Outro dia, o Moscow Python Meetup # 66 foi realizado - a comunidade continua discutindo ferramentas relevantes que aprimoram a linguagem e a adaptam a diferentes ambientes. Inclusive na reunião, meu relatório foi feito. Meu nome é Nail, estou usando o Yandex.Connect.

A história que preparei foi sobre o uWSGI. Este é um servidor de aplicativos da web multifuncional e todos os aplicativos modernos são acompanhados por métricas. Tentei mostrar como os recursos do uWSGI podem ajudar na coleta de métricas.
- Olá pessoal, fico feliz em receber todos vocês nas paredes do Yandex. É bom que tantas pessoas tenham visto meus e outros relatórios, que tantas pessoas estejam interessadas e morem em Python. Sobre o que é o meu relatório? É chamado de "uWSGI para ajudar nas métricas". Vou falar um pouco sobre mim. Estou no Python há seis anos, trabalho na equipe Yandex.Connect, estamos escrevendo uma plataforma de negócios que fornece serviços Yandex desenvolvidos internamente para usuários de terceiros, ou seja, para todos. Qualquer pessoa ou organização pode usar os produtos desenvolvidos pela Yandex para si próprios, para seus próprios fins.
Falaremos sobre métricas, como obtê-las, como usamos em nossa equipe o uWSGI como uma ferramenta para obter métricas, como isso nos ajuda. Depois, vou contar uma pequena história de otimização.
Algumas palavras sobre métricas. Como você sabe, o desenvolvimento de um aplicativo moderno é impossível sem testes. É estranho se alguém desenvolve seus aplicativos sem testes. Ao mesmo tempo, parece-me que a operação de um aplicativo moderno é impossível sem métricas. Nossa aplicação é um organismo vivo. Uma pessoa pode tomar algumas métricas, como pressão, freqüência cardíaca, - o aplicativo também possui indicadores nos quais estamos interessados e gostaríamos de observar. Ao contrário de uma pessoa que geralmente usa essas métricas vitais quando se sente mal, no caso de um aplicativo, sempre podemos executá-las.

Por que estamos fazendo métricas? A propósito, quem usa métricas? Espero que, depois do meu relatório, haja mais mãos e as pessoas se interessem e comecem a coletar métricas, que entendam que isso é necessário e útil.
Então, por que precisamos de métricas? Antes de tudo, vemos o que está acontecendo com o sistema, destacamos alguns indicadores normativos para o nosso sistema e entendemos se vamos além desses indicadores durante o processo de inscrição ou não. Você pode observar algum comportamento anormal do sistema, por exemplo, um aumento no número de erros, entender o que há de errado com o sistema, diante de nossos usuários e receber mensagens sobre incidentes não dos usuários, mas do sistema de monitoramento. Com base nas métricas, podemos configurar alertas e receber sms, cartas, chamadas, como desejar.

O que são, em regra, métricas? Estes são alguns números, talvez um contador que cresça monotonamente. Por exemplo, o número de solicitações. Alguns valores unitários que mudam no tempo aumentam ou diminuem. Um exemplo é o número de tarefas em uma fila. Ou histogramas - valores que caem em alguns intervalos, os chamados cestos. Como regra, é conveniente ler esses dados relacionados ao tempo e descobrir em qual intervalo de tempo quantos valores se encaixam.

Que tipo de métrica podemos usar? Vou me concentrar no desenvolvimento de aplicativos da Web, pois está mais perto de mim. Por exemplo, podemos gravar o número de solicitações, nossos terminais, o tempo de resposta de nossos terminais, os códigos de resposta de serviços relacionados, se formos a eles e tivermos uma arquitetura de microsserviço. Se usarmos o cache, poderemos entender a eficiência do cache de falha ou acerto, entender a distribuição dos tempos de resposta dos servidores de terceiros e, por exemplo, do banco de dados. Mas, para visualizar as métricas, você precisa coletá-las de alguma forma.

Como podemos coletá-los? Existem várias opções. Quero falar sobre a primeira opção - um esquema de envio. Em que consiste?
Suponha que recebamos uma solicitação de um usuário. Localmente, com nosso aplicativo, instalamos algum tipo, geralmente um agente push. Digamos que temos um Docker, existe um aplicativo e um agente push ainda permanece em paralelo. O agente de envio recebe o valor das métricas localmente, de alguma forma, armazena em buffer, faz lotes e as envia para o sistema de armazenamento de métricas.
Qual é a vantagem de usar esquemas push? Podemos enviar alguma métrica diretamente para o sistema de métrica a partir do aplicativo, mas, ao mesmo tempo, obtemos algum tipo de interação de rede, latência e sobrecarga para coletar métricas. No caso de um cliente push local, isso é nivelado.
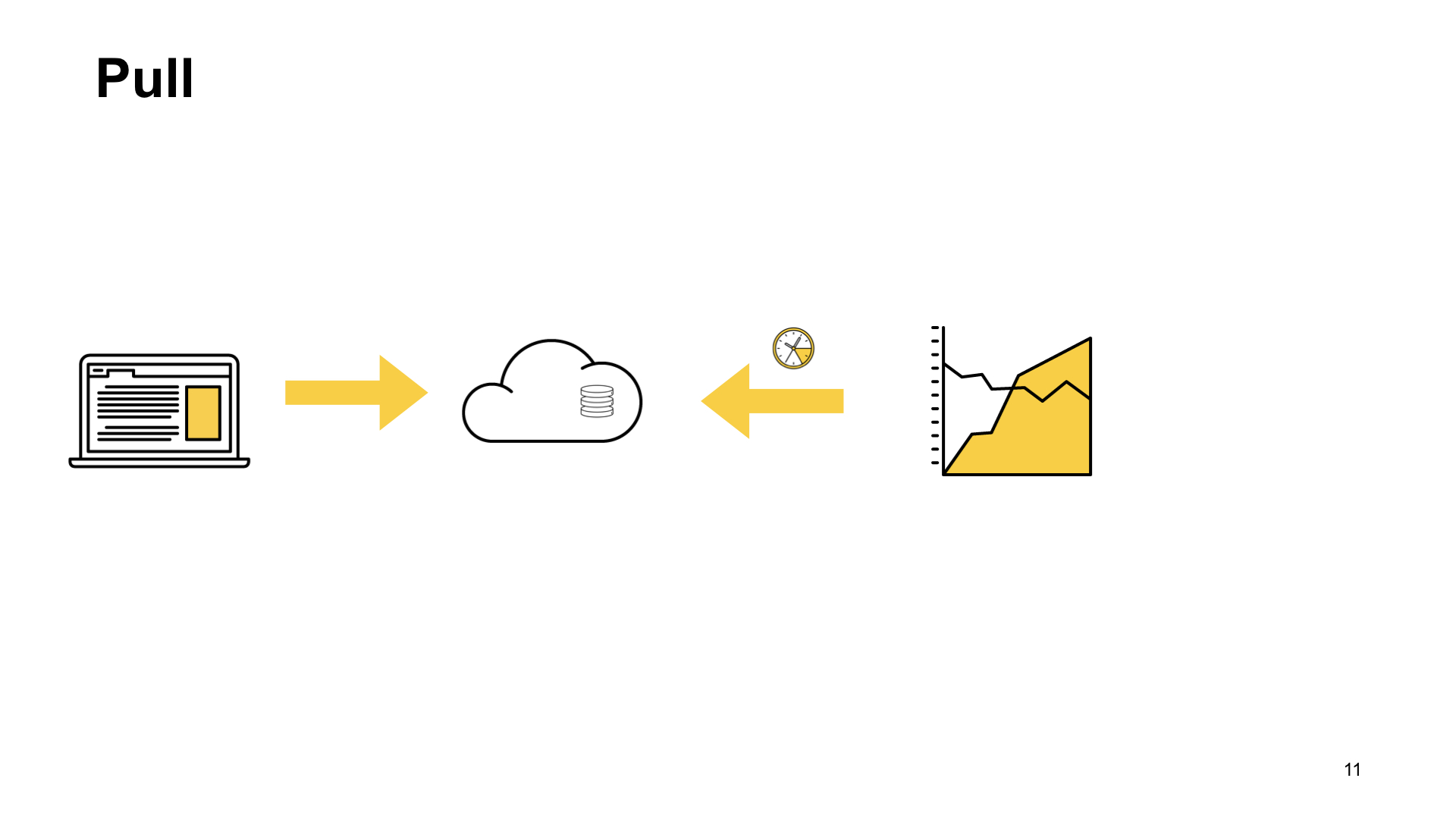
Outra opção é um esquema de recebimento. Com o esquema pull, temos o mesmo cenário. Uma solicitação do usuário chega até nós, de alguma forma a mantemos em casa. E então, com uma certa frequência - uma vez por segundo, uma vez por minuto, conforme necessário - o sistema de coleta de métricas chega a um endpoint especial de nossa aplicação e utiliza esses indicadores.

Outra opção são os logs. Todos escrevemos logs e os enviamos para algum lugar. Nada nos impede de pegar esses logs, de algum modo processá-los e obter métricas com base nos logs.
Por exemplo, escrevemos o fato da solicitação de um usuário no log e, em seguida, coletamos os logs, hop-hop, contados. Um exemplo típico é o ELK (Elasticsearch, Logstash, Kibana).

Como isso funciona conosco? A Yandex possui sua própria infraestrutura, seu próprio sistema de coleta de métricas. Ela espera uma resposta padronizada para um identificador que implementa um esquema de recebimento. Além disso, temos uma nuvem interna onde lançamos nosso aplicativo. E tudo isso é integrado em um único sistema. Fazendo o upload para a nuvem, simplesmente indicamos: "Vá para esta caneta e obtenha as métricas".

Aqui está um exemplo de resposta para o esquema pull que nosso sistema de coleta de métricas espera.
Para nós mesmos na equipe, decidimos escolher uma maneira mais adequada para nós, para destacar vários critérios pelos quais escolheremos a melhor opção para nós. Eficiência é a rapidez com que podemos obter no sistema métrico uma demonstração do fato de qualquer ação. Dependência - se precisamos instalar ferramentas adicionais ou configurar a infraestrutura para obter a métrica. E versatilidade - como esse método é adequado para diferentes tipos de aplicações.
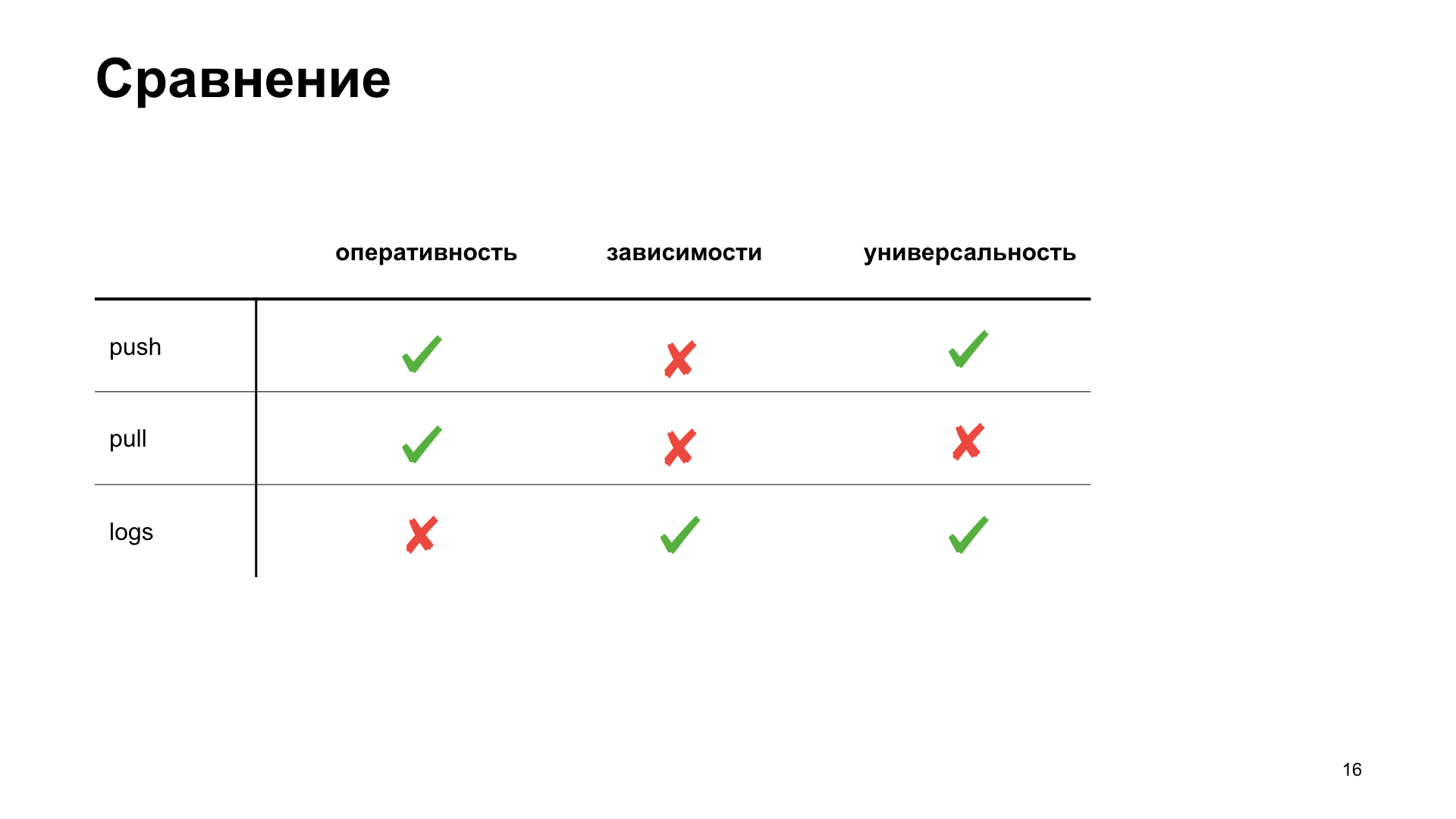
Foi o que conseguimos no final. Embora, de acordo com os critérios de eficiência e versatilidade, o esquema de push ganhe. Mas estamos desenvolvendo um aplicativo da Web e nossa nuvem já possui uma infraestrutura pronta para trabalhar com essa tarefa, por isso decidimos escolher um esquema pull para nós mesmos. Nós falaremos sobre ela.
Para dar algo ao esquema pull, precisamos pré-agregá-lo em algum lugar, salvá-lo. Nosso sistema de monitoramento entra em puxadores a cada cinco segundos. Onde podemos salvar? Localmente na sua memória ou em um armazenamento de terceiros.

Se salvarmos localmente, como regra, isso é adequado para o caso de um processo. E nós, em nosso uWSGI, executamos vários processos em paralelo. Ou podemos usar algum tipo de armazenamento compartilhado. O que vem à nossa mente com a palavra "armazenamento compartilhado"? Esse é algum tipo de banco de dados Redis, Memcached, relacionais ou não relacionais, ou mesmo um arquivo.

Sobre o uWSGI. Deixe-me lembrá-lo daqueles que o usam pouco ou raramente: o uWSGI é um servidor de aplicativos da web que permite executar aplicativos Python sob você. Ele implementa a interface, o protocolo uWSGI. Este protocolo está descrito no PEP 333, que você está interessado, você pode ler.

Também nos ajudará a escolher a melhor solução Yandex.Tank. Esta é uma ferramenta de teste de carga, permite que você projete nosso aplicativo com vários perfis de carga e cria belos gráficos. Ou funciona no console, como você gosta.

Os experimentos. Vamos criar uma aplicação sintética para nossos testes sintéticos, vamos revesti-la com um tanque. O aplicativo uWSGI terá um conflito simples com 10 trabalhadores.

Aqui está o nosso aplicativo Flask. A carga útil que nosso aplicativo executa, emularemos um loop vazio.

Disparamos e o Yandex.Tank nos fornece um desses gráficos. O que ele está mostrando? Percentis de tempos de resposta. A linha inclinada são os RPS que estão crescendo e os histogramas são os percentis em que nosso servidor da Web se encaixa sob essa carga.
Tomaremos essa opção como referência e veremos como as diferentes opções para armazenar métricas afetam o desempenho.

A opção mais simples é usar o PostgreSQL. Como trabalhamos com o PostgreSQL, nós o temos. Vamos usar o que já está pronto.
Digamos que temos um rótulo no PostgreSQL no qual simplesmente incrementamos o contador.

Já em pequenas quantidades de RPS, vemos uma forte degradação do desempenho. Pode-se dizer apenas enorme.

A próxima opção é Redis. Mas aqui estamos mais espertos: instalamos localmente e o utilizamos não pela rede, mas pelo soquete Unix. Aumente também o contador.
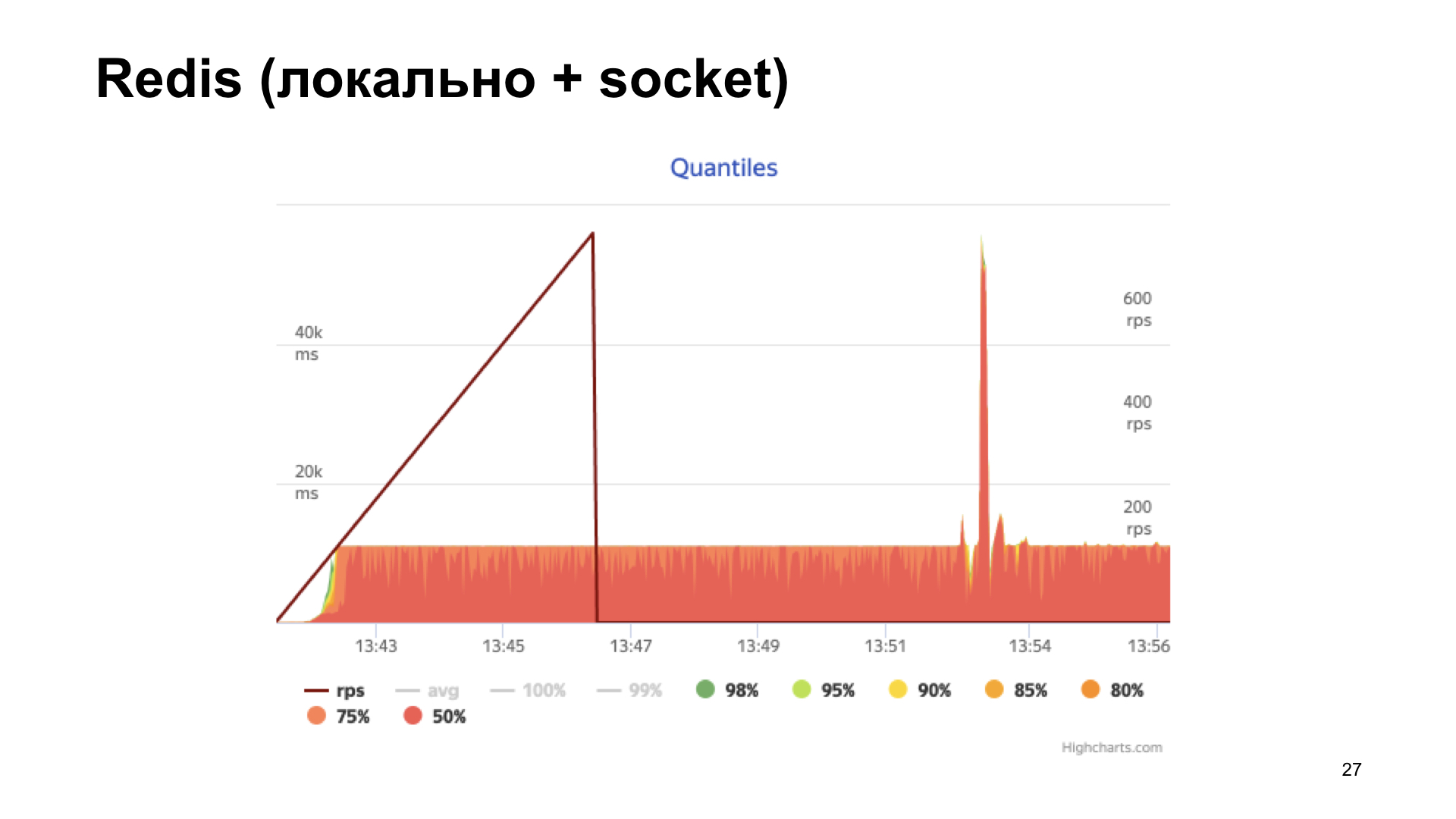
Nós obtemos o histograma dos tempos de resposta na saída. Vemos que as coisas estão melhores aqui, mas em algum momento chegamos a uma prateleira e, em seguida, a produtividade não está mais aumentando. Essa opção parece mais ideal, mas queremos fazer ainda melhor.

Aqui o uWSGI, uma combinação real, vem em nosso auxílio. Existem muitos módulos diferentes. Mule para executar subprocessos, estrutura de cache, cron, subsistema de métricas e sistema de alerta. "Sistema de métricas do subsistema" - parece promissor.

Ela sabe como adicionar algum tipo de métrica, aumentar o contador, diminuir o contador, multiplicar, dividir - o que seu coração desejar.
O único subsistema de métricas não pode fornecer exatamente as métricas incorporadas a ele.
Por que isso é importante para nós? Como você viu anteriormente, temos uma maneira de fornecer estatísticas em um formato específico, e vários trabalhadores estão em execução. Não sabemos quais funcionários receberão a solicitação, mas, para retornar todas as métricas, precisamos criar algum tipo de registro de nomes e, de alguma forma, embaralhá-lo entre os processos. Isso é grande coisa, eu quero evitar isso. O que mais nós temos?

Claro, subsistema de cache. E aqui vemos: ele pode fazer quase a mesma coisa e também é capaz de fornecer os nomes das chaves armazenadas no cache. É disso que você precisa.

O subsistema de cache é um cache incorporado ao uWSGI. Um módulo rápido e seguro para threads, que é um armazenamento comum de valores-chave.

Mas, como esse é um cache, existe um segundo problema bem conhecido: como nomear uma variável e como invalidar o cache? No nosso caso, vamos ver quais são as configurações de cache padrão. Possui restrições no comprimento da chave. No nosso caso, esse é o nome da métrica. O padrão é 2048 bytes. E você pode aumentar a configuração, se necessário. O número de elementos que ele armazena por padrão é 65.536. Parece que esse valor deve ser suficiente para todos. É improvável que alguém colete um número tão grande de métricas de seu aplicativo.
E ttl por padrão é 0. Ou seja, os valores dos caches armazenados não são invalidados por tempo. Assim, podemos obtê-los do cache e enviá-los ao sistema de métricas.

Novamente, a opção é um aplicativo que usa a caixa uWSGI.
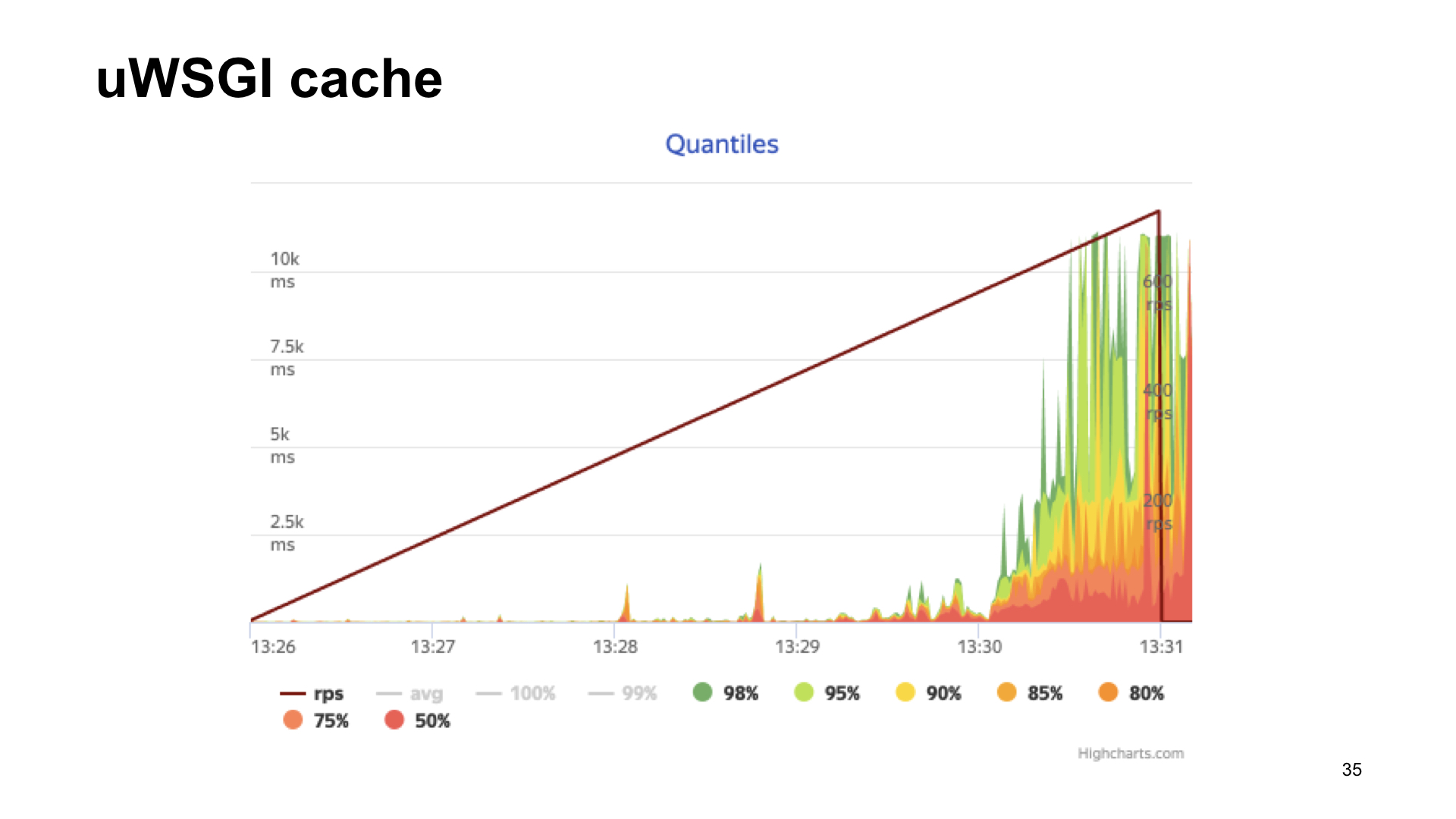
Aqui estão os resultados do bombardeio deste aplicativo.

O resultado sem métricas, se com uWSGI, com um alongamento, parece quase o mesmo.
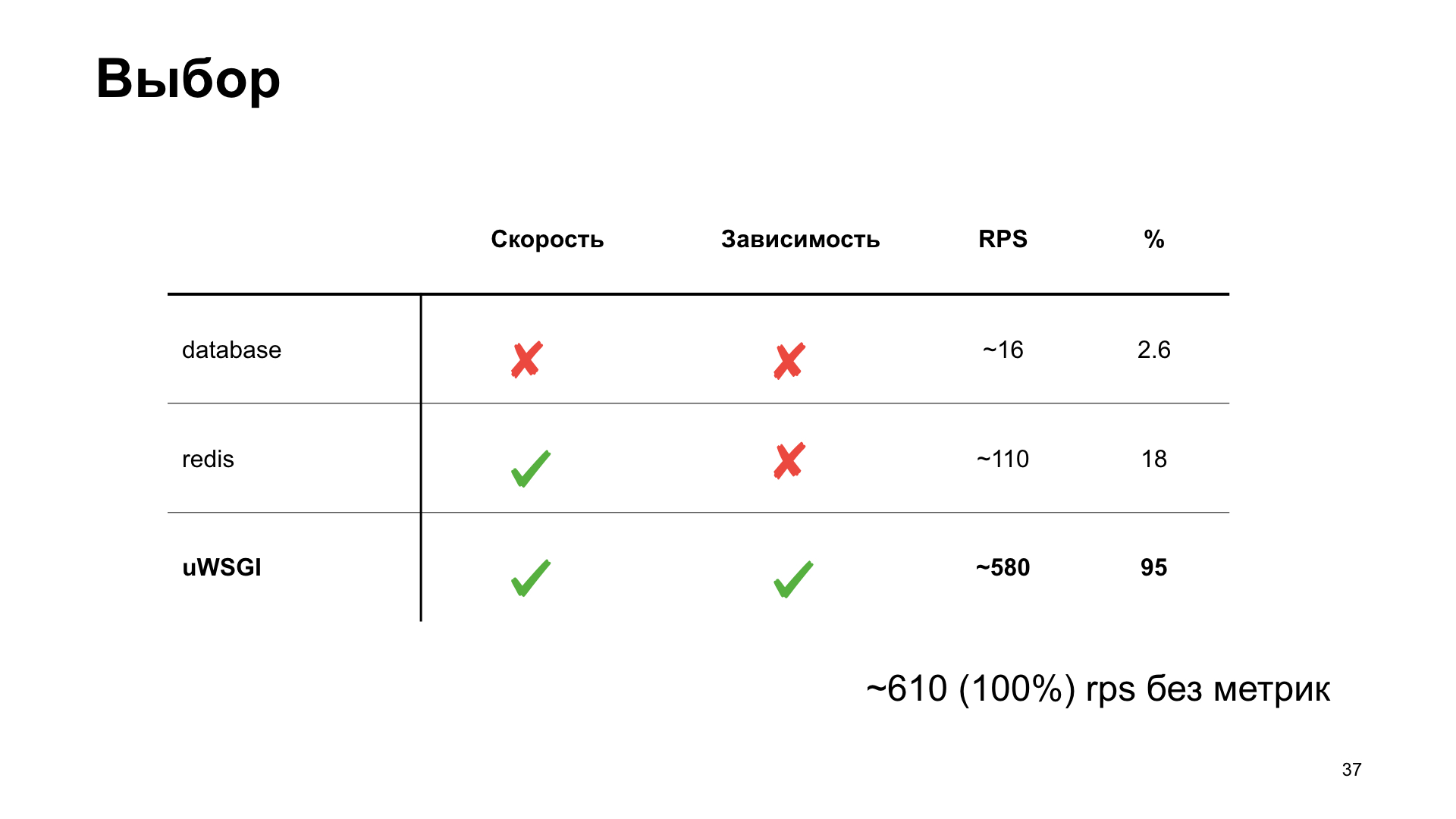
Como você pode ver, no caso do uWSGI, perdemos apenas 5% do desempenho em relação à versão "vanilla" sem métricas. Outras opções têm um rebaixamento bastante significativo e, portanto, como resultado da votação do espectador, o uWSGI vence.

Como aplicamos isso? Escrevemos uma pequena biblioteca, um invólucro em torno do uWSGI. Por exemplo, instalamos uma instância da nossa biblioteca e aqui adicionamos a métrica "Tempo de consulta no banco de dados" como exemplo.

Também estamos interessados em acompanhar como o cache funciona. Simplesmente redefinimos os métodos da memória do cliente, economizamos tempo para receber dados, tempo para fazer o download e o número de acertos e falhas do cache.

Como fazemos isso dentro da biblioteca? Para enviar os valores, obtemos os nomes das chaves armazenadas no cache, as executamos e simplesmente as fornecemos no formato desejado para o terminal.
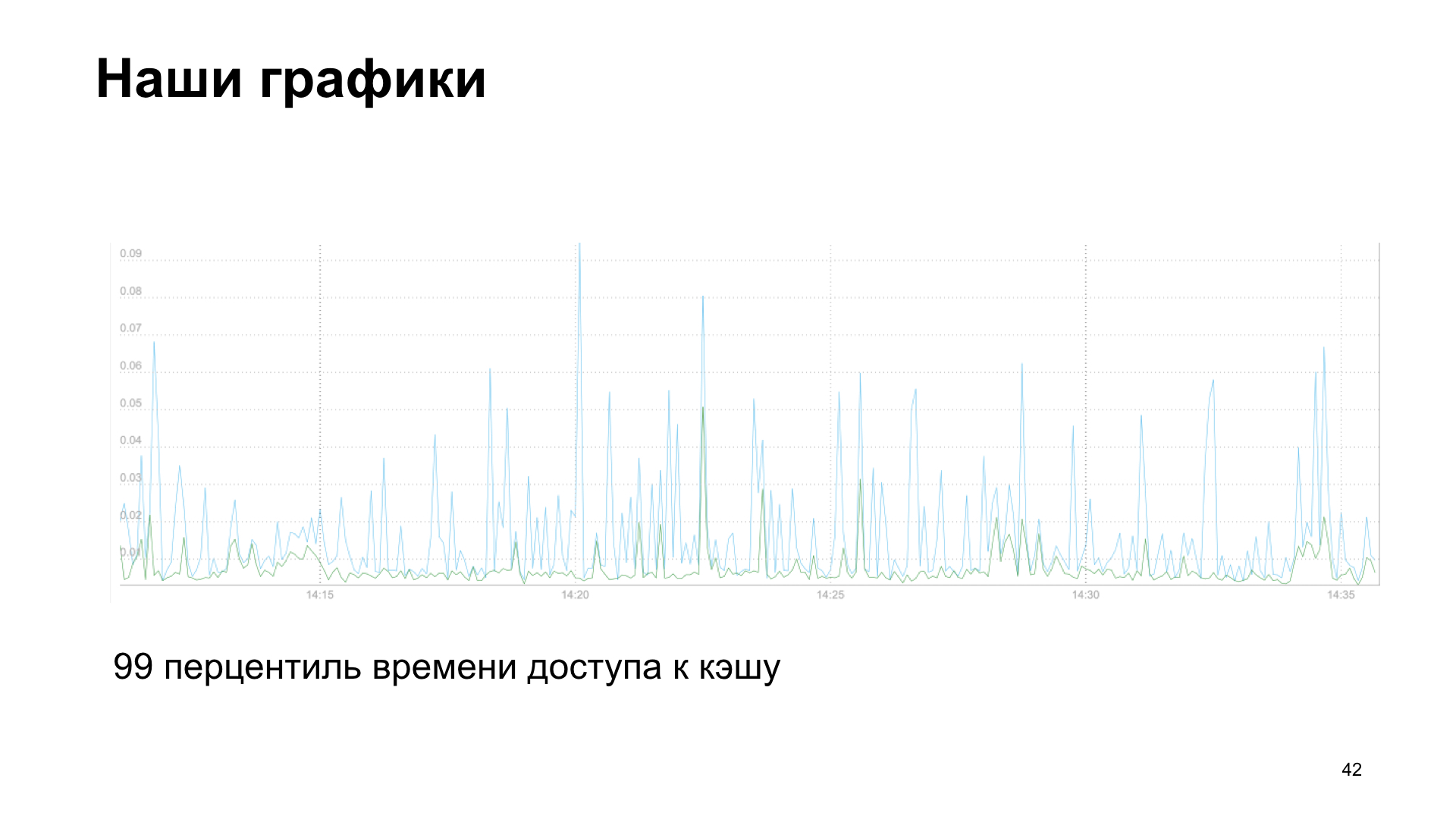
Como resultado, obtemos um gráfico, neste caso, é o percentil 99 do tempo de acesso ao cache, leitura e gravação.

Ou, como opção, o número de solicitações de serviços de terceiros à nossa API.

Temos histórias de fracasso e sucesso. Começamos a adicionar cada vez mais métricas e tivemos uma queda no desempenho. As próprias métricas nos ajudaram. Se você coletar métricas, poderá ver que algo está errado. Portanto, também recomendo que você analise retrospectivamente as métricas que acumulou ao longo da semana, mês e seis meses. E veja qual tendência seu aplicativo está mostrando em quais indicadores. Percebemos que começamos a descansar no cálculo das métricas.

A criação de perfil nos ajudou. Aqui você vê um flamegraph, que mostra visualmente quantas chamadas de várias funções foram realizadas durante o processo, chamadas que deram a maior contribuição no tempo. Percebemos que não nos saímos muito bem na primeira versão usando pickle. Dentro da nossa biblioteca, ela passou um tempo considerável em conserva.

Recusamos a decapagem, transferimos para a cashe inc, medimos tudo, ficou mais rápido.

Na nova implementação, passamos a maior parte do tempo trabalhando com o cache, não com a decapagem.

Por que estou lhe dizendo isso? Peço que você comece a coletar métricas, observando métricas e se concentrando nas métricas. Ao escolher uma opção de coleção de métricas possível, compare as opções e veja qual é a melhor para você. E, claro, o perfil é bom. Se você perceber que algo está errado, algo está diminuindo a velocidade - perfil.
Obrigado a todos! Como prometi, referências: