As duas séries anteriores de artigos se concentraram no
isolamento, no
multiversionismo e no
diário .
Nesta série, falaremos sobre bloqueios. Vou aderir a esse termo, mas na literatura também pode haver outro:
castelo .
O ciclo consistirá em quatro partes:
- Bloqueios de relacionamento (este artigo);
- Bloqueios de linha ;
- Fechaduras de outros objetos e fechaduras predicadas;
- Bloqueios na RAM .
O material de todos os artigos é baseado em
cursos de treinamento administrativo que Pavel
pluzanov e eu
fazemos , mas não os repetimos literalmente e são destinados a uma leitura atenta e a experimentações independentes.
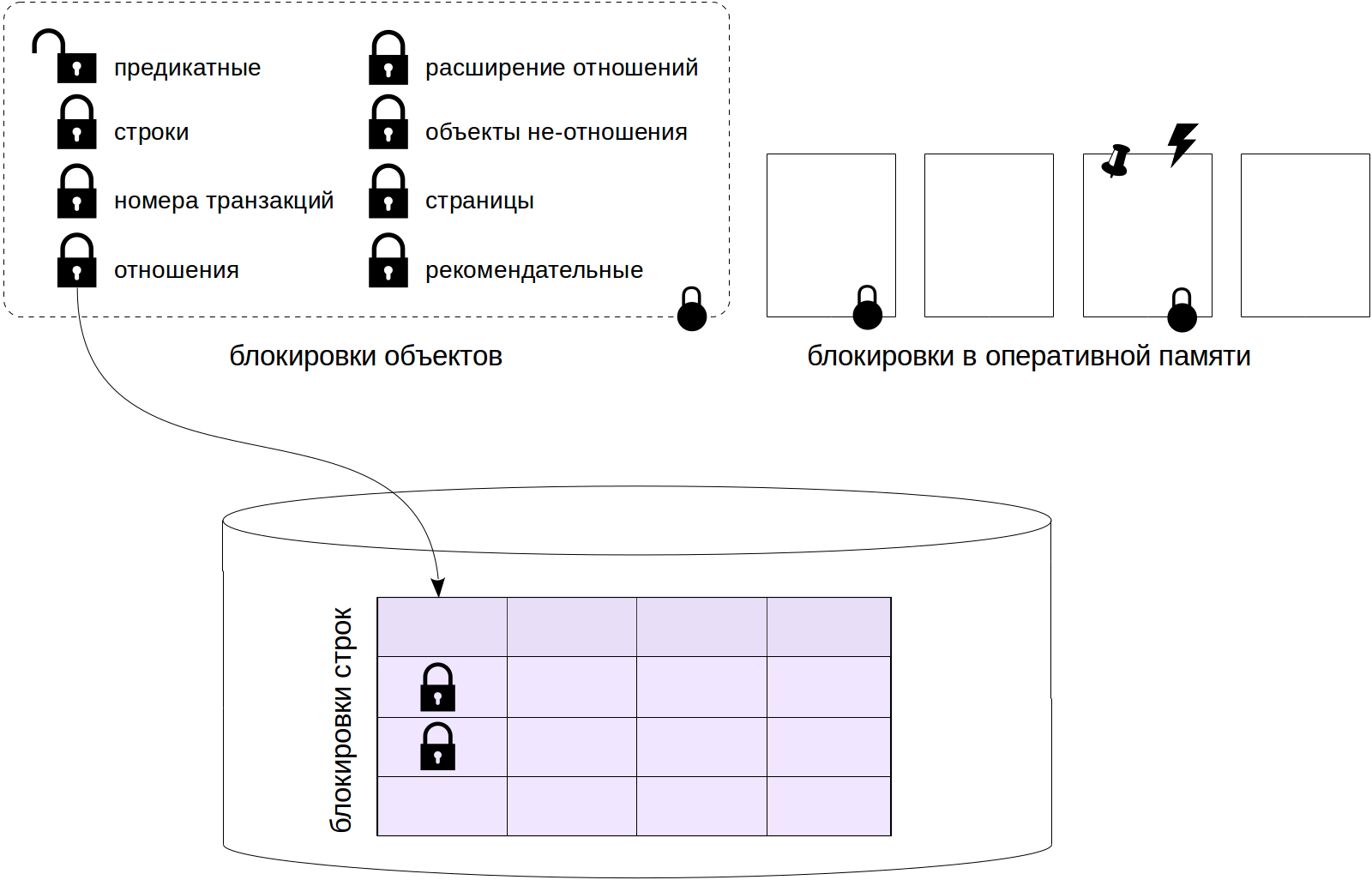
Informações gerais sobre bloqueios
O PostgreSQL usa muitos mecanismos diferentes que são usados para bloquear algo (ou pelo menos são chamados assim). Portanto, começarei com as palavras mais gerais sobre por que os bloqueios são necessários, o que são e como diferem um do outro. Depois, veremos o que é encontrado nessa variedade no PostgreSQL e somente depois disso começaremos a lidar com diferentes tipos de bloqueios em detalhes.
Bloqueios são usados para otimizar o acesso simultâneo a recursos compartilhados.
Acesso competitivo refere-se ao acesso simultâneo de vários processos. Os processos em si podem ser executados em paralelo (se o equipamento permitir) e sequencialmente no modo de compartilhamento de tempo - isso não é importante.
Se não houver concorrência, não haverá necessidade de bloqueios (por exemplo, um cache de buffer compartilhado exige bloqueios, mas um local não).
Antes de acessar um recurso, um processo deve adquirir o bloqueio associado a esse recurso. Ou seja, estamos falando de uma certa disciplina: tudo funciona desde que todos os processos cumpram as regras estabelecidas para acessar um recurso compartilhado. Se o DBMS gerencia os bloqueios, ele próprio monitora o pedido; se o bloqueio é definido pelo aplicativo, essa obrigação recai sobre ele.
Em um nível baixo, um bloqueio é representado por uma seção da memória compartilhada, na qual é observado de alguma forma se o bloqueio está livre ou capturado (e, possivelmente, informações adicionais são registradas: número do processo, tempo de captura etc.).
Você pode perceber que esse pedaço de memória compartilhada é, por si só, um recurso ao qual o acesso competitivo é possível. Se descermos um nível abaixo, veremos que primitivas acessórios especiais (como semáforos ou mutexes) fornecidas pelo sistema operacional são usadas para organizar o acesso. Seu significado é que o código que acessa o recurso compartilhado deve ser executado em apenas um processo por vez. No nível mais baixo, essas primitivas são implementadas com base nas instruções do processador atômico (como testar e configurar ou comparar e trocar).
Depois que o recurso não é mais necessário pelo processo, ele
libera o bloqueio para que outras pessoas possam usá-lo.
Obviamente, nem sempre é possível bloquear o bloqueio: o recurso já pode ser usado por outra pessoa. Em seguida, o processo entra na fila de espera (se o mecanismo de bloqueio oferecer essa oportunidade) ou tenta novamente para capturar o bloqueio após um certo tempo. De uma forma ou de outra, isso leva ao fato de que o processo é forçado a ficar ocioso aguardando a liberação do recurso.
Às vezes é possível aplicar outras estratégias não bloqueadoras. Por exemplo, o mecanismo de multi- versão permite que vários processos, em alguns casos, trabalhem simultaneamente com diferentes versões de dados sem bloquear um ao outro.
Em princípio, um recurso protegido pode ser qualquer coisa, se apenas esse recurso puder ser identificado sem ambiguidade e corresponder a um endereço de bloqueio.
Por exemplo, o recurso pode ser o objeto com o qual o DBMS está trabalhando, como uma página de dados (identificada pelo nome e posição do arquivo), uma tabela (oid no diretório do sistema), uma linha da tabela (página e deslocamento dentro da página). Um recurso pode ser uma estrutura na memória, como uma tabela de hash, buffer etc. (identificado por um número pré-atribuído). Às vezes, é até conveniente usar recursos abstratos que não têm nenhum significado físico (eles são identificados simplesmente por um número único).
A eficácia dos bloqueios é influenciada por muitos fatores, dos quais distinguimos dois.
- A granularidade (granularidade) é importante se os recursos formarem uma hierarquia.
Por exemplo, uma tabela consiste em páginas que contêm linhas da tabela. Todos esses objetos podem atuar como recursos. Se os processos geralmente estiverem interessados em apenas algumas linhas e o bloqueio estiver definido no nível da tabela, outros processos não poderão trabalhar com linhas diferentes ao mesmo tempo. Portanto, quanto maior a granularidade, melhor a possibilidade de paralelização.
Mas isso leva a um aumento no número de bloqueios (informações sobre quais devem ser armazenadas na memória). Nesse caso, um aumento no nível (escalonamento) de bloqueios pode ser aplicado: quando o número de bloqueios granulares de nível inferior exceder um determinado limite, eles serão substituídos por um bloqueio de nível superior.
- Os bloqueios podem ser capturados em diferentes modos .
Os nomes dos modos podem ser absolutamente arbitrários, apenas a matriz de sua compatibilidade é importante. Um modo incompatível com qualquer modo (incluindo ele próprio) geralmente é chamado de exclusivo ou exclusivo. Se os modos forem compatíveis, o bloqueio poderá ser capturado por vários processos simultaneamente; esses modos são chamados de compartilhados. Em geral, quanto mais modos diferentes compatíveis entre si puderem ser distinguidos, mais oportunidades são criadas para o paralelismo.
De acordo com o tempo de uso, os bloqueios podem ser divididos em longos e curtos.
- Os bloqueios de longo prazo são capturados por um período potencialmente longo (geralmente até o final da transação) e geralmente estão relacionados a recursos como tabelas (relacionamentos) e linhas. O PostgreSQL normalmente gerencia esses bloqueios automaticamente, mas o usuário ainda tem algum controle sobre esse processo.
Os bloqueios longos são caracterizados por um grande número de modos, para que o maior número possível de ações simultâneas possa ser executado nos dados. Normalmente, para esses bloqueios, existe uma infraestrutura desenvolvida (por exemplo, suporte de filas de espera e detecção de conflitos) e ferramentas de monitoramento, uma vez que os custos de manutenção de todas essas comodidades ainda são incomparavelmente mais baixos em comparação ao custo das operações em dados protegidos.
- Bloqueios de curto prazo são capturados por um curto período de tempo (de algumas instruções do processador a frações de segundo) e geralmente se referem a estruturas de dados na memória compartilhada. O PostgreSQL gerencia esses bloqueios completamente automaticamente - você só precisa saber sobre a existência deles.
Os bloqueios curtos são caracterizados por um mínimo de modos (exclusivos e compartilhados) e uma infraestrutura simples. Em alguns casos, mesmo as ferramentas de monitoramento podem não estar disponíveis.
O PostgreSQL usa diferentes tipos de bloqueios.
Bloqueios no nível do objeto são
bloqueios "pesados" de longo prazo. Os recursos aqui são relações e outros objetos. Se a palavra bloqueio aparecer no texto sem esclarecimentos, isso significa apenas um bloqueio "normal".
Entre os bloqueios de longo prazo, os bloqueios
no nível da linha se destacam separadamente. Sua implementação difere de outros bloqueios de longo prazo devido ao seu número potencialmente grande (imagine atualizar um milhão de linhas em uma transação). Esses bloqueios serão discutidos no próximo artigo.
O terceiro artigo da série será dedicado aos bloqueios restantes no nível do objeto, bem como aos
bloqueios predicados (uma vez que as informações sobre todos esses bloqueios são armazenadas na RAM da mesma maneira).
Bloqueios curtos incluem vários
bloqueios de estruturas de RAM . Vamos considerá-los no último artigo do ciclo.
Bloqueios de objeto
Então, começamos com bloqueios no nível do objeto. Aqui, um objeto é entendido em primeiro lugar como
relações , isto é, tabelas, índices, sequências, representações materializadas, mas também algumas outras entidades. Esses bloqueios geralmente protegem os objetos de serem alterados ao mesmo tempo ou de serem usados enquanto o objeto está sendo alterado, mas também para outras necessidades.
Redação embaçada? É porque os bloqueios desse grupo são usados para uma variedade de propósitos. O que os une é como eles são organizados.
Dispositivo
Os bloqueios de objetos estão localizados na memória compartilhada do servidor. Seu número é limitado pelo produto dos valores de dois parâmetros:
max_locks_per_transaction ×
max_connections .
O conjunto de bloqueios é comum a todas as transações, ou seja, uma transação pode capturar mais bloqueios que
max_locks_per_transaction : é importante apenas que o número total de bloqueios no sistema não exceda o limite definido. O pool é criado na inicialização, portanto, alterar uma das duas opções indicadas requer uma reinicialização do servidor.
Todos os bloqueios podem ser visualizados na visualização pg_locks.
Se um recurso já estiver bloqueado no modo incompatível, uma transação que tenta capturá-lo é colocada na fila e aguarda a liberação do bloqueio. As transações pendentes não consomem recursos do processador: os processos de serviço correspondentes “adormecem” e são ativados pelo sistema operacional quando o recurso é liberado.
É possível uma situação de
deadlock ou
deadlock , em que uma transação requer que um recurso ocupado pela segunda transação continue e a segunda requer um recurso ocupado pela primeira (no caso geral, um deadlock e mais de duas transações podem ocorrer). Nesse caso, a espera continuará indefinidamente, portanto o PostgreSQL detecta automaticamente essas situações e anula uma das transações para que outras pessoas possam continuar trabalhando. (Falaremos mais sobre impasses no próximo artigo.)
Tipos de Objetos
Aqui está uma lista dos tipos de bloqueios (ou, se você preferir, os tipos de objetos) com os quais trataremos neste e no próximo artigo. Os nomes são dados de acordo com a coluna locktype da visualização pg_locks.
- relação
Bloqueios de relacionamento.
- transactionid e virtualxid
Bloqueando um número de transação (real ou virtual). Cada transação possui um bloqueio exclusivo de seu próprio número, portanto, é conveniente usar esses bloqueios quando você precisar esperar até o final de outra transação.
- tupla
Bloqueio de versão de cadeia. É usado em alguns casos para definir a prioridade entre várias transações que esperam bloquear a mesma linha.
Adiaremos a discussão dos demais tipos de bloqueios até o terceiro artigo do ciclo. Todos eles são capturados apenas no modo excepcional ou em exclusivo e compartilhado.
- estender
Usado ao adicionar páginas a um arquivo de qualquer relacionamento.
- objeto
Bloquear objetos que não são relacionamentos (bancos de dados, esquemas, assinaturas etc.).
- página
O bloqueio de página é usado com pouca frequência e apenas por alguns tipos de índices.
- consultivo
Bloqueio recomendado, definido manualmente pelo usuário.
Bloqueios de relacionamento
Para não perder o contexto, vou marcar nessa imagem os tipos de bloqueios, que serão discutidos mais adiante.
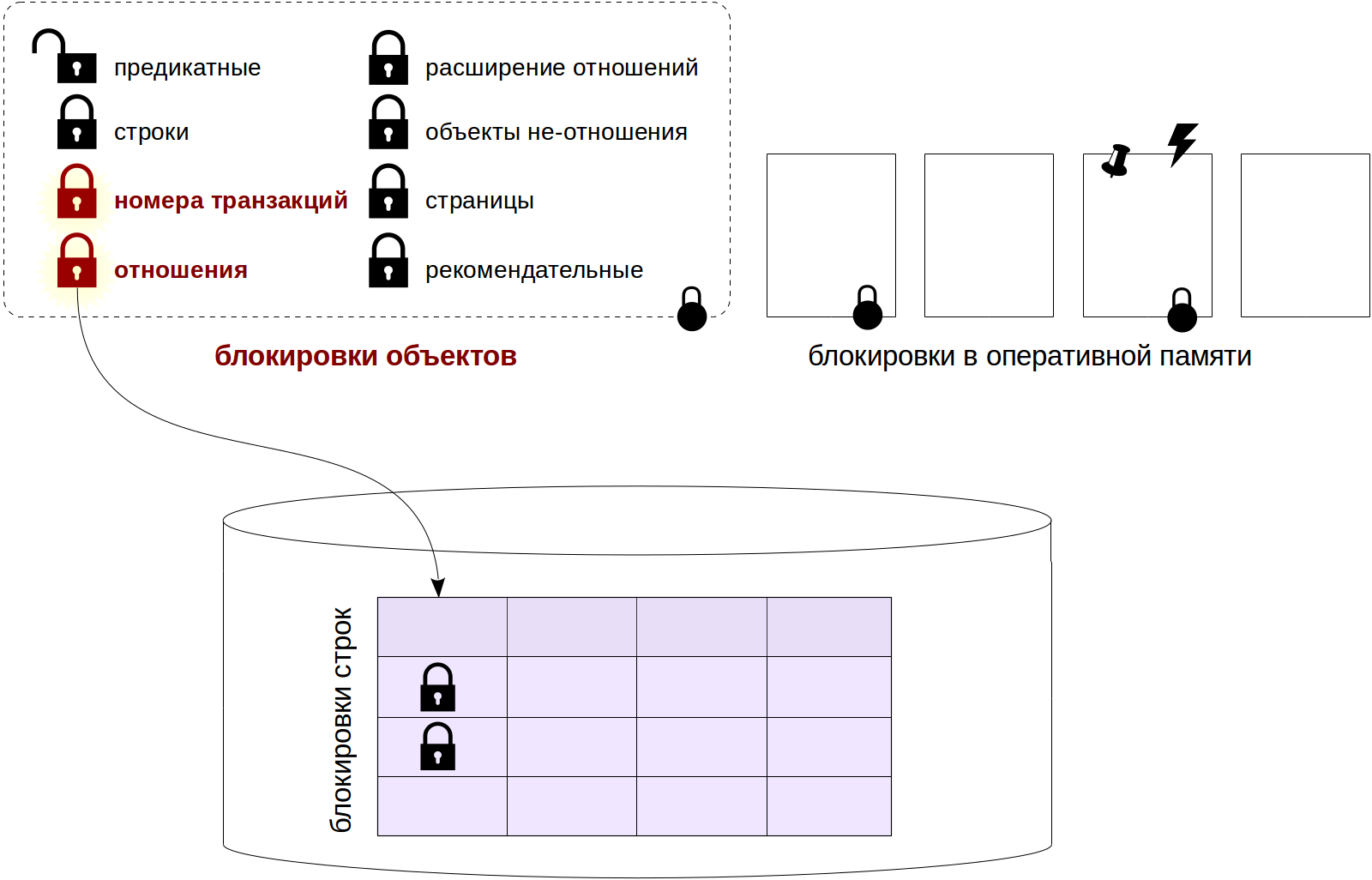
Modos
Se não é o mais importante, certamente as relações de bloqueio e bloqueio mais “ramificadas”. Para ela, são definidos até 8 modos diferentes. Essa quantidade é necessária para que o maior número possível de instruções pertencentes a uma tabela possa ser executado simultaneamente.
Não faz sentido aprender esses modos de cor ou tentar entender o significado de seus nomes; o principal é ter uma
matriz na frente dos olhos no momento certo, que mostra quais bloqueios entram em conflito entre si. Por conveniência, é reproduzido aqui, juntamente com exemplos de comandos que requerem níveis de bloqueio apropriados:
Alguns comentários:
- Os primeiros 4 modos permitem alterações simultâneas de dados na tabela, e os próximos 4 não.
- O primeiro modo (acesso compartilhado) é o mais fraco, é compatível com outro que não o anterior (acesso exclusivo). Este último modo é exclusivo, não é compatível com nenhum modo.
- O comando ALTER TABLE possui muitas opções, diferentes das quais requerem diferentes níveis de bloqueio. Portanto, na matriz, esse comando aparece em linhas diferentes e é marcado com um asterisco.
Por exemplo, por exemplo
dê um exemplo. O que acontece se eu executar o comando CREATE INDEX?
Encontramos na documentação que este comando define o bloqueio no modo Compartilhar. De acordo com a matriz, determinamos que o comando é compatível consigo mesmo (ou seja, você pode criar vários índices simultaneamente) e com os comandos de leitura. Portanto, os comandos SELECT continuarão funcionando, mas os comandos UPDATE, DELETE, INSERT serão bloqueados.
E vice-versa - transações incompletas que modificam dados na tabela bloquearão a operação do comando CREATE INDEX. Portanto, há uma variante do comando - CREATE INDEX CONCURRENTLY. Ele funciona por mais tempo (e pode até cair com um erro), mas permite alterações simultâneas de dados.
Isso pode ser visto na prática. Para experimentos, usaremos
a tabela de contas "bancárias" conhecidas desde o
primeiro ciclo , na qual armazenaremos o número e o valor da conta.
=> CREATE TABLE accounts( acc_no integer PRIMARY KEY, amount numeric ); => INSERT INTO accounts VALUES (1,1000.00), (2,2000.00), (3,3000.00);
Na segunda sessão, inicie a transação. Precisamos de um número de processo de serviço.
| => SELECT pg_backend_pid();
| pg_backend_pid | ---------------- | 4746 | (1 row)
Quais bloqueios mantém a transação recém-iniciada? Nós olhamos em pg_locks:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4746;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 5/15 | | ExclusiveLock | t (1 row)
Como eu já disse, uma transação sempre mantém um bloqueio exclusivo (ExclusiveLock) de seu próprio número, nesse caso, um virtual. Não há outros bloqueios nesse processo.
Agora atualize a linha da tabela. Como a situação mudará?
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
=> \g
locktype | relation | virtxid | xid | mode | granted ---------------+---------------+---------+--------+------------------+--------- relation | accounts_pkey | | | RowExclusiveLock | t relation | accounts | | | RowExclusiveLock | t virtualxid | | 5/15 | | ExclusiveLock | t transactionid | | | 529404 | ExclusiveLock | t (4 rows)
Agora, existem bloqueios na tabela e no índice mutáveis (criados para a chave primária), que são usados pelo comando UPDATE. Ambos os bloqueios são obtidos no modo RowExclusiveLock. Além disso, foi adicionado um bloqueio exclusivo do número real da transação (que apareceu assim que a transação começou a alterar os dados).
Agora, em outra sessão, tentaremos criar um índice em uma tabela.
|| => SELECT pg_backend_pid();
|| pg_backend_pid || ---------------- || 4782 || (1 row)
|| => CREATE INDEX ON accounts(acc_no);
O comando congela em antecipação à liberação do recurso. Que tipo de bloqueio ela está tentando capturar? Verifique:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4782;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 6/15 | | ExclusiveLock | t relation | accounts | | | ShareLock | f (2 rows)
Vemos que a transação está tentando obter o bloqueio da tabela no modo ShareLock, mas não pode (concedido = f).
É conveniente encontrar o número do processo de bloqueio e, em geral, vários números, usando a função que apareceu na versão 9.6 (antes disso eu tinha que tirar conclusões examinando cuidadosamente todo o conteúdo de pg_locks):
=> SELECT pg_blocking_pids(4782);
pg_blocking_pids ------------------ {4746} (1 row)
E então, para entender a situação, você pode obter informações sobre as sessões, incluindo os números encontrados:
=> SELECT * FROM pg_stat_activity WHERE pid = ANY(pg_blocking_pids(4782)) \gx
-[ RECORD 1 ]----+------------------------------------------------------------ datid | 16386 datname | test pid | 4746 usesysid | 16384 usename | student application_name | psql client_addr | client_hostname | client_port | -1 backend_start | 2019-08-07 15:02:53.811842+03 xact_start | 2019-08-07 15:02:54.090672+03 query_start | 2019-08-07 15:02:54.10621+03 state_change | 2019-08-07 15:02:54.106965+03 wait_event_type | Client wait_event | ClientRead state | idle in transaction backend_xid | 529404 backend_xmin | query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1; backend_type | client backend
Depois que a transação é concluída, os bloqueios são liberados e o índice é criado.
| => COMMIT;
| COMMIT
|| CREATE INDEX
Na fila! ..
Para melhor imaginar o que a aparência de um bloqueio incompatível leva, veremos o que acontece se o comando VACUUM FULL for executado durante a operação do sistema.
Deixe o comando SELECT ser executado primeiro em nossa tabela. Ela recebe um bloqueio no nível mais fraco do Access Share. Para controlar o tempo de liberação do bloqueio, executamos este comando dentro da transação - até que a transação termine, o bloqueio não será liberado. Na realidade, vários comandos podem ler (e modificar) a tabela e algumas das consultas podem demorar um pouco.
=> BEGIN; => SELECT * FROM accounts;
acc_no | amount --------+--------- 2 | 2000.00 3 | 3000.00 1 | 1100.00 (3 rows)
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+-----------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} (1 row)
Em seguida, o administrador executa o comando VACUUM FULL, que requer um bloqueio de nível exclusivo do Access, incompatível com qualquer coisa, mesmo com o compartilhamento de acesso. (O comando LOCK TABLE também requer o mesmo bloqueio.) As filas de transações.
| => BEGIN; | => LOCK TABLE accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} (2 rows)
Mas o aplicativo continua emitindo solicitações e agora o comando SELECT aparece no sistema. Teoricamente, ela poderia ter "escorregado" enquanto o VACUUM FULL está esperando, mas não - ela honestamente ocupa um lugar na fila do VACUUM FULL.
|| => SELECT * FROM accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} relation | AccessShareLock | f | 4782 | {4746} (3 rows)
Depois que a primeira transação com o comando SELECT é concluída e libera o bloqueio, o comando VACUUM FULL é iniciado (que simulamos com o comando LOCK TABLE).
=> COMMIT;
COMMIT
| LOCK TABLE
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessExclusiveLock | t | 4746 | {} relation | AccessShareLock | f | 4782 | {4746} (2 rows)
E somente após o VACUUM FULL concluir seu trabalho e remover o bloqueio, todos os comandos acumulados na fila (SELECT em nosso exemplo) poderão capturar os bloqueios correspondentes (compartilhamento de acesso) e executar.
| => COMMIT;
| COMMIT
|| acc_no | amount || --------+--------- || 2 | 2000.00 || 3 | 3000.00 || 1 | 1100.00 || (3 rows)
Assim, um comando impreciso pode paralisar a operação do sistema por um tempo significativamente maior que o tempo de execução do próprio comando.
Ferramentas de monitoramento
Obviamente, os bloqueios são necessários para a operação correta, mas podem levar a expectativas indesejáveis. Tais expectativas podem ser monitoradas para entender sua causa e, se possível, eliminá-las (por exemplo, alterando o algoritmo do aplicativo).
Já nos familiarizamos com um método: no momento de um bloqueio longo, podemos executar uma solicitação para a visualização pg_locks, examinar as transações bloqueáveis e de bloqueio (função pg_blocking_pids) e descriptografá-las usando pg_stat_activity.
Outra maneira é ativar o parâmetro
log_lock_waits . Nesse caso, as informações aparecerão no log de mensagens do servidor se a transação estiver aguardando mais do que
deadlock_timeout (apesar do fato de o parâmetro para deadlocks ser usado, estamos falando de expectativas normais).
Vamos tentar.
=> ALTER SYSTEM SET log_lock_waits = on; => SELECT pg_reload_conf();
O valor padrão do parâmetro
deadlock_timeout é de um segundo:
=> SHOW deadlock_timeout;
deadlock_timeout ------------------ 1s (1 row)
Toque a fechadura.
=> BEGIN; => UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
| => BEGIN; | => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
O segundo comando UPDATE espera um bloqueio. Aguarde um segundo e conclua a primeira transação.
=> SELECT pg_sleep(1); => COMMIT;
COMMIT
Agora a segunda transação pode ser concluída.
| UPDATE 1
| => COMMIT;
| COMMIT
E toda a informação importante entrou no diário:
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms 2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898. 2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms 2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
Para ser continuado .