Antes de começar a implementar um novo recurso, você precisa quebrar a cabeça de maneira justa.
O desenvolvimento de funcionalidades complexas requer uma boa coordenação dos esforços de uma equipe de engenheiros.
E um dos pontos mais importantes é a questão das tarefas paralelas.
É possível evitar que os soldados da linha de frente tenham que esperar por uma implementação de back-end? Existe uma maneira de paralelizar o desenvolvimento de fragmentos individuais da interface do usuário?
O tópico da paralelização de tarefas no desenvolvimento da Web será discutido neste artigo.
O problema
Então, vamos começar identificando o problema. Imagine que você tenha um produto experiente (serviço de Internet), no qual são coletados vários microsserviços diferentes. Cada microsserviço em seu sistema é um tipo de miniaplicativo integrado à arquitetura geral e resolve algum problema específico do usuário do serviço. Imagine que nesta manhã (o último dia do sprint), o Product Owner chamado Vasily se dirigiu a você e anunciou: "No próximo sprint, começamos a analisar a importação de dados, o que tornará os usuários do serviço ainda mais felizes. Isso permitirá que o usuário preencha o serviço imediatamente para suas posições duvidosas de 1C denso! ".
Imagine que você é um gerente ou líder de equipe e não está ouvindo todas essas descrições entusiásticas de usuários felizes do ponto de vista comercial. Você estima quanto trabalho tudo isso exigirá. Como um bom gerente, você faz todos os esforços para reduzir o apetite de Vasily pelas tarefas de pontuação para MVP (doravante, Produto Mínimo Viável). Ao mesmo tempo, os dois principais requisitos do MVP - a capacidade do sistema de importação de suportar uma grande carga e trabalhar em segundo plano, não podem ser descartados.
Você entende que a abordagem tradicional, quando todos os dados são processados na mesma solicitação do usuário, não funcionará. Aqui você tem que cercar o jardim de qualquer trabalhador em segundo plano. Você precisará vincular o barramento de eventos, pensar em como o balanceador de carga, o banco de dados distribuído etc. funciona. Em geral, todas as delícias da arquitetura de microsserviço. Como resultado, você conclui que o desenvolvimento do back-end para esse recurso se arrastará, não vá para vendedores de sorte.
A pergunta surge automaticamente: "O que os soldados da linha de frente farão todo esse tempo enquanto não houver API?".
Além disso, verifica-se que os dados não devem ser importados imediatamente. Você deve primeiro validá-los e permitir que o usuário corrija todos os erros encontrados. Acontece também um fluxo de trabalho astuto no front-end. E é necessário cortar o recurso, como de costume, "ontem". Conseqüentemente, os veteranos de guerra devem ser de alguma forma coordenados para que não batam em um nabo, não criem conflitos e vejam calmamente cada pedaço dele (veja KDPV no início do artigo).
Em uma situação diferente, poderíamos começar a serrar de trás para a frente. Primeiro, implemente o back-end e verifique se ele está segurando a carga e, em seguida, pendure calmamente o front-end nele. Mas o problema é que as especificações descrevem um novo recurso em termos gerais, têm lacunas e pontos controversos em termos de usabilidade. Mas e se, no final da implementação frontal, acontecer que, nesse formato, o recurso não satisfará o usuário? Alterações de usabilidade podem exigir alterações no modelo de dados. Teremos que refazer a frente e a traseira, o que será muito caro.
O Agile está tentando nos ajudar.
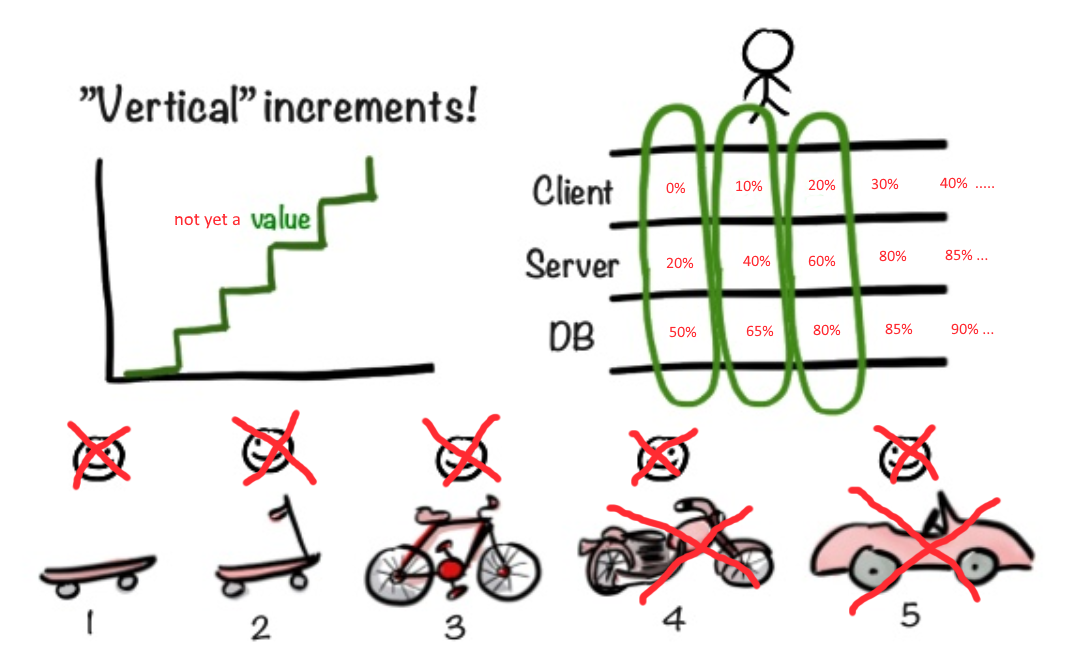
Metodologias flexíveis fornecem conselhos sábios. "Comece com o skate e mostre ao usuário. De repente, ele vai gostar. Se você gosta, continue na mesma linha, aperte as fichas novas."
Mas e se o usuário precisar imediatamente de pelo menos uma motocicleta e em duas a três semanas? E se, para começar a trabalhar na fachada da motocicleta, você precisa pelo menos decidir sobre as dimensões do motor e o tamanho do chassi?
Como garantir que a implementação da fachada não seja adiada até que haja certeza com as outras camadas do aplicativo?
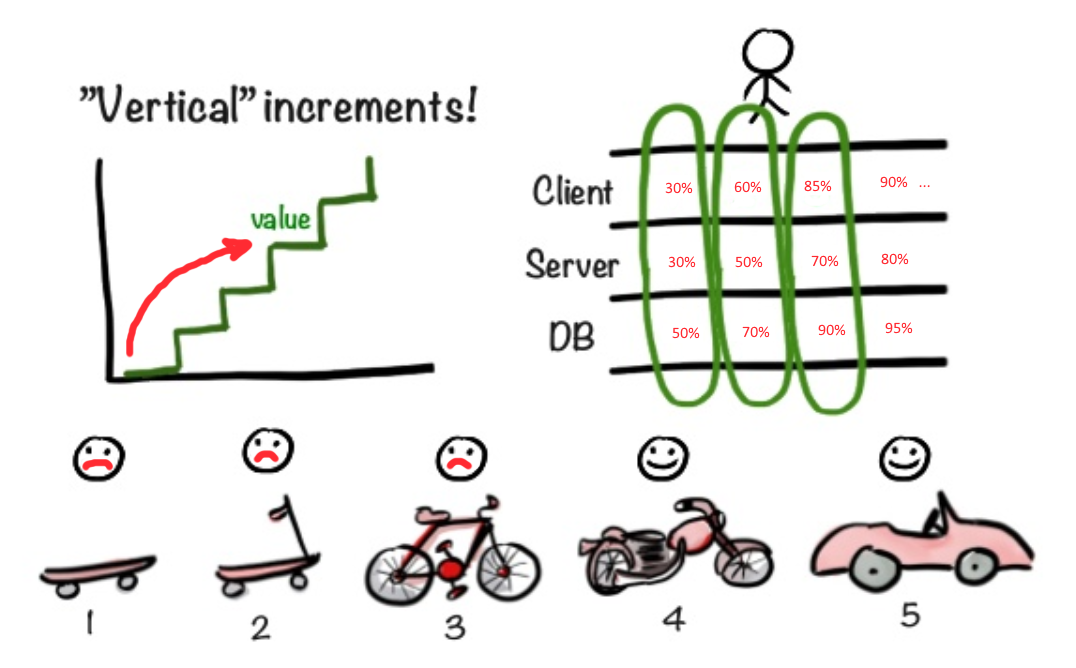
Em nossa situação, é melhor usar uma abordagem diferente. É melhor começar imediatamente a fazer uma fachada (frente) para garantir que a ideia inicial do MVP esteja correta. Por um lado, deslizar uma fachada decorativa para o Dono do produto Vasily, atrás do qual não há nada, parece estar enganando, uma fraude. Por outro lado, obtemos feedback muito rapidamente dessa maneira sobre a parte da funcionalidade que o usuário encontrará em primeiro lugar. Você pode ter uma arquitetura incrivelmente interessante, mas se não houver usabilidade, todo o aplicativo será lançado na borda do aplicativo, sem entender os detalhes. Portanto, parece-me mais importante fornecer a interface do usuário mais funcional o mais rápido possível, em vez de sincronizar o progresso da frente com o back-end. Não faz sentido emitir uma interface do usuário inacabada e fazer backup para testes, cuja funcionalidade não atende aos principais requisitos. Ao mesmo tempo, emitir 80% da funcionalidade necessária da interface do usuário, mas sem um back-end funcional, pode se tornar lucrativo.
Alguns detalhes técnicos
Então, eu já descrevi brevemente que recurso vamos implementar. Adicione alguns detalhes técnicos.
O usuário deve poder fazer upload de um arquivo de dados grande para o serviço. O conteúdo desse arquivo deve estar em um formato específico (por exemplo, CSV). O arquivo deve ter uma certa estrutura de dados e existem campos obrigatórios que não devem estar vazios. Em outras palavras, após o descarregamento no back-end, você precisará validar os dados. A validação pode durar um tempo considerável. Você não pode manter a conexão com o back-end aberta (ela será interrompida por tempo limite). Portanto, devemos aceitar rapidamente o arquivo e iniciar o processamento em segundo plano. No final da validação, devemos informar ao usuário que ele pode começar a editar os dados. O usuário deve corrigir os erros detectados durante a validação.
Após a correção de todos os erros, o usuário clica no botão Importar. Os dados corrigidos são enviados de volta ao back-end. para concluir o procedimento de importação. Devemos informar o front-end sobre o progresso de todas as etapas da importação.
A maneira mais eficaz de alertar é o WebSockets. De frente, através do Websocket com um determinado período, as solicitações serão enviadas para obter o status atual do processamento de dados em segundo plano. Para o processamento de dados em segundo plano, precisamos de manipuladores em segundo plano, uma fila de comandos distribuídos, barramento de eventos, etc.
O fluxo de dados é visto da seguinte forma (para referência):
- Por meio da API do navegador de arquivos, solicitamos que o usuário selecione o arquivo desejado no disco.
- Através do AJAX, enviamos o arquivo para o back-end.
- Estamos aguardando a validação e análise do arquivo de dados para concluir (pesquisamos o status da operação em segundo plano via Websocket).
- Após a conclusão da validação, carregaremos os dados preparados para importação e os renderizaremos na tabela na página de importação.
- O usuário edita dados, corrige erros. Ao clicar no botão na parte inferior da página, enviamos os dados corrigidos para o back-end.
- Novamente no lado do cliente, realizamos uma pesquisa periódica do status da operação em segundo plano.
- Até o final da importação atual, o usuário não poderá iniciar uma nova importação (mesmo na janela do navegador vizinho ou no computador vizinho).
Plano de desenvolvimento
UI do Mocap vs. Interface do usuário do protótipo

Vamos destacar imediatamente a diferença entre Wireframe, Maquete e Protótipo.
A imagem acima mostra o Wireframe. Este é apenas um desenho (em números ou em papel - isso não importa). Os outros dois conceitos são mais complicados.
Mocap é uma forma de apresentação da interface futura que é usada apenas como apresentação e será posteriormente substituída completamente. Este formulário será arquivado como uma amostra no futuro. A interface real será feita usando outras ferramentas. Um mocap pode ser feito em um editor de vetores com detalhes de design suficientes, mas os desenvolvedores de front-end simplesmente o colocam de lado e o espiam como modelo. O Mocap pode ser fabricado mesmo em construtores de navegadores especializados e vem com interatividade limitada. Mas seu destino é inalterado. Ele se tornará um modelo no álbum do Design Guide.
O protótipo é criado usando as mesmas ferramentas da futura interface do usuário (por exemplo, React). O código do protótipo está hospedado no repositório de aplicativos geral. Não será substituído, como é o caso do mocap. Primeiro, é usado para testar o conceito (Prova de conceito, PoC). Então, se passar no teste, eles começarão a desenvolvê-lo, transformando-o gradualmente em uma interface de usuário completa.
Agora mais perto do ponto ...
Imagine que os colegas do workshop de design nos apresentaram artefatos de seu processo criativo: modelos da interface futura. Nossa tarefa é planejar o trabalho para que, o mais rápido possível, torne possível o trabalho paralelo de veteranos.
À medida que a compilação do algoritmo começa com um fluxograma, iniciamos a criação de um protótipo com um Wireframe minimalista (veja a figura acima). Nesse Wireframe, dividimos a funcionalidade futura em grandes blocos. O principal princípio aqui é focar a responsabilidade. Você não deve dividir uma parte da funcionalidade em blocos diferentes. Moscas vão para um bloco e costeletas para outro.
Em seguida, você precisa criar uma página em branco (fictícia) o mais rápido possível, configurar o roteamento e colocar um link para esta página no menu. Então você precisa criar espaços em branco para os componentes básicos (um para cada bloco no protótipo Wireframe). E alimentar essa estrutura peculiar no ramo de desenvolvimento de um novo recurso.
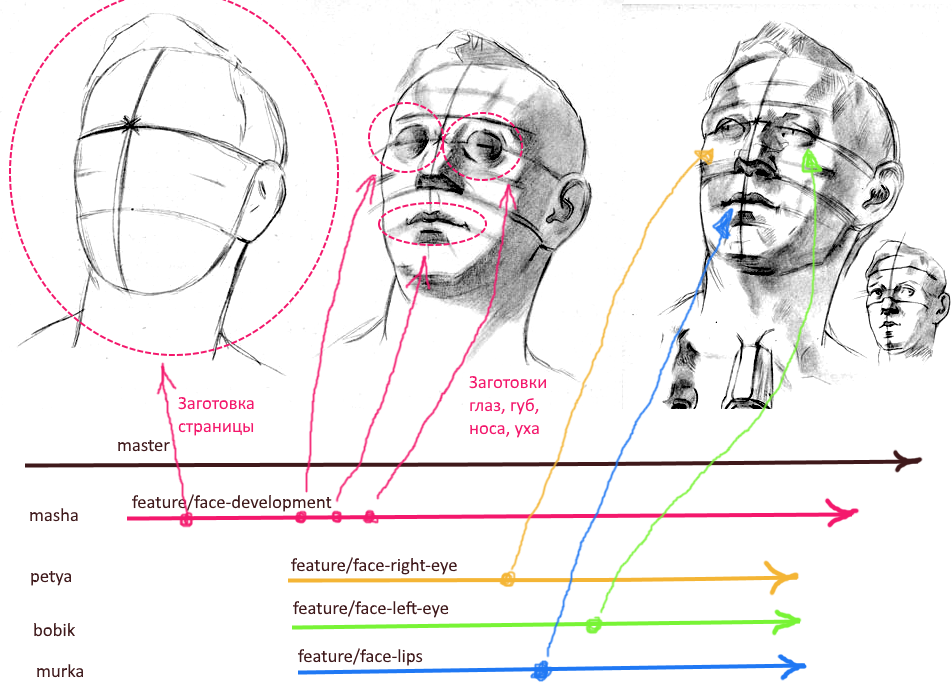
Temos a seguinte hierarquia de ramificações no git:
master ---------------------- > └ feature/import-dev ------ >
O ramo "import-dev" desempenhará o papel de brunch de desenvolvimento para todo o recurso. É aconselhável consertar uma pessoa responsável (mantenedor) nesse ramo que esteja mantendo alterações atômicas de todos os colegas que trabalham no recurso em paralelo. Também é aconselhável não fazer confirmações diretas neste ramo, a fim de reduzir a chance de conflitos e mudanças inesperadas quando houver fusões nesse ramo de solicitações de recebimento atômico.
Porque Neste momento, já criamos componentes para os blocos principais da página, então você pode criar imediatamente ramificações separadas para cada bloco da interface do usuário. A hierarquia final pode ser assim:
master ----------------------- > └ feature/import-dev ------- > ├ feature/import-head ---- > ├ feature/import-filter -- > ├ feature/import-table --- > ├ feature/import-pager --- > └ feature/import-footer -- >
Nota: não importa em que ponto criar esses brunches atômicos e a convenção de nomenclatura apresentada acima não é a única adequada. O brunch pode ser criado imediatamente antes de iniciar o trabalho. E os nomes dos brunches devem ser claros para todos os participantes do desenvolvimento. O nome deve ser o mais curto possível e, ao mesmo tempo, indicar explicitamente por qual parte da funcionalidade a filial é responsável.
Pela abordagem descrita acima, garantimos a operação sem conflitos de vários desenvolvedores da interface do usuário. Cada fragmento da interface do usuário tem seu próprio diretório na hierarquia do projeto. O catálogo de fragmentos contém o componente principal, seu conjunto de estilos e seu próprio conjunto de componentes filhos. Cada fragmento também pode ter seu próprio gerente de estado (partes MobX, Redux, VueX). Talvez os componentes do fragmento usem alguns estilos globais. No entanto, a alteração de estilos globais ao desenvolver um fragmento de uma nova página é proibida. Alterar o comportamento e o estilo padrão do átomo geral do design também não vale a pena.
Nota: “átomo de projeto” significa um elemento do conjunto de componentes padrão de nosso serviço - consulte Projeto atômico ; no nosso caso, supõe-se que o sistema Atomic Design já tenha sido implementado.
Então, separamos fisicamente os soldados da linha de frente um do outro. Agora, cada um deles pode trabalhar em silêncio, sem medo de conflitos com a fusão. Além disso, qualquer pessoa pode, a qualquer momento, criar uma solicitação pull de sua ramificação no recurso / import-dev . Agora já é possível lançar com calma conteúdo estático e até formar interativo em um armazenamento de estado.
Mas como garantimos que os fragmentos da interface do usuário possam interagir entre si?
Precisamos implementar o link entre os fragmentos. O serviço JS, atuando como um gateway para troca de dados com o suporte, é adequado para a função de um link entre fragmentos. Através do mesmo serviço, você pode implementar a notificação de eventos. Ao assinar certos eventos, os fragmentos incluirão implicitamente o ciclo de vida geral do microsserviço. Alterações nos dados em um fragmento tornarão necessário atualizar o estado de outro fragmento. Em outras palavras, fizemos a integração de fragmentos por meio de dados e um modelo de evento.
Para criar este serviço, precisamos de mais uma ramificação no git:
master --------------------------- > └ feature/import-dev ----------- > ├ feature/import-js-service -- > ├ feature/import-head -------- > ├ feature/import-filter ------ > ├ feature/import-table ------- > ├ feature/import-pager ------- > └ feature/import-footer ------ >
Nota: não tenha medo do número de galhos e não hesite em produzir galhos. O Git permite que você trabalhe eficientemente com um grande número de ramificações. Quando um hábito se desenvolve, fica fácil ramificar:
$/> git checkout -b feature/import-service $/> git commit . $/> git push origin HEAD $/> git checkout feature/import-dev $/> git merge feature/import-service
Isso parecerá tenso para alguns, mas o lucro de minimizar conflitos é mais significativo. Além disso, enquanto você é o proprietário exclusivo da filial, você pode pressionar -f com segurança sem arriscar danos ao histórico local de confirmações de alguém.
Dados falsos
Portanto, no estágio anterior, preparamos o serviço JS de integração (importService) e preparamos os fragmentos da interface do usuário. Mas sem dados, nosso protótipo não funcionará. Nada é desenhado, exceto decorações estáticas.
Agora precisamos decidir sobre um modelo de dados aproximado e criar esses dados na forma de arquivos JSON ou JS (a escolha a favor de um ou outro depende das configurações de importação em seu projeto; o json-loader está configurado). Nosso importService, bem como seus testes (pensaremos mais adiante), importam desses arquivos os dados necessários para simular respostas de um back-end real (ele ainda não foi implementado). Onde colocar esses dados não é importante. O principal é que eles podem ser facilmente importados para o importService e são testados em nosso microsserviço.
É recomendável discutir o formato dos dados, a convenção de nomenclatura de campo com os desenvolvedores das costas imediatamente. Você pode, por exemplo, concordar em usar um formato que esteja em conformidade com a Especificação OpenAPI . Quaisquer que sejam as especificações do formato de suporte, criamos dados falsos exatamente de acordo com o formato dos dados de suporte.
Nota: não tenha medo de cometer um erro com o modelo de dados falsos; Sua tarefa é fazer uma versão preliminar do contrato de dados, que ainda será acordado com os desenvolvedores de back-end.
Contratos
Dados falsos podem servir como um bom começo para começar a trabalhar na especificação da futura API no back-end. E aqui não importa quem e como a alta qualidade implementa o modelo de rascunho. Crucial é a discussão e coordenação conjuntas com a participação de desenvolvedores da frente e de trás.
Você pode usar ferramentas especializadas para descrever contratos (especificações da API). Por exemplo, OpenAPI / Swagger . De uma maneira boa, ao descrever uma API com essa ferramenta, não é necessário que todos os desenvolvedores estejam presentes. Isso pode ser feito por um desenvolvedor (editor de especificações). O resultado de uma discussão coletiva da nova API seria alguns artefatos como MFU (Meeting Follow Up), segundo o qual o editor de especificação cria uma referência para a futura API.
No final do rascunho da especificação, não deve demorar muito para verificar a correção. Cada participante da discussão coletiva poderá, independentemente dos outros, fazer uma inspeção superficial para verificar se sua opinião foi levada em consideração. Se algo parecer incorreto, será possível esclarecer através das especificações do editor (comunicações normais de trabalho). Se todos estiverem satisfeitos com a especificação, ela poderá ser publicada e usada como documentação para o serviço.
Teste de Unidade
Nota: Para mim, o valor dos testes de unidade é bastante baixo. Aqui eu concordo com David Heinemeier Hansson @ RailsConf . "Os testes de unidade são uma ótima maneira de garantir que seu programa faça o que você pode fazer ... conforme o esperado." Mas admito casos especiais em que os testes de unidade trazem muitos benefícios.
Agora que decidimos os dados falsos, podemos começar a testar a funcionalidade básica. Para testar componentes front-end, você pode usar ferramentas como karma, gracejo, mocha, chai, jasmim. Geralmente, o arquivo com o mesmo nome com o postfix "spec" ou "test" é colocado ao lado do recurso JS em teste:
importService ├ importService.js └ importService.test.js
O valor específico do postfix depende das configurações do coletor de pacotes JS em seu projeto.
Obviamente, em uma situação em que as costas estão em um estado "contraceptivo", é muito difícil cobrir todos os casos possíveis com testes de unidade. Mas o objetivo dos testes de unidade é um pouco diferente. Eles são projetados para testar o funcionamento de partes individuais da lógica.
Por exemplo, é bom cobrir vários tipos de auxiliares com testes de unidade, por meio dos quais partes da lógica ou certos algoritmos são compartilhados entre componentes e serviços JS. Além disso, esses testes podem cobrir o comportamento nos componentes e lojas do MobX, Redux, VueX em resposta a alterações de dados do usuário.
Integração e teste E2E
Testes de integração significam verificar o comportamento do sistema quanto à conformidade com a especificação. I.e. verifica-se que o usuário verá exatamente o comportamento descrito nas especificações. Este é um nível mais alto de teste comparado aos testes de unidade.
Por exemplo, um teste que verifica se há um erro no campo obrigatório quando o usuário apagou todo o texto. Ou um teste que verifica se um erro é gerado ao tentar salvar dados inválidos.
Os testes E2E (ponta a ponta) funcionam em um nível ainda mais alto. Eles verificam se o comportamento da interface do usuário está correto. Por exemplo, verificando se, após enviar o arquivo de dados para o serviço, é mostrado ao usuário um toque que sinaliza um processo assíncrono contínuo. Ou verifique se a visualização dos componentes padrão do serviço corresponde aos guias dos projetistas.
Esse tipo de teste funciona com alguma estrutura de automação da interface do usuário. Por exemplo, poderia ser selênio . Esses testes, juntamente com o Selenium WebDriver, são executados em alguns navegadores (geralmente o Chrome no "modo sem cabeça"). Eles trabalham por um longo tempo, mas reduzem a carga dos especialistas em controle de qualidade, fazendo um teste de fumaça para eles.
Escrever esses tipos de testes consome bastante tempo. Quanto mais cedo começarmos a escrevê-los, melhor. Apesar de não termos um backup completo, já podemos começar a descrever os testes de integração. Já temos uma especificação.
Com uma descrição do E2E, há ainda menos testes de obstáculos. Já esboçamos os componentes padrão da biblioteca de átomos de design. Implementou partes específicas da interface do usuário. Fez alguns interativos sobre dados falsos e API no importService. Nada impede que você inicie a automação da interface do usuário, pelo menos em casos básicos.
Ao escrever esses testes, você pode novamente desconcertar desenvolvedores individuais se não houver pessoas desconcertadas. E também para descrever os testes, você pode criar uma ramificação separada (como descrito acima). Nas ramificações para testes, será necessário atualizar periodicamente as atualizações da ramificação " feature / import-dev ".
A sequência geral de mesclagens será a seguinte:
- Por exemplo, um desenvolvedor da filial " feature / import-filter " criou um PR. Esse PR é visualizado e o mantenedor da ramificação " feature / import-dev " injeta esse PR.
- O mantenedor anuncia que a atualização foi derramada.
- O desenvolvedor na ramificação " feature / import-tests-e2e " obtém alterações extremas com a mesclagem da ramificação "-dev.
CI e automação de teste
Os testes de front-end são implementados usando ferramentas que funcionam através da CLI. No package.json, os comandos são escritos para executar diferentes tipos de testes. Esses comandos não são usados apenas pelos desenvolvedores no ambiente local. Eles também são necessários para executar testes no ambiente de CI (Continuous Integration).
Se agora executarmos a compilação no IC e não houver erros, nosso protótipo aguardado será entregue ao ambiente de teste (80% da funcionalidade na frente com um back-end ainda não implementado). Podemos mostrar a Vasily o comportamento aproximado do futuro microsserviço. Vasiliy chuta esse protótipo e, talvez, faça algumas observações (talvez até sérias). Nesta fase, fazer ajustes não é caro. No nosso caso, o apoio requer sérias mudanças arquiteturais; portanto, o trabalho nele pode ser mais lento do que na frente. Enquanto o apoio não for finalizado, as alterações no plano de desenvolvimento não levarão a conseqüências desastrosas. Se necessário, altere alguma coisa nesta fase, solicitaremos que você faça ajustes na especificação da API (em excesso). Depois disso, as etapas descritas acima são repetidas. Os funcionários da linha de frente ainda não dependem de back-end. Os especialistas individuais em front-end são independentes um do outro.
Backend. Controladores de stub
O ponto de partida para o desenvolvimento da API no backend é a especificação da API aprovada ( OpenAPI / Swagger ). Se houver uma especificação, o apoio também ficará mais fácil de paralelizar. A análise da especificação deve levar os desenvolvedores a pensar sobre os elementos básicos da arquitetura. Quais componentes / serviços comuns você precisa criar antes de prosseguir com a implementação de chamadas de API individuais. E aqui novamente, você pode aplicar a abordagem como nos espaços em branco da interface do usuário.
Podemos começar de cima, ou seja, da camada externa de nossas costas (dos controladores). Nesta fase, começamos com roteamento, espaços em branco do controlador e dados falsos. A camada de serviços (BL) e acesso a dados (DAL) ainda não fazemos. Simplesmente transferimos os dados do JS para o back-end e programamos os controladores para que eles implementem as respostas esperadas para os casos básicos, distribuindo partes dos dados falsos.
Após a conclusão desse estágio, os soldados da linha de frente devem ter um back-end de trabalho com dados de teste estáticos. Além disso, são precisamente os dados nos quais os soldados da linha de frente escrevem testes de integração. Em princípio, neste momento não deve ser difícil alternar o gateway JS (importService) para usar espaços em branco do controlador nas costas.
A parte de resposta para solicitações por meio do Websocket não é conceitualmente diferente dos controladores de API da Web. Também fazemos essa "resposta" nos dados de teste e conectamos importService a esta preparação.
Por fim, todas as JS devem ser transferidas para trabalhar com um servidor real.
Backend. Finalização de controladores. Stubs DAO
Agora é a vez de finalizar a camada de apoio externo. Para controladores, os serviços são implementados um a um no BL. Agora os serviços funcionarão com dados falsos. A adição nesse estágio é que, nos serviços, já implementamos uma lógica de negócios real. Nesse estágio, é aconselhável começar a adicionar novos testes de acordo com a lógica comercial das especificações. É importante que nenhum teste de integração caia.
Nota: ainda não dependemos se o esquema de dados está implementado no banco de dados.
Backend. Finalize o DAO. Db real
Depois que o esquema de dados é implementado no banco de dados, podemos transferir os dados de teste das etapas anteriores para ele e mudar nosso DAL rudimentar para trabalhar com o servidor de banco de dados real. Porque Se transferirmos os dados iniciais criados para a frente do banco de dados, todos os testes devem permanecer relevantes. Se algum dos testes cair, algo deu errado e você precisa entender.
Nota: em geral, com uma probabilidade muito alta de trabalhar com o esquema de dados no banco de dados, haverá pouco para um novo recurso; talvez alterações no banco de dados sejam feitas simultaneamente com a implementação de serviços no BL.
No final deste estágio, obtemos uma versão alfa do microsserviço completo. Esta versão já pode ser exibida para usuários internos (Dono do produto, um tecnólogo do produto ou outra pessoa) para avaliação como MVP.
As iterações padrão do Agile sobre o trabalho de correção de bugs, implementação de chips adicionais e polimento final continuarão.
Conclusão
Eu acho que você não deve usar o acima cegamente como um guia de ação. Primeiro você precisa experimentar e se adaptar ao seu projeto. A abordagem descrita acima é capaz de desatar desenvolvedores individuais um do outro e permitir que eles trabalhem em paralelo sob certas condições. Todos os gestos com brunching e transferência de dados, a implementação de espaços em branco em dados falsos parecem uma sobrecarga significativa. O lucro nessa sobrecarga aparece devido ao aumento da simultaneidade. Se a equipe de desenvolvimento consiste um escavador e meio duas stacks completas ou um freotovik com um back-end, provavelmente haverá muito lucro com essa abordagem. Embora nessa situação, alguns pontos possam aumentar a eficácia do desenvolvimento.
O lucro dessa abordagem aparece quando, no início, implementamos rapidamente as peças o mais próximo possível de uma futura implementação real e separamos fisicamente o trabalho em diferentes partes no nível da estrutura de arquivos no projeto e no sistema de gerenciamento de código (git).
Espero que você tenha achado este artigo útil.
Obrigado pela atenção!