
A World Wide Web é um oceano de dados. Aqui você pode ver quase todas as informações de seu interesse. No entanto, "puxar" essas informações da Internet já é mais difícil. Existem várias maneiras de obter dados e a raspagem na web é uma delas.
O que é raspagem da web? Em suma, é uma tecnologia que permite recuperar dados de páginas HTML. Ao usar raspagem, não é necessário copiar e colar as informações necessárias ou transferi-las da tela para o bloco de notas. As informações aparecerão no seu computador em um formato conveniente para você.
Web-scraping no exemplo do site Kinopoisk.ru
É uma boa ideia definir uma meta para não fazer raspagem por raspagem. Decidi que seria uma comparação das classificações de filmes no Kinopoisk.ru e IMDB.com, bem como as classificações médias de filmes por gênero . Para análise, foram realizados os filmes lançados de 2010 a 2018, com um mínimo de 500 votos.
Para começar, carregue as bibliotecas necessárias:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
Em seguida, recebo o número de filmes em um ano que atendem à condição de seleção (mais de 500 votos). Isso é feito para descobrir o número total de páginas com dados e "gerar" links para elas, porque links são semelhantes em estrutura.
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
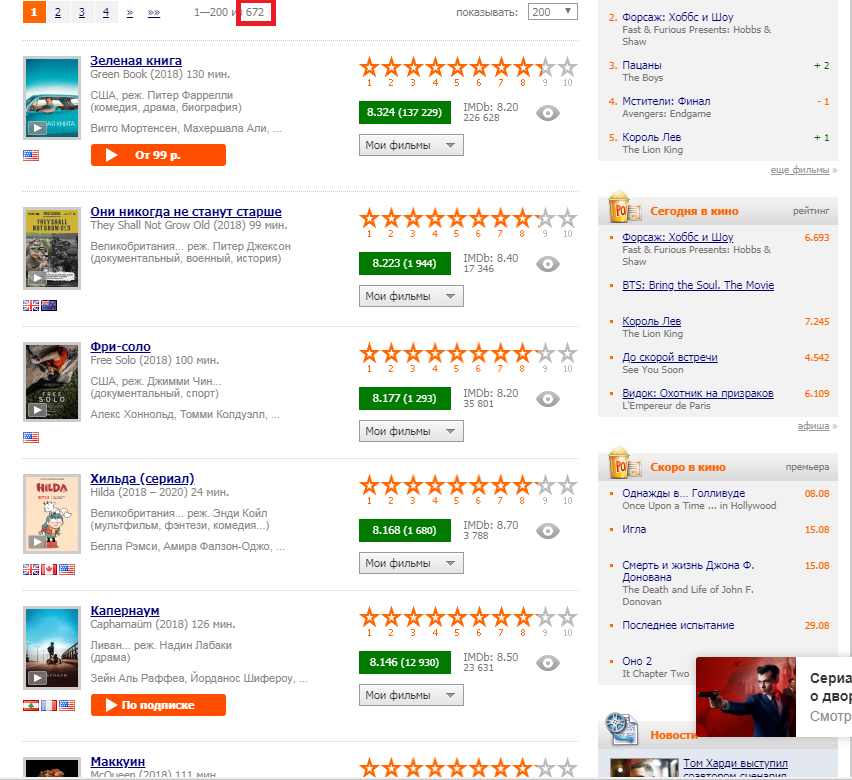
Nossa tarefa é "retirar" o número 672, destacado na figura por um retângulo vermelho. Para isso, precisamos de scraping na web.
Páginas de raspagem da web do site Kinopoisk.ru usando o pacote rvest
Primeiro, precisamos "ler" o URL que recebemos. Para fazer isso, use a função read_html() do pacote read_html() .
# XML HTML webpage <- read_html(url)
E então, usando as funções do pacote rvest primeiro "extraímos" a parte do documento HTML que precisamos (a função html_nodes() ) e, a partir desta parte, extraímos as informações necessárias em um formato conveniente para nós (as html_text() , html_table() , html_attr() outro)
Mas como entendemos qual elemento precisamos extrair? Para fazer isso, precisamos passar o mouse sobre as informações em que estamos interessados, clicar em LMB e selecionar "visualizar código". No nosso caso, temos a seguinte imagem:
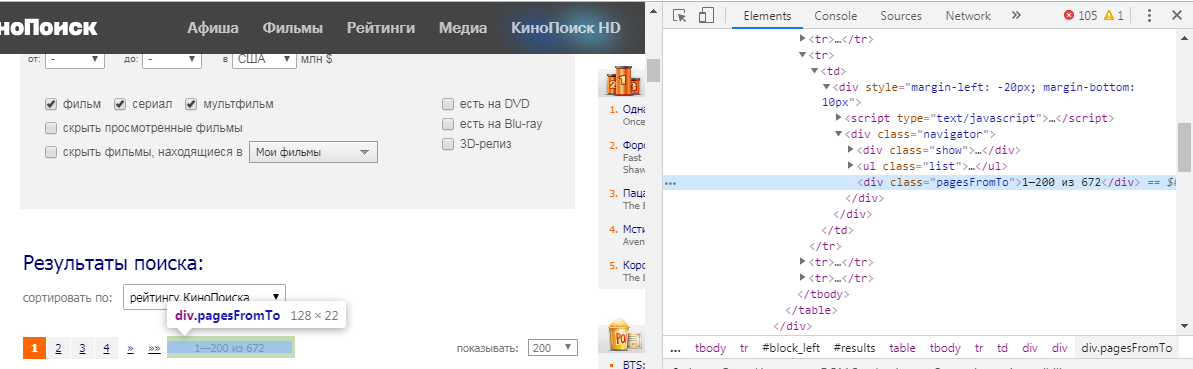
A função html_nodes() possui o formato html_nodes(x, css) . x é a página da web definida anteriormente, mas em css escrevemos o id ou a classe do elemento. No nosso caso, é:
number_html <- html_nodes(webpage, ".pagesFromTo")
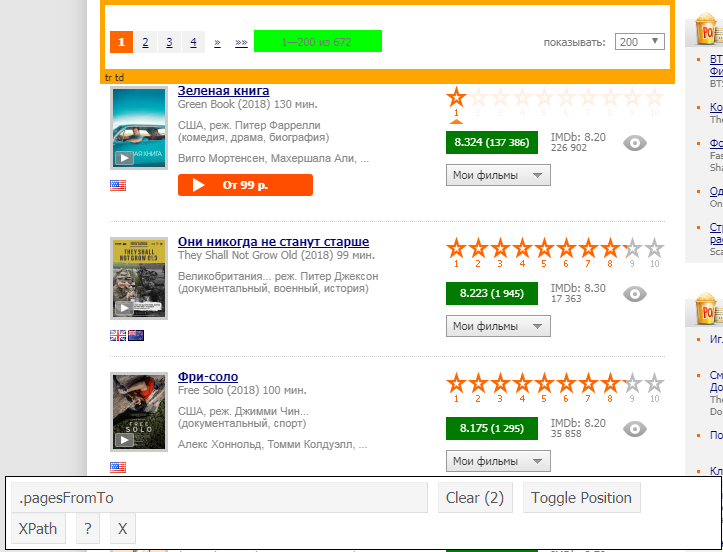
Além disso, para "detectar" o elemento desejado, você pode usar a extensão selectorGadget , que mostra o que precisamos inserir explicitamente:
Em seguida, com a função html_text, extraímos a parte do texto do elemento selecionado:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
Obtivemos o número necessário na página HTML do Kinopoisk, mas agora precisamos "limpá-lo". Este é um procedimento padrão para a raspagem, porque muito raramente precisamos do elemento que precisamos da forma que precisamos.
Temos dois elementos idênticos devido ao fato de que o número total de filmes é indicado na parte superior e inferior da página e seu seletor de css é exatamente o mesmo. Portanto, para iniciantes, removemos o elemento em excesso:
number <- number[1] [1] "1—50 672"
Em seguida, precisamos nos livrar da parte do vetor que sobe para o número 672. Você pode fazer isso de maneiras diferentes, mas a base de todos os métodos é escrever uma expressão regular. Nesse caso, eu “substituo” a parte “1-50 de” por um vazio (você pode usar str_remove vez de str_replace ), depois removo os espaços extras (função str_trim ) e, finalmente, traduzo o vetor do caractere para o tipo numérico. Na saída, recebo o número 672. Exatamente tantos filmes de 2018 têm mais de 500 votos de usuários no Kinopoisk.
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
O que faremos a seguir? Se você olhar as páginas do Kinopoisk, verá que os endereços das páginas de pesquisa têm a mesma estrutura e diferem apenas em número. Portanto, para não inserir o endereço da página manualmente a cada vez, calcularemos o número de páginas e "geraremos" o número necessário de endereços. É feito assim:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
A saída é 14 endereços. A função de ceiling neste exemplo arredonda um número para um número inteiro BIG.
E então usamos a função lapply na entrada da qual os endereços das páginas são alimentados, e a função "extrai" informações das páginas do Kinopoisk sobre o nome, classificação, número de votos e gêneros principais (máximo 3) do filme. O código de função pode ser encontrado no repositório no Github .
Como resultado, obtemos uma tabela com 8111 filmes.
Vale a pena notar sobre o uso da função Sys.sleep. Usando-o, você pode definir o tempo de atraso entre as expressões. Por que isso é necessário? Se você deseja receber informações em um ano, não há necessidade. Mas se você estiver interessado em um grande número de filmes / anos, depois de um certo número de solicitações, o Kinopoisk o considerará um robô e você receberá uma lista vazia para sua solicitação. Para evitar isso, é necessário inserir o tempo de atraso.
Da mesma forma, "descarte" o site IMDB.com.
Análise de dados
Temos duas tabelas, em uma informação sobre filmes com IMDB, na outra, do Kinopoisk. Agora precisamos combiná-los. Vamos nos unir de acordo com as colunas NOME e ANO. Para reduzir o número de discrepâncias nos nomes, mesmo no estágio de raspagem, removi todos os sinais de pontuação e converti as letras para minúsculas. Como resultado, depois de todas as conexões e exclusões, obtemos 3450 filmes com as informações de que precisamos nos dois sites.
Estou interessado na diferença nas classificações de filmes em dois sites, por isso criaremos a variável DELTA, que é a diferença entre as estimativas do IMDB e Kinopoisk. Se DELTA for positivo, a pontuação no IMDB é maior; se negativo, menor.
Primeiro, construa um histograma para o indicador DELTA:
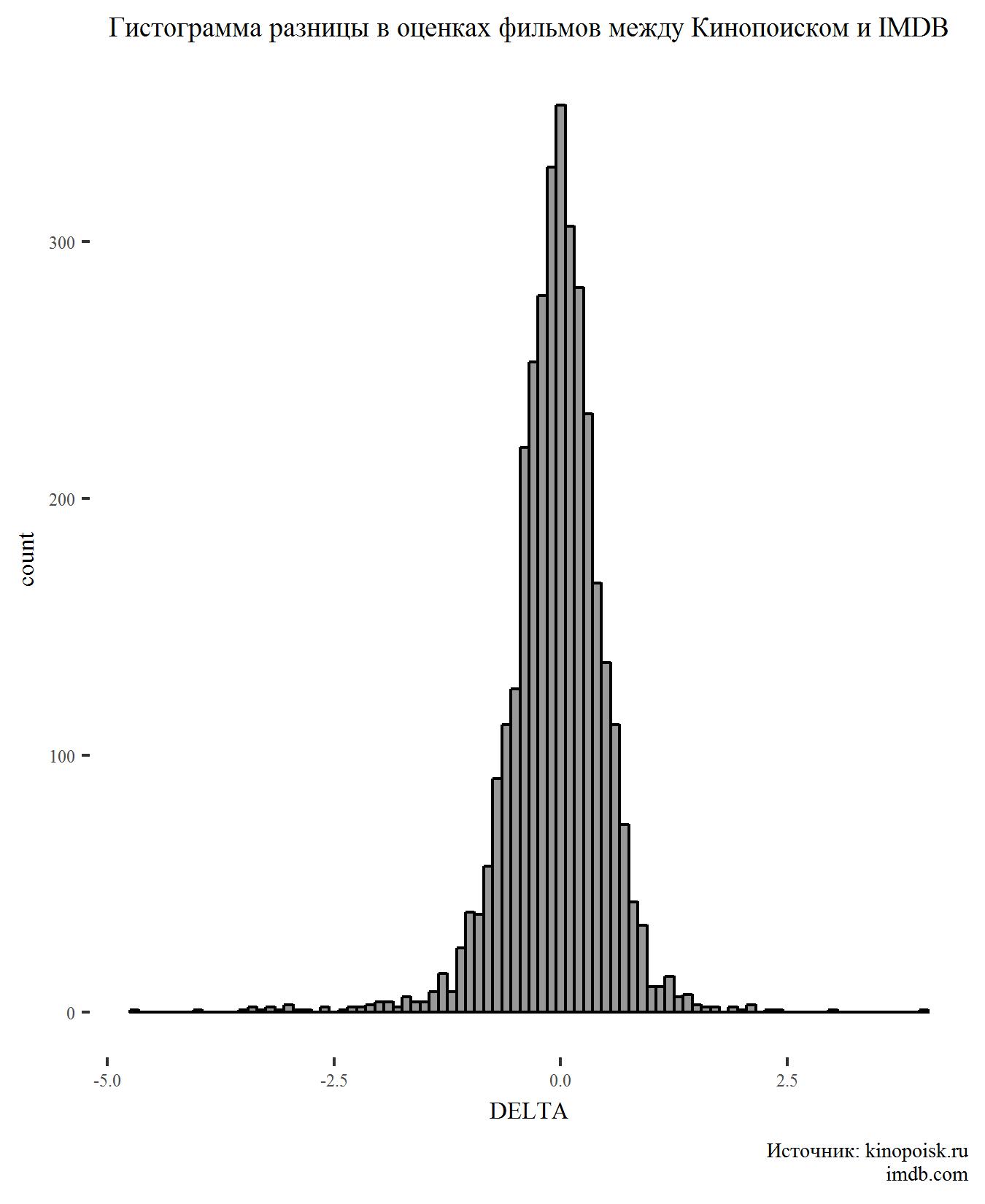
Não há nada de surpreendente no gráfico. A diferença nas classificações tem uma distribuição normal e um pico na região de zero, o que sugere que os usuários dos dois sites geralmente concordam com a classificação dos filmes.
Convergir, mas não exatamente. O teste t de duas amostras independentes nos permite dizer que as classificações no Kinopoisk são mais altas e essa diferença é estatisticamente significativa (valor de p <0,05).
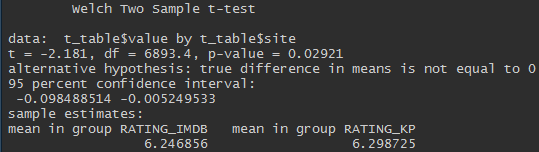
Embora a diferença seja significativa, é muito pequena.
A seguir, vamos ver como a diferença nas classificações depende do número de votos.
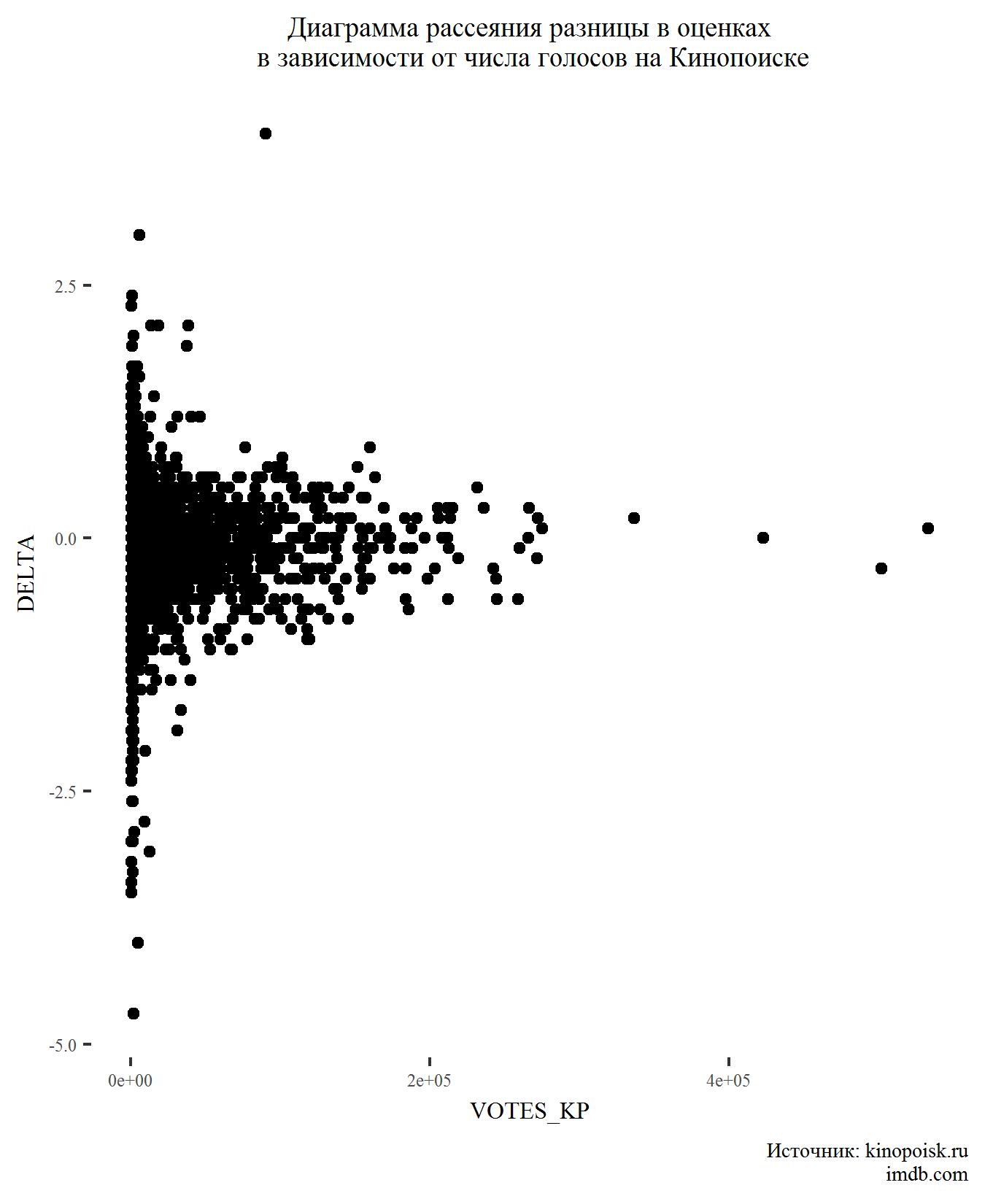
Nada de inesperado aqui também. Filmes com um grande número de votos geralmente têm muito pouca diferença nas classificações.
Agora, vamos avaliar filmes por gênero. Vale a pena notar imediatamente que um filme pode ter até três gêneros, mas apenas uma classificação, para que um filme possa ser "testado", comédia e melodrama.
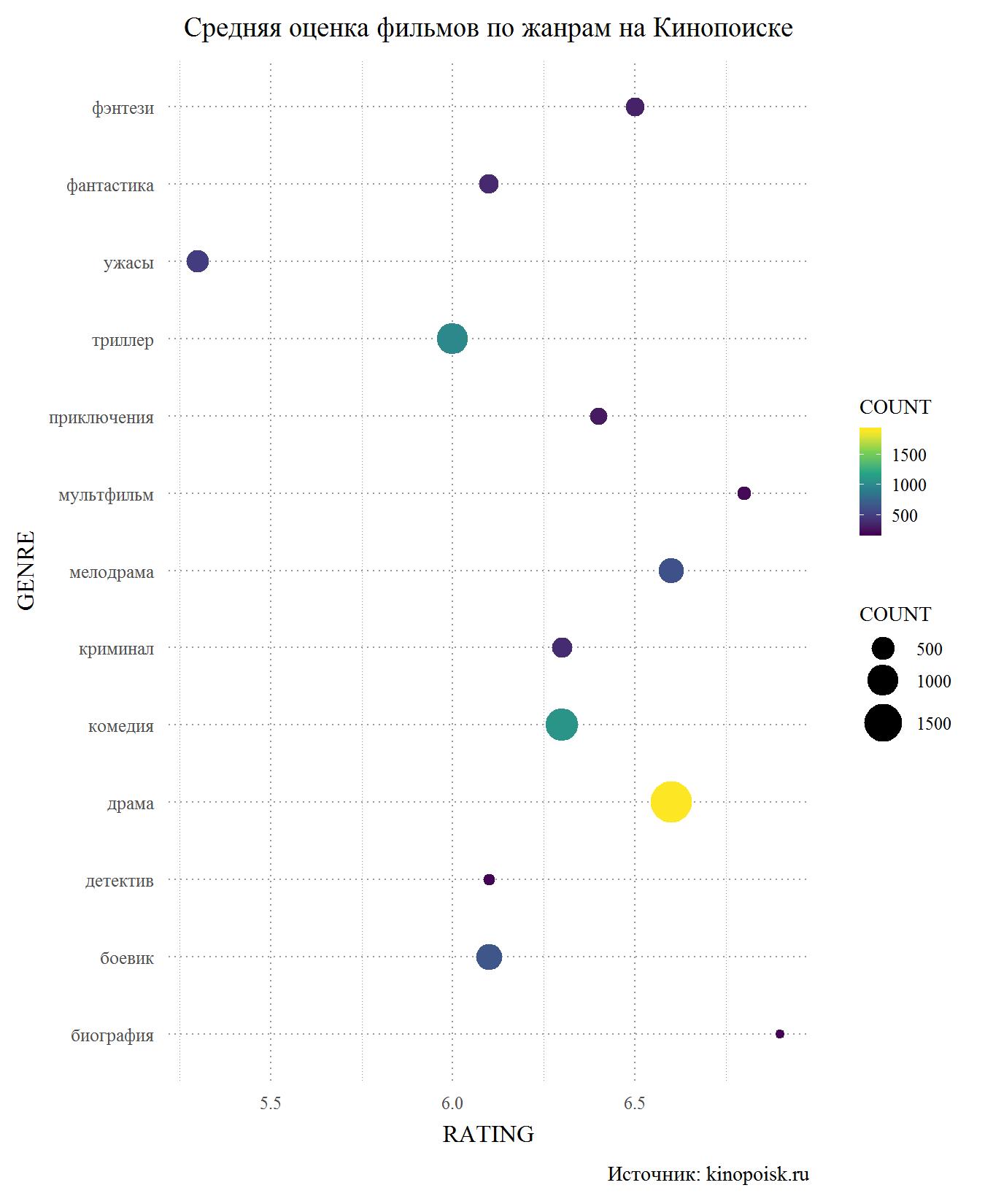
Vamos começar com o Kinopoisk. Entre os gêneros com pelo menos 150 aparições no banco de dados, o horror é um estranho óbvio. Também usuários baixos classificam thrillers, detetives de ação e, o que foi surpreendente para mim, ficção científica. Por outro lado, os filmes melodramáticos no Kinopoisk surgem com um estrondo, com uma classificação média acima de 6,5 e perdendo apenas para os desenhos animados e os filmes biográficos, que são muito menores no banco de dados.
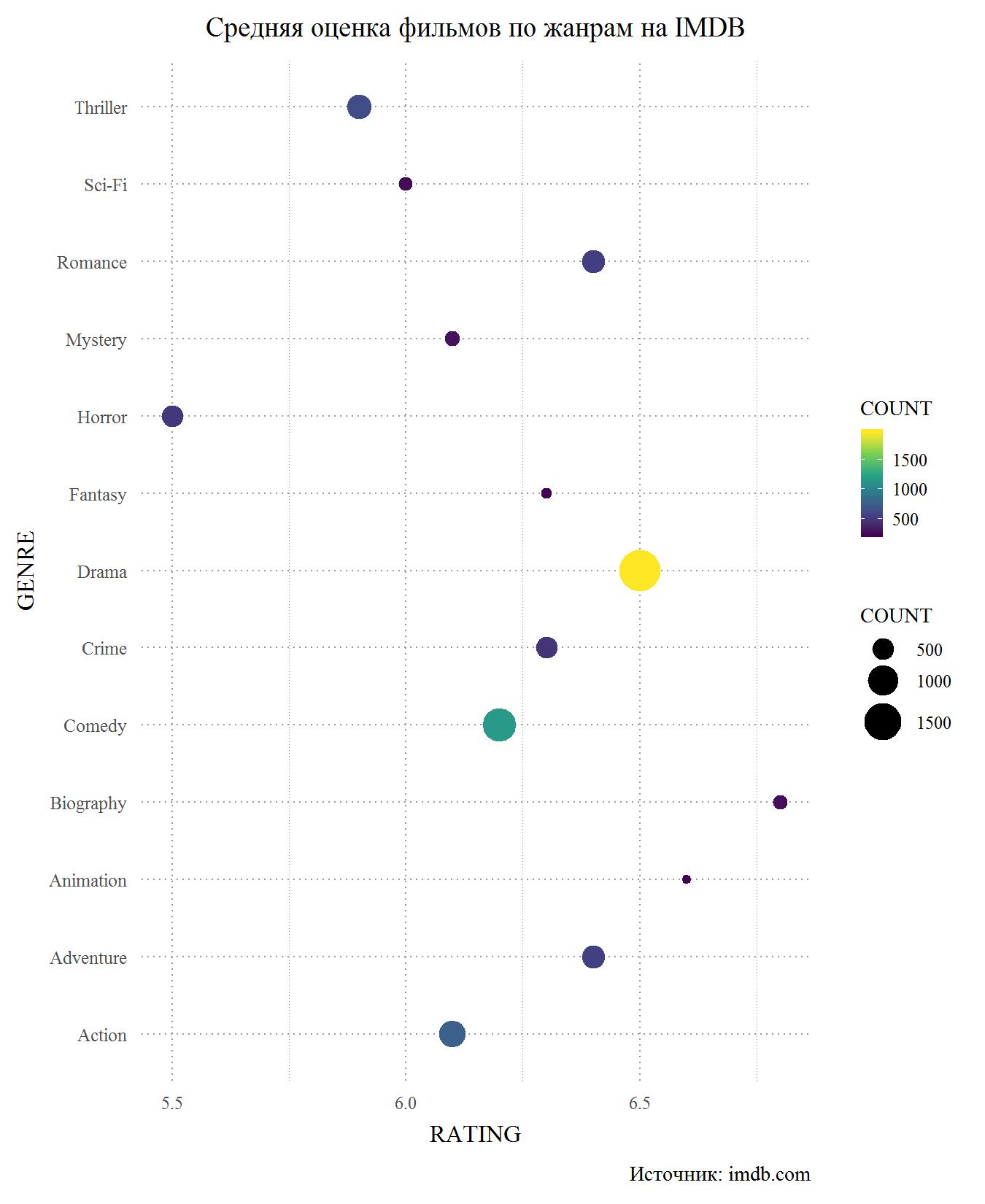
Agora considere o mesmo gráfico, mas para o IMDB. Em princípio, ele novamente confirma que a diferença de classificação entre os sites é insignificante. Isso não é surpreendente, porque muitos usuários têm contas nos dois sites e é improvável que dêem classificações diferentes em sites diferentes. Mais uma vez, o principal perdedor são os horrores, e podemos dizer que eles são o gênero de filmes com classificação mais baixa. É difícil para mim avaliar por que isso acontece, porque o único filme de terror que assisti na minha vida é Gremlins. Talvez sejam os horrores que são o gênero de orçamento mais baixo, de onde vêm a fraca atuação de atores baratos e os cenários francamente ruins. Suspense com ficção científica e no IMDB estão entre os retardatários, mas os militantes estão se saindo melhor. Entre os líderes estão novamente filmes e desenhos biográficos. O drama ocupa o terceiro lugar, mas a pontuação dos melodramas caiu abaixo de 6,5, ao nível dos filmes de aventura. Também no IMDB abaixo de comédias.
Conclusão e um pouco sobre os "fatores externos"
Embora exista uma diferença nas estimativas (no Kinopoisk, elas são um pouco mais altas), é um pouco. De acordo com vários gêneros, a grande diferença também é imperceptível. Os blockbusters que têm dezenas ou mesmo centenas de milhares de votos, se tiverem diferenças, ficam dentro de 0,5 pontos.
Filmes com um pequeno número (especialmente no Kinopoisk) de votos, até 10 mil, geralmente têm uma grande diferença nas classificações. No entanto, a maior diferença na classificação a favor do IMDB é o filme com 30.000 votos em um site estrangeiro e mais de 90.000 no Kinopoisk. Esta é a criação de Alexei Pimanov "Crimeia". O filme é tão apreciado por espectadores estrangeiros? Dificilmente. Muito provavelmente, os cineastas usaram a mesma "política de marketing" em relação ao IMDB do Kinopoisk. É que, se o Kinopoisk "limpou" essas estimativas, elas permaneceram no IMDB. Eu acho que é por isso que "Crimeia" é um "bom pequeno parente".
Ficaria muito grato por quaisquer comentários, sugestões, reclamações
Link do repositório do Github
Perfil do meu círculo