Neste artigo, trataremos do alinhamento de dados e também resolveremos a 17ª tarefa do site
pwnable.kr .
Informações OrganizacionaisEspecialmente para aqueles que desejam aprender algo novo e se desenvolver em qualquer uma das áreas de segurança da informação e da informática, escreverei e falarei sobre as seguintes categorias:
- PWN;
- criptografia (criptografia);
- tecnologias de rede (rede);
- reverso (engenharia reversa);
- esteganografia (estegano);
- pesquisa e exploração de vulnerabilidades na WEB.
Além disso, compartilharei minha experiência em análise forense de computadores, análise de malware e firmware, ataques a redes sem fio e redes locais, realização de protestos e explorações por escrito.
Para que você possa descobrir sobre novos artigos, software e outras informações, criei um
canal no Telegram e um
grupo para discutir quaisquer questões no campo da CID. Além disso, considerarei pessoalmente seus pedidos, perguntas, sugestões e recomendações
pessoais e responderei a todos .
Todas as informações são fornecidas apenas para fins educacionais. O autor deste documento não se responsabiliza por nenhum dano causado a alguém como resultado do uso dos conhecimentos e métodos obtidos como resultado do estudo deste documento.
Alinhamento de dados
O alinhamento de dados na memória de acesso aleatório do computador é um arranjo especial de dados na memória para um acesso mais rápido. Ao trabalhar com memória, os processos usam a palavra máquina como a unidade principal. Diferentes tipos de processadores podem ter tamanhos diferentes: um, dois, quatro, oito etc. bytes. Ao salvar objetos na memória, pode acontecer que algum campo ultrapasse esses limites de palavras. Alguns processadores podem trabalhar com dados não alinhados por mais tempo do que com dados alinhados. E processadores não sofisticados geralmente não podem trabalhar com dados desalinhados.
Para imaginar melhor um modelo de dados alinhados e desalinhados, considere um exemplo no objeto a seguir - a estrutura de dados.
struct Data{ int var1; void* mas[4]; };
Como o tamanho de uma variável int nos processadores x32 e x64 não é de 4 bytes e o valor de uma variável void * é de 4 e 8 bytes, respectivamente, essa estrutura para os processadores x32 e x64 será representada na memória da seguinte maneira.

Os processadores X64 com essa estrutura não funcionarão, pois os dados não estão alinhados. Para alinhamento de dados, é necessário adicionar outro campo de 4 bytes à estrutura.
struct Data{ int var1; int addition; void* mas[4]; };
Assim, os dados da estrutura de dados dos processadores x64 serão alinhados na memória.

Solução de trabalho Memcpy
Clicamos no ícone de assinatura memcpy e informamos que precisamos conectar via SSH com a senha de convidado.
Eles também fornecem código fonte. 
Quando conectado, vemos o banner correspondente.
Vamos descobrir quais arquivos estão no servidor e quais direitos temos.

Temos um arquivo leia-me. Após a leitura, aprendemos que o programa é executado na porta 9022.

Conecte-se à porta 9022. Nos é oferecido um experimento - compare a versão lenta e rápida do memcpy. Em seguida, o programa inserirá um número em um determinado intervalo e emitirá um relatório sobre a comparação das versões lenta e rápida da função. Há uma coisa: experimentos 10 e relatórios - 5.
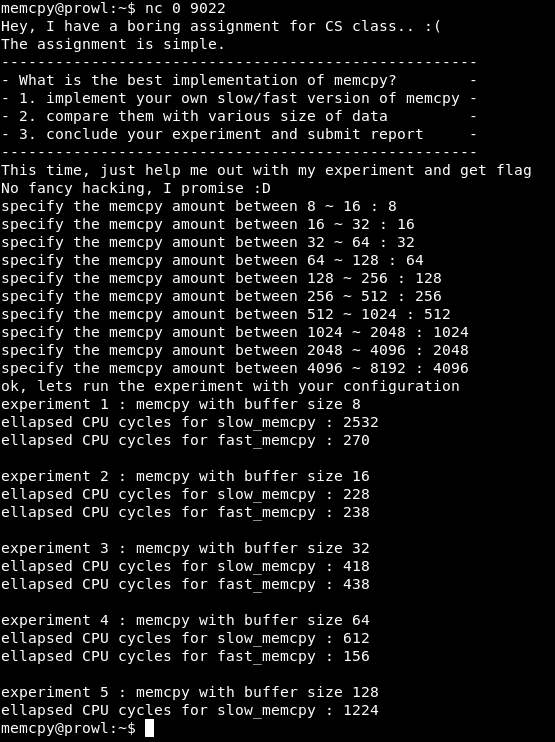
Vamos arrumar o porquê. Encontre o local no código para comparar os resultados.
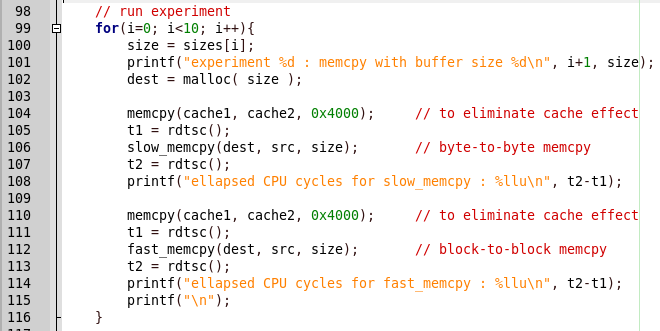
Tudo é simples, primeiro é chamado slow_memcpy, depois fast_memcpy. Mas no relatório do programa há uma conclusão sobre a liberação lenta da função e, quando a rápida implementação é chamada, o programa trava. Vamos ver o código de implementação rápida.
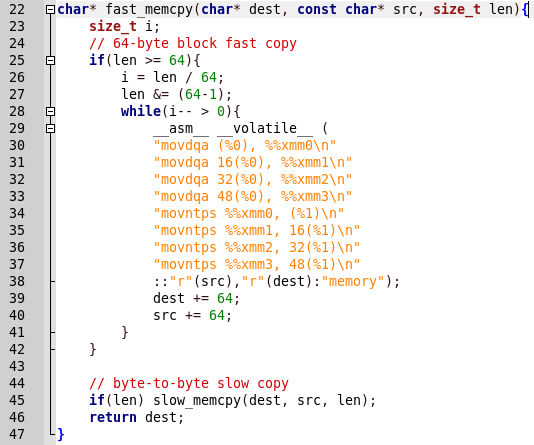
A cópia é feita usando as funções do assembler. Determinamos por comandos que esse é o SSE2. Como dito
aqui : o SSE2 usa oito registradores de 128 bits (xmm0 a xmm7) incluídos na arquitetura x86 com a introdução da extensão SSE, cada qual tratada como 2 valores consecutivos de ponto flutuante de precisão dupla. Além disso, esse código está trabalhando com dados alinhados.


Assim, trabalhando com dados não alinhados, o programa pode falhar. O alinhamento é realizado por 128 bits, ou seja, 16 bytes cada, o que significa que os blocos devem ser iguais a 16. Precisamos descobrir quantos bytes já estão no primeiro bloco na pilha (deixe X) e, em seguida, devemos transferir o programa quantos bytes (deixar Y) para que ( X + Y)% 16 foi 0.
Como todas as operações ocupam blocos de pilha que são múltiplos de dois, itere sobre X como 2, 4, 8, etc. até 16.
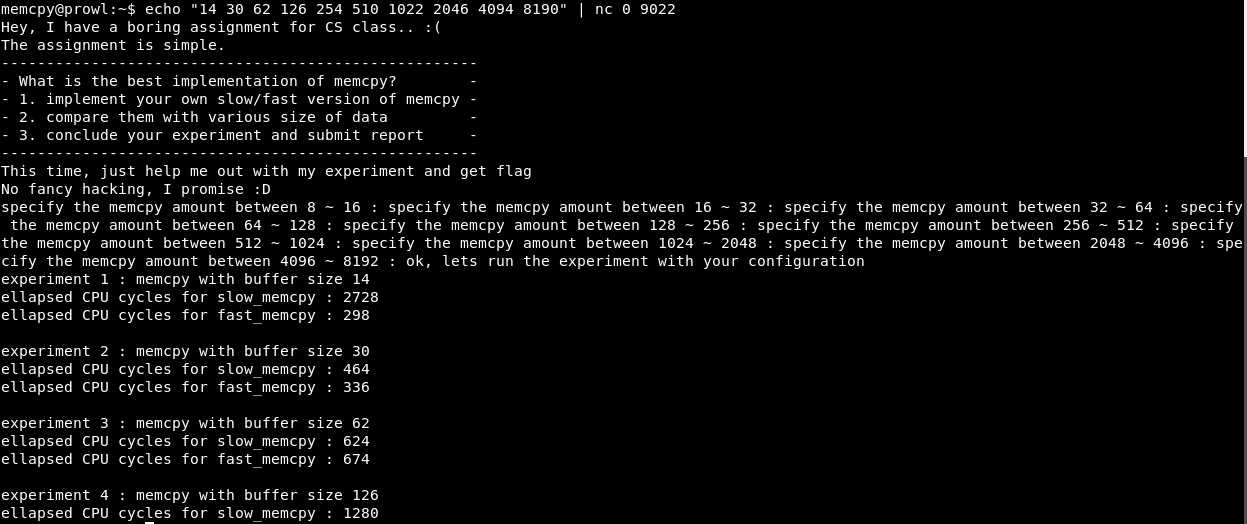
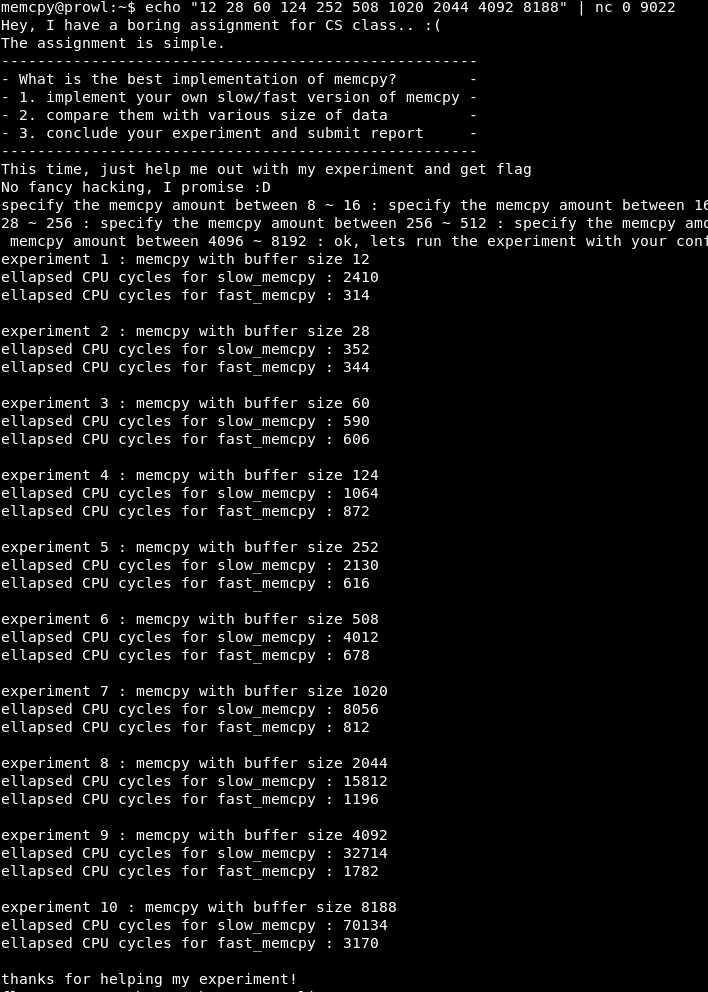
Como você pode ver, com X = 4, o programa é executado com sucesso.

Conseguimos a concha, lemos a bandeira, ganha 10 pontos.
Você pode se juntar a nós no
Telegram . Da próxima vez, trataremos do estouro de heap.