo, definindo os seguintes parâmetros necessários.
project - O ID do seu projeto GCP.runner é um runner pipeline que analisará seu programa e construirá seu pipeline. Para executar na nuvem, você deve especificar um DataflowRunner.staging_location - O caminho para o armazenamento em nuvem do Cloud Dataflow para indexação dos pacotes de código necessários aos manipuladores de processos.temp_location - o caminho para o armazenamento em nuvem do Cloud Dataflow para hospedar arquivos de tarefas temporários criados durante a operação do pipeline.streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
Enquanto esse comando estiver em execução, podemos acessar a guia DataFlow no console do Google e visualizar nosso pipeline. Ao clicar no pipeline, veremos algo semelhante à Figura 4. Para fins de depuração, pode ser muito útil acessar os logs e depois o Stackdriver para visualizar os logs detalhados. Isso me ajudou a resolver problemas com o pipeline em vários casos.
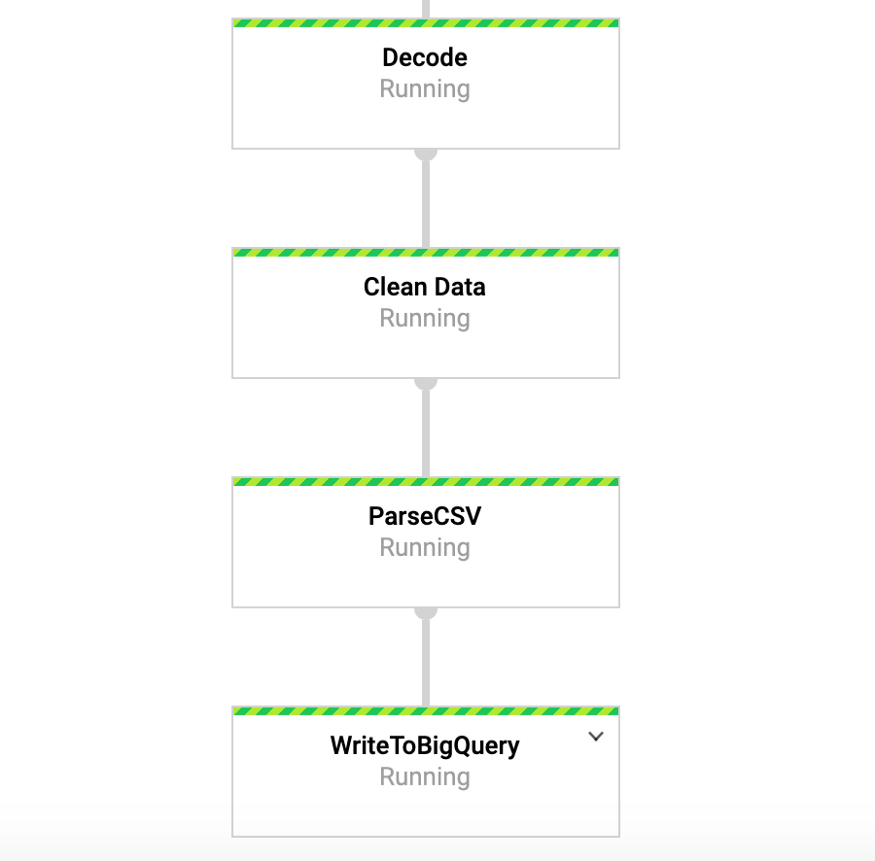 Figura 4: Transportador de vigas
Figura 4: Transportador de vigasAcesse nossos dados no BigQuery
Portanto, já deveríamos ter iniciado o pipeline com os dados entrando em nossa tabela. Para testar isso, podemos acessar o BigQuery e visualizar os dados. Depois de usar o comando abaixo, você deverá ver as primeiras linhas do conjunto de dados. Agora que temos os dados armazenados no BigQuery, podemos realizar análises adicionais, além de compartilhar dados com colegas e começar a responder perguntas de negócios.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 Figura 5: BigQuery
Figura 5: BigQueryConclusão
Esperamos que esta publicação sirva como um exemplo útil de criação de um pipeline de dados de streaming, além de encontrar maneiras de tornar os dados mais acessíveis. Armazenar dados neste formato nos oferece muitas vantagens. Agora podemos começar a responder perguntas importantes, por exemplo, quantas pessoas usam nosso produto? A base de usuários cresce ao longo do tempo? Quais aspectos do produto as pessoas mais interagem? E existem erros onde eles não deveriam estar? Essas são questões que serão do interesse da organização. Com base nas idéias decorrentes das respostas a essas perguntas, poderemos melhorar o produto e aumentar o interesse do usuário.
O feixe é realmente útil para esse tipo de exercício e também possui vários outros casos de uso interessantes. Por exemplo, você pode analisar os dados dos ticks de troca em tempo real e fazer transações com base na análise; talvez você tenha dados de sensores provenientes de veículos e deseje calcular o cálculo do nível de tráfego. Você também pode, por exemplo, ser uma empresa de jogos que coleta dados do usuário e os utiliza para criar painéis para rastrear as principais métricas. Ok, senhores, este tópico já é para outro post, obrigado pela leitura e para quem quiser ver o código completo, abaixo está um link para o meu GitHub.
https://github.com/DFoly/User_log_pipeline
Só isso.
Leia a primeira parte .