A CleverDATA está desenvolvendo uma plataforma para trabalhar com big data. Em particular, em nossa plataforma, é possível trabalhar com informações de cheques de compras on-line. Nossa tarefa era aprender a processar os dados de texto das verificações e tirar conclusões sobre os consumidores para criar as características correspondentes na troca de dados. Era natural abordar o aprendizado de máquina para resolver esse problema. Neste artigo, queremos falar sobre os problemas que encontramos na classificação de textos de verificações on-line.
FonteNossa empresa desenvolve soluções para monetização de dados. Um de nossos produtos é a troca de dados 1DMC, que permite enriquecer dados de fontes externas (mais de 9000 fontes, sua audiência diária é de cerca de 100 milhões de perfis). As tarefas que o 1DMC ajuda a resolver são bem conhecidas dos profissionais de marketing: criação de segmentos parecidos, empresas de mídia ampla, campanhas de publicidade direcionadas para um público altamente especializado etc. Se o seu comportamento estiver próximo ao do público-alvo de uma loja, é provável que você se enquadre no segmento semelhante. Se foram registradas informações sobre seu vício em qualquer área de interesse, você poderá entrar em uma campanha publicitária direcionada altamente especializada. Ao mesmo tempo, todas as leis sobre dados pessoais são implementadas, você recebe publicidade mais relevante para seus interesses e as empresas usam efetivamente seu orçamento para atrair clientes.
As informações sobre perfis são armazenadas na troca na forma de vários atributos interpretados por humanos:
Pode ser uma informação de que uma pessoa possui equipamento motorizado, por exemplo, um helicóptero. Ou que uma pessoa tenha interesse em comida de um determinado tipo, por exemplo, ela é vegetariana.
Declaração do problema e maneiras de resolvê-lo
Recentemente, o 1DMC recebeu dados de um dos operadores de dados fiscais. Para apresentá-los na forma de atributos de perfil de troca, tornou-se necessário trabalhar com os textos de verificação em forma bruta. Aqui está um texto de verificação típico para um dos clientes:
Assim, a tarefa é combinar a verificação com os atributos. Atrair o aprendizado de máquina para resolver o problema descrito, em primeiro lugar, existe o desejo de experimentar métodos de
ensino sem um professor (Aprendizado Não Supervisionado). O professor tem informações sobre as respostas corretas e, como não temos essas informações, os métodos de ensino sem um professor podem se encaixar bem no caso que está sendo resolvido. Um método típico de ensino sem professor é o agrupamento, graças ao qual a amostra de treinamento é dividida em grupos ou agrupamentos estáveis. No nosso caso, depois de agrupar os textos de acordo com as palavras, teremos que comparar os clusters resultantes com os atributos. O número de atributos exclusivos é bastante grande, portanto, era desejável evitar a marcação manual. Outra abordagem para o ensino de textos sem professor é chamada modelagem de tópicos, que permite identificar os principais tópicos em textos não colocados. Depois de usar a modelagem temática, será necessário comparar os tópicos obtidos com os atributos, que eu também queria evitar. Além disso, é possível usar a proximidade semântica entre o texto da verificação e a descrição do atributo com base em qualquer modelo de idioma. No entanto, os experimentos mostraram que a qualidade dos modelos baseados na proximidade semântica não é adequada para nossas tarefas. Do ponto de vista comercial, você precisa ter certeza de que uma pessoa gosta de jujitsu e é por isso que compra artigos esportivos. É mais lucrativo não usar conclusões intermediárias, controversas e duvidosas. Portanto, infelizmente, métodos de aprendizado não supervisionado não são adequados para a tarefa.
Se abandonarmos os métodos de aprendizado não supervisionado, é lógico recorrer aos métodos de aprendizado supervisionado e, em particular, à classificação. O professor é uma informação sobre as aulas verdadeiras, e uma abordagem típica é realizar uma classificação em várias classes, mas nesse caso a tarefa é complicada pelo fato de termos muitas aulas (pelo número de atributos únicos). Há outra característica: os atributos podem trabalhar nos mesmos textos em vários grupos, ou seja, classificação deve ser multilabel. Por exemplo, as informações de que uma pessoa comprou uma capa para um smartphone podem conter atributos como: uma pessoa que possui um dispositivo como a Samsung com um telefone Galaxy, compra os atributos de uma Deppa Sky Case e geralmente compra acessórios para telefones. Ou seja, vários atributos de uma determinada pessoa devem ser registrados no perfil de uma só vez.
Para traduzir a tarefa na categoria "treinamento com um professor", é necessário obter uma marcação. Quando as pessoas encontram esse problema, contratam assessores e, em troca de dinheiro e tempo, obtêm uma boa marcação e criam modelos preditivos a partir da marcação. Muitas vezes acontece que a marcação estava errada e os avaliadores precisam estar conectados para trabalhar regularmente, porque novos atributos e novos provedores de dados aparecem. Uma maneira alternativa é usar o Yandex. Toloki. " Permite reduzir custos para avaliadores, mas não garante qualidade.
Sempre há uma opção para encontrar uma nova abordagem, e foi decidido seguir esse caminho. Se houvesse um conjunto de textos para um atributo, seria possível construir um modelo de classificação binária. Os textos para cada atributo podem ser obtidos em consultas de pesquisa e, para a pesquisa, você pode usar a descrição de texto do atributo, que está na taxonomia. Nesse estágio, encontramos o seguinte recurso: os textos de saída não são tão diversos que constroem um modelo forte a partir deles, e faz sentido recorrer ao aumento de texto para obter uma variedade de textos.
Aumento de Texto
Para aumento de texto, é lógico usar o modelo de linguagem. O resultado do trabalho do modelo de linguagem é a incorporação - este é um mapeamento do espaço de palavras para o espaço de vetores de um comprimento fixo específico, e os vetores correspondentes a palavras com significado próximo serão localizados um no lado do outro no novo espaço e distantes. Para a tarefa de aumento de texto, essa propriedade é a chave, pois nesse caso é necessário procurar sinônimos. Para um conjunto aleatório de palavras no nome de um atributo de taxonomia, amostramos um subconjunto aleatório de elementos semelhantes no espaço de representação de texto.
Vejamos o aumento com um exemplo. Uma pessoa tem interesse no gênero místico do cinema. Amostramos a amostra, obtemos um conjunto diversificado de textos que podem ser enviados ao rastreador e coletamos os resultados da pesquisa. Esta será uma amostra positiva para o treinamento do classificador.
E selecionamos a amostra negativa mais facilmente, o mesmo número de atributos que não estão relacionados ao tema do filme:
Modelo de treinamento
Ao usar a abordagem TF-IDF (por exemplo,
aqui ) com um filtro por frequências e regressão logística, você já pode obter excelentes resultados: inicialmente textos muito diferentes foram enviados ao rastreador e o modelo lida bem. Obviamente, é necessário verificar a operação do modelo em dados reais, abaixo apresentamos o resultado da operação do modelo de acordo com o atributo "interesse em comprar equipamentos AEG".
Cada linha contém as palavras AEG, o modelo enfrentado sem falsos positivos. No entanto, se considerarmos um caso mais complicado, por exemplo, um carro GAZ, encontraremos um problema: o modelo se concentra em palavras-chave e não usa o contexto.
Tratamento de erros
Vamos construir um modelo de interesse em educação continuada - cursos de reciclagem profissional.
O curso de lições de mágica para um gato comum também é um caso difícil, que pode ser enganoso para uma pessoa.
Para filtrar os falsos positivos, usamos incorporação: calculamos o centro da amostra positiva no espaço de incorporação e medimos a distância para cada linha.
A diferença de distância para os cursos de aulas de mágica e a aquisição de resumos é visível a olho nu.
Outro exemplo: proprietários da marca Audi. A distância no espaço dos casamentos, nesse caso, também salva de falsos positivos.
Problema de escalabilidade
Até o momento, a troca de dados opera cerca de 30 mil atributos, e novos aparecem regularmente. A necessidade de automação do treinamento de novos modelos e marcação com novos atributos é bastante óbvia. A sequência de etapas para construir um modelo de um novo atributo é a seguinte:
- pegue o nome do atributo da taxonomia;
- crie uma lista de consultas para o mecanismo de pesquisa usando aumento de texto;
- seleção de texto kraulim;
- treinamos o modelo de classificação na amostra obtida;
- digamos, um modelo treinado de dados brutos de compra;
- filtre o resultado com word2vec no centro da classe positiva.
Há vários pontos fracos no algoritmo descrito acima:
- é difícil controlar o corpus de textos que está agachado
- difícil controlar a qualidade da amostra de treinamento;
- não há como determinar se um modelo bem treinado está realizando seu trabalho.
É importante entender que as métricas clássicas não são adequadas para o controle de qualidade de um modelo treinado, porque falta de informações sobre classes verdadeiras nos textos de verificação. O aprendizado e a previsão ocorrem em dados diferentes, a qualidade do modelo pode ser medida em uma amostra de treinamento e não há marcação no corpo dos textos principais, o que significa que você não pode usar os métodos usuais para avaliar a qualidade.
Modelo de avaliação da qualidade
Para avaliar a qualidade do modelo treinado, tomamos duas populações: uma se refere a objetos abaixo do limiar da resposta do modelo, a segunda se refere a objetos nos quais o modelo foi avaliado acima do limiar.
Para cada uma das populações, calculamos a distância word2vec ao centro da amostra de treinamento positivo. Temos duas distribuições de distância que se parecem com isso.
A cor vermelha indica a distribuição das distâncias para objetos que ultrapassaram o limite e azul indica objetos abaixo do limite, de acordo com a avaliação do modelo. As distribuições podem ser divididas e, para estimar a distância entre distribuições, é lógico, antes de tudo, referir-se à Dullgence Kullback-Leibler (DKL). Uma DCL é uma funcionalidade assimétrica; a desigualdade do triângulo não é satisfeita nela. Essa restrição complica o uso do DCL como uma métrica, mas pode ser usada se refletir a dependência necessária. No nosso caso, o DCL assumiu valores constantes em todos os modelos, independentemente dos valores limite, tornando-se necessário procurar outros métodos.
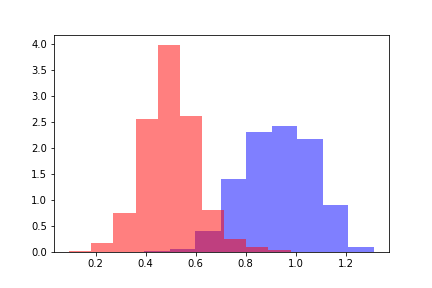
Para estimar as distâncias entre distribuições, calculamos a diferença entre os valores médios das distribuições. A diferença resultante é mensurável nos desvios padrão da distribuição inicial de distâncias. Indique o valor obtido pela métrica Z por analogia com o valor Z, e o valor da métrica Z será uma função do valor limite do modelo preditivo. Para cada limite fixo do modelo, a função métrica Z retorna a diferença entre as distribuições em sigma da distribuição de distância inicial.
Das muitas abordagens testadas, foi a métrica Z que deu a dependência necessária para determinar a qualidade do modelo construído.
Considere o comportamento da métrica Z: quanto maior a métrica Z, melhor o modelo lidou, porque quanto maior a distância entre as distribuições, caracteriza a classificação qualitativa. No entanto, uma regra de decisão claramente definida para determinar a classificação qualitativa não pôde ser derivada. Por exemplo, um modelo com uma métrica Z no canto inferior esquerdo da figura obtém um valor constante igual a 10. Esse modelo determina o interesse em viajar para a Tailândia. A amostra de treinamento foi predominantemente anunciada por vários spas e o modelo foi treinado em textos que não estavam diretamente relacionados a viagens à Tailândia. Ou seja, o modelo funcionou bem, mas não reflete o interesse em viagens à Tailândia.
Z-metic para vários modelos preditivos. Os modelos na metade direita da imagem são bons e os cinco na metade esquerda são ruins.Durante pesquisas e experimentos, 160 modelos com marcação de acordo com o critério “bom / ruim” foram acumulados. Com base nos sinais da métrica z, foi construído um metamodelo baseado no aumento de gradiente que determina a qualidade do modelo construído. Dessa forma, foi possível configurar o monitoramento da qualidade dos modelos construídos no modo automático.
Sumário
No momento, a sequência de ações é a seguinte:
- pegue o nome do atributo da taxonomia;
- crie uma lista de consultas para o mecanismo de pesquisa usando aumento de texto;
- seleção de texto kraulim;
- treinamos o modelo de classificação na amostra obtida;
- digamos, um modelo treinado de dados brutos de compra;
- filtramos o resultado com word2vec a distância do centro da classe positiva;
- calculamos a métrica Z e construímos sinais para o metamodelo;
- usamos um metamodelo e avaliamos a qualidade do modelo resultante;
- se o modelo é de qualidade aceitável, é adicionado ao conjunto de modelos usado. Caso contrário, o modelo retornará para revisão.
De acordo com a avaliação do metamodelo no modo automático, é tomada uma decisão para introduzir na produção ou retornar para revisão. O refinamento é possível de várias maneiras que foram derivadas para o analista.
- Muitas vezes, os modelos atrapalham certas palavras que têm vários significados. Uma lista negra de palavras enganosas facilita o trabalho do modelo.
- Outra abordagem é criar uma regra para excluir objetos do conjunto de treinamento. Essa abordagem ajuda se o primeiro método não funcionar.
- Para textos complexos e atributos com vários valores, um dicionário específico é transferido para o modelo, o que limita o modelo, mas permite controlar erros.
Mas e as redes neurais?
Antes de tudo, havia um desejo de usar redes neurais para a tarefa descrita. Por exemplo, é possível treinar o Transformer em um grande corpo de textos e, em seguida, fazer o Learning Transfer em um conjunto de pequenas amostras de treinamento de cada atributo. Infelizmente, o uso de uma rede neural teve que ser abandonado pelos seguintes motivos.
- Se o modelo para um atributo parar de funcionar corretamente, será necessário desativá-lo sem perda para os atributos restantes.
- Se o modelo não funcionar bem para um atributo, será necessário ajustar e ajustar o modelo isoladamente, sem risco de prejudicar o resultado para outros atributos.
- Quando um novo atributo aparece, é necessário obter um modelo para ele o mais rápido possível, sem treinamento a longo prazo de todos os modelos (ou um modelo grande).
- Resolver o problema de controle de qualidade de um atributo é mais rápido e fácil do que resolver o problema de controle de qualidade de todos os atributos de uma só vez. Se um modelo grande não lidar com um dos atributos, você precisará ajustar e refinar todo o modelo grande, o que exige mais tempo e atenção especializada.
Assim, um conjunto de pequenos modelos independentes para resolver o problema acabou sendo mais prático do que um modelo grande e complexo. Além disso, o modelo de linguagem e os embeddings ainda são usados para controle de qualidade e aumento de texto; portanto, não foi possível evitar completamente o uso de redes neurais, e não havia esse objetivo. O uso de redes neurais é limitado às tarefas em que são necessárias.
Para ser continuado
O trabalho no projeto continua: é necessário organizar o monitoramento, atualizar modelos, trabalhar com anomalias etc. Uma das áreas prioritárias para desenvolvimento adicional é a tarefa de coletar e analisar os casos que não foram classificados por nenhum modelo do conjunto. No entanto, já vemos os resultados do nosso trabalho: cerca de 60% das verificações após a aplicação dos modelos recebem seus atributos. Obviamente, há uma proporção significativa de verificações que não carregam informações sobre os interesses dos proprietários, portanto, um nível de propriedade total é inatingível. No entanto, é encorajador que o resultado obtido até o momento já ultrapasse nossas expectativas e continuemos a trabalhar nessa direção.
Este artigo foi co-escrito com
samy1010 .
E trabalhos tradicionais!