A idéia do artigo nasceu espontaneamente de uma discussão nos comentários do artigo
“Algo sobre o inode” .
O fato é que as especificidades internas de nossos serviços são o armazenamento de um grande número de arquivos pequenos. No momento, temos cerca de centenas de terabytes desses dados. E nos deparamos com alguns óbvios e não muito ancinhos, e caminhamos com sucesso sobre eles.
Portanto, compartilho nossa experiência, talvez alguém venha a calhar.
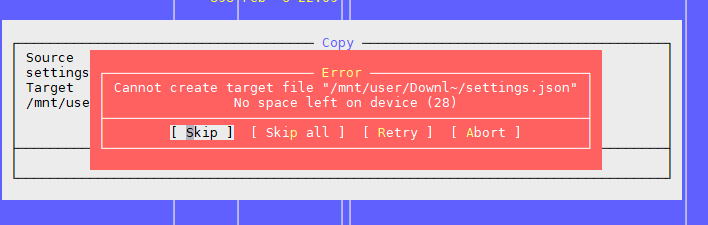
Problema 1: "Não resta espaço no dispositivo"
Como mencionado no artigo acima, o problema é que existem blocos livres no sistema de arquivos, mas o inode acabou.
Você pode verificar o número de inodes usados e livres com o
df -ih :
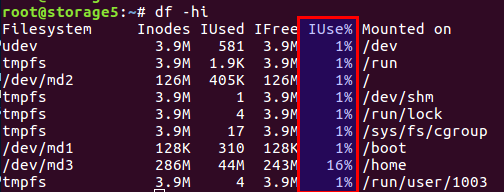
Não vou recontar o artigo, enfim, existem dois blocos de dados diretamente no disco e blocos de meta-informações, eles também são inodes (nó de índice). Seu número é definido durante a inicialização do sistema de arquivos (estamos falando sobre ext2 e seus descendentes) e não muda mais. O saldo de blocos de dados e inodes é calculado a partir dos dados médios; no nosso caso, quando existem muitos arquivos pequenos, o saldo deve mudar para o número de inodes - deve haver mais deles.
O Linux já forneceu opções com diferentes saldos, e todas essas configurações pré-calculadas estão no arquivo
/etc/mke2fs.conf .
Portanto, durante a inicialização inicial do sistema de arquivos por meio do mke2fs, é possível especificar o perfil desejado.
Aqui estão alguns exemplos do arquivo:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
Você pode selecionar o caso de uso desejado com a opção -T ao chamar mke2fs. Você também pode definir manualmente os parâmetros necessários se não houver uma solução pronta.
Mais detalhes são descritos nos manuais para
mke2fs.conf e
mke2fs .
Um recurso não mencionado no artigo mencionado acima - você pode definir o tamanho do bloco de dados. Obviamente, para arquivos grandes, faz sentido ter um tamanho de bloco maior, para arquivos pequenos - em um menor.
No entanto, vale a pena considerar um recurso tão interessante quanto a arquitetura do processador.
Certa vez, pensei que precisava de um tamanho de bloco maior para arquivos de fotos grandes. Estava em casa, no nome do arquivo inicial WD na arquitetura ARM. Sem hesitar, defino o tamanho do bloco como 8k ou 16k em vez do padrão 4k, tendo medido previamente a economia. E tudo foi maravilhoso exatamente até o momento em que o armazenamento em si não falhou, enquanto o disco estava ativo. Depois de colocar o disco em um computador comum com um processador Intel comum, tive uma surpresa: tamanho de bloco não suportado. Navegou. Há dados, está tudo bem, mas impossível de ler. Os processadores i386 e similares não sabem como trabalhar com tamanhos de bloco que não correspondem ao tamanho da página de memória, mas são exatamente 4k. Em geral, o caso terminou com o uso de utilitários do espaço do usuário, tudo ficou lento e triste, mas os dados foram salvos. Quem se importa -
fuseext2 no google o nome do utilitário
fuseext2 . Moral: ou pense com antecedência em todos os casos ou não construa um super-herói e use as configurações padrão para donas de casa.
UPD De acordo com a observação do usuário,
berez esclarece que para i386 o tamanho do bloco não deve exceder 4k, mas não precisa ser exatamente 4k, ou seja, 1k e 2k válidos.
Então, como resolvemos os problemas.
Primeiro, encontramos um problema quando um disco com vários terabytes estava cheio de dados e não foi possível refazer a configuração do sistema de arquivos.
Em segundo lugar, a decisão foi urgente.
Como resultado, chegamos à conclusão de que precisamos alterar o saldo reduzindo o número de arquivos.
Para reduzir o número de arquivos, foi decidido colocar os arquivos em um arquivo comum. Considerando nossas especificidades, colocamos todos os arquivos em um archive por um determinado período de tempo e arquivamos a tarefa cron diariamente à noite.
Selecionou um arquivo zip. Nos comentários ao artigo anterior, o tar foi proposto, mas há uma complicação: ele não possui um índice e os arquivos são encadeados (por um motivo, "tar" é uma abreviação de "Tape Archive", um legado de unidades de fita), ou seja, . se você precisar ler o arquivo no final do arquivo morto, precisará ler todo o arquivo morto, pois não há deslocamentos para cada arquivo em relação ao início do arquivo morto. E, portanto, é uma operação longa. No zip, tudo é muito melhor: possui o mesmo índice e compensações de arquivos dentro do arquivo morto, e o tempo de acesso a cada arquivo não depende de sua localização. Bem, no nosso caso, foi possível definir a opção de compactação como "0", porque todos os arquivos já haviam sido compactados no gzip anteriormente.
Os clientes passam os arquivos pelo nginx e, de acordo com a API antiga, apenas o nome do arquivo é especificado, por exemplo, assim:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
Para descompactar arquivos em tempo real, encontramos e conectamos o módulo nginx-unzip-module (
https://github.com/youzee/nginx-unzip-module ) e configuramos dois upstream.
O resultado é esta configuração:

Dois hosts nas configurações ficaram assim:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
E a configuração upstream no nginx upstream:
upstream storage { server server.com:8081; server server.com:8082; }
Como funciona:
- O cliente vai para a frente nginx
- O nginx frontal tenta fornecer o arquivo do primeiro upstream, ou seja, diretamente do sistema de arquivos
- Se não houver arquivo, ele tenta fornecê-lo a partir do segundo upstream, que tenta encontrar o arquivo dentro do arquivo morto.
O segundo problema: novamente, "Não resta espaço no dispositivo"
Esse é o segundo problema que encontramos quando há muitos arquivos no diretório.
Estamos tentando criar um arquivo, o sistema jura que não há espaço. Mude o nome do arquivo e tente criá-lo novamente.
Acontece.
Parece algo como isto:

A verificação de inodes não deu nada - há muitos deles gratuitos.
Verificar o local é o mesmo.
Pensamos que poderia haver muitos arquivos no diretório, mas há um limite para isso, mas novamente não: Número máximo de arquivos por diretório: ~ 1,3 × 10 ^ 20
Sim, e você pode criar um arquivo se alterar o nome.
A conclusão é um problema no nome do arquivo.
Pesquisas posteriores mostraram que o problema está no algoritmo de hash ao construir o índice de diretório. Com um grande número de arquivos, há colisões com todas as conseqüências resultantes. Mais detalhes podem ser encontrados aqui:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_DirectoriesVocê pode desativar esta opção, mas ... procurar um arquivo por nome pode se tornar imprevisivelmente longo ao classificar todos os arquivos.
tune2fs -O "^dir_index" /dev/sdb3
Em geral, como uma solução alternativa pode funcionar.
Moral: muitos arquivos em um diretório geralmente são ruins. Isto não é necessário.
Geralmente, nesses casos, eles criam subdiretórios, pelas primeiras letras do nome do arquivo ou por alguns outros parâmetros, por exemplo, por datas, na maioria dos casos, isso salva.
Mas o número total de arquivos pequenos ainda é ruim, mesmo que sejam divididos em diretórios - e veja o primeiro problema.
O terceiro problema: como ver a lista de arquivos, se houver muitos deles
Em nossa situação, quando temos muitos arquivos, de uma forma ou de outra, nos deparamos com o problema de como visualizar o conteúdo do diretório.
A solução padrão é o
ls .
Ok, vamos ver o que acontece nos arquivos 4772098:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 segundos ... será demais. E na maioria das vezes leva para processar arquivos no espaço do usuário, e não no kernel.
Mas existe uma solução:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 segundos 10 vezes mais rápido.
Viva!
UPDUma solução ainda mais rápida do usuário
berez é desativar a classificação
ls time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
O quarto problema: LA grande ao trabalhar com arquivos
Periodicamente, surge uma situação em que você precisa copiar um monte de arquivos de uma máquina para outra. Ao mesmo tempo, o LA geralmente cresce de maneira irrealista, porque tudo depende do desempenho dos próprios discos.
A coisa mais razoável que você deseja é usar um SSD. Muito legal. A única questão é o custo dos SSDs com vários terabytes.
Mas se os discos forem comuns, você precisará copiar os arquivos, e este também é um sistema de produção, em que a sobrecarga leva a exclamações insatisfeitas dos clientes? Existem pelo menos duas ferramentas úteis:
nice e
ionice .
nice - reduz a prioridade do processo, respectivamente, o sheduler distribui mais intervalos de tempo para outros processos mais prioritários.
Em nossa prática, ajudou a definir bom como máximo (19 é a prioridade mínima, -20 (menos 20) é a máxima).
ionice - ajusta a prioridade da entrada / saída (programação de E / S)
Se você usa o RAID e precisa sincronizar repentinamente (após uma reinicialização malsucedida ou precisar restaurar a matriz RAID após a substituição do disco), em algumas situações, faz sentido reduzir a velocidade de sincronização para que outros processos funcionem mais ou menos adequadamente. Para fazer isso, o seguinte comando ajudará:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
O quinto problema: como sincronizar arquivos em tempo real
Temos as mesmas quantidades enormes de arquivos que precisam ser copiados para um segundo servidor para evitar ... Os arquivos são constantemente gravados; portanto, para ter um mínimo de perdas, é necessário copiá-los o mais rápido possível.
Solução padrão: Rsync sobre SSH.
Essa é uma boa opção, a menos que você precise fazer uma vez a cada poucos segundos. E há muitos arquivos. Mesmo que você não os copie, você ainda precisa entender de alguma forma o que mudou e comparar vários milhões de arquivos é o tempo e a carga nos discos.
I.e. precisamos saber imediatamente o que copiar, sem iniciar a comparação todas as vezes.
Salvação -
lsyncd .
Lsyncd -
Daemon de sincronização ao vivo (espelho) . Ele também funciona através do rsync, mas monitora adicionalmente o sistema de arquivos em busca de alterações usando inotify e fsevents e começa a copiar apenas os arquivos que apareceram ou foram alterados.
O sexto problema: como entender quem carrega os discos
Todo mundo provavelmente sabe disso, mas, no entanto, por uma
iotop integridade: para monitorar o subsistema de disco, existe o comando
iotop - como
top , mas mostra os processos que usam os discos mais ativamente.

A propósito, o bom e velho top também deixa claro que há problemas com os discos ou não. Existem dois parâmetros mais adequados para isso:
Load Average e
IOwait .
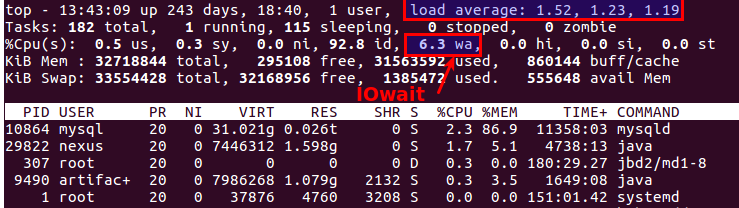
O primeiro mostra quantos processos estão na fila de serviço, geralmente mais de 2 - algo já está dando errado. Com a cópia ativa em servidores de backup, permitimos de 6 a 8, após o que a situação é considerada anormal.
O segundo é o quanto o processador está ocupado com as operações do disco. O IOwait> 10% é motivo de preocupação, embora em servidores com um perfil de carga específico seja estável de 40 a 50%, e essa é realmente a norma.
Termino aqui, embora provavelmente haja muitos pontos que não tivemos que enfrentar, ficarei feliz em aguardar comentários e descrições de casos reais interessantes.