
Quando você ouve entrevistas o dia inteiro, começa a perceber padrões. Antes, no nosso caso, a ausência deles. Consegui encontrar apenas duas coisas que permanecem inalteradas. Eu até inventei um jogo alcoólico baseado neles: toda vez que alguém decide que a resposta para a pergunta é uma tabela de hash, bebemos uma pilha, se a resposta correta é realmente uma tabela de hash, bebemos duas. Mas eu não aconselho jogar, quase morri.
Por que estou ouvindo entrevistas o dia todo? Porque, há alguns anos, eu me tornei um dos criadores do serviço
Interviewing.io , uma plataforma de
entrevistas onde pessoas da área de TI podem desenvolver habilidades de comunicação com o empregador e encontrar trabalho enquanto isso.
Como resultado, tenho acesso a uma grande quantidade de dados sobre como o mesmo usuário se mostra em entrevistas diferentes. E eles se tornam tão imprevisíveis que você inevitavelmente pensará em quão geralmente são indicativos os resultados de uma única reunião.
Como obtemos os dados
Quando o usuário que conduz a entrevista e o usuário que procura trabalho se encontram, eles se reúnem em um editor de código conjunto. Lá, a capacidade de se comunicar em voz e por meio de mensagens de texto está conectada; existe um análogo de um quadro de marcadores para a tomada de decisões - você pode iniciar imediatamente problemas técnicos.
As perguntas em nossas entrevistas geralmente são da categoria das perguntas feitas durante a entrevista por telefone aos candidatos ao cargo de desenvolvedor de software de back-end. Os usuários que conduzem entrevistas geralmente são funcionários de grandes empresas (Google, Facebook, Yelp) ou representantes de startups com forte viés técnico (Asana, Mattermark, KeepSafe e outros). No final de cada reunião, os empregadores avaliam os candidatos de acordo com vários critérios, um dos quais são habilidades de programação. As classificações são colocadas em uma escala de um ("mais ou menos") a quatro ("ótimo!"). Na nossa plataforma, notas de três e acima na maioria dos casos significam que o candidato é forte o suficiente para passar para a próxima etapa.
Aqui você pode dizer: “Tudo isso é maravilhoso, mas o que há de especial aqui? Muitas empresas coletam essas estatísticas no processo de seleção. ” Nossos dados diferem dessas estatísticas em um aspecto: o mesmo usuário pode participar de várias entrevistas, cada uma delas com um novo funcionário da nova empresa. Isso abre oportunidades para uma análise comparativa muito interessante em um ambiente mais ou menos estável.
Conclusão # 1: Os resultados variam muito de entrevista para entrevista
Vamos começar com algumas fotos. No gráfico abaixo, cada ícone na forma de homenzinho mostra a classificação individual média de um dos usuários que participaram de duas ou mais entrevistas. Um dos parâmetros que não são exibidos neste gráfico é o período de tempo.
Você pode ver como o sucesso das pessoas muda com o tempo, aqui. Há algo no espírito do caos primitivo.
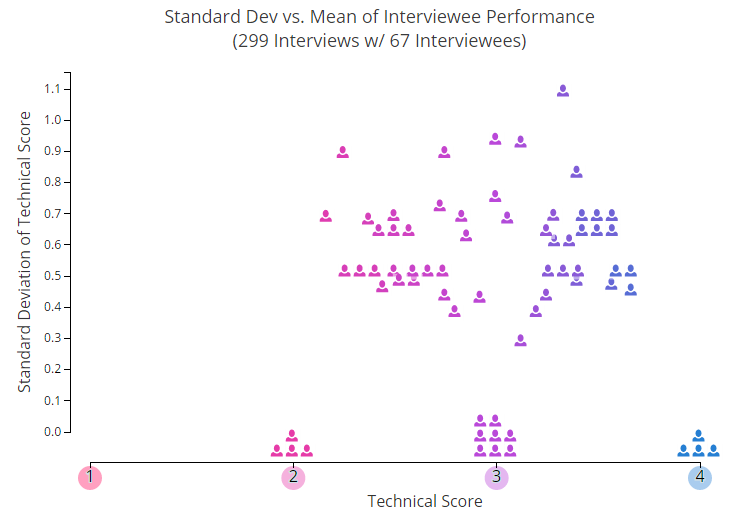
O eixo Y mostra um desvio típico dos valores médios - consequentemente, quanto mais subimos, mais imprevisíveis são os resultados das entrevistas. Como você pode ver, cerca de 25% dos participantes são mantidos de forma estável no mesmo nível, enquanto os demais pulam para cima e para baixo.
Depois de estudar cuidadosamente esse cronograma, você, apesar de uma pilha de dados, provavelmente conseguiria descobrir qual dos usuários você gostaria de convidar para uma entrevista. Mas aqui é importante lembrar: pegamos valores médios. Agora imagine que você precisa tomar uma decisão com base em uma única avaliação, que foi usada para calculá-la. É aqui que os problemas começam.
Para maior clareza, você pode abrir uma
versão interativa do gráfico morto . Lá, cada ícone é aberto quando você passa o mouse e pode ver qual nota o usuário recebeu em cada uma das entrevistas. Os resultados podem surpreendê-lo bastante! Bem, por exemplo:
- A maior parte dos que têm pelo menos um quatro já se viram pelo menos uma vez nas duplas.
- Mesmo se você selecionar apenas os candidatos mais fortes (a pontuação média é de 3,3 e superior), os resultados ainda flutuam significativamente
- A "média" (pontuação média - de 2,6 a 3,3), os resultados são particularmente contraditórios
Nós nos perguntamos se havia alguma relação entre o nível do candidato e a amplitude das vibrações. Em outras palavras, talvez para aqueles mais fracos, haja saltos acentuados característicos, enquanto programadores fortes são estáveis? Como se vê, não. Quando realizamos uma análise de regressão de um desvio típico em relação à estimativa média, não conseguimos estabelecer nenhuma relação significativa (R ao quadrado era de cerca de 0,03). E isso significa que as pessoas obtêm notas diferentes, independentemente do seu nível geral.
Eu diria o seguinte: quando você olha para todos esses dados e imagina que precisa escolher uma pessoa de acordo com os resultados de uma entrevista, parece que você está olhando para uma sala bonita e luxuosamente mobiliada através de um buraco de fechadura. Em um caso, você tem sorte de ver uma foto na parede, em outro - uma coleção de vinhos e no terceiro - você se enterra na parede traseira do sofá.
Em situações reais, quando estamos tentando decidir se chamamos um candidato para uma entrevista no escritório, geralmente tentamos evitar erros do primeiro tipo (ou seja, não selecionamos aleatoriamente aqueles que estão abaixo da barra) e erros do segundo tipo (ou seja, não recusar aqueles que Valeria a pena convidar). Os líderes de mercado geralmente constroem uma estratégia baseada no fato de que erros do segundo tipo causam menos danos. Parece lógico, certo? Se houver recursos suficientes e o número de candidatos for grande, mesmo com um grande número de erros do segundo tipo, ainda haverá alguém adequado.
Mas essa estratégia de cometer erros do segundo tipo tem um lado sombrio e agora se faz sentir, se espalhando pela atual crise de contratação na esfera de TI. As entrevistas individuais em sua forma atual fornecem informações suficientes? Estamos rejeitando, apesar do aumento da demanda por desenvolvedores talentosos, trabalhadores competentes simplesmente porque estamos tentando considerar um cronograma extenso com fortes diferenças através de um pequeno olho mágico?
Portanto, se ignorarmos as metáforas e a leitura moral: como os resultados das entrevistas são tão imprevisíveis, qual é a probabilidade de um candidato forte falhar em uma entrevista por telefone?
Conclusão No. 2: A probabilidade de falha na entrevista com base nos resultados de tentativas anteriores
Abaixo está a distribuição percentual de toda a base de nossos usuários por estimativas médias.
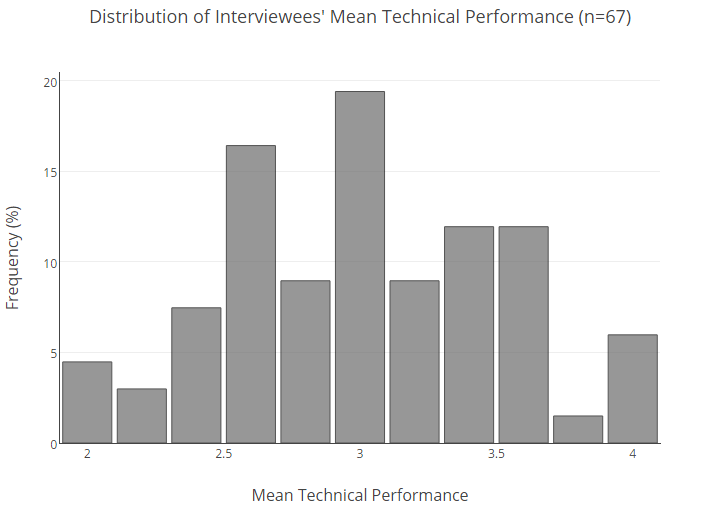
Para entender a probabilidade de um candidato com um certo resultado médio não se mostrar bem em uma entrevista, tivemos que fazer estatísticas.
Primeiro, dividimos os entrevistados em grupos com base nas classificações médias (enquanto os valores foram arredondados para 0,25). Em seguida, para cada grupo, calculou-se a probabilidade de falha, ou seja, obtendo pontuação igual ou inferior a 2. Além disso, para compensar a quantidade modesta de dados,
re-amostramos .
Ao compilar a re-amostragem, consideramos o resultado de uma futura entrevista como uma distribuição multi-nominal. Em outras palavras, apresentamos que seus resultados são determinados pelo lançamento de um dado com quatro faces e, para cada grupo, o centro de gravidade do cubo é deslocado de uma certa maneira.
Então começamos a jogar esses dados até criarmos um novo conjunto de dados simulados para cada grupo. Novas probabilidades de falha para usuários com estimativas diferentes foram calculadas com base nesses dados. Abaixo você pode ver o gráfico que recebemos após 10.000 desses lançamentos.
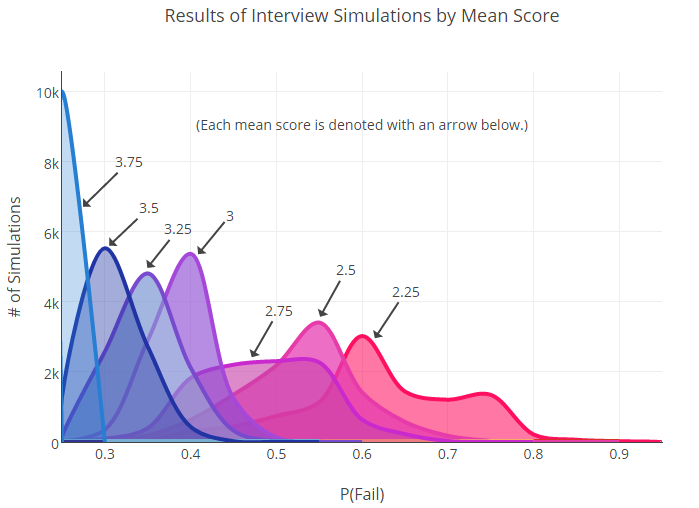
Como você pode ver, existem muitas interseções. Isso é importante: o fato de se sobrepor nos diz que pode não haver diferenças estatisticamente significativas entre alguns dos grupos (por exemplo, 2,75 e 3).
Obviamente, quando tivermos mais dados (muito mais), os limites entre os grupos serão mais claros. Por outro lado, o próprio fato de ser necessária uma amostra enorme para encontrar a diferença entre os indicadores de taxa de falha pode indicar uma variabilidade inicialmente alta nos resultados para o usuário médio.
No final, com confiança, podemos dizer o seguinte: a diferença entre os pontos extremos da escala (2,25 e 3,75) é significativa, mas todo o resto já é muito menos inequívoco.
No entanto, com base nessa distribuição, fizemos uma tentativa de calcular a probabilidade percentual de um candidato com uma ou outra classificação média mostrar um resultado ruim em uma única entrevista:
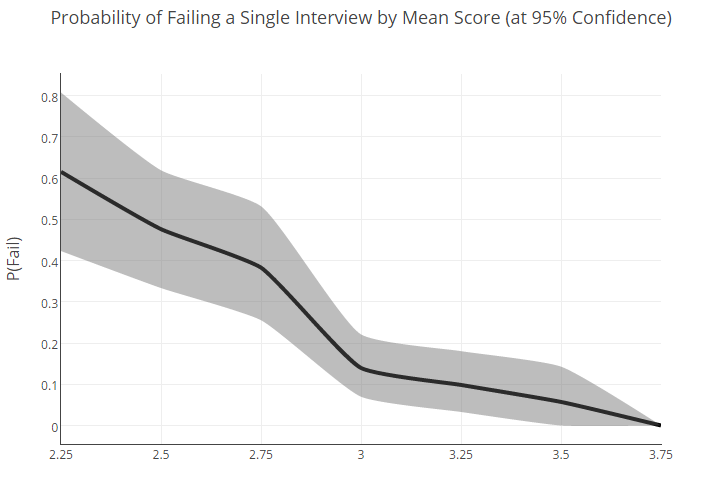
O fato de pessoas com um bom nível geral (ou seja, uma classificação média de cerca de 3) poderem falhar com uma probabilidade de 22% mostra que os esquemas de seleção que usamos agora podem e devem ser aprimorados. Resultados nebulosos para a "média" apenas confirmam esta conclusão.
Então, as entrevistas estão condenadas?
Em geral, a palavra “entrevistas” evoca em nossas mentes uma imagem de algo informativo e com resultados reproduzíveis. No entanto, os dados que coletamos falam sobre algo completamente diferente. E isso tem algo em comum com a minha experiência pessoal na contratação de funcionários e com as opiniões que ouço frequentemente na comunidade.
O artigo de Zack Holman,
Startup Interviewing is F *****, elucida essa discrepância entre os motivos para a seleção de candidatos e o trabalho que eles têm que fazer. Os senhores deputados da TripleByte
chegaram a conclusões semelhantes , tendo processado seus próprios dados. A plataforma
rejeitado.us recentemente forneceu evidências vívidas de inconsistência no processo de entrevista.
Pode-se argumentar que muitos que foram selecionados após uma entrevista por telefone com a empresa A mostraram o melhor resultado em outra entrevista, terminaram em algumas das empresas consideradas decentes - e agora, seis meses depois, recebem ofertas para conversar com recrutadores da empresa A. E, apesar de todos os esforços de ambas as partes, esse processo de seleção lenta, imprevisível e, por fim, aleatória de candidatos continua, como se estivesse em um círculo mágico.
Portanto, sim, é claro, uma das conclusões que podem ser tiradas é que as entrevistas técnicas estão em um impasse; elas não fornecem informações confiáveis o suficiente para prever o resultado de uma entrevista individual. Entrevistas com problemas algorítmicos são um tópico muito quente na comunidade, e gostaríamos de analisá-lo em detalhes no futuro.
Será especialmente interessante rastrear a relação entre o sucesso dos candidatos e o tipo de entrevista - temos cada vez mais abordagens e variações aparecendo em nossa plataforma. De fato, esse é um dos nossos objetivos a longo prazo: como explorar os dados coletados, examinar o leque de estratégias atuais de seleção de candidatos e tirar algumas conclusões sérias e baseadas em dados sobre quais formatos de entrevista fornecem as informações mais úteis.
Enquanto isso, estou inclinado à idéia de que é melhor olhar para um nível generalizado do que ser guiado em uma decisão importante pelos resultados arbitrários de uma única reunião. Os dados generalizados nos permitem fazer uma correção não apenas para aqueles que, em um caso isolado, responderam de maneira pouco característica, mas também para aqueles que deixaram uma boa impressão puramente por azar ou, eventualmente, inclinaram a cabeça na frente desse monstro e memorizaram a entrevista Cracking the Coding.
Entendo que nem sempre é prático ou mesmo possível para uma empresa coletar outras evidências da habilidade do candidato em algum lugar selvagem. Mas se, digamos, um caso limítrofe ou uma pessoa não se mostrar como você esperava, provavelmente faz sentido conversar com ela novamente e mudar para outro material antes de tomar uma decisão final.