A essência da história sobre o gerenciador de pacotes mais popular do Kubernetes pode ser representada com a ajuda de emoji:
- a caixa é Helm (é a mais adequada na versão mais recente do Emoji);
- fechadura - segurança;
- o homem é a solução para o problema.

De fato, tudo será um pouco mais complicado, e a história está cheia de detalhes técnicos sobre
como tornar o Helm seguro .
- Resumidamente, o que é Helm se você não sabia ou esqueceu. Quais problemas ele resolve e onde está localizado no ecossistema.
- Considere a arquitetura do Helm. Nem uma única conversa sobre segurança e como tornar uma ferramenta ou solução mais segura pode ocorrer sem entender a arquitetura do componente.
- Vamos discutir os componentes do Helm.
- O problema mais grave é o futuro - a nova versão do Helm 3.
Tudo neste artigo está relacionado ao Helm 2. Esta versão está em produção e provavelmente é você quem está usando agora, e é aí que há riscos de segurança.
Sobre o palestrante: Alexander Khayorov (
allexx ) desenvolve há 10 anos, ajuda a melhorar o conteúdo do
Moscow Python Conf ++ e ingressou no comitê da
Helm Summit . Atualmente trabalhando na Chainstack na posição de líder de desenvolvimento - este é um híbrido entre o gerente de desenvolvimento e a pessoa responsável pela entrega dos releases finais. Ou seja, está localizado no local das hostilidades, onde tudo acontece desde a criação do produto até sua operação.
O Chainstack é uma startup pequena, em crescimento ativo, cuja tarefa é oferecer aos clientes a oportunidade de esquecer a infraestrutura e as dificuldades de operação de aplicativos descentralizados. A equipe de desenvolvimento está localizada em Cingapura. Não peça ao Chainstack para vender ou comprar criptomoedas, mas ofereça-se para falar sobre estruturas de blockchain corporativas, e elas terão prazer em responder.
Elmo
Este é o gerenciador de pacotes (gráficos) do Kubernetes. A maneira mais intuitiva e versátil de levar aplicativos ao cluster Kubernetes.

Naturalmente, trata-se de uma abordagem mais estrutural e industrial do que criar seus próprios manifestos YAML e escrever pequenos utilitários.
Helm é o melhor disponível e popular no momento.
Por que leme? Principalmente porque é suportado pelo CNCF. Cloud Native - uma grande organização, é a empresa controladora dos projetos Kubernetes, etcd, Fluentd e outros.
Outro fato importante, Helm é um projeto muito popular. Quando, em janeiro de 2019, eu estava planejando falar sobre como tornar o Helm seguro, o projeto tinha mil estrelas no GitHub. Em maio, havia 12 mil deles.
Muitas pessoas estão interessadas no Helm, portanto, mesmo que você ainda não o use, você precisará conhecer sua segurança.
A segurança é importante.A equipe principal do Helm é suportada pelo Microsoft Azure e, portanto, este é um projeto bastante estável, diferente de muitos outros. O lançamento do Helm 3 Alpha 2 em meados de julho indica que muitas pessoas estão trabalhando no projeto e têm desejo e força para desenvolver e melhorar o Helm.
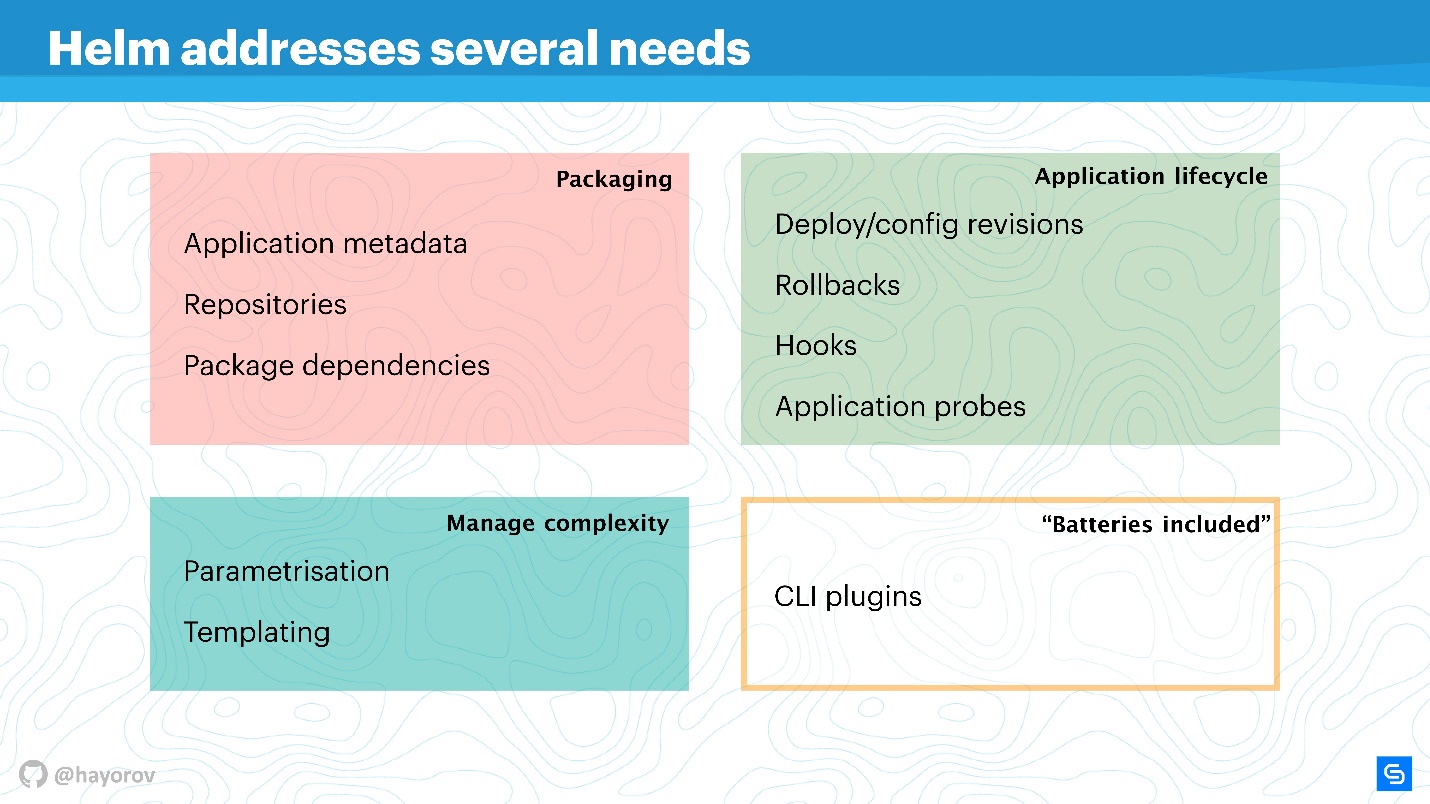
O Helm resolve vários problemas de gerenciamento de aplicativos raiz no Kubernetes.
- Embalagem de aplicação. Até um aplicativo como “Hello, World” no WordPress já consiste em vários serviços, e eu quero agrupá-los.
- Gerenciamento da complexidade que surge com o gerenciamento desses aplicativos.
- Um ciclo de vida que não termina após a instalação ou implantação do aplicativo. Ele continua vivo, precisa ser atualizado, e Helm ajuda nisso e está tentando trazer as medidas e políticas certas para isso.
A embalagem é organizada de maneira compreensível: existem metadados em total conformidade com o trabalho de um gerenciador de pacotes regular para Linux, Windows ou MacOS. Ou seja, o repositório, dependendo de vários pacotes, metainformações para aplicativos, configurações, recursos de configuração, indexação de informações etc. O Helm permite que você o obtenha e use para aplicativos.
Gerenciamento de complexidade . Se você tiver muitos aplicativos semelhantes, precisará de parametrização. Os modelos seguem isso, mas, para não criar sua própria maneira de criar modelos, você pode usar o que o Helm oferece imediatamente.
Gerenciamento do ciclo de vida de aplicativos - na minha opinião, esse é o problema mais interessante e não resolvido. Foi por isso que vim para Helm no devido tempo. Precisávamos monitorar o ciclo de vida do aplicativo, queríamos transferir nossos ciclos de CI / CD e aplicativo para esse paradigma.
Helm permite que você:
- gerenciar implantação, apresenta o conceito de configuração e revisão;
- reversão com sucesso;
- use ganchos para diferentes eventos;
- Adicione verificações adicionais de aplicativos e responda a seus resultados.
Além disso
, Helm possui “baterias” - um grande número de coisas saborosas que podem ser incluídas na forma de plug-ins, simplificando sua vida. Os plugins podem ser escritos de forma independente, são bastante isolados e não requerem uma arquitetura esbelta. Se você deseja implementar algo, recomendo fazê-lo como um plug-in e, em seguida, é possível incluí-lo no upstream.
O Helm é baseado em três conceitos principais:
- Repo do gráfico - descrição e matriz de parametrização possível para o seu manifesto.
- Config - ou seja, os valores que serão aplicados (texto, valores numéricos, etc.).
- O Release reúne os dois principais componentes e, juntos, se transformam no Release. As versões podem ser versionadas, alcançando assim a organização do ciclo de vida: pequena no momento da instalação e grande no momento da atualização, downgrade ou reversão.
Arquitetura do leme
O diagrama reflete conceitualmente a arquitetura de alto nível do Helm.
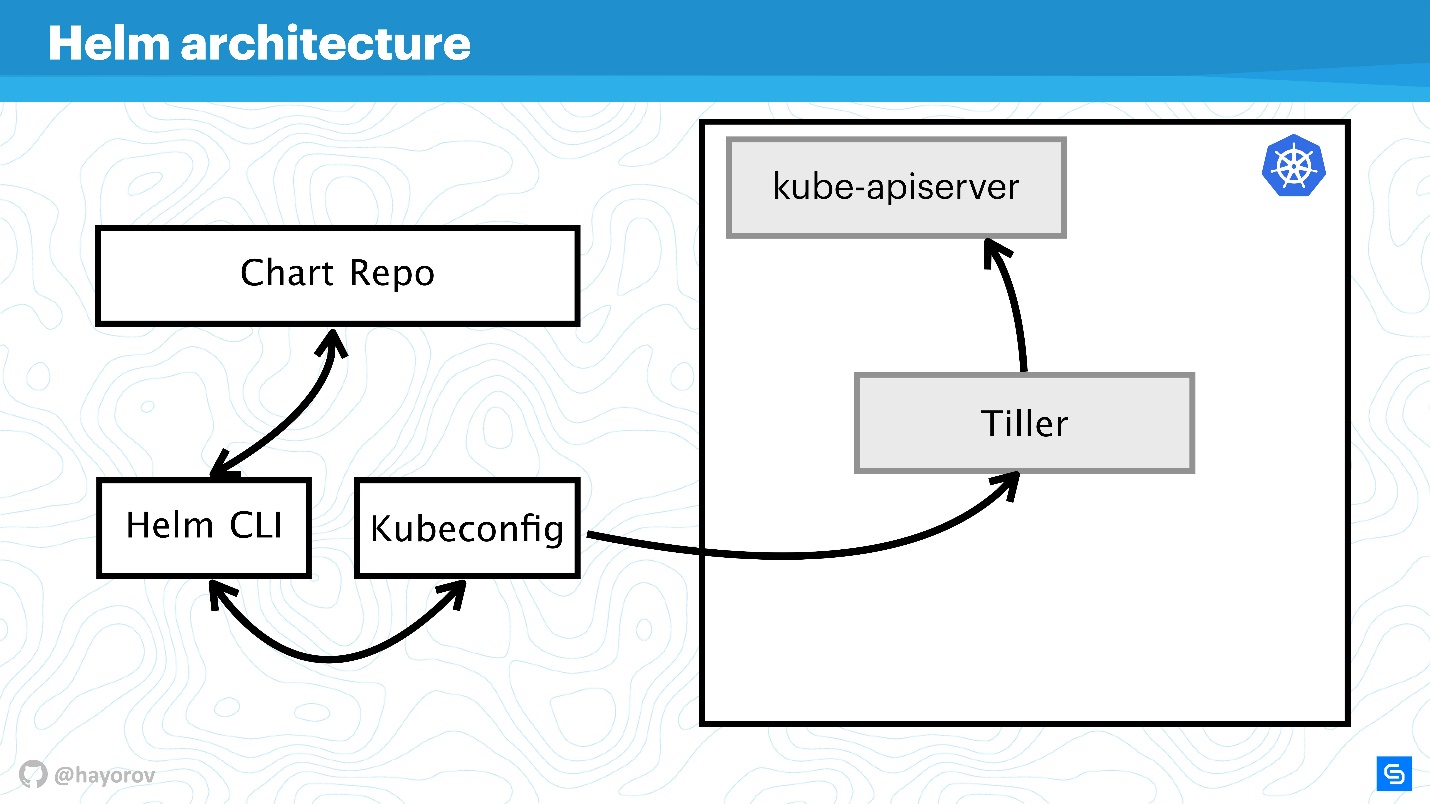
Deixe-me lembrá-lo de que Helm é algo conectado ao Kubernetes. Portanto, não podemos prescindir do Kubernetes-cluster (retângulo). O componente kube-apiserver está no assistente. Sem Helm, temos o Kubeconfig. O Helm traz um pequeno binário, por assim dizer, o utilitário Helm CLI, instalado em um computador, laptop ou mainframe - para qualquer coisa.
Mas isso não é suficiente. Helm possui um componente de servidor Tiller. Ele representa os interesses do Helm dentro de um cluster, é o mesmo aplicativo dentro de um cluster Kubernetes, como qualquer outro.
O próximo componente do repositório de gráficos é o repositório de gráficos. Existe um repositório oficial e pode haver um repositório privado de uma empresa ou projeto.
Interação
Vamos ver como os componentes da arquitetura interagem quando queremos instalar um aplicativo usando o Helm.
- Dizemos que o
Helm install , vá para o repositório (Chart Repo) e obtenha um gráfico do Helm.
- O Helm Utility (Helm CLI) interage com o Kubeconfig para descobrir qual cluster entrar em contato.
- Após receber essas informações, o utilitário se volta para o Tiller, que está em nosso cluster, já como um aplicativo.
- O Tiller recorre ao Kube-apiserver para executar ações no Kubernetes, para criar alguns objetos (serviços, pods, réplicas, segredos etc.).
Além disso, complicaremos o esquema para ver o vetor de ataques aos quais toda a arquitetura Helm como um todo pode ser submetida. E então tentaremos protegê-la.
Vetor de ataque
O primeiro ponto potencialmente fraco é a
API do usuário privilegiada . Como parte do esquema, este é um hacker que obteve acesso de administrador ao Helm CLI.
Um usuário de API não privilegiado também pode ser perigoso se estiver localizado em algum lugar próximo. Esse usuário terá um contexto diferente, por exemplo, ele pode ser corrigido em um espaço para nome do cluster nas configurações do Kubeconfig.
O vetor de ataque mais interessante pode ser o processo localizado dentro do cluster em algum lugar perto de Tiller e pode acessá-lo. Pode ser um servidor da web ou um microsserviço que visualiza o ambiente de rede do cluster.
Uma opção de ataque exótica, mas que está ganhando popularidade, está associada ao Chart Repo. Um gráfico criado por um autor inescrupuloso pode conter um recurso inseguro, e você o executará, assumindo fé. Ou pode substituir o gráfico que você baixa do repositório oficial e, por exemplo, criar um recurso na forma de políticas e aumentar seu acesso.
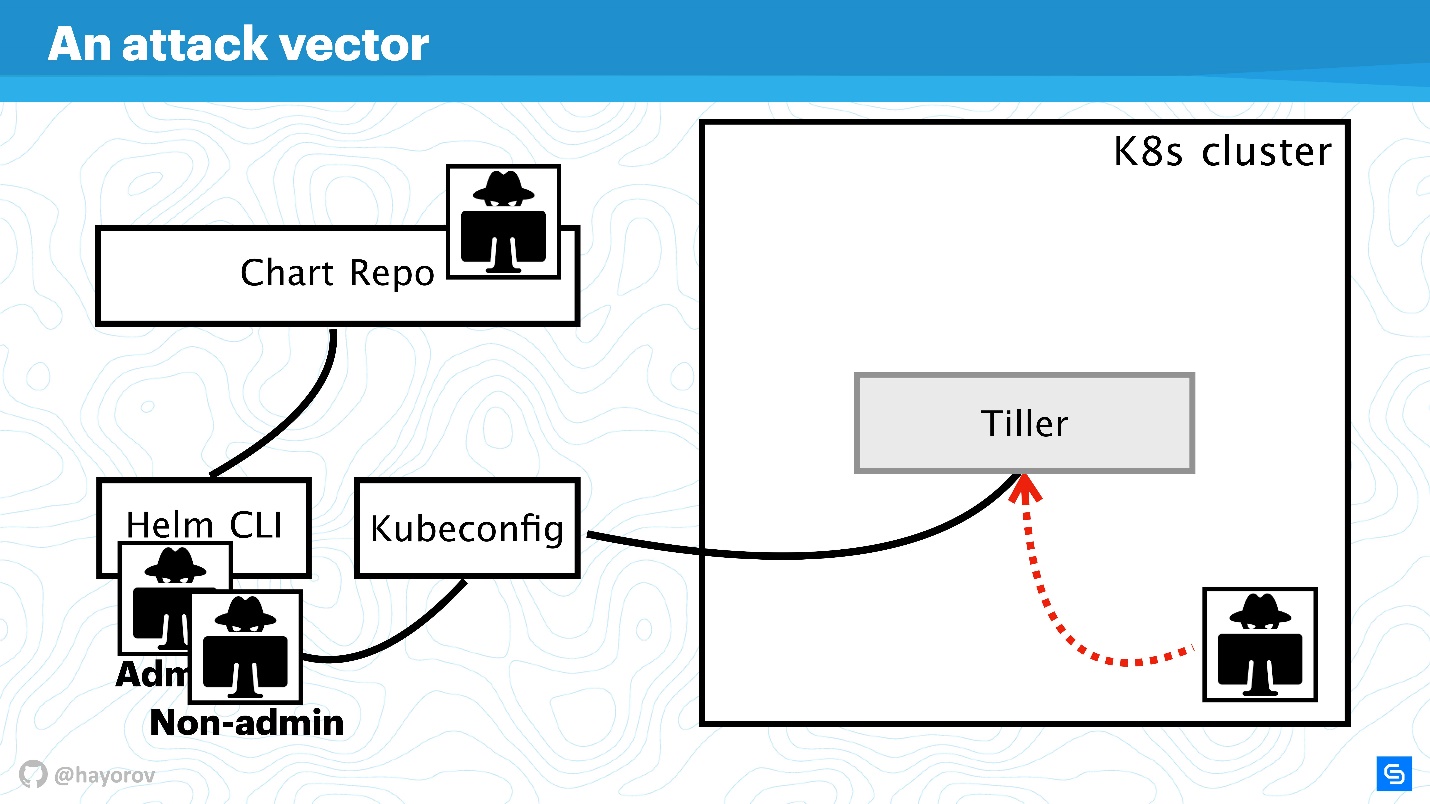
Vamos tentar combater os ataques de todos esses quatro lados e descobrir onde há problemas na arquitetura Helm e onde, possivelmente, eles não estão.
Vamos ampliar o esquema, adicionar mais elementos, mas manter todos os componentes básicos.
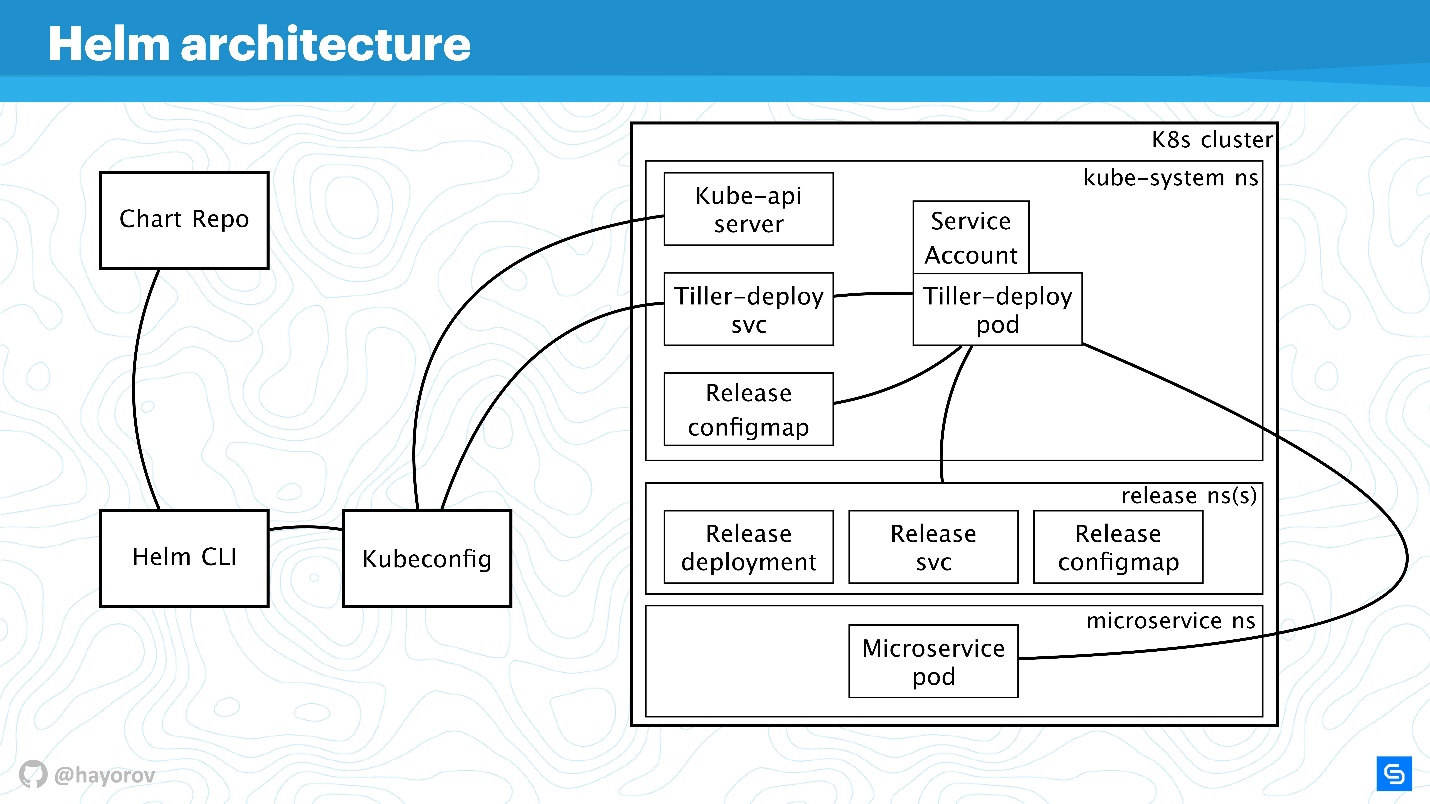
O Helm CLI se comunica com o Chart Repo, interage com o Kubeconfig, o trabalho é transferido para o cluster no componente Tiller.
O timão é representado por dois objetos:
- Tiller-deploy svc, que expõe um determinado serviço;
- Pod de implantação do leme (no diagrama em uma única cópia em uma réplica), que executa toda a carga que acessa o cluster.
Para interação, diferentes protocolos e esquemas são usados. Do ponto de vista da segurança, estamos mais interessados em:
- O mecanismo pelo qual o Helm CLI acessa o repositório de gráficos: qual protocolo, se há autenticação e o que pode ser feito sobre isso.
- O protocolo pelo qual o Helm CLI, usando o kubectl, se comunica com o Tiller. Este é um servidor RPC instalado dentro do cluster.
- O próprio Leme está disponível para microsserviços que estão em um cluster e interagem com o Kube-apiserver.
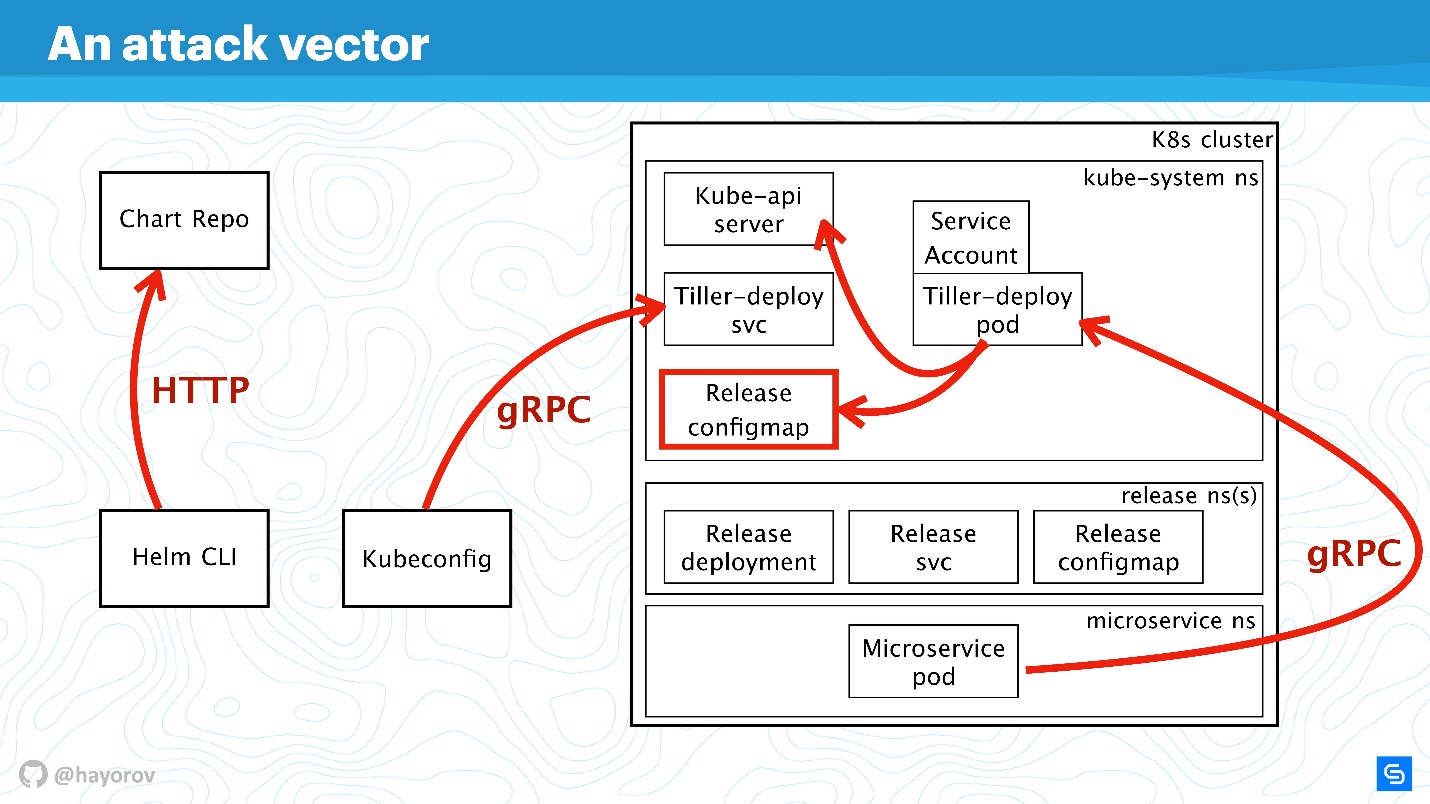
Discutiremos todas essas instruções em ordem.
RBAC
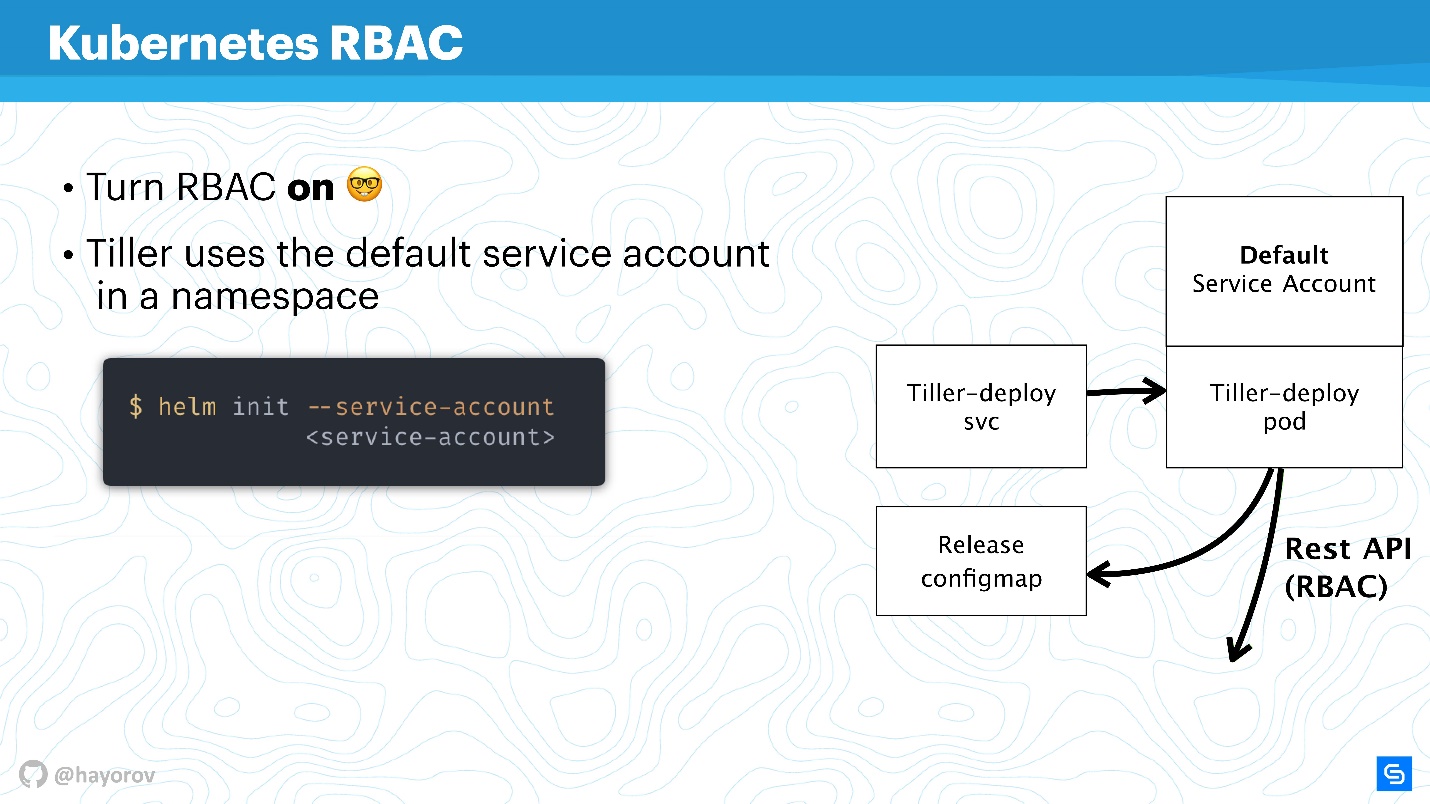
É inútil falar sobre qualquer segurança do Helm ou outro serviço dentro do cluster se o RBAC não estiver ativado.
Parece que essa não é uma recomendação nova, mas tenho certeza de que até agora muitos não incluíram o RBAC nem na produção, porque isso é muito barulhento e há muito a ser configurado. No entanto, peço que isso seja feito.
 https://rbac.dev/
https://rbac.dev/ é um site de advogados da RBAC. Ele coletou uma enorme quantidade de materiais interessantes que ajudarão a configurar o RBAC, mostrar por que é bom e como conviver com ele em princípio na produção.
Vou tentar explicar como Tiller e RBAC funcionam. O Leme trabalha dentro de um cluster em uma determinada conta de serviço. Normalmente, se o RBAC não estiver configurado, este será o superusuário. Na configuração básica, o Tiller será o administrador. É por isso que se costuma dizer que o Tiller é um túnel SSH para o seu cluster. Esse é realmente o caso, portanto, você pode usar uma conta de serviço dedicada separada em vez da conta de serviço padrão no diagrama acima.
Ao inicializar o Helm, instale-o primeiro no servidor, você pode definir a conta de serviço usando
--service-account . Isso permitirá que você use o usuário com o conjunto mínimo de direitos necessário. É verdade que você precisa criar uma "guirlanda": Role e RoleBinding.
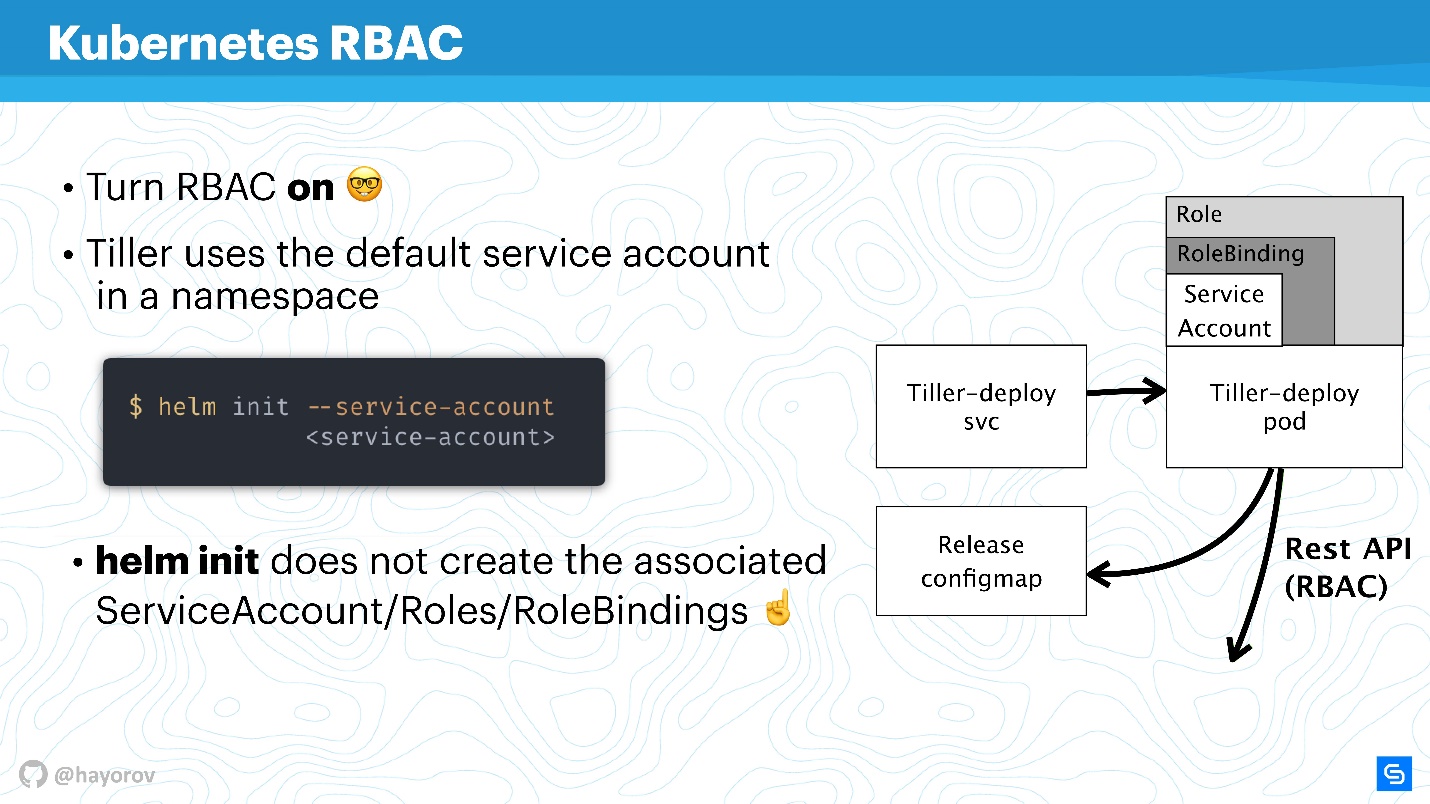
Infelizmente, Helm não fará isso por você. Você ou o administrador do cluster Kubernetes precisa preparar um conjunto de Função, RoleBinding para a conta de serviço com antecedência para transferir o Helm.
A questão é: qual é a diferença entre Role e ClusterRole? A diferença é que ClusterRole é válido para todos os namespaces, ao contrário de Role e RoleBinding regulares, que funcionam apenas para namespaces especializados. Você pode configurar políticas para todo o cluster e todos os espaços para nome, bem como personalizado para cada espaço para nome separadamente.
Vale ressaltar que o RBAC resolve outro grande problema. Muitos reclamam que o Helm, infelizmente, não é multilocação (não oferece suporte à multilocação). Se várias equipes consomem um cluster e usam o Helm, é impossível, em princípio, configurar políticas e diferenciar seu acesso nesse cluster, porque existe uma conta de serviço sob a qual o Helm funciona e cria todos os recursos no cluster a partir dele. às vezes muito desconfortável. Isso é verdade - como o próprio binário, como um processo,
Helm Tiller não tem idéia sobre a multilocação .
No entanto, existe uma ótima maneira de executar o Tiller em um cluster várias vezes. Não há problema com isso; o Tiller pode ser executado em todos os namespace. Assim, você pode usar RBAC, Kubeconfig como contexto e restringir o acesso ao Helm especial.
Ele terá a seguinte aparência.
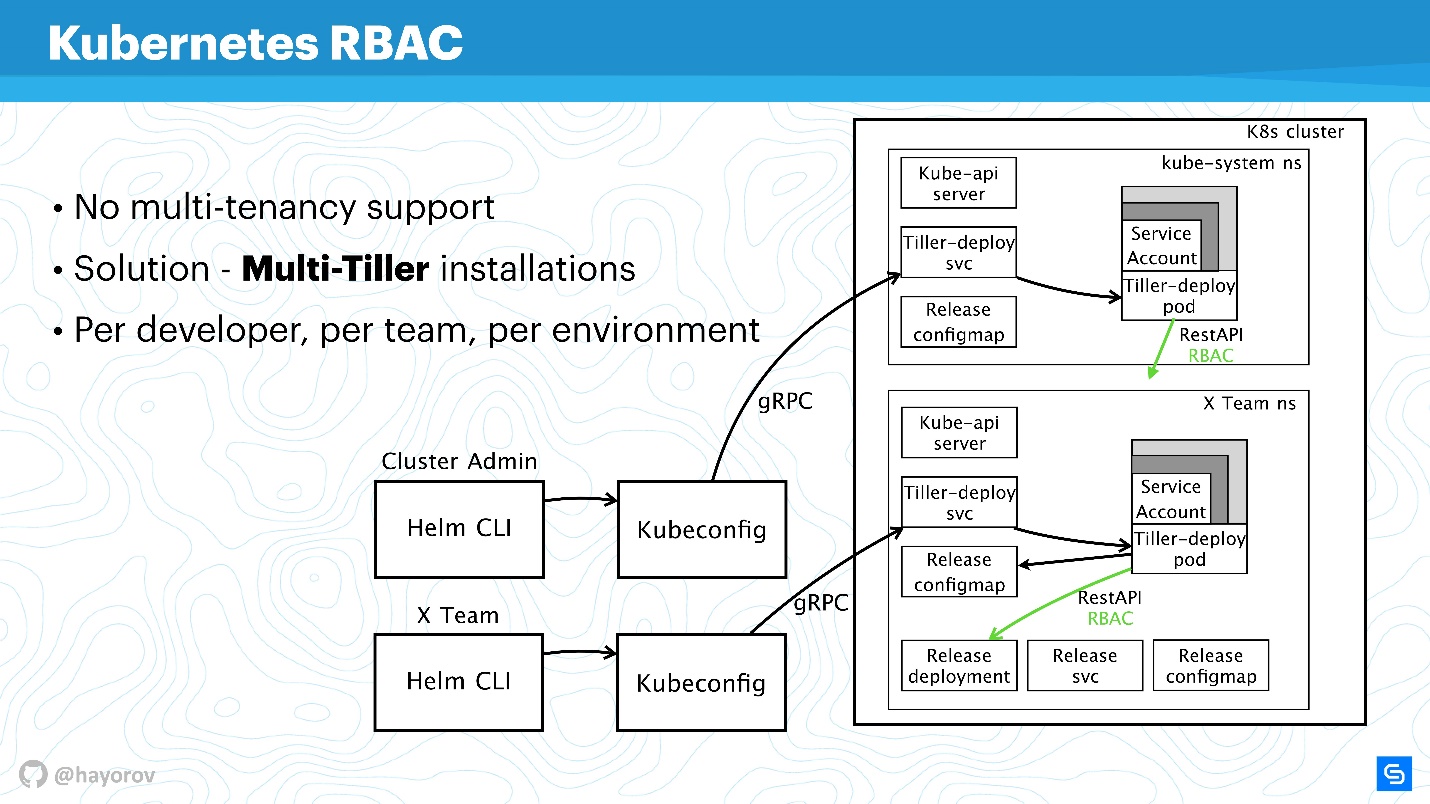
Por exemplo, existem dois Kubeconfig com contexto para equipes diferentes (dois namespace): X Team para a equipe de desenvolvimento e o cluster de administradores. O cluster do administrador possui seu próprio Tiller amplo, localizado no namespace do sistema Kube, respectivamente, uma conta de serviço avançada. E um espaço de nome separado para a equipe de desenvolvimento, eles poderão implantar seus serviços em um espaço de nome especial.
Essa é uma abordagem funcional, o Tiller não é tão guloso que pode afetar muito o seu orçamento. Essa é uma das correções rápidas.
Sinta-se à vontade para configurar o Tiller separadamente e fornecer ao Kubeconfig o contexto para a equipe, para um desenvolvedor específico ou para o ambiente: desenvolvedor, teste, produção (é duvidoso que tudo esteja no mesmo cluster, no entanto, isso pode ser feito).
Continuando nossa história, mude do RBAC e fale sobre o ConfigMaps.
Configmaps
O Helm usa o ConfigMaps como um data warehouse. Quando falamos sobre arquitetura, não havia nenhum banco de dados em que informações sobre releases, configurações, reversões etc. eram armazenadas, e por isso o ConfigMaps é usado.
O principal problema do ConfigMaps é conhecido - eles são inseguros em princípio, é
impossível armazenar dados confidenciais neles. Estamos falando de tudo que não deve ir além do serviço, por exemplo, senhas. A maneira mais nativa para o Helm agora é passar do ConfigMaps para os segredos.
Isso é feito de maneira muito simples. Redefina a configuração do Leme e especifique que o armazenamento será um segredo. Então, para cada implantação, você não receberá o ConfigMap, mas um segredo.
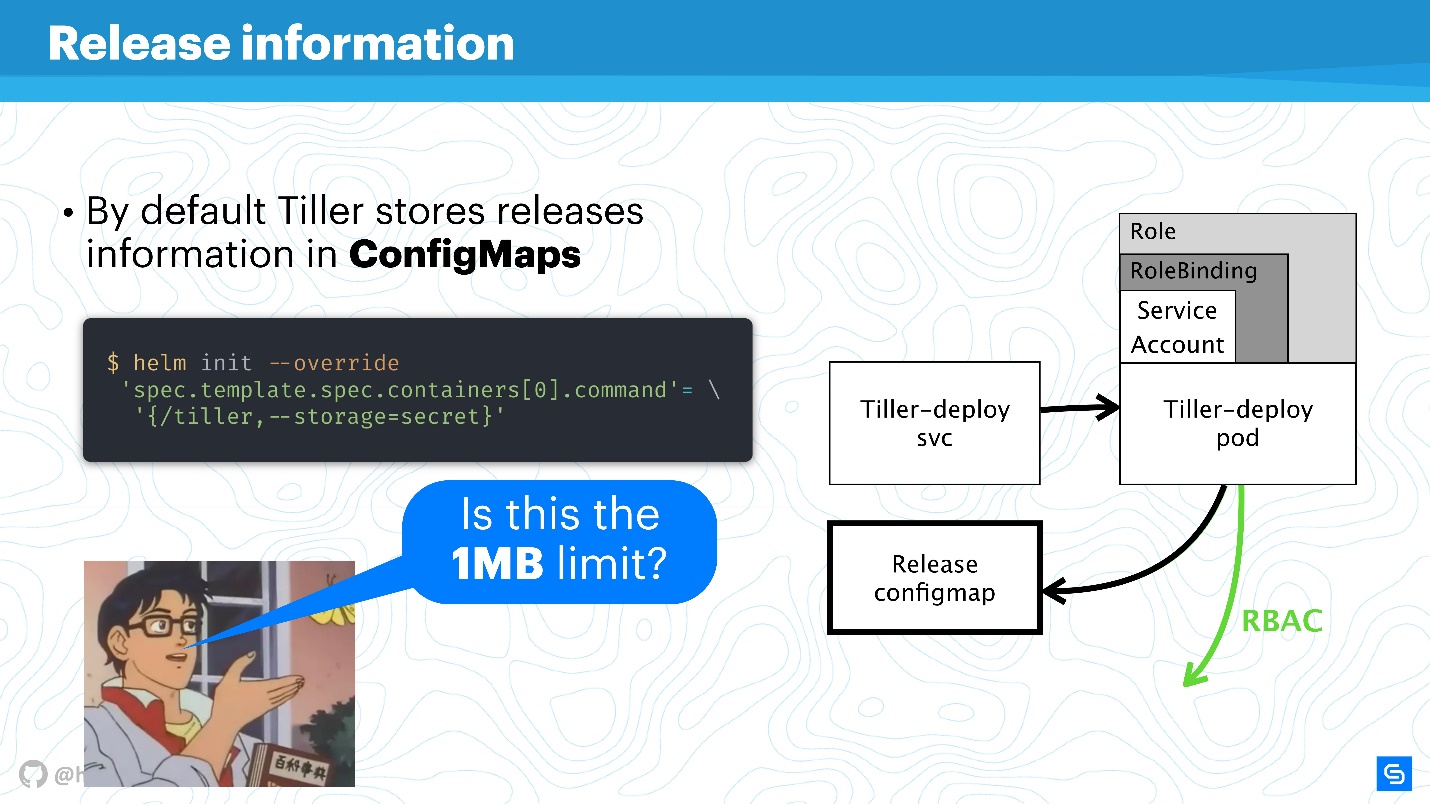
Você pode argumentar que os segredos em si são um conceito estranho e não é muito seguro. No entanto, vale a pena entender que os desenvolvedores do Kubernetes estão fazendo isso. A partir da versão 1.10, ou seja, Há muito tempo, existe a possibilidade, pelo menos em nuvens públicas, de conectar o armazenamento correto para armazenar segredos. Agora, a equipe está trabalhando para melhorar ainda mais o acesso a segredos, envios individuais ou outras entidades.
O Storage Helm é melhor para traduzir em segredos, e eles, por sua vez, protegem centralmente.
Obviamente, haverá um
limite para armazenamento de dados de 1 MB . O Helm aqui usa o etcd como um repositório distribuído para o ConfigMaps. E lá eles pensaram que era um bloco de dados adequado para replicações, etc. Há uma discussão interessante no Reddit sobre isso, eu recomendo encontrar esse assunto divertido de leitura para o fim de semana ou ler o aperto
aqui .
Relatórios de gráfico
Os gráficos são os mais vulneráveis socialmente e podem se tornar a fonte do "homem do meio", especialmente se você usar a solução de estoque. Primeiro, estamos falando de repositórios que são expostos via HTTP.
Definitivamente, você precisa expor o Helm Repo via HTTPS - essa é a melhor opção e é barata.
Preste atenção ao
mecanismo de assinaturas de gráficos . A tecnologia é simples de desonrar. É a mesma coisa que você usa no GitHub, a máquina PGP usual com chaves públicas e privadas. Configure e tenha certeza, com as chaves necessárias e assinando tudo, esse é realmente o seu gráfico.
Além disso, o
cliente Helm suporta TLS (não no sentido de HTTP do lado do servidor, mas TLS mútuo). Você pode usar chaves de servidor e cliente para se comunicar. Francamente, eu não uso esse mecanismo por causa de aversão a certificados mútuos. Em princípio, o
chartmuseum - a principal ferramenta de exposição do Helm Repo para o Helm 2 - também suporta autenticação básica. Você pode usar a autenticação básica se for mais conveniente e mais calmo.
Há também um
plug-in helm-gcs que permite hospedar repositórios de gráficos no Google Cloud Storage. Isso é bastante conveniente, funciona muito bem e é bastante seguro, porque todos os mecanismos descritos são utilizados.
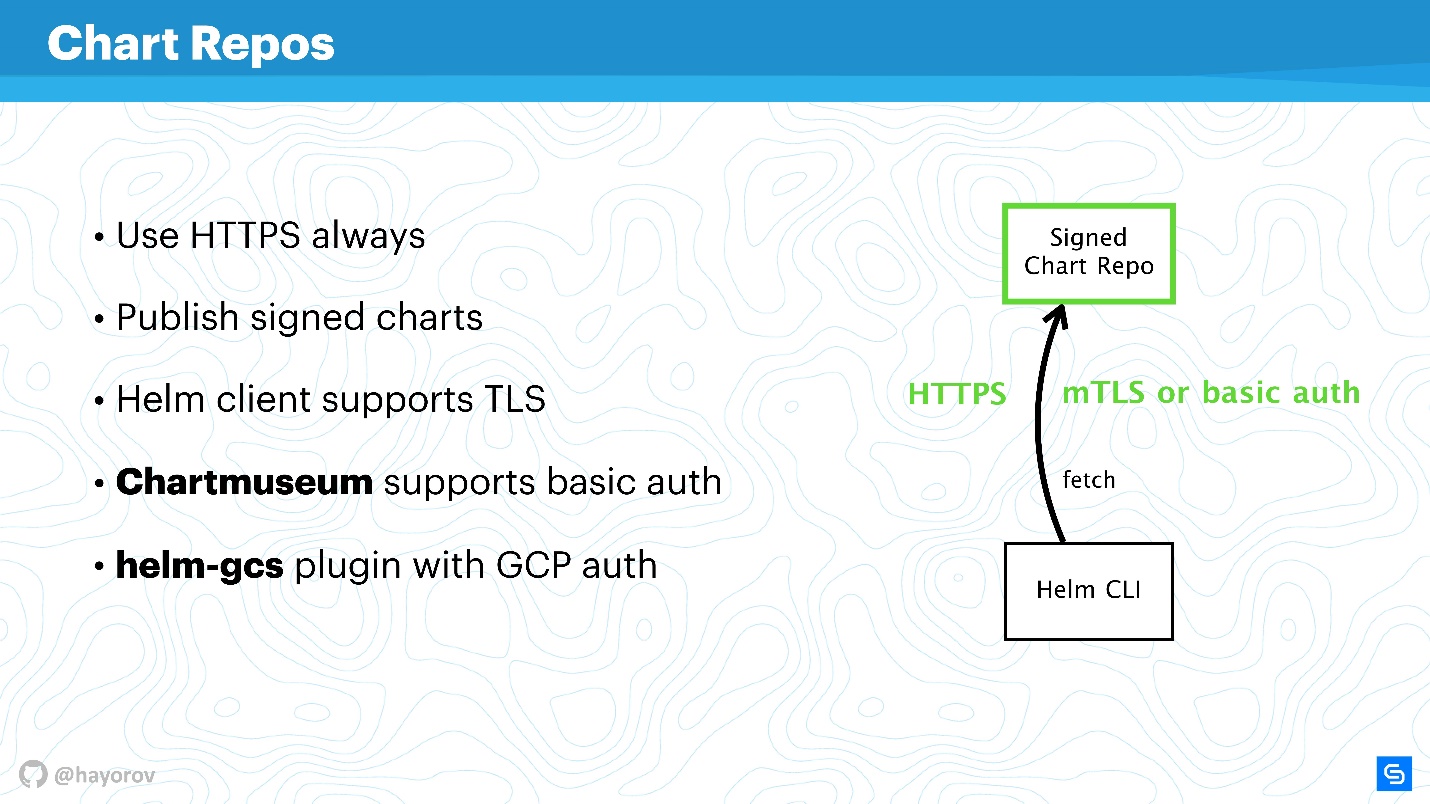
Se você ativar o HTTPS ou TLS, usar o mTLS, conectar a autenticação básica para reduzir ainda mais os riscos, obterá um canal de comunicação seguro Helm CLI e Chart Repo.
API do gRPC
O próximo passo é muito responsável - proteger o Tiller, que está no cluster e, por um lado, o servidor, por outro, acessa os outros componentes e tenta se apresentar como alguém.
Como eu disse, o Tiller é um serviço que expõe o gRPC, um cliente Helm chega a ele via gRPC. Por padrão, é claro, o TLS está desativado. Por que isso é feito é uma pergunta discutível, parece-me simplificar a configuração no início.
Para produção e mesmo para preparação, recomendo ativar o TLS no gRPC.
Na minha opinião, diferentemente do mTLS para gráficos, isso é apropriado aqui e é feito com muita simplicidade - gere uma infraestrutura PQI, crie um certificado, inicie o Tiller, transfira o certificado durante a inicialização. Depois disso, você pode executar todos os comandos do Helm, parecendo ser um certificado e uma chave privada gerados.
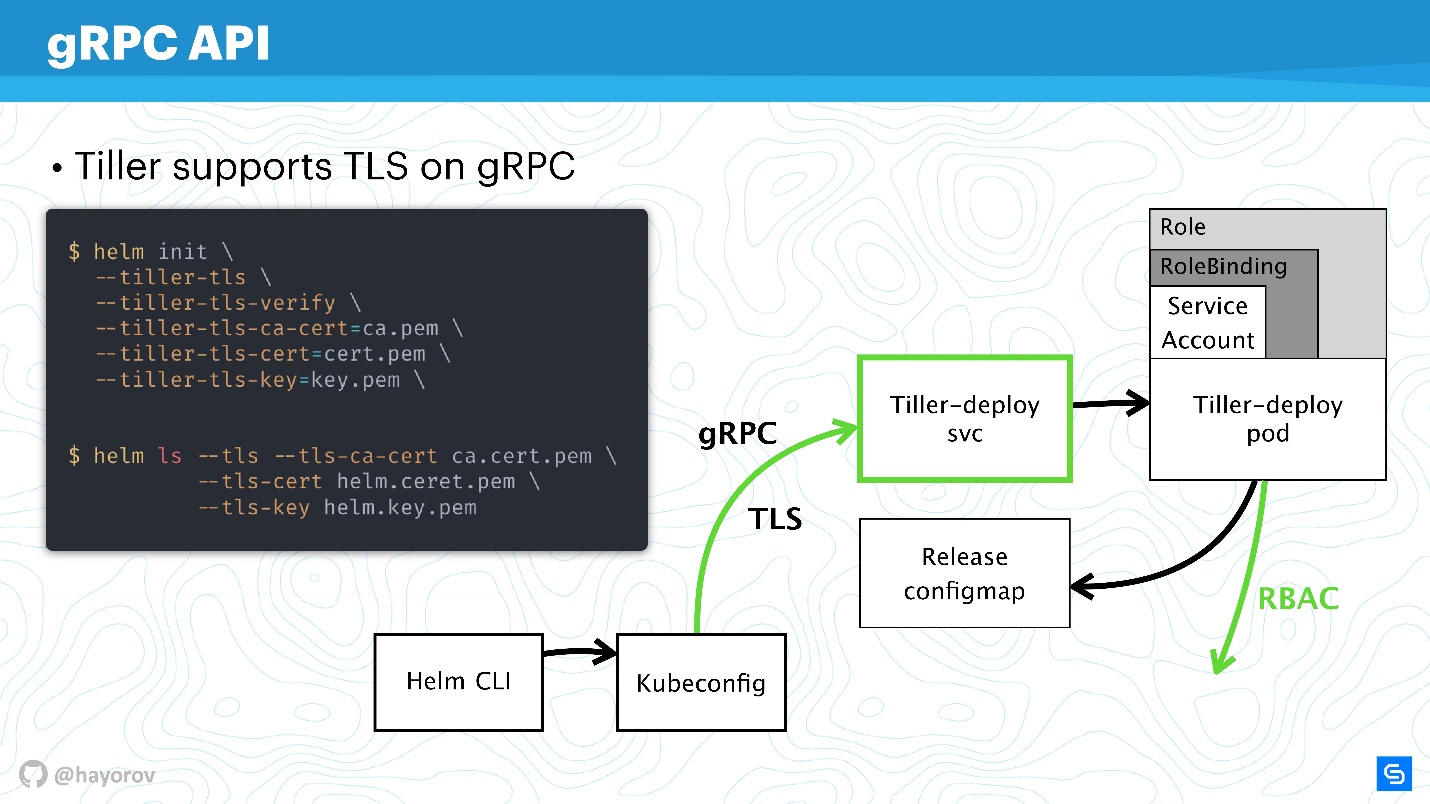
Assim, você se protegerá de todos os pedidos ao Tiller de fora do cluster.
Assim, protegemos o canal de conexão com o Tiller, já discutimos o RBAC e ajustamos os direitos do Kubernetes apiserver, reduzimos o domínio com o qual ele pode interagir.
Elmo Protegido
Vejamos o diagrama final. Essa é a mesma arquitetura com as mesmas setas.
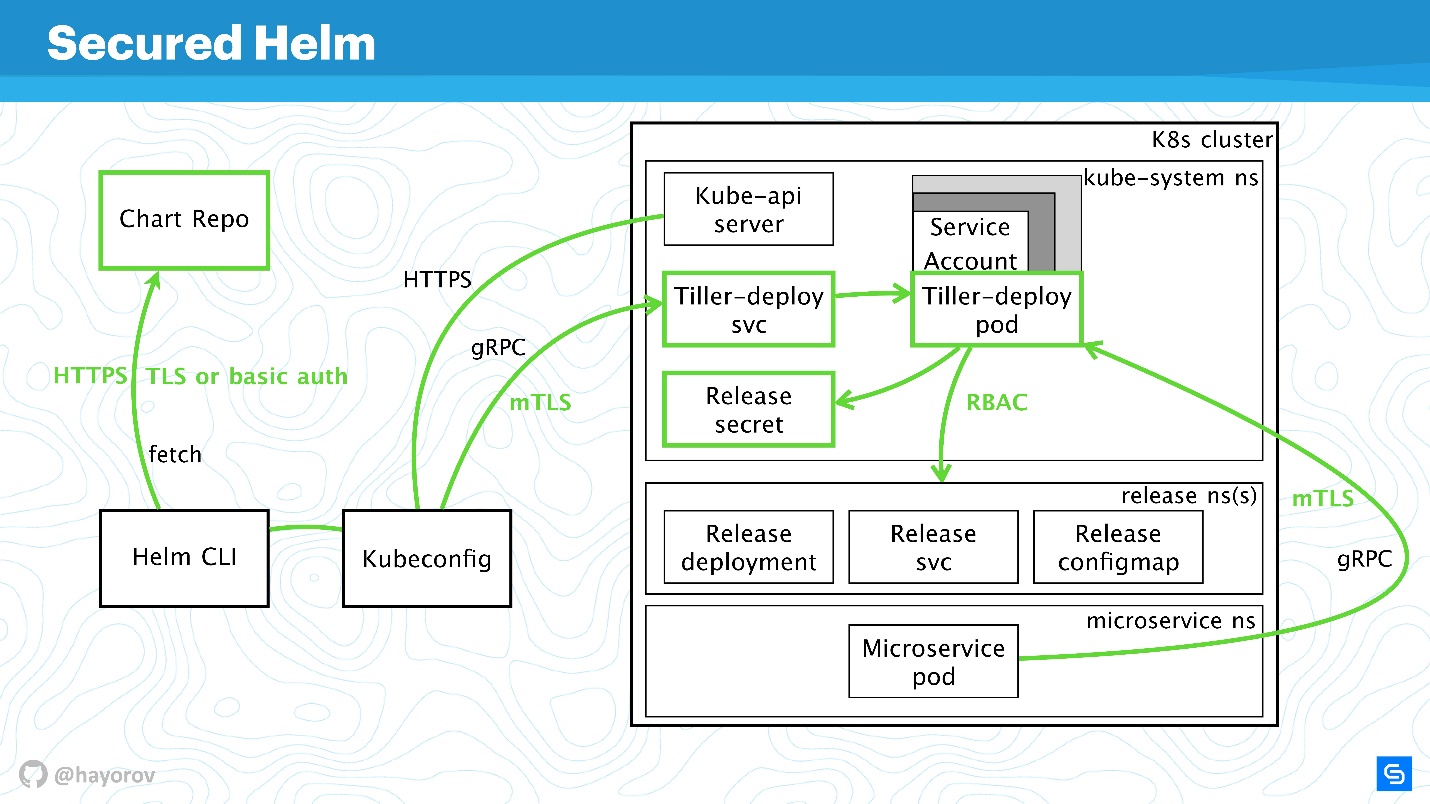
Todas as conexões agora podem ser pintadas com segurança em verde:
- para o Chart Repo, usamos TLS ou mTLS e autenticação básica;
- mTLS para Tiller, e é exposto como um serviço de gRPC com TLS, usamos certificados;
- o cluster usa uma conta de serviço especial com Role e RoleBinding.
Protegemos marcadamente o cluster, mas alguém inteligente disse:
"Só pode haver uma solução absolutamente segura - o computador está desligado, que está em uma caixa de concreto e é guardado por soldados".
Existem diferentes maneiras de manipular dados e encontrar novos vetores de ataque. No entanto, estou confiante de que essas recomendações permitirão a implementação de um padrão básico de segurança da indústria.
Bônus
Esta parte não está diretamente relacionada à segurança, mas também será útil. Vou mostrar algumas coisas interessantes que poucas pessoas conhecem. Por exemplo, como procurar gráficos - oficiais e não oficiais.
O repositório
github.com/helm/charts agora possui cerca de 300 gráficos e dois fluxos: estável e incubadora. O colaborador sabe o quão difícil é passar da incubadora para a estável e como é fácil sair da estável. No entanto, essa não é a melhor ferramenta para procurar gráficos para o Prometheus e tudo o que você gosta por um motivo simples não é um portal no qual é conveniente pesquisar pacotes.
Mas há um serviço
hub.helm.sh com o qual é muito mais conveniente encontrar gráficos. Mais importante ainda, existem muitos mais repositórios externos e quase 800 charots estão disponíveis. Além disso, você pode conectar seu repositório se, por algum motivo, não desejar enviar seus gráficos para estáveis.
Experimente o hub.helm.sh e vamos desenvolvê-lo juntos. Esse serviço está no projeto Helm, e você pode até contribuir com sua interface do usuário se for um fornecedor front-end e quiser simplesmente melhorar a aparência.
Também quero chamar sua atenção para a
integração da API do
Open Service Broker . Parece complicado e incompreensível, mas resolve os problemas que todos enfrentam. Vou explicar com um exemplo simples.
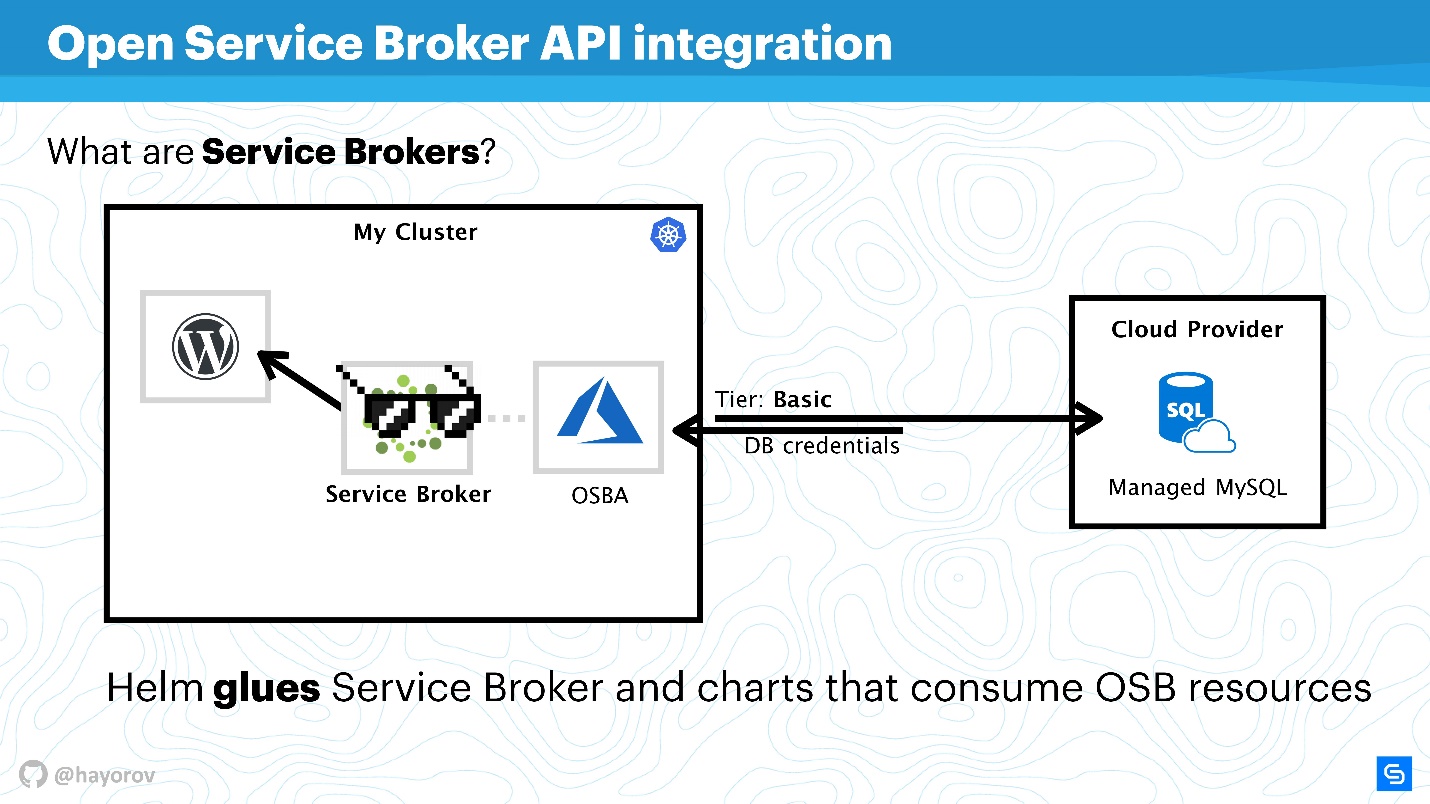
Há um cluster Kubernetes no qual queremos executar o aplicativo clássico - WordPress. Como regra, é necessário um banco de dados para funcionalidade completa. Existem muitas soluções diferentes, por exemplo, você pode iniciar seu serviço completo. Isso não é muito conveniente, mas muitos o fazem.
Outros, como nós no Chainstack, usam bancos de dados gerenciados, como MySQL ou PostgreSQL, para servidores. Portanto, nossos bancos de dados estão localizados em algum lugar da nuvem.
Mas surge um problema: você precisa conectar nosso serviço ao banco de dados, criar um banco de dados de sabor, passar credenciais e de alguma forma gerenciá-lo. Tudo isso geralmente é feito manualmente pelo administrador ou desenvolvedor do sistema. E não há problema quando existem poucos aplicativos. Quando há muitos, você precisa de uma combinação. Existe essa combinação - este é o Service Broker. Ele permite que você use um plug-in especial no cluster de nuvem pública e solicite recursos do provedor por meio do Broker, como se fosse uma API. Você pode usar as ferramentas nativas do Kubernetes para isso.
É muito simples Você pode consultar, por exemplo, o MySQL gerenciado no Azure com uma camada base (isso pode ser personalizado). Usando a API do Azure, a base será criada e preparada para uso. Você não precisa interferir nisso, o plugin é responsável por isso. Por exemplo, o OSBA (plug-in do Azure) retornará credenciais ao serviço e passará para o Helm. Você pode usar o WordPress com MySQL nublado, não lida com bancos de dados gerenciados e não se preocupe com serviços estatais internos.
Podemos dizer que o Helm atua como uma cola, que por um lado permite implantar serviços e, por outro lado, consome os recursos dos provedores de nuvem.
Você pode escrever seu próprio plug-in e usar toda essa história local. Então você só tem seu próprio plug-in para o provedor corporativo de nuvem. Eu recomendo que você tente essa abordagem, especialmente se você tiver uma grande escala e quiser implantar rapidamente um desenvolvedor, teste ou toda a infraestrutura de um recurso. Isso facilitará a vida de suas operações ou DevOps.
Outra descoberta que eu já mencionei é o
plug-in helm-gcs , que permite usar os buckets do Google (armazenamento de objetos) para armazenar gráficos Helm.

São necessários apenas quatro comandos para começar a usá-lo:
- instale o plugin;
- inicie-o;
- defina o caminho para bucket, localizado no gcp;
- publicar gráficos de maneira padrão.
A vantagem é que o método gcp nativo para autorização será usado. Você pode usar uma conta de serviço, uma conta de desenvolvedor - qualquer coisa. É muito conveniente e não custa nada para operar. Se você, como eu, defende a filosofia opsless, isso será muito conveniente, especialmente para equipes pequenas.
Alternativas
Helm não é a única solução de gerenciamento de serviços. Há muitas perguntas para ele, e é provavelmente por isso que a terceira versão apareceu tão rapidamente. Claro que existem alternativas.
Pode ser como soluções especializadas, por exemplo, Ksonnet ou Metaparticle. Você pode usar suas ferramentas clássicas de gerenciamento de infraestrutura (Ansible, Terraform, Chef, etc.) para os mesmos fins que falei.
Por fim, existe a solução
Operator Framework , cuja popularidade está crescendo.
A Estrutura do Operador é a principal alternativa do Helm à qual você deve prestar atenção.
É mais nativo para CNCF e Kubernetes,
mas o limite de entrada é muito maior , você precisa programar mais e descrever menos manifestos.
Existem vários addons, como Draft, Scaffold. Eles simplificam bastante a vida, por exemplo, os desenvolvedores simplificam o ciclo de envio e lançamento do Helm para implantar um ambiente de teste. Eu os chamaria de extensores de oportunidades.
Aqui está um gráfico visual de onde está localizado.
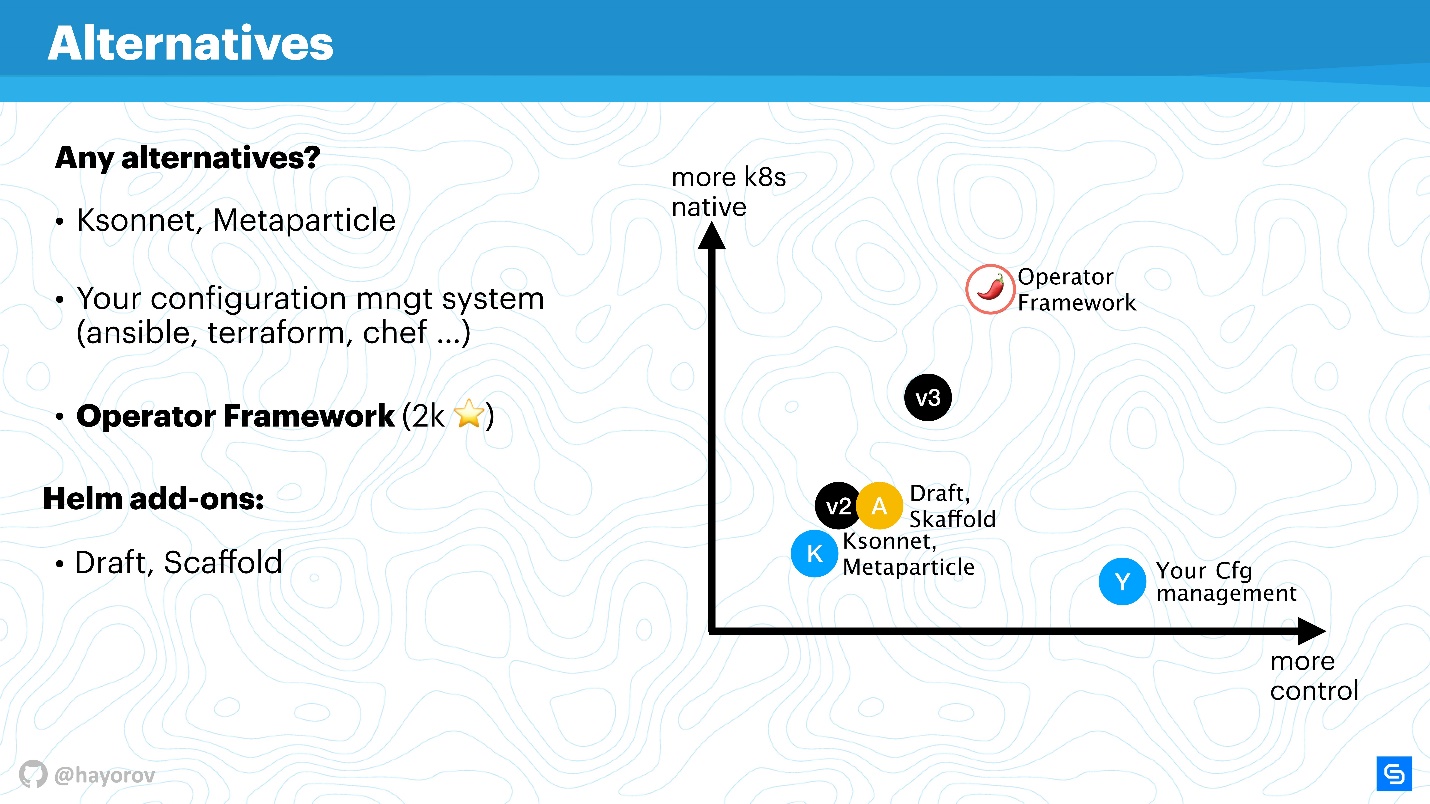
No eixo x, o nível de seu controle pessoal sobre o que está acontecendo, no eixo y, o nível de natividade dos Kubernetes. A versão 2 do leme está em algum lugar no meio. Na versão 3, não é colossal, mas o controle e o nível de natividade são aprimorados. As soluções no nível Ksonnet ainda são inferiores até ao Helm 2. No entanto, vale a pena dar uma olhada para saber o que mais há neste mundo. Obviamente, seu gerenciador de configuração estará sob seu controle, mas absolutamente não é nativo do Kubernetes.
A Estrutura do Operador é absolutamente nativa do Kubernetes e permite que você gerencie-a de maneira muito mais elegante e meticulosa (mas lembre-se do nível de entrada). Em vez disso, é adequado para um aplicativo especializado e cria um gerenciamento para ele, em vez de um coletor de massa para embalar um grande número de aplicativos usando o Helm.
Os extensores simplesmente melhoram um pouco o controle, complementam o fluxo de trabalho ou cortam os cantos dos pipelines de CI / CD.
O futuro do Helm
A boa notícia é que o Helm 3. está aparecendo. A versão alfa do Helm 3.0.0-alpha.2 já foi lançada, você pode tentar. É bastante estável, mas a funcionalidade ainda é limitada.
Por que você precisa do Helm 3? Primeiro de tudo, esta é a história do
desaparecimento de Tiller , como um componente. Isso, como você já entende, é um grande passo à frente, porque tudo é simplificado do ponto de vista da segurança arquitetural.
Quando o Helm 2 foi criado, durante o Kubernetes 1.8 ou mesmo anterior, muitos conceitos eram imaturos. Por exemplo, o conceito de CRD está sendo implementado ativamente e o Helm
usará o CRD para armazenar estruturas. Será possível usar apenas o cliente e não manter o lado do servidor. Portanto, use comandos nativos do Kubernetes para trabalhar com estruturas e recursos. Este é um grande passo em frente.
O suporte para repositórios OCI nativos (Open Container Initiative) será exibido. Essa é uma iniciativa enorme, e Helm é interessante principalmente para publicar seus gráficos. Chega ao ponto que, por exemplo, o Docker Hub suporta muitos padrões OCI. Não me pergunto, mas talvez os fornecedores clássicos de repositórios do Docker comecem a lhe dar a oportunidade de colocar seus gráficos Helm para você.
Uma história controversa para mim é
o suporte de Lua como um mecanismo de modelagem para escrever scripts. Eu não sou um grande fã de Lua, mas será um recurso completamente opcional. Eu verifiquei 3 vezes - usar Lua não será necessário. Portanto, qualquer pessoa que queira usar Lua, alguém que goste de Go, entre no nosso enorme acampamento e use o go-tmpl para isso.
, —
. int string, . JSONS-, values.
event-driven model . . Helm 3, , , , , .
Helm 3 , , Helm 2, Kubernetes . , Helm Kubernetes Kubernetes.
Outra boa notícia é que no DevOpsConf, Alexander Khayorov lhe dirá se os contêineres podem ser seguros? Lembre-se, uma conferência sobre a integração dos processos de desenvolvimento, teste e operação será realizada em Moscou, em 30 de setembro e 1º de outubro . Até 20 de agosto, você ainda pode enviar um relatório e falar sobre sua experiência na solução de uma das muitas tarefas da abordagem do DevOps.
Siga os pontos de verificação e notícias da conferência no canal de boletim e telegrama .