Todos nós amamos e usamos os incríveis recursos do Grupo de Disponibilidade em réplicas secundárias, como verificações de integridade, backups etc.
De fato, a incapacidade de salvar essas informações em um banco de dados em uma réplica ainda é uma dor de cabeça (e pense em coisas como o CDC para ainda mais desconforto).
Mas pare de reclamar, aqui está a idéia principal: querida Microsoft, vamos usar nossas réplicas para atualizar estatísticas ... bem, e fazer muito mais com elas.
Sempre existe uma maneira ou algo assim
* quase sempreVamos listar os detalhes básicos conhecidos de uma possível solução no Enterprise Edition MS SQL Server:
- podemos tornar as réplicas legíveis e ler os dados delas (não que você sempre tenha que fazer isso, mas se realmente sabe o que está fazendo ...);
- podemos copiar nossos objetos para o Tempdb (sim, suas tabelas com vários terabytes provavelmente não são muito adequadas para essa operação) ou para outro banco de dados gravável;
- podemos gravar os resultados em uma pasta compartilhada acessível às duas réplicas (seja um arquivo de texto em um compartilhamento de arquivo);
- podemos exportar estatísticas como um blob do SQL Server;
- podemos importar o blob baixado para as estatísticas.
Vamos fazer
Eu tenho um teste AG em um par de máquinas virtuais com o SQL Server 2017 (você pode usar qualquer versão) e criarei uma tabela simples na qual desejo atualizar as estatísticas.
Aqui está um script para criar uma tabela e inserir um milhão de linhas nela:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Agora vamos criar as estatísticas ST_SampleDataTable_C2 para a coluna c2
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
E então vou inserir 1000 linhas, o que será muito importante e por isso realmente preciso atualizar as estatísticas.
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Agora eu tenho 1000 entradas nas quais, na coluna C2, o valor é 999999999. E isso definitivamente significa o Problema da Chave Crescente e eu realmente preciso atualizar as estatísticas ... na réplica para não sobrecarregar o servidor principal com cálculos e impediu-o de servir os clientes.
Usando o bom e velho comando DBCC SHOW_STATISTICS, vamos examinar nossas estatísticas.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
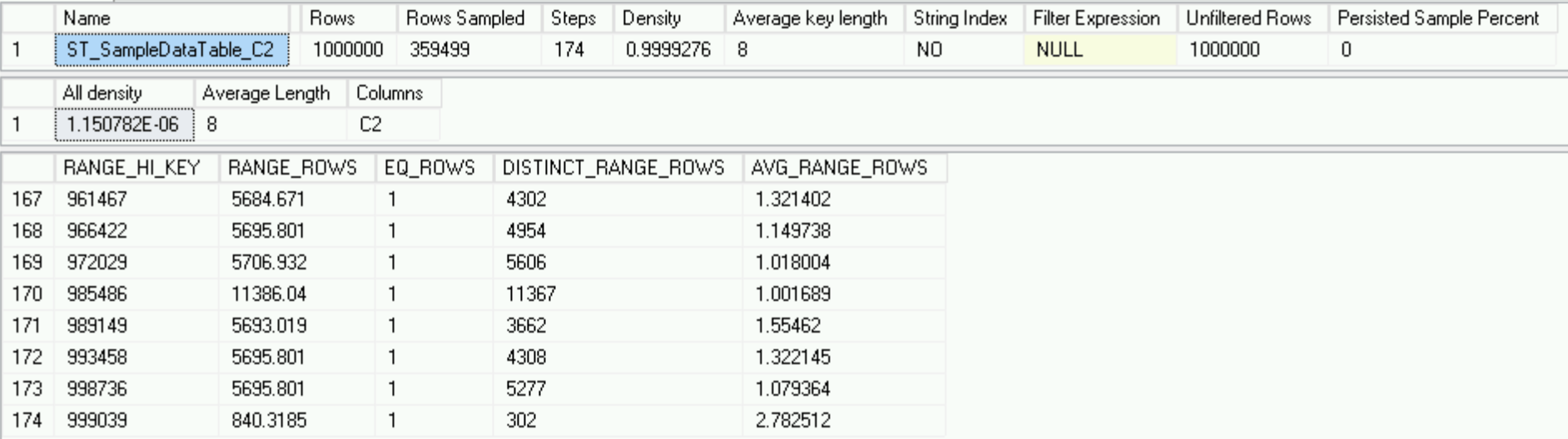
Tudo é perfeito em nosso reino e nossas estatísticas estão em perfeita ordem, embora isso leve em conta apenas 1 milhão de linhas e não haja mil linhas prejudiciais, que, em última instância, devem se tornar parte dessas estatísticas.
Além disso, podemos observar o fluxo de estatísticas usando o parâmetro STATS_STREAM do comando DBCC SHOW_STATISTICS:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

É apenas um conjunto de caracteres que os blogs escrevem há anos, mas ainda não tenho certeza se esse é um recurso totalmente documentado (embora nunca tenha impedido as pessoas de usá-lo).
Na sugestão
Vamos copiar nossa tabela em uma réplica para tempdb (embora meu AG esteja no modo síncrono, a mesma coisa pode ser feita de forma assíncrona, apenas os dados podem vir com um pequeno atraso).
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
Agora estamos prontos para atualizar as estatísticas com uma varredura completa em tempdb na réplica.
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
(
Nota do tradutor - Nico esqueceu de criar estatísticas e usa a sintaxe incorreta da operação UPDATE STATISTICS, em vez de UPDATE, ela deve ser CREATE, ou seja, as estatísticas não são atualizadas, mas são criadas )
Volte para DBCC SHOW_STATISTICS e veja:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
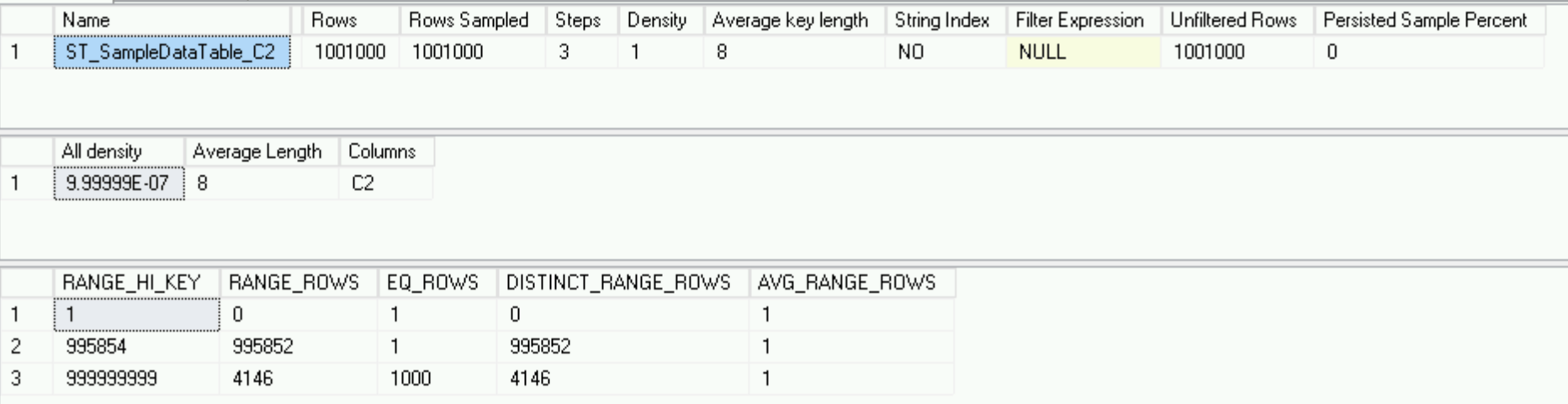
Parece completamente diferente do que era no servidor principal - apenas 3 linhas versus 178, mas descreve os dados perfeitamente - temos um milhão de linhas exclusivas e 1000 linhas com o mesmo valor da coluna C2 - o histograma é o melhor possível .
Vejamos o fluxo de estatísticas:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

Você não precisa ser um gênio para perceber que o fluxo parece completamente diferente - vemos os caracteres 5689A0C6 no fluxo atualizado, enquanto no original, entre todos esses zeros que vimos EDF10EB4.
Vamos nos concentrar na exportação desses dados para um arquivo de texto em algum lugar fora do SQL Server e fazê-lo com a ajuda do maravilhoso comando BCP, que exige que o CMDSHELL esteja ativado (nota: você provavelmente não deseja isso no servidor de produção):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
E aqui está o tamanho do arquivo stats.txt em nossa esfera:

Apenas alguns kilobytes! Fácil de transmitir, fácil de gerenciar.
Voltar ao servidor principal
No servidor principal, precisaremos criar uma tabela temporária que armazene o fluxo de estatísticas antes que possamos atualizá-las em nossa tabela SampleDataTable principal (na prática, podemos expandir essa tabela para muitos bancos de dados, tabelas, estatísticas).
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Vamos importar os dados do nosso arquivo de texto para a nossa nova tabela temporária e ver o que importamos:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;

Podemos ver os mesmos dados que calculamos na réplica, mas esses dados já estão em nosso servidor principal e tudo o que resta fazer é atualizar nossas estatísticas a partir delas na tabela. Esta operação pode ser executada usando a operação UPDATE STATISTICS usando o parâmetro WITH STATS_STREAM = ...
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
Este script lê o valor importado acima (sim, eu sei - fiz este exemplo para uma tabela e não me incomodei com várias estatísticas, tabelas, bancos de dados etc.), gera uma instrução UPDATE STATISTICS, exibe-a na tela e, no final, cumpre.
Aqui está o que eu recebo na saída:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
A execução do DBCC SHOW_STATISTICS no servidor principal fornece o mesmo resultado que eu esperava - o mesmo que vimos na réplica. O círculo está fechado.
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
A parte realmente impressionante dessa história é que o tamanho do objeto com estatísticas é muito pequeno e podemos transferi-lo para o servidor principal com muita facilidade / instantaneamente.
Cenário não tão básico.
Se você tiver vários AGs entre as mesmas réplicas, em que uma réplica é a principal em um AG e a outra é a principal no segundo, poderá inserir dados BLOB no fluxo de dados entre as réplicas e adicionar um pequeno banco de dados com os dados transmitidos.
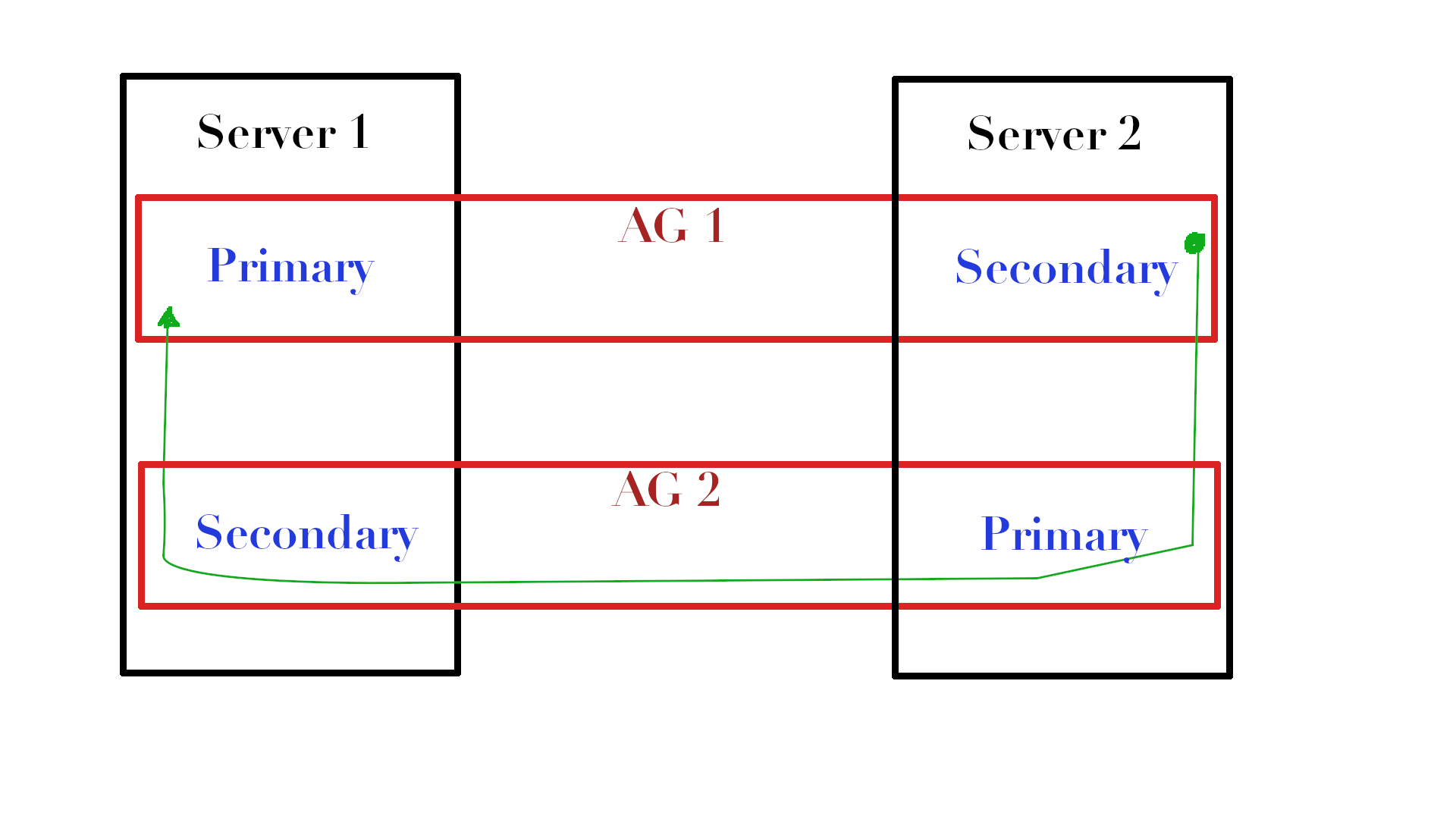
Olhe para a foto. Se tivermos dois AGs (AG1 e AG2) localizados em servidores diferentes e tivermos uma tabela específica no Server1 no AG1 para a qual queremos atualizar estatísticas, no Server2 poderemos copiar esta tabela (vamos chamá-la de dbo.MyTable ) no tempdb, atualize e, usando o AG2, envie o objeto com o fluxo de estatísticas de volta ao Server1, onde simplesmente importe estatísticas desse fluxo para as estatísticas de que precisamos.
Sim, eu sei, parece confuso, mas pense nisso como um canal de feedback através do qual os resultados são entregues, em vez de colocá-los em arquivos.
Lugar para dúvida
Você pode ter algumas objeções, por exemplo:
- por que devo fazer isso em uma réplica se posso fazê-lo com segurança no servidor principal? (bem, a ideia é descarregar o servidor principal)
- mas potencialmente não carregamos a réplica (sim, mas se ela estiver ociosa, é por isso que queremos usar sua energia)
- e não podemos agir de alguma forma no servidor principal? (não, apenas lemos os dados da réplica e enviamos alguns kilobytes, que em nosso século gigabytes e terabytes parecem "shtoa?") ( Note tradutor - em geral, apenas no caso da réplica legível AG, podemos )
- E se, no meio do processo, o servidor principal começar a atualizar as estatísticas por conta própria? (nesse caso, ele pode interromper o segundo processo ou reiniciar com os dados atualizados).
Canal de Feedback da AG
Este é um canal com feedback da réplica para o servidor principal - depois que prometemos a transação no AG síncrono, o servidor principal aguardará a confirmação da réplica - e acho que esse canal pode ser usado para implementar essa melhoria. Veja a foto tirada em um post de
Simon Su .
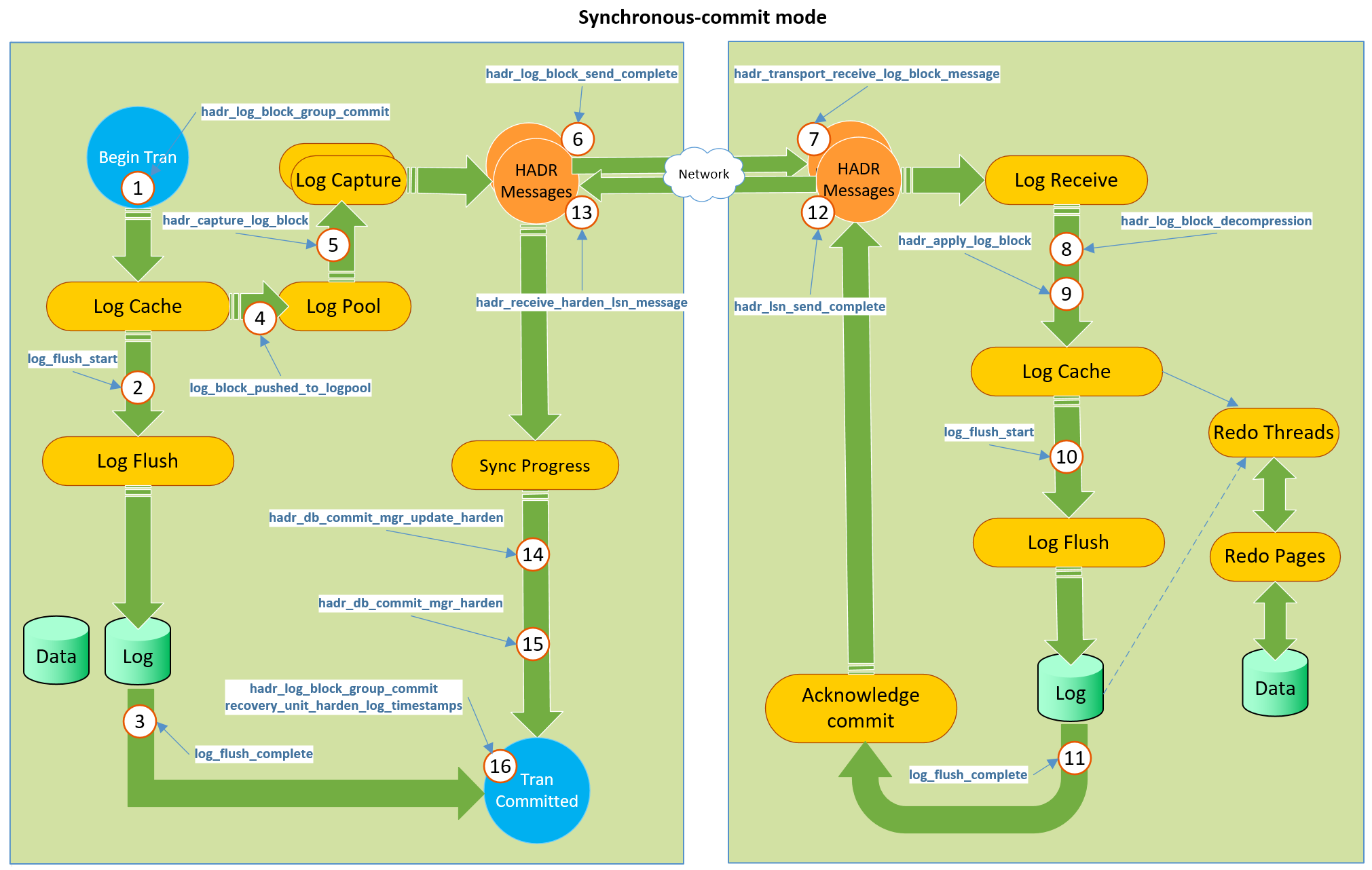
Que representa todo o mecanismo do canal de feedback existente. A réplica, usando a etapa 12 e subsequente, confirma no servidor principal que as informações foram salvas. O mesmo canal pode ser usado para enviar um objeto de fluxo estatístico após recontar uma réplica. Obviamente, não precisaremos usar o tempdb para esse fim, mas criar um objeto na memória dentro do banco de dados que não deve ser armazenado permanentemente (consulte as tabelas Somente Esquema OLTP na Memória ou pense em tabelas NOLOGGING no Oracle) e deve ser removido no final da operação - isso seria muito legal.
Pensamentos gerais
Não deve depender se a réplica síncrona ou não - na maioria das vezes as estatísticas não são atualizadas a cada dois segundos e isso nos leva à segunda parte da idéia - para fazer uma chamada para atualizar as estatísticas no servidor principal com um parâmetro como
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
onde o parâmetro SECONDARY indica onde a operação deve ser executada.
E, assim como nos backups, devemos poder especificar a réplica preferida para executar UPDATE STATISTICS (ou qualquer outra operação no futuro) nas configurações.
Estou certo de que esse recurso incentivará muitos usuários do Enterprise Edition a migrar para a nova versão do SQL Server, que permitirá a distribuição de operações pesadas entre réplicas.
Quanto à situação atual - vejo exatamente como você pode automatizar essa solução usando o Powershell.
Microsoft, é a sua vez! ;)
Vote no recurso proposto
aqui .
Nota do tradutor: Quaisquer sugestões e comentários sobre tradução e estilo são bem-vindos, como sempre.
Normalmente, chamei réplica primária na tradução "servidor primário" e réplica secundária - simplesmente uma réplica. Talvez isso não esteja totalmente correto, mas meu ouvido dói menos que as réplicas "primária" e "secundária" no msdn.