A análise de texto sempre começa com análise lexical ou tokenização. Existe uma maneira fácil de resolver esse problema para quase qualquer idioma usando expressões regulares. Outro uso do bom e velho regexp.
Costumo encontrar a tarefa de analisar textos. Para tarefas simples, como analisar um valor inserido pelo usuário, a funcionalidade básica da expressão regular é suficiente. Para tarefas complexas e pesadas, como escrever um compilador ou análise de código estático, você pode usar ferramentas especializadas (AntLR, JavaCC, Yacc). Mas muitas vezes encontro tarefas de nível intermediário, quando não há expressões regulares suficientes, mas não sinto vontade de colocar ferramentas pesadas no projeto. Além disso, essas ferramentas geralmente funcionam no estágio de compilação e no tempo de execução não permitem alterar os parâmetros de análise (por exemplo, formar uma lista de palavras-chave a partir de uma tabela de arquivo ou banco de dados).
Como exemplo, darei uma tarefa que surgiu durante o processo de aceleração de consultas SQL . Analisamos os logs de nossas consultas SQL e queríamos encontrar consultas "ruins" de acordo com certas regras. Por exemplo, consultas nas quais o mesmo campo é verificado para um conjunto de valores usando OR
name = 'John' OR name = 'Michael' OR name = 'Bob'
Queríamos substituir esses pedidos por
name IN ('John', 'Michael', 'Bob')
Expressões regulares não podem mais lidar, mas eu também não queria criar um analisador SQL completo usando o AntLR. Seria possível dividir o texto da solicitação em tokens e usar código simples para fazer a análise sem nenhuma ferramenta especializada.
Esse problema pode ser resolvido usando a funcionalidade básica de expressões regulares. Vamos tentar dividir a consulta SQL em tokens. Veremos uma versão simplificada do SQL para não sobrecarregar o texto com detalhes. Para criar um lexer SQL completo, você precisará escrever expressões regulares um pouco mais complexas.
Aqui está um conjunto de expressões para tokens básicos da linguagem SQL:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
Quero prestar atenção à expressão regular da palavra-chave
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
Possui dois recursos.
- O operador \ b é usado no início e no final, por exemplo, para não cortar o prefixo ou da organização de palavras, que é uma palavra-chave e que alguns mecanismos de regex separarão em um token separado sem usar o operador \ b.
- todas as palavras são agrupadas por colchetes que não capturam (? :) que não capturam a correspondência. Isso será usado no futuro para não violar a indexação de expressões regulares parciais na expressão geral.
Agora você pode combinar todas essas expressões em um único todo, usando o agrupamento e o operador |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
Agora você pode tentar aplicar essa expressão a uma expressão SQL, por exemplo, para
SELECT count(id)
Aqui está o resultado no Regex Tester. Ao clicar no link, você pode brincar com a expressão e o resultado da análise. Pode-se observar que, por exemplo, SELECT corresponde imediatamente a um grupo 1, que corresponde ao tipo de palavra - chave .
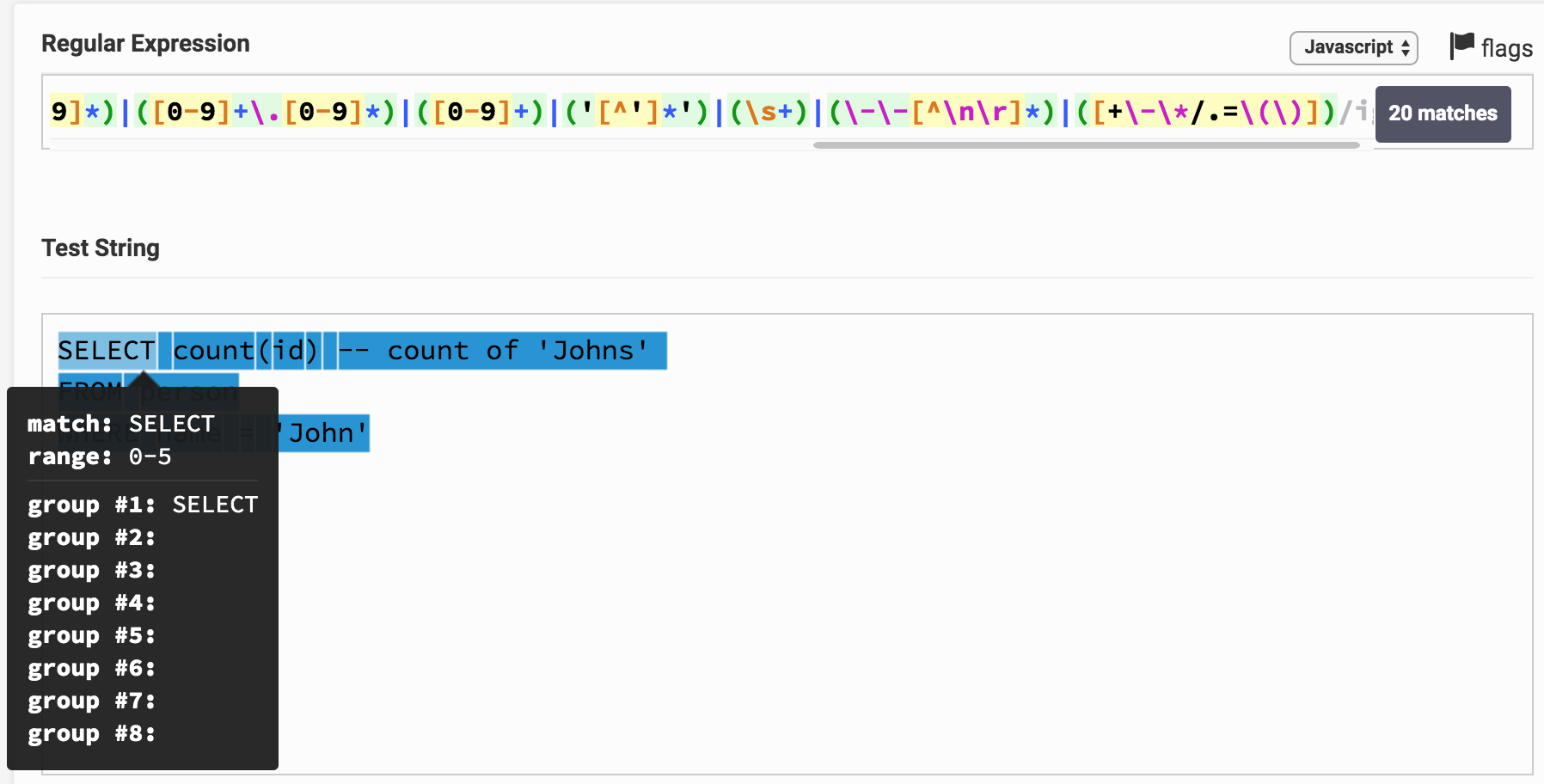
Você pode perceber que o texto inteiro da solicitação acabou sendo dividido em substrings e cada um corresponde a um determinado grupo. Pelo número do grupo, você pode correlacioná-lo com o tipo de token (token).
Transformar o algoritmo em um programa em qualquer linguagem de programação que suporte expressões regulares não é difícil. Aqui está uma pequena classe que implementa isso em Java.
RegexTokenizer.java (+ mais algumas aulas) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
Nesta classe, o algoritmo é implementado usando grupos nomeados, que não estão presentes em todos os mecanismos. Esse recurso permite acessar grupos não por índice, mas por nome, o que é um pouco mais conveniente do que acessar por índice.
No meu I7 de 2,3 GHz, essa classe demonstra uma velocidade de análise de 5 a 20 MB por segundo (dependendo da complexidade das expressões). O algoritmo pode ser paralelo analisando vários arquivos de uma só vez, aumentando a velocidade geral do trabalho.
Encontrei vários algoritmos semelhantes na rede, mas encontrei opções que não formam uma expressão regular comum, mas aplicam expressões regulares de forma consistente para cada tipo de token no início da linha, depois descarte o token encontrado no início da linha e tente aplicar todos os regexps. Isso funciona de 10 a 20 vezes mais lento, requer mais memória e o algoritmo é mais complicado. Consegui uma velocidade maior de trabalho apenas usando minha implementação de expressão regular baseada no DFA (máquina determinística de estados finitos). Nos motores regex, o NKA é geralmente usado - uma máquina de estados finitos não determinísticos ). O DFA é 2-3 vezes mais rápido, mas as expressões regulares são mais difíceis de escrever devido a um conjunto limitado de operadores.
No meu exemplo para SQL, simplifiquei um pouco as expressões regulares e o tokenizer resultante não pode ser considerado um analisador lexical completo de consultas SQL, mas o objetivo do artigo é mostrar o princípio e não criar um tokenizer SQL real. Eu usei essa abordagem em minha prática e criei analisadores lexicais completos para SQL, Java, C, XML, HTML, JSON, Pascal e até COBOL (tive que mexer com ela).
Aqui estão algumas regras simples para escrever expressões regulares para análise lexical.
- Se o mesmo token puder ser atribuído a tipos diferentes (por exemplo, qualquer palavra-chave pode ser reconhecida como um identificador), um tipo mais restrito deverá ser definido no início. Em seguida, a expressão regular será aplicada primeiro e determinará o tipo de token. Por exemplo, no meu exemplo, as palavras - chave são definidas antes do id e o token de seleção será reconhecido como palavra-chave , não id
- Defina primeiro os tokens mais longos, depois os mais curtos. Por exemplo, primeiro você precisa definir <= , > = e depois separar > , < , = Nesse caso, o texto <= será corretamente reconhecido como um único token do operador menor ou igual e não dois tokens separados < e =
- Aprenda a usar lookahead e lookbehind . Por exemplo, o caractere * no SQL tem o significado de um operador de multiplicação e uma indicação de todos os campos em uma tabela. Usando uma simples observação, você pode separar esses dois casos, por exemplo, aqui regexp (? <=. \ S | select \ s ) * localiza o caractere * apenas no valor "todos os campos da tabela".
- Às vezes, é útil definir expressões regulares para erros que ocorrem no texto. Por exemplo, se você realçar a sintaxe, pode definir o tipo do token de sequência inacabada como
'[^\n\r]* . No processo de edição do texto, o usuário pode não ter tempo para fechar as aspas na sequência, mas o seu tokenizador poderá reconhecer corretamente essa situação e destacá-la corretamente.
Usando essas regras e aplicando esse algoritmo, você pode dividir rapidamente o texto em tokens para praticamente qualquer idioma.