Olá pessoal. Vou falar sobre microsserviços, mas de um ponto de vista ligeiramente diferente do de Vadim Madison, no post "O que sabemos sobre microsserviços" . Em geral, eu me considero um desenvolvedor de banco de dados. O que os microsserviços têm a ver com isso? O Avito usa: Vertica, PostgreSQL, Redis, MongoDB, Tarantool, VoltDB, SQLite ... No total, temos mais de 456 bancos de dados para mais de 849 serviços. E de alguma forma você precisa viver com isso.
Neste post, mostrarei como implementamos a descoberta de dados na arquitetura de microsserviços. Este post é uma transcrição gratuita do meu relatório com o Highload ++ 2018 , o vídeo pode ser visto aqui .

Todos devem saber como uma arquitetura de microsserviço deve ser construída em termos de bases. Aqui está o padrão com o qual todos geralmente começam. Existe uma base comum entre os serviços. No slide, os retângulos laranja são serviços, existe uma base comum entre eles.
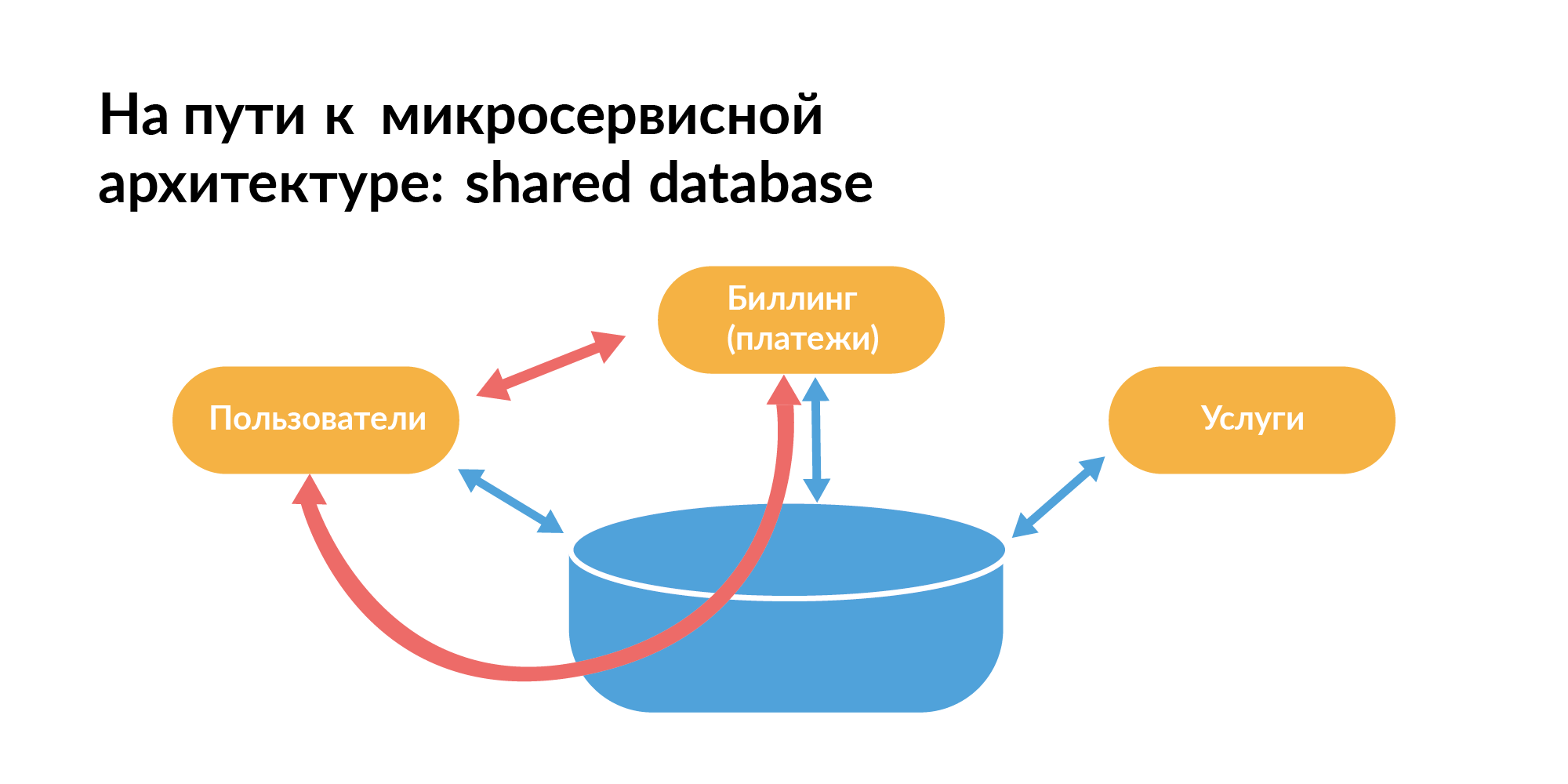
Você não pode viver assim, porque não pode testar serviços isoladamente quando, além da comunicação direta entre eles, também há comunicação através do banco de dados. Uma solicitação de serviço pode diminuir a velocidade de outro serviço. Isso é ruim.

Do ponto de vista do trabalho com bancos de dados para arquitetura de microsserviço, o padrão DataBase por Serviço deve ser usado - cada serviço possui seu próprio banco de dados. Se houver muitos shards no banco de dados, a base deverá ser compartilhada para que eles sejam sincronizados. Isso é uma teoria, mas na realidade não é assim.

Em empresas reais, eles usam não apenas microsserviços, mas também um monólito. Existem serviços escritos corretamente. E existem serviços antigos que ainda usam um padrão de base comum.
Vadim Madison, em sua apresentação, mostrou esta imagem com conexão. Só ele mostrou sem um componente, e a rede nele era uniforme. Nesta rede no centro, há um ponto que está conectado a muitos pontos (microsserviços). Este é um monólito. É pequeno no diagrama. Mas, de fato, o monólito é grande. Quando falamos de uma empresa real, é necessário entender as nuances da coexistência da arquitetura monolítica microsserviços, nascida e de saída, mas ainda importante.
Como um monólito é reescrito em uma arquitetura de microsserviço no nível de planejamento? Obviamente, isso é modelagem de domínio. Em todos os lugares, diz que você precisa fazer a modelagem de domínio. Mas, por exemplo, nós no Avito por vários anos criamos microsserviços sem modelagem de domínio. Então eu peguei e desenvolvedores de banco de dados. Estamos cientes de fluxos de dados completos. Esse conhecimento ajuda a projetar um modelo de domínio.

A descoberta de dados tem uma interpretação clássica - é assim que se trabalha com dados espalhados por diferentes armazenamentos, a fim de levar a conclusões agregadas e fazer as conclusões corretas. Isso é realmente tudo besteira de marketing. Essas definições são sobre como baixar todos os dados dos microsserviços para o armazenamento. Sobre isso eu tive relatórios há vários anos, não vamos nos debruçar sobre isso.
Vou falar sobre outro processo, mais próximo do processo de mudança para microsserviços. Quero mostrar como você pode entender a complexidade de um sistema em constante evolução em termos de dados, em termos de microsserviços. Onde ver toda a imagem de centenas de serviços, bases, equipes, pessoas? De fato, esta questão é a principal idéia do relatório.

Para não morrer nessa arquitetura de microsserviço, você precisa de um gêmeo digital. Sua empresa é a totalidade de tudo que fornece a infraestrutura tecnológica. Você precisa criar uma imagem adequada de todas essas dificuldades, com base nas quais pode resolver rapidamente problemas. E este não é um repositório analítico.

Que tarefas podemos definir para um gêmeo digital? Afinal, tudo começou com a descoberta de dados mais simples.
Perguntas:
- Quais serviços armazenam dados importantes?
- Em que dados pessoais não são armazenados?
- Você tem centenas de bases. Que dados pessoais existem? E em que não?
- Como os dados importantes fluem entre os serviços?
- Por exemplo, o serviço não tinha dados pessoais, e então ele começou a ouvir o ônibus, e eles apareceram. Onde os dados são copiados quando são apagados?
- Quem pode trabalhar com quais dados?
- Quem pode acessar diretamente pelo serviço, alguns pelo banco de dados, outros pelo barramento?
- Quem através de outro serviço pode puxar a alça da API (solicitação) e baixar alguma coisa?
A resposta para essas perguntas é quase sempre um gráfico de elementos, um gráfico de relacionamentos. Este gráfico precisa ser preenchido, atualizado e mantido com novos dados. Decidimos chamar esse gráfico de Tecido Persistente (na tradução - lembrando o tecido). Aqui está a visualização dele.
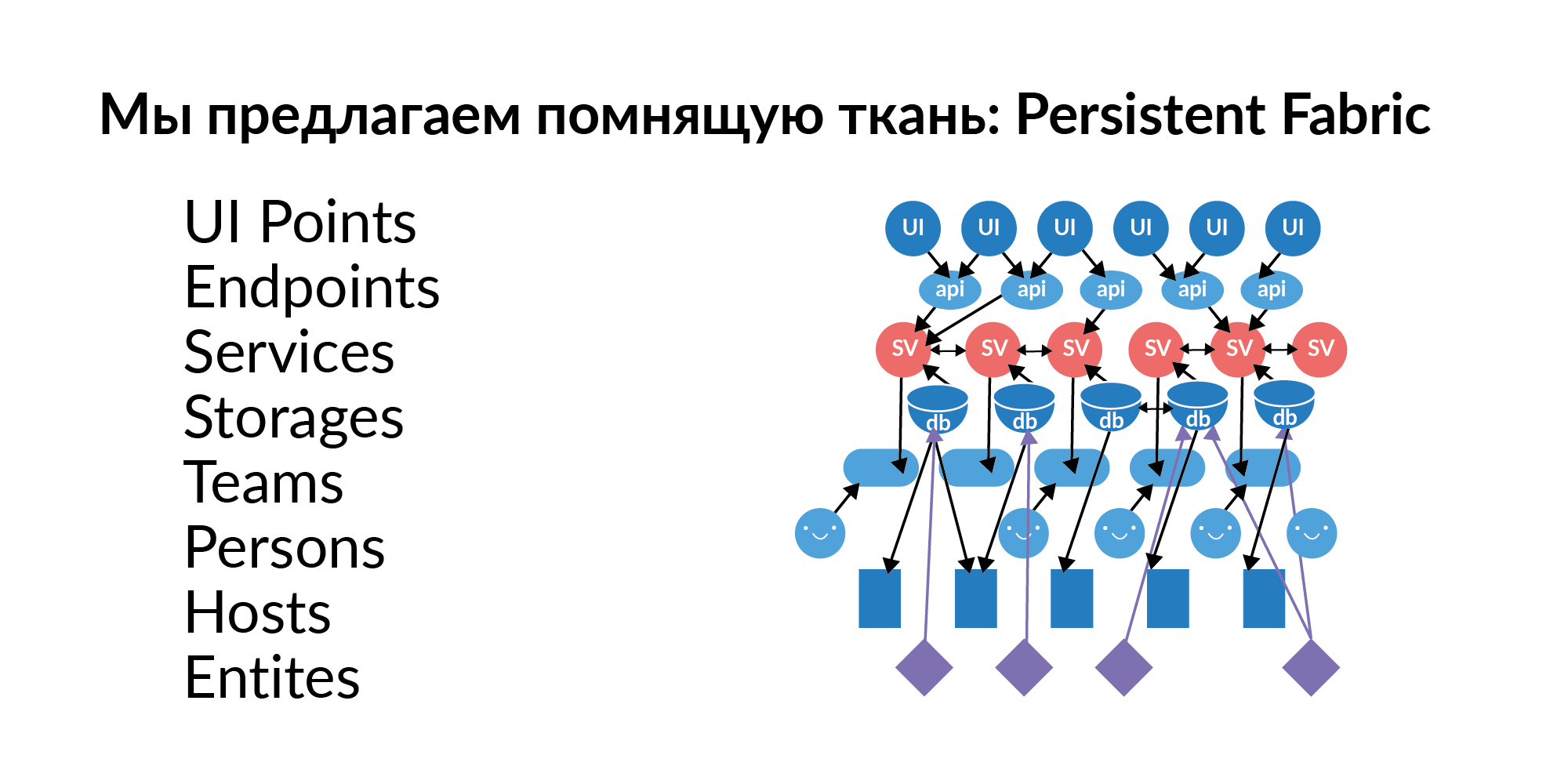
Vamos ver o que pode haver nesse tecido de lembrança.
Pontos de interface . Estes são elementos de interação do usuário com a interface gráfica. Pode haver vários pontos de interface do usuário em uma página. Essas são ações-chave personalizadas, relativamente falando.
Pontos finais . A interface do usuário aponta empurrões Endpoints. Na tradição russa, isso é chamado de canetas. Alças de serviços. Os terminais extraem serviços.
Serviços Centenas de serviços. Os serviços estão conectados um ao outro. Entendemos qual serviço pode obter o serviço. Entendemos que chamada para pontos de interface do usuário pode chamar quais serviços na cadeia.
Bases (em um sentido lógico) . A base como termo de armazenamento parece ruim, porque esse termo se refere a algo analítico. Agora, consideramos o banco de dados como armazenamento. Por exemplo, Redis, PostgreSQL, Tarantool. Se um serviço usa um banco de dados, geralmente usa vários bancos de dados.
- Para armazenamento de dados a longo prazo, por exemplo, PostgreSQL.
- Redis é usado como um cache.
- Tarantool, que pode calcular rapidamente algo no fluxo de dados.
Anfitriões O banco de dados possui uma implantação para hosts. Uma base, um Redis pode realmente viver em 16 máquinas (anel principal) e outro 16 escravo ao vivo. Isso fornece uma compreensão de quais servidores você precisa restringir o acesso para que alguns dados importantes não vazem.
Entidades . As entidades são armazenadas nos bancos de dados. Exemplos de entidades: usuário, anúncio, pagamento. As entidades podem ser armazenadas em vários bancos de dados. E aqui é importante não apenas saber que essa entidade está lá. É importante saber que esta entidade tem um armazenamento sendo a Fonte Dourada. Fonte de Ouro é a base onde uma entidade é criada e editada. Todas as outras bases são caches funcionais. Um ponto importante. Se, Deus proibir, uma entidade tiver duas Fontes Douradas, será necessária uma laboriosa coordenação das fontes separadas. As entidades que estão no banco de dados devem ter acesso ao serviço se quisermos enriquecer esse serviço com novas funcionalidades.
Equipes . Equipes que possuem os serviços. Um serviço que não pertence às equipes é um serviço ruim. É difícil para ele encontrar alguém responsável.
Agora vou me correlacionar fortemente com o relatório de Vadim Madison, porque ele mencionou que a pessoa que foi a última a cometer lá se reflete nos serviços. Este é um bom ponto de partida. Mas a longo prazo, isso é ruim, porque a pessoa que cometeu por último lá pode sair.
Portanto, você precisa conhecer a equipe, as pessoas nelas e seu papel. Temos um gráfico tão simples, onde em cada camada existem várias centenas de elementos. Você conhece um sistema onde tudo isso pode ser armazenado?
O ponto chave. Para que este Tecido Persistente seja utilizado, ele não deve ser preenchido apenas uma vez. Os serviços são criados, eles morrem, o armazenamento é alocado, eles se movem pelos servidores, as equipes são criadas, interrompidas e as pessoas mudam para outras equipes. As entidades são novas, adicionadas a novos serviços, excluídas. Os terminais são criados, registrados, as trajetórias do usuário do ponto de vista da GUI também são refeitas. O mais importante não é que, em algum lugar, você precise armazená-lo tecnicamente. O mais importante é tornar todas as camadas de Tecido Persistente atualizadas. Que é atualizado.
Proponho percorrer as camadas. Ilustrarei como fazemos isso. Vou mostrar como isso pode ser feito no nível de camadas individuais.

Informações sobre a equipe podem ser obtidas na estrutura organizacional de 1C. Aqui, quero ilustrar que o Persistent Fabric não precisa preencher o gráfico gigante inteiro para preencher. Cada camada precisa ser preenchida corretamente.

Informações sobre pessoas podem ser obtidas no LDAP. Uma pessoa pode assumir papéis diferentes em equipes diferentes. Isso é absolutamente normal. Agora criamos o sistema Avito People e, a partir dele, levamos o vínculo das pessoas às equipes e seus papéis. O mais importante é que esses dados simples sigam para que pelo menos mantenham links para as extremidades dos links, para que os nomes das equipes correspondam às equipes da estrutura organizacional 1C.
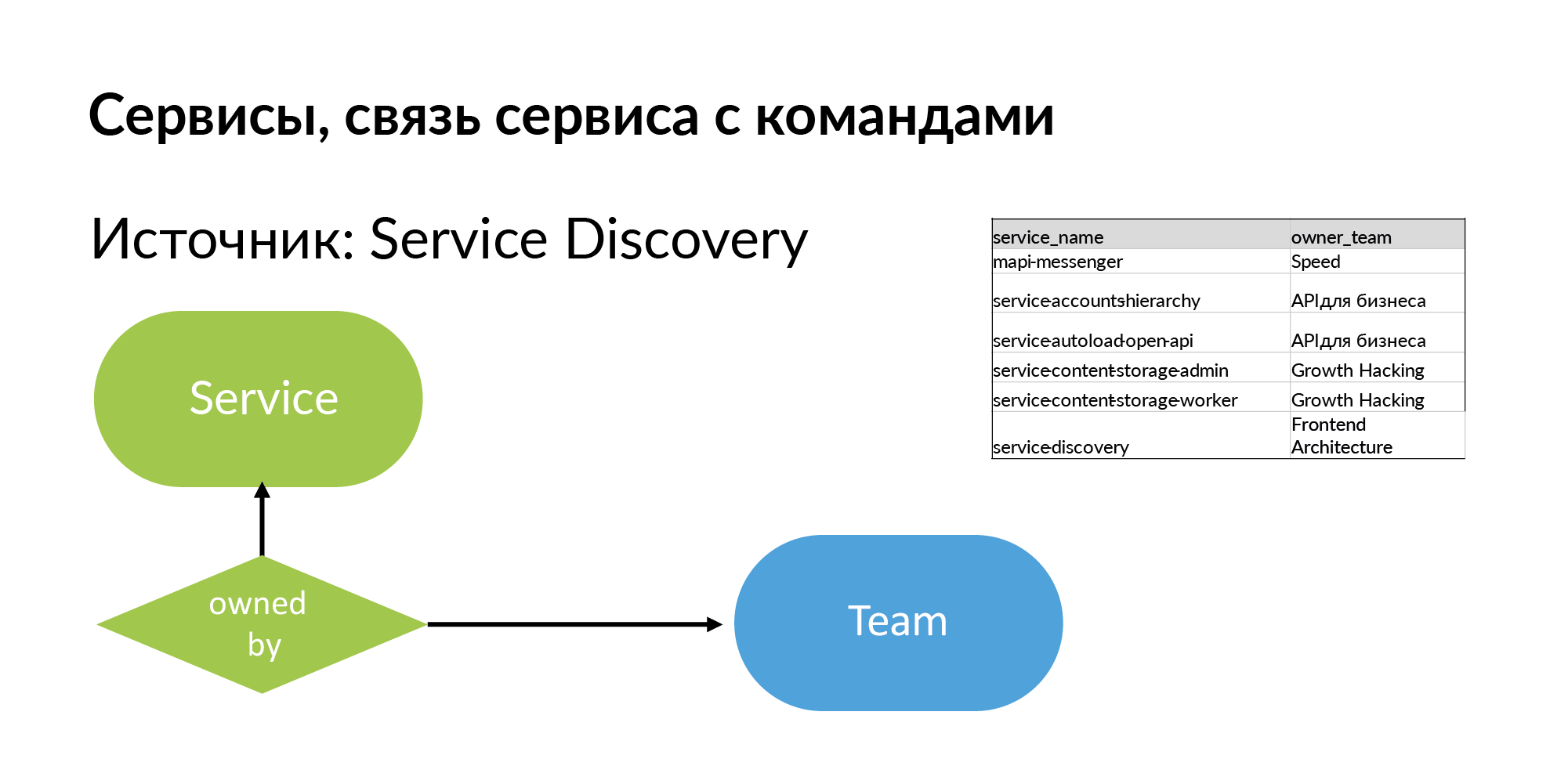
Serviços Para o serviço, você precisa obter o nome e a equipe que o possui. A fonte é descoberta de serviço. Este é o sistema que Vadim Madison mencionou sob o nome Atlas. Atlas é um registro geral de serviços.
É útil entender que quase todos esses sistemas, como o Atlas, armazenam informações sobre 95% dos serviços. 5% dos serviços nesses sistemas estão ausentes, porque serviços antigos criados sem registro no Atlas. E quando você começa a trabalhar com esse esquema, sente o que está perdendo.

Armazenamentos são repositórios genéricos. Pode ser PostgreSQL, MongoDB, Memcache, Vertica. Temos várias fontes para a descoberta de armazenamento. Os bancos de dados NoSQL usam sua própria metade do Atlas. Para obter informações sobre bancos de dados PostgreSQL, a análise yaml é usada. Mas eles querem tornar sua descoberta de armazenamento mais correta.
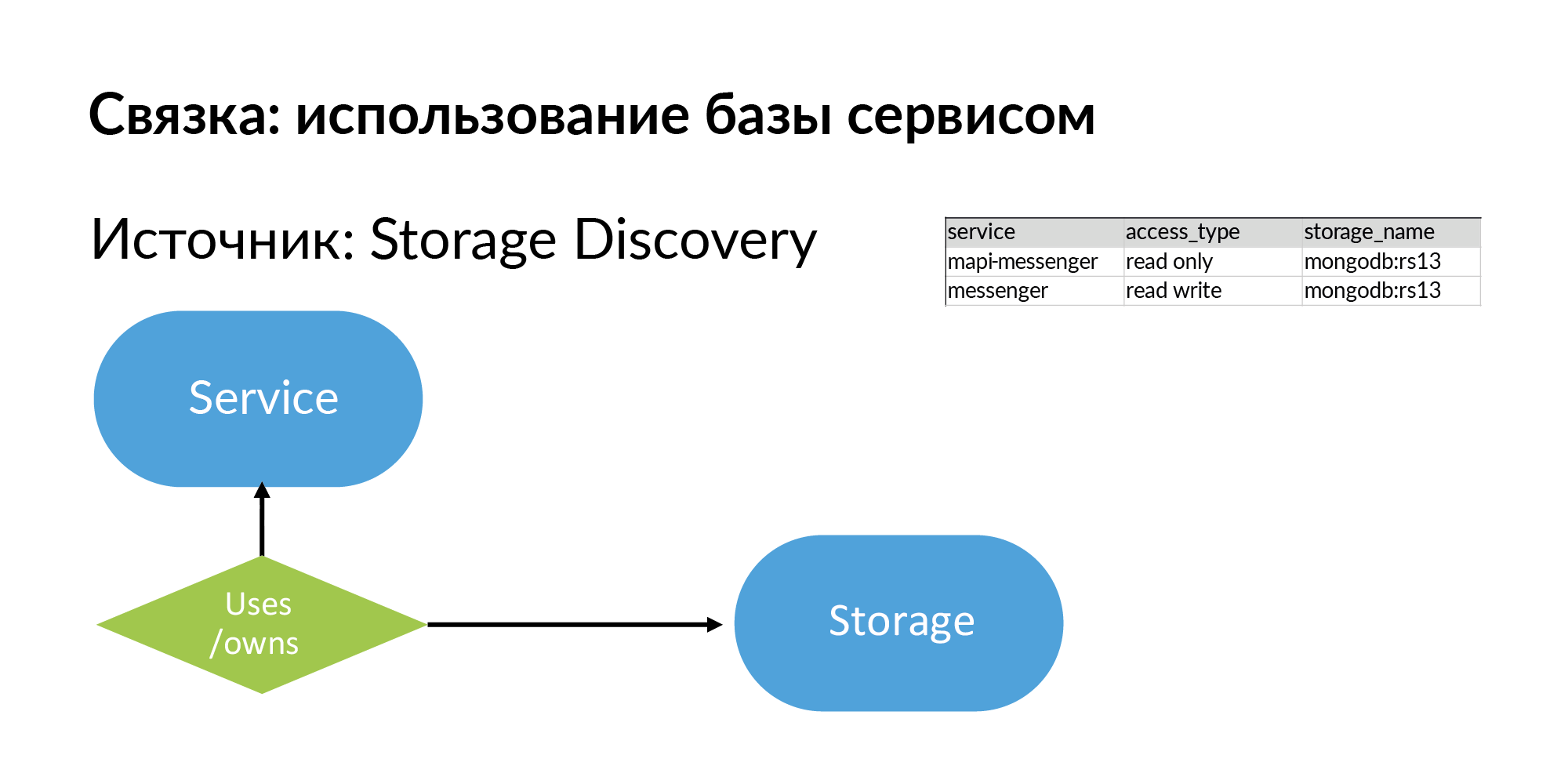
Portanto, armazena e informações sobre o que o serviço usa, bem ou possui (esses são tipos diferentes) de armazenamento. Veja, tudo o que descrevi é, em princípio, bastante simples, pode ser preenchido até no Planilhas Google.
O que pode ser feito com isso? Vamos imaginar que este é um gráfico. Como trabalhar com o gráfico? Adicione-o à base do gráfico. Por exemplo, no Neo4j. Estes já são exemplos de consultas reais e exemplos dos resultados dessas consultas.
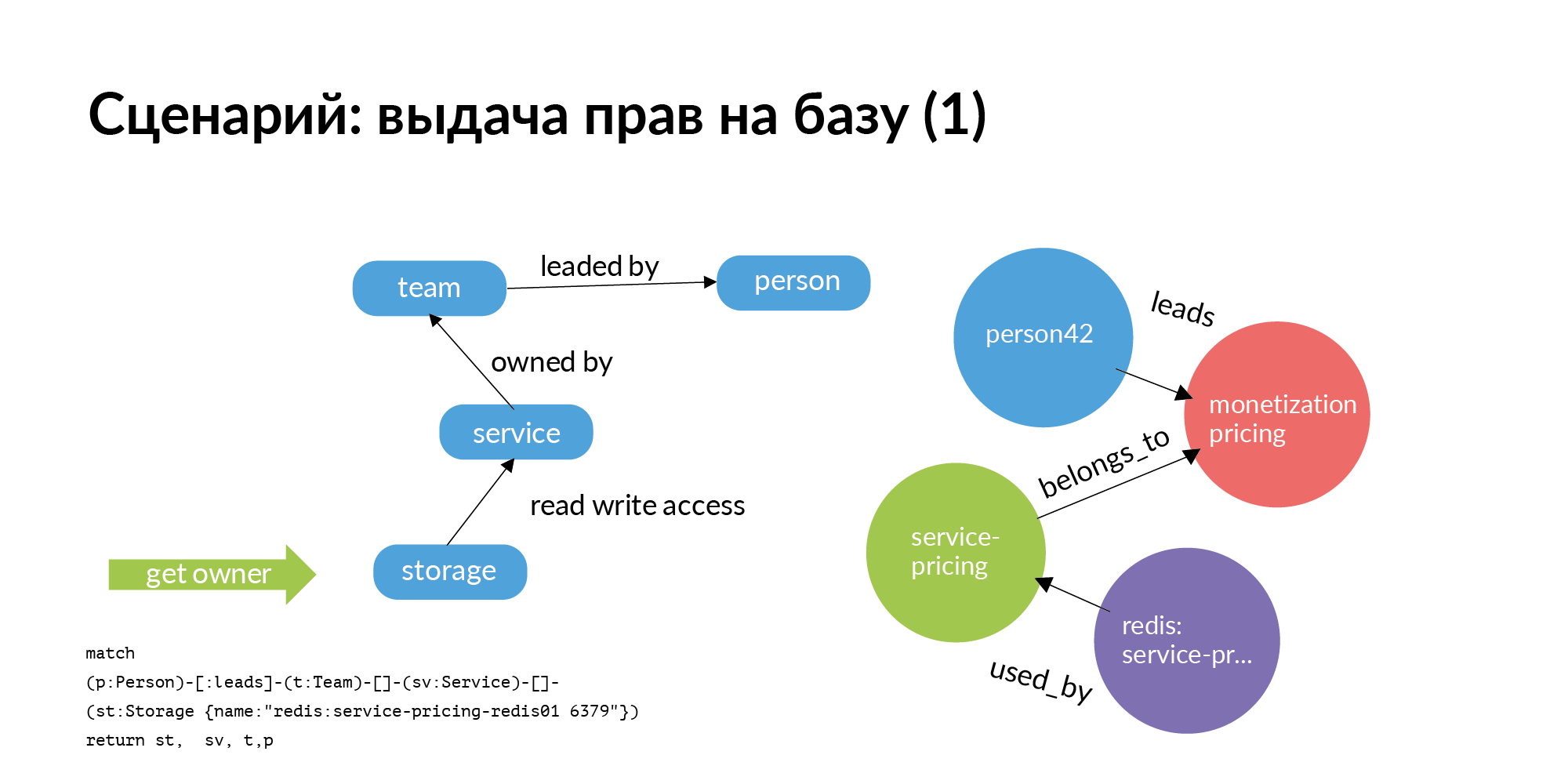
O primeiro cenário. Precisamos emitir direitos para a base. A base deve estar estritamente em serviço. Deve incluir apenas este serviço e apenas membros da equipe proprietária do serviço. Mas nós vivemos no mundo real. Muitas vezes, outras equipes acham útil ir para a base de outro serviço. Pergunta: a quem perguntar sobre a concessão de direitos? O grande problema é que centenas de bases compreendem quem está no comando. Apesar de quem o criou, parou há muito tempo ou foi transferido para outro cargo, ou não se lembra de quem trabalha com ele.
E aqui está a consulta de gráfico mais simples (Neo4j). Você precisa de acesso ao armazenamento. Você vai do armazenamento para o serviço que o possui. Vá para a equipe proprietária do serviço. Além do serviço, você descobrirá quem é essa equipe do TechLead. No Avito, as equipes de produto têm um gerente técnico e um gerente de produto que não podem ajudar nas bases. Somente metade da solicitação é realmente exibida no slide. O acesso ao armazenamento não é uma operação atômica. Para acessar o armazenamento, você precisa acessar os servidores nos quais está instalado. Esta é uma tarefa separada bastante interessante.
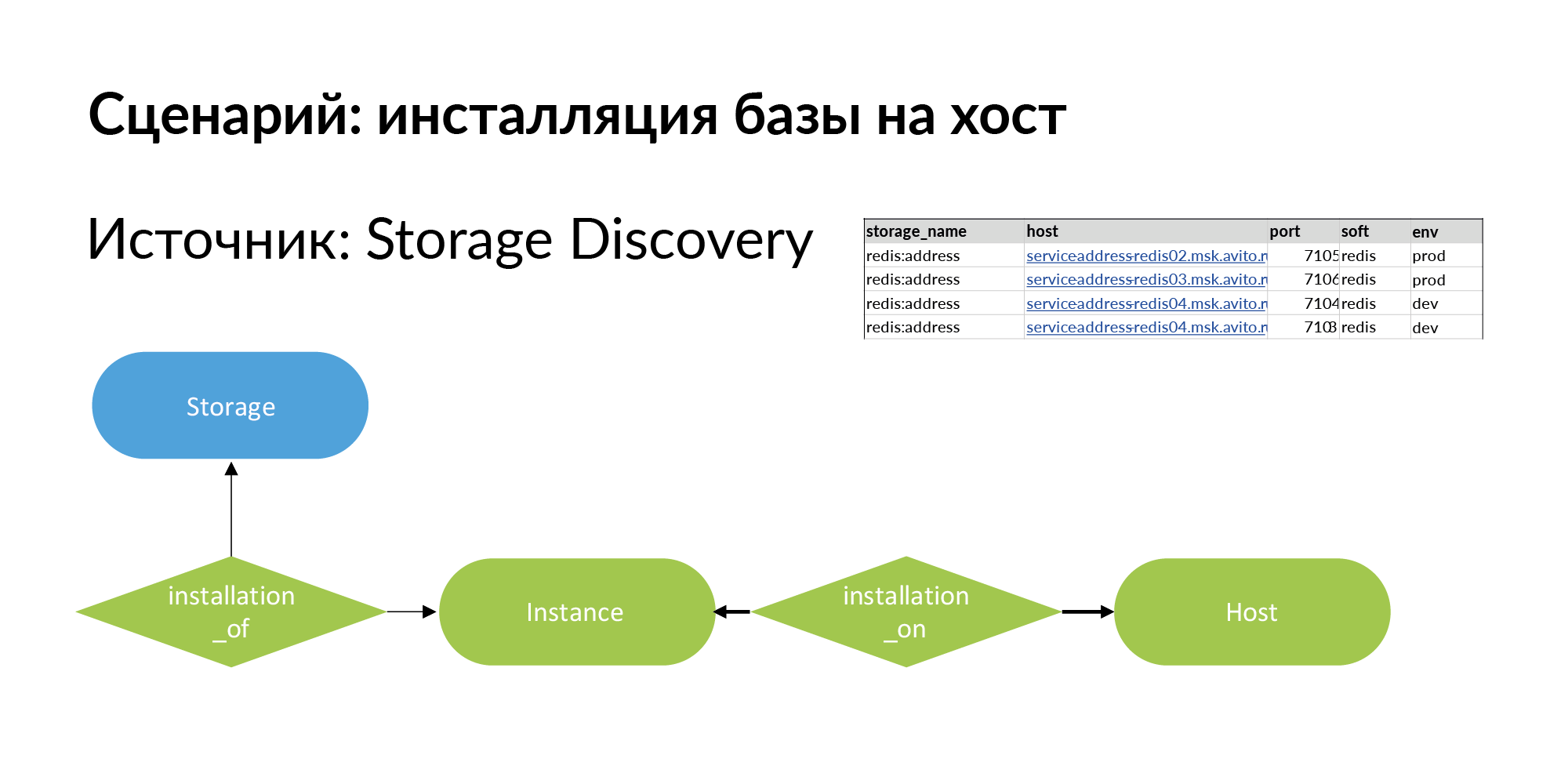
Para resolvê-lo, adicionamos uma nova entidade. Esta é uma instalação. Aqui está o problema terminológico. Há armazenamento, por exemplo, Redis base (redis: endereço). Há um host - pode ser uma máquina física, um contêiner lxc, kubernetes. Instalando o armazenamento no host que chamamos de Instância.
Pode ter quatro instalações em três hosts, conforme mostrado no exemplo acima. É recomendável que o armazenamento para produção seja instalado em máquinas físicas separadas para aumentar o desempenho. Para um ambiente de desenvolvimento, tudo o que você precisa fazer é instalar em um host e atribuir portas diferentes ao Redis.

O primeiro pedido de emissão de direitos à base foi direto ao ponto. O chefe confirmou que os direitos podem ser concedidos.
Em seguida, vem a segunda parte da solicitação. A segunda solicitação de armazenamento vai para a instância e o host. Esta solicitação considera todas as instalações para o ambiente correspondente. No slide, há um exemplo para um ambiente de produção. Com base nisso, os direitos de conexão com hosts e portas específicos já foram emitidos. Este foi um exemplo de uma solicitação de concessão para um funcionário que não faz parte da equipe.

Considere um exemplo em que uma equipe precisa contratar um novo funcionário. Ele precisa ter acesso concedido (para iniciantes - somente leitura) a todos os serviços, a todo armazenamento deste comando. No slide, a equipe real com uma seleção incompleta. Círculos verdes são líderes de equipe. Círculos cor de rosa são equipes. Amarelo são serviços. Vários serviços amarelos possuem armazenamento azul. Os cinza são anfitriões. Violeta é a instalação do armazenamento nos hosts. Este é um exemplo para uma unidade pequena. Mas existem muitas unidades cujos serviços não são 7, mas 27. Para essas unidades, a imagem será grande. Se você usar o Persistent Fabric, poderá fazer solicitações e obter respostas em uma lista.

Vamos continuar preenchendo nosso tecido inteligente e falar sobre entidades comerciais. As entidades no Avito são anúncios, usuários, pagamentos e assim por diante. Nas minhas publicações ( HP Vertica, projetando um data warehouse, big data , Vertica + Anchor Modeling = comece a cultivar seu cogumelo ) sobre data warehouses, você sabe que existem centenas dessas entidades no Avito. De fato, todos eles não precisam ser registrados. De onde posso obter uma lista de entidades? Do repositório analítico. Você pode enviar informações sobre de onde elas obtêm essa entidade. No primeiro estágio, isso é suficiente.
Além disso, desenvolvemos esse conhecimento: para cada entidade, fazemos uma lista de repositórios onde está. Também indicamos que o armazenamento armazena a entidade como um cache ou o armazenamento a entidade como Fonte de Ouro, ou seja, é sua fonte principal.

Ao preencher esta coluna, você tem a oportunidade de fazer solicitações. Você tem alguma entidade e precisa entender: em quais serviços a entidade vive, onde reflete, em que armazenamento, em quais hosts está instalado? Por exemplo, ao processar dados pessoais, você precisa destruir os arquivos de log. Para fazer isso, é muito importante entender em quais máquinas físicas os arquivos de log podem permanecer.
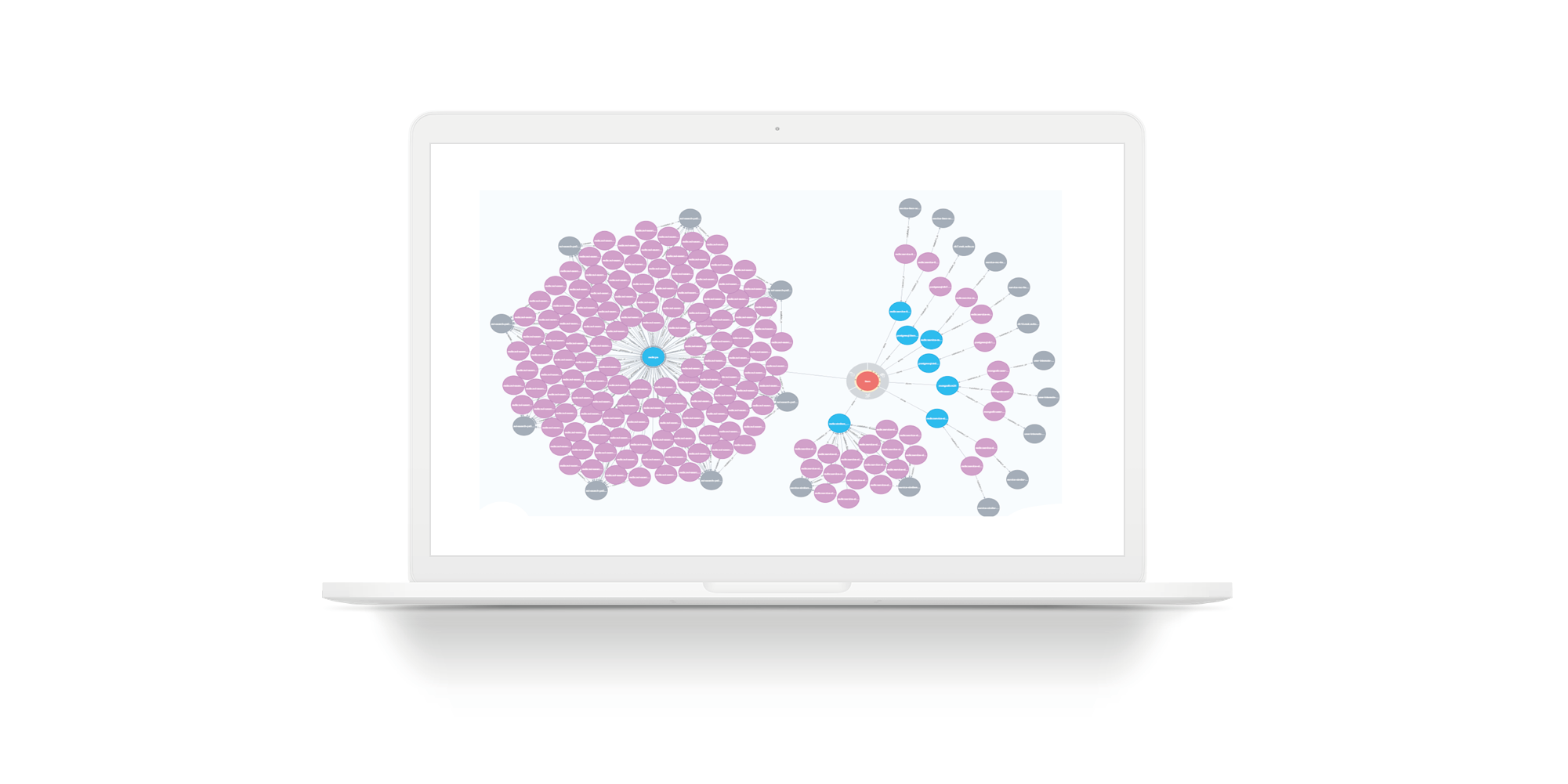
O slide ilustra uma consulta simples para uma entidade imaginária. A quantidade de armazenamento é reduzida para que o gráfico caiba no slide. Círculos vermelhos são entidades. Círculos azuis são as bases onde esta entidade está localizada. O restante é como nos slides anteriores: círculos cinzentos são hosts, círculos roxos são instalações de armazenamento nos hosts.
Portanto, se você deseja passar pelo PCI DSS, precisa restringir o acesso a determinadas entidades. Para fazer isso, você precisa restringir o acesso aos círculos cinzas. Se você precisar de acesso em tempo real, fechamos o acesso aos círculos roxos. Esta é uma informação estática.
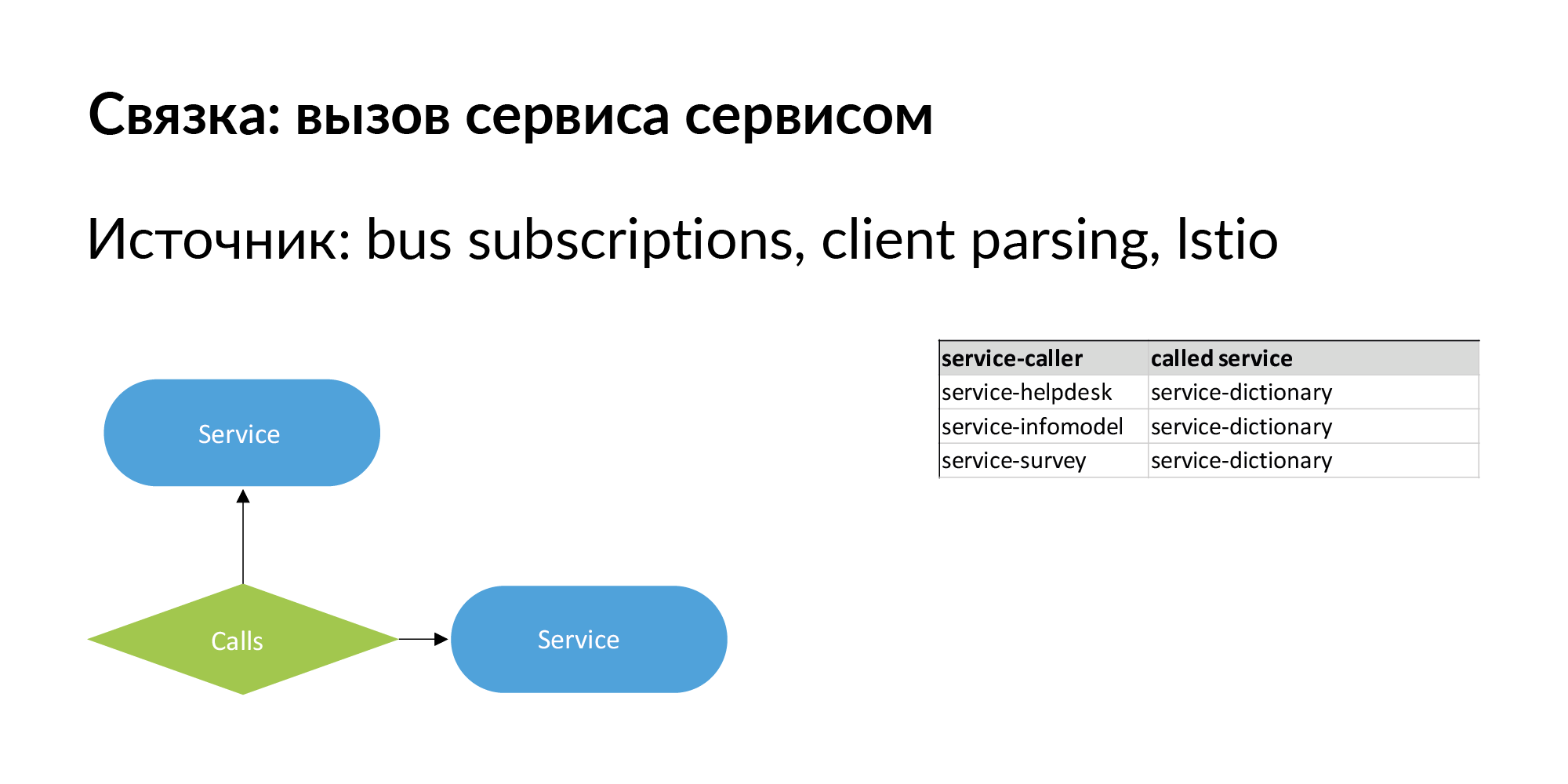
Quando falamos sobre arquitetura de microsserviço, o mais importante é que ela muda. É importante ter não apenas um relacionamento hierárquico entre entidades, mas também relacionamentos entre irmãos. Um monte de serviços é um exemplo de conexões de nível único, que foram bem-sucedidas e usadas. Um pacote configurável do formulário "serviço chama serviço". Há informações sobre chamadas diretas - o serviço chama a API de outro serviço.
Também deve haver informações sobre a conexão do formulário: o serviço nº 1 envia eventos para o barramento (fila) e o serviço nº 2 é inscrito neste evento. É como uma conexão lenta assíncrona passando por um barramento. Esse relacionamento também é importante em termos de movimentação de dados. Usando esses links, você pode verificar a operação dos serviços se a versão do serviço ao qual eles estão inscritos foi alterada.
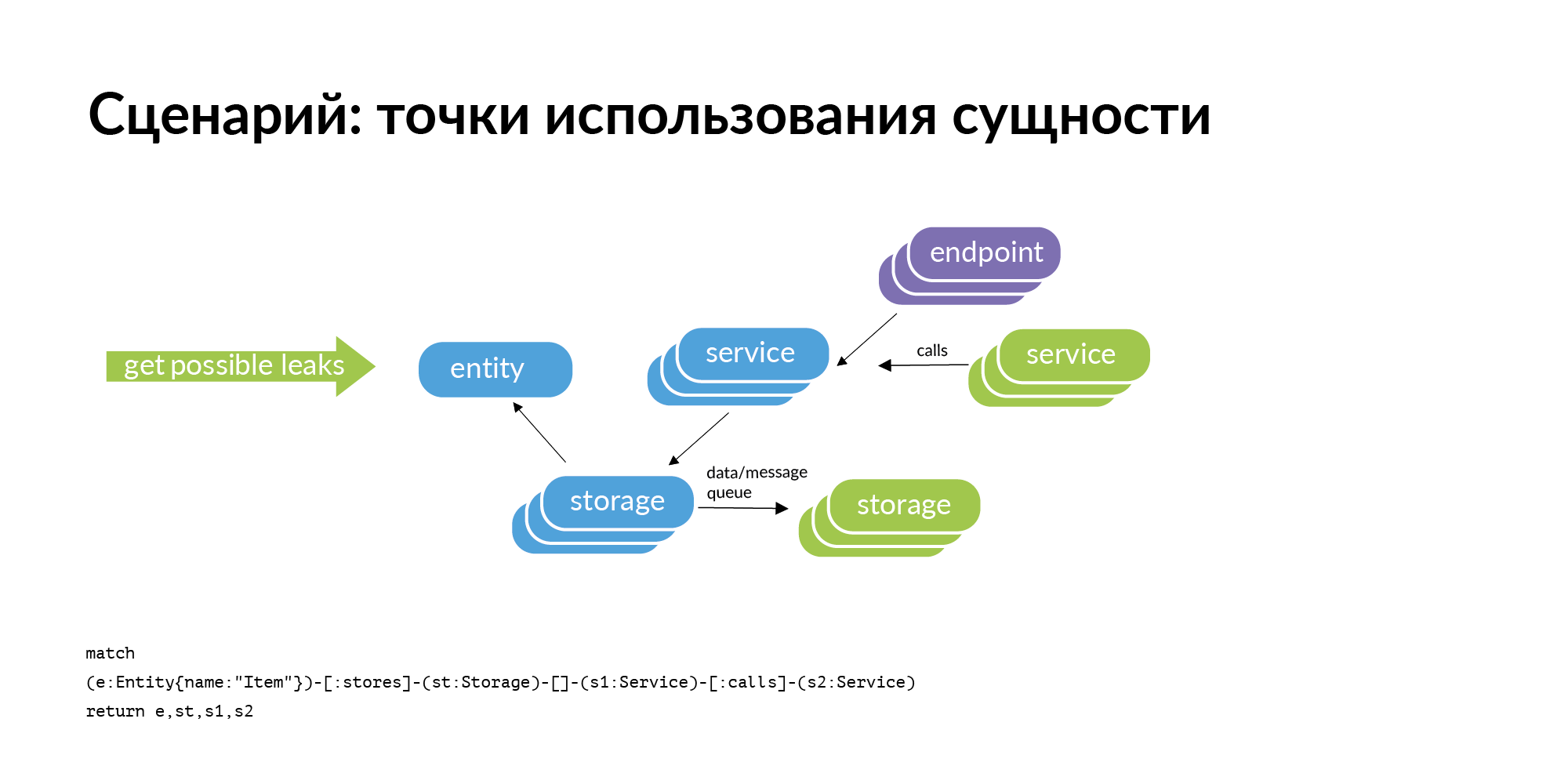
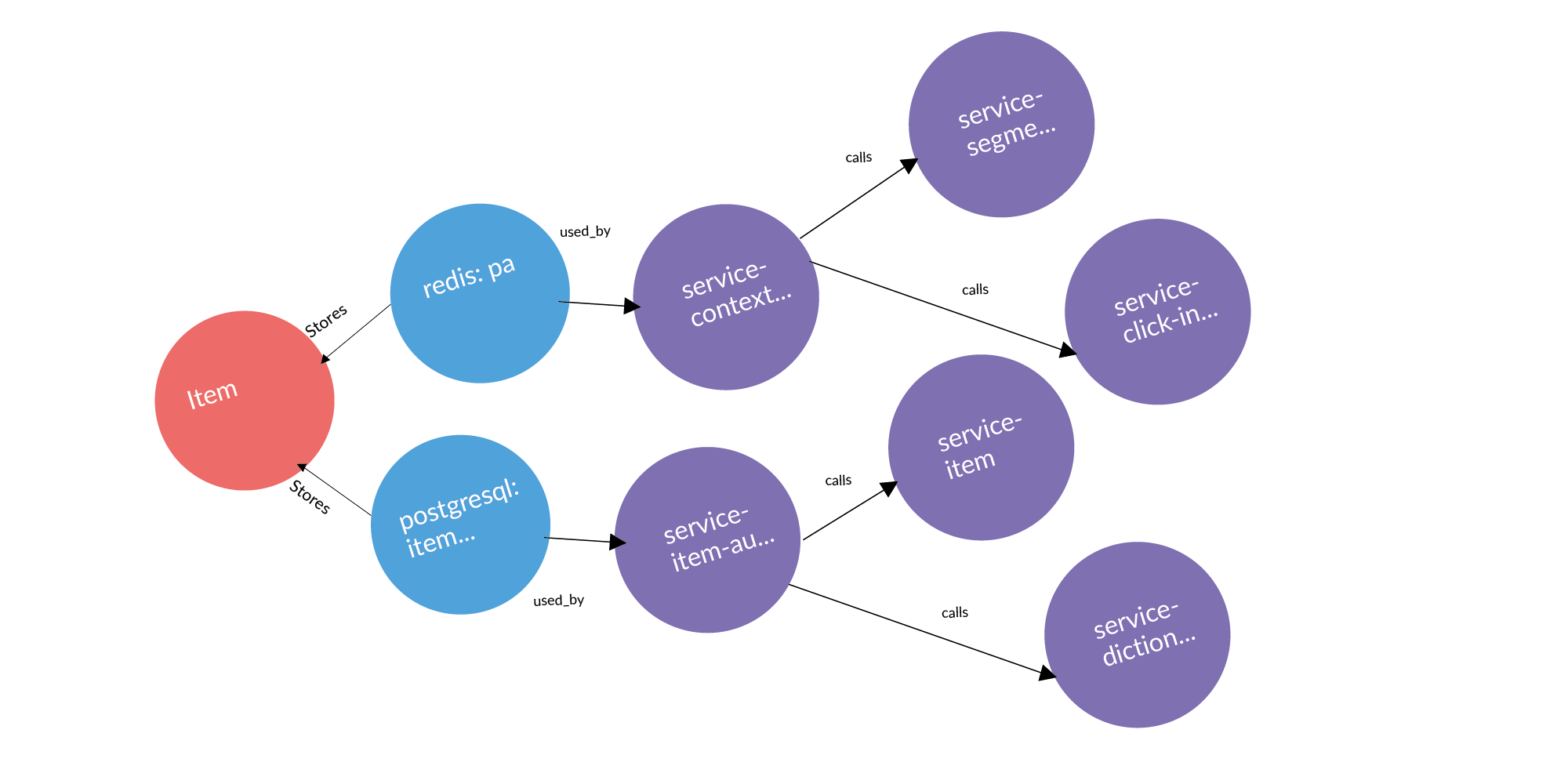
Existe uma entidade e sabemos que ela é armazenada em determinado armazenamento. Se considerarmos o problema de encontrar pontos de uso da entidade, a consulta óbvia que surge conosco é a verificação do perímetro. O armazenamento pertence a alguns serviços. Onde essa entidade pode vazar (ser copiada) do perímetro? Pode vazar através de chamadas de serviço. O serviço contatou, recebeu e manteve o usuário. Pode vazar pelos pneus. Os pneus podem conectar você usando o RabbitMQ, Londiste. No slide de Londiste, ainda não o carregamos. Mas as chamadas já estão carregadas.
Aqui está um exemplo de uma solicitação real: um anúncio, dois bancos de dados onde ele está armazenado, dois serviços que possuem esses bancos de dados. Após três colunas, existem serviços que funcionam com serviços que possuem essa entidade. Esses são pontos de vazamento em potencial que vale a pena acrescentar.

Pontos finais. Vadim mencionou que você pode usar a documentação para criar um registro de serviços de terminais. Você também pode obter essas informações do monitoramento. Se o Endpoint for importante, os próprios desenvolvedores o adicionarão ao monitoramento. Se o Endpoint não for monitorado, não será necessário.
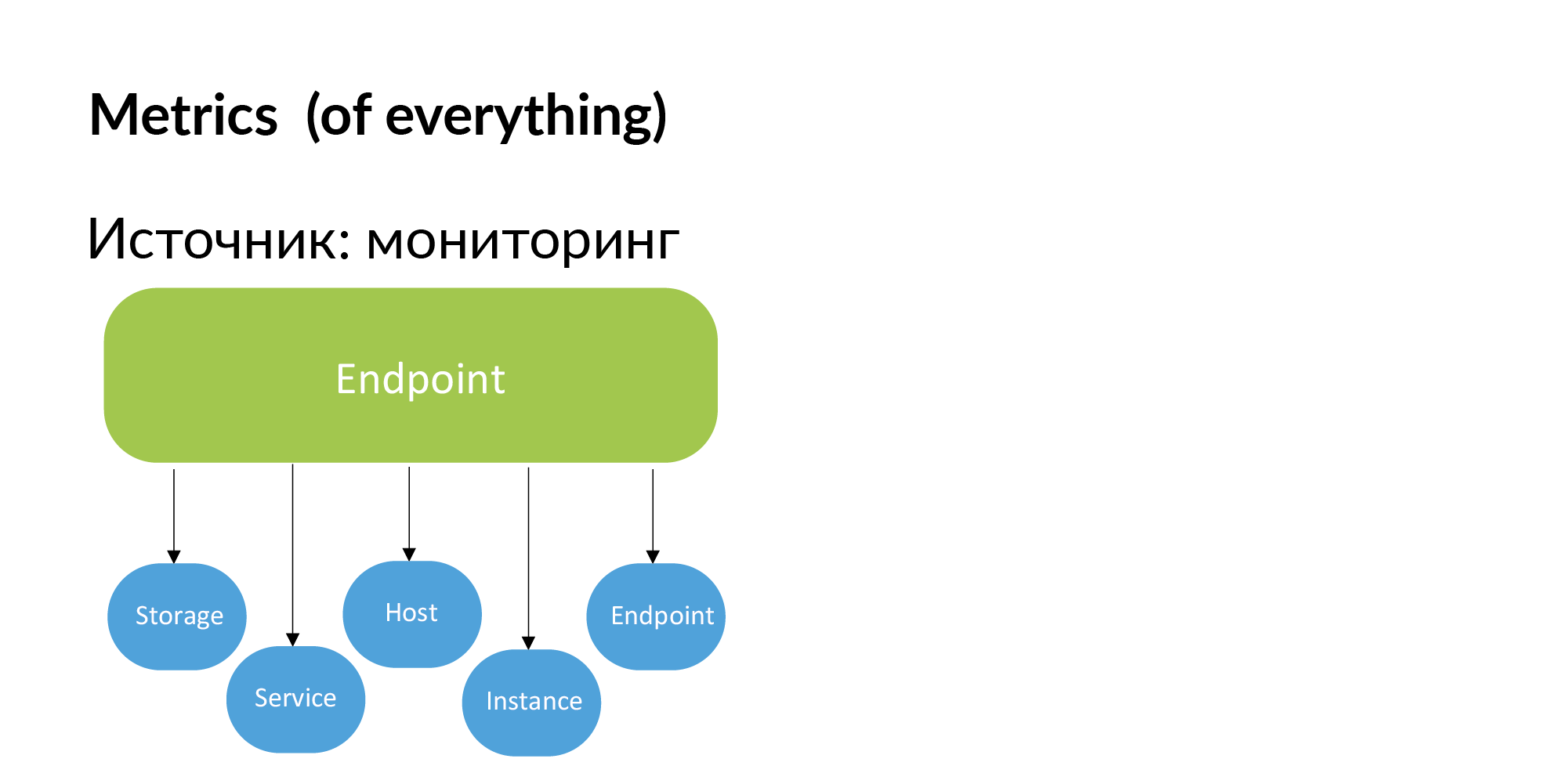
Consequentemente, as métricas podem ser obtidas no monitoramento. Vinculando métricas ao armazenamento, aos serviços, aos hosts, à instância (shards do banco de dados) e ponto final.

Quando você encontra uma falha, por exemplo, o terminal emite um código HTTP 500, para rastrear a raiz do problema, é necessário fazer uma solicitação para esse terminal. Do terminal, vá para o serviço, vá para os serviços que este serviço chama, dos serviços, vá para o armazenamento, do armazenamento, vá para a instância e os hosts.
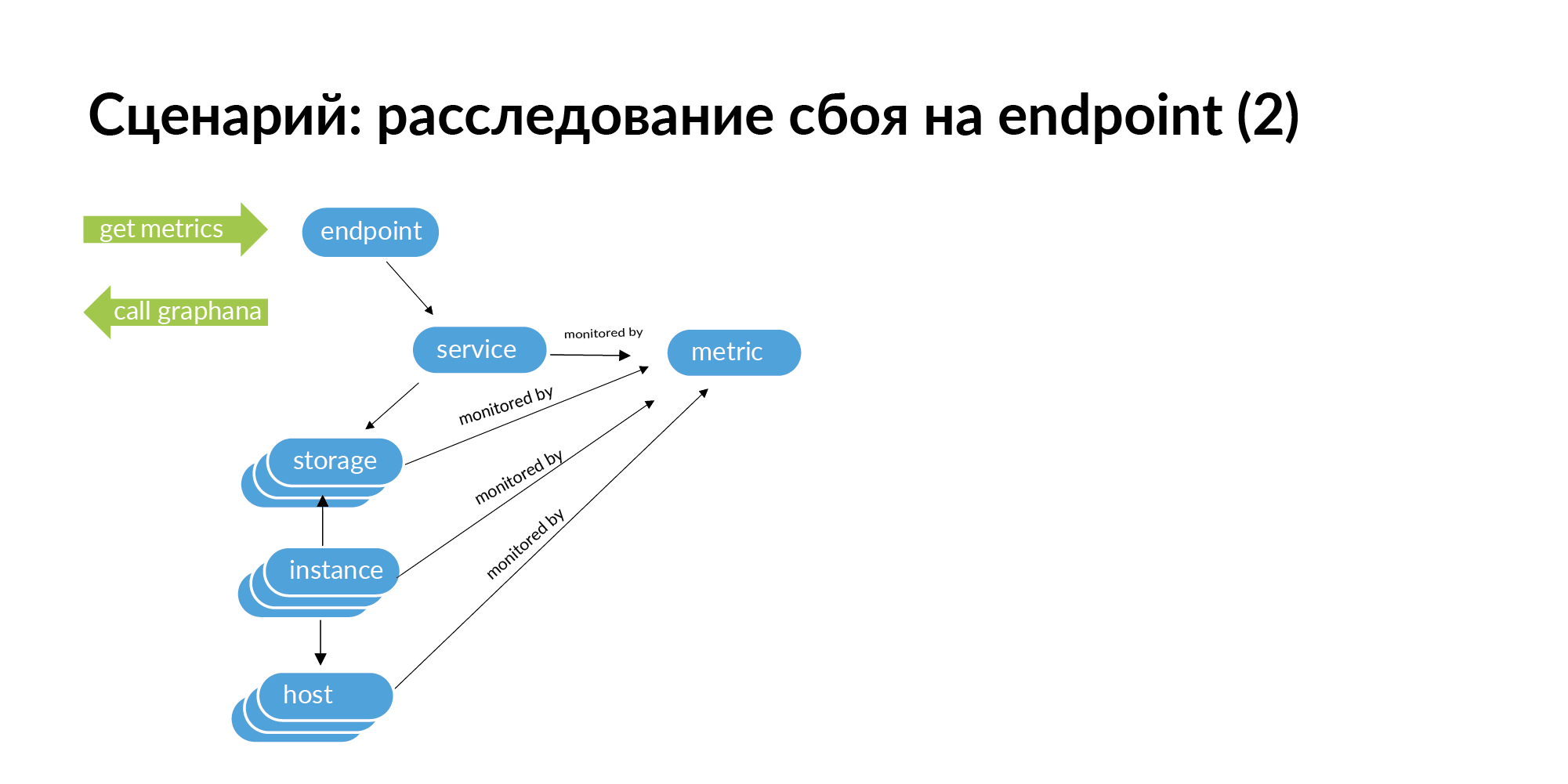
Além disso, se você observar este gráfico, poderá obter uma lista de identificadores para monitoramento. Você pode procurar por esse ponto final em toda a cadeia, o que pode causar uma falha. Na arquitetura de microsserviço, uma falha no nó de extremidade pode ser causada por uma falha de rede em algum servidor no qual um fragmento de banco de dados é implantado. Isso pode ser visto no monitoramento, mas com uma grande estrutura de serviço, é muito trabalhoso verificar todos os serviços no monitoramento.

Teste. Para testar adequadamente um microsserviço, você precisa verificar o serviço com outros serviços nos quais ele precisa funcionar. , . . . , . .
, , , production. , . — , , .
, . , . . .
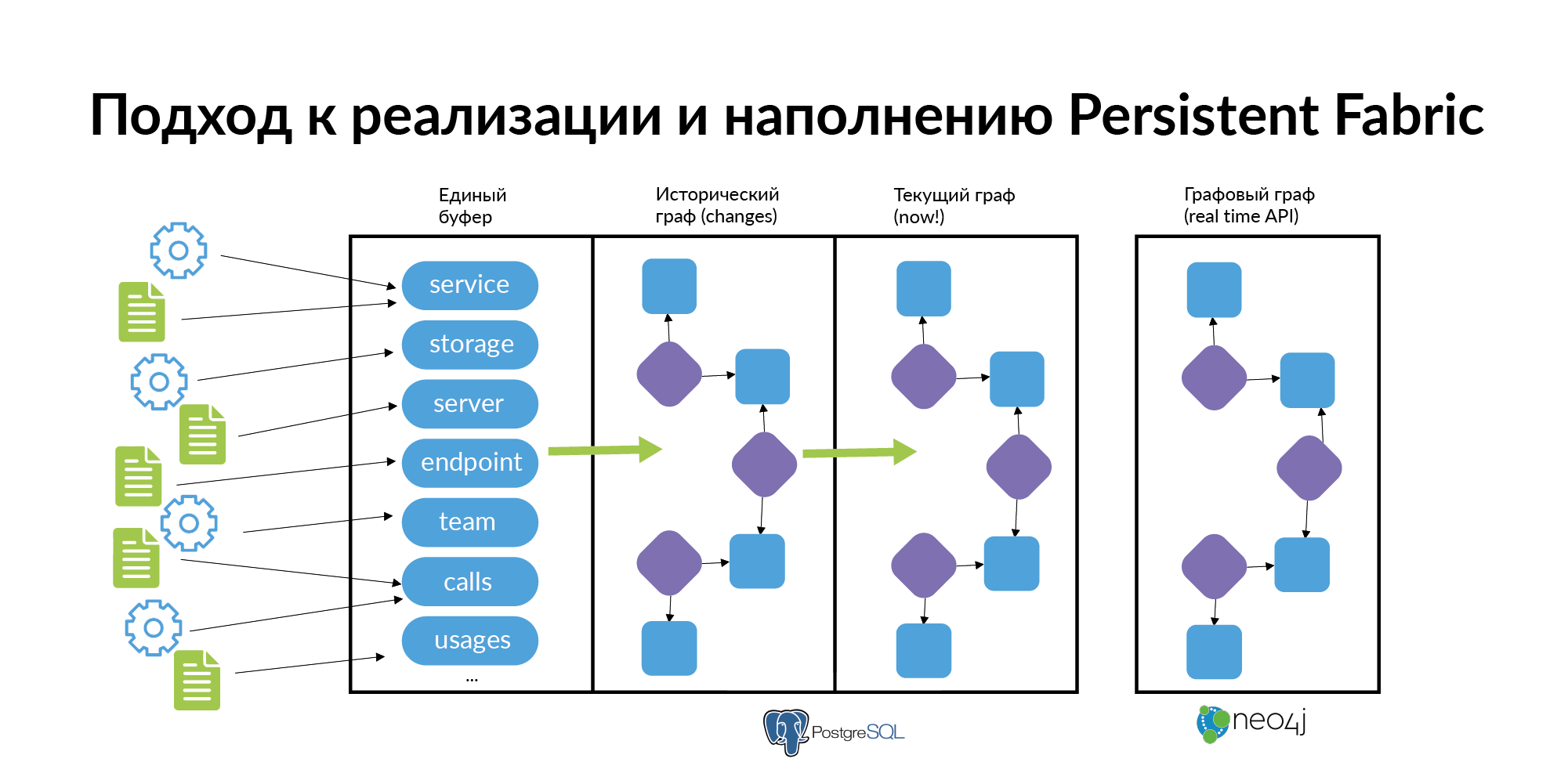
— , . .
- . . . . storage. — . endpoint. , , .. .
- . «» . , , , connection, connection , . , . ( , Anchor Modeling ). . « ». . Neo4j, .
- , . . , UI points frontend , backend , storage DBA, DevOps , .
in-progress
.
(Londiste, PGQ, RabbitMQ).
Também estamos tentando adicionar gráficos de caminhos do usuário. Os pontos de interface do usuário do gráfico de comunicação são formados nas informações sobre como os usuários andam entre eles. Agora isso é feito no nível de log do cliente. No momento, estamos migrando para combinar essas informações e encaminhar para um Fabric Persistent para que a experiência do usuário possa ser traduzida em pontos da interface do usuário, de lá para o Endpoint e de lá para os serviços. A partir dessas informações, para entender o que os usuários costumam usar e descobrir, por exemplo, por que um serviço pequeno, não muito carregado e não muito importante, afeta a experiência do usuário.