Pensamos em construir a infraestrutura de grandes testes de carga há um ano, quando atingimos a marca de 12 mil usuários online trabalhando em
nosso serviço ao mesmo tempo. Durante 3 meses, fizemos a primeira versão do teste, que mostrou os limites do serviço.
A ironia do destino é que, ao mesmo tempo em que o teste foi lançado, atingimos os limites do produto, pelo que o serviço caiu 2 horas. Além disso, isso nos incentivou a começar a realizar testes de caso a caso, criando uma infraestrutura eficaz de suporte de carga. Por infraestrutura, quero dizer todas as ferramentas para trabalhar com a carga: ferramentas para inicialização e inicialização, um cluster para carregar a carga, um cluster, um produto similar, serviços para coletar métricas e preparar relatórios, código para gerenciar tudo isso e serviços para dimensionamento.
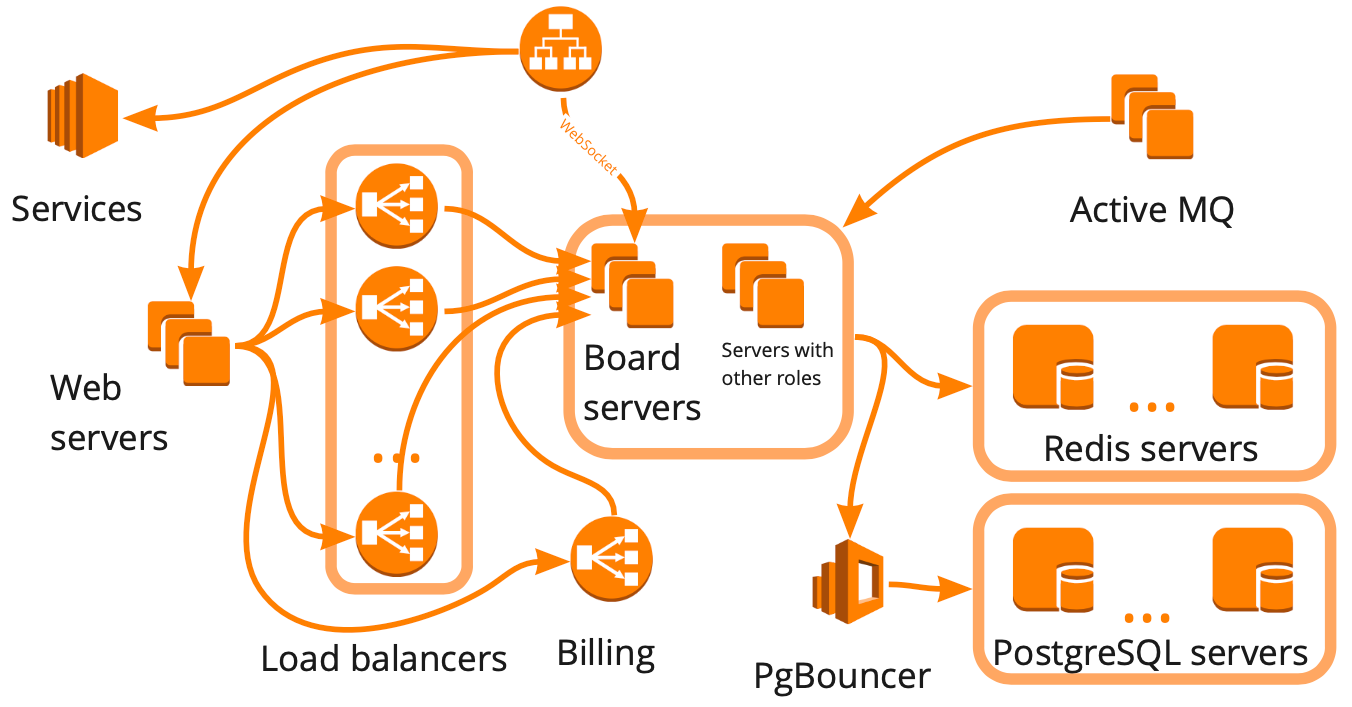
É assim que o esquema do miro.com é simplificado: existem muitos servidores diferentes que de alguma forma interagem entre si e cada um executa tarefas específicas. Parece que, para construir a infraestrutura de testes de carga, bastava desenhar esse esquema, levar em consideração todos os relacionamentos e começar a cobrir cada bloco sequencialmente com scripts. Essa abordagem é boa, mas levaria muitos meses, o que não era adequado para nós por causa do rápido crescimento - nos últimos seis meses, passamos de 12 mil para 20 mil usuários on-line trabalhando no serviço ao mesmo tempo. Além disso, não sabíamos como a infraestrutura de nosso serviço responderia a um aumento de carga: qual dos blocos se tornaria um gargalo e qual poderíamos dimensionar linearmente.
Como resultado, decidimos testar o serviço usando usuários virtuais, simulando seu trabalho realista, ou seja, construindo um clone de produção e fazendo um grande teste, que:
- carregar um cluster que seja idêntico à produção em estrutura, mas à frente em poder;
- nos dê todos os dados para tomar decisões;
- mostrará que toda a infraestrutura é capaz de suportar a carga correta;
- será a base para os testes de estresse que precisaremos no futuro.
O único ponto negativo desse teste é o seu preço de custo, porque para isso precisamos de um ambiente que seja maior que o ambiente de produção.
Neste artigo, falarei sobre a criação de um cenário realista, plug-ins - WS, Stress-client, Taurus, - cluster de carga, cluster de vendas e mostrará exemplos de uso de testes.
O próximo artigo é sobre como gerenciamos centenas de servidores para um teste de carga.
Crie um cenário realista
Para criar um cenário realista, precisamos:
- analise o trabalho dos usuários no produto e, para isso, determine as métricas importantes para nós, comece a coletá-las regularmente e analise os saltos;
- criar blocos personalizados convenientes com os quais possamos carregar com eficiência a parte necessária da lógica de negócios;
- Verifique o realismo do script com métricas do servidor.
Agora, mais sobre cada item.
Análise do trabalho do usuário no prodEm nosso serviço, os usuários podem criar painéis e trabalhar neles com diferentes conteúdos: fotos, textos, mocapas, adesivos, diagramas etc. A primeira métrica que precisamos coletar é o número de painéis e a distribuição de conteúdo neles.
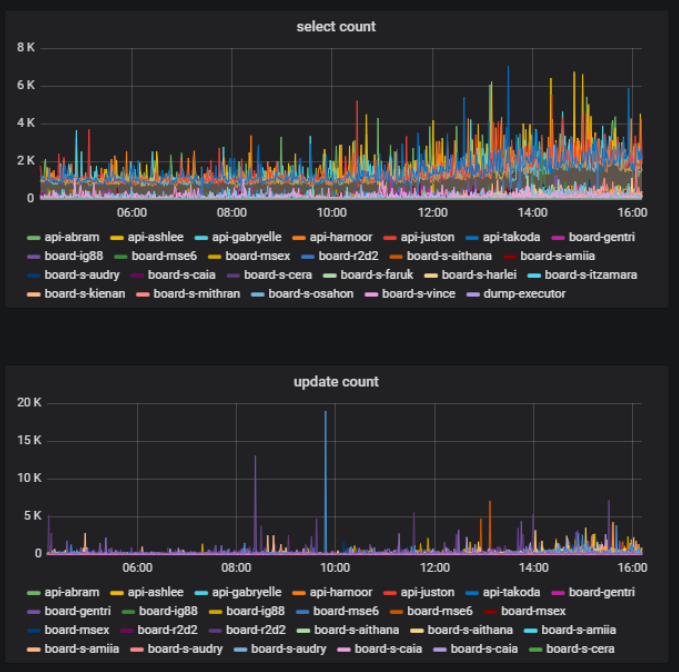
No mesmo quadro, no mesmo momento, alguns usuários podem fazer algo ativamente - criar, excluir, editar - e outros simplesmente visualizar o material criado. Essa também é uma métrica importante - a proporção entre o número de usuários que alteram o conteúdo do quadro e o número total de usuários de um quadro. Podemos obter isso com base em estatísticas sobre o trabalho com o banco de dados.
Em nosso back-end, usamos a abordagem de componentes. Componentes que chamamos de modelos. Dividimos nosso código em modelos para que, para cada parte da lógica de negócios, um determinado modelo seja responsável. Podemos calcular o número de chamadas ao banco de dados que ocorrem em cada modelo e entender qual parte da lógica carrega mais o banco de dados.
 Blocos personalizados convenientes
Blocos personalizados convenientesPor exemplo, precisamos adicionar um bloco ao script que carregue nosso serviço de forma idêntica à de como acontece quando você abre uma página do painel com uma lista de painéis do usuário. Durante o carregamento desta página, são enviadas solicitações de HTTP com um grande conjunto de dados: o número de placas, as contas às quais o usuário tem acesso, todos os usuários da conta e assim por diante.

Como carregar um painel de forma eficaz? Ao analisar o comportamento da produção, vimos picos de carga no banco de dados durante a abertura do painel de uma conta grande. Podemos recriar uma conta idêntica e alterar a intensidade do uso de seus dados no script, carregando efetivamente um painel com um pequeno número de ocorrências. Também podemos criar uma carga desigual para maior realismo.
Ao mesmo tempo, é importante para nós que o número de usuários virtuais e a carga criada por eles sejam o mais semelhante possível aos usuários e a carga na produção. Para fazer isso, também recriaremos no teste a carga em segundo plano no painel médio. Assim, a maioria dos usuários virtuais trabalha em pequenos painéis médios e apenas alguns usuários criam uma carga desastrosa, como acontece na produção.
Inicialmente, não queríamos cobrir cada função de servidor e cada relacionamento com um script separado. Isso pode ser visto no exemplo com o painel - simplesmente repetimos durante o teste o que acontece quando o painel é aberto no produto quando o usuário o abre e não cobrimos o que isso afeta nos scripts sintéticos. Isso permite que você, por padrão, inclua nuances de teste que nem antecipamos. Portanto, estamos nos aproximando da criação de um teste de infraestrutura do lado da lógica de negócios.
Usamos essa lógica para carregar efetivamente todos os outros blocos do serviço. Ao mesmo tempo, cada bloco individual, do ponto de vista da lógica do uso do funcional, pode não ser realista; é importante fornecer uma carga métrica realista nos servidores. E então podemos criar um script a partir desses blocos que imita o trabalho real dos usuários.

Os dados fazem parte do script.
Lembre-se de que os dados também fazem parte do script e a lógica do código em si depende muito dos dados. Ao criar um banco de dados grande para o teste - e obviamente deve ser grande para um grande teste de infraestrutura - precisamos aprender a criar dados que não serão exibidos durante a execução do script. Se você acumular dados indesejados, o script poderá não ser realista e será difícil corrigir um banco de dados grande. Portanto, começamos a usar a API Rest para criar dados da mesma maneira que nossos usuários.
Por exemplo, para criar placas com os dados disponíveis, executamos solicitações de API para carregar placas a partir do backup. Como resultado, obtemos dados reais honestos - placas diferentes de tamanhos diferentes. Ao mesmo tempo, o banco de dados está sendo preenchido rapidamente, devido ao fato de estarmos recebendo solicitações no script multithreaded. Em velocidade, isso é comparável à geração de dados do lixo.
Resultados para esta parte
- Use cenários realistas se quiser verificar tudo de uma vez;
- Analisar o comportamento real do usuário para projetar a estrutura do script;
- Crie imediatamente blocos convenientes para personalização;
- Configure por métricas reais do servidor, não por análises de uso;
- Lembre-se de que os dados fazem parte do script.
Carregar cluster
Esquema de ferramentas para aplicação de carga:
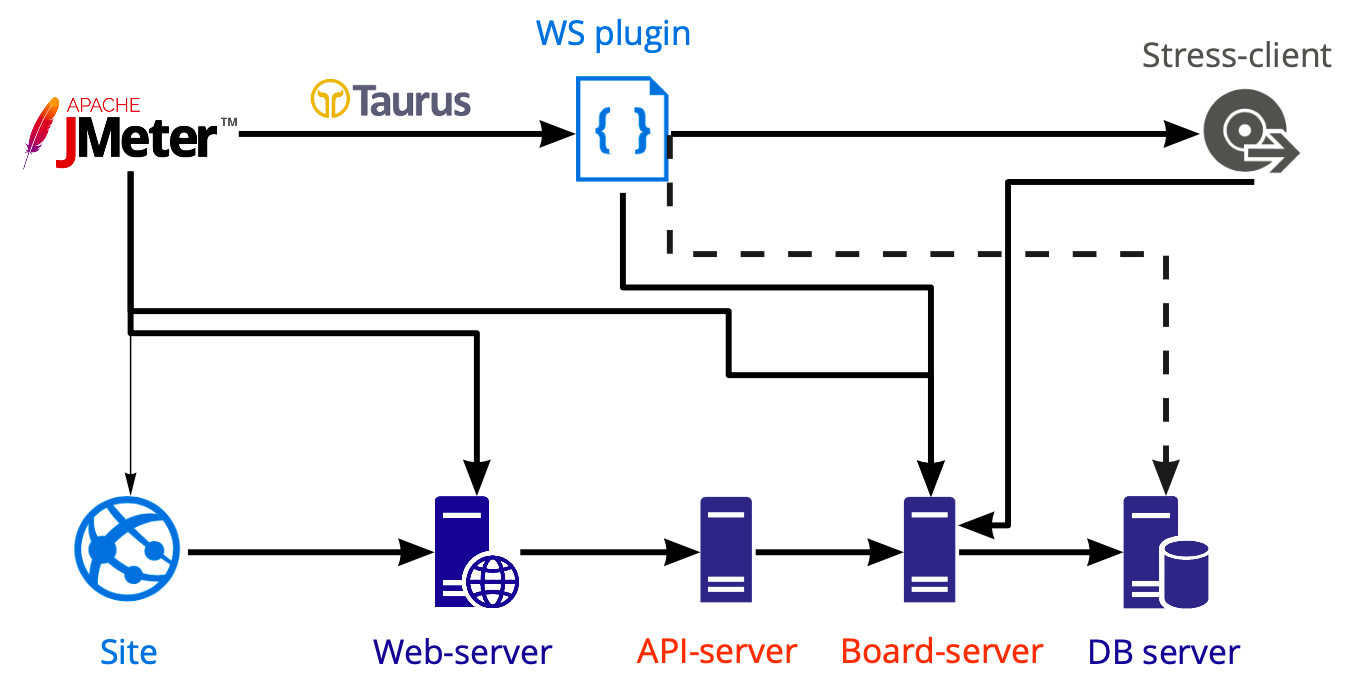
No Jmeter, criamos um script que lançamos usando o Taurus e carregamos vários servidores: servidores web, api, board. Realizamos testes de banco de dados separadamente usando o Postgresql, não o Jmeter, portanto, o diagrama mostra uma linha tracejada.
Trabalho personalizado dentro do soquete da web
O trabalho na placa ocorre dentro da conexão WS e é nela que é possível o trabalho multiusuário. Agora, na caixa Jmeter, dentro do gerenciador de plug-ins, existem vários plug-ins para trabalhar com o soquete da web. A lógica é a mesma em todos os lugares - os plug-ins simplesmente abrem uma conexão de soquete da Web, mas todas as ações que ocorrem dentro, em qualquer caso, você precisa se escrever. Porque Como não podemos trabalhar da mesma maneira que com solicitações de http, ou seja, não podemos escrever um script, extrair valores dinâmicos com extratores e ignorá-los ainda mais.
O trabalho dentro do soquete da web geralmente é muito personalizado: você invoca certos métodos com certos dados personalizados e, portanto, precisa entender se a solicitação foi executada corretamente e quanto tempo levou para ser executada. O Ouvinte dentro deste plugin também é escrito de forma independente; não encontramos uma boa solução pronta.
Stress-client
Queremos repetir o mais simples possível o que usuários reais fazem. Mas não sabemos como gravar e reproduzir o que está acontecendo no navegador dentro do WS. Se escrevermos tudo dentro do WS do zero, obteremos um novo cliente, e não aquele que os usuários reais usam. Não tenho vontade de escrever um novo cliente se já tivermos um trabalhando.
Portanto, decidimos colocar nosso cliente dentro da Jmeter. E confrontado com uma série de dificuldades. Por exemplo, executar js dentro do Jmeter é uma história separada, como Esta é uma
versão absolutamente
específica dos recursos suportados. E se você quiser usar seu código de cliente existente, provavelmente não terá êxito, porque construções novas e com ventosas não podem ser iniciadas aqui, elas terão que ser reescritas.
A segunda dificuldade é que não queremos oferecer suporte a todo o código do cliente para testes de carga. Portanto, removemos tudo supérfluo do cliente e deixamos apenas a interação cliente-servidor. Isso nos permitiu usar métodos cliente-servidor e fazer tudo o que nosso cliente pode fazer. A vantagem é que a interação cliente-servidor muda extremamente raramente, o que significa que o suporte ao código dentro do script raramente é necessário. Por exemplo, nos últimos seis meses, nunca fiz alterações no código, porque funciona muito bem.
A terceira dificuldade - a aparência de scripts grandes complica significativamente o script. Em primeiro lugar, pode se tornar um gargalo no teste. Em segundo lugar, provavelmente não conseguiremos iniciar um grande número de threads de uma máquina. Agora só podemos lançar 730 threads.
Nosso exemplo de instância da Amazon Jmeter server AWS: m5.large ($0.06 per Hour) vCPU: 2 Mem (GiB): 8 Dedicated EBS Bandwidth (Mbps): Up to 3,500 Network Performance (Gbps): Up to 10 → ~730
Onde obter centenas de servidores e como economizar
Em seguida, surge a pergunta: 730 threads de uma máquina, mas queremos 50K. Onde criar tantos servidores? Como estamos criando uma solução em nuvem, a compra de servidores para testar uma solução em nuvem parece estranha. Além disso, é sempre uma certa lentidão nos processos de compra de ferro novo. Portanto, precisamos criá-los também na nuvem, para finalmente escolhermos entre os provedores de nuvem e as ferramentas de carregamento em nuvem.
Não usamos ferramentas de carregamento em nuvem como Blazemeter e RedLine13, porque elas têm restrições de uso que não nos agradam. Como temos locais de teste diferentes, queríamos encontrar uma solução universal que permitisse que 90% dos desenvolvimentos fossem usados, inclusive em testes locais.
Como resultado, escolhemos entre os provedores de nuvem.
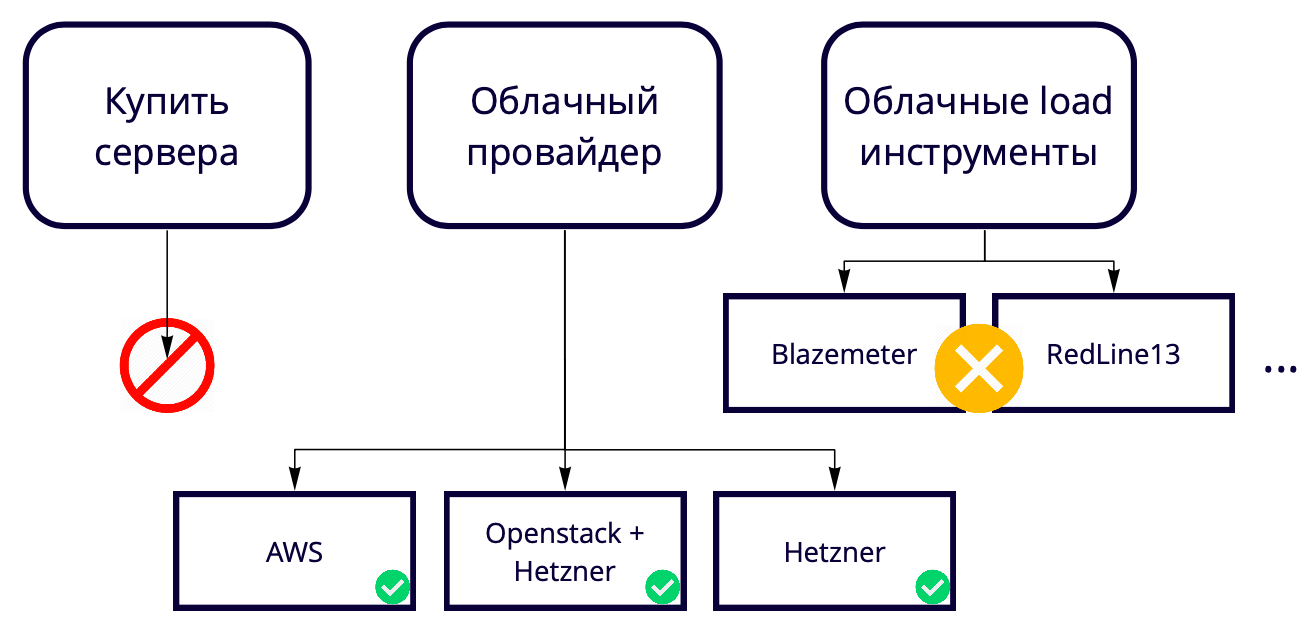
Nossa produção é na AWS, então estamos testando principalmente lá, e queremos que o banco de testes seja o mais semelhante possível à produção. A Amazon possui muitos recursos pagos, alguns dos quais usamos no produto, por exemplo, balanceadores. Se esses recursos não forem necessários na AWS, você poderá usá-los 17 vezes mais barato no Hetzner. Ou você pode manter o servidor no Hetzner, usar o Openstack e escrever balanceadores e outros recursos, já que, usando o Openstack, você pode repetir toda a infraestrutura. Nós conseguimos.
Testar 50 mil usuários com 69 instâncias na AWS nos custa aproximadamente US $ 3 mil por mês. Como salvar? Por exemplo, a AWS tem instâncias temporárias - instâncias spot. A frescura deles é que não os mantemos constantemente, apenas os aumentamos durante os testes e eles custam muito menos. A nuance é que alguém pode comprá-los a um preço mais alto no momento do teste. Felizmente, isso nunca aconteceu antes, mas já economizamos pelo menos 60% do custo às suas custas.
Carregar cluster
Usamos o cluster da caixa Jmeter. Funciona muito bem, não precisa ser modificado de forma alguma. Possui várias opções de inicialização. Usamos o mais simples quando um assistente inicia N instâncias, e pode haver centenas delas.
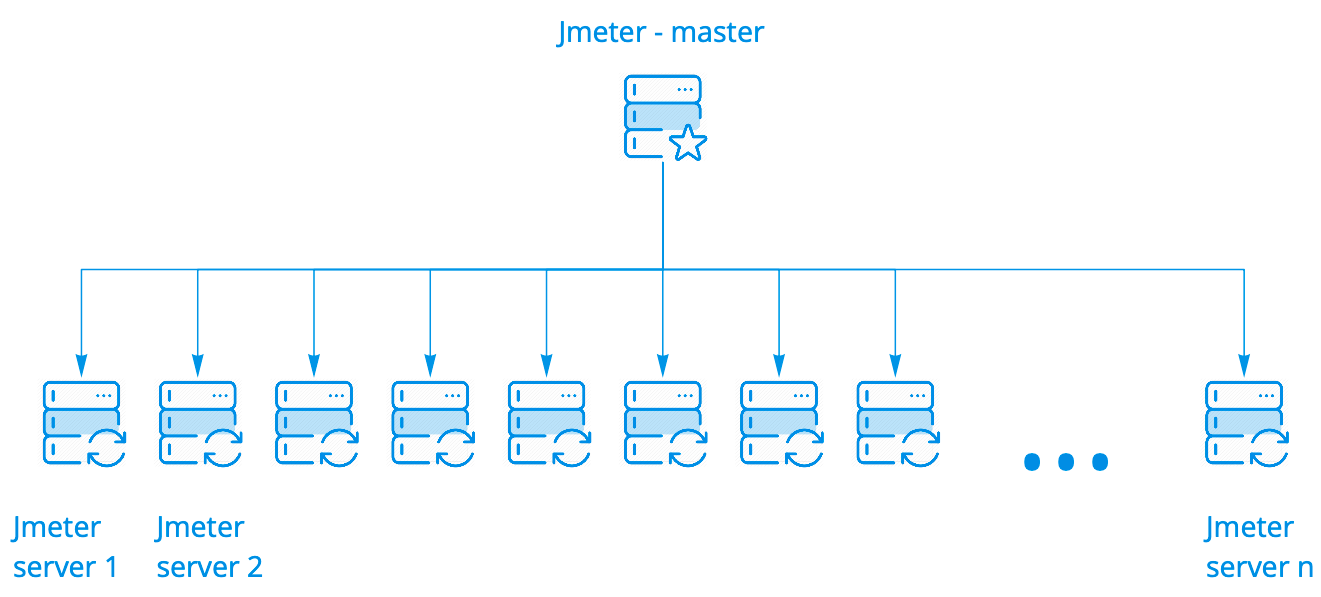
O assistente executa o script nos servidores Jmeter, mantendo contato com eles, coleta estatísticas gerais de todas as instâncias em tempo real e o exibe no console. Tudo isso parece exatamente o mesmo que executar o script em um servidor, embora vejamos os resultados do lançamento em uma centena de servidores.
Para uma análise detalhada dos resultados da execução do script em todas as instâncias, usamos o Kibana. Parsim registra usando Filebeat.

Um ouvinte do Prometheus para Apache JMeter
O Jmeter possui um
plug -
in para trabalhar com o Prometheus , que fornece todas as estatísticas sobre o uso da JVM e threads dentro do teste. Isso permite que você veja com que frequência os usuários se conectam, saem e assim por diante. O plug-in pode ser personalizado para enviar dados do script para o Prometheus e vê-los em tempo real no Grafana.
Touro
Queremos resolver uma série de problemas atuais com o Taurus, mas ainda não o lidamos:
- Configura em vez de clones de script. Se você testou no Jmeter, provavelmente enfrentou a necessidade de executar scripts com diferentes conjuntos de parâmetros de origem, para os quais foi necessário criar seus clones. No Taurus, é possível ter um cenário, e com a ajuda de configurações para controlar os parâmetros de inicialização;
- Configura para gerenciar servidores Jmeter ao trabalhar com um cluster;
- Um analisador de resultados online que permite coletar resultados separadamente dos encadeamentos Jmeter e não sobrecarregar o próprio script;
- Integração conveniente com o CI;
- A capacidade de testar um sistema distribuído.
Os resultados desta parte
- Se usarmos o código dentro do Jmeter, é melhor pensar imediatamente em seu desempenho, porque, caso contrário, podemos testar o Jmeter, não o nosso produto;
- O cluster Jmeter é uma coisa maravilhosa: é fácil de configurar, o monitoramento é facilmente parafusado a ele;
- Um cluster grande pode ser mantido em instâncias spot, será muito mais barato;
- Cuidado com os ouvintes dentro do Jmeter, para que o script não diminua a velocidade do trabalho em um grande número de servidores.
Exemplos de uso de testes de infraestrutura
A história toda acima é basicamente sobre como criar um cenário realista para um teste de limite de serviço. Os exemplos abaixo mostram como você pode reutilizar a infraestrutura de testes de carga para resolver problemas locais. Falarei detalhadamente sobre dois testes, mas em geral realizamos periodicamente cerca de 10 tipos de testes de carga.
Teste de banco de dados
O que podemos carregar teste no banco de dados? Consultas pesadas são improváveis, porque podemos testá-las no modo de thread único, se apenas olharmos para os planos de consulta.
Uma situação interessante é quando executamos o teste e vemos a carga no disco. O gráfico mostra como o iowait aumenta.
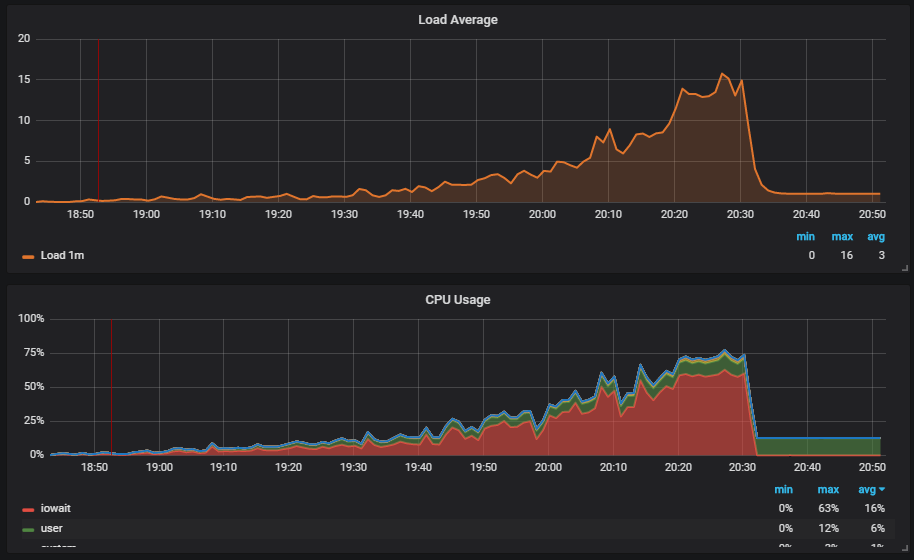
Além disso, vemos que isso afeta os usuários.
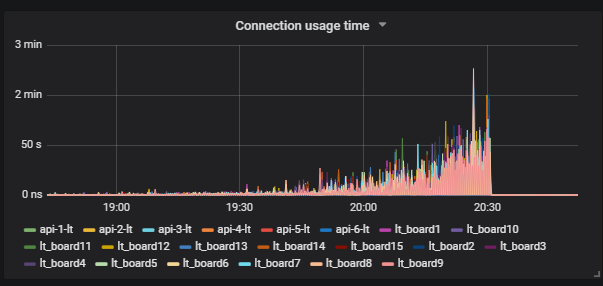
Entendemos o motivo: o vácuo não funcionou e não excluiu os dados do lixo do banco de dados. Se você não trabalhou com o Postgresql, o Vacuum é como o coletor de lixo em Java.

Além disso, vemos que o
Checkpoint começou a funcionar fora do cronograma. Para nós, este é um sinal de que as configurações do Postgresql não correspondem à intensidade do trabalho com o banco de dados.
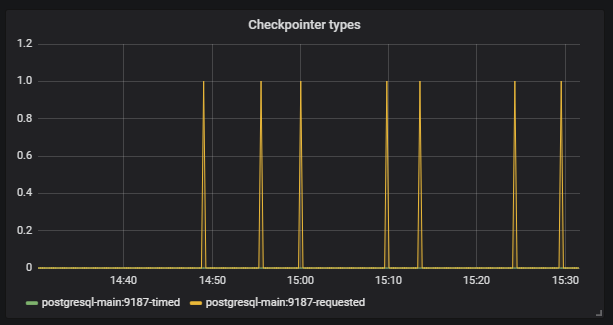
Nossa tarefa é configurar corretamente o banco de dados para que essas situações não se repitam. O mesmo Postgresql tem muitas configurações. Para um ajuste fino, você precisa trabalhar em iterações curtas: corrigida a configuração, iniciada, verificada, corrigida, iniciada, verificada. Obviamente, para isso, você precisa aplicar uma boa carga à base, mas para isso, você só precisa de grandes testes de infraestrutura.
A peculiaridade é que, para que o teste acelere normalmente e não caia onde não é necessário, o overclock deve ser demorado. Demora cerca de três horas para testar, e isso não se parece mais com iterações curtas.
Estamos à procura de uma solução. Encontramos uma das ferramentas do Postgresql -
Pg_replay . Ele pode reproduzir de várias maneiras exatamente o que está escrito nos registros e exatamente como aconteceu no momento da gravação. Como podemos usá-lo efetivamente? Recolhemos o dump base, registramos tudo o que acontece no banco de dados após salvar nos logs e, em seguida, temos a oportunidade de implantar o dump e reproduzir tudo o que aconteceu com a base multithread.
Onde gravar logs? Uma solução popular para registrar logs é coletá-los no produto, pois isso fornece o script reprodutível mais realista. Mas há vários problemas:
- Para o teste, você precisa usar os dados de vendas, o que nem sempre é possível;
- O processo usa uma operação cara de syslog;
- O disco está carregando.
Nossa abordagem para grandes testes nos ajuda aqui. Realizamos um despejo em um ambiente de teste, executamos um grande teste e registramos os logs de tudo o que acontece no momento em que o script realista é executado. Em seguida, usamos nossa própria ferramenta
marucy para testar o banco de dados:
- Uma instância é criada na AWS;
- O despejo de que precisamos é implantado;
- Pg_replay é iniciado e reproduz os logs necessários;
- Utilizamos nosso monitoramento para analisar o resultado da Prometheus + Grafana. Existem exemplos de painéis no repositório.
Ao iniciar o marucy, podemos passar um pequeno número de parâmetros que podem ser alterados, por exemplo, a intensidade do script.
Como resultado, usamos nosso script realista para criar um teste e, em seguida, executamos o teste sem usar um cluster grande. É importante considerar que, para testar qualquer banco de dados sql, o script deve ser desigual, caso contrário, o próprio banco de dados se comportará de maneira diferente do prod.
Monitoramento de degradação
Para testes de degradação, usamos nosso cenário realista. A idéia é que precisamos garantir que o serviço não funcione mais lentamente após o próximo lançamento. Se nossos desenvolvedores alterarem o código, o que leva a um aumento no tempo de execução das solicitações, podemos comparar os novos valores com os de referência e sinalizar se há um erro na compilação. Para valores de referência, tomamos os valores atuais que nos convêm.
Controlar o tempo de execução da consulta é útil, mas fomos além. Queríamos ver que o tempo de resposta durante o trabalho de usuários reais após o lançamento não se prolongou. Pensamos que, no momento dos testes de estresse, provavelmente poderíamos entrar e verificar alguma coisa, mas esses serão apenas dezenas de casos. É mais eficiente executar testes funcionais existentes e ver mil casos ao mesmo tempo.

Como isso funciona para nós? Há um mestre que, após a montagem, é implantado em uma bancada de testes. Em seguida, os testes funcionais são executados automaticamente em paralelo com os testes de carga. Em seguida, obtemos um relatório no Allure sobre como os testes funcionais foram sobrecarregados.
Neste relatório, por exemplo, vemos que um teste de comparação caiu com um valor de referência.
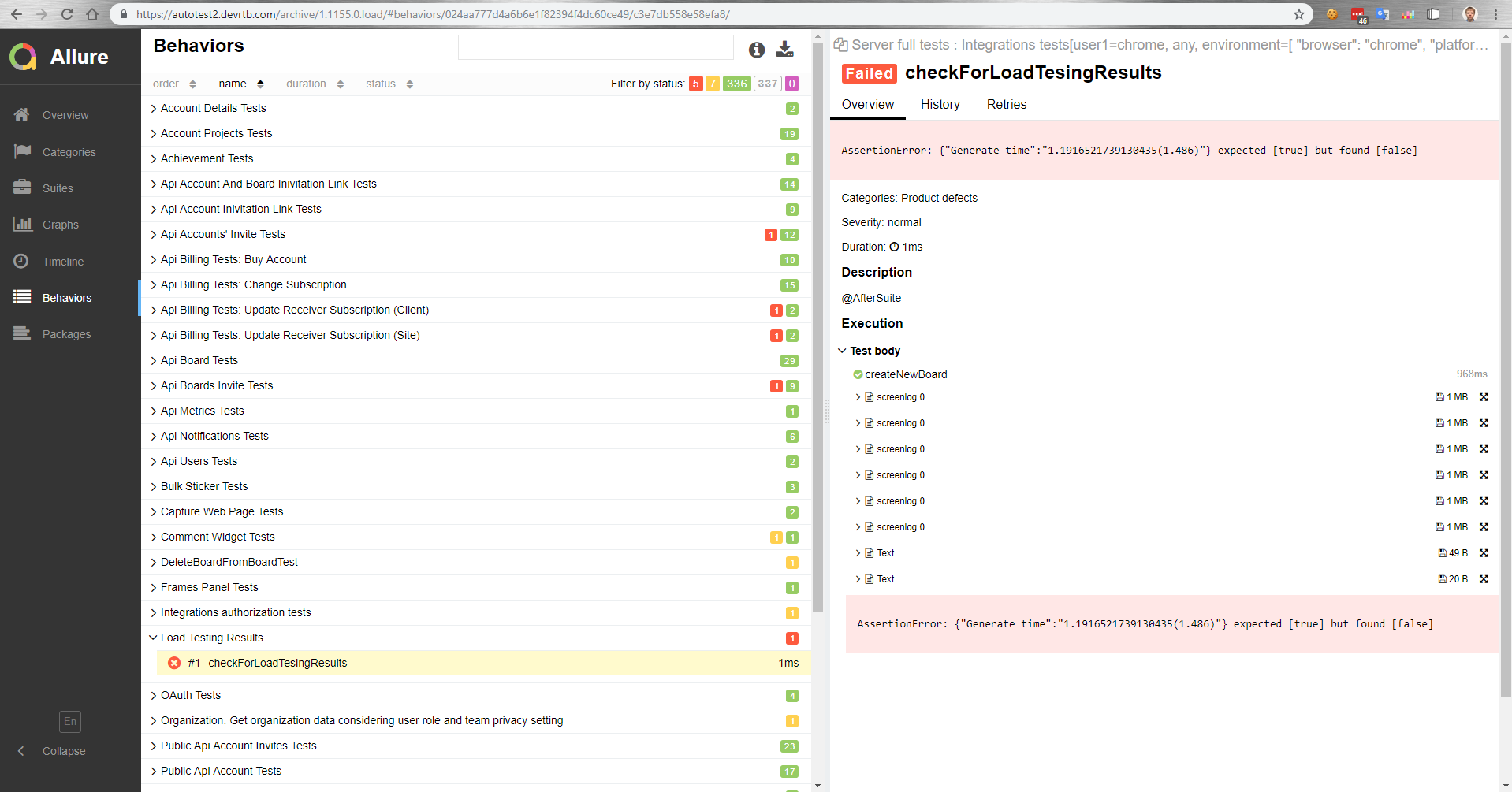
Também em testes funcionais, podemos medir o tempo de execução de uma operação em um navegador. Ou, um teste funcional simplesmente não é bem-sucedido devido a um aumento no tempo de execução da operação sob carga, porque o tempo limite no cliente funcionará.
Resultados para esta parte
- Um teste realista permite que você teste barato o banco de dados e configure-o facilmente;
- Teste funcional sob carga é possível.
O
próximo artigo é sobre como gerenciamos centenas de servidores para um teste de carga.