Infraestrutura é do que dependem o trabalho e os lucros dos negócios de TI. Todos os processos que ocorrem com o código do computador do desenvolvedor até a produção dependem da operação ininterrupta de servidores, software e serviços externos. Se a infraestrutura não funcionar como deveria, a empresa perde lucro.
As startups não prestam muita atenção à infraestrutura - precisam cortar o produto até que os investidores fiquem sem dinheiro. As grandes empresas não estão mais preparadas - temos milhares de tarefas aqui, precisamos trabalhar.
Entender que a infra-estrutura de uma empresa de TI também é um produto, que tem uma meta, que é necessário considerar custos e acompanhar métricas, geralmente não alcança.
Você sabe quanto custa sua infraestrutura: servidores, software, serviços externos? O que você acha do custo, por quais métricas? Quanto você vai perder se algo cair ou se não houver backup?
Artyom Naumenko (@entsu) da Skyeng sabe as respostas para essas perguntas. Ele trabalhou em empresas com dois desenvolvedores no estado e em empresas com mil funcionários. Atualmente, ele gerencia a infraestrutura em Skyeng e, ao mesmo tempo, o centro de aprendizado infantil Skyeng. Artem dirá como a empresa está construindo infraestrutura, como eles ganham dinheiro com ela e que erros não devem ser cometidos.
Sobre empresa
Skyeng é uma empresa jovem, tem apenas 6 anos de idade. Mas todo esse tempo vem crescendo três vezes a cada ano.
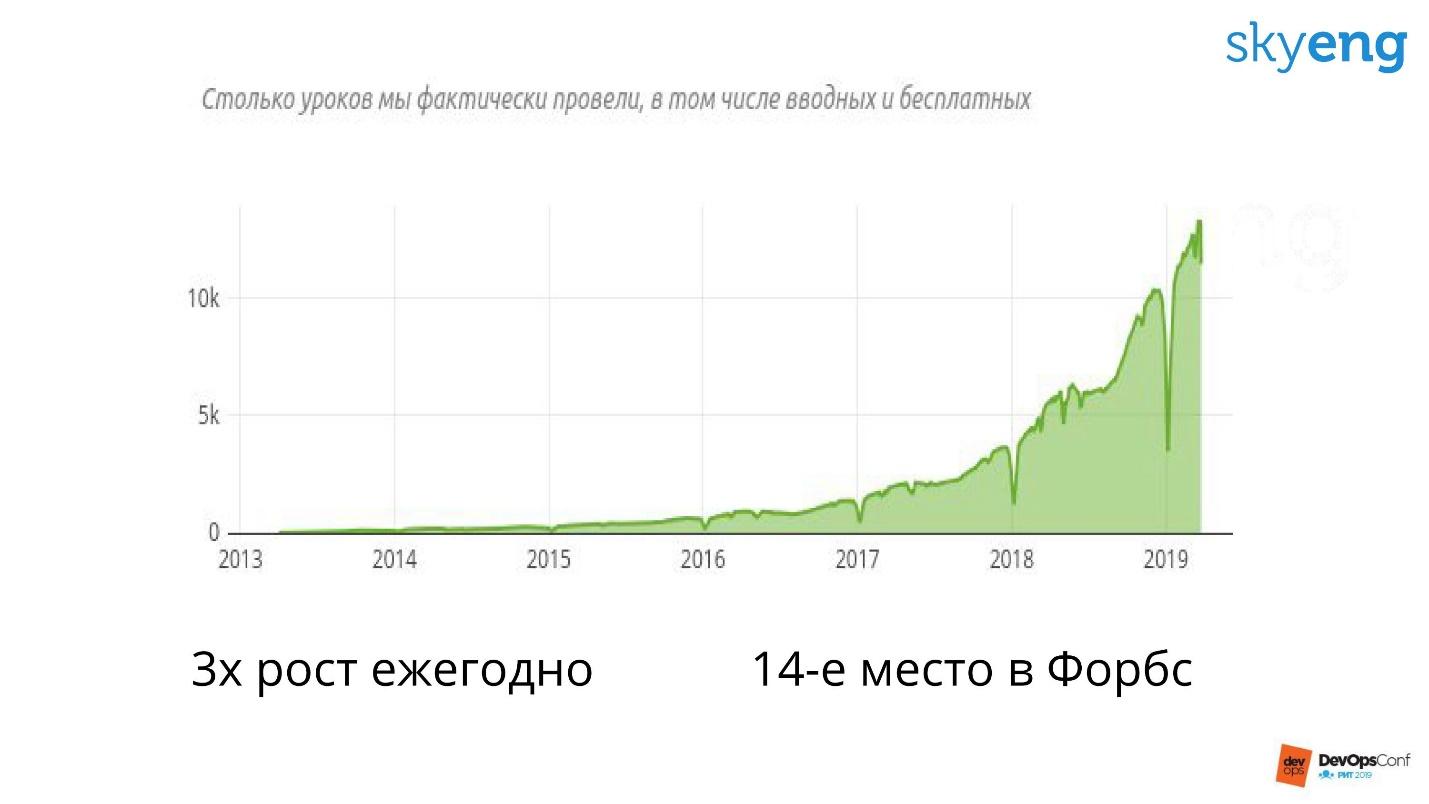
Isso significa que a infraestrutura também cresce três vezes por ano. Hoje, temos 100 servidores, 300 em um ano e 900 em 2. Isso não é fácil, estamos trabalhando duro para garantir esse crescimento.
Skyeng é uma empresa de TI. A empresa é jovem, ainda não há muito legado, tudo é padrão para a pilha PHP:
- PHP
- Angular
- PostgreSQL
- Linux no qual tudo está girando.
Cerca de uma centena de desenvolvedores. A empresa está crescendo e até o final do ano haverá mais.

A maioria dos nossos serviços é escrita por nós e todo o negócio da empresa gira em sua própria infraestrutura. É monitorado por uma equipe de infraestrutura de 6 pessoas. Nós fornecemos todos os processos que ocorrem com o código do computador do desenvolvedor à produção. O código é desenvolvido em nossas máquinas virtuais e servidores, implantação - com a ajuda de nosso Jenkins configurado e nossas ferramentas de implantação, a operação na produção também está em nossos servidores, que gerenciamos.
O objetivo da empresa é crescer 7 vezes em 2 anos. A infraestrutura deve crescer da mesma forma. Para atingir a meta, cada membro da equipe de devops trabalha como um boi. Todos os anos devemos ser 3 vezes melhores que no ano passado e 7 vezes melhores no futuro. Na Skyeng, ninguém está interessado em histórias bonitas que "tentaram, mas falharam". O resultado é importante, não o processo.
Princípios de construção de infraestrutura
Os negócios de qualquer empresa de TI trabalham com infraestrutura. Se não funcionar, o negócio não funcionará, seja Yandex, Amazon ou Skyeng. Estamos cientes disso, portanto, a primeira coisa que é importante para uma infraestrutura legal é
definir uma meta . Parece um discurso de Tony Robbins, mas sem um objetivo, nada vai funcionar.
A meta deve ser definida por dois motivos.
- Se você tem um objetivo, você irá em direção a ele.
- Se não houver objetivo, não há para onde ir. Mesmo se você vier a algum lugar, não poderá se elevar do objetivo alcançado.
Se não houver objetivo, é impossível alcançar.
Problemas da empresa
A definição de metas por si só não é suficiente. O objetivo da empresa é crescer 7 vezes em 2 anos. Haverá problemas durante o crescimento. Eles variam, dependendo do tamanho e tipo de empresa.
O primeiro tipo de empresas e pessoas são startups . Na figura abaixo, “partida típica” - uma jangada e uma pequena equipe que está tentando nadar em algum lugar. As vantagens de uma startup são que cada membro da equipe entende para onde a equipe está se movendo, quem está fazendo o que e o que deve fazer para alcançar um objetivo comum.

O problema com as startups é a falta de dinheiro. Quando um grande volume de tarefas cai nos devops, ele não tem tempo e se pergunta um assistente. Geralmente ele recebe a resposta: “Por quê? Você administra todas as regras - continue!
O próximo tipo são navios enormes . Alguns membros da tripulação do navio não vêem para onde está navegando. Eles desempenham sua pequena função, por exemplo, jogam carvão no forno e não entendem o que está acontecendo globalmente.

O principal problema com os navios é que mais e mais tarefas são necessárias. Cem clientes, para cada problema, não está claro como priorizar, o quadro geral está desfocado, mas estamos “trabalhando”! O tempo nunca é suficiente e são necessárias mais e mais tarefas. Uma equipe nunca poderá construir um transportador que jogue carvão no forno para trabalhar em tarefas importantes.
O terceiro tipo são líderes . O principal problema para os gerentes de infraestrutura são servidores caros, infraestrutura cara e falta de entendimento de como os custos de infraestrutura afetam a receita comercial em geral. O gerente precisa, de alguma forma, responder perguntas sobre por que existem tantos milhões para servidores, se ficaremos menos se pagarmos mais e o que acontecerá se pagarmos menos.

Objetivos de infraestrutura
Descreverei quais metas em Skyeng estabelecemos para nossa infraestrutura no contexto das metas globais da empresa e como as atingimos. A infraestrutura tem 4 objetivos.
Acompanhe o orçamento . Uma empresa é uma estrutura comercial para ganhar dinheiro, então devemos contá-los.
Resolva tarefas rapidamente . Eles não aumentaram o servidor a tempo, o novo serviço da empresa não será iniciado e não ganhará dinheiro. O backup não foi restaurado a tempo - novamente, algo não funcionará e a empresa perderá lucro.
Conveniência dos desenvolvedores . Este item requer uma explicação separada. No ano passado, Skyeng gastou 600 milhões de rublos em desenvolvimento. Se nós, como infraestrutura, aumentássemos a velocidade dos desenvolvedores em pelo menos 1%, teríamos ganho 6 milhões.Se você colocar dois funcionários em período integral, o que aumentará a produtividade em 1%, será rentável.
Resultado a longo prazo . Não devemos nos esforçar uma vez, fazer algo legal para que todos fiquem felizes e tudo desmoronar. O que fazemos deve funcionar por um longo tempo.
Para que isso funcione, é necessário inventar métricas. Eles devem ser mensuráveis, caso contrário, não são objetivos, mas bobagens. Os objetivos devem ser expressos em números e gráficos.
Vamos considerar os itens com mais detalhes.
O orçamento
Medir a infraestrutura por empresa é o que parte dos gastos da empresa vai para infraestrutura.
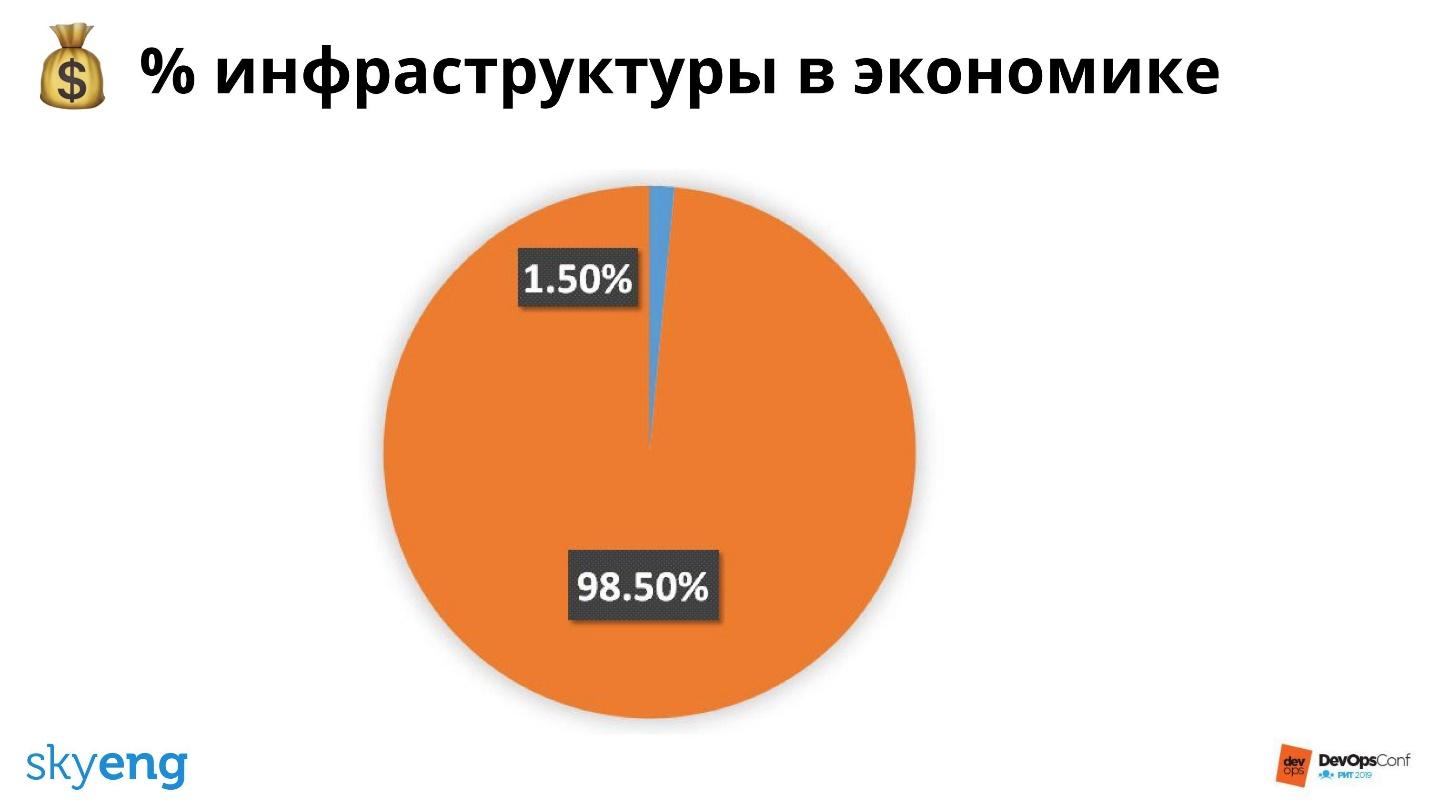
Skyeng é uma escola, e o principal valor é uma lição. Uma lição média custa 800 rublos. Destes, 12 são para infraestrutura: servidores e devops.
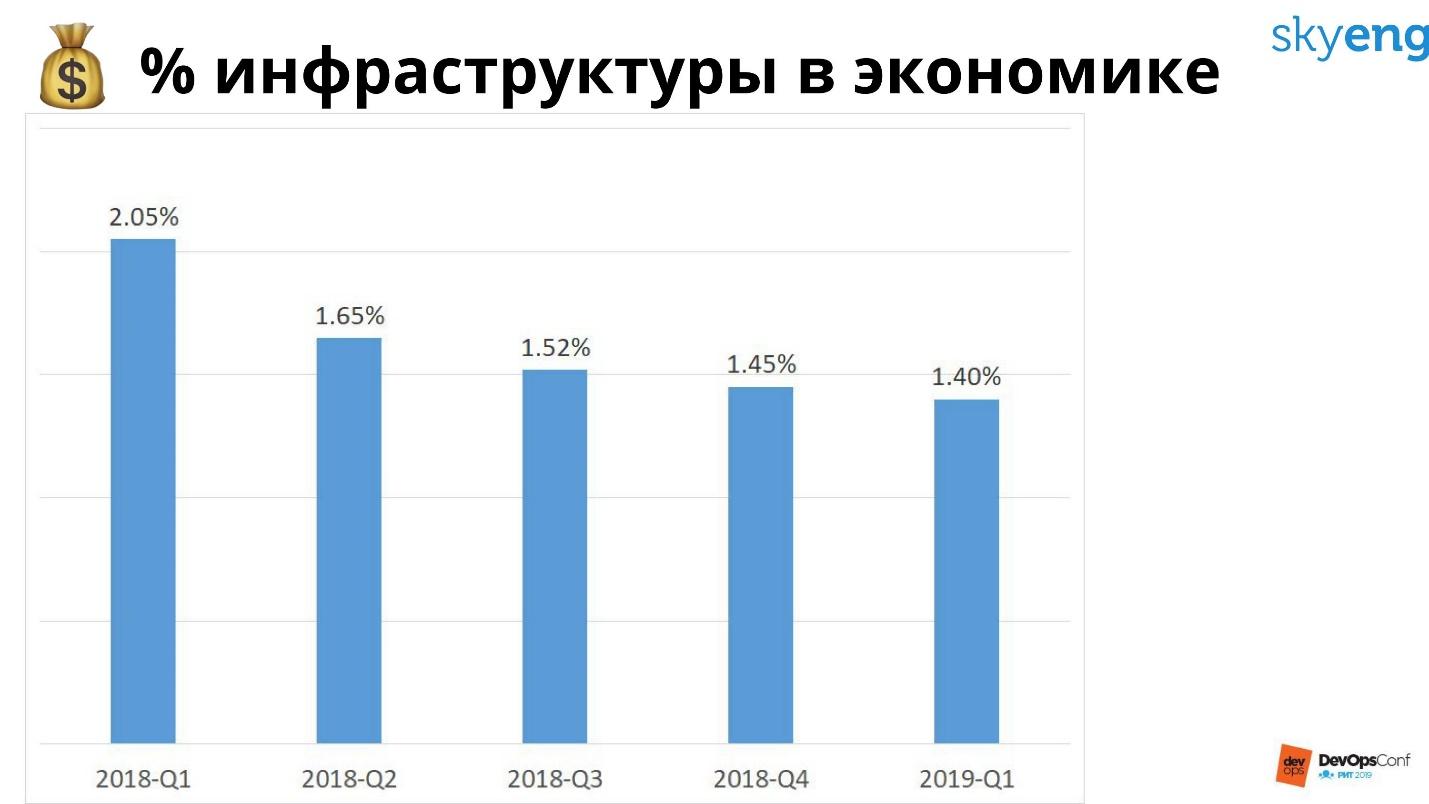
O percentual de infraestrutura está caindo, estamos trabalhando nisso. Isso nos beneficia, negócios e clientes. Você pode ter servidores baratos, não faça backup e abandone esse cronograma ainda mais. Mas isso está errado, é necessário considerar não apenas os custos de infraestrutura, mas também os custos de infraestrutura e as perdas esperadas pelas quedas.
Para cada serviço, consideramos quanto dinheiro por hora perdemos com sua queda. Mantemos um registro detalhado de quando e qual serviço estava mentindo, e quanto perdemos com isso.
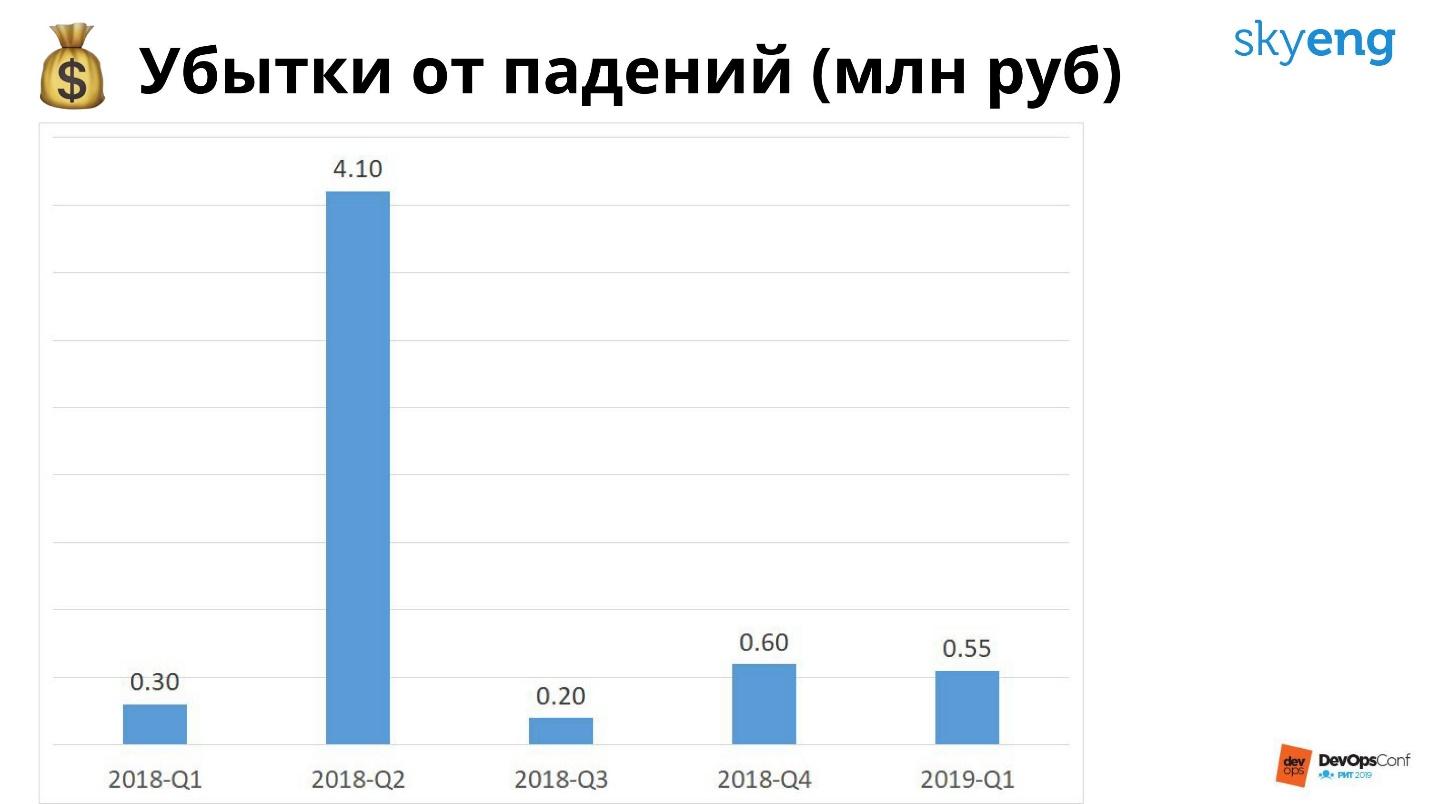 O cronograma de perdas por quedas no ano passado.
O cronograma de perdas por quedas no ano passado.A maioria das perdas no segundo trimestre de 2018 - olá a Roskomnadzor! Os gastos com infraestrutura no ano passado foram de 20 milhões, e os gastos com queda - 5 milhões: se tivéssemos reservado tudo, isso nos salvaria de Roskomnadzor, mas ainda estaríamos no vermelho em 15 milhões.
Não é rentável para as empresas duplicar tudo. É preciso pensar no que duplicar e no que não.
Duplicamos os serviços para os quais o custo de um servidor ou banco de dados adicional é menor que os riscos esperados de quedas.
Faça rápido
Medimos a porcentagem de tarefas concluídas no dia da configuração. A infraestrutura vem com muitas tarefas que precisam ser resolvidas aqui e agora. Outras equipes que não podem fazer seu trabalho dependem disso. Grandes tarefas que levam semanas são consideradas separadamente.
 Agende tarefas no dia da configuração.
Agende tarefas no dia da configuração.De acordo com o cronograma, a probabilidade de concluir uma tarefa no dia da configuração é de aproximadamente 80%. Vemos esse gráfico e acreditamos que tudo é legal. Mas outras equipes podem não pensar assim e avaliar de forma diferente. Portanto, realizamos pesquisas com outras equipes.
 Exemplo de pesquisa.
Exemplo de pesquisa.Realizamos pesquisas através do formulário habitual do Google com perguntas. Os desenvolvedores e nossos outros clientes respondem regularmente a eles.
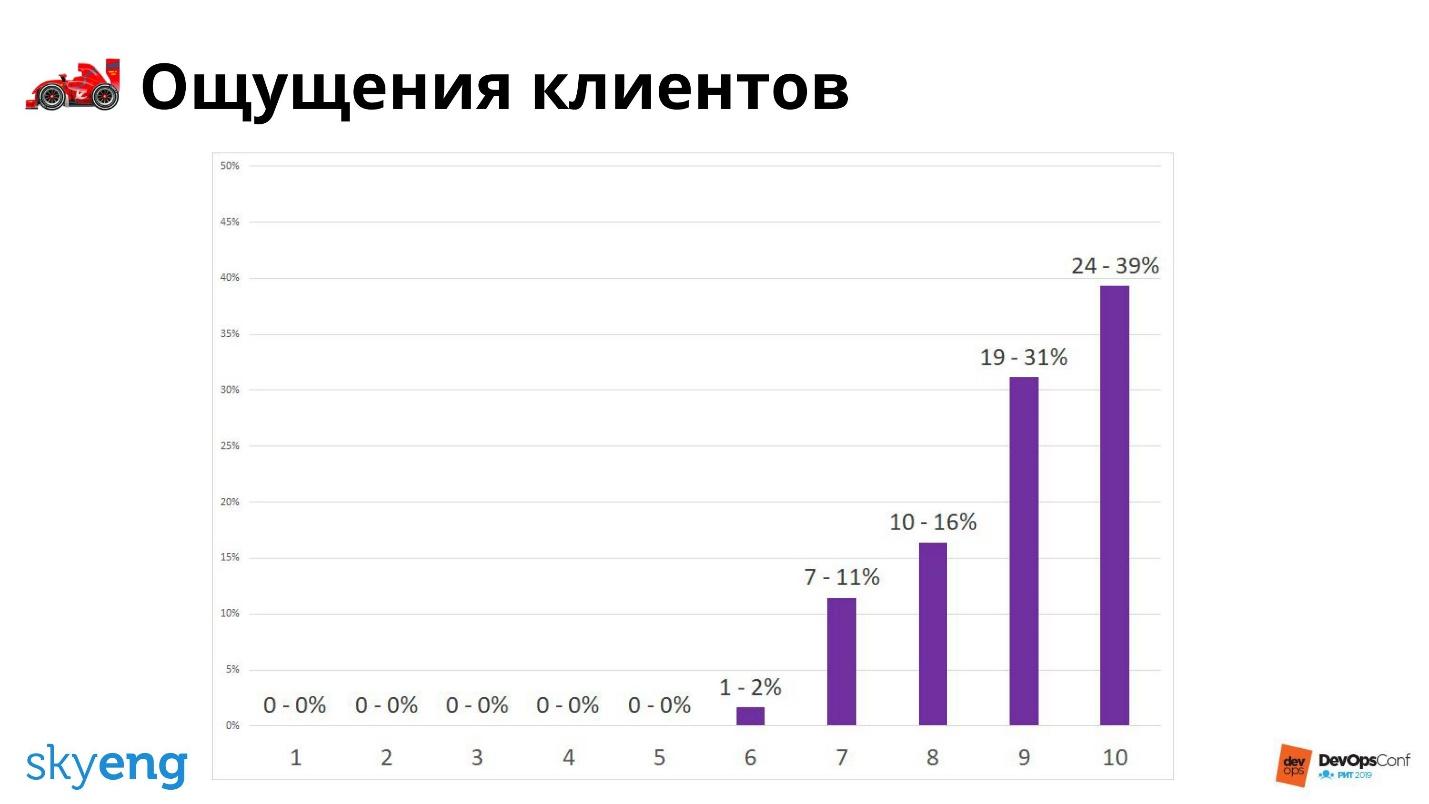 O resultado da pesquisa sobre a velocidade da infraestrutura.
O resultado da pesquisa sobre a velocidade da infraestrutura.O estado atual das coisas é bem descrito pelas pesquisas, mas não o futuro. Para avaliar a probabilidade da situação no futuro, medimos o número de tarefas executadas usando a solicitação pull. É isso que se beneficiará em um ano ou dois.
Seis meses atrás, decidimos que iríamos para "infraestrutura como código". Aqui medimos todas as solicitações da infraestrutura: preencha um dump ou um pedaço de logs, corrija o ponto nginx no produto ou crie um novo servidor. Todas essas são solicitações, e as avaliamos pelo número de solicitações pull. No futuro, queremos que qualquer solicitação seja resolvida com a ajuda de uma solicitação de recebimento ou para que simplesmente não nos sejam solicitados.
Sabemos que a abordagem "infraestrutura como código" fornece três bônus principais:
- redução no custo da mudança;
- aumento da taxa de mudança;
- redução de risco.
Precisamos dos três, portanto, nos movemos para esse lado e medimos o quão perto estamos.
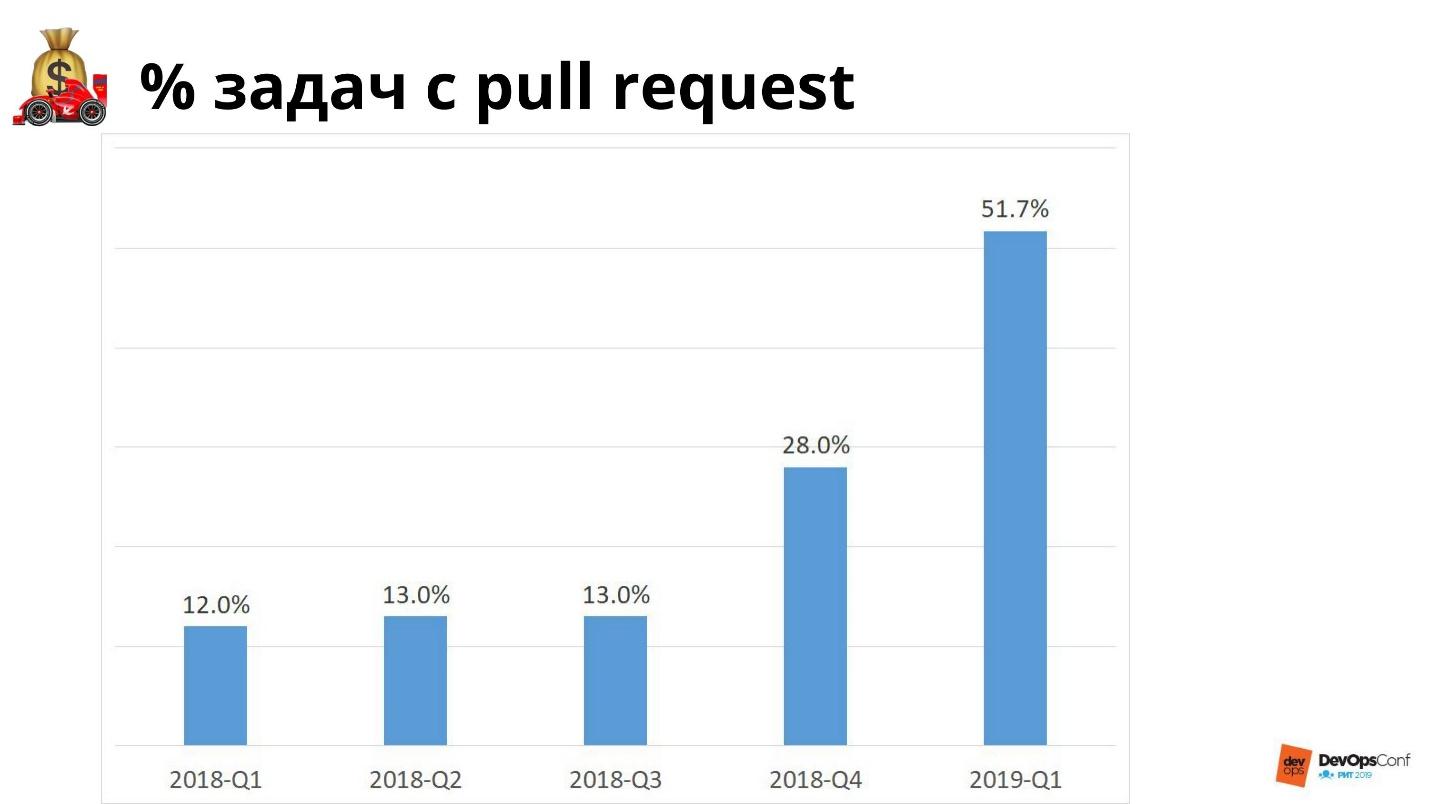
Para logs existe um sistema de visualização, para emissão de acessos existe o Terraform. Você pode criar um sistema no qual tudo será automatizado. Idealmente, este gráfico deve ir 100%. Quando qualquer chamada é feita usando código, podemos executá-lo rapidamente e implantá-lo em outra infraestrutura com a mesma rapidez.
É conveniente para desenvolvedores
Isso é importante para o Skyeng. Agora temos 100 desenvolvedores; até o final do ano, haverá 120. É importante que eles funcionem com eficiência. Queremos contratar pessoas por um motivo, precisamos daqueles que melhorarão a empresa.
A única e principal métrica para desenvolvedores é o resultado de uma pesquisa de satisfação com a equipe de infraestrutura.
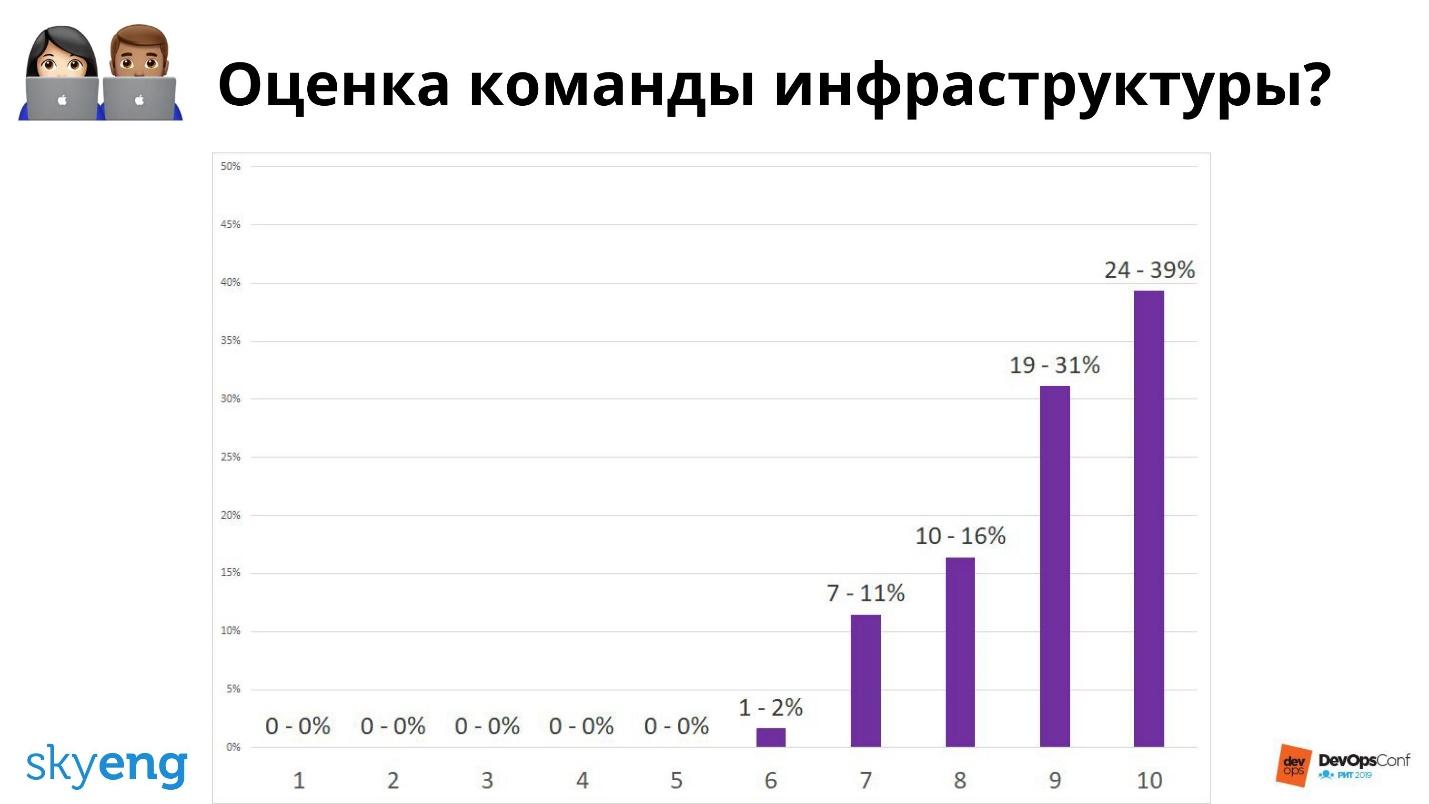 Em geral, está tudo bem.
Em geral, está tudo bem.A maioria nos valoriza bem. Mas se você perguntar o quanto eles estão satisfeitos com o ambiente de desenvolvimento, tudo não é tão agradável.
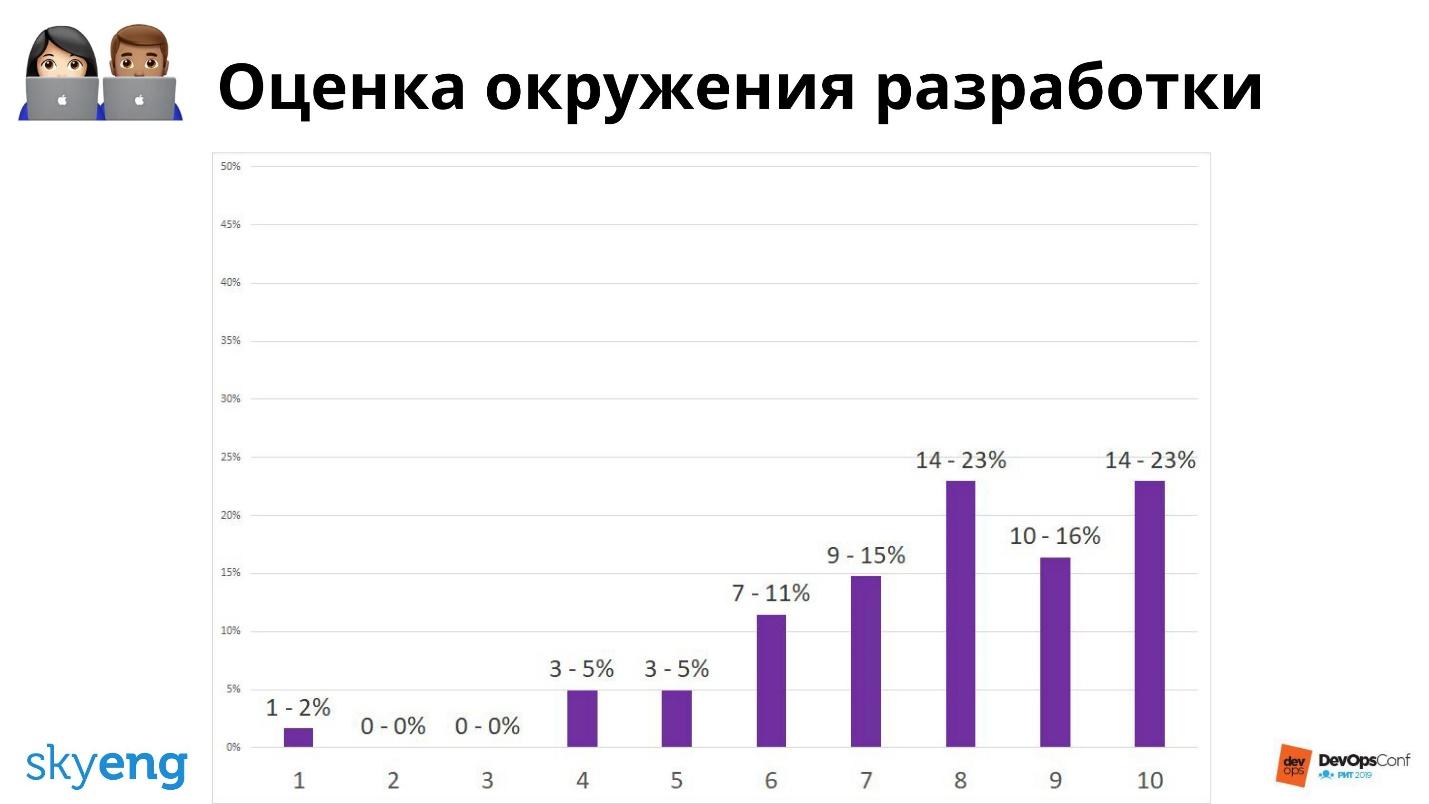
O ambiente de desenvolvimento é a nossa dor de cabeça. Este é um ponto de crescimento que precisa ser aprimorado. Portanto, entrevistamos pessoalmente os funcionários que responderam o pior: qual é o problema, o que diminuiu a velocidade ou não funcionou para ele? Saber o que está acontecendo pode melhorar as coisas.
Até você saber o que está acontecendo, você não pode mudar nada.
Resultado a longo prazo
Qualquer uma de nossas métricas pode ser aumentada simplesmente concentrando-se nela. Por exemplo, para aumentar a porcentagem de tarefas concluídas no mesmo dia, você pode descartar tudo e resolver apenas as tarefas que chegaram. Você pode executar todas as tarefas usando o código.
Por exemplo, em uma determinada cidade "N", todos os esforços são gastos no desenvolvimento de estradas. Eles fazem trilhas planas, largas e com várias faixas na cidade. Isso é legal primeiro, segundo ano. Mas todas as outras áreas são degradantes: não há ambiente acessível, árvores estão sendo derrubadas, há mais carros, não há estacionamentos suficientes e o ambiente já saiu da cidade por essas estradas. Em 5 a 10 anos, táxis autônomos e hiperloops já aparecerão na cidade vizinha, mas aqui ainda há apenas estradas tranquilas. É claro que este é o caminho para lugar nenhum.
Não devemos permitir isso, precisamos olhar para o futuro. Portanto, medimos a quantidade de tempo que gastamos em desenvolvimento e suporte.
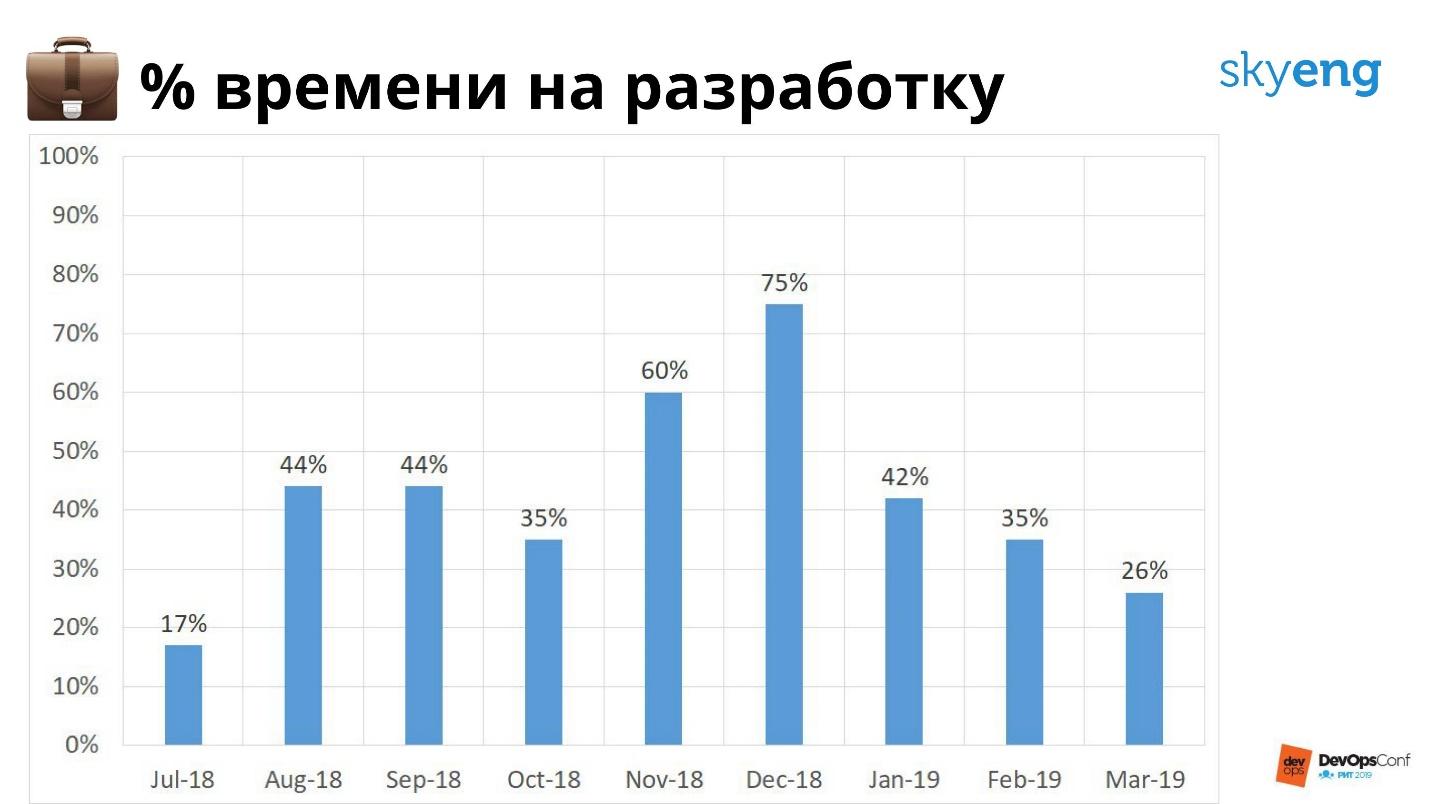
O gráfico mostra que, nos últimos meses, pouco tempo foi gasto no desenvolvimento. Para mim, como líder, isso é um sinal de que as pessoas são necessárias ou a automação de processos. De acordo com o cronograma, posso até calcular quantos meses todos os recursos serão necessários para apoiar, quando não chegarmos a tempo e houver um colapso.
Tarefas benéficas
Estabelecemos uma meta e pensamos em métricas, mas até começarmos a implementá-la com nossas mãos, nada mudará. Você precisa fazer não apenas algo, mas as tarefas mais lucrativas em termos de métricas e tempo.
Com o tempo, tudo simplifica.
Quaisquer duas tarefas podem ser comparadas com o tempo: a primeira leva uma semana, a segunda - 3 horas. Não depende de qual departamento a tarefa veio. As métricas são mais complicadas - existem muitas. Como calcular qual tarefa é mais lucrativa: a primeira ou a segunda, se uma otimiza algumas métricas e a outra, a outra?
Para nós mesmos, decidimos simplesmente - criamos uma unidade universal que descreve todas as tarefas.
Nossa unidade universal é o rublo . Avaliamos o benefício de qualquer tarefa pelo lucro que trará e dividirá pelo tempo necessário para concluir essa tarefa. Portanto, avaliamos cada tarefa em termos de métricas (rublos) e tempo.
 Nossas tarefas trimestrais.
Nossas tarefas trimestrais.Na captura de tela abaixo, as duas últimas colunas indicam quanto dinheiro ganharemos na tarefa e quanto tempo gastaremos nela. A equipe de infraestrutura ganha dinheiro melhorando as condições dos desenvolvedores, otimizando os processos na empresa e a operação dos servidores. Estamos mudando para o Docker não porque é legal, mas porque pensamos que era rentável.

Métricas adicionais que medimos.
Avanço:
- % suporte;
- % de tarefas com PR;
- % de tarefas fechadas por dia.
Atrasado:
- % do lucro da empresa;
- perdas de quedas;
- revisões do desenvolvedor.
Isso é apenas parte das métricas, temos mais delas.
Tarefas que não avaliamos
Nós não avaliamos bugs. Se pegarmos algum tipo de sistema para dar suporte e suporte, corrigiremos os erros simplesmente porque eles não deveriam estar lá.
O mesmo se aplica ao suporte. Em geral, medimos quanto tempo é gasto em suporte e não permitimos que seja demais. Avaliamos cada sistema como um todo por seus benefícios ou malefícios. Tarefas mais fáceis de executar ou muito urgentes, não avaliamos. Tudo o que eu falei não se aplica a eles - nós apenas os fazemos.
Por que é útil e importante avaliar tarefas
Prêmios e conquistas . Nos negócios, você sempre precisa falar a língua do dinheiro. Ele entende apenas dinheiro. Se você diz que tem um projeto, o corte, ele trará 5 milhões e pedirá um milhão de prêmios por equipe - eles concordarão com você. Para os negócios, isso é compreensível.
Contratação Não ofereça empresas para contratar funcionários e introduzir novas tecnologias, mas ofereça dinheiro juntos. Então ele certamente encontrará você. No mínimo, a discussão começará não ao longo do caminho: "Você tem tempo ou não tem tempo, precisa de uma pessoa ou não", mas quão legal é o projeto para o qual você precisa de uma pessoa, ele o administrará e o projeto realmente trará tantos milhões. A conversa seguirá uma direção diferente e você entenderá com antecedência se esse projeto vale o custo ou é mais fácil jogá-lo fora e procurar outro?
Otimização de custos . Se entendermos em que dinheiro é gasto, podemos contá-lo facilmente e otimizar despesas.
Decisões administrativas . Este item eu percebi recentemente. A infraestrutura começou a crescer e eu decidi dividir a equipe em subcomandos. Surgiu a questão de como fazer isso com precisão, com o objetivo de aumentar a equipe. A solução apareceu com base em métricas - dividiu todas as métricas de nossa infraestrutura em blocos e cada equipe é responsável por suas próprias métricas. Eu tenho 3 subcomandos. Para cada um, a área de responsabilidade comum é compreensível e todos os participantes compreendem pelo que são pessoalmente responsáveis. Esta é uma área de responsabilidade compreensível.
Para ficar legal
- Estabeleça uma meta - em nenhum lugar sem ela.
- Divida a meta em métricas e meça.
- Avalie tarefas e complete o mais legal.
Então você definitivamente terá sucesso!
No DevOps Conf 2019 , falaremos sobre "infraestrutura como código" separadamente. O futuro da abordagem, os padrões do Terraform, a implantação e o gerenciamento da infraestrutura BareMetal e Kubernetes são quatro documentos sobre o assunto. Uma conferência que reunirá processo e tecnologia será realizada em Moscou, nos dias 30 de setembro e 1º de outubro . A programação está pronta, você pode estudar o programa , resumos ou reservar ingressos .
Assine a newsletter e o canal Telegram e fique atento às novidades e novos relatórios.